id,node_id,number,title,user,state,locked,assignee,milestone,comments,created_at,updated_at,closed_at,author_association,pull_request,body,repo,type,active_lock_reason,performed_via_github_app,reactions,draft,state_reason
999902754,I_kwDOBm6k_c47mU4i,1473,base logo link visits `undefined` rather than href url,192568,open,0,,,2,2021-09-18T04:17:04Z,2021-09-19T00:45:32Z,,CONTRIBUTOR,,"I have two connected sites:
http://www.SaferOrToxic.org
(a Hugo website)
and:
http://disinfectants.SaferOrToxic.org/disinfectants/listN
(a datasette table page)
The latter is linked as ""The List"" in the former's menu.
(I'd love a prettier URL, but that's what I've got.)
On:
http://disinfectants.SaferOrToxic.org/disinfectants/listN
... all the other menu links should point back to:
https://www.SaferOrToxic.org
And they do!
But the logo, for some reason--though it has an href pointing to:
https://www.SaferOrToxic.org
Keeps going to this instead:
https://disinfectants.saferortoxic.org/disinfectants/undefined
What is causing that? How can I fix it?
In #1284 back in March, I was doing battle with the index.html template, in a still unresolved issue. (I wanted only a single table page at the root.)
But I thought, well, if I can't resolve that, at least I could just point the main website to the datasette page (""The List,"") and then have the List point back to the home website.
The menu hrefs to https://www.SaferOrToxic.org work just fine, exactly as they should, from the datasette page. Even the Home link works properly.
But the logo link keeps rewriting to: https://disinfectants.saferortoxic.org/disinfectants/undefined
This is the HTML:
```
![]() ```
Is this somehow related to cloudflare?
Or something in the datasette code?
I'm starting to think it's a cloudflare issue.
```
Is this somehow related to cloudflare?
Or something in the datasette code?
I'm starting to think it's a cloudflare issue.
![]() Can I at least rule out it being a datasette issue?
My repository is here:
https://github.com/mroswell/list-N
(BTW, I couldn't figure out how to reference a local image, either, on the datasette side, which is why I'm using the image from the www home page.)
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1473/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1006781949,I_kwDOBm6k_c48AkX9,1478,Documentation Request: Feature alternative ID instead of default ID,192568,open,0,,,0,2021-09-24T19:56:13Z,2021-09-25T16:18:54Z,,CONTRIBUTOR,,"My data already has an ID that comes from a federal agency.
Would love to have documentation on how to modify the template to:
- Remove the generated ID from the table
- Link the federal ID to the detail page
- and to ensure that the JSON file uses that as the ID. I'd be happy to include the database ID in the export, but not as a key.
I don't want to remove the ID from the database, though, because my experience with the federal agency is that data often has anomalies. I don't want all hell to break loose if they end up applying the same ID to multiple rows (which they haven't done yet). I just don't want it to display in the table or the data exports.
Perhaps this isn't a template issue, maybe more of a db manipulation...
Margie",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1478/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1023243105,I_kwDOBm6k_c48_XNh,1486,pipx installation instructions for plugins don't reference pipx inject,41546558,closed,0,,,0,2021-10-12T00:43:42Z,2021-10-13T21:09:11Z,2021-10-13T21:09:11Z,CONTRIBUTOR,,"The datasette [installation instructions](https://github.com/simonw/datasette/blob/main/docs/installation.rst) discuss how to install with pipx, how to upgrade with pipx, and how to upgrade plugins with pipx but do not mention how to install a plugin with pipx. You discussed this on your [blog](https://til.simonwillison.net/python/installing-upgrading-plugins-with-pipx) but looks like this didn't make it in when you updated the docs for pipx (#756).
I'll submit a PR shortly to fix this.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1486/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1015646369,I_kwDOBm6k_c48iYih,1480,Exceeding Cloud Run memory limits when deploying a 4.8G database,110420,open,0,,,9,2021-10-04T21:20:24Z,2022-10-07T04:39:10Z,,CONTRIBUTOR,,"When I try to deploy a 4.8G SQLite database to Google Cloud Run, I get this error message:
> Memory limit of 8192M exceeded with 8826M used. Consider increasing the memory limit, see https://cloud.google.com/run/docs/configuring/memory-limits
Unfortunately, the maximum amount of memory that can be allocated to an instance is 8192M.
Naively profiling the memory usage of running Datasette with this database locally on my MacBook shows the following memory usage (using Activity Monitor) when I just start up Datasette locally:
- Real Memory Size: 70.6 MB
- Virtual Memory Size: 4.51 GB
- Shared Memory Size: 2.5 MB
- Private Memory Size: 57.4 MB
I'm trying to understand if there's a query or other operation that gets run during container deployment that causes memory use to be so large and if this can be avoided somehow.
This is somewhat related to #1082, but on a different platform, so I decided to open a new issue.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1480/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1059549523,I_kwDOBm6k_c4_J3FT,1526,"Add to vercel.json, rather than overwriting it.",192568,closed,0,,,2,2021-11-22T00:47:12Z,2021-11-22T04:49:45Z,2021-11-22T04:13:47Z,CONTRIBUTOR,,"I'd like to be able to add to vercel.json. But Datasette overwrites whatever I put in that file. I originally reported this here:
https://github.com/simonw/datasette-publish-vercel/issues/51
In that case, I wanted to do a rewrite... and now I need to do 301 redirects (because we had to rename our site).
Can this be addressed?
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1526/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1060631257,I_kwDOBm6k_c4_N_LZ,1528,"Add new `""sql_file""` key to Canned Queries in metadata?",15178711,open,0,,,3,2021-11-22T21:58:01Z,2022-06-10T03:23:08Z,,CONTRIBUTOR,,"Currently for canned queries, you have to inline SQL in your `metadata.yaml` like so:
```yaml
databases:
fixtures:
queries:
neighborhood_search:
sql: |-
select neighborhood, facet_cities.name, state
from facetable
join facet_cities on facetable.city_id = facet_cities.id
where neighborhood like '%' || :text || '%'
order by neighborhood
title: Search neighborhoods
```
This works fine, but for a few reasons, I usually have my canned queries already written in separate `.sql` files. I'd like to instead re-use those instead of re-writing it.
So, I'd like to see a new `""sql_file""` key that works like so:
`metadata.yaml`:
```yaml
databases:
fixtures:
queries:
neighborhood_search:
sql_file: neighborhood_search.sql
title: Search neighborhoods
```
`neighborhood_search.sql`:
```sql
select neighborhood, facet_cities.name, state
from facetable
join facet_cities on facetable.city_id = facet_cities.id
where neighborhood like '%' || :text || '%'
order by neighborhood
```
Both of these would work in the exact same way, where Datasette would instead open + include `neighborhood_search.sql` on startup.
A few reasons why I'd like to keep my canned queries SQL separate from metadata.yaml:
- Keeping SQL in standalone SQL files means syntax highlighting and other text editor integrations in my code
- Multiline strings in yaml, while functional, are a tad cumbersome and are hard to edit
- Works well with other tools (can pipe `.sql` files into the `sqlite3` CLI, or use with other SQLite clients easier)
- Typically my canned queries are quite long compared to everything else in my metadata.yaml, so I'd love to separate it where possible
Let me know if this is a feature you'd like to see, I can try to send up a PR if this sounds right!",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1528/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1994857251,I_kwDOBm6k_c525xsj,2208,No suggested facets when a column named 'value' is included,198537,open,0,,,1,2023-11-15T14:11:17Z,2023-11-15T14:18:59Z,,CONTRIBUTOR,,"When a column named 'value' is included there are no suggested facets is shown as the query uses an alias of 'value'.
https://github.com/simonw/datasette/blob/452a587e236ef642cbc6ae345b58767ea8420cb5/datasette/facets.py#L168-L174
Currently the following is shown (from https://latest.datasette.io/fixtures/facetable)

When I add a column named 'value' only the JSON facets are processed.

I think that not using aliases could be a solution (except if someone wants to use a column named `count(*)` though this seems to be unlikely). I'll open a PR with that.
There is also a TODO with a similar question in the same file. I have not looked into that yet.
https://github.com/simonw/datasette/blob/452a587e236ef642cbc6ae345b58767ea8420cb5/datasette/facets.py#L512",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2208/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
2028698018,I_kwDOBm6k_c5463mi,2213,feature request: gzip compression of database downloads,536941,open,0,,,1,2023-12-06T14:35:03Z,2023-12-06T15:05:46Z,,CONTRIBUTOR,,"At the bottom of database pages, datasette gives users the opportunity to download the underlying sqlite database. It would be great if that could be served gzip compressed.
this is similar to #1213, but for me, i don't need datasette to compress html and json because my CDN layer does it for me, however, cloudflare at least, will not compress a mimetype of ""application""
(see list of mimetype: https://developers.cloudflare.com/speed/optimization/content/brotli/content-compression/)",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2213/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1089529555,I_kwDOBm6k_c5A8ObT,1581,"when hashed urls are turned on, the _memory db has improperly long-lived cache expiry",536941,closed,0,,,1,2021-12-28T00:05:48Z,2022-03-24T04:08:18Z,2022-03-24T04:08:18Z,CONTRIBUTOR,,"if hashed_urls are on, then a -000 suffix is added to the `_memory` database, and the cache settings are set just as if it was a normal hashed database.
in particular, this header is set:
`cache-control: max-age=31536000`
this is not appropriate because the `_memory-000` database isn't really hashed based on the contents of the databases (see #1561).
Either the cache-control header should be changed, or the _memory db should have a hash suffix that does depend on the contents of the databases.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1581/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1076388044,I_kwDOBm6k_c5AKGDM,1547,Writable canned queries fail to load custom templates,127565,closed,0,,7571612,6,2021-12-10T03:31:48Z,2022-01-13T22:27:59Z,2021-12-19T21:12:00Z,CONTRIBUTOR,,"I've created a canned query with `""write"": true` set. I've also created a custom template for it, but the template doesn't seem to be found. If I look in the HTML I see (`stock_exchange` is the db name):
``
My non-writeable canned queries pick up custom templates as expected, and if I look at their HTML I see the canned query name added to the templates considered (the canned query here is `date_search`):
``
So it seems like the writeable canned query is behaving differently for some reason. Is it an authentication thing? I'm using the built in `--root` authentication.
Thanks!
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1547/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1077620955,I_kwDOBm6k_c5AOzDb,1549,Redesign CSV export to improve usability,536941,open,0,,3268330,5,2021-12-11T19:02:12Z,2022-04-04T11:17:13Z,,CONTRIBUTOR,,"*Original title: Set content type for CSV so that browsers will attempt to download instead opening in the browser*
Right now, if the user clicks on the CSV related to a
Can I at least rule out it being a datasette issue?
My repository is here:
https://github.com/mroswell/list-N
(BTW, I couldn't figure out how to reference a local image, either, on the datasette side, which is why I'm using the image from the www home page.)
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1473/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1006781949,I_kwDOBm6k_c48AkX9,1478,Documentation Request: Feature alternative ID instead of default ID,192568,open,0,,,0,2021-09-24T19:56:13Z,2021-09-25T16:18:54Z,,CONTRIBUTOR,,"My data already has an ID that comes from a federal agency.
Would love to have documentation on how to modify the template to:
- Remove the generated ID from the table
- Link the federal ID to the detail page
- and to ensure that the JSON file uses that as the ID. I'd be happy to include the database ID in the export, but not as a key.
I don't want to remove the ID from the database, though, because my experience with the federal agency is that data often has anomalies. I don't want all hell to break loose if they end up applying the same ID to multiple rows (which they haven't done yet). I just don't want it to display in the table or the data exports.
Perhaps this isn't a template issue, maybe more of a db manipulation...
Margie",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1478/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1023243105,I_kwDOBm6k_c48_XNh,1486,pipx installation instructions for plugins don't reference pipx inject,41546558,closed,0,,,0,2021-10-12T00:43:42Z,2021-10-13T21:09:11Z,2021-10-13T21:09:11Z,CONTRIBUTOR,,"The datasette [installation instructions](https://github.com/simonw/datasette/blob/main/docs/installation.rst) discuss how to install with pipx, how to upgrade with pipx, and how to upgrade plugins with pipx but do not mention how to install a plugin with pipx. You discussed this on your [blog](https://til.simonwillison.net/python/installing-upgrading-plugins-with-pipx) but looks like this didn't make it in when you updated the docs for pipx (#756).
I'll submit a PR shortly to fix this.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1486/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1015646369,I_kwDOBm6k_c48iYih,1480,Exceeding Cloud Run memory limits when deploying a 4.8G database,110420,open,0,,,9,2021-10-04T21:20:24Z,2022-10-07T04:39:10Z,,CONTRIBUTOR,,"When I try to deploy a 4.8G SQLite database to Google Cloud Run, I get this error message:
> Memory limit of 8192M exceeded with 8826M used. Consider increasing the memory limit, see https://cloud.google.com/run/docs/configuring/memory-limits
Unfortunately, the maximum amount of memory that can be allocated to an instance is 8192M.
Naively profiling the memory usage of running Datasette with this database locally on my MacBook shows the following memory usage (using Activity Monitor) when I just start up Datasette locally:
- Real Memory Size: 70.6 MB
- Virtual Memory Size: 4.51 GB
- Shared Memory Size: 2.5 MB
- Private Memory Size: 57.4 MB
I'm trying to understand if there's a query or other operation that gets run during container deployment that causes memory use to be so large and if this can be avoided somehow.
This is somewhat related to #1082, but on a different platform, so I decided to open a new issue.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1480/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1059549523,I_kwDOBm6k_c4_J3FT,1526,"Add to vercel.json, rather than overwriting it.",192568,closed,0,,,2,2021-11-22T00:47:12Z,2021-11-22T04:49:45Z,2021-11-22T04:13:47Z,CONTRIBUTOR,,"I'd like to be able to add to vercel.json. But Datasette overwrites whatever I put in that file. I originally reported this here:
https://github.com/simonw/datasette-publish-vercel/issues/51
In that case, I wanted to do a rewrite... and now I need to do 301 redirects (because we had to rename our site).
Can this be addressed?
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1526/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1060631257,I_kwDOBm6k_c4_N_LZ,1528,"Add new `""sql_file""` key to Canned Queries in metadata?",15178711,open,0,,,3,2021-11-22T21:58:01Z,2022-06-10T03:23:08Z,,CONTRIBUTOR,,"Currently for canned queries, you have to inline SQL in your `metadata.yaml` like so:
```yaml
databases:
fixtures:
queries:
neighborhood_search:
sql: |-
select neighborhood, facet_cities.name, state
from facetable
join facet_cities on facetable.city_id = facet_cities.id
where neighborhood like '%' || :text || '%'
order by neighborhood
title: Search neighborhoods
```
This works fine, but for a few reasons, I usually have my canned queries already written in separate `.sql` files. I'd like to instead re-use those instead of re-writing it.
So, I'd like to see a new `""sql_file""` key that works like so:
`metadata.yaml`:
```yaml
databases:
fixtures:
queries:
neighborhood_search:
sql_file: neighborhood_search.sql
title: Search neighborhoods
```
`neighborhood_search.sql`:
```sql
select neighborhood, facet_cities.name, state
from facetable
join facet_cities on facetable.city_id = facet_cities.id
where neighborhood like '%' || :text || '%'
order by neighborhood
```
Both of these would work in the exact same way, where Datasette would instead open + include `neighborhood_search.sql` on startup.
A few reasons why I'd like to keep my canned queries SQL separate from metadata.yaml:
- Keeping SQL in standalone SQL files means syntax highlighting and other text editor integrations in my code
- Multiline strings in yaml, while functional, are a tad cumbersome and are hard to edit
- Works well with other tools (can pipe `.sql` files into the `sqlite3` CLI, or use with other SQLite clients easier)
- Typically my canned queries are quite long compared to everything else in my metadata.yaml, so I'd love to separate it where possible
Let me know if this is a feature you'd like to see, I can try to send up a PR if this sounds right!",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1528/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1994857251,I_kwDOBm6k_c525xsj,2208,No suggested facets when a column named 'value' is included,198537,open,0,,,1,2023-11-15T14:11:17Z,2023-11-15T14:18:59Z,,CONTRIBUTOR,,"When a column named 'value' is included there are no suggested facets is shown as the query uses an alias of 'value'.
https://github.com/simonw/datasette/blob/452a587e236ef642cbc6ae345b58767ea8420cb5/datasette/facets.py#L168-L174
Currently the following is shown (from https://latest.datasette.io/fixtures/facetable)

When I add a column named 'value' only the JSON facets are processed.

I think that not using aliases could be a solution (except if someone wants to use a column named `count(*)` though this seems to be unlikely). I'll open a PR with that.
There is also a TODO with a similar question in the same file. I have not looked into that yet.
https://github.com/simonw/datasette/blob/452a587e236ef642cbc6ae345b58767ea8420cb5/datasette/facets.py#L512",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2208/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
2028698018,I_kwDOBm6k_c5463mi,2213,feature request: gzip compression of database downloads,536941,open,0,,,1,2023-12-06T14:35:03Z,2023-12-06T15:05:46Z,,CONTRIBUTOR,,"At the bottom of database pages, datasette gives users the opportunity to download the underlying sqlite database. It would be great if that could be served gzip compressed.
this is similar to #1213, but for me, i don't need datasette to compress html and json because my CDN layer does it for me, however, cloudflare at least, will not compress a mimetype of ""application""
(see list of mimetype: https://developers.cloudflare.com/speed/optimization/content/brotli/content-compression/)",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2213/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1089529555,I_kwDOBm6k_c5A8ObT,1581,"when hashed urls are turned on, the _memory db has improperly long-lived cache expiry",536941,closed,0,,,1,2021-12-28T00:05:48Z,2022-03-24T04:08:18Z,2022-03-24T04:08:18Z,CONTRIBUTOR,,"if hashed_urls are on, then a -000 suffix is added to the `_memory` database, and the cache settings are set just as if it was a normal hashed database.
in particular, this header is set:
`cache-control: max-age=31536000`
this is not appropriate because the `_memory-000` database isn't really hashed based on the contents of the databases (see #1561).
Either the cache-control header should be changed, or the _memory db should have a hash suffix that does depend on the contents of the databases.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1581/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1076388044,I_kwDOBm6k_c5AKGDM,1547,Writable canned queries fail to load custom templates,127565,closed,0,,7571612,6,2021-12-10T03:31:48Z,2022-01-13T22:27:59Z,2021-12-19T21:12:00Z,CONTRIBUTOR,,"I've created a canned query with `""write"": true` set. I've also created a custom template for it, but the template doesn't seem to be found. If I look in the HTML I see (`stock_exchange` is the db name):
``
My non-writeable canned queries pick up custom templates as expected, and if I look at their HTML I see the canned query name added to the templates considered (the canned query here is `date_search`):
``
So it seems like the writeable canned query is behaving differently for some reason. Is it an authentication thing? I'm using the built in `--root` authentication.
Thanks!
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1547/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1077620955,I_kwDOBm6k_c5AOzDb,1549,Redesign CSV export to improve usability,536941,open,0,,3268330,5,2021-12-11T19:02:12Z,2022-04-04T11:17:13Z,,CONTRIBUTOR,,"*Original title: Set content type for CSV so that browsers will attempt to download instead opening in the browser*
Right now, if the user clicks on the CSV related to a table or a query, the response header for the content type is
""content-type: text/plain; charset=utf-8""
Most browsers will try to open a file with this content-type in the browser.
This is not what most people want to do, and lots of folks don't know that if they want to download the CSV and open it in the a spreadsheet program they next need to save the page through their browser.
It would be great if the response header could be something like
```
'Content-type: text/csv');
'Content-disposition: attachment;filename=MyVerySpecial.csv');
```
which would lead browsers to open a download dialog.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1549/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1078702875,I_kwDOBm6k_c5AS7Mb,1552,Allow to set `facets_array` in metadata (like current `facets`),3556,closed,0,,7571612,9,2021-12-13T16:00:44Z,2022-01-13T22:26:15Z,2021-12-16T18:47:48Z,CONTRIBUTOR,,"For now, you can set a `facets` value (array) in your metadata file but I couldn't find a way to set a `facets_array` in order to provide default facets for arrays (like tags). My use-case is to access to [that kind of view](https://latest.datasette.io/fixtures/facetable?_facet_array=tags) by default without URL's parameters as with other default facets.
_I'm new to datasette, and I'm willing to help with a PR if that is not already implemented and I missed it!_",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1552/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1079111498,I_kwDOBm6k_c5AUe9K,1553,if csv export is truncated in non streaming mode set informative response header,536941,open,0,,,3,2021-12-13T22:50:44Z,2021-12-16T19:17:28Z,,CONTRIBUTOR,,"streaming mode is currently not enabled for custom queries, so the queries will be truncated to max row limit.
it would be great if a response is truncated that an header signalling that was set in the header.
i need to write some pagination code for getting full results back for a custom query and it would make the code much better if i could reliably known when there is nothing more to limit/offset ",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1553/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1082765654,I_kwDOBm6k_c5AibFW,1561,"add hash id to ""_memory"" url if hashed url mode is turned on and crossdb is also turned on",536941,closed,0,,,3,2021-12-17T00:45:12Z,2022-03-19T04:45:40Z,2022-03-19T04:45:40Z,CONTRIBUTOR,,"If hashed_url mode is turned on and crossdb is also turned on, then queries to _memory should have a hash_id.
One way that it could work is to have the _memory hash be a hash of all the individual databases.
Otherwise, crossdb queries can get quit out of data if using aggressive caching.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1561/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1105916061,I_kwDOBm6k_c5B6vCd,1601,Add KNN and data_licenses to hidden tables list,25778,closed,0,,,5,2022-01-17T14:19:57Z,2022-01-20T21:29:44Z,2022-01-20T04:38:54Z,CONTRIBUTOR,,"They're generated by Spatialite and not very interesting in most cases.
![]() ",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1601/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1090810196,I_kwDOBm6k_c5BBHFU,1583,consider adding deletion step of cloudbuild artifacts to gcloud publish,536941,open,0,,,1,2021-12-30T00:33:23Z,2021-12-30T00:34:16Z,,CONTRIBUTOR,,"right now, as part of the the publish process images and other artifacts are stored to gcloud's cloud storage before being deployed to cloudrun.
after successfully deploying, it would be nice if the the script deleted these artifacts. otherwise, if you have regularly scheduled build process, you can end up paying to store lots of out of date artifacts.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1583/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1096536240,I_kwDOBm6k_c5BW9Cw,1586,run analyze on all databases as part of start up or publishing,536941,open,0,,,1,2022-01-07T17:52:34Z,2022-02-02T07:13:37Z,,CONTRIBUTOR,,"Running `analyze;` lets sqlite's query planner make *much* better use of any indices.
It might be nice if the analyze was run as part of the start up of ""serve"" or ""publish"".",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1586/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1108671952,I_kwDOBm6k_c5CFP3Q,1605,Scripted exports,25778,open,0,,,10,2022-01-19T23:45:55Z,2022-11-30T15:06:38Z,,CONTRIBUTOR,,"Posting this while I'm thinking about it: I mentioned at the end of [this thread](https://twitter.com/eyeseast/status/1483893011658551299) that I'm usually doing `datasette --get` to export canned queries.
I used to use a tool called [datafreeze](https://github.com/pudo/datafreeze) to do scripted exports, but that project looks dead now. The ergonomics of it are pretty nice, though, and the `Freezefile.yml` structure is actually not too far from Datasette's canned queries.
This is related to the idea for `datasette query` (#1356) but I think it's a distinct feature. It's most likely a plugin, but I want to raise it here because it's probably something other people have thought about.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1605/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1114147905,I_kwDOBm6k_c5CaIxB,1612,Move canned queries closer to the SQL input area,639012,closed,0,,3268330,5,2022-01-25T17:06:39Z,2022-03-19T04:04:49Z,2022-01-25T18:34:21Z,CONTRIBUTOR,,"*Original title: Consider placing example queries above the sql input?*
Hi! Have been enjoying deploying ad hoc datasettes for collaborators to pick over!
I keep finding myself manually ""fixing"" the database.html template so that the ""example queries"" (canned queries) appear directly *over* the sql box? So they are sorta more a suggestion for collaborators who aren't inclined to write their own queries?
My sense is any time I go to the trouble of writing canned queries my users should see 'em?
(( I have also considered a client-side reactive-ish option where selecting a query just places the raw SQL in the box and doesn't execute it, but this seems to end up being an inconvenience, rather than a teaching tool. ))
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1612/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1163369515,I_kwDOBm6k_c5FV5wr,1655,query result page is using 400mb of browser memory 40x size of html page and 400x size of csv data,536941,open,0,,,8,2022-03-09T00:56:40Z,2023-10-17T21:53:17Z,,CONTRIBUTOR,,"[this page](https://labordata.bunkum.us/opdr-8335ea3?sql=with+most_recent_lu+as+%28%0D%0A++select%0D%0A++++*%0D%0A++from%0D%0A++++%28%0D%0A++++++select%0D%0A++++++++*%0D%0A++++++from%0D%0A++++++++lm_data%0D%0A++++++order+by%0D%0A++++++++f_num%2C%0D%0A++++++++receive_date+desc%0D%0A++++%29+t%0D%0A++group+by%0D%0A++++f_num%0D%0A%29%0D%0Aselect%0D%0A++aff_abbr+%7C%7C+coalesce%28%27+local+%27+%7C%7C+desig_num%2C+%27+%27+%7C%7C+unit_name%29+as+abbr_local_name%2C%0D%0A++coalesce%28%0D%0A++++regexp_match%28%27%28.*%3F%29%28%2C%3F+AFL-CIO%24%29%27%2C+union_name%29%2C%0D%0A++++regexp_match%28%27%28.*%3F%29%28+IND%24%29%27%2C+union_name%29%2C%0D%0A++++union_name%0D%0A++%29+%7C%7C+coalesce%28%27+local+%27+%7C%7C+desig_num%2C+%27+%27+%7C%7C+unit_name%29+as+full_local_name%2C%0D%0A++*%0D%0Afrom%0D%0A++most_recent_lu%0D%0Awhere+%28desig_num+IS+NOT+NULL+OR+unit_name+IS+NOT+NULL%29+AND+desig_name+%21%3D+%27HQ%27%0D%0Alimit%0D%0A++5000+offset+0)
is using about 400 mb in firefox 97 on mac os x. if you download the html for the page, it's about 11mb and if you get the csv for the data its about 1mb.
it's using over a 1G on chrome 99.
i found this because, i was trying to figure out why editing the SQL was getting very slow.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1655/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1181432624,I_kwDOBm6k_c5Gazsw,1688,[plugins][documentation] Is it possible to serve per-plugin static folders when writing one-off (single file) plugins?,9020979,closed,0,,,3,2022-03-26T01:17:44Z,2022-03-27T01:01:14Z,2022-03-26T21:34:47Z,CONTRIBUTOR,,"I'm trying to make a small plugin that depends on static assets, by following the guide [here](https://docs.datasette.io/en/stable/writing_plugins.html#writing-one-off-plugins). I made a `plugins/` directory with `datasette_nteract_data_explorer.py`.
I am trying to follow the example of `datasette_vega`, and serving static assets. I created a `statics/` directory within `plugins/` to serve my JS and CSS.
https://github.com/simonw/datasette-vega/blob/00de059ab1ef77394ba9f9547abfacf966c479c4/datasette_vega/__init__.py#L13
Unfortunately, datasette doesn't seem to be able to find my assets.
Input:
```bash
datasette ~/Library/Safari/History.db --plugins-dir=plugins/
```

Output:

I suspect this issue might go away if I move away from ""one-off"" plugin mode, but it's been a while since I created a new python package so I'm not sure how much work there is to go between ""one off"" and ""packaged for PyPI"". I'd like to try to avoid needing to repackage a new `tar.gz` file and or reinstall my library repeatedly when developing new python code.
1. Is there a way to serve a static assets when using the `plugins/` directory method instead of installing plugins as a new python package?
2. If not, is there a way I can work on developing a plugin without creating and repackaging tar.gz files after every change, or is that the recommended path?
Thanks for your help!
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1688/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1182227211,I_kwDOBm6k_c5Gd1sL,1692,[plugins][feature request]: Support additional script tag attributes when loading custom JS,9020979,open,0,,,2,2022-03-27T01:16:03Z,2022-03-30T06:14:51Z,,CONTRIBUTOR,,"## Motivation
- The build system for my new [plugin](https://github.com/hydrosquall/datasette-nteract-data-explorer) has two output JS files, one for browsers that support ES modules, one for browsers that don't. At present, I'm only passing one of them into Datasette.
- I'd like to specify the non-es-module script as a fallback for older browsers. I don't want to load it by default, because browsers will only need one, and it's heavy, so for now I'm only supporting modern browsers.
To be able to support legacy browsers without slowing down users with modern browsers, I would like to be able to set additional HTML attributes on the tag fallback script, `nomodule` and `defer`. My injected scripts should look something like this:
```html
```
## Proposal
To achieve this, I propose additional optional properties to the API accepted by the `extra_js_urls` hook and custom JS field the `metadata.json` [described here](https://docs.datasette.io/en/stable/custom_templates.html#custom-css-and-javascript).
Under this API, I'd write something like this to get the above HTML rendered in Datasette.
```json
{
""extra_js_urls"": [
{
""url"": ""/index.my-es-module-bundle.js"",
""module"": true,
},
{
""url"": ""/index.my-legacy-fallback-bundle.js"",
""nomodule"": """",
""defer"": true
}
]
}
```
## Resources
- [MDN on the script tag](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/script)
- There may be other properties that could be added that are potentially valuable, like `async` or `referrerpolicy`, but I don't have an immediate need for those.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1692/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1193090967,I_kwDOBm6k_c5HHR-X,1699,Proposal: datasette query,25778,open,0,,,6,2022-04-05T12:36:43Z,2022-04-11T01:32:12Z,,CONTRIBUTOR,,"I started sketching out a plugin to add a `datasette query` subcommand to export data from the command line. This is based on discussions in #1356 and #1605. Before I get too far down this rabbit hole, I figure it's worth getting some feedback here (unless this should happen in `Discussions`). Here's what I'm thinking:
At its most basic, it will write the results of a query to STDOUT.
```sh
datasette query -d data.db 'select * from data' > results.json
```
This isn't much improvement over using [sqlite-utils](https://github.com/simonw/sqlite-utils). To make better use of datasette and its ecosystem, run `datasette query` using a canned query defined in a `metadata.yml` file.
For example, using the metadata file from [alltheplaces-datasette](https://github.com/eyeseast/alltheplaces-datasette/blob/main/metadata.yml):
```sh
cd alltheplaces-datasette
datasette query -d alltheplaces.db -m metadata.yml count_by_spider
```
That query would be good to get as CSV, and we can auto-discover metadata and databases in the current directory:
```sh
cd alltheplaces-datasette
datasette query count_by_spider -f csv
```
In this case, `count_by_spider` is a canned query defined on the `alltheplaces` database. If the same query is defined on multiple databases or its otherwise unclear which database `query` should use, pass the `-d` or `--database` option.
If a query takes parameters, I can pass them in at runtime, using the `--param` or `-p` option:
```sh
datasette query -d data.db -p value something 'select * from neighborhoods where some_column = :value'
```
I'm very interested in feedback on this, including whether it should be a plugin or in Datasette core. (I don't have a strong opinion about this, but I'm prototyping it as a plugin to start.)",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1699/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1198822563,I_kwDOBm6k_c5HdJSj,1706,"[feature] immutable mode for a directory, not just individual sqlite file",9020979,open,0,,,4,2022-04-10T00:50:57Z,2022-12-09T19:11:40Z,,CONTRIBUTOR,,"## Motivation
- I have a directory of sqlite databases
- I'd like to use immutable mode when opening them for better performance [docs](https://docs.datasette.io/en/0.54/performance.html#immutable-mode)
- Currently using this flag throws the following error
IsADirectoryError: [Errno 21] Is a directory: '/name-of-directory'
## Proposal
Immutable flag works for both single files and directories
datasette -i /folder-of-sqlite-files",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1706/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1200224939,I_kwDOBm6k_c5Hifqr,1707,[feature] expanded detail page,536941,open,0,,,1,2022-04-11T16:29:17Z,2022-04-11T16:33:00Z,,CONTRIBUTOR,,"Right now, if click on the detail page for a row you get the info for the row and links to related tables:

It would be very cool if there was an option to expand the rows of the related tables from within this detail view.
If you had that then datasette could fulfill a pretty common use case where you want to search for an entity and get a consolidate detail view about what you know about that entity.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1707/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1218133366,I_kwDOBm6k_c5Imz12,1728,Writable canned queries fail with useless non-error against immutable databases,127565,closed,0,,8303187,13,2022-04-28T03:10:34Z,2022-08-14T16:34:40Z,2022-08-14T16:34:40Z,CONTRIBUTOR,,"I've been banging my head against a wall for a while and would appreciate any pointers...
- I have a writeable canned query to update rows in the db.
- I'm using the github-oauth plugin for authentication.
- I have `allow` set on the query to accept my GitHub id and a GH organisation.
- Authentication seems to work as expected both locally and on Cloudrun -- viewing `/-/actor` gives the same result in both environments
- I can access the 'padlocked' canned query in both environments.
Everything seems to be the same, but the canned query works perfectly when run locally, and fails when I try it on Cloudrun. I'm redirected back to the canned query page and the db is not changed. There's nothing in the Cloudstor logs to indicate an error.
Any clues as to where I should be looking for the problem?",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1728/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1292368833,I_kwDOBm6k_c5NB_vB,1764,Keep track of config_dir in directory mode (for plugins),25778,closed,0,,,0,2022-07-03T16:57:49Z,2022-07-18T01:12:45Z,2022-07-18T01:12:45Z,CONTRIBUTOR,,"I started working on using `config_dir` with my [datasette-query-files plugin](https://github.com/eyeseast/datasette-query-files) and realized Datasette doesn't actually hold onto the `config_dir` argument. It gets used in `__init__` but then forgotten. It would be nice to be able to use it in plugins, though.
Here's the reference issue: https://github.com/eyeseast/datasette-query-files/issues/4
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1764/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1339663518,I_kwDOBm6k_c5P2aSe,1784,"Include ""entrypoint"" option on `--load-extension`?",15178711,closed,0,,,2,2022-08-16T00:22:57Z,2022-08-23T18:34:31Z,2022-08-23T18:34:31Z,CONTRIBUTOR,,"## Problem
SQLite extensions have the option to define multiple ""entrypoints"" in each loadable extension. For example, the upcoming version of `sqlite-lines` will have 2 entrypoints: the default `sqlite3_lines_init` (which SQLite will automatically guess for) and `sqlite3_lines_noread_init`. The `sqlite3_lines_noread_init` version omits functions that read from the filesystem, which is necessary for security purposes when running untrusted SQL (which Datasette does).
(Similar multiple entrypoints will also be added for sqlite-http).
The `--load-extension` flag, however, doesn't give the option to specify a different entrypoint, so the default one is always used.
## Proposal
I want there to be a new command line option of the `--load-extension` flag to specify a custom entrypoint like so:
```
datasette my.db \
--load-extension ./lines0 sqlite3_lines0_noread_init
```
Then, under the hood, this line of code:
https://github.com/simonw/datasette/blob/7af67b54b7d9bca43e948510fc62f6db2b748fa8/datasette/app.py#L562
Would look something like this:
```python
conn.execute(""SELECT load_extension(?, ?)"", [extension, entrypoint])
```
One potential problem: For backward compatibility, I'm not sure if Click allows cli flags to have variable number of options (""arity""). So I guess it could also use a `:` delimiter like `--static`:
```
datasette my.db \
--load-extension ./lines0:sqlite3_lines0_noread_init
```
Or maybe even a new flag name?
```
datasette my.db \
--load-extension-entrypoint ./lines0 sqlite3_lines0_noread_init
```
Personally I prefer the `:` option... and maybe even `--load-extension` -> `--load`? Definitely out of scope for this issue tho
```
datasette my.db \
--load./lines0:sqlite3_lines0_noread_init
```",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1784/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1334628400,I_kwDOBm6k_c5PjNAw,1779,google cloudrun updated their limits on maxscale based on memory and cpu count,536941,closed,0,,8303187,13,2022-08-10T13:27:21Z,2022-08-14T19:42:59Z,2022-08-14T17:07:34Z,CONTRIBUTOR,,"if you don't set an explicit limit on container scaling, then [google defaults to 100](https://cloud.google.com/run/docs/configuring/max-instances#limits)
google recently updated the [limits on container scaling](https://cloud.google.com/run/docs/configuring/max-instances#limits), such that if you set up datasette to use more memory or cpu, then you need to set the maxScale argument much smaller than 100.
would be nice if `datasette publish` could do this math for you and set the right maxScale.
[Log of an failing publish run](https://github.com/labordata/warehouse/runs/7764725972?check_suite_focus=true#step:8:332).
```
ERROR: (gcloud.run.deploy) spec.template.spec.containers[0].resources.limits.cpu: Invalid value specified for cpu. For the specified value, maxScale may not exceed 15.
Consider running your workload in a region with greater capacity, decreasing your requested cpu-per-instance, or requesting an increase in quota for this region if you are seeing sustained usage near this limit, see https://cloud.google.com/run/quotas. Your project may gain access to further scaling by adding billing information to your account.
Traceback (most recent call last):
File ""/home/runner/.local/bin/datasette"", line 8, in
sys.exit(cli())
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 1128, in __call__
return self.main(*args, **kwargs)
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 1053, in main
rv = self.invoke(ctx)
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 1659, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 1659, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 1395, in invoke
return ctx.invoke(self.callback, **ctx.params)
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 754, in invoke
return __callback(*args, **kwargs)
File ""/home/runner/.local/lib/python3.8/site-packages/datasette/publish/cloudrun.py"", line 160, in cloudrun
check_call(
File ""/usr/lib/python3.8/subprocess.py"", line 364, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command 'gcloud run deploy --allow-unauthenticated --platform=managed --image gcr.io/labordata/datasette warehouse --memory 8Gi --cpu 2' returned non-zero exit status 1.
```",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1779/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1377811868,I_kwDOBm6k_c5SH72c,1813,missing next and next_url in JSON responses from an instance deployed on Fly ,883348,closed,0,,,1,2022-09-19T11:32:34Z,2022-09-19T11:34:45Z,2022-09-19T11:34:45Z,CONTRIBUTOR,,"👋 thank you for an incredibly useful project!
I have noticed that my deployed instance on Fly does not include the `next` and `next_url` keys even for a truncated response :
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1601/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1090810196,I_kwDOBm6k_c5BBHFU,1583,consider adding deletion step of cloudbuild artifacts to gcloud publish,536941,open,0,,,1,2021-12-30T00:33:23Z,2021-12-30T00:34:16Z,,CONTRIBUTOR,,"right now, as part of the the publish process images and other artifacts are stored to gcloud's cloud storage before being deployed to cloudrun.
after successfully deploying, it would be nice if the the script deleted these artifacts. otherwise, if you have regularly scheduled build process, you can end up paying to store lots of out of date artifacts.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1583/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1096536240,I_kwDOBm6k_c5BW9Cw,1586,run analyze on all databases as part of start up or publishing,536941,open,0,,,1,2022-01-07T17:52:34Z,2022-02-02T07:13:37Z,,CONTRIBUTOR,,"Running `analyze;` lets sqlite's query planner make *much* better use of any indices.
It might be nice if the analyze was run as part of the start up of ""serve"" or ""publish"".",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1586/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1108671952,I_kwDOBm6k_c5CFP3Q,1605,Scripted exports,25778,open,0,,,10,2022-01-19T23:45:55Z,2022-11-30T15:06:38Z,,CONTRIBUTOR,,"Posting this while I'm thinking about it: I mentioned at the end of [this thread](https://twitter.com/eyeseast/status/1483893011658551299) that I'm usually doing `datasette --get` to export canned queries.
I used to use a tool called [datafreeze](https://github.com/pudo/datafreeze) to do scripted exports, but that project looks dead now. The ergonomics of it are pretty nice, though, and the `Freezefile.yml` structure is actually not too far from Datasette's canned queries.
This is related to the idea for `datasette query` (#1356) but I think it's a distinct feature. It's most likely a plugin, but I want to raise it here because it's probably something other people have thought about.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1605/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1114147905,I_kwDOBm6k_c5CaIxB,1612,Move canned queries closer to the SQL input area,639012,closed,0,,3268330,5,2022-01-25T17:06:39Z,2022-03-19T04:04:49Z,2022-01-25T18:34:21Z,CONTRIBUTOR,,"*Original title: Consider placing example queries above the sql input?*
Hi! Have been enjoying deploying ad hoc datasettes for collaborators to pick over!
I keep finding myself manually ""fixing"" the database.html template so that the ""example queries"" (canned queries) appear directly *over* the sql box? So they are sorta more a suggestion for collaborators who aren't inclined to write their own queries?
My sense is any time I go to the trouble of writing canned queries my users should see 'em?
(( I have also considered a client-side reactive-ish option where selecting a query just places the raw SQL in the box and doesn't execute it, but this seems to end up being an inconvenience, rather than a teaching tool. ))
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1612/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1163369515,I_kwDOBm6k_c5FV5wr,1655,query result page is using 400mb of browser memory 40x size of html page and 400x size of csv data,536941,open,0,,,8,2022-03-09T00:56:40Z,2023-10-17T21:53:17Z,,CONTRIBUTOR,,"[this page](https://labordata.bunkum.us/opdr-8335ea3?sql=with+most_recent_lu+as+%28%0D%0A++select%0D%0A++++*%0D%0A++from%0D%0A++++%28%0D%0A++++++select%0D%0A++++++++*%0D%0A++++++from%0D%0A++++++++lm_data%0D%0A++++++order+by%0D%0A++++++++f_num%2C%0D%0A++++++++receive_date+desc%0D%0A++++%29+t%0D%0A++group+by%0D%0A++++f_num%0D%0A%29%0D%0Aselect%0D%0A++aff_abbr+%7C%7C+coalesce%28%27+local+%27+%7C%7C+desig_num%2C+%27+%27+%7C%7C+unit_name%29+as+abbr_local_name%2C%0D%0A++coalesce%28%0D%0A++++regexp_match%28%27%28.*%3F%29%28%2C%3F+AFL-CIO%24%29%27%2C+union_name%29%2C%0D%0A++++regexp_match%28%27%28.*%3F%29%28+IND%24%29%27%2C+union_name%29%2C%0D%0A++++union_name%0D%0A++%29+%7C%7C+coalesce%28%27+local+%27+%7C%7C+desig_num%2C+%27+%27+%7C%7C+unit_name%29+as+full_local_name%2C%0D%0A++*%0D%0Afrom%0D%0A++most_recent_lu%0D%0Awhere+%28desig_num+IS+NOT+NULL+OR+unit_name+IS+NOT+NULL%29+AND+desig_name+%21%3D+%27HQ%27%0D%0Alimit%0D%0A++5000+offset+0)
is using about 400 mb in firefox 97 on mac os x. if you download the html for the page, it's about 11mb and if you get the csv for the data its about 1mb.
it's using over a 1G on chrome 99.
i found this because, i was trying to figure out why editing the SQL was getting very slow.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1655/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1181432624,I_kwDOBm6k_c5Gazsw,1688,[plugins][documentation] Is it possible to serve per-plugin static folders when writing one-off (single file) plugins?,9020979,closed,0,,,3,2022-03-26T01:17:44Z,2022-03-27T01:01:14Z,2022-03-26T21:34:47Z,CONTRIBUTOR,,"I'm trying to make a small plugin that depends on static assets, by following the guide [here](https://docs.datasette.io/en/stable/writing_plugins.html#writing-one-off-plugins). I made a `plugins/` directory with `datasette_nteract_data_explorer.py`.
I am trying to follow the example of `datasette_vega`, and serving static assets. I created a `statics/` directory within `plugins/` to serve my JS and CSS.
https://github.com/simonw/datasette-vega/blob/00de059ab1ef77394ba9f9547abfacf966c479c4/datasette_vega/__init__.py#L13
Unfortunately, datasette doesn't seem to be able to find my assets.
Input:
```bash
datasette ~/Library/Safari/History.db --plugins-dir=plugins/
```

Output:

I suspect this issue might go away if I move away from ""one-off"" plugin mode, but it's been a while since I created a new python package so I'm not sure how much work there is to go between ""one off"" and ""packaged for PyPI"". I'd like to try to avoid needing to repackage a new `tar.gz` file and or reinstall my library repeatedly when developing new python code.
1. Is there a way to serve a static assets when using the `plugins/` directory method instead of installing plugins as a new python package?
2. If not, is there a way I can work on developing a plugin without creating and repackaging tar.gz files after every change, or is that the recommended path?
Thanks for your help!
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1688/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1182227211,I_kwDOBm6k_c5Gd1sL,1692,[plugins][feature request]: Support additional script tag attributes when loading custom JS,9020979,open,0,,,2,2022-03-27T01:16:03Z,2022-03-30T06:14:51Z,,CONTRIBUTOR,,"## Motivation
- The build system for my new [plugin](https://github.com/hydrosquall/datasette-nteract-data-explorer) has two output JS files, one for browsers that support ES modules, one for browsers that don't. At present, I'm only passing one of them into Datasette.
- I'd like to specify the non-es-module script as a fallback for older browsers. I don't want to load it by default, because browsers will only need one, and it's heavy, so for now I'm only supporting modern browsers.
To be able to support legacy browsers without slowing down users with modern browsers, I would like to be able to set additional HTML attributes on the tag fallback script, `nomodule` and `defer`. My injected scripts should look something like this:
```html
```
## Proposal
To achieve this, I propose additional optional properties to the API accepted by the `extra_js_urls` hook and custom JS field the `metadata.json` [described here](https://docs.datasette.io/en/stable/custom_templates.html#custom-css-and-javascript).
Under this API, I'd write something like this to get the above HTML rendered in Datasette.
```json
{
""extra_js_urls"": [
{
""url"": ""/index.my-es-module-bundle.js"",
""module"": true,
},
{
""url"": ""/index.my-legacy-fallback-bundle.js"",
""nomodule"": """",
""defer"": true
}
]
}
```
## Resources
- [MDN on the script tag](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/script)
- There may be other properties that could be added that are potentially valuable, like `async` or `referrerpolicy`, but I don't have an immediate need for those.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1692/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1193090967,I_kwDOBm6k_c5HHR-X,1699,Proposal: datasette query,25778,open,0,,,6,2022-04-05T12:36:43Z,2022-04-11T01:32:12Z,,CONTRIBUTOR,,"I started sketching out a plugin to add a `datasette query` subcommand to export data from the command line. This is based on discussions in #1356 and #1605. Before I get too far down this rabbit hole, I figure it's worth getting some feedback here (unless this should happen in `Discussions`). Here's what I'm thinking:
At its most basic, it will write the results of a query to STDOUT.
```sh
datasette query -d data.db 'select * from data' > results.json
```
This isn't much improvement over using [sqlite-utils](https://github.com/simonw/sqlite-utils). To make better use of datasette and its ecosystem, run `datasette query` using a canned query defined in a `metadata.yml` file.
For example, using the metadata file from [alltheplaces-datasette](https://github.com/eyeseast/alltheplaces-datasette/blob/main/metadata.yml):
```sh
cd alltheplaces-datasette
datasette query -d alltheplaces.db -m metadata.yml count_by_spider
```
That query would be good to get as CSV, and we can auto-discover metadata and databases in the current directory:
```sh
cd alltheplaces-datasette
datasette query count_by_spider -f csv
```
In this case, `count_by_spider` is a canned query defined on the `alltheplaces` database. If the same query is defined on multiple databases or its otherwise unclear which database `query` should use, pass the `-d` or `--database` option.
If a query takes parameters, I can pass them in at runtime, using the `--param` or `-p` option:
```sh
datasette query -d data.db -p value something 'select * from neighborhoods where some_column = :value'
```
I'm very interested in feedback on this, including whether it should be a plugin or in Datasette core. (I don't have a strong opinion about this, but I'm prototyping it as a plugin to start.)",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1699/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1198822563,I_kwDOBm6k_c5HdJSj,1706,"[feature] immutable mode for a directory, not just individual sqlite file",9020979,open,0,,,4,2022-04-10T00:50:57Z,2022-12-09T19:11:40Z,,CONTRIBUTOR,,"## Motivation
- I have a directory of sqlite databases
- I'd like to use immutable mode when opening them for better performance [docs](https://docs.datasette.io/en/0.54/performance.html#immutable-mode)
- Currently using this flag throws the following error
IsADirectoryError: [Errno 21] Is a directory: '/name-of-directory'
## Proposal
Immutable flag works for both single files and directories
datasette -i /folder-of-sqlite-files",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1706/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1200224939,I_kwDOBm6k_c5Hifqr,1707,[feature] expanded detail page,536941,open,0,,,1,2022-04-11T16:29:17Z,2022-04-11T16:33:00Z,,CONTRIBUTOR,,"Right now, if click on the detail page for a row you get the info for the row and links to related tables:

It would be very cool if there was an option to expand the rows of the related tables from within this detail view.
If you had that then datasette could fulfill a pretty common use case where you want to search for an entity and get a consolidate detail view about what you know about that entity.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1707/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1218133366,I_kwDOBm6k_c5Imz12,1728,Writable canned queries fail with useless non-error against immutable databases,127565,closed,0,,8303187,13,2022-04-28T03:10:34Z,2022-08-14T16:34:40Z,2022-08-14T16:34:40Z,CONTRIBUTOR,,"I've been banging my head against a wall for a while and would appreciate any pointers...
- I have a writeable canned query to update rows in the db.
- I'm using the github-oauth plugin for authentication.
- I have `allow` set on the query to accept my GitHub id and a GH organisation.
- Authentication seems to work as expected both locally and on Cloudrun -- viewing `/-/actor` gives the same result in both environments
- I can access the 'padlocked' canned query in both environments.
Everything seems to be the same, but the canned query works perfectly when run locally, and fails when I try it on Cloudrun. I'm redirected back to the canned query page and the db is not changed. There's nothing in the Cloudstor logs to indicate an error.
Any clues as to where I should be looking for the problem?",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1728/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1292368833,I_kwDOBm6k_c5NB_vB,1764,Keep track of config_dir in directory mode (for plugins),25778,closed,0,,,0,2022-07-03T16:57:49Z,2022-07-18T01:12:45Z,2022-07-18T01:12:45Z,CONTRIBUTOR,,"I started working on using `config_dir` with my [datasette-query-files plugin](https://github.com/eyeseast/datasette-query-files) and realized Datasette doesn't actually hold onto the `config_dir` argument. It gets used in `__init__` but then forgotten. It would be nice to be able to use it in plugins, though.
Here's the reference issue: https://github.com/eyeseast/datasette-query-files/issues/4
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1764/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1339663518,I_kwDOBm6k_c5P2aSe,1784,"Include ""entrypoint"" option on `--load-extension`?",15178711,closed,0,,,2,2022-08-16T00:22:57Z,2022-08-23T18:34:31Z,2022-08-23T18:34:31Z,CONTRIBUTOR,,"## Problem
SQLite extensions have the option to define multiple ""entrypoints"" in each loadable extension. For example, the upcoming version of `sqlite-lines` will have 2 entrypoints: the default `sqlite3_lines_init` (which SQLite will automatically guess for) and `sqlite3_lines_noread_init`. The `sqlite3_lines_noread_init` version omits functions that read from the filesystem, which is necessary for security purposes when running untrusted SQL (which Datasette does).
(Similar multiple entrypoints will also be added for sqlite-http).
The `--load-extension` flag, however, doesn't give the option to specify a different entrypoint, so the default one is always used.
## Proposal
I want there to be a new command line option of the `--load-extension` flag to specify a custom entrypoint like so:
```
datasette my.db \
--load-extension ./lines0 sqlite3_lines0_noread_init
```
Then, under the hood, this line of code:
https://github.com/simonw/datasette/blob/7af67b54b7d9bca43e948510fc62f6db2b748fa8/datasette/app.py#L562
Would look something like this:
```python
conn.execute(""SELECT load_extension(?, ?)"", [extension, entrypoint])
```
One potential problem: For backward compatibility, I'm not sure if Click allows cli flags to have variable number of options (""arity""). So I guess it could also use a `:` delimiter like `--static`:
```
datasette my.db \
--load-extension ./lines0:sqlite3_lines0_noread_init
```
Or maybe even a new flag name?
```
datasette my.db \
--load-extension-entrypoint ./lines0 sqlite3_lines0_noread_init
```
Personally I prefer the `:` option... and maybe even `--load-extension` -> `--load`? Definitely out of scope for this issue tho
```
datasette my.db \
--load./lines0:sqlite3_lines0_noread_init
```",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1784/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1334628400,I_kwDOBm6k_c5PjNAw,1779,google cloudrun updated their limits on maxscale based on memory and cpu count,536941,closed,0,,8303187,13,2022-08-10T13:27:21Z,2022-08-14T19:42:59Z,2022-08-14T17:07:34Z,CONTRIBUTOR,,"if you don't set an explicit limit on container scaling, then [google defaults to 100](https://cloud.google.com/run/docs/configuring/max-instances#limits)
google recently updated the [limits on container scaling](https://cloud.google.com/run/docs/configuring/max-instances#limits), such that if you set up datasette to use more memory or cpu, then you need to set the maxScale argument much smaller than 100.
would be nice if `datasette publish` could do this math for you and set the right maxScale.
[Log of an failing publish run](https://github.com/labordata/warehouse/runs/7764725972?check_suite_focus=true#step:8:332).
```
ERROR: (gcloud.run.deploy) spec.template.spec.containers[0].resources.limits.cpu: Invalid value specified for cpu. For the specified value, maxScale may not exceed 15.
Consider running your workload in a region with greater capacity, decreasing your requested cpu-per-instance, or requesting an increase in quota for this region if you are seeing sustained usage near this limit, see https://cloud.google.com/run/quotas. Your project may gain access to further scaling by adding billing information to your account.
Traceback (most recent call last):
File ""/home/runner/.local/bin/datasette"", line 8, in
sys.exit(cli())
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 1128, in __call__
return self.main(*args, **kwargs)
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 1053, in main
rv = self.invoke(ctx)
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 1659, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 1659, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 1395, in invoke
return ctx.invoke(self.callback, **ctx.params)
File ""/home/runner/.local/lib/python3.8/site-packages/click/core.py"", line 754, in invoke
return __callback(*args, **kwargs)
File ""/home/runner/.local/lib/python3.8/site-packages/datasette/publish/cloudrun.py"", line 160, in cloudrun
check_call(
File ""/usr/lib/python3.8/subprocess.py"", line 364, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command 'gcloud run deploy --allow-unauthenticated --platform=managed --image gcr.io/labordata/datasette warehouse --memory 8Gi --cpu 2' returned non-zero exit status 1.
```",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1779/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1377811868,I_kwDOBm6k_c5SH72c,1813,missing next and next_url in JSON responses from an instance deployed on Fly ,883348,closed,0,,,1,2022-09-19T11:32:34Z,2022-09-19T11:34:45Z,2022-09-19T11:34:45Z,CONTRIBUTOR,,"👋 thank you for an incredibly useful project!
I have noticed that my deployed instance on Fly does not include the `next` and `next_url` keys even for a truncated response :
![]() This is publically accessible here: `https://collectif-objets-datasette.fly.dev/collectif-objets.json?sql=select+*+from+mairies`
However when I run the dataset server locally with the same data I get these next keys for the exact same query:
This is publically accessible here: `https://collectif-objets-datasette.fly.dev/collectif-objets.json?sql=select+*+from+mairies`
However when I run the dataset server locally with the same data I get these next keys for the exact same query:
![]() I am wondering if I've missed some config or something specific to deployments on Fly.io?
I am running datasette v0.62, without any specific config :
- locally `poetry run datasette data/collectif-objets.sqlite`
- for the deploy : `poetry run datasette publish fly data/collectif-objets.sqlite`
as visible in [the Makefile](https://github.com/adipasquale/collectif-objets-datasette/blob/main/Makefile). _The very limited codebase is public but the sqlite db is not versioned yet because it is too large._",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1813/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1385026210,I_kwDOBm6k_c5SjdKi,1819,Preserve query on timeout,2182,closed,0,,,3,2022-09-25T13:32:31Z,2022-09-26T23:16:15Z,2022-09-26T23:06:06Z,CONTRIBUTOR,,"If a query hits the timeout it shows a message like:
> SQL query took too long. The time limit is controlled by the [sql_time_limit_ms](https://docs.datasette.io/en/stable/settings.html#sql-time-limit-ms) configuration option.
But the query is lost. Hitting the browser back button shows the query _before_ the one that errored.
It would be nice if the query that errored was preserved for more tweaking. This would make it similar to how ""invalid syntax"" works since #1346 / #619.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1819/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1400083043,I_kwDOBm6k_c5Tc5Jj,1834,inspect data is not used for caching database hash,536941,closed,0,,,0,2022-10-06T17:52:01Z,2022-10-06T20:06:21Z,2022-10-06T20:06:08Z,CONTRIBUTOR,,"When databases are loaded,
https://github.com/simonw/datasette/blob/cb1e093fd361b758120aefc1a444df02462389a3/datasette/app.py#L257-L260
there is nothing preventing the rehashing of the database for immutable databases.
https://github.com/simonw/datasette/blob/cb1e093fd361b758120aefc1a444df02462389a3/datasette/database.py#L50-L53
what i might expect is that relevant values of `inspect_data` get passed to the `Database` class to prevent re-hashing?
With data that is many gigs large, this is a significant start up time.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1834/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1400374908,I_kwDOBm6k_c5TeAZ8,1836,docker image is duplicating db files somehow,536941,open,0,,,13,2022-10-06T22:35:54Z,2022-10-08T16:56:51Z,,CONTRIBUTOR,,"if you look into the docker image created by docker publish, the `datasette inspect` line is duplicating the db files.
here's the result of the inspect command:
I am wondering if I've missed some config or something specific to deployments on Fly.io?
I am running datasette v0.62, without any specific config :
- locally `poetry run datasette data/collectif-objets.sqlite`
- for the deploy : `poetry run datasette publish fly data/collectif-objets.sqlite`
as visible in [the Makefile](https://github.com/adipasquale/collectif-objets-datasette/blob/main/Makefile). _The very limited codebase is public but the sqlite db is not versioned yet because it is too large._",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1813/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1385026210,I_kwDOBm6k_c5SjdKi,1819,Preserve query on timeout,2182,closed,0,,,3,2022-09-25T13:32:31Z,2022-09-26T23:16:15Z,2022-09-26T23:06:06Z,CONTRIBUTOR,,"If a query hits the timeout it shows a message like:
> SQL query took too long. The time limit is controlled by the [sql_time_limit_ms](https://docs.datasette.io/en/stable/settings.html#sql-time-limit-ms) configuration option.
But the query is lost. Hitting the browser back button shows the query _before_ the one that errored.
It would be nice if the query that errored was preserved for more tweaking. This would make it similar to how ""invalid syntax"" works since #1346 / #619.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1819/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1400083043,I_kwDOBm6k_c5Tc5Jj,1834,inspect data is not used for caching database hash,536941,closed,0,,,0,2022-10-06T17:52:01Z,2022-10-06T20:06:21Z,2022-10-06T20:06:08Z,CONTRIBUTOR,,"When databases are loaded,
https://github.com/simonw/datasette/blob/cb1e093fd361b758120aefc1a444df02462389a3/datasette/app.py#L257-L260
there is nothing preventing the rehashing of the database for immutable databases.
https://github.com/simonw/datasette/blob/cb1e093fd361b758120aefc1a444df02462389a3/datasette/database.py#L50-L53
what i might expect is that relevant values of `inspect_data` get passed to the `Database` class to prevent re-hashing?
With data that is many gigs large, this is a significant start up time.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1834/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1400374908,I_kwDOBm6k_c5TeAZ8,1836,docker image is duplicating db files somehow,536941,open,0,,,13,2022-10-06T22:35:54Z,2022-10-08T16:56:51Z,,CONTRIBUTOR,,"if you look into the docker image created by docker publish, the `datasette inspect` line is duplicating the db files.
here's the result of the inspect command:
![]() ",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1836/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1428560020,I_kwDOBm6k_c5VJhiU,1872,"SITE-BUSTING ERROR: ""render_template() called before await ds.invoke_startup()""",192568,closed,0,,,3,2022-10-30T02:28:39Z,2022-10-30T06:26:01Z,2022-10-30T06:26:01Z,CONTRIBUTOR,,"1. My https://list.saferdisinfectants.org/disinfectants/listN page (linked from https://SaferDisinfectants.org ) has been running beautifully for a year and a half, including a GitHub Actions workflow that's been routinely updating the database.
2. I received a recent report that the list page is down. I don't know when it went down, but the content is replaced with: ""render_template() called before await ds.invoke_startup()""
3. The local datasette repo runs without incident.
4. The site is hosted on vercel, linked to my github repo. Perhaps some vercel changes were made, but not by anyone on our side. Here is a screenshot of the current project settings:
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1836/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1428560020,I_kwDOBm6k_c5VJhiU,1872,"SITE-BUSTING ERROR: ""render_template() called before await ds.invoke_startup()""",192568,closed,0,,,3,2022-10-30T02:28:39Z,2022-10-30T06:26:01Z,2022-10-30T06:26:01Z,CONTRIBUTOR,,"1. My https://list.saferdisinfectants.org/disinfectants/listN page (linked from https://SaferDisinfectants.org ) has been running beautifully for a year and a half, including a GitHub Actions workflow that's been routinely updating the database.
2. I received a recent report that the list page is down. I don't know when it went down, but the content is replaced with: ""render_template() called before await ds.invoke_startup()""
3. The local datasette repo runs without incident.
4. The site is hosted on vercel, linked to my github repo. Perhaps some vercel changes were made, but not by anyone on our side. Here is a screenshot of the current project settings:
![]() Here a screenshot of the latest deployment status:
Here a screenshot of the latest deployment status:
![]() This is my repository:
https://github.com/mroswell/list-N
(I notice: datasette==0.59 in my requirements.txt file)
Because it's been long while since I actively worked on this or any other datasette project, I forget a lot of what I knew at one point. Perhaps some configuration file could be missing? Or perhaps I just need to know the right incantation to add to that vercel settings page.
Help is welcome as the nonprofit org is soon hosting its annual conference, and we'd love to have the page working again.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1872/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1439009231,I_kwDOBm6k_c5VxYnP,1884,Exclude virtual tables from datasette inspect,25778,open,0,,,6,2022-11-07T21:26:01Z,2022-11-21T04:40:56Z,,CONTRIBUTOR,,"Ran `inspect` on a spatialite database and got these warnings:
```
ERROR: conn=, sql = 'select count(*) from [SpatialIndex]', params = None: no such module: VirtualSpatialIndex
ERROR: conn=, sql = 'select count(*) from [ElementaryGeometries]', params = None: no such module: VirtualElementary
ERROR: conn=, sql = 'select count(*) from [KNN]', params = None: no such module: VirtualKNN
```
It still worked, but probably want to catch this.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1884/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1448143294,I_kwDOBm6k_c5WUOm-,1890,Autocomplete text entry for filter values that correspond to facets,536941,closed,0,,,16,2022-11-14T14:11:31Z,2022-11-17T00:47:36Z,2022-11-16T03:23:01Z,CONTRIBUTOR,,"datasette allows users to enter in the value for named parameters into a free-text form field.
I think it would add a lot of usability, if the form field could be a drop down of options when query value is already a faceted column.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1890/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1450796965,I_kwDOBm6k_c5WeWel,1894,Initialize CodeMirror during DOMContentLoaded instead of onload,95570,closed,0,,,0,2022-11-16T03:52:19Z,2022-11-18T07:29:02Z,2022-11-18T07:29:02Z,CONTRIBUTOR,,As per https://github.com/simonw/datasette/pull/1893/files#r1023248927 this should prevent a flash between the textarea being replaced by CodeMirror.,107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1894/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1452495049,I_kwDOBm6k_c5Wk1DJ,1899,Clicking within the CodeMirror area below the SQL (i.e. when there's only a single line) doesn't cause the editor to get focused ,95570,closed,0,,,4,2022-11-17T00:29:52Z,2022-11-18T07:28:28Z,2022-11-18T07:20:53Z,CONTRIBUTOR,,"After the upgrade to 6 (#1893) I noticed this. I think it's because we're doing overflow:hidden to accomplish the CSS resizer.
When there's a single line of SQL there's a gap below that line where clicking doesn't do anything. It should focus at the end of the line.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1899/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1453813400,I_kwDOBm6k_c5Wp26Y,1901,"Some plugins show ""home"" breadcrumbs twice in the top left",95570,closed,0,,,8,2022-11-17T18:44:58Z,2022-11-18T07:22:37Z,2022-11-18T07:02:56Z,CONTRIBUTOR,,"
This is my repository:
https://github.com/mroswell/list-N
(I notice: datasette==0.59 in my requirements.txt file)
Because it's been long while since I actively worked on this or any other datasette project, I forget a lot of what I knew at one point. Perhaps some configuration file could be missing? Or perhaps I just need to know the right incantation to add to that vercel settings page.
Help is welcome as the nonprofit org is soon hosting its annual conference, and we'd love to have the page working again.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1872/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1439009231,I_kwDOBm6k_c5VxYnP,1884,Exclude virtual tables from datasette inspect,25778,open,0,,,6,2022-11-07T21:26:01Z,2022-11-21T04:40:56Z,,CONTRIBUTOR,,"Ran `inspect` on a spatialite database and got these warnings:
```
ERROR: conn=, sql = 'select count(*) from [SpatialIndex]', params = None: no such module: VirtualSpatialIndex
ERROR: conn=, sql = 'select count(*) from [ElementaryGeometries]', params = None: no such module: VirtualElementary
ERROR: conn=, sql = 'select count(*) from [KNN]', params = None: no such module: VirtualKNN
```
It still worked, but probably want to catch this.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1884/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1448143294,I_kwDOBm6k_c5WUOm-,1890,Autocomplete text entry for filter values that correspond to facets,536941,closed,0,,,16,2022-11-14T14:11:31Z,2022-11-17T00:47:36Z,2022-11-16T03:23:01Z,CONTRIBUTOR,,"datasette allows users to enter in the value for named parameters into a free-text form field.
I think it would add a lot of usability, if the form field could be a drop down of options when query value is already a faceted column.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1890/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1450796965,I_kwDOBm6k_c5WeWel,1894,Initialize CodeMirror during DOMContentLoaded instead of onload,95570,closed,0,,,0,2022-11-16T03:52:19Z,2022-11-18T07:29:02Z,2022-11-18T07:29:02Z,CONTRIBUTOR,,As per https://github.com/simonw/datasette/pull/1893/files#r1023248927 this should prevent a flash between the textarea being replaced by CodeMirror.,107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1894/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1452495049,I_kwDOBm6k_c5Wk1DJ,1899,Clicking within the CodeMirror area below the SQL (i.e. when there's only a single line) doesn't cause the editor to get focused ,95570,closed,0,,,4,2022-11-17T00:29:52Z,2022-11-18T07:28:28Z,2022-11-18T07:20:53Z,CONTRIBUTOR,,"After the upgrade to 6 (#1893) I noticed this. I think it's because we're doing overflow:hidden to accomplish the CSS resizer.
When there's a single line of SQL there's a gap below that line where clicking doesn't do anything. It should focus at the end of the line.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1899/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1453813400,I_kwDOBm6k_c5Wp26Y,1901,"Some plugins show ""home"" breadcrumbs twice in the top left",95570,closed,0,,,8,2022-11-17T18:44:58Z,2022-11-18T07:22:37Z,2022-11-18T07:02:56Z,CONTRIBUTOR,,"![]() ",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1901/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1473659191,I_kwDOBm6k_c5X1kE3,1929,Incorrect link from the API explorer to the JSON API documentation,3556,closed,0,,,4,2022-12-03T02:08:58Z,2022-12-06T19:36:23Z,2022-12-06T19:34:20Z,CONTRIBUTOR,,"I installed `datasette==1.0a1`.
When I go to http://127.0.0.1:8001/-/api I have a link: `Use this tool to try out the [Datasette API](https://docs.datasette.io/en/1.0a1/json_api.html).` but that documentation page does not exist.
I'm not sure where it has to be fixed, should it link to the stable page https://docs.datasette.io/en/stable/json_api.html , the latest one https://docs.datasette.io/en/latest/json_api.html#the-json-write-api or would it be more appropriated to deploy documentation for the `1.0a1` version?",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1929/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1469796454,I_kwDOBm6k_c5Xm1Bm,1920,Document Datasette.metadata() method,25778,open,0,,,0,2022-11-30T15:10:36Z,2022-11-30T15:10:36Z,,CONTRIBUTOR,,"Code is here: https://github.com/simonw/datasette/blob/main/datasette/app.py#L503
This will be the official way to access metadata from plugins.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1920/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1469821027,I_kwDOBm6k_c5Xm7Bj,1921,Document methods to get canned queries,25778,open,0,,,0,2022-11-30T15:26:33Z,2022-11-30T23:34:21Z,,CONTRIBUTOR,,"Two methods will get canned queries for a Datasette instance:
[`Datasette.get_canned_queries`](https://github.com/simonw/datasette/blob/main/datasette/app.py#L575) will return all canned queries for a database that an `actor` can see.
[`Datasette.get_canned_query`](https://github.com/simonw/datasette/blob/main/datasette/app.py#L592) will return a single canned query by name.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1921/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1509783085,I_kwDOBm6k_c5Z_XYt,1969,sql-formatter javascript is not now working with CloudFlare rocketloader,536941,open,0,,,0,2022-12-23T21:14:06Z,2023-01-10T01:56:33Z,,CONTRIBUTOR,,"This is probably not a bug with datasette, but I thought you might want to know, @simonw.
I noticed today that my CloudFlare proxied datasette instance lost the ""Format SQL"" option. I'm pretty sure it was there last week.
In the CloudFlare settings, if I turn off [Rocket Loader](https://developers.cloudflare.com/fundamentals/speed/rocket-loader/), I get the ""Format SQL"" option back.
Rocket Loader works by asynchronously loading the javascript, so maybe there was a recent change that doesn't play well with the asynch loading?
I'm up to date with https://github.com/simonw/datasette/commit/e03aed00026cc2e59c09ca41f69a247e1a85cc89",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1969/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1515815014,I_kwDOBm6k_c5aWYBm,1973,render_cell plugin hook's row object is not a sqlite.Row,193185,open,0,,,4,2023-01-01T20:27:46Z,2023-01-29T00:40:31Z,,CONTRIBUTOR,,"From https://docs.datasette.io/en/stable/plugin_hooks.html#render-cell-row-value-column-table-database-datasette:
> row - sqlite.Row
> The SQLite row object that the value being rendered is part of
This appears to actually be a [CustomRow](https://github.com/simonw/datasette/blob/f0fadc28ddb9f82e5cc1ecaa51e8a342eb6dc528/datasette/utils/__init__.py#L773-L789), but I think that's unrelated to my issue.
I have a table:
```sql
CREATE TABLE IF NOT EXISTS ""dss_job_stats""(
job_id integer not null references dss_job(id) on delete cascade,
host text not null,
// other columns elided as irrelevant
primary key (job_id, host)
);
```
On datasette 0.63.2, the `render_cell` hook receives a `row` value that looks like:
```
CustomRow([('job_id', {'value': 2, 'label': '2'}), ('host', 'cldellow.com')])
```
I expected the `job_id` value to be `2`, but it's actually `{'value': 2, 'label': '2'}`.
I can work around this, but was wondering if this was intended behaviour?",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1973/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1522778923,I_kwDOBm6k_c5aw8Mr,1978,Document datasette.urls.row and row_blob,25778,closed,0,,,2,2023-01-06T15:45:51Z,2023-01-09T14:30:00Z,2023-01-09T14:30:00Z,CONTRIBUTOR,,"These are in the codebase but not in documentation. I think everything else in this class is documented.
```python
class Urls:
...
def row(self, database, table, row_path, format=None):
path = f""{self.table(database, table)}/{row_path}""
if format is not None:
path = path_with_format(path=path, format=format)
return PrefixedUrlString(path)
def row_blob(self, database, table, row_path, column):
return self.table(database, table) + ""/{}.blob?_blob_column={}"".format(
row_path, urllib.parse.quote_plus(column)
)
```
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1978/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,not_planned
1552368054,I_kwDOBm6k_c5ch0G2,2000,rewrite_sql hook,193185,open,0,,,1,2023-01-23T01:02:52Z,2023-01-23T06:08:01Z,,CONTRIBUTOR,,"I'm not sold that this is a good idea, but thought it'd be worth writing up a ticket. Proposal: add a hook like
```python
def rewrite_sql(datasette, database, request, fn, sql, params)
```
It would be called from Database.execute, Database.execute_write, Database.execute_write_script, Database.execute_write_many before running the user's SQL. `fn` would indicate which method was being used, in case that's relevant for the SQL inspection -- for example `execute` only permits a single statement.
The hook could return a SQL statement to be executed instead, or an async function to be awaited on that returned the SQL to be executed.
Plugins that could be written with this hook:
- https://github.com/cldellow/datasette-ersatz-table-valued-functions would use this to avoid monkey-patching
- a plugin to inspect and reject unsafe Spatialite function calls (reported by [Simon in Discord](https://discord.com/channels/823971286308356157/823971286941302908/1066438832293159004))
- a plugin to do more general rewrites of queries to enforce table or row-level security, for example, based on the currently logged in actor's ID
- a plugin to maintain audit tables when users write to a table
- a plugin to cache expensive queries (eg the queries that drive facets) - these could allow stale reads if previously cached, then refresh them in an offline queue
Flaws with this idea:
`execute_fn` and `execute_write_fn` would not go through this hook, which limits the guarantees you can make about it for security purposes.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2000/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1565179870,I_kwDOBm6k_c5dSr_e,2013,Datasette uses non-standard quoting for identifiers,193185,open,0,,,0,2023-02-01T00:05:39Z,2023-02-01T00:06:30Z,,CONTRIBUTOR,,"Related to #2001, but where #2001 was about literals, this is about identifiers
From https://www.sqlite.org/lang_keywords.html:
> ""keyword"" A keyword in double-quotes is an identifier.
> [keyword] A keyword enclosed in square brackets is an identifier. This is not standard SQL. This quoting mechanism is used by MS Access and SQL Server and is included in SQLite for compatibility.
Datasette uses this quoting here -- https://github.com/simonw/datasette/blob/0b4a28691468b5c758df74fa1d72a823813c96bf/datasette/utils/__init__.py#L345-L349, in some of the other DB access code, and in some of the test fixtures.
Migrating to standard double quote identifiers would make it easier to get Datasette working with alternative backends",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2013/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1571711808,I_kwDOBm6k_c5drmtA,2018,`check_visibility` gives confusing (wrong?) results if permission is `None`,193185,open,0,,,0,2023-02-06T01:03:08Z,2023-02-06T01:03:46Z,,CONTRIBUTOR,,"I'm trying to gate access to an edit UI on the user having `update-row` on the underlying view or table.
I expected [datasette.check_visibility](https://docs.datasette.io/en/latest/internals.html#await-check-visibility-actor-action-none-resource-none-permissions-none) to be a good way to do this:
```python
visible, private = await datasette.check_visibility(
request.actor,
permissions=[
(""update-row"", (database, table)),
],
)
if not visible:
return None
```
But `visible` is returning true, even when there is no explicit `update-row` permission. (In this case, `request.actor` is `None`.)
Based on [the update-row permissions docs](https://docs.datasette.io/en/latest/authentication.html#update-row), I expected this to be default deny, and so no explicit permission would result in false.
I think the root cause is that `check_visibility` calls `ensure_permissions` and expects it to throw if the permission is not available.
But `ensure_permissions` does not throw when `permission_allowed` returns None: https://github.com/simonw/datasette/blob/1.0a2/datasette/app.py#L825-L829",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2018/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1605959201,I_kwDOBm6k_c5fuP4h,2032,datasette errors when foreign key integrity is enabled,193185,open,0,,,0,2023-03-02T01:27:51Z,2023-03-02T01:31:58Z,,CONTRIBUTOR,,"By default, [SQLite does not enforce foreign key constraints](https://www.sqlite.org/foreignkeys.html#fk_enable). I typically enable these checks by running:
```sql
PRAGMA foreign_keys = ON;
```
inside of a `prepare_connection` hook.
If a plugin causes the schema to change (eg datasette-scraper creating a new table, or datasette-edit-schema changing a column), then https://github.com/simonw/datasette/blob/0b4a28691468b5c758df74fa1d72a823813c96bf/datasette/utils/internal_db.py#L71-L77 will fail with:
```
FOREIGN KEY constraint failed
```
This could be resolved by either:
- deleting from the `tables` column last
- changing the schema so that the foreign keys have [ON DELETE CASCADE](https://www.sqlite.org/foreignkeys.html#fk_actions)
Let me know if you'd be open to a PR that addresses this -- since foreign key constraints aren't enabled by default, I guess it's questionable whether this is a bug. I think I can workaround this by inspecting the database parameter in `prepare_connection` and trying not to enable fkey checks on the `_internal` database.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2032/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1620515757,I_kwDOBm6k_c5glxut,2039,Subtle bug with `--load-extension` and `--static` flags with absolute Windows paths with`C:\`,15178711,open,0,,,0,2023-03-12T21:18:52Z,2023-03-12T21:18:52Z,,CONTRIBUTOR,,"From the Datasette discord: A user tried running the following command on windows:
```
datasette --load-extension=""C:\spatialite\mod_spatialite-5.0.1-win-x86\mod_spatialite.dll""
```
This failed with `""The specified module could not be found""`, because the entrypoint option introduced in #1789 splits the input differently. Instead of loading the extension found at `""C:\spatialite\mod_spatialite-5.0.1-win-x86\mod_spatialite.dll""`, it instead tried to load the extension at `""C""` with entrypoint `""\spatialite\mod_spatialite-5.0.1-win-x86\mod_spatialite.dll"".
This is hard because most absolute windows paths have a colon in them, like `C:\foo.txt` or `D:\bar.txt`. I'd image the `--static` flag is also vulnerable to this type of bug.
The ""solution"" is to use a relative path instead, but that doesn't feel that great. ",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2039/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1781530343,I_kwDOBm6k_c5qL_7n,2093,"Proposal: Combine settings, metadata, static, etc. into a single `datasette.yaml` File",15178711,open,0,,,8,2023-06-29T21:18:23Z,2023-09-11T20:19:32Z,,CONTRIBUTOR,,"Very often I get tripped up when trying to configure my Datasette instances. For example: if I want to change the port my app listen too, do I do that with a CLI flag, a `--setting` flag, inside `metadata.json`, or an env var? If I want to up the time limit of SQL statements, is that under `metadata.json` or a setting? Where does my plugin configuration go?
Normally I need to look it up in Datasette docs, and I quickly find my answer, but the number of places where ""config"" goes it overwhelming.
- Flat CLI flags like `--port`, `--host`, `--cors`, etc.
- `--setting`, like `default_page_size`, `sql_time_limit_ms` etc
- Inside `metadata.json`, including plugin configuration
Typically my Datasette deploys are extremely long shell commands, with multiple `--setting` and other CLI flags.
## Proposal: Consolidate all ""config"" into `datasette.toml`
I propose that we add a new `datasette.toml` that combines ""settings"", ""metadata"", and other common CLI flags like `--port` and `--cors` into a single file. It would be similar to ""Cargo.toml"" in Rust projects, ""package.json"" in Node projects, and ""pyproject.toml"" in Python, etc.
A sample of what it could look like:
```toml
# ""top level"" configuration that are currently CLI flags on `datasette serve`
[config]
port = 8020
host = ""0.0.0.0""
cors = true
# replaces multiple `--setting` flags
[settings]
base_url = ""/app/datasette/""
default_allow_sql = true
sql_time_limit_ms = 3500
# replaces `metadata.json`.
# The contents of datasette-metadata.json could be defined in this file instead, but supporting separate files is nice (since those are easy to machine-generate)
[metadata]
include=""./datasette-metadata.json""
# plugin-specific
[plugins]
[plugins.datasette-auth-github]
client_id = {env = ""DATASETTE_AUTH_GITHUB_CLIENT_ID""}
client_secret = {env = ""GITHUB_CLIENT_SECRET""}
[plugins.datasette-cluster-map]
latitude_column = ""lat""
longitude_column = ""lon""
```
## Pros
- Instead of multiple files and CLI flags, everything could be in one tidy file
- Editing config in a separate file is easier than editing CLI flags, since you don't have to kill a process + edit a command every time
- New users will know ""just edit my `datasette.toml` instead of needing to learn metadata + settings + CLI flags
- Better dev experience for multiple environment. For example, could have `datasette -c datasette-dev.toml` for local dev environments (enables SQL, debug plugins, long timeouts, etc.), and a `datasette -c datasette-prod.toml` for ""production"" (lower timeouts, less plugins, monitoring plugins, etc.)
## Cons
- Yet another config-management system. Now Datasette users will need to know about metadata, settings, CLI flags, _and_ `datasette.toml`. However with enough documentation + announcements + examples, I think we can get ahead of it.
- If toml is chosen, would need to add a toml parser for Python version <3.11
- Multiple sources of config require priority. For example: Would `--setting default_allow_sql off` override the value inside `[settings]`? What about `--port`?
## Other Notes
### Toml
I chose toml over json because toml supports comments. I chose toml over yaml because Python 3.11 has builtin support for it. I also find toml easier to work with since it doesn't have the odd ""gotchas"" that YAML has (""ex `3.10` resolving to `3.1`, Norway `NO` resolving to `false`, etc.). It also mimics `pyproject.toml` which is nice. Happy to change my mind about this however
### Plugin config will be difficult
Plugin config is currently in `metadata.json` in two places:
1. Top level, under `""plugins.[plugin-name]""`. This fits well into `datasette.toml` as `[plugins.plugin-name]`
2. Table level, under `""databases.[db-name].tables.[table-name].plugins.[plugin-name]`. This doesn't fit that well into `datasette.toml`, unless it's nested under `[metadata]`?
### Extensions, static, one-off plugins?
We could also include equivalents of `--plugins-dir`, `--static`, and `--load-extension` into `datasette.toml`, but I'd imagine there's a few security concerns there to think through.
### Explicitly list with plugins to use?
I believe Datasette by default will load all install plugins on startup, but maybe `datasette.toml` can specify a list of plugins to use? For example, a dev version of `datasette.toml` can specify `datasette-pretty-traces`, but the prod version can leave it out",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2093/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1783304750,I_kwDOBm6k_c5qSxIu,2094,JS Plugin Hooks for the Code Editor,15178711,open,0,,,0,2023-07-01T00:51:57Z,2023-07-01T00:51:57Z,,CONTRIBUTOR,,"When #2052 merges, I'd like to add support to add extensions/functions to the Datasette code editor.
I'd eventually like to build a JS plugin for [`sqlite-docs`](https://github.com/asg017/sqlite-docs), to add things like:
- Inline documentation for tables/columns on hover
- Inline docs for custom functions that are loaded in
- More detailed autocomplete for tables/columns/functions
I did some hacking to see what this would look like, see here:
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1901/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1473659191,I_kwDOBm6k_c5X1kE3,1929,Incorrect link from the API explorer to the JSON API documentation,3556,closed,0,,,4,2022-12-03T02:08:58Z,2022-12-06T19:36:23Z,2022-12-06T19:34:20Z,CONTRIBUTOR,,"I installed `datasette==1.0a1`.
When I go to http://127.0.0.1:8001/-/api I have a link: `Use this tool to try out the [Datasette API](https://docs.datasette.io/en/1.0a1/json_api.html).` but that documentation page does not exist.
I'm not sure where it has to be fixed, should it link to the stable page https://docs.datasette.io/en/stable/json_api.html , the latest one https://docs.datasette.io/en/latest/json_api.html#the-json-write-api or would it be more appropriated to deploy documentation for the `1.0a1` version?",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1929/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1469796454,I_kwDOBm6k_c5Xm1Bm,1920,Document Datasette.metadata() method,25778,open,0,,,0,2022-11-30T15:10:36Z,2022-11-30T15:10:36Z,,CONTRIBUTOR,,"Code is here: https://github.com/simonw/datasette/blob/main/datasette/app.py#L503
This will be the official way to access metadata from plugins.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1920/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1469821027,I_kwDOBm6k_c5Xm7Bj,1921,Document methods to get canned queries,25778,open,0,,,0,2022-11-30T15:26:33Z,2022-11-30T23:34:21Z,,CONTRIBUTOR,,"Two methods will get canned queries for a Datasette instance:
[`Datasette.get_canned_queries`](https://github.com/simonw/datasette/blob/main/datasette/app.py#L575) will return all canned queries for a database that an `actor` can see.
[`Datasette.get_canned_query`](https://github.com/simonw/datasette/blob/main/datasette/app.py#L592) will return a single canned query by name.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1921/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1509783085,I_kwDOBm6k_c5Z_XYt,1969,sql-formatter javascript is not now working with CloudFlare rocketloader,536941,open,0,,,0,2022-12-23T21:14:06Z,2023-01-10T01:56:33Z,,CONTRIBUTOR,,"This is probably not a bug with datasette, but I thought you might want to know, @simonw.
I noticed today that my CloudFlare proxied datasette instance lost the ""Format SQL"" option. I'm pretty sure it was there last week.
In the CloudFlare settings, if I turn off [Rocket Loader](https://developers.cloudflare.com/fundamentals/speed/rocket-loader/), I get the ""Format SQL"" option back.
Rocket Loader works by asynchronously loading the javascript, so maybe there was a recent change that doesn't play well with the asynch loading?
I'm up to date with https://github.com/simonw/datasette/commit/e03aed00026cc2e59c09ca41f69a247e1a85cc89",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1969/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1515815014,I_kwDOBm6k_c5aWYBm,1973,render_cell plugin hook's row object is not a sqlite.Row,193185,open,0,,,4,2023-01-01T20:27:46Z,2023-01-29T00:40:31Z,,CONTRIBUTOR,,"From https://docs.datasette.io/en/stable/plugin_hooks.html#render-cell-row-value-column-table-database-datasette:
> row - sqlite.Row
> The SQLite row object that the value being rendered is part of
This appears to actually be a [CustomRow](https://github.com/simonw/datasette/blob/f0fadc28ddb9f82e5cc1ecaa51e8a342eb6dc528/datasette/utils/__init__.py#L773-L789), but I think that's unrelated to my issue.
I have a table:
```sql
CREATE TABLE IF NOT EXISTS ""dss_job_stats""(
job_id integer not null references dss_job(id) on delete cascade,
host text not null,
// other columns elided as irrelevant
primary key (job_id, host)
);
```
On datasette 0.63.2, the `render_cell` hook receives a `row` value that looks like:
```
CustomRow([('job_id', {'value': 2, 'label': '2'}), ('host', 'cldellow.com')])
```
I expected the `job_id` value to be `2`, but it's actually `{'value': 2, 'label': '2'}`.
I can work around this, but was wondering if this was intended behaviour?",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1973/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1522778923,I_kwDOBm6k_c5aw8Mr,1978,Document datasette.urls.row and row_blob,25778,closed,0,,,2,2023-01-06T15:45:51Z,2023-01-09T14:30:00Z,2023-01-09T14:30:00Z,CONTRIBUTOR,,"These are in the codebase but not in documentation. I think everything else in this class is documented.
```python
class Urls:
...
def row(self, database, table, row_path, format=None):
path = f""{self.table(database, table)}/{row_path}""
if format is not None:
path = path_with_format(path=path, format=format)
return PrefixedUrlString(path)
def row_blob(self, database, table, row_path, column):
return self.table(database, table) + ""/{}.blob?_blob_column={}"".format(
row_path, urllib.parse.quote_plus(column)
)
```
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/1978/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,not_planned
1552368054,I_kwDOBm6k_c5ch0G2,2000,rewrite_sql hook,193185,open,0,,,1,2023-01-23T01:02:52Z,2023-01-23T06:08:01Z,,CONTRIBUTOR,,"I'm not sold that this is a good idea, but thought it'd be worth writing up a ticket. Proposal: add a hook like
```python
def rewrite_sql(datasette, database, request, fn, sql, params)
```
It would be called from Database.execute, Database.execute_write, Database.execute_write_script, Database.execute_write_many before running the user's SQL. `fn` would indicate which method was being used, in case that's relevant for the SQL inspection -- for example `execute` only permits a single statement.
The hook could return a SQL statement to be executed instead, or an async function to be awaited on that returned the SQL to be executed.
Plugins that could be written with this hook:
- https://github.com/cldellow/datasette-ersatz-table-valued-functions would use this to avoid monkey-patching
- a plugin to inspect and reject unsafe Spatialite function calls (reported by [Simon in Discord](https://discord.com/channels/823971286308356157/823971286941302908/1066438832293159004))
- a plugin to do more general rewrites of queries to enforce table or row-level security, for example, based on the currently logged in actor's ID
- a plugin to maintain audit tables when users write to a table
- a plugin to cache expensive queries (eg the queries that drive facets) - these could allow stale reads if previously cached, then refresh them in an offline queue
Flaws with this idea:
`execute_fn` and `execute_write_fn` would not go through this hook, which limits the guarantees you can make about it for security purposes.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2000/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1565179870,I_kwDOBm6k_c5dSr_e,2013,Datasette uses non-standard quoting for identifiers,193185,open,0,,,0,2023-02-01T00:05:39Z,2023-02-01T00:06:30Z,,CONTRIBUTOR,,"Related to #2001, but where #2001 was about literals, this is about identifiers
From https://www.sqlite.org/lang_keywords.html:
> ""keyword"" A keyword in double-quotes is an identifier.
> [keyword] A keyword enclosed in square brackets is an identifier. This is not standard SQL. This quoting mechanism is used by MS Access and SQL Server and is included in SQLite for compatibility.
Datasette uses this quoting here -- https://github.com/simonw/datasette/blob/0b4a28691468b5c758df74fa1d72a823813c96bf/datasette/utils/__init__.py#L345-L349, in some of the other DB access code, and in some of the test fixtures.
Migrating to standard double quote identifiers would make it easier to get Datasette working with alternative backends",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2013/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1571711808,I_kwDOBm6k_c5drmtA,2018,`check_visibility` gives confusing (wrong?) results if permission is `None`,193185,open,0,,,0,2023-02-06T01:03:08Z,2023-02-06T01:03:46Z,,CONTRIBUTOR,,"I'm trying to gate access to an edit UI on the user having `update-row` on the underlying view or table.
I expected [datasette.check_visibility](https://docs.datasette.io/en/latest/internals.html#await-check-visibility-actor-action-none-resource-none-permissions-none) to be a good way to do this:
```python
visible, private = await datasette.check_visibility(
request.actor,
permissions=[
(""update-row"", (database, table)),
],
)
if not visible:
return None
```
But `visible` is returning true, even when there is no explicit `update-row` permission. (In this case, `request.actor` is `None`.)
Based on [the update-row permissions docs](https://docs.datasette.io/en/latest/authentication.html#update-row), I expected this to be default deny, and so no explicit permission would result in false.
I think the root cause is that `check_visibility` calls `ensure_permissions` and expects it to throw if the permission is not available.
But `ensure_permissions` does not throw when `permission_allowed` returns None: https://github.com/simonw/datasette/blob/1.0a2/datasette/app.py#L825-L829",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2018/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1605959201,I_kwDOBm6k_c5fuP4h,2032,datasette errors when foreign key integrity is enabled,193185,open,0,,,0,2023-03-02T01:27:51Z,2023-03-02T01:31:58Z,,CONTRIBUTOR,,"By default, [SQLite does not enforce foreign key constraints](https://www.sqlite.org/foreignkeys.html#fk_enable). I typically enable these checks by running:
```sql
PRAGMA foreign_keys = ON;
```
inside of a `prepare_connection` hook.
If a plugin causes the schema to change (eg datasette-scraper creating a new table, or datasette-edit-schema changing a column), then https://github.com/simonw/datasette/blob/0b4a28691468b5c758df74fa1d72a823813c96bf/datasette/utils/internal_db.py#L71-L77 will fail with:
```
FOREIGN KEY constraint failed
```
This could be resolved by either:
- deleting from the `tables` column last
- changing the schema so that the foreign keys have [ON DELETE CASCADE](https://www.sqlite.org/foreignkeys.html#fk_actions)
Let me know if you'd be open to a PR that addresses this -- since foreign key constraints aren't enabled by default, I guess it's questionable whether this is a bug. I think I can workaround this by inspecting the database parameter in `prepare_connection` and trying not to enable fkey checks on the `_internal` database.",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2032/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1620515757,I_kwDOBm6k_c5glxut,2039,Subtle bug with `--load-extension` and `--static` flags with absolute Windows paths with`C:\`,15178711,open,0,,,0,2023-03-12T21:18:52Z,2023-03-12T21:18:52Z,,CONTRIBUTOR,,"From the Datasette discord: A user tried running the following command on windows:
```
datasette --load-extension=""C:\spatialite\mod_spatialite-5.0.1-win-x86\mod_spatialite.dll""
```
This failed with `""The specified module could not be found""`, because the entrypoint option introduced in #1789 splits the input differently. Instead of loading the extension found at `""C:\spatialite\mod_spatialite-5.0.1-win-x86\mod_spatialite.dll""`, it instead tried to load the extension at `""C""` with entrypoint `""\spatialite\mod_spatialite-5.0.1-win-x86\mod_spatialite.dll"".
This is hard because most absolute windows paths have a colon in them, like `C:\foo.txt` or `D:\bar.txt`. I'd image the `--static` flag is also vulnerable to this type of bug.
The ""solution"" is to use a relative path instead, but that doesn't feel that great. ",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2039/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1781530343,I_kwDOBm6k_c5qL_7n,2093,"Proposal: Combine settings, metadata, static, etc. into a single `datasette.yaml` File",15178711,open,0,,,8,2023-06-29T21:18:23Z,2023-09-11T20:19:32Z,,CONTRIBUTOR,,"Very often I get tripped up when trying to configure my Datasette instances. For example: if I want to change the port my app listen too, do I do that with a CLI flag, a `--setting` flag, inside `metadata.json`, or an env var? If I want to up the time limit of SQL statements, is that under `metadata.json` or a setting? Where does my plugin configuration go?
Normally I need to look it up in Datasette docs, and I quickly find my answer, but the number of places where ""config"" goes it overwhelming.
- Flat CLI flags like `--port`, `--host`, `--cors`, etc.
- `--setting`, like `default_page_size`, `sql_time_limit_ms` etc
- Inside `metadata.json`, including plugin configuration
Typically my Datasette deploys are extremely long shell commands, with multiple `--setting` and other CLI flags.
## Proposal: Consolidate all ""config"" into `datasette.toml`
I propose that we add a new `datasette.toml` that combines ""settings"", ""metadata"", and other common CLI flags like `--port` and `--cors` into a single file. It would be similar to ""Cargo.toml"" in Rust projects, ""package.json"" in Node projects, and ""pyproject.toml"" in Python, etc.
A sample of what it could look like:
```toml
# ""top level"" configuration that are currently CLI flags on `datasette serve`
[config]
port = 8020
host = ""0.0.0.0""
cors = true
# replaces multiple `--setting` flags
[settings]
base_url = ""/app/datasette/""
default_allow_sql = true
sql_time_limit_ms = 3500
# replaces `metadata.json`.
# The contents of datasette-metadata.json could be defined in this file instead, but supporting separate files is nice (since those are easy to machine-generate)
[metadata]
include=""./datasette-metadata.json""
# plugin-specific
[plugins]
[plugins.datasette-auth-github]
client_id = {env = ""DATASETTE_AUTH_GITHUB_CLIENT_ID""}
client_secret = {env = ""GITHUB_CLIENT_SECRET""}
[plugins.datasette-cluster-map]
latitude_column = ""lat""
longitude_column = ""lon""
```
## Pros
- Instead of multiple files and CLI flags, everything could be in one tidy file
- Editing config in a separate file is easier than editing CLI flags, since you don't have to kill a process + edit a command every time
- New users will know ""just edit my `datasette.toml` instead of needing to learn metadata + settings + CLI flags
- Better dev experience for multiple environment. For example, could have `datasette -c datasette-dev.toml` for local dev environments (enables SQL, debug plugins, long timeouts, etc.), and a `datasette -c datasette-prod.toml` for ""production"" (lower timeouts, less plugins, monitoring plugins, etc.)
## Cons
- Yet another config-management system. Now Datasette users will need to know about metadata, settings, CLI flags, _and_ `datasette.toml`. However with enough documentation + announcements + examples, I think we can get ahead of it.
- If toml is chosen, would need to add a toml parser for Python version <3.11
- Multiple sources of config require priority. For example: Would `--setting default_allow_sql off` override the value inside `[settings]`? What about `--port`?
## Other Notes
### Toml
I chose toml over json because toml supports comments. I chose toml over yaml because Python 3.11 has builtin support for it. I also find toml easier to work with since it doesn't have the odd ""gotchas"" that YAML has (""ex `3.10` resolving to `3.1`, Norway `NO` resolving to `false`, etc.). It also mimics `pyproject.toml` which is nice. Happy to change my mind about this however
### Plugin config will be difficult
Plugin config is currently in `metadata.json` in two places:
1. Top level, under `""plugins.[plugin-name]""`. This fits well into `datasette.toml` as `[plugins.plugin-name]`
2. Table level, under `""databases.[db-name].tables.[table-name].plugins.[plugin-name]`. This doesn't fit that well into `datasette.toml`, unless it's nested under `[metadata]`?
### Extensions, static, one-off plugins?
We could also include equivalents of `--plugins-dir`, `--static`, and `--load-extension` into `datasette.toml`, but I'd imagine there's a few security concerns there to think through.
### Explicitly list with plugins to use?
I believe Datasette by default will load all install plugins on startup, but maybe `datasette.toml` can specify a list of plugins to use? For example, a dev version of `datasette.toml` can specify `datasette-pretty-traces`, but the prod version can leave it out",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2093/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1783304750,I_kwDOBm6k_c5qSxIu,2094,JS Plugin Hooks for the Code Editor,15178711,open,0,,,0,2023-07-01T00:51:57Z,2023-07-01T00:51:57Z,,CONTRIBUTOR,,"When #2052 merges, I'd like to add support to add extensions/functions to the Datasette code editor.
I'd eventually like to build a JS plugin for [`sqlite-docs`](https://github.com/asg017/sqlite-docs), to add things like:
- Inline documentation for tables/columns on hover
- Inline docs for custom functions that are loaded in
- More detailed autocomplete for tables/columns/functions
I did some hacking to see what this would look like, see here:
![]()
![]() There can be a new hook that allows JS plugins to add new ""extension"" in the CodeMirror editorview here:
https://github.com/simonw/datasette/blob/8cd60fd1d899952f1153460469b3175465f33f80/datasette/static/cm-editor-6.0.1.js#L25
Will need some more planning. For example, the Codemirror bundle in Datasette has functions that we could re-export for plugins to use (so we don't load 2 version of `""@codemirror/autocomplete""`, for example. ",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2094/reactions"", ""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 1, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1822813627,I_kwDOBm6k_c5spe27,2108,some (many?) SQL syntax errors are not throwing errors with a .csv endpoint,536941,open,0,,,0,2023-07-26T16:57:45Z,2023-07-26T16:58:07Z,,CONTRIBUTOR,,"here's a CTE query that should always fail with a syntax error:
```sql
with foo as (nonsense)
select
*
from
foo;
```
when we make this query against the default endpoint, we do indeed get a 400 status code the problem is returned to the user: https://global-power-plants.datasettes.com/global-power-plants?sql=with+foo+as+%28nonsense%29+select+*+from+foo%3B
but, if we use the csv endpoint, we get a 200 status code and no indication of a problem: https://global-power-plants.datasettes.com/global-power-plants.csv?sql=with+foo+as+%28nonsense%29+select+*+from+foo%3B
same with this bad sql
```sql
select
a,
from
foo;
```
https://global-power-plants.datasettes.com/global-power-plants?sql=select%0D%0A++a%2C%0D%0Afrom%0D%0A++foo%3B
vs
https://global-power-plants.datasettes.com/global-power-plants.csv?sql=select%0D%0A++a%2C%0D%0Afrom%0D%0A++foo%3B
but, datasette catches this bad sql at both endpoints:
```sql
slect
a
from
foo;
```
https://global-power-plants.datasettes.com/global-power-plants?sql=slect%0D%0A++a%0D%0Afrom%0D%0A++foo%3B
https://global-power-plants.datasettes.com/global-power-plants.csv?sql=slect%0D%0A++a%0D%0Afrom%0D%0A++foo%3B
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2108/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1855885427,I_kwDOBm6k_c5unpBz,2143,De-tangling Metadata before Datasette 1.0,15178711,open,0,,,24,2023-08-18T00:51:50Z,2023-08-24T18:28:27Z,,CONTRIBUTOR,,"Metadata in Datasette is a really powerful feature, but is a bit difficult to work with. It was initially a way to add ""metadata"" about your ""data"" in Datasette instances, like descriptions for databases/tables/columns, titles, source URLs, licenses, etc. But it later became the go-to spot for other Datasette features that have nothing to do with metadata, like permissions/plugins/canned queries.
Specifically, I've found the following problems when working with Datasette metadata:
1. Metadata cannot be updated without re-starting the entire Datasette instance.
2. The `metadata.json`/`metadata.yaml` has become a kitchen sink of unrelated (imo) features like plugin config, authentication config, canned queries
3. The Python APIs for defining extra metadata are a bit awkward (the `datasette.metadata()` class, `get_metadata()` hook, etc.)
## Possible solutions
Here's a few ideas of Datasette core changes we can make to address these problems.
### Re-vamp the Datasette Python metadata APIs
The Datasette object has a single `datasette.metadata()` method that's a bit difficult to work with. There's also no Python API for inserted new metadata, so plugins have to rely on the `get_metadata()` hook.
The `get_metadata()` hook can also be improved - it doesn't work with async functions yet, so you're quite limited to what you can do.
(I'm a bit fuzzy on what to actually do here, but I imagine it'll be very small breaking changes to a few Python methods)
### Add an optional `datasette_metadata` table
Datasette should detect and use metadata stored in a new special table called `datasette_metadata`. This would be a regular table that a user can edit on their own, and would serve as a ""live updating"" source of metadata, than can be changed while the Datasette instance is running.
Not too sure what the schema would look like, but I'd imagine:
```sql
CREATE TABLE datasette_metadata(
level text,
target any,
key text,
value any,
primary key (level, target)
)
```
Every row in this table would map to a single metadata ""entry"".
- `level` would be one of ""datasette"", ""database"", ""table"", ""column"", which is the ""level"" the entry describes. For example, `level=""table""` means it is metadata about a specific table, `level=""database""` for a specific database, or `level=""datasette""` for the entire Datasette instance.
- `target` would ""point"" to the specific object the entry metadata is about, and would depend on what `level` is specific.
- `level=""database""`: `target` would be the string name of the database that the metadata entry is about. ex `""fixtures""`
- `level=""table""`: `target` would be a JSON array of two strings. The first element would be the database name, and the second would be the table name. ex `[""fixtures"", ""students""]`
- `level=""column""`: `target` would be a JSON array of 3 strings: The database name, table name, and column name. Ex `[""fixtures"", ""students"", ""student_id""`]
- `key` would be the type of metadata entry the row has, similar to the current ""keys"" that exist in `metadata.json`. Ex `""about_url""`, `""source""`, `""description""`, etc
- `value` would be the text value of be metadata entry. The literal text value of a description, about_url, column_label, etc
A quick sample:
level | target | key | value
-- | -- | -- | --
datasette | NULL | title | my datasette title...
db | fixtures | source |
table | [""fixtures"", ""students""] | label_column | student_name
column | [""fixtures"", ""students"", ""birthdate""] | description |
This `datasette_metadata` would be configured with other tools, and hopefully not manually by end users. Datasette Core could also offer a UI for editing entries in `datasette_metadata`, to update descriptions/columns on the fly.
### Re-vamp `metadata.json` and move non-metadata config to another place
The motivation behind this is that it's awkward that `metadata.json` contains config about things that are not strictly metadata, including:
- Plugin configuration
- [Authentication/permissions](https://docs.datasette.io/en/latest/authentication.html#access-permissions-in-metadata) (ex the `allow` key on datasettes/databases/tables
- Canned queries. might be controversial, but in my mind, canned queries are application-specific code and configuration, and don't describe the data that exists in SQLite databases.
I think we should move these outside of `metadata.json` and into a different file. The `datasette.json` idea in #2093 may be a good solution here: plugin/permissions/canned queries can be defined in `datasette.json`, while `metadata.json`/`datasette_metadata` will strictly be about documenting databases/tables/columns.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2143/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1865869205,I_kwDOBm6k_c5vNueV,2157,"Proposal: Make the `_internal` database persistent, customizable, and hidden",15178711,open,0,,,3,2023-08-24T20:54:29Z,2023-08-31T02:45:56Z,,CONTRIBUTOR,,"The current `_internal` database is used by Datasette core to cache info about databases/tables/columns/foreign keys of databases in a Datasette instance. It's a temporary database created at startup, that can only be seen by the root user. See an [example `_internal` DB here](https://latest.datasette.io/_internal), after [logging in as root](https://latest.datasette.io/login-as-root).
The current `_internal` database has a few rough edges:
- It's part of `datasette.databases`, so many plugins have to specifically exclude `_internal` from their queries [examples here](https://github.com/search?q=datasette+hookimpl+%22_internal%22+language%3APython+-path%3Adatasette%2F&ref=opensearch&type=code)
- It's only used by Datasette core and can't be used by plugins or 3rd parties
- It's created from scratch at startup and stored in memory. Why is fine, the performance is great, but persistent storage would be nice.
Additionally, it would be really nice if plugins could use this `_internal` database to store their own configuration, secrets, and settings. For example:
- `datasette-auth-tokens` [creates a `_datasette_auth_tokens` table](https://github.com/simonw/datasette-auth-tokens/blob/main/datasette_auth_tokens/__init__.py#L15) to store auth token metadata. This could be moved into the `_internal` database to avoid writing to the gues database
- `datasette-socrata` [creates a `socrata_imports`](https://github.com/simonw/datasette-socrata/blob/1409aa9b4d2fc3aff286b52e73af33b5786d56d0/datasette_socrata/__init__.py#L190-L198) table, which also can be in `_internal`
- `datasette-upload-csvs` [creates a `_csv_progress_`](https://github.com/simonw/datasette-upload-csvs/blob/main/datasette_upload_csvs/__init__.py#L154) table, which can be in `_internal`
- `datasette-write-ui` wants to have the ability for users to toggle whether a table appears editable, which can be either in `datasette.yaml` or on-the-fly by storing config in `_internal`
In general, these are specific features that Datasette plugins would have access to if there was a central internal database they could read/write to:
- **Dynamic configuration**. Changing the `datasette.yaml` file works, but can be tedious to restart the server every time. Plugins can define their own configuration table in `_internal`, and could read/write to it to store configuration based on user actions (cell menu click, API access, etc.)
- **Caching**. If a plugin or Datasette Core needs to cache some expensive computation, they can store it inside `_internal` (possibly as a temporary table) instead of managing their own caching solution.
- **Audit logs**. If a plugin performs some sensitive operations, they can log usage info to `_internal` for others to audit later.
- **Long running process status**. Many plugins (`datasette-upload-csvs`, `datasette-litestream`, `datasette-socrata`) perform tasks that run for a really long time, and want to give continue status updates to the user. They can store this info inside` _internal`
- **Safer authentication**. Passwords and authentication plugins usually store credentials/hashed secrets in configuration files or environment variables, which can be difficult to handle. Now, they can store them in `_internal`
## Proposal
- We remove `_internal` from [`datasette.databases`](https://docs.datasette.io/en/latest/internals.html#databases) property.
- We add new `datasette.get_internal_db()` method that returns the `_internal` database, for plugins to use
- We add a new `--internal internal.db` flag. If provided, then the `_internal` DB will be sourced from that file, and further updates will be persisted to that file (instead of an in-memory database)
- When creating internal.db, create a new `_datasette_internal` table to mark it a an ""datasette internal database""
- In `datasette serve`, we check for the existence of the `_datasette_internal` table. If it exists, we assume the user provided that file in error and raise an error. This is to limit the chance that someone accidentally publishes their internal database to the internet. We could optionally add a `--unsafe-allow-internal` flag (or database plugin) that allows someone to do this if they really want to.
## New features unlocked with this
These features don't really need a standardized `_internal` table per-say (plugins could currently configure their own long-time storage features if they really wanted to), but it would make it much simpler to create these kinds of features with a persistent application database.
- **`datasette-comments`** : A plugin for commenting on rows or specific values in a database. Comment contents + threads + email notification info can be stored in `_internal`
- **Bookmarks**: ""Bookmarking"" an SQL query could be stored in `_internal`, or a URL link shortener
- **Webhooks**: If a plugin wants to either consume a webhook or create a new one, they can store hashed credentials/API endpoints in `_internal`",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2157/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1900026059,I_kwDOBm6k_c5xQBjL,2188,"Plugin Hooks for ""compile to SQL"" languages",15178711,open,0,,,2,2023-09-18T01:37:15Z,2023-09-18T06:58:53Z,,CONTRIBUTOR,,"There's a ton of tools/languages that compile to SQL, which may be nice in Datasette. Some examples:
- Logica https://logica.dev
- PRQL https://prql-lang.org
- Malloy, but not sure if it works with SQLite? https://github.com/malloydata/malloy
It would be cool if plugins could extend Datasette to use these languages, in both the code editor and API usage.
A few things I'd imagine a `datasette-prql` or `datasette-logica` plugin would do:
- `prql=` instead of `sql=`
- Code editor support (syntax highlighting, autocomplete)
- Hide/show SQL",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2188/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
273595473,MDExOlB1bGxSZXF1ZXN0MTUyMzYwNzQw,81,:fire: Removes DS_Store,50527,closed,0,,,2,2017-11-13T22:07:52Z,2017-11-14T02:24:54Z,2017-11-13T22:16:55Z,CONTRIBUTOR,simonw/datasette/pulls/81,,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/81/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
273816720,MDExOlB1bGxSZXF1ZXN0MTUyNTIyNzYy,89,SQL syntax highlighting with CodeMirror,15543,closed,0,,,1,2017-11-14T14:43:33Z,2017-11-15T02:03:01Z,2017-11-15T02:03:01Z,CONTRIBUTOR,simonw/datasette/pulls/89,"Addresses #13
Future enhancements could include autocompletion of table and column names, e.g. with
```javascript
extraKeys: {""Ctrl-Space"": ""autocomplete""},
hintOptions: {tables: {
users: [""name"", ""score"", ""birthDate""],
countries: [""name"", ""population"", ""size""]
}}
```
(see https://codemirror.net/doc/manual.html#addon_sql-hint and source at http://codemirror.net/mode/sql/)",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/89/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
273961179,MDExOlB1bGxSZXF1ZXN0MTUyNjMxNTcw,94,Initial add simple prod ready Dockerfile refs #57,247192,closed,0,,,1,2017-11-14T22:09:09Z,2017-11-15T03:08:04Z,2017-11-15T03:08:04Z,CONTRIBUTOR,simonw/datasette/pulls/94,"Multi-stage build based off official python:3.6-slim
Example usage:
```
docker run --rm -t -i -p 9000:8001 -v $(pwd)/db:/db datasette datasette serve /db/chinook.db
```",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/94/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
274284246,MDExOlB1bGxSZXF1ZXN0MTUyODcwMDMw,104,[WIP] Add publish to heroku support,21148,closed,0,,,6,2017-11-15T19:56:22Z,2017-11-21T20:55:05Z,2017-11-21T20:55:05Z,CONTRIBUTOR,simonw/datasette/pulls/104,"
Refs #90 ",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/104/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
274343647,MDExOlB1bGxSZXF1ZXN0MTUyOTE0NDgw,107,add support for ?field__isnull=1,3433657,closed,0,,,4,2017-11-15T23:36:36Z,2017-11-17T15:12:29Z,2017-11-17T13:29:22Z,CONTRIBUTOR,simonw/datasette/pulls/107,Is this what you had in mind for [this issue](https://github.com/simonw/datasette/issues/64)?,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/107/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
274733145,MDExOlB1bGxSZXF1ZXN0MTUzMjAxOTQ1,114,"Add spatialite, switch to debian and local build",54999,closed,0,,,1,2017-11-17T02:37:09Z,2017-11-17T03:50:52Z,2017-11-17T03:50:52Z,CONTRIBUTOR,simonw/datasette/pulls/114,"Improves the Dockerfile to support spatial datasets, work with the local datasette code (Friendly with git tags and Dockerhub) and moves to slim debian, a small image easy to extend via apt packages for sqlite.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/114/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
274877366,MDExOlB1bGxSZXF1ZXN0MTUzMzA2ODgy,115,Add keyboard shortcut to execute SQL query,198537,closed,0,,,1,2017-11-17T14:13:33Z,2017-11-17T15:16:34Z,2017-11-17T14:22:56Z,CONTRIBUTOR,simonw/datasette/pulls/115,"Very cool tool, thanks a lot!
This PR adds a `Shift-Enter` short cut to execute the SQL query. I used CodeMirrors keyboard handling.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/115/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
274900388,MDExOlB1bGxSZXF1ZXN0MTUzMzI0MzAx,117,Don't prevent tabbing to `Run SQL` button,198537,closed,0,,,1,2017-11-17T15:27:50Z,2017-11-19T20:30:24Z,2017-11-18T00:53:43Z,CONTRIBUTOR,simonw/datasette/pulls/117,"Mentioned in #115
Here you go!",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/117/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
291451116,MDExOlB1bGxSZXF1ZXN0MTY1MDI5ODA3,182,Add db filesize next to download link,3433657,closed,0,,,0,2018-01-25T04:58:56Z,2019-03-22T13:50:57Z,2019-02-06T04:59:38Z,CONTRIBUTOR,simonw/datasette/pulls/182,"Took a stab at #172, will this do the trick?",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/182/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
287240246,MDExOlB1bGxSZXF1ZXN0MTYxOTgyNzEx,178,"If metadata exists, add it to heroku launch command",82988,closed,0,,,1,2018-01-09T21:42:21Z,2018-01-15T09:42:46Z,2018-01-14T21:05:16Z,CONTRIBUTOR,simonw/datasette/pulls/178,"The heroku build does seem to make use of any provided `metadata.json` file.
Add the `--metadata` switch to the Heroku web launch command if a `metadata.json` file is available.
Addresses: https://github.com/simonw/datasette/issues/177",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/178/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
289375133,MDExOlB1bGxSZXF1ZXN0MTYzNTIzOTc2,180,make html title more readable in query template,56477,closed,0,,,0,2018-01-17T18:56:03Z,2018-04-03T16:03:38Z,2018-04-03T15:24:05Z,CONTRIBUTOR,simonw/datasette/pulls/180,tiny tweak to make this easier to visually parse—I think it matches your style in other templates,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/180/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
324836533,MDExOlB1bGxSZXF1ZXN0MTg5MzE4NDUz,277,Refactor inspect logic,45057,closed,0,,,2,2018-05-21T08:49:31Z,2018-05-22T16:07:24Z,2018-05-22T14:03:07Z,CONTRIBUTOR,simonw/datasette/pulls/277,"This pulls the logic for inspect out into a new file which makes it a bit easier to understand.
This was going to be the first part of an implementation for #276, but it seems like that might take a while so I'm going to PR a few bits of refactoring individually.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/277/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
325352370,MDExOlB1bGxSZXF1ZXN0MTg5NzA3Mzc0,279,Add version number support with Versioneer,198537,closed,0,,,4,2018-05-22T15:39:45Z,2018-05-22T19:35:23Z,2018-05-22T19:35:22Z,CONTRIBUTOR,simonw/datasette/pulls/279,"I think that's all for getting Versioneer support, I've been happily using it in a couple of projects ...
```
In [2]: datasette.__version__
Out[2]: '0.22+3.g6e12445'
```
Repo:
https://github.com/warner/python-versioneer
Versioneer Licence:
Public Domain (CC0-1.0)
Closes #273
",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/279/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
325373747,MDExOlB1bGxSZXF1ZXN0MTg5NzIzNzE2,280,Build Dockerfile with recent Sqlite + Spatialite,565628,closed,0,,,10,2018-05-22T16:33:50Z,2018-06-28T11:26:23Z,2018-05-23T17:43:35Z,CONTRIBUTOR,simonw/datasette/pulls/280,"This solves #278 without bloating the Dockerfile too much, the image size is now
495MB (original was ~240MB) but it could be reduced significantly if we only
copied the output of the compilation of spatialite and friends to
/usr/local/lib, instead of the entirety of it however that will take more time.
In the python code change references to `import sqlite3` to `import pysqlite3`
and it should use the compiled version of sqlite3.23.1. You don't need to
try/except because pysqlite3 falls back to builtin sqlite3 if there is no
compiled version.
```bash
$ docker run --rm -it datasette spatialite
SpatiaLite version ..: 4.4.0-RC0 Supported Extensions:
- 'VirtualShape' [direct Shapefile access]
- 'VirtualDbf' [direct DBF access]
- 'VirtualXL' [direct XLS access]
- 'VirtualText' [direct CSV/TXT access]
- 'VirtualNetwork' [Dijkstra shortest path]
- 'RTree' [Spatial Index - R*Tree]
- 'MbrCache' [Spatial Index - MBR cache]
- 'VirtualSpatialIndex' [R*Tree metahandler]
- 'VirtualElementary' [ElemGeoms metahandler]
- 'VirtualKNN' [K-Nearest Neighbors metahandler]
- 'VirtualXPath' [XML Path Language - XPath]
- 'VirtualFDO' [FDO-OGR interoperability]
- 'VirtualGPKG' [OGC GeoPackage interoperability]
- 'VirtualBBox' [BoundingBox tables]
- 'SpatiaLite' [Spatial SQL - OGC]
PROJ.4 version ......: Rel. 4.9.3, 15 August 2016
GEOS version ........: 3.5.1-CAPI-1.9.1 r4246
TARGET CPU ..........: x86_64-linux-gnu
the SPATIAL_REF_SYS table already contains some row(s)
SQLite version ......: 3.23.1
Enter "".help"" for instructions
SQLite version 3.23.1 2018-04-10 17:39:29
Enter "".help"" for instructions
Enter SQL statements terminated with a "";""
spatialite>
```
```bash
$ docker run --rm -it datasette python -c ""import pysqlite3; print(pysqlite3.sqlite_version)""
3.23.1
```",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/280/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
313494458,MDExOlB1bGxSZXF1ZXN0MTgxMDMzMDI0,200,Hide Spatialite system tables,45057,closed,0,,,3,2018-04-11T21:26:58Z,2018-04-12T21:34:48Z,2018-04-12T21:34:48Z,CONTRIBUTOR,simonw/datasette/pulls/200,They were getting on my nerves.,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/200/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
313785206,MDExOlB1bGxSZXF1ZXN0MTgxMjQ3NTY4,202,Raise 404 on nonexistent table URLs,45057,closed,0,,,2,2018-04-12T15:47:06Z,2018-04-13T19:22:56Z,2018-04-13T18:19:15Z,CONTRIBUTOR,simonw/datasette/pulls/202,"Currently they just 500. Also cleaned the logic up a bit, I hope I didn't miss anything.
This is issue #184.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/202/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314256802,MDExOlB1bGxSZXF1ZXN0MTgxNjAwOTI2,204,Initial units support,45057,closed,0,,,0,2018-04-13T21:32:49Z,2018-04-14T09:44:33Z,2018-04-14T03:32:54Z,CONTRIBUTOR,simonw/datasette/pulls/204,"Add support for specifying units for a column in metadata.json and rendering them on display using [pint](https://pint.readthedocs.io/en/latest/).
Example table metadata:
```json
""license_frequency"": {
""units"": {
""frequency"": ""Hz"",
""channel_width"": ""Hz"",
""height"": ""m"",
""antenna_height"": ""m"",
""azimuth"": ""degrees""
}
}
```
[Example result](https://wtr-api.herokuapp.com/wtr-663ea99/license_frequency/1)
This works surprisingly well! I'd like to add support for using units when querying but this is PR is pretty usable as-is.
(Pint doesn't seem to support decibels though - it thinks they're decibytes - which is an annoying omission.)
(ref ticket #203)",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/204/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314323977,MDExOlB1bGxSZXF1ZXN0MTgxNjQ0ODA1,206,Fix sqlite error when loading rows with no incoming FKs,45057,closed,0,,,0,2018-04-14T12:08:17Z,2018-04-14T14:32:42Z,2018-04-14T14:24:25Z,CONTRIBUTOR,simonw/datasette/pulls/206,"This fixes `ERROR: conn=, sql
= 'select ', params = {'id': '1'}` caused by an invalid query loading incoming FKs when none exist.
The error was ignored due to async but it still got printed to the console.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/206/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314329002,MDExOlB1bGxSZXF1ZXN0MTgxNjQ3NzE3,207,Link foreign keys which don't have labels,45057,closed,0,,,1,2018-04-14T13:27:14Z,2018-04-14T15:00:00Z,2018-04-14T15:00:00Z,CONTRIBUTOR,simonw/datasette/pulls/207,"This renders unlabeled FKs as simple links. I can't see why this would cause any major problems.

Also includes bonus fixes for two minor issues:
* In foreign key link hrefs the primary key was escaped using HTML escaping rather than URL escaping. This broke some non-integer PKs.
* Print tracebacks to console when handling 500 errors.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/207/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314319372,MDExOlB1bGxSZXF1ZXN0MTgxNjQyMTE0,205,Support filtering with units and more,45057,closed,0,,,3,2018-04-14T10:47:51Z,2018-04-14T15:24:04Z,2018-04-14T15:24:04Z,CONTRIBUTOR,simonw/datasette/pulls/205,"The first commit:
* Adds units to exported JSON
* Adds units key to metadata skeleton
* Adds some docs for units
The second commit adds filtering by units by the first method I mentioned in #203:

[Try it here](https://wtr-api.herokuapp.com/wtr-663ea99/license_frequency?frequency__gt=50GHz&height__lt=50ft). I think it integrates pretty neatly.
The third commit adds support for registering custom units with Pint from metadata.json. Probably pretty niche, but I need decibels!",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/205/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314340944,MDExOlB1bGxSZXF1ZXN0MTgxNjU0ODM5,208,Return HTTP 405 on InvalidUsage rather than 500,45057,closed,0,,,0,2018-04-14T16:12:50Z,2018-04-14T18:00:39Z,2018-04-14T18:00:39Z,CONTRIBUTOR,simonw/datasette/pulls/208,"This also stops it filling up the logs. This happens for HEAD requests at the moment - which perhaps should be handled better, but that's a different issue.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/208/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314455877,MDExOlB1bGxSZXF1ZXN0MTgxNzIzMzAz,209, Don't duplicate simple primary keys in the link column,45057,closed,0,,,6,2018-04-15T21:56:15Z,2018-04-18T08:40:37Z,2018-04-18T01:13:04Z,CONTRIBUTOR,simonw/datasette/pulls/209,"When there's a simple (single-column) primary key, it looks weird to duplicate it in the link column.
This change removes the second PK column and treats the link column as if it were the PK column from a header/sorting perspective.
This might make it a bit more difficult to tell what the link for the row is, I'm not sure yet. I feel like the alternative is to change the link column to just have the text ""view"" or something, instead of repeating the PK. (I doubt it makes much more sense with compound PKs.)
Bonus change in this PR: fix urlencoding of links in the displayed HTML.
Before:

After:
",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/209/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
316365426,MDExOlB1bGxSZXF1ZXN0MTgzMTM1NjA0,232,Fix a typo,45281,closed,0,,,1,2018-04-20T18:20:04Z,2018-04-21T00:19:08Z,2018-04-21T00:19:08Z,CONTRIBUTOR,simonw/datasette/pulls/232,It looks like this was the only instance of it: https://github.com/simonw/datasette/search?utf8=%E2%9C%93&q=SOLite&type=,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/232/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
341235633,MDExOlB1bGxSZXF1ZXN0MjAxNDUxMzMy,345,Allow app names for `datasette publish heroku`,45057,closed,0,,,1,2018-07-14T13:12:34Z,2018-07-14T14:09:54Z,2018-07-14T14:04:44Z,CONTRIBUTOR,simonw/datasette/pulls/345,"Lets you supply the `-n` parameter for Heroku deploys, which also lets you update existing Heroku deployments.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/345/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
361764460,MDExOlB1bGxSZXF1ZXN0MjE2NjUxMzE3,365,fix small doc typo,418191,closed,0,,,2,2018-09-19T14:02:02Z,2019-12-19T02:30:33Z,2018-09-19T17:15:43Z,CONTRIBUTOR,simonw/datasette/pulls/365,,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/365/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
374675798,MDExOlB1bGxSZXF1ZXN0MjI2MzE0ODYy,367,Mark codemirror files as vendored,48517,closed,0,,,2,2018-10-27T18:41:25Z,2019-05-03T21:12:09Z,2019-05-03T21:11:20Z,CONTRIBUTOR,simonw/datasette/pulls/367,"GitHub lists datasette as a Javascript project, primarily because of the vendored codemirror files. This is somewhat confusing when you're looking for datasette, knowing it's written in Python.
Luckily it's possible exclude certain files from GitHub's code statistics: https://github.com/github/linguist#using-gitattributes",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/367/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
374676773,MDExOlB1bGxSZXF1ZXN0MjI2MzE1NTEz,368,Update installation instructions,48517,closed,0,,,0,2018-10-27T18:52:31Z,2019-05-03T18:18:43Z,2019-05-03T18:18:42Z,CONTRIBUTOR,simonw/datasette/pulls/368,"I was writing this as a response to your tweet, but decided I might just make it a pull request.
I feel like it might be confusing to those unfamiliar with Python's `-m` flag and the built-in `venv` module to omit the space between the flag and its argument. By adding a space and prefixing the second occurrence of `venv` with a `./` it's maybe a bit clearer what the arguments are and what they do.
By also using `python3 -m pip` it becomes even clearer that `-m` is a special flag that makes the python executable do neat things.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/368/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
386459810,MDExOlB1bGxSZXF1ZXN0MjM1MTk0Mjg2,390,tiny typo in customization docs,418191,closed,0,,,1,2018-12-01T13:44:42Z,2019-12-19T02:30:35Z,2018-12-16T21:32:56Z,CONTRIBUTOR,simonw/datasette/pulls/390,was looking to add some custom templates to my use of datasette and saw this small typo.,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/390/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
413887019,MDExOlB1bGxSZXF1ZXN0MjU1NzI1MDU3,413,Update spatialite.rst,28597217,closed,0,,,1,2019-02-25T00:08:35Z,2019-03-15T05:06:45Z,2019-03-15T05:06:45Z,CONTRIBUTOR,simonw/datasette/pulls/413,a line of sql added to create the idx_ in the python recipe,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/413/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
427429265,MDExOlB1bGxSZXF1ZXN0MjY2MDM1Mzgy,424,Column types in inspected metadata,45057,closed,0,,,2,2019-03-31T18:46:33Z,2019-04-29T18:30:50Z,2019-04-29T18:30:46Z,CONTRIBUTOR,simonw/datasette/pulls/424,"This PR does two things:
* Adds the sqlite column type for each column to the inspected table info.
* Stops binary columns from being rendered to HTML, unless a plugin handles it.
There's a bit more detail in the changeset descriptions.
These changes are intended as a precursor to a plugin which adds first-class support for Spatialite geographic primitives, and perhaps more useful geo-stuff.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/424/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
438048318,MDExOlB1bGxSZXF1ZXN0Mjc0MTc0NjE0,437,Add inspect and prepare_sanic hooks,45057,closed,0,,,2,2019-04-28T11:53:34Z,2019-06-24T16:38:57Z,2019-06-24T16:38:56Z,CONTRIBUTOR,simonw/datasette/pulls/437,"This adds two new plugin hooks:
The `inspect` hook allows plugins to add data to the inspect dictionary.
The `prepare_sanic` hook allows plugins to hook into the web router. I've attached a warning to this hook in the docs in light of #272 but I want this hook now...
On quick inspection, I don't think it's worthwhile to try and make this hook independent of the web framework (but it looks like Starlette would make the hook implementation a bit nicer).
Ref #14",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/437/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
438240541,MDExOlB1bGxSZXF1ZXN0Mjc0MzEzNjI1,439,[WIP] Add primary key to the extra_body_script hook arguments,45057,closed,0,,,2,2019-04-29T10:08:23Z,2019-05-01T09:58:32Z,2019-05-01T09:58:30Z,CONTRIBUTOR,simonw/datasette/pulls/439,"This allows the row to be identified on row pages. The context here is that I want to access the row's data to plot it on a map.
I considered passing the entire template context through to the hook function. This would expose the actual row data and potentially avoid a further fetch request in JS, but it does make the plugin API a lot more leaky.
(At any rate, using the selected row data is tricky in my case because of Spatialite's infuriating custom binary representation...)",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/439/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
438437973,MDExOlB1bGxSZXF1ZXN0Mjc0NDY4ODM2,441,Add register_output_renderer hook,45057,closed,0,,,8,2019-04-29T18:03:21Z,2019-05-01T23:01:57Z,2019-05-01T23:01:57Z,CONTRIBUTOR,simonw/datasette/pulls/441,"This changeset refactors out the JSON renderer and then adds a hook and
dispatcher system to allow custom output renderers to be registered.
The CSV output renderer is untouched because supporting streaming
renderers through this system would be significantly more complex, and
probably not worthwhile.
We can't simply allow hooks to be called at request time because we need
a list of supported file extensions when the request is being routed in
order to resolve ambiguous database/table names. So, renderers need to
be registered at startup.
I've tried to make this API independent of Sanic's request/response
objects so that this can remain stable during the switch to ASGI. I'm
using dictionaries to keep it simple and to make adding additional
options in the future easy.
Fixes #440",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/441/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
438450757,MDExOlB1bGxSZXF1ZXN0Mjc0NDc4NzYx,442,Suppress rendering of binary data,45057,closed,0,,,2,2019-04-29T18:36:41Z,2019-05-03T18:26:48Z,2019-05-03T16:44:49Z,CONTRIBUTOR,simonw/datasette/pulls/442,"Binary columns (including spatialite geographies) get shown as ugly
binary strings in the HTML by default. Nobody wants to see that mess.
Show the size of the column in bytes instead. If you want to decode
the binary data, you can use a plugin to do it.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/442/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
439480260,MDExOlB1bGxSZXF1ZXN0Mjc1Mjc1NjEw,443,Pass view_name to extra_body_script hook,45057,closed,0,,,0,2019-05-02T08:38:36Z,2019-05-03T13:12:20Z,2019-05-03T13:12:20Z,CONTRIBUTOR,simonw/datasette/pulls/443,"At the moment it's not easy to tell whether the hook is being called
in (for example) the row or table view, as in both cases the
`database` and `table` parameters are provided.
This passes the `view_name` added in #441 to the `extra_body_script`
hook.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/443/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
439487648,MDExOlB1bGxSZXF1ZXN0Mjc1MjgxMzA3,444,Add a max-line-length setting for flake8,45057,closed,0,,,0,2019-05-02T08:58:57Z,2019-05-04T09:44:48Z,2019-05-03T13:11:28Z,CONTRIBUTOR,simonw/datasette/pulls/444,"This stops my automatic editor linting from flagging lines which are too
long. It's been lingering in my checkout for ages.
160 is an arbitrary large number - we could alter it if we have any
opinions (but I find the line length limit to be my least favourite part
of PEP8).",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/444/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
440304714,MDExOlB1bGxSZXF1ZXN0Mjc1OTA5MTk3,450,Coalesce hidden table count to 0,45057,closed,0,,,2,2019-05-04T09:37:10Z,2019-05-11T18:10:09Z,2019-05-11T18:10:09Z,CONTRIBUTOR,simonw/datasette/pulls/450,"For some reason I'm hitting a `None` here with a FTS table. I'm not
entirely sure why but this makes the logic work the same as with
non-hidden tables.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/450/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
440325850,MDExOlB1bGxSZXF1ZXN0Mjc1OTIzMDY2,452,SQL builder utility classes,45057,open,0,,,0,2019-05-04T13:57:47Z,2019-05-04T14:03:04Z,,CONTRIBUTOR,simonw/datasette/pulls/452,"This adds a straightforward set of classes to aid in the construction of
SQL queries.
My plan for this was to allow plugins to manipulate the
Datasette-generated SQL in a more structured way. I'm not sure that's
going to work, but I feel like this is still a step forward - it
reduces the number of intermediate variables in `TableView.data` which
aids readability, and also factors out a lot of the boring string
concatenation.
There are a fair number of minor structure changes in here too as I've
tried to make the ordering of `TableView.data` a bit more logical. As
far as I can tell, I haven't broken anything...",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/452/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
442402832,MDExOlB1bGxSZXF1ZXN0Mjc3NTI0MDcy,458,setup: add tests to package exclusion,7725188,closed,0,,,1,2019-05-09T19:47:21Z,2020-07-21T01:14:42Z,2019-05-10T01:54:51Z,CONTRIBUTOR,simonw/datasette/pulls/458,"This PR fixes #456 by adding `tests` to the package exclusion list.
Cheers",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/458/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
434321685,MDExOlB1bGxSZXF1ZXN0MjcxMzM4NDA1,434,"""datasette publish cloudrun"" command to publish to Google Cloud Run",10352819,closed,0,,,8,2019-04-17T14:41:18Z,2019-05-03T21:50:44Z,2019-05-03T13:59:02Z,CONTRIBUTOR,simonw/datasette/pulls/434,"This is a very rough draft to start a discussion on a possible datasette cloud run publish plugin (see issue #400).
The main change was to dynamically set the listening port in `make_dockerfile` to satisfy cloud run's [requirements](https://cloud.google.com/run/docs/reference/container-contract).
This was done by running `datasette` through `sh` to get environment variable substitution. Not sure if that's the right approach?
",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/434/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
451705509,MDExOlB1bGxSZXF1ZXN0Mjg0NzQzNzk0,500,Fix typo in install step: should be install -e,32314,closed,0,,,1,2019-06-03T21:50:51Z,2019-06-11T18:48:43Z,2019-06-11T18:48:40Z,CONTRIBUTOR,simonw/datasette/pulls/500,,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/500/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
445873563,MDExOlB1bGxSZXF1ZXN0MjgwMjA0Mjc2,479,doc typo fix,98555,closed,0,,,1,2019-05-19T22:54:25Z,2019-05-20T16:42:29Z,2019-05-20T16:42:29Z,CONTRIBUTOR,simonw/datasette/pulls/479,Fix typo in performance doc page,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/479/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
445875242,MDExOlB1bGxSZXF1ZXN0MjgwMjA1NTAy,480,Split pypi and docker travis tasks,813732,closed,0,,4471010,1,2019-05-19T23:14:37Z,2019-07-07T20:03:20Z,2019-07-07T20:03:20Z,CONTRIBUTOR,simonw/datasette/pulls/480,"Resolves #478
This *should* work, but because this is a change that'll only really be testable on a) this repo, b) master branch, this might fail fast if I didn't get the configurations right.
Looking at #478 it should just be as simple as splitting out the docker and pypi processes into separate jobs, but it might end up being more complicated than that, depending on what pre-processes the pypi deployment needs, and how travisci treats deployment steps without scripts in general. ",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/480/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
465728430,MDExOlB1bGxSZXF1ZXN0Mjk1NzExNTA0,554,Fix static mounts using relative paths and prevent traversal exploits,3243482,closed,0,,,4,2019-07-09T11:32:02Z,2019-07-11T16:29:26Z,2019-07-11T16:13:19Z,CONTRIBUTOR,simonw/datasette/pulls/554,"While debugging why my static mounts using a relative path (`--static mystatic:rel/path/to/dir`) not working, I noticed that the requests fail no matter what, returning 404 errors.
The reason is that datasette tries to prevent traversal exploits by checking if the path is relative to its registered directory. This check fails when the mount is a relative directory, because `/abs/dir/file` obviously not under `dir/file`.
https://github.com/simonw/datasette/blob/81fa8b6cdc5457b42a224779e5291952314e8d20/datasette/utils/asgi.py#L303-L306
This also has the consequence of returning any requested file, because when `/abs/dir/../../evil.file` resolves `aiofiles` happily returns it to the client after it resolves the path itself. The solution is to make sure we're checking relativity of paths after they're fully resolved.
I've implemented the mentioned changes and also updated the tests.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/554/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
465773546,MDExOlB1bGxSZXF1ZXN0Mjk1NzQ4MjY4,556,Add support for running datasette as a module,3243482,closed,0,,,1,2019-07-09T13:13:30Z,2019-07-11T16:07:45Z,2019-07-11T16:07:44Z,CONTRIBUTOR,simonw/datasette/pulls/556,"This PR allows running datasette using `python -m datasette` command in addition to just running the executable.
This function is quite useful when debugging a plugin in a project because IDEs like PyCharm can easily start a debug session when datasette is run as a module in contrast to trying to attach a debugger to a running process.
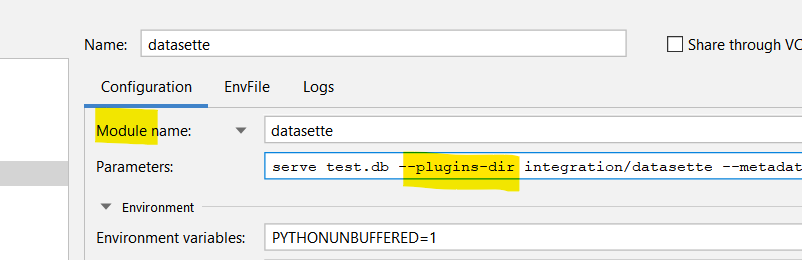
",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/556/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
There can be a new hook that allows JS plugins to add new ""extension"" in the CodeMirror editorview here:
https://github.com/simonw/datasette/blob/8cd60fd1d899952f1153460469b3175465f33f80/datasette/static/cm-editor-6.0.1.js#L25
Will need some more planning. For example, the Codemirror bundle in Datasette has functions that we could re-export for plugins to use (so we don't load 2 version of `""@codemirror/autocomplete""`, for example. ",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2094/reactions"", ""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 1, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1822813627,I_kwDOBm6k_c5spe27,2108,some (many?) SQL syntax errors are not throwing errors with a .csv endpoint,536941,open,0,,,0,2023-07-26T16:57:45Z,2023-07-26T16:58:07Z,,CONTRIBUTOR,,"here's a CTE query that should always fail with a syntax error:
```sql
with foo as (nonsense)
select
*
from
foo;
```
when we make this query against the default endpoint, we do indeed get a 400 status code the problem is returned to the user: https://global-power-plants.datasettes.com/global-power-plants?sql=with+foo+as+%28nonsense%29+select+*+from+foo%3B
but, if we use the csv endpoint, we get a 200 status code and no indication of a problem: https://global-power-plants.datasettes.com/global-power-plants.csv?sql=with+foo+as+%28nonsense%29+select+*+from+foo%3B
same with this bad sql
```sql
select
a,
from
foo;
```
https://global-power-plants.datasettes.com/global-power-plants?sql=select%0D%0A++a%2C%0D%0Afrom%0D%0A++foo%3B
vs
https://global-power-plants.datasettes.com/global-power-plants.csv?sql=select%0D%0A++a%2C%0D%0Afrom%0D%0A++foo%3B
but, datasette catches this bad sql at both endpoints:
```sql
slect
a
from
foo;
```
https://global-power-plants.datasettes.com/global-power-plants?sql=slect%0D%0A++a%0D%0Afrom%0D%0A++foo%3B
https://global-power-plants.datasettes.com/global-power-plants.csv?sql=slect%0D%0A++a%0D%0Afrom%0D%0A++foo%3B
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2108/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1855885427,I_kwDOBm6k_c5unpBz,2143,De-tangling Metadata before Datasette 1.0,15178711,open,0,,,24,2023-08-18T00:51:50Z,2023-08-24T18:28:27Z,,CONTRIBUTOR,,"Metadata in Datasette is a really powerful feature, but is a bit difficult to work with. It was initially a way to add ""metadata"" about your ""data"" in Datasette instances, like descriptions for databases/tables/columns, titles, source URLs, licenses, etc. But it later became the go-to spot for other Datasette features that have nothing to do with metadata, like permissions/plugins/canned queries.
Specifically, I've found the following problems when working with Datasette metadata:
1. Metadata cannot be updated without re-starting the entire Datasette instance.
2. The `metadata.json`/`metadata.yaml` has become a kitchen sink of unrelated (imo) features like plugin config, authentication config, canned queries
3. The Python APIs for defining extra metadata are a bit awkward (the `datasette.metadata()` class, `get_metadata()` hook, etc.)
## Possible solutions
Here's a few ideas of Datasette core changes we can make to address these problems.
### Re-vamp the Datasette Python metadata APIs
The Datasette object has a single `datasette.metadata()` method that's a bit difficult to work with. There's also no Python API for inserted new metadata, so plugins have to rely on the `get_metadata()` hook.
The `get_metadata()` hook can also be improved - it doesn't work with async functions yet, so you're quite limited to what you can do.
(I'm a bit fuzzy on what to actually do here, but I imagine it'll be very small breaking changes to a few Python methods)
### Add an optional `datasette_metadata` table
Datasette should detect and use metadata stored in a new special table called `datasette_metadata`. This would be a regular table that a user can edit on their own, and would serve as a ""live updating"" source of metadata, than can be changed while the Datasette instance is running.
Not too sure what the schema would look like, but I'd imagine:
```sql
CREATE TABLE datasette_metadata(
level text,
target any,
key text,
value any,
primary key (level, target)
)
```
Every row in this table would map to a single metadata ""entry"".
- `level` would be one of ""datasette"", ""database"", ""table"", ""column"", which is the ""level"" the entry describes. For example, `level=""table""` means it is metadata about a specific table, `level=""database""` for a specific database, or `level=""datasette""` for the entire Datasette instance.
- `target` would ""point"" to the specific object the entry metadata is about, and would depend on what `level` is specific.
- `level=""database""`: `target` would be the string name of the database that the metadata entry is about. ex `""fixtures""`
- `level=""table""`: `target` would be a JSON array of two strings. The first element would be the database name, and the second would be the table name. ex `[""fixtures"", ""students""]`
- `level=""column""`: `target` would be a JSON array of 3 strings: The database name, table name, and column name. Ex `[""fixtures"", ""students"", ""student_id""`]
- `key` would be the type of metadata entry the row has, similar to the current ""keys"" that exist in `metadata.json`. Ex `""about_url""`, `""source""`, `""description""`, etc
- `value` would be the text value of be metadata entry. The literal text value of a description, about_url, column_label, etc
A quick sample:
level | target | key | value
-- | -- | -- | --
datasette | NULL | title | my datasette title...
db | fixtures | source |
table | [""fixtures"", ""students""] | label_column | student_name
column | [""fixtures"", ""students"", ""birthdate""] | description |
This `datasette_metadata` would be configured with other tools, and hopefully not manually by end users. Datasette Core could also offer a UI for editing entries in `datasette_metadata`, to update descriptions/columns on the fly.
### Re-vamp `metadata.json` and move non-metadata config to another place
The motivation behind this is that it's awkward that `metadata.json` contains config about things that are not strictly metadata, including:
- Plugin configuration
- [Authentication/permissions](https://docs.datasette.io/en/latest/authentication.html#access-permissions-in-metadata) (ex the `allow` key on datasettes/databases/tables
- Canned queries. might be controversial, but in my mind, canned queries are application-specific code and configuration, and don't describe the data that exists in SQLite databases.
I think we should move these outside of `metadata.json` and into a different file. The `datasette.json` idea in #2093 may be a good solution here: plugin/permissions/canned queries can be defined in `datasette.json`, while `metadata.json`/`datasette_metadata` will strictly be about documenting databases/tables/columns.
",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2143/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1865869205,I_kwDOBm6k_c5vNueV,2157,"Proposal: Make the `_internal` database persistent, customizable, and hidden",15178711,open,0,,,3,2023-08-24T20:54:29Z,2023-08-31T02:45:56Z,,CONTRIBUTOR,,"The current `_internal` database is used by Datasette core to cache info about databases/tables/columns/foreign keys of databases in a Datasette instance. It's a temporary database created at startup, that can only be seen by the root user. See an [example `_internal` DB here](https://latest.datasette.io/_internal), after [logging in as root](https://latest.datasette.io/login-as-root).
The current `_internal` database has a few rough edges:
- It's part of `datasette.databases`, so many plugins have to specifically exclude `_internal` from their queries [examples here](https://github.com/search?q=datasette+hookimpl+%22_internal%22+language%3APython+-path%3Adatasette%2F&ref=opensearch&type=code)
- It's only used by Datasette core and can't be used by plugins or 3rd parties
- It's created from scratch at startup and stored in memory. Why is fine, the performance is great, but persistent storage would be nice.
Additionally, it would be really nice if plugins could use this `_internal` database to store their own configuration, secrets, and settings. For example:
- `datasette-auth-tokens` [creates a `_datasette_auth_tokens` table](https://github.com/simonw/datasette-auth-tokens/blob/main/datasette_auth_tokens/__init__.py#L15) to store auth token metadata. This could be moved into the `_internal` database to avoid writing to the gues database
- `datasette-socrata` [creates a `socrata_imports`](https://github.com/simonw/datasette-socrata/blob/1409aa9b4d2fc3aff286b52e73af33b5786d56d0/datasette_socrata/__init__.py#L190-L198) table, which also can be in `_internal`
- `datasette-upload-csvs` [creates a `_csv_progress_`](https://github.com/simonw/datasette-upload-csvs/blob/main/datasette_upload_csvs/__init__.py#L154) table, which can be in `_internal`
- `datasette-write-ui` wants to have the ability for users to toggle whether a table appears editable, which can be either in `datasette.yaml` or on-the-fly by storing config in `_internal`
In general, these are specific features that Datasette plugins would have access to if there was a central internal database they could read/write to:
- **Dynamic configuration**. Changing the `datasette.yaml` file works, but can be tedious to restart the server every time. Plugins can define their own configuration table in `_internal`, and could read/write to it to store configuration based on user actions (cell menu click, API access, etc.)
- **Caching**. If a plugin or Datasette Core needs to cache some expensive computation, they can store it inside `_internal` (possibly as a temporary table) instead of managing their own caching solution.
- **Audit logs**. If a plugin performs some sensitive operations, they can log usage info to `_internal` for others to audit later.
- **Long running process status**. Many plugins (`datasette-upload-csvs`, `datasette-litestream`, `datasette-socrata`) perform tasks that run for a really long time, and want to give continue status updates to the user. They can store this info inside` _internal`
- **Safer authentication**. Passwords and authentication plugins usually store credentials/hashed secrets in configuration files or environment variables, which can be difficult to handle. Now, they can store them in `_internal`
## Proposal
- We remove `_internal` from [`datasette.databases`](https://docs.datasette.io/en/latest/internals.html#databases) property.
- We add new `datasette.get_internal_db()` method that returns the `_internal` database, for plugins to use
- We add a new `--internal internal.db` flag. If provided, then the `_internal` DB will be sourced from that file, and further updates will be persisted to that file (instead of an in-memory database)
- When creating internal.db, create a new `_datasette_internal` table to mark it a an ""datasette internal database""
- In `datasette serve`, we check for the existence of the `_datasette_internal` table. If it exists, we assume the user provided that file in error and raise an error. This is to limit the chance that someone accidentally publishes their internal database to the internet. We could optionally add a `--unsafe-allow-internal` flag (or database plugin) that allows someone to do this if they really want to.
## New features unlocked with this
These features don't really need a standardized `_internal` table per-say (plugins could currently configure their own long-time storage features if they really wanted to), but it would make it much simpler to create these kinds of features with a persistent application database.
- **`datasette-comments`** : A plugin for commenting on rows or specific values in a database. Comment contents + threads + email notification info can be stored in `_internal`
- **Bookmarks**: ""Bookmarking"" an SQL query could be stored in `_internal`, or a URL link shortener
- **Webhooks**: If a plugin wants to either consume a webhook or create a new one, they can store hashed credentials/API endpoints in `_internal`",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2157/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
1900026059,I_kwDOBm6k_c5xQBjL,2188,"Plugin Hooks for ""compile to SQL"" languages",15178711,open,0,,,2,2023-09-18T01:37:15Z,2023-09-18T06:58:53Z,,CONTRIBUTOR,,"There's a ton of tools/languages that compile to SQL, which may be nice in Datasette. Some examples:
- Logica https://logica.dev
- PRQL https://prql-lang.org
- Malloy, but not sure if it works with SQLite? https://github.com/malloydata/malloy
It would be cool if plugins could extend Datasette to use these languages, in both the code editor and API usage.
A few things I'd imagine a `datasette-prql` or `datasette-logica` plugin would do:
- `prql=` instead of `sql=`
- Code editor support (syntax highlighting, autocomplete)
- Hide/show SQL",107914493,issue,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/2188/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,
273595473,MDExOlB1bGxSZXF1ZXN0MTUyMzYwNzQw,81,:fire: Removes DS_Store,50527,closed,0,,,2,2017-11-13T22:07:52Z,2017-11-14T02:24:54Z,2017-11-13T22:16:55Z,CONTRIBUTOR,simonw/datasette/pulls/81,,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/81/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
273816720,MDExOlB1bGxSZXF1ZXN0MTUyNTIyNzYy,89,SQL syntax highlighting with CodeMirror,15543,closed,0,,,1,2017-11-14T14:43:33Z,2017-11-15T02:03:01Z,2017-11-15T02:03:01Z,CONTRIBUTOR,simonw/datasette/pulls/89,"Addresses #13
Future enhancements could include autocompletion of table and column names, e.g. with
```javascript
extraKeys: {""Ctrl-Space"": ""autocomplete""},
hintOptions: {tables: {
users: [""name"", ""score"", ""birthDate""],
countries: [""name"", ""population"", ""size""]
}}
```
(see https://codemirror.net/doc/manual.html#addon_sql-hint and source at http://codemirror.net/mode/sql/)",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/89/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
273961179,MDExOlB1bGxSZXF1ZXN0MTUyNjMxNTcw,94,Initial add simple prod ready Dockerfile refs #57,247192,closed,0,,,1,2017-11-14T22:09:09Z,2017-11-15T03:08:04Z,2017-11-15T03:08:04Z,CONTRIBUTOR,simonw/datasette/pulls/94,"Multi-stage build based off official python:3.6-slim
Example usage:
```
docker run --rm -t -i -p 9000:8001 -v $(pwd)/db:/db datasette datasette serve /db/chinook.db
```",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/94/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
274284246,MDExOlB1bGxSZXF1ZXN0MTUyODcwMDMw,104,[WIP] Add publish to heroku support,21148,closed,0,,,6,2017-11-15T19:56:22Z,2017-11-21T20:55:05Z,2017-11-21T20:55:05Z,CONTRIBUTOR,simonw/datasette/pulls/104,"
Refs #90 ",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/104/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
274343647,MDExOlB1bGxSZXF1ZXN0MTUyOTE0NDgw,107,add support for ?field__isnull=1,3433657,closed,0,,,4,2017-11-15T23:36:36Z,2017-11-17T15:12:29Z,2017-11-17T13:29:22Z,CONTRIBUTOR,simonw/datasette/pulls/107,Is this what you had in mind for [this issue](https://github.com/simonw/datasette/issues/64)?,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/107/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
274733145,MDExOlB1bGxSZXF1ZXN0MTUzMjAxOTQ1,114,"Add spatialite, switch to debian and local build",54999,closed,0,,,1,2017-11-17T02:37:09Z,2017-11-17T03:50:52Z,2017-11-17T03:50:52Z,CONTRIBUTOR,simonw/datasette/pulls/114,"Improves the Dockerfile to support spatial datasets, work with the local datasette code (Friendly with git tags and Dockerhub) and moves to slim debian, a small image easy to extend via apt packages for sqlite.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/114/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
274877366,MDExOlB1bGxSZXF1ZXN0MTUzMzA2ODgy,115,Add keyboard shortcut to execute SQL query,198537,closed,0,,,1,2017-11-17T14:13:33Z,2017-11-17T15:16:34Z,2017-11-17T14:22:56Z,CONTRIBUTOR,simonw/datasette/pulls/115,"Very cool tool, thanks a lot!
This PR adds a `Shift-Enter` short cut to execute the SQL query. I used CodeMirrors keyboard handling.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/115/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
274900388,MDExOlB1bGxSZXF1ZXN0MTUzMzI0MzAx,117,Don't prevent tabbing to `Run SQL` button,198537,closed,0,,,1,2017-11-17T15:27:50Z,2017-11-19T20:30:24Z,2017-11-18T00:53:43Z,CONTRIBUTOR,simonw/datasette/pulls/117,"Mentioned in #115
Here you go!",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/117/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
291451116,MDExOlB1bGxSZXF1ZXN0MTY1MDI5ODA3,182,Add db filesize next to download link,3433657,closed,0,,,0,2018-01-25T04:58:56Z,2019-03-22T13:50:57Z,2019-02-06T04:59:38Z,CONTRIBUTOR,simonw/datasette/pulls/182,"Took a stab at #172, will this do the trick?",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/182/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
287240246,MDExOlB1bGxSZXF1ZXN0MTYxOTgyNzEx,178,"If metadata exists, add it to heroku launch command",82988,closed,0,,,1,2018-01-09T21:42:21Z,2018-01-15T09:42:46Z,2018-01-14T21:05:16Z,CONTRIBUTOR,simonw/datasette/pulls/178,"The heroku build does seem to make use of any provided `metadata.json` file.
Add the `--metadata` switch to the Heroku web launch command if a `metadata.json` file is available.
Addresses: https://github.com/simonw/datasette/issues/177",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/178/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
289375133,MDExOlB1bGxSZXF1ZXN0MTYzNTIzOTc2,180,make html title more readable in query template,56477,closed,0,,,0,2018-01-17T18:56:03Z,2018-04-03T16:03:38Z,2018-04-03T15:24:05Z,CONTRIBUTOR,simonw/datasette/pulls/180,tiny tweak to make this easier to visually parse—I think it matches your style in other templates,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/180/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
324836533,MDExOlB1bGxSZXF1ZXN0MTg5MzE4NDUz,277,Refactor inspect logic,45057,closed,0,,,2,2018-05-21T08:49:31Z,2018-05-22T16:07:24Z,2018-05-22T14:03:07Z,CONTRIBUTOR,simonw/datasette/pulls/277,"This pulls the logic for inspect out into a new file which makes it a bit easier to understand.
This was going to be the first part of an implementation for #276, but it seems like that might take a while so I'm going to PR a few bits of refactoring individually.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/277/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
325352370,MDExOlB1bGxSZXF1ZXN0MTg5NzA3Mzc0,279,Add version number support with Versioneer,198537,closed,0,,,4,2018-05-22T15:39:45Z,2018-05-22T19:35:23Z,2018-05-22T19:35:22Z,CONTRIBUTOR,simonw/datasette/pulls/279,"I think that's all for getting Versioneer support, I've been happily using it in a couple of projects ...
```
In [2]: datasette.__version__
Out[2]: '0.22+3.g6e12445'
```
Repo:
https://github.com/warner/python-versioneer
Versioneer Licence:
Public Domain (CC0-1.0)
Closes #273
",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/279/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
325373747,MDExOlB1bGxSZXF1ZXN0MTg5NzIzNzE2,280,Build Dockerfile with recent Sqlite + Spatialite,565628,closed,0,,,10,2018-05-22T16:33:50Z,2018-06-28T11:26:23Z,2018-05-23T17:43:35Z,CONTRIBUTOR,simonw/datasette/pulls/280,"This solves #278 without bloating the Dockerfile too much, the image size is now
495MB (original was ~240MB) but it could be reduced significantly if we only
copied the output of the compilation of spatialite and friends to
/usr/local/lib, instead of the entirety of it however that will take more time.
In the python code change references to `import sqlite3` to `import pysqlite3`
and it should use the compiled version of sqlite3.23.1. You don't need to
try/except because pysqlite3 falls back to builtin sqlite3 if there is no
compiled version.
```bash
$ docker run --rm -it datasette spatialite
SpatiaLite version ..: 4.4.0-RC0 Supported Extensions:
- 'VirtualShape' [direct Shapefile access]
- 'VirtualDbf' [direct DBF access]
- 'VirtualXL' [direct XLS access]
- 'VirtualText' [direct CSV/TXT access]
- 'VirtualNetwork' [Dijkstra shortest path]
- 'RTree' [Spatial Index - R*Tree]
- 'MbrCache' [Spatial Index - MBR cache]
- 'VirtualSpatialIndex' [R*Tree metahandler]
- 'VirtualElementary' [ElemGeoms metahandler]
- 'VirtualKNN' [K-Nearest Neighbors metahandler]
- 'VirtualXPath' [XML Path Language - XPath]
- 'VirtualFDO' [FDO-OGR interoperability]
- 'VirtualGPKG' [OGC GeoPackage interoperability]
- 'VirtualBBox' [BoundingBox tables]
- 'SpatiaLite' [Spatial SQL - OGC]
PROJ.4 version ......: Rel. 4.9.3, 15 August 2016
GEOS version ........: 3.5.1-CAPI-1.9.1 r4246
TARGET CPU ..........: x86_64-linux-gnu
the SPATIAL_REF_SYS table already contains some row(s)
SQLite version ......: 3.23.1
Enter "".help"" for instructions
SQLite version 3.23.1 2018-04-10 17:39:29
Enter "".help"" for instructions
Enter SQL statements terminated with a "";""
spatialite>
```
```bash
$ docker run --rm -it datasette python -c ""import pysqlite3; print(pysqlite3.sqlite_version)""
3.23.1
```",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/280/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
313494458,MDExOlB1bGxSZXF1ZXN0MTgxMDMzMDI0,200,Hide Spatialite system tables,45057,closed,0,,,3,2018-04-11T21:26:58Z,2018-04-12T21:34:48Z,2018-04-12T21:34:48Z,CONTRIBUTOR,simonw/datasette/pulls/200,They were getting on my nerves.,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/200/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
313785206,MDExOlB1bGxSZXF1ZXN0MTgxMjQ3NTY4,202,Raise 404 on nonexistent table URLs,45057,closed,0,,,2,2018-04-12T15:47:06Z,2018-04-13T19:22:56Z,2018-04-13T18:19:15Z,CONTRIBUTOR,simonw/datasette/pulls/202,"Currently they just 500. Also cleaned the logic up a bit, I hope I didn't miss anything.
This is issue #184.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/202/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314256802,MDExOlB1bGxSZXF1ZXN0MTgxNjAwOTI2,204,Initial units support,45057,closed,0,,,0,2018-04-13T21:32:49Z,2018-04-14T09:44:33Z,2018-04-14T03:32:54Z,CONTRIBUTOR,simonw/datasette/pulls/204,"Add support for specifying units for a column in metadata.json and rendering them on display using [pint](https://pint.readthedocs.io/en/latest/).
Example table metadata:
```json
""license_frequency"": {
""units"": {
""frequency"": ""Hz"",
""channel_width"": ""Hz"",
""height"": ""m"",
""antenna_height"": ""m"",
""azimuth"": ""degrees""
}
}
```
[Example result](https://wtr-api.herokuapp.com/wtr-663ea99/license_frequency/1)
This works surprisingly well! I'd like to add support for using units when querying but this is PR is pretty usable as-is.
(Pint doesn't seem to support decibels though - it thinks they're decibytes - which is an annoying omission.)
(ref ticket #203)",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/204/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314323977,MDExOlB1bGxSZXF1ZXN0MTgxNjQ0ODA1,206,Fix sqlite error when loading rows with no incoming FKs,45057,closed,0,,,0,2018-04-14T12:08:17Z,2018-04-14T14:32:42Z,2018-04-14T14:24:25Z,CONTRIBUTOR,simonw/datasette/pulls/206,"This fixes `ERROR: conn=, sql
= 'select ', params = {'id': '1'}` caused by an invalid query loading incoming FKs when none exist.
The error was ignored due to async but it still got printed to the console.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/206/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314329002,MDExOlB1bGxSZXF1ZXN0MTgxNjQ3NzE3,207,Link foreign keys which don't have labels,45057,closed,0,,,1,2018-04-14T13:27:14Z,2018-04-14T15:00:00Z,2018-04-14T15:00:00Z,CONTRIBUTOR,simonw/datasette/pulls/207,"This renders unlabeled FKs as simple links. I can't see why this would cause any major problems.

Also includes bonus fixes for two minor issues:
* In foreign key link hrefs the primary key was escaped using HTML escaping rather than URL escaping. This broke some non-integer PKs.
* Print tracebacks to console when handling 500 errors.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/207/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314319372,MDExOlB1bGxSZXF1ZXN0MTgxNjQyMTE0,205,Support filtering with units and more,45057,closed,0,,,3,2018-04-14T10:47:51Z,2018-04-14T15:24:04Z,2018-04-14T15:24:04Z,CONTRIBUTOR,simonw/datasette/pulls/205,"The first commit:
* Adds units to exported JSON
* Adds units key to metadata skeleton
* Adds some docs for units
The second commit adds filtering by units by the first method I mentioned in #203:

[Try it here](https://wtr-api.herokuapp.com/wtr-663ea99/license_frequency?frequency__gt=50GHz&height__lt=50ft). I think it integrates pretty neatly.
The third commit adds support for registering custom units with Pint from metadata.json. Probably pretty niche, but I need decibels!",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/205/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314340944,MDExOlB1bGxSZXF1ZXN0MTgxNjU0ODM5,208,Return HTTP 405 on InvalidUsage rather than 500,45057,closed,0,,,0,2018-04-14T16:12:50Z,2018-04-14T18:00:39Z,2018-04-14T18:00:39Z,CONTRIBUTOR,simonw/datasette/pulls/208,"This also stops it filling up the logs. This happens for HEAD requests at the moment - which perhaps should be handled better, but that's a different issue.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/208/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
314455877,MDExOlB1bGxSZXF1ZXN0MTgxNzIzMzAz,209, Don't duplicate simple primary keys in the link column,45057,closed,0,,,6,2018-04-15T21:56:15Z,2018-04-18T08:40:37Z,2018-04-18T01:13:04Z,CONTRIBUTOR,simonw/datasette/pulls/209,"When there's a simple (single-column) primary key, it looks weird to duplicate it in the link column.
This change removes the second PK column and treats the link column as if it were the PK column from a header/sorting perspective.
This might make it a bit more difficult to tell what the link for the row is, I'm not sure yet. I feel like the alternative is to change the link column to just have the text ""view"" or something, instead of repeating the PK. (I doubt it makes much more sense with compound PKs.)
Bonus change in this PR: fix urlencoding of links in the displayed HTML.
Before:

After:
",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/209/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
316365426,MDExOlB1bGxSZXF1ZXN0MTgzMTM1NjA0,232,Fix a typo,45281,closed,0,,,1,2018-04-20T18:20:04Z,2018-04-21T00:19:08Z,2018-04-21T00:19:08Z,CONTRIBUTOR,simonw/datasette/pulls/232,It looks like this was the only instance of it: https://github.com/simonw/datasette/search?utf8=%E2%9C%93&q=SOLite&type=,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/232/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
341235633,MDExOlB1bGxSZXF1ZXN0MjAxNDUxMzMy,345,Allow app names for `datasette publish heroku`,45057,closed,0,,,1,2018-07-14T13:12:34Z,2018-07-14T14:09:54Z,2018-07-14T14:04:44Z,CONTRIBUTOR,simonw/datasette/pulls/345,"Lets you supply the `-n` parameter for Heroku deploys, which also lets you update existing Heroku deployments.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/345/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
361764460,MDExOlB1bGxSZXF1ZXN0MjE2NjUxMzE3,365,fix small doc typo,418191,closed,0,,,2,2018-09-19T14:02:02Z,2019-12-19T02:30:33Z,2018-09-19T17:15:43Z,CONTRIBUTOR,simonw/datasette/pulls/365,,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/365/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
374675798,MDExOlB1bGxSZXF1ZXN0MjI2MzE0ODYy,367,Mark codemirror files as vendored,48517,closed,0,,,2,2018-10-27T18:41:25Z,2019-05-03T21:12:09Z,2019-05-03T21:11:20Z,CONTRIBUTOR,simonw/datasette/pulls/367,"GitHub lists datasette as a Javascript project, primarily because of the vendored codemirror files. This is somewhat confusing when you're looking for datasette, knowing it's written in Python.
Luckily it's possible exclude certain files from GitHub's code statistics: https://github.com/github/linguist#using-gitattributes",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/367/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
374676773,MDExOlB1bGxSZXF1ZXN0MjI2MzE1NTEz,368,Update installation instructions,48517,closed,0,,,0,2018-10-27T18:52:31Z,2019-05-03T18:18:43Z,2019-05-03T18:18:42Z,CONTRIBUTOR,simonw/datasette/pulls/368,"I was writing this as a response to your tweet, but decided I might just make it a pull request.
I feel like it might be confusing to those unfamiliar with Python's `-m` flag and the built-in `venv` module to omit the space between the flag and its argument. By adding a space and prefixing the second occurrence of `venv` with a `./` it's maybe a bit clearer what the arguments are and what they do.
By also using `python3 -m pip` it becomes even clearer that `-m` is a special flag that makes the python executable do neat things.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/368/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
386459810,MDExOlB1bGxSZXF1ZXN0MjM1MTk0Mjg2,390,tiny typo in customization docs,418191,closed,0,,,1,2018-12-01T13:44:42Z,2019-12-19T02:30:35Z,2018-12-16T21:32:56Z,CONTRIBUTOR,simonw/datasette/pulls/390,was looking to add some custom templates to my use of datasette and saw this small typo.,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/390/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
413887019,MDExOlB1bGxSZXF1ZXN0MjU1NzI1MDU3,413,Update spatialite.rst,28597217,closed,0,,,1,2019-02-25T00:08:35Z,2019-03-15T05:06:45Z,2019-03-15T05:06:45Z,CONTRIBUTOR,simonw/datasette/pulls/413,a line of sql added to create the idx_ in the python recipe,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/413/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
427429265,MDExOlB1bGxSZXF1ZXN0MjY2MDM1Mzgy,424,Column types in inspected metadata,45057,closed,0,,,2,2019-03-31T18:46:33Z,2019-04-29T18:30:50Z,2019-04-29T18:30:46Z,CONTRIBUTOR,simonw/datasette/pulls/424,"This PR does two things:
* Adds the sqlite column type for each column to the inspected table info.
* Stops binary columns from being rendered to HTML, unless a plugin handles it.
There's a bit more detail in the changeset descriptions.
These changes are intended as a precursor to a plugin which adds first-class support for Spatialite geographic primitives, and perhaps more useful geo-stuff.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/424/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
438048318,MDExOlB1bGxSZXF1ZXN0Mjc0MTc0NjE0,437,Add inspect and prepare_sanic hooks,45057,closed,0,,,2,2019-04-28T11:53:34Z,2019-06-24T16:38:57Z,2019-06-24T16:38:56Z,CONTRIBUTOR,simonw/datasette/pulls/437,"This adds two new plugin hooks:
The `inspect` hook allows plugins to add data to the inspect dictionary.
The `prepare_sanic` hook allows plugins to hook into the web router. I've attached a warning to this hook in the docs in light of #272 but I want this hook now...
On quick inspection, I don't think it's worthwhile to try and make this hook independent of the web framework (but it looks like Starlette would make the hook implementation a bit nicer).
Ref #14",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/437/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
438240541,MDExOlB1bGxSZXF1ZXN0Mjc0MzEzNjI1,439,[WIP] Add primary key to the extra_body_script hook arguments,45057,closed,0,,,2,2019-04-29T10:08:23Z,2019-05-01T09:58:32Z,2019-05-01T09:58:30Z,CONTRIBUTOR,simonw/datasette/pulls/439,"This allows the row to be identified on row pages. The context here is that I want to access the row's data to plot it on a map.
I considered passing the entire template context through to the hook function. This would expose the actual row data and potentially avoid a further fetch request in JS, but it does make the plugin API a lot more leaky.
(At any rate, using the selected row data is tricky in my case because of Spatialite's infuriating custom binary representation...)",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/439/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
438437973,MDExOlB1bGxSZXF1ZXN0Mjc0NDY4ODM2,441,Add register_output_renderer hook,45057,closed,0,,,8,2019-04-29T18:03:21Z,2019-05-01T23:01:57Z,2019-05-01T23:01:57Z,CONTRIBUTOR,simonw/datasette/pulls/441,"This changeset refactors out the JSON renderer and then adds a hook and
dispatcher system to allow custom output renderers to be registered.
The CSV output renderer is untouched because supporting streaming
renderers through this system would be significantly more complex, and
probably not worthwhile.
We can't simply allow hooks to be called at request time because we need
a list of supported file extensions when the request is being routed in
order to resolve ambiguous database/table names. So, renderers need to
be registered at startup.
I've tried to make this API independent of Sanic's request/response
objects so that this can remain stable during the switch to ASGI. I'm
using dictionaries to keep it simple and to make adding additional
options in the future easy.
Fixes #440",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/441/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
438450757,MDExOlB1bGxSZXF1ZXN0Mjc0NDc4NzYx,442,Suppress rendering of binary data,45057,closed,0,,,2,2019-04-29T18:36:41Z,2019-05-03T18:26:48Z,2019-05-03T16:44:49Z,CONTRIBUTOR,simonw/datasette/pulls/442,"Binary columns (including spatialite geographies) get shown as ugly
binary strings in the HTML by default. Nobody wants to see that mess.
Show the size of the column in bytes instead. If you want to decode
the binary data, you can use a plugin to do it.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/442/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
439480260,MDExOlB1bGxSZXF1ZXN0Mjc1Mjc1NjEw,443,Pass view_name to extra_body_script hook,45057,closed,0,,,0,2019-05-02T08:38:36Z,2019-05-03T13:12:20Z,2019-05-03T13:12:20Z,CONTRIBUTOR,simonw/datasette/pulls/443,"At the moment it's not easy to tell whether the hook is being called
in (for example) the row or table view, as in both cases the
`database` and `table` parameters are provided.
This passes the `view_name` added in #441 to the `extra_body_script`
hook.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/443/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
439487648,MDExOlB1bGxSZXF1ZXN0Mjc1MjgxMzA3,444,Add a max-line-length setting for flake8,45057,closed,0,,,0,2019-05-02T08:58:57Z,2019-05-04T09:44:48Z,2019-05-03T13:11:28Z,CONTRIBUTOR,simonw/datasette/pulls/444,"This stops my automatic editor linting from flagging lines which are too
long. It's been lingering in my checkout for ages.
160 is an arbitrary large number - we could alter it if we have any
opinions (but I find the line length limit to be my least favourite part
of PEP8).",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/444/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
440304714,MDExOlB1bGxSZXF1ZXN0Mjc1OTA5MTk3,450,Coalesce hidden table count to 0,45057,closed,0,,,2,2019-05-04T09:37:10Z,2019-05-11T18:10:09Z,2019-05-11T18:10:09Z,CONTRIBUTOR,simonw/datasette/pulls/450,"For some reason I'm hitting a `None` here with a FTS table. I'm not
entirely sure why but this makes the logic work the same as with
non-hidden tables.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/450/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
440325850,MDExOlB1bGxSZXF1ZXN0Mjc1OTIzMDY2,452,SQL builder utility classes,45057,open,0,,,0,2019-05-04T13:57:47Z,2019-05-04T14:03:04Z,,CONTRIBUTOR,simonw/datasette/pulls/452,"This adds a straightforward set of classes to aid in the construction of
SQL queries.
My plan for this was to allow plugins to manipulate the
Datasette-generated SQL in a more structured way. I'm not sure that's
going to work, but I feel like this is still a step forward - it
reduces the number of intermediate variables in `TableView.data` which
aids readability, and also factors out a lot of the boring string
concatenation.
There are a fair number of minor structure changes in here too as I've
tried to make the ordering of `TableView.data` a bit more logical. As
far as I can tell, I haven't broken anything...",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/452/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
442402832,MDExOlB1bGxSZXF1ZXN0Mjc3NTI0MDcy,458,setup: add tests to package exclusion,7725188,closed,0,,,1,2019-05-09T19:47:21Z,2020-07-21T01:14:42Z,2019-05-10T01:54:51Z,CONTRIBUTOR,simonw/datasette/pulls/458,"This PR fixes #456 by adding `tests` to the package exclusion list.
Cheers",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/458/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
434321685,MDExOlB1bGxSZXF1ZXN0MjcxMzM4NDA1,434,"""datasette publish cloudrun"" command to publish to Google Cloud Run",10352819,closed,0,,,8,2019-04-17T14:41:18Z,2019-05-03T21:50:44Z,2019-05-03T13:59:02Z,CONTRIBUTOR,simonw/datasette/pulls/434,"This is a very rough draft to start a discussion on a possible datasette cloud run publish plugin (see issue #400).
The main change was to dynamically set the listening port in `make_dockerfile` to satisfy cloud run's [requirements](https://cloud.google.com/run/docs/reference/container-contract).
This was done by running `datasette` through `sh` to get environment variable substitution. Not sure if that's the right approach?
",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/434/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
451705509,MDExOlB1bGxSZXF1ZXN0Mjg0NzQzNzk0,500,Fix typo in install step: should be install -e,32314,closed,0,,,1,2019-06-03T21:50:51Z,2019-06-11T18:48:43Z,2019-06-11T18:48:40Z,CONTRIBUTOR,simonw/datasette/pulls/500,,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/500/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
445873563,MDExOlB1bGxSZXF1ZXN0MjgwMjA0Mjc2,479,doc typo fix,98555,closed,0,,,1,2019-05-19T22:54:25Z,2019-05-20T16:42:29Z,2019-05-20T16:42:29Z,CONTRIBUTOR,simonw/datasette/pulls/479,Fix typo in performance doc page,107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/479/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
445875242,MDExOlB1bGxSZXF1ZXN0MjgwMjA1NTAy,480,Split pypi and docker travis tasks,813732,closed,0,,4471010,1,2019-05-19T23:14:37Z,2019-07-07T20:03:20Z,2019-07-07T20:03:20Z,CONTRIBUTOR,simonw/datasette/pulls/480,"Resolves #478
This *should* work, but because this is a change that'll only really be testable on a) this repo, b) master branch, this might fail fast if I didn't get the configurations right.
Looking at #478 it should just be as simple as splitting out the docker and pypi processes into separate jobs, but it might end up being more complicated than that, depending on what pre-processes the pypi deployment needs, and how travisci treats deployment steps without scripts in general. ",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/480/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
465728430,MDExOlB1bGxSZXF1ZXN0Mjk1NzExNTA0,554,Fix static mounts using relative paths and prevent traversal exploits,3243482,closed,0,,,4,2019-07-09T11:32:02Z,2019-07-11T16:29:26Z,2019-07-11T16:13:19Z,CONTRIBUTOR,simonw/datasette/pulls/554,"While debugging why my static mounts using a relative path (`--static mystatic:rel/path/to/dir`) not working, I noticed that the requests fail no matter what, returning 404 errors.
The reason is that datasette tries to prevent traversal exploits by checking if the path is relative to its registered directory. This check fails when the mount is a relative directory, because `/abs/dir/file` obviously not under `dir/file`.
https://github.com/simonw/datasette/blob/81fa8b6cdc5457b42a224779e5291952314e8d20/datasette/utils/asgi.py#L303-L306
This also has the consequence of returning any requested file, because when `/abs/dir/../../evil.file` resolves `aiofiles` happily returns it to the client after it resolves the path itself. The solution is to make sure we're checking relativity of paths after they're fully resolved.
I've implemented the mentioned changes and also updated the tests.",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/554/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,
465773546,MDExOlB1bGxSZXF1ZXN0Mjk1NzQ4MjY4,556,Add support for running datasette as a module,3243482,closed,0,,,1,2019-07-09T13:13:30Z,2019-07-11T16:07:45Z,2019-07-11T16:07:44Z,CONTRIBUTOR,simonw/datasette/pulls/556,"This PR allows running datasette using `python -m datasette` command in addition to just running the executable.
This function is quite useful when debugging a plugin in a project because IDEs like PyCharm can easily start a debug session when datasette is run as a module in contrast to trying to attach a debugger to a running process.

",107914493,pull,,,"{""url"": ""https://api.github.com/repos/simonw/datasette/issues/556/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",0,