html_url,issue_url,id,node_id,user,created_at,updated_at,author_association,body,reactions,issue,performed_via_github_app
https://github.com/simonw/datasette/issues/394#issuecomment-603849245,https://api.github.com/repos/simonw/datasette/issues/394,603849245,MDEyOklzc3VlQ29tbWVudDYwMzg0OTI0NQ==,132978,2020-03-25T13:48:13Z,2020-03-25T13:48:13Z,NONE,"Great - thanks again.
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",396212021,
https://github.com/simonw/datasette/issues/394#issuecomment-641889565,https://api.github.com/repos/simonw/datasette/issues/394,641889565,MDEyOklzc3VlQ29tbWVudDY0MTg4OTU2NQ==,58298410,2020-06-10T09:49:34Z,2020-06-10T09:49:34Z,NONE,"Hi,
I came across this issue while looking for a way to spawn Datasette as a SQLite files viewer in JupyterLab. I found https://github.com/simonw/jupyterserverproxy-datasette-demo which seems to be the most up to date proof of concept, but it seems to be failing to list the available db (at least in the Binder demo, https://hub.gke.mybinder.org/user/simonw-jupyters--datasette-demo-uw4dmlnn/datasette/, I only have `:memory`).
Does anyone tried to improve on this proof of concept to have a Datasette visualization for SQLite files?
Thanks!","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",396212021,
https://github.com/simonw/datasette/issues/394#issuecomment-642522285,https://api.github.com/repos/simonw/datasette/issues/394,642522285,MDEyOklzc3VlQ29tbWVudDY0MjUyMjI4NQ==,58298410,2020-06-11T09:15:19Z,2020-06-11T09:15:19Z,NONE,"Hi @wragge,
This looks great, thanks for the share! I refactored it into a self-contained function, binding on a random available TCP port (multi-user context). I am using subprocess API directly since the `%run` magic was leaving defunct process behind :/

```python
import socket
from signal import SIGINT
from subprocess import Popen, PIPE
from IPython.display import display, HTML
from notebook.notebookapp import list_running_servers
def get_free_tcp_port():
""""""
Get a free TCP port.
""""""
tcp = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp.bind(('', 0))
_, port = tcp.getsockname()
tcp.close()
return port
def datasette(database):
""""""
Run datasette on an SQLite database.
""""""
# Get current running servers
servers = list_running_servers()
# Get the current base url
base_url = next(servers)['base_url']
# Get a free port
port = get_free_tcp_port()
# Create a base url for Datasette suing the proxy path
proxy_url = f'{base_url}proxy/absolute/{port}/'
# Display a link to Datasette
display(HTML(f'View Datasette (Click on the stop button to close the Datasette server)
'))
# Launch Datasette
with Popen(
[
'python', '-m', 'datasette', '--',
database,
'--port', str(port),
'--config', f'base_url:{proxy_url}'
],
stdout=PIPE,
stderr=PIPE,
bufsize=1,
universal_newlines=True
) as p:
print(p.stdout.readline(), end='')
while True:
try:
line = p.stderr.readline()
if not line:
break
print(line, end='')
exit_code = p.poll()
except KeyboardInterrupt:
p.send_signal(SIGINT)
```
Ideally, I'd like some extra magic to notify users when they are leaving the closing the notebook tab and make them terminate the running datasette processes. I'll be looking for it.","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 1, ""rocket"": 0, ""eyes"": 0}",396212021,
https://github.com/simonw/datasette/issues/401#issuecomment-455520561,https://api.github.com/repos/simonw/datasette/issues/401,455520561,MDEyOklzc3VlQ29tbWVudDQ1NTUyMDU2MQ==,1055831,2019-01-18T11:48:13Z,2019-01-18T11:48:13Z,NONE,"Thanks. I'll take a look at your changes.
I must admit I was struggling to see how to pass info from the python code in __init__.py into the javascript document.addEventListener function.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",400229984,
https://github.com/simonw/datasette/issues/403#issuecomment-455752238,https://api.github.com/repos/simonw/datasette/issues/403,455752238,MDEyOklzc3VlQ29tbWVudDQ1NTc1MjIzOA==,1794527,2019-01-19T05:47:55Z,2019-01-19T05:47:55Z,NONE,Ah. That makes much more sense. Interesting approach.,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",400511206,
https://github.com/simonw/sqlite-utils/issues/8#issuecomment-464341721,https://api.github.com/repos/simonw/sqlite-utils/issues/8,464341721,MDEyOklzc3VlQ29tbWVudDQ2NDM0MTcyMQ==,82988,2019-02-16T12:08:41Z,2019-02-16T12:08:41Z,NONE,We also get an error if a column name contains a `.`,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",403922644,
https://github.com/simonw/sqlite-utils/issues/8#issuecomment-482994231,https://api.github.com/repos/simonw/sqlite-utils/issues/8,482994231,MDEyOklzc3VlQ29tbWVudDQ4Mjk5NDIzMQ==,82988,2019-04-14T15:04:07Z,2019-04-14T15:29:33Z,NONE,"
PLEASE IGNORE THE BELOW... I did a package update and rebuilt the kernel I was working in... may just have been an old version of sqlite_utils, seems to be working now. (Too many containers / too many environments!)
Has an issue been reintroduced here with FTS? eg I'm getting an error thrown by spaces in column names here:
```
/usr/local/lib/python3.7/site-packages/sqlite_utils/db.py in insert_all(self, records, pk, foreign_keys, upsert, batch_size, column_order)
def enable_fts(self, columns, fts_version=""FTS5""):
--> 329 ""Enables FTS on the specified columns""
330 sql = """"""
331 CREATE VIRTUAL TABLE ""{table}_fts"" USING {fts_version} (
```
when trying an `insert_all`.
Also, if a col has a `.` in it, I seem to get:
```
/usr/local/lib/python3.7/site-packages/sqlite_utils/db.py in insert_all(self, records, pk, foreign_keys, upsert, batch_size, column_order)
327 jsonify_if_needed(record.get(key, None)) for key in all_columns
328 )
--> 329 result = self.db.conn.execute(sql, values)
330 self.db.conn.commit()
331 self.last_id = result.lastrowid
OperationalError: near ""."": syntax error
```
(Can't post a worked minimal example right now; racing trying to build something against a live timing screen that will stop until next weekend in an hour or two...)
PS Hmmm I did a test and they seem to work; I must be messing up s/where else...
```
import sqlite3
from sqlite_utils import Database
dbname='testingDB_sqlite_utils.db'
#!rm $dbname
conn = sqlite3.connect(dbname, timeout=10)
#Setup database tables
c = conn.cursor()
setup='''
CREATE TABLE IF NOT EXISTS ""test1"" (
""NO"" INTEGER,
""NAME"" TEXT
);
CREATE TABLE IF NOT EXISTS ""test2"" (
""NO"" INTEGER,
`TIME OF DAY` TEXT
);
CREATE TABLE IF NOT EXISTS ""test3"" (
""NO"" INTEGER,
`AVG. SPEED (MPH)` FLOAT
);
'''
c.executescript(setup)
DB = Database(conn)
import pandas as pd
df1 = pd.DataFrame({'NO':[1,2],'NAME':['a','b']})
DB['test1'].insert_all(df1.to_dict(orient='records'))
df2 = pd.DataFrame({'NO':[1,2],'TIME OF DAY':['early on','late']})
DB['test2'].insert_all(df2.to_dict(orient='records'))
df3 = pd.DataFrame({'NO':[1,2],'AVG. SPEED (MPH)':['123.3','123.4']})
DB['test3'].insert_all(df3.to_dict(orient='records'))
```
all seem to work ok. I'm still getting errors in my set up though, which is not too different to the text cases?","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",403922644,
https://github.com/simonw/datasette/issues/409#issuecomment-472844001,https://api.github.com/repos/simonw/datasette/issues/409,472844001,MDEyOklzc3VlQ29tbWVudDQ3Mjg0NDAwMQ==,43100,2019-03-14T13:04:20Z,2019-03-14T13:04:42Z,NONE,It seems this affects the Datasette Publish -site as well: https://github.com/simonw/datasette-publish-support/issues/3,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",408376825,
https://github.com/simonw/datasette/issues/409#issuecomment-472875713,https://api.github.com/repos/simonw/datasette/issues/409,472875713,MDEyOklzc3VlQ29tbWVudDQ3Mjg3NTcxMw==,209967,2019-03-14T14:14:39Z,2019-03-14T14:14:39Z,NONE,also linking this zeit issue in case it is helpful: https://github.com/zeit/now-examples/issues/163#issuecomment-440125769,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",408376825,
https://github.com/simonw/datasette/issues/411#issuecomment-519065799,https://api.github.com/repos/simonw/datasette/issues/411,519065799,MDEyOklzc3VlQ29tbWVudDUxOTA2NTc5OQ==,1055831,2019-08-07T12:00:36Z,2019-08-07T12:00:36Z,NONE,"Hi,
Apologies for the long delay.
I tried your suggesting escaping approach:
`SELECT a.pos AS rank, b.id, b.name, b.country, b.latitude AS latitude, b.longitude AS longitude, a.distance / 1000.0 AS dist_km FROM KNN AS a LEFT JOIN airports AS b ON (b.rowid = a.fid)WHERE f_table_name = 'airports' AND ref_geometry = MakePoint(:Long || "", "" || :Lat) AND max_items = 6;
`
and it returns this error:
`wrong number of arguments to function MakePoint()`
Anything else you suggest I try?
Thanks","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",410384988,
https://github.com/simonw/datasette/issues/411#issuecomment-1779267468,https://api.github.com/repos/simonw/datasette/issues/411,1779267468,IC_kwDOBm6k_c5qDXeM,363004,2023-10-25T13:23:04Z,2023-10-25T13:23:04Z,NONE,"Using the [Counties example](https://us-counties.datasette.io/counties/county_for_latitude_longitude?longitude=-122&latitude=37), I was able to pull out the MakePoint method as
MakePoint(cast(rm_rnb_history_pres.rx_lng as float), cast(rm_rnb_history_pres.rx_lat as float)) as geometry
which worked, giving me a geometry column.
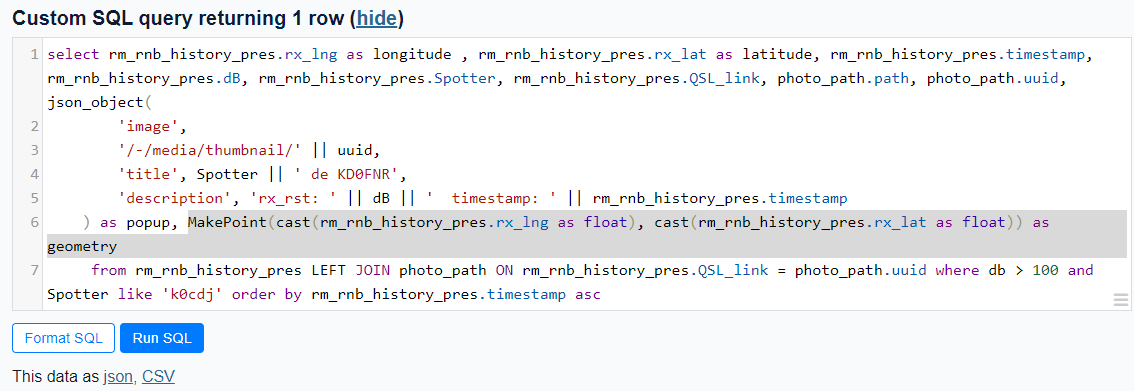
gave
I believe it's the cast to float that does the trick. Prior to using the cast, I also received a 'wrong number of arguments' eror.
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",410384988,
https://github.com/simonw/sqlite-utils/issues/18#issuecomment-480621924,https://api.github.com/repos/simonw/sqlite-utils/issues/18,480621924,MDEyOklzc3VlQ29tbWVudDQ4MDYyMTkyNA==,82988,2019-04-07T19:31:42Z,2019-04-07T19:31:42Z,NONE,"I've just noticed that SQLite lets you IGNORE inserts that collide with a pre-existing key. This can be quite handy if you have a dataset that keeps changing in part, and you don't want to upsert and replace pre-existing PK rows but you do want to ignore collisions to existing PK rows.
Do `sqlite_utils` support such (cavalier!) behaviour?","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",413871266,
https://github.com/simonw/datasette/issues/415#issuecomment-473217334,https://api.github.com/repos/simonw/datasette/issues/415,473217334,MDEyOklzc3VlQ29tbWVudDQ3MzIxNzMzNA==,36796532,2019-03-15T09:30:57Z,2019-03-15T09:30:57Z,NONE,"Awesome, thanks! 😁 ","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",418329842,
https://github.com/simonw/datasette/issues/417#issuecomment-751127384,https://api.github.com/repos/simonw/datasette/issues/417,751127384,MDEyOklzc3VlQ29tbWVudDc1MTEyNzM4NA==,1279360,2020-12-24T22:56:48Z,2020-12-24T22:56:48Z,NONE,"Instead of scanning the directory every 10s, have you considered listening for the native system events to notify you of updates?
I think python has a nice module to do this for you called [watchdog](https://pypi.org/project/watchdog/)","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",421546944,
https://github.com/simonw/datasette/issues/417#issuecomment-751504136,https://api.github.com/repos/simonw/datasette/issues/417,751504136,MDEyOklzc3VlQ29tbWVudDc1MTUwNDEzNg==,212369,2020-12-27T19:02:06Z,2020-12-27T19:02:06Z,NONE,"Very much looking forward to seeing this functionality come together. This is probably out-of-scope for an initial release, but in the future it could be useful to also think of how to run this is a container'ized context. For example, an immutable datasette container that points to an S3 bucket of SQLite DBs or CSVs. Or an immutable datasette container pointing to a NFS volume elsewhere on a Kubernetes cluster.","{""total_count"": 2, ""+1"": 2, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",421546944,
https://github.com/simonw/datasette/pull/426#issuecomment-485557574,https://api.github.com/repos/simonw/datasette/issues/426,485557574,MDEyOklzc3VlQ29tbWVudDQ4NTU1NzU3NA==,222245,2019-04-22T21:23:22Z,2019-04-22T21:23:22Z,NONE,Can you cut a new release with this?,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",431756352,
https://github.com/simonw/datasette/issues/483#issuecomment-495034774,https://api.github.com/repos/simonw/datasette/issues/483,495034774,MDEyOklzc3VlQ29tbWVudDQ5NTAzNDc3NA==,45919695,2019-05-23T01:38:32Z,2019-05-23T01:43:04Z,NONE,"I think that location information is one of the other common pieces of hierarchical data. At least one that is general enough that extra dimensions could be auto-generated.
Also, I think this is an awesome project. Thank you for creating this.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",447408527,
https://github.com/simonw/datasette/issues/496#issuecomment-497885590,https://api.github.com/repos/simonw/datasette/issues/496,497885590,MDEyOklzc3VlQ29tbWVudDQ5Nzg4NTU5MA==,1740337,2019-05-31T23:05:05Z,2019-05-31T23:05:05Z,NONE,"Upon doing a ""fix"" which allowed a longer build timeout the cloudrun container was too slow when it actually ran. So I would say if your sqlite database is over 1 GB heroku and cloudrun are not good options.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",450862577,
https://github.com/simonw/datasette/issues/498#issuecomment-499262397,https://api.github.com/repos/simonw/datasette/issues/498,499262397,MDEyOklzc3VlQ29tbWVudDQ5OTI2MjM5Nw==,7936571,2019-06-05T21:28:32Z,2019-06-05T21:28:32Z,NONE,"Thinking about this more, I'd probably have to make a template page to go along with this, right? I'm guessing there's no way to add an all-databases-all-tables search to datasette's ""home page"" except by copying the ""home page"" template and editing it?","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",451513541,
https://github.com/simonw/datasette/issues/498#issuecomment-501903071,https://api.github.com/repos/simonw/datasette/issues/498,501903071,MDEyOklzc3VlQ29tbWVudDUwMTkwMzA3MQ==,7936571,2019-06-13T22:35:06Z,2019-06-13T22:35:06Z,NONE,"I'd like to start working on this. I've made a custom template for `index.html` that contains a `form` that contains a search `input`. But I'm not sure where to go from here. When user enters a search term, I'd like for that term to go into a function I'll make that will search all tables with full text search enabled.
Can I make additional custom Python scripts for this or must I edit datasette's files directly?","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",451513541,
https://github.com/simonw/datasette/issues/498#issuecomment-504785662,https://api.github.com/repos/simonw/datasette/issues/498,504785662,MDEyOklzc3VlQ29tbWVudDUwNDc4NTY2Mg==,7936571,2019-06-23T20:47:37Z,2019-06-23T20:47:37Z,NONE,"Very cool, thank you.
Using http://search-24ways.herokuapp.com as an example, let's say I want to search all FTS columns in all tables in all databases for the word ""web.""
[Here's a link](http://search-24ways.herokuapp.com/24ways-f8f455f?sql=select+count%28*%29from+articles+where+rowid+in+%28select+rowid+from+articles_fts+where+articles_fts+match+%3Asearch%29&search=web) to the query I'd need to run to search ""web"" on FTS columns in `articles` table of the `24ways` database.
And [here's a link](http://search-24ways.herokuapp.com/24ways-f8f455f.json?sql=select+count%28*%29from+articles+where+rowid+in+%28select+rowid+from+articles_fts+where+articles_fts+match+%3Asearch%29&search=web) to the JSON version of the above result. I'd like to get the JSON result of that query for each FTS table of each database in my datasette project.
Is it possible in Javascript to automate the construction of query URLs like the one I linked, but for every FTS table in my datasette project?","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",451513541,
https://github.com/simonw/datasette/issues/498#issuecomment-505228873,https://api.github.com/repos/simonw/datasette/issues/498,505228873,MDEyOklzc3VlQ29tbWVudDUwNTIyODg3Mw==,7936571,2019-06-25T00:21:17Z,2019-06-25T00:21:17Z,NONE,"Eh, I'm not concerned with a relevance score right now. I think I'd be fine with a search whose results show links to data tables with at least one result.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",451513541,
https://github.com/simonw/datasette/issues/498#issuecomment-506985050,https://api.github.com/repos/simonw/datasette/issues/498,506985050,MDEyOklzc3VlQ29tbWVudDUwNjk4NTA1MA==,7936571,2019-06-29T20:28:21Z,2019-06-29T20:28:21Z,NONE,"In my case, I have an ever-growing number of databases and tables within them. Most tables have FTS enabled. I cannot predict the names of future tables and databases, nor can I predict the names of the columns for which I wish to enable FTS.
For my purposes, I was thinking of writing up something that sends these two GET requests to each of my databases' tables.
```
http://my-server.com/database-name/table-name.json?_search=mySearchString
http://my-server.com/database-name/table-name.json
```
In the resulting JSON strings, I'd check the value of the key `filtered_table_rows_count`. If the value is `0` in the first URL's result, or if values from both requests are the same, that means FTS is either disabled for the table or it has no rows matching the search query.
Is this feasible within the datasette library, or would it require some type of plugin? Or maybe you know of a better way of accomplishing this goal. Maybe I overlooked something.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",451513541,
https://github.com/simonw/datasette/issues/498#issuecomment-508590397,https://api.github.com/repos/simonw/datasette/issues/498,508590397,MDEyOklzc3VlQ29tbWVudDUwODU5MDM5Nw==,7936571,2019-07-04T23:34:41Z,2019-07-04T23:34:41Z,NONE,I'll take your suggestion and do this all in Javascript. Would I need to make a `static/` folder in my datasette project's root directory and make a custom `index.html` template that pulls from `static/js/search-all-fts.js`? Or would you suggest another way?,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",451513541,
https://github.com/simonw/datasette/issues/498#issuecomment-509042334,https://api.github.com/repos/simonw/datasette/issues/498,509042334,MDEyOklzc3VlQ29tbWVudDUwOTA0MjMzNA==,7936571,2019-07-08T00:18:29Z,2019-07-08T00:18:29Z,NONE,@simonw I made this primitive search that I've put in my Datasette project's custom templates directory: https://gist.github.com/chrismp/e064b41f08208a6f9a93150a23cf7e03,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",451513541,
https://github.com/simonw/datasette/issues/499#issuecomment-499260727,https://api.github.com/repos/simonw/datasette/issues/499,499260727,MDEyOklzc3VlQ29tbWVudDQ5OTI2MDcyNw==,7936571,2019-06-05T21:22:55Z,2019-06-05T21:22:55Z,NONE,"I was thinking of having some kind of GUI in which regular reporters can upload a CSV and choose how to name the tables, columns and whatnot. Maybe it's possible to make such a GUI using Jinja template language? I ask because I'm unsure how to pursue this but I'd like to try. ","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",451585764,
https://github.com/simonw/datasette/issues/502#issuecomment-503237884,https://api.github.com/repos/simonw/datasette/issues/502,503237884,MDEyOklzc3VlQ29tbWVudDUwMzIzNzg4NA==,7936571,2019-06-18T17:39:18Z,2019-06-18T17:46:08Z,NONE,It appears that I cannot reopen this issue but the proposed solution did not solve it. The link is not there. I have full text search enabled for a bunch of tables in my database and even clicking the link to reveal hidden tables did not show the download DB link.,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",453131917,
https://github.com/simonw/datasette/issues/506#issuecomment-500238035,https://api.github.com/repos/simonw/datasette/issues/506,500238035,MDEyOklzc3VlQ29tbWVudDUwMDIzODAzNQ==,1059677,2019-06-09T19:21:18Z,2019-06-09T19:21:18Z,NONE,"If you don't mind calling out to Java, then Apache Tika is able to tell you what a load of ""binary stuff"" is, plus render it to XHTML where possible.
There's a python wrapper around the Apache Tika server, but for a more typical datasette usecase you'd probably just want to grab the Tika CLI jar, and call it with `--detect` and/or `--xhtml` to process the unknown binary blob","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",453846217,
https://github.com/simonw/sqlite-utils/issues/26#issuecomment-1141711418,https://api.github.com/repos/simonw/sqlite-utils/issues/26,1141711418,IC_kwDOCGYnMM5EDSI6,19304,2022-05-31T06:21:15Z,2022-05-31T06:21:15Z,NONE,"I ran into this. My use case has a JSON file with array of `book` objects with a key called `reviews` which is also an array of objects. My JSON is human-edited and does not specify IDs for either books or reviews. Because sqlite-utils does not support inserting nested objects, I instead have to maintain two separate CSV files with `id` column in `books.csv` and `book_id` column in reviews.csv.
I think the right way to declare the relationship while inserting a JSON might be to describe the relationship:
`sqlite-utils insert data.db books mydata.json --hasmany reviews --hasone author --manytomany tags`
This is relying on the assumption that foreign keys can point to `rowid` primary key.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",455486286,
https://github.com/simonw/sqlite-utils/issues/26#issuecomment-1170595021,https://api.github.com/repos/simonw/sqlite-utils/issues/26,1170595021,IC_kwDOCGYnMM5FxdzN,60892516,2022-06-29T23:35:29Z,2022-06-29T23:35:29Z,NONE,"Have you seen [MakeTypes](https://github.com/jvilk/MakeTypes)? Not the exact same thing but it may be relevant.
And it's inspired by the paper [""Types from Data: Making Structured Data First-Class Citizens in F#""](https://dl.acm.org/citation.cfm?id=2908115).","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",455486286,
https://github.com/simonw/datasette/issues/511#issuecomment-730893729,https://api.github.com/repos/simonw/datasette/issues/511,730893729,MDEyOklzc3VlQ29tbWVudDczMDg5MzcyOQ==,4060506,2020-11-20T06:35:13Z,2020-11-20T06:35:13Z,NONE,"Trying to run on Windows today, I get an error from the utils/asgi.py module.
It's trying `from os import EX_CANTCREAT` which is Unix-only. I commented this line out, and (so far) it's working. ","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",456578474,
https://github.com/simonw/datasette/issues/512#issuecomment-503236800,https://api.github.com/repos/simonw/datasette/issues/512,503236800,MDEyOklzc3VlQ29tbWVudDUwMzIzNjgwMA==,7936571,2019-06-18T17:36:37Z,2019-06-18T17:36:37Z,NONE,Oh I didn't know the `description` field could be used for a database's metadata. ,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",457147936,
https://github.com/simonw/datasette/issues/513#issuecomment-503249999,https://api.github.com/repos/simonw/datasette/issues/513,503249999,MDEyOklzc3VlQ29tbWVudDUwMzI0OTk5OQ==,7936571,2019-06-18T18:11:36Z,2019-06-18T18:11:36Z,NONE,"Ah, so basically put the SQLite databases on Linode, for example, and run `datasette serve` on there? I'm comfortable with that. ","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",457201907,
https://github.com/simonw/datasette/issues/514#issuecomment-504684709,https://api.github.com/repos/simonw/datasette/issues/514,504684709,MDEyOklzc3VlQ29tbWVudDUwNDY4NDcwOQ==,7936571,2019-06-22T17:36:25Z,2019-06-22T17:36:25Z,NONE,"> WorkingDirectory=/path/to/data
@russss, Which directory does this represent?","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459397625,
https://github.com/simonw/datasette/issues/514#issuecomment-504685187,https://api.github.com/repos/simonw/datasette/issues/514,504685187,MDEyOklzc3VlQ29tbWVudDUwNDY4NTE4Nw==,7936571,2019-06-22T17:43:24Z,2019-06-22T17:43:24Z,NONE,"> > > WorkingDirectory=/path/to/data
> >
> >
> > @russss, Which directory does this represent?
>
> It's the working directory (cwd) of the spawned process. In this case if you set it to the directory your data is in, you can use relative paths to the db (and metadata/templates/etc) in the `ExecStart` command.
In my case, on a remote server, I set up a virtual environment in `/home/chris/Env/datasette`, and when I activated that environment I ran `pip install datasette`.
My datasette project is in `/home/chris/datatsette-project`, so I guess I'd use that directory in the `WorkingDirectory` parameter?
And the `ExecStart` parameter would be `/home/chris/Env/datasette/lib/python3.7/site-packages/datasette serve -h 0.0.0.0 my.db` I'm guessing?
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459397625,
https://github.com/simonw/datasette/issues/514#issuecomment-504686266,https://api.github.com/repos/simonw/datasette/issues/514,504686266,MDEyOklzc3VlQ29tbWVudDUwNDY4NjI2Ng==,7936571,2019-06-22T17:58:50Z,2019-06-23T21:21:57Z,NONE,"@russss
Actually, here's what I've got in `/etc/systemd/system/datasette.service`
```
[Unit]
Description=Datasette
After=network.target
[Service]
Type=simple
User=chris
WorkingDirectory=/home/chris/digital-library
ExecStart=/home/chris/Env/datasette/lib/python3.7/site-packages/datasette serve -h 0.0.0.0 databases/*.db --cors --metadata metadata.json
Restart=on-failure
[Install]
WantedBy=multi-user.target
```
I ran:
```
$ sudo systemctl daemon-reload
$ sudo systemctl enable datasette
$ sudo systemctl start datasette
```
Then I ran:
`$ journalctl -u datasette -f`
Got this message.
```
Hint: You are currently not seeing messages from other users and the system.
Users in groups 'adm', 'systemd-journal', 'wheel' can see all messages.
Pass -q to turn off this notice.
-- Logs begin at Thu 2019-06-20 00:05:23 CEST. --
Jun 22 19:55:57 ns331247 systemd[16176]: datasette.service: Failed to execute command: Permission denied
Jun 22 19:55:57 ns331247 systemd[16176]: datasette.service: Failed at step EXEC spawning /home/chris/Env/datasette/lib/python3.7/site-packages/datasette: Permission denied
Jun 22 19:55:57 ns331247 systemd[16184]: datasette.service: Failed to execute command: Permission denied
Jun 22 19:55:57 ns331247 systemd[16184]: datasette.service: Failed at step EXEC spawning /home/chris/Env/datasette/lib/python3.7/site-packages/datasette: Permission denied
Jun 22 19:55:58 ns331247 systemd[16186]: datasette.service: Failed to execute command: Permission denied
Jun 22 19:55:58 ns331247 systemd[16186]: datasette.service: Failed at step EXEC spawning /home/chris/Env/datasette/lib/python3.7/site-packages/datasette: Permission denied
Jun 22 19:55:58 ns331247 systemd[16190]: datasette.service: Failed to execute command: Permission denied
Jun 22 19:55:58 ns331247 systemd[16190]: datasette.service: Failed at step EXEC spawning /home/chris/Env/datasette/lib/python3.7/site-packages/datasette: Permission denied
Jun 22 19:55:58 ns331247 systemd[16191]: datasette.service: Failed to execute command: Permission denied
Jun 22 19:55:58 ns331247 systemd[16191]: datasette.service: Failed at step EXEC spawning /home/chris/Env/datasette/lib/python3.7/site-packages/datasette: Permission denied
```
When I go to the address for my server, I am met with the standard ""Welcome to nginx"" message:
```
Welcome to nginx!
If you see this page, the nginx web server is successfully installed and working. Further configuration is required.
For online documentation and support please refer to nginx.org.
Commercial support is available at nginx.com.
Thank you for using nginx.
```","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459397625,
https://github.com/simonw/datasette/issues/514#issuecomment-504789231,https://api.github.com/repos/simonw/datasette/issues/514,504789231,MDEyOklzc3VlQ29tbWVudDUwNDc4OTIzMQ==,7936571,2019-06-23T21:35:33Z,2019-06-23T21:35:33Z,NONE,"@russss
Thanks, just one more thing.
I edited `datasette.service`:
```
[Unit]
Description=Datasette
After=network.target
[Service]
Type=simple
User=chris
WorkingDirectory=/home/chris/digital-library
ExecStart=/home/chris/Env/datasette/bin/datasette serve -h 0.0.0.0 databases/*.db --cors --metadata metadata.json
Restart=on-failure
[Install]
WantedBy=multi-user.target
```
Then ran:
```
$ sudo systemctl daemon-reload
$ sudo systemctl enable datasette
$ sudo systemctl start datasette
```
But the logs from `journalctl` show this datasette error:
```
Jun 23 23:31:41 ns331247 datasette[1771]: Error: Invalid value for ""[FILES]..."": Path ""databases/*.db"" does not exist.
Jun 23 23:31:44 ns331247 datasette[1778]: Usage: datasette serve [OPTIONS] [FILES]...
Jun 23 23:31:44 ns331247 datasette[1778]: Try ""datasette serve --help"" for help.
```
But the `databases` directory does exist in the directory specified by `WorkingDirectory`. Is this a datasette problem or did I write something incorrectly in the `.service` file?
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459397625,
https://github.com/simonw/datasette/issues/514#issuecomment-504998302,https://api.github.com/repos/simonw/datasette/issues/514,504998302,MDEyOklzc3VlQ29tbWVudDUwNDk5ODMwMg==,7936571,2019-06-24T12:57:19Z,2019-06-24T12:57:19Z,NONE,"Same error when I used the full path.
On Sun, Jun 23, 2019 at 18:31 Simon Willison
wrote:
> I suggest trying a full path in ExecStart like this:
>
> ExecStart=/home/chris/Env/datasette/bin/datasette serve -h 0.0.0.0
> /home/chris/digital-library/databases/*.db --cors --metadata metadata.json
>
> That should eliminate the chance of some kind of path confusion.
>
> —
> You are receiving this because you authored the thread.
> Reply to this email directly, view it on GitHub
> ,
> or mute the thread
>
> .
>
--
*Chris Persaud*
ChrisPersaud.com
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459397625,
https://github.com/simonw/datasette/issues/514#issuecomment-505232675,https://api.github.com/repos/simonw/datasette/issues/514,505232675,MDEyOklzc3VlQ29tbWVudDUwNTIzMjY3NQ==,7936571,2019-06-25T00:43:12Z,2019-06-25T00:43:12Z,NONE,"Yep, that worked to get the site up and running at `my-server.com:8000` but when I edited `run-datasette.sh` to contain this...
```
#!/bin/bash
/home/chris/Env/datasette/bin/datasette serve -h 0.0.0.0 -p 80 /home/chris/digital-library/databases/*.db --cors --metadata /home/chris/digital-library/metadata.json
```
I got this error.
```
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: [2019-06-25 02:42:41 +0200] [752] [INFO] Goin' Fast @ http://0.0.0.0:80
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: [2019-06-25 02:42:41 +0200] [752] [ERROR] Unable to start server
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: Traceback (most recent call last):
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: File ""uvloop/loop.pyx"", line 1111, in uvloop.loop.Loop._create_server
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: File ""uvloop/handles/tcp.pyx"", line 89, in uvloop.loop.TCPServer.bind
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: File ""uvloop/handles/streamserver.pyx"", line 95, in uvloop.loop.UVStreamServer._fatal_error
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: File ""uvloop/handles/tcp.pyx"", line 87, in uvloop.loop.TCPServer.bind
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: File ""uvloop/handles/tcp.pyx"", line 26, in uvloop.loop.__tcp_bind
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: PermissionError: [Errno 13] Permission denied
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: During handling of the above exception, another exception occurred:
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: Traceback (most recent call last):
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: File ""/home/chris/Env/datasette/lib/python3.7/site-packages/sanic/server.py"", line 591, in serve
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: http_server = loop.run_until_complete(server_coroutine)
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: File ""uvloop/loop.pyx"", line 1451, in uvloop.loop.Loop.run_until_complete
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: File ""uvloop/loop.pyx"", line 1684, in create_server
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: File ""uvloop/loop.pyx"", line 1116, in uvloop.loop.Loop._create_server
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: PermissionError: [Errno 13] error while attempting to bind on address ('0.0.0.0', 80): permission denied
Jun 25 02:42:41 ns331247 run-datasette.sh[747]: [2019-06-25 02:42:41 +0200] [752] [INFO] Server Stopped
```
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459397625,
https://github.com/simonw/datasette/issues/514#issuecomment-509154312,https://api.github.com/repos/simonw/datasette/issues/514,509154312,MDEyOklzc3VlQ29tbWVudDUwOTE1NDMxMg==,4363711,2019-07-08T09:36:25Z,2019-07-08T09:40:33Z,NONE,"@chrismp: Ports 1024 and under are privileged and can usually only be bound by a root or supervisor user, so it makes sense if you're running as the user `chris` that port 8000 works but 80 doesn't.
See [this generic question-and-answer](https://superuser.com/questions/710253/allow-non-root-process-to-bind-to-port-80-and-443) and [this systemd question-and-answer](https://stackoverflow.com/questions/40865775/linux-systemd-service-on-port-80) for more information about ways to skin this cat. Without knowing your specific circumstances, either extending those privileges to that service/executable/user, proxying them through something like nginx or indeed looking at what the nginx systemd job has to do to listen at port 80 all sound like good ways to start.
At this point, this is more generic systemd/Linux support than a Datasette issue, which is why a complete rando like me is able to contribute anything. ","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459397625,
https://github.com/simonw/datasette/issues/514#issuecomment-509431603,https://api.github.com/repos/simonw/datasette/issues/514,509431603,MDEyOklzc3VlQ29tbWVudDUwOTQzMTYwMw==,7936571,2019-07-08T23:39:52Z,2019-07-08T23:39:52Z,NONE,"In `datasette.service`, I edited
```
User=chris
```
To...
```
User=root
```
It worked. I can access `http://my-server.com`. I hope this is safe. Thanks for all the help, everyone.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459397625,
https://github.com/simonw/datasette/issues/514#issuecomment-539721880,https://api.github.com/repos/simonw/datasette/issues/514,539721880,MDEyOklzc3VlQ29tbWVudDUzOTcyMTg4MA==,319156,2019-10-08T22:00:03Z,2019-10-08T22:00:03Z,NONE,"If you are just using Nginx to open a reserved port, systemd can do that on its own. https://www.freedesktop.org/software/systemd/man/systemd.socket.html. ","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459397625,
https://github.com/simonw/datasette/issues/522#issuecomment-506000023,https://api.github.com/repos/simonw/datasette/issues/522,506000023,MDEyOklzc3VlQ29tbWVudDUwNjAwMDAyMw==,1383872,2019-06-26T18:48:53Z,2019-06-26T18:48:53Z,NONE,Reference implementation from Requests: https://github.com/kennethreitz/requests/blob/3.0/requests/structures.py#L14,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459622390,
https://github.com/simonw/datasette/issues/526#issuecomment-810943882,https://api.github.com/repos/simonw/datasette/issues/526,810943882,MDEyOklzc3VlQ29tbWVudDgxMDk0Mzg4Mg==,701,2021-03-31T10:03:55Z,2021-03-31T10:03:55Z,NONE,"+1 on using nested queries to achieve this! Would be great as streaming CSV is an amazing feature.
Some UX/DX details:
I was expecting it to work to simply add `&_stream=on` to custom SQL queries because the docs say
> Any Datasette table, view or **custom SQL query** can be exported as CSV.
After a bit of testing back and forth I realized streaming only works for full tables.
Would love this feature because I'm using `pandas.read_csv` to paint graphs from custom queries and the graphs are cut off because of the 1000 row limit. ","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459882902,
https://github.com/simonw/datasette/pull/529#issuecomment-505424665,https://api.github.com/repos/simonw/datasette/issues/529,505424665,MDEyOklzc3VlQ29tbWVudDUwNTQyNDY2NQ==,1383872,2019-06-25T12:35:07Z,2019-06-25T12:35:07Z,NONE,"Opps, wrote this late last night, didn't see you'd already worked on the issue.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",460396952,
https://github.com/simonw/datasette/issues/537#issuecomment-512126748,https://api.github.com/repos/simonw/datasette/issues/537,512126748,MDEyOklzc3VlQ29tbWVudDUxMjEyNjc0OA==,14834132,2019-07-17T06:48:35Z,2019-07-17T06:48:35Z,NONE,"It looks as if the `datasette.utils.AsgiRouter.__call__` is the place to add this https://github.com/simonw/datasette/blob/90d4f497f9b3f6a5882937c91fddb496ac3e7368/datasette/utils/asgi.py#L101 .
The sentry_asgi middleware uses the `__qualname__` or `__name__` attributes of the `endpoint` https://github.com/encode/sentry-asgi/blob/c6a42d44d31f85885b79e4ee898683ecf8104971/sentry_asgi/middleware.py#L84
Looking at the Starlette implementation `endpoint` is a `Callable` https://github.com/encode/starlette/commit/34d0097feb6f057bd050d5057df5a2f96b97384e#diff-34fba745b50527bfb4245d02afd59246R100 which as far as I can tell is analogous to the `view` function which is matched here https://github.com/simonw/datasette/blob/90d4f497f9b3f6a5882937c91fddb496ac3e7368/datasette/utils/asgi.py#L96 .
A slight issue is that `__qualname__` is matched *first* in the sentry_asgi middleware, and `__name__` is used if that doesn't exist. I think (please correct me if I am wrong) that for datasette, the `__name__` is what should be used. For example, when using the development fixtures and hitting `http://127.0.0.1:8001/fixtures/compound_three_primary_keys` the `view` function that is matched gives:
```python
>>> view.__qualname__
'AsgiView.as_asgi..view'
>>> view.__name__
'TableView'
```
Would `TableView` be the desired value here? Or am I looking in entirely the wrong place? :smile:
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",463544206,
https://github.com/simonw/datasette/issues/537#issuecomment-512930353,https://api.github.com/repos/simonw/datasette/issues/537,512930353,MDEyOklzc3VlQ29tbWVudDUxMjkzMDM1Mw==,14834132,2019-07-18T18:20:53Z,2019-07-18T18:34:03Z,NONE,"Ok great, getting the `__qualname__` to be `TableView` and adding `endpoint` to the `scope` in `AsgiRouter` is simple enough (already done). However, (unless I'm missing a plugin hook or something) the suggestion of utilising it within a `datasette-sentry` plugin may not work. The only hook that would have access to the `scope` is the `asgi_wrapper` hook. But as this _wraps_ the existing `asgi` app, the `endpoint` won't yet have been added to the `scope` received by the hook https://github.com/SteadBytes/datasette/blob/107d47567dedd472eebec7f35bc34f5b58285ba8/datasette/app.py#L672 . However, I'm not sure where else the `endpoint` could be added to the asgi scope :thinking:
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",463544206,
https://github.com/simonw/datasette/issues/537#issuecomment-513279397,https://api.github.com/repos/simonw/datasette/issues/537,513279397,MDEyOklzc3VlQ29tbWVudDUxMzI3OTM5Nw==,647359,2019-07-19T15:47:57Z,2019-07-19T15:48:09Z,NONE,"The middleware implementation there works okay with a router nested inside if the scope is *mutated*. (Ie. ""endpoint"" doesn't need to exist at the point that the middleware starts running, but if it *has* been made available by the time an exception is thrown, then it can be used.)
Starlette's usage of ""endpoint"" there is unilateral, rather than something I've discussed against the ASGI spec - certainly it's important for any monitoring ASGI middleware to be able to have some kind of visibility onto some limited subset of routing information, and `""endpoint""` in the scope referencing some routed-to callable seemed general enough to be useful.
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",463544206,
https://github.com/simonw/datasette/issues/537#issuecomment-513439736,https://api.github.com/repos/simonw/datasette/issues/537,513439736,MDEyOklzc3VlQ29tbWVudDUxMzQzOTczNg==,14834132,2019-07-20T06:05:01Z,2019-07-20T06:05:01Z,NONE,The asgi spec doesn't explicitly specify (at least as far as I can tell) whether the scope is immutable/mutable https://asgi.readthedocs.io/en/latest/specs/lifespan.html#scope . @simonw using a header for this would be a nice approach. It would also potentially increase the portability of any middleware/plugins/clients across different applications/frameworks as it's not tied directly to an asgi implementation,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",463544206,
https://github.com/simonw/datasette/issues/537#issuecomment-513442743,https://api.github.com/repos/simonw/datasette/issues/537,513442743,MDEyOklzc3VlQ29tbWVudDUxMzQ0Mjc0Mw==,647359,2019-07-20T06:50:47Z,2019-07-20T06:50:47Z,NONE,"Right now the spec does say “copy the scope, rather than mutate it” https://asgi.readthedocs.io/en/latest/specs/main.html#middleware
I wouldn’t be surprised if that there’s room for discussion on evolving the exact language there.
There’s obvs a nice element to the strictness there, tho practically I’m not sure it’s something that implementations will follow, and its not something that Starlette chooses to abide by.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",463544206,
https://github.com/simonw/datasette/issues/537#issuecomment-513446227,https://api.github.com/repos/simonw/datasette/issues/537,513446227,MDEyOklzc3VlQ29tbWVudDUxMzQ0NjIyNw==,14834132,2019-07-20T07:50:44Z,2019-07-20T07:50:44Z,NONE,"Oh yes well spotted thank you 😁
I agree that the strictness would be nice as it could help to avoid different middleware altering the scope in incompatible ways. However I do also agree that it's likely for not all implementations to follow 🤔","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",463544206,
https://github.com/simonw/datasette/issues/537#issuecomment-513652597,https://api.github.com/repos/simonw/datasette/issues/537,513652597,MDEyOklzc3VlQ29tbWVudDUxMzY1MjU5Nw==,14834132,2019-07-22T06:03:18Z,2019-07-22T06:03:18Z,NONE,"@simonw do you think it is still worth populating the `endpoint` key in the scope as originally intended by this issue, or should we hold off until a decision about possibly using an `X-Endpoint` header instead? :smile: ","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",463544206,
https://github.com/simonw/datasette/issues/558#issuecomment-511252718,https://api.github.com/repos/simonw/datasette/issues/558,511252718,MDEyOklzc3VlQ29tbWVudDUxMTI1MjcxOA==,380586,2019-07-15T01:29:29Z,2019-07-15T01:29:29Z,NONE,"Thanks, the latest version works.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",467218270,
https://github.com/simonw/sqlite-utils/issues/46#issuecomment-592999503,https://api.github.com/repos/simonw/sqlite-utils/issues/46,592999503,MDEyOklzc3VlQ29tbWVudDU5Mjk5OTUwMw==,35075,2020-02-29T22:08:20Z,2020-02-29T22:08:20Z,NONE,"@simonw any thoughts on allow extracts to specify the lookup column name? If I'm understanding the documentation right, `.lookup()` allows you to define the ""value"" column (the documentation uses name), but when you use `extracts` keyword as part of `.insert()`, `.upsert()` etc. the lookup must be done against a column named ""value"". I have an existing lookup table that I've populated with columns ""id"" and ""name"" as opposed to ""id"" and ""value"", and seems I can't use `extracts=`, unless I'm missing something...
Initial thought on how to do this would be to allow the dictionary value to be a tuple of table name column pair... so:
```
table = db.table(""trees"", extracts={""species_id"": (""Species"", ""name""})
```
I haven't dug too much into the existing code yet, but does this make sense? Worth doing?
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",471780443,
https://github.com/dogsheep/healthkit-to-sqlite/issues/9#issuecomment-514745798,https://api.github.com/repos/dogsheep/healthkit-to-sqlite/issues/9,514745798,MDEyOklzc3VlQ29tbWVudDUxNDc0NTc5OA==,166463,2019-07-24T18:25:36Z,2019-07-24T18:25:36Z,NONE,"This is on macOS 10.14.6, with Python 3.7.4, packages in the virtual environment:
```
Package Version
------------------- -------
aiofiles 0.4.0
Click 7.0
click-default-group 1.2.1
datasette 0.29.2
h11 0.8.1
healthkit-to-sqlite 0.3.1
httptools 0.0.13
hupper 1.8.1
importlib-metadata 0.18
Jinja2 2.10.1
MarkupSafe 1.1.1
Pint 0.8.1
pip 19.2.1
pluggy 0.12.0
setuptools 41.0.1
sqlite-utils 1.7
tabulate 0.8.3
uvicorn 0.8.4
uvloop 0.12.2
websockets 7.0
zipp 0.5.2
```","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",472429048,
https://github.com/dogsheep/healthkit-to-sqlite/issues/9#issuecomment-515370687,https://api.github.com/repos/dogsheep/healthkit-to-sqlite/issues/9,515370687,MDEyOklzc3VlQ29tbWVudDUxNTM3MDY4Nw==,166463,2019-07-26T09:01:19Z,2019-07-26T09:01:19Z,NONE,"Yes, that did fix the issue I was seeing — it will now import my complete HealthKit data.
Thorsten
> On Jul 25, 2019, at 23:07, Simon Willison wrote:
>
> @tholo this should be fixed in just-released version 0.3.2 - could you run a pip install -U healthkit-to-sqlite and let me know if it works for you now?
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub , or mute the thread .
>
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",472429048,
https://github.com/simonw/datasette/issues/566#issuecomment-517936126,https://api.github.com/repos/simonw/datasette/issues/566,517936126,MDEyOklzc3VlQ29tbWVudDUxNzkzNjEyNg==,8330931,2019-08-03T16:13:36Z,2019-08-03T16:13:36Z,NONE,This example now works on my other machine when running from the anaconda prompt. So I'm not sure if this is actually a datasette issue or not.,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",476437213,
https://github.com/simonw/datasette/issues/567#issuecomment-540545863,https://api.github.com/repos/simonw/datasette/issues/567,540545863,MDEyOklzc3VlQ29tbWVudDU0MDU0NTg2Mw==,2181410,2019-10-10T12:20:29Z,2019-10-10T12:20:29Z,NONE,"Hi Simon. Is there somewhere to read about its ability to run against read-only databases that are able to be modified by other processes? While we're waiting for ""Datasette Edit"" :)","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",476573875,
https://github.com/simonw/sqlite-utils/issues/54#issuecomment-524300388,https://api.github.com/repos/simonw/sqlite-utils/issues/54,524300388,MDEyOklzc3VlQ29tbWVudDUyNDMwMDM4OA==,20264,2019-08-23T12:41:09Z,2019-08-23T12:41:09Z,NONE,Extremely cool and easy to understand. Thank you!,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",480961330,
https://github.com/dogsheep/genome-to-sqlite/issues/1#issuecomment-765495861,https://api.github.com/repos/dogsheep/genome-to-sqlite/issues/1,765495861,MDEyOklzc3VlQ29tbWVudDc2NTQ5NTg2MQ==,25372415,2021-01-22T15:44:00Z,2021-01-22T15:44:00Z,NONE,"Risk of autoimmune disorders: https://www.snpedia.com/index.php/Genotype
```
select rsid, genotype, case genotype
when 'AA' then '2x risk of rheumatoid arthritis and other autoimmune diseases'
when 'GG' then 'Normal risk for autoimmune disorders'
end as interpretation from genome where rsid = 'rs2476601'
```","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",496415321,
https://github.com/dogsheep/genome-to-sqlite/issues/1#issuecomment-765498984,https://api.github.com/repos/dogsheep/genome-to-sqlite/issues/1,765498984,MDEyOklzc3VlQ29tbWVudDc2NTQ5ODk4NA==,25372415,2021-01-22T15:48:25Z,2021-01-22T15:49:33Z,NONE,"The ""Warrior Gene"" https://www.snpedia.com/index.php/Rs4680
```
select rsid, genotype, case genotype
when 'AA' then '(worrier) advantage in memory and attention tasks'
when 'AG' then 'Intermediate dopamine levels, other effects'
when 'GG' then '(warrior) multiple associations, see details'
end as interpretation from genome where rsid = 'rs4680'
```
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",496415321,
https://github.com/dogsheep/genome-to-sqlite/issues/1#issuecomment-765502845,https://api.github.com/repos/dogsheep/genome-to-sqlite/issues/1,765502845,MDEyOklzc3VlQ29tbWVudDc2NTUwMjg0NQ==,25372415,2021-01-22T15:53:19Z,2021-01-22T15:53:19Z,NONE,"rs7903146 Influences risk of Type-2 diabetes
https://www.snpedia.com/index.php/Rs7903146
```
select rsid, genotype, case genotype
when 'CC' then 'Normal (lower) risk of Type 2 Diabetes and Gestational Diabetes.'
when 'CT' then '1.4x increased risk for diabetes (and perhaps colon cancer).'
when 'TT' then '2x increased risk for Type-2 diabetes'
end as interpretation from genome where rsid = 'rs7903146'
```","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",496415321,
https://github.com/dogsheep/genome-to-sqlite/issues/1#issuecomment-765506901,https://api.github.com/repos/dogsheep/genome-to-sqlite/issues/1,765506901,MDEyOklzc3VlQ29tbWVudDc2NTUwNjkwMQ==,25372415,2021-01-22T15:58:41Z,2021-01-22T15:58:58Z,NONE,"Both rs10757274 and rs2383206 can both indicate higher risks of heart disease
https://www.snpedia.com/index.php/Rs2383206
```
select rsid, genotype, case genotype
when 'AA' then 'Normal'
when 'AG' then '~1.2x increased risk for heart disease'
when 'GG' then '~1.3x increased risk for heart disease'
end as interpretation from genome where rsid = 'rs10757274'
```
```
select rsid, genotype, case genotype
when 'AA' then 'Normal'
when 'AG' then '1.4x increased risk for heart disease'
when 'GG' then '1.7x increased risk for heart disease'
end as interpretation from genome where rsid = 'rs2383206'
```","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",496415321,
https://github.com/dogsheep/genome-to-sqlite/issues/1#issuecomment-765523517,https://api.github.com/repos/dogsheep/genome-to-sqlite/issues/1,765523517,MDEyOklzc3VlQ29tbWVudDc2NTUyMzUxNw==,25372415,2021-01-22T16:20:25Z,2021-01-22T16:20:25Z,NONE,"rs53576: the oxytocin receptor (OXTR) gene
```
select rsid, genotype, case genotype
when 'AA' then 'Lack of empathy?'
when 'AG' then 'Lack of empathy?'
when 'GG' then 'Optimistic and empathetic; handle stress well'
end as interpretation from genome where rsid = 'rs53576'
```","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",496415321,
https://github.com/dogsheep/genome-to-sqlite/issues/1#issuecomment-765525338,https://api.github.com/repos/dogsheep/genome-to-sqlite/issues/1,765525338,MDEyOklzc3VlQ29tbWVudDc2NTUyNTMzOA==,25372415,2021-01-22T16:22:44Z,2021-01-22T16:22:44Z,NONE,"rs1333049 associated with coronary artery disease
https://www.snpedia.com/index.php/Rs1333049
```
select rsid, genotype, case genotype
when 'CC' then '1.9x increased risk for coronary artery disease'
when 'CG' then '1.5x increased risk for CAD'
when 'GG' then 'normal'
end as interpretation from genome where rsid = 'rs1333049'
```","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",496415321,
https://github.com/dogsheep/genome-to-sqlite/issues/1#issuecomment-831004775,https://api.github.com/repos/dogsheep/genome-to-sqlite/issues/1,831004775,MDEyOklzc3VlQ29tbWVudDgzMTAwNDc3NQ==,25372415,2021-05-03T03:46:23Z,2021-05-03T03:46:23Z,NONE,"RS1800955 is related to novelty seeking and ADHD
https://www.snpedia.com/index.php/Rs1800955
`select rsid, genotype, case genotype
when 'CC' then 'increased susceptibility to novelty seeking'
when 'CT' then 'increased susceptibility to novelty seeking'
when 'TT' then 'normal'
end as interpretation from genome where rsid = 'rs1800955'`","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",496415321,
https://github.com/simonw/datasette/pull/578#issuecomment-541837823,https://api.github.com/repos/simonw/datasette/issues/578,541837823,MDEyOklzc3VlQ29tbWVudDU0MTgzNzgyMw==,887095,2019-10-14T18:19:42Z,2019-10-14T18:19:42Z,NONE,"My use case was: I wanted to use datasette on a Raspberry Pi. `docker pull datasetteproject/datasette` pulled the official image, which then failed to execute because it is not ARM ready. Building my own quite took some time (~60 minutes via Qemu on Intel i5).
You are right, the build method is quite new and I would not be surprised if the syntax / command will change in future. The outcome however, a Docker multi-architecture manifest, is aligned with Docker's strategy on how to tackle multiple architectures: transparently, on the registry-side.
I just thought it would be nice to have the official image ready for multiple architectures. But I fully understand if the current methods feel too experimental to be mergable...","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",499954048,
https://github.com/simonw/datasette/issues/588#issuecomment-544502617,https://api.github.com/repos/simonw/datasette/issues/588,544502617,MDEyOklzc3VlQ29tbWVudDU0NDUwMjYxNw==,12617395,2019-10-21T12:58:22Z,2019-10-21T12:58:22Z,NONE,"Thanks for the reply. I was hoping queries per table were supported, as I have an application that builds tables depending on the user input to the application. It will either create one table, or two.. and if one or the other is missing, certain queries will return errors. Of course I can work around this by labeling the query name and hope users don't click queries they have not created a table for, but ideally the user would see the queries available based on the tables that exist in their database. ","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",505512251,
https://github.com/simonw/datasette/issues/593#issuecomment-541323265,https://api.github.com/repos/simonw/datasette/issues/593,541323265,MDEyOklzc3VlQ29tbWVudDU0MTMyMzI2NQ==,4312421,2019-10-12T13:04:54Z,2019-10-12T13:07:01Z,NONE,"hum, well, I fail also with hypercorn on ""add_signal_handler()"" not implemented directly in Windows, python-3.8 included
https://stackoverflow.com/questions/45987985/asyncio-loops-add-signal-handler-in-windows","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",506183241,
https://github.com/simonw/datasette/issues/593#issuecomment-541324637,https://api.github.com/repos/simonw/datasette/issues/593,541324637,MDEyOklzc3VlQ29tbWVudDU0MTMyNDYzNw==,4312421,2019-10-12T13:22:50Z,2019-10-12T13:22:50Z,NONE,"maybe situation is to change ? I see this in uvicorn https://github.com/encode/uvicorn/pull/423
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",506183241,
https://github.com/simonw/datasette/issues/593#issuecomment-541390656,https://api.github.com/repos/simonw/datasette/issues/593,541390656,MDEyOklzc3VlQ29tbWVudDU0MTM5MDY1Ng==,4312421,2019-10-13T06:22:07Z,2019-10-13T06:22:07Z,NONE,"well, I succeeded to make uvicorn work.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",506183241,
https://github.com/simonw/datasette/issues/594#issuecomment-547373739,https://api.github.com/repos/simonw/datasette/issues/594,547373739,MDEyOklzc3VlQ29tbWVudDU0NzM3MzczOQ==,2680980,2019-10-29T11:21:52Z,2019-10-29T11:21:52Z,NONE,"Just an FYI for folks wishing to run datasette with Python 3.8, I was able to successfully use datasette with the following in a virtual environment:
```
pip install uvloop==0.14.0rc1
pip install uvicorn==0.9.1
```
","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 1, ""rocket"": 0, ""eyes"": 0}",506297048,
https://github.com/simonw/datasette/pull/595#issuecomment-541499978,https://api.github.com/repos/simonw/datasette/issues/595,541499978,MDEyOklzc3VlQ29tbWVudDU0MTQ5OTk3OA==,4312421,2019-10-14T04:32:33Z,2019-10-14T04:33:26Z,NONE,"Maybe make the setup rule conditional, so that below python-3.6, it looks for unicorn-0.8 ?","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",506300941,
https://github.com/simonw/datasette/pull/595#issuecomment-541664602,https://api.github.com/repos/simonw/datasette/issues/595,541664602,MDEyOklzc3VlQ29tbWVudDU0MTY2NDYwMg==,647359,2019-10-14T13:03:10Z,2019-10-14T13:03:10Z,NONE,"🤷♂️ @stonebig's suggestion would be the best I got too, *if* you want to support 3.5->3.8.
It's either that, or hold off on 3.8 support until you're ready to go to 3.6->3.8.
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",506300941,
https://github.com/simonw/datasette/pull/595#issuecomment-552327079,https://api.github.com/repos/simonw/datasette/issues/595,552327079,MDEyOklzc3VlQ29tbWVudDU1MjMyNzA3OQ==,647359,2019-11-11T07:34:27Z,2019-11-11T07:34:27Z,NONE,"> Glitch has been upgraded to Python 3.7.
Whoop! 🥳 ✨ ","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",506300941,
https://github.com/simonw/datasette/issues/596#issuecomment-567225156,https://api.github.com/repos/simonw/datasette/issues/596,567225156,MDEyOklzc3VlQ29tbWVudDU2NzIyNTE1Ng==,132978,2019-12-18T21:40:35Z,2019-12-18T21:40:35Z,NONE,"I initially went looking for a way to hide a column completely. Today I found the setting to truncate cells, but it applies to all cells. In my case I have text columns that can have many thousands of characters. I was wondering whether the metadata JSON would be an appropriate place to indicate how columns are displayed (on a col-by-col basis). E.g., I'd like to be able to specify that only 20 chars of a given column be shown, and the font be monospace. But maybe I can do that in some other way - I barely know anything about datasette yet, sorry!","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",507454958,
https://github.com/simonw/datasette/issues/596#issuecomment-567226048,https://api.github.com/repos/simonw/datasette/issues/596,567226048,MDEyOklzc3VlQ29tbWVudDU2NzIyNjA0OA==,132978,2019-12-18T21:43:13Z,2019-12-18T21:43:13Z,NONE,"Meant to add that of course it would be better not to reinvent CSS (one time was already enough). But one option would be to provide a mechanism to specify a CSS class for a column (a cell, a row...) and let the user give a URL path to a CSS file on the command line.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",507454958,
https://github.com/simonw/datasette/issues/596#issuecomment-720741903,https://api.github.com/repos/simonw/datasette/issues/596,720741903,MDEyOklzc3VlQ29tbWVudDcyMDc0MTkwMw==,132978,2020-11-02T21:44:45Z,2020-11-02T21:44:45Z,NONE,Hi & thanks for the note @simonw! I wish I had more time to play with (and contribute to) datasette. I know you don't need me to tell you that it's super cool :-),"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",507454958,
https://github.com/simonw/datasette/issues/596#issuecomment-1238383171,https://api.github.com/repos/simonw/datasette/issues/596,1238383171,IC_kwDOBm6k_c5J0DpD,562352,2022-09-06T16:27:25Z,2022-09-06T16:27:25Z,NONE,"Perhaps some ways to address this.
1. Add a **horizontal scrollbar at the top of the table**. There are some solutions here: https://stackoverflow.com/questions/3934271/horizontal-scrollbar-on-top-and-bottom-of-table
2. Use a **fixed table header**. It would be useful when you're lost in the middle of a very big table. Pure CSS solutions seem to exist: https://stackoverflow.com/questions/21168521/table-fixed-header-and-scrollable-body
3. Maybe a possibility to resize columns. Not sure about that because it would more work not to lose it after each reload.
4. A way to keep **favorite views for each user**. The process would be: I select the column I want or not (with existing ""settings"" icon of each column); then I select a ""favoritize view"" option somewhere; then I can recall all my favorite views from a menu. These data could be hosted on the browser.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",507454958,
https://github.com/simonw/datasette/issues/605#issuecomment-548058715,https://api.github.com/repos/simonw/datasette/issues/605,548058715,MDEyOklzc3VlQ29tbWVudDU0ODA1ODcxNQ==,12617395,2019-10-30T18:44:41Z,2019-10-30T18:55:37Z,NONE,"Sure. I imagine it being pretty straight forward. Today when you click on the database, the UI displays:
-Table 1-
-fields-
-row count-
-Table 2-
-fields-
-row count-
Queries:
-query1-
-query2-
..
...
My proposal would be to display as follows:
-Table 1-
-fields-
-row count-
Queries:
-query1-
-query2-
..
...
-Table 2-
-fields-
-row count-
Queries:
-query1-
-query2-
..
...
This way, if a given table is not present in the database, the associated queries are also not present. Today, I have a list of queries, some work, some result in errors depending on whether the dependent tables exist in the database.
Let me know if that makes sense. Thanks again!","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",510076368,
https://github.com/simonw/datasette/issues/607#issuecomment-546722281,https://api.github.com/repos/simonw/datasette/issues/607,546722281,MDEyOklzc3VlQ29tbWVudDU0NjcyMjI4MQ==,8431341,2019-10-27T18:46:29Z,2019-10-27T19:00:40Z,NONE,"Update: I've created a table of only unique names. This reduces the search space from over 16 million, to just about 640,000. Interestingly, it takes less than 2 seconds to create this table using Python. Performing the same search that we did earlier for `elon musk` takes nearly a second - much faster than before but still not speedy enough for an autocomplete feature (which usually needs to return results within 100ms to feel ""real time"").
Any ideas for slashing the search speed nearly 10 fold?
> 
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",512996469,
https://github.com/simonw/datasette/issues/607#issuecomment-546723302,https://api.github.com/repos/simonw/datasette/issues/607,546723302,MDEyOklzc3VlQ29tbWVudDU0NjcyMzMwMg==,8431341,2019-10-27T18:59:55Z,2019-10-27T19:00:48Z,NONE,"Ultimately, I'm needing to serve searches like this to multiple users (at times concurrently). Given the size of the database I'm working with, can anyone comment as to whether I should be storing this in something like MySQL or Postgres rather than SQLite. I know there's been much [defense of sqlite being performant](https://www.sqlite.org/whentouse.html) but I wonder if those arguments break down as the database size increases.
For example, if I scroll to the bottom of that linked page, where it says **Checklist For Choosing The Right Database Engine**, here's how I answer those questions:
- Is the data separated from the application by a network? → choose client/server
__Yes__
- Many concurrent writers? → choose client/server
__Not exactly. I may have many concurrent readers but almost no concurrent writers.__
- Big data? → choose client/server
__No, my database is less than 40 gb and wont approach a terabyte in the next decade.__
So is sqlite still a good idea here?","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",512996469,
https://github.com/simonw/datasette/issues/607#issuecomment-546752311,https://api.github.com/repos/simonw/datasette/issues/607,546752311,MDEyOklzc3VlQ29tbWVudDU0Njc1MjMxMQ==,8431341,2019-10-28T00:37:10Z,2019-10-28T00:37:10Z,NONE,"UPDATE:
According to tips suggested in [Squeezing Performance from SQLite: Indexes? Indexes!](https://medium.com/@JasonWyatt/squeezing-performance-from-sqlite-indexes-indexes-c4e175f3c346) I have added an index to my large table and benchmarked query speeds in the case where I want to return `all rows`, `rows exactly equal to 'Musk Elon'` and, `rows like 'musk'`. Indexing reduced query time for each of those measures and **dramatically** reduced the time to return `rows exactly equal to 'Musk Elon'` as shown below:
> table: edgar_idx
> rows: 16,428,090 rows
> **indexed: False**
> Return all rows where company name exactly equal to Musk Elon
> query: select rowid, * from edgar_idx where ""company"" = :p0 order by rowid limit 101
> query time: Query took 21821.031ms
>
> Return all rows where company name contains Musk
> query: select rowid, * from edgar_idx where ""company"" like :p0 order by rowid limit 101
> query time: Query took 20505.029ms
>
> Return everything
> query: select rowid, * from edgar_idx order by rowid limit 101
> query time: Query took 7985.011ms
>
> **indexed: True**
> Return all rows where company name exactly equal to Musk Elon
> query: select rowid, * from edgar_idx where ""company"" = :p0 order by rowid limit 101
> query time: Query took 30.0ms
>
> Return all rows where company name contains Musk
> query: select rowid, * from edgar_idx where ""company"" like :p0 order by rowid limit 101
> query time: Query took 13340.019ms
>
> Return everything
> query: select rowid, * from edgar_idx order by rowid limit 101
> query time: Query took 2190.003ms
So indexing reduced query time for an exact match to ""Musk Elon"" from almost `22 seconds` to `30.0ms`. **That's amazing and truly promising!** However, an autocomplete feature relies on fuzzy / incomplete matching, which is more similar to the `contains 'musk'` query... Unfortunately, that takes 13 seconds even after indexing. So the hunt for a fast fuzzy / autocomplete search capability persists.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",512996469,
https://github.com/simonw/datasette/issues/607#issuecomment-548060038,https://api.github.com/repos/simonw/datasette/issues/607,548060038,MDEyOklzc3VlQ29tbWVudDU0ODA2MDAzOA==,8431341,2019-10-30T18:47:57Z,2019-10-30T18:47:57Z,NONE,"Hi Simon, thanks for the pointer! Feeling good that I came to your conclusion a few days ago. I did hit a snag with figuring out how to compile a special version of sqlite for my windows machine (which I only realized I needed to do after running your command `sqlite-utils enable-fts mydatabase.db items name description`).
I'll try to solve that problem next week and report back here with my findings (if you know of a good tutorial for compiling on windows, I'm all ears). Either way, I'll try to close this issue out in the next two weeks. Thanks again!","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",512996469,
https://github.com/simonw/datasette/issues/607#issuecomment-550649607,https://api.github.com/repos/simonw/datasette/issues/607,550649607,MDEyOklzc3VlQ29tbWVudDU1MDY0OTYwNw==,8431341,2019-11-07T03:38:10Z,2019-11-07T03:38:10Z,NONE,"I just got FTS5 working and it is incredible! The lookup time for returning all rows where company name contains ""Musk"" from my table of 16,428,090 rows has dropped from `13,340.019` ms to `15.6`ms. Well below the 100ms latency for the ""real time autocomplete"" feel (which doesn't currently include the http call).
So cool! Thanks again for the pointers and awesome datasette!","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",512996469,
https://github.com/simonw/datasette/issues/616#issuecomment-551872999,https://api.github.com/repos/simonw/datasette/issues/616,551872999,MDEyOklzc3VlQ29tbWVudDU1MTg3Mjk5OQ==,49656826,2019-11-08T15:31:33Z,2019-11-08T15:31:33Z,NONE,"Thank you so much, Simon!
Now, I'm contacting Heroku's support team to find a way to update the Datasette version on bases.vortex.media.
Do you know how to do it?","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",518506242,
https://github.com/dogsheep/twitter-to-sqlite/issues/31#issuecomment-1251845216,https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/31,1251845216,IC_kwDODEm0Qs5KnaRg,150986,2022-09-20T05:05:03Z,2022-09-20T05:05:03Z,NONE,"yay! Thanks a bunch for the `twitter-to-sqlite friends` command!
The twitter ""Download an archive of your data"" feature doesn't include who I follow, so this is particularly handy.
The whole Dogsheep thing is great :) I've written about similar things under [cloud-services](https://www.madmode.com/search/label/cloud-services/):
- 2021: [Closet Librarian Approach to Cloud Services](https://www.madmode.com/2021/closet-librarian-approach-cloud-services.html)
- 2015: [jukekb \- Browse iTunes libraries and upload playlists to Google Music](https://www.madmode.com/2015/jukekb)","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",520508502,
https://github.com/simonw/datasette/issues/619#issuecomment-626006493,https://api.github.com/repos/simonw/datasette/issues/619,626006493,MDEyOklzc3VlQ29tbWVudDYyNjAwNjQ5Mw==,412005,2020-05-08T20:29:12Z,2020-05-08T20:29:12Z,NONE,"just trying out datasette and quite like it, thanks! i found this issue annoying enough to have a go at a fix. have you any thoughts on a good approach? (i'm happy to dig in myself if you haven't thought about it yet, but wanted to check if you had an idea for how to fix when you raised the issue)","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",520655983,
https://github.com/simonw/datasette/issues/619#issuecomment-697973420,https://api.github.com/repos/simonw/datasette/issues/619,697973420,MDEyOklzc3VlQ29tbWVudDY5Nzk3MzQyMA==,45416,2020-09-23T21:07:58Z,2020-09-23T21:07:58Z,NONE,"I've just run into this after crafting a complex query and discovered that hitting back loses my query.
Even showing me the whole bad query would be a huge improvement over the current status quo.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",520655983,
https://github.com/simonw/datasette/pull/627#issuecomment-552737357,https://api.github.com/repos/simonw/datasette/issues/627,552737357,MDEyOklzc3VlQ29tbWVudDU1MjczNzM1Nw==,2680980,2019-11-12T05:13:46Z,2019-11-12T05:13:46Z,NONE,Thanks @simonw. I appreciate your work on this.,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",521323012,
https://github.com/simonw/datasette/pull/627#issuecomment-609393513,https://api.github.com/repos/simonw/datasette/issues/627,609393513,MDEyOklzc3VlQ29tbWVudDYwOTM5MzUxMw==,4312421,2020-04-05T10:23:57Z,2020-04-05T10:23:57Z,NONE,is there any specific reason to stick to Jinja2~=2.10.3 when there is Jinja-2.11.1 ?,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",521323012,
https://github.com/simonw/datasette/issues/633#issuecomment-620841496,https://api.github.com/repos/simonw/datasette/issues/633,620841496,MDEyOklzc3VlQ29tbWVudDYyMDg0MTQ5Ng==,46165,2020-04-28T20:37:50Z,2020-04-28T20:37:50Z,NONE,"Using the Heroku web interface, you can set the WEB_CONCURRENCY = 1

","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",522334771,
https://github.com/simonw/datasette/issues/639#issuecomment-558437707,https://api.github.com/repos/simonw/datasette/issues/639,558437707,MDEyOklzc3VlQ29tbWVudDU1ODQzNzcwNw==,172847,2019-11-26T03:02:53Z,2019-11-26T03:03:29Z,NONE,"@simonw - Thanks for the reply!
My reading of the heroku documents is that if one sets things up using git, then one can use ""git push"" (from a {local, GitHub, GitLab} git repository to Heroku) to ""update"" a Heroku deployment, but I'm not sure exactly how this works. However, assuming there is some way to use ""git push"" to update the Heroku deployment, the question becomes how can one do this in conjunction with datasette.
Again based on my reading the heroku documents, it would seem that the following should work (but it doesn't quite):
1) Use datasette to create a deployment (named MYAPP)
2) Put it in maintenance mode
3) heroku git:clone -a MYAPP
-- This results in an empty repository (as expected)
4) In another directory, heroku slugs:download -a MYAPP
5) Copy the downloaded slug into the repository
6) Make some change to metadata.json
6) Commit and push it back
7) Take the deployment out of maintenance mode
8) Refresh the deployment
Using the heroku console, I've verified that the edits appear on heroku, but somehow they are not reflected in the running app.
I'm hopeful that with some small tweak or perhaps the addition of a bit of voodoo, this strategy will work.
I think it will be important to get this working for another reason: getting Heroku, Cloudcube, and datasette to work together, to overcome the slug size limitation so that large SQLite databases can be deployed to Heroku using Datasette.
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",527670799,
https://github.com/simonw/datasette/issues/639#issuecomment-558852316,https://api.github.com/repos/simonw/datasette/issues/639,558852316,MDEyOklzc3VlQ29tbWVudDU1ODg1MjMxNg==,172847,2019-11-26T22:54:23Z,2019-11-26T22:54:23Z,NONE,"@jacobian - Thanks for your help. Having to upload an entire slug each time a small change is needed in `metadata.json` seems no better than the current situation so I probably won't go down that rabbit hole just yet. In any case, the really important goal is moving the SQLite file out of Heroku in a way that the Heroku app can still read it efficiently. Is this possible? Is Cloudcube the right place to start? Is there any alternative? ","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",527670799,
https://github.com/simonw/datasette/issues/639#issuecomment-559916057,https://api.github.com/repos/simonw/datasette/issues/639,559916057,MDEyOklzc3VlQ29tbWVudDU1OTkxNjA1Nw==,172847,2019-11-30T06:08:50Z,2019-11-30T06:08:50Z,NONE,"@simonw, @jacobian - I was able to resolve the metadata.json issue by adding `-m metadata.json` to the Procfile. Now `git push heroku master` picks up the changes, though I have the impression that heroku is doing more work than necessary (e.g. one of the information messages is: `Installing requirements with pip`).
I also had to set the environment variable WEB_CONCURRENCY -- I used WEB_CONCURRENCY=1.
I am still anxious to know whether it's possible for Datasette on Heroku to access the SQLite file at another location. Cloudcube seems the most promising, and I'm hoping it can be done by tweaking the Procfile suitably, but maybe that's too optimistic?
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",527670799,
https://github.com/simonw/datasette/issues/646#issuecomment-561133534,https://api.github.com/repos/simonw/datasette/issues/646,561133534,MDEyOklzc3VlQ29tbWVudDU2MTEzMzUzNA==,18017473,2019-12-03T11:50:44Z,2019-12-03T11:50:44Z,NONE,"Thanks for the reply.
Will try to implement that on my end, if I have any success I will post here/ make a pull request.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",531502365,
https://github.com/simonw/datasette/issues/646#issuecomment-561247711,https://api.github.com/repos/simonw/datasette/issues/646,561247711,MDEyOklzc3VlQ29tbWVudDU2MTI0NzcxMQ==,18017473,2019-12-03T16:31:39Z,2019-12-03T17:31:33Z,NONE,"> I don't think this is possible at the moment but you're right, it totally should be.
Just give me a heads-up if you think you can do that quickly. I am trying to implement it with very little knowledge of how datasette works, so it will take loads of time.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",531502365,
https://github.com/simonw/datasette/issues/648#issuecomment-625286519,https://api.github.com/repos/simonw/datasette/issues/648,625286519,MDEyOklzc3VlQ29tbWVudDYyNTI4NjUxOQ==,28694175,2020-05-07T14:23:22Z,2020-05-07T14:28:33Z,NONE,"Hi! I'm using datasette on this repository: https://github.com/chekos/RIPA-2018-datasette
and on my local machine i can see an /about page i created but when i deploy to heroku i get a 404 (http://ripa-2018-db.herokuapp.com)
![]() I bumped datasette in my requirements file to 0.41 so I'm 100% what the issue is 🤔
Do you have any idea what could be the problem? 👀
EDIT: for context, I have a templates directory with a pages/about.html file in https://github.com/chekos/RIPA-2018-datasette/tree/master/datasette/templates","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",534492501,
https://github.com/simonw/datasette/issues/648#issuecomment-625321121,https://api.github.com/repos/simonw/datasette/issues/648,625321121,MDEyOklzc3VlQ29tbWVudDYyNTMyMTEyMQ==,28694175,2020-05-07T15:21:19Z,2020-05-07T15:21:19Z,NONE,"It seems that heroku wasn't updating to 0.41 on deployment.
Had to add `--branch 0.41` and that solved it! Heroku caches dependencies
I bumped datasette in my requirements file to 0.41 so I'm 100% what the issue is 🤔
Do you have any idea what could be the problem? 👀
EDIT: for context, I have a templates directory with a pages/about.html file in https://github.com/chekos/RIPA-2018-datasette/tree/master/datasette/templates","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",534492501,
https://github.com/simonw/datasette/issues/648#issuecomment-625321121,https://api.github.com/repos/simonw/datasette/issues/648,625321121,MDEyOklzc3VlQ29tbWVudDYyNTMyMTEyMQ==,28694175,2020-05-07T15:21:19Z,2020-05-07T15:21:19Z,NONE,"It seems that heroku wasn't updating to 0.41 on deployment.
Had to add `--branch 0.41` and that solved it! Heroku caches dependencies
![]() and (i think) because the `requirements.txt` doesn't specify the datasette version, it didn't update from 0.40 to 0.41 on heroku even though it was specified on my local requirements file as `datasette >= 0.41`
These are the lines that gave me an idea on how to solve it:
https://github.com/simonw/datasette/blob/182e5c8745c94576718315f7596ccc81e5e2417b/datasette/publish/heroku.py#L164-L186","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",534492501,
https://github.com/simonw/sqlite-utils/issues/69#issuecomment-710768396,https://api.github.com/repos/simonw/sqlite-utils/issues/69,710768396,MDEyOklzc3VlQ29tbWVudDcxMDc2ODM5Ng==,30607,2020-10-17T07:46:59Z,2020-10-17T07:46:59Z,NONE,Great @simonw thank you very much,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",534507142,
https://github.com/simonw/sqlite-utils/issues/70#issuecomment-575799104,https://api.github.com/repos/simonw/sqlite-utils/issues/70,575799104,MDEyOklzc3VlQ29tbWVudDU3NTc5OTEwNA==,26292069,2020-01-17T21:20:17Z,2020-01-17T21:20:17Z,NONE,"Omg sorry I took so long to reply!
On SQL we can say how the foreign key behaves when it is deleted or updated on the parent table (see https://www.sqlitetutorial.net/sqlite-foreign-key/ for more details).
I did not see clearly how to create tables with this feature on sqlite-utils library.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",539204432,
and (i think) because the `requirements.txt` doesn't specify the datasette version, it didn't update from 0.40 to 0.41 on heroku even though it was specified on my local requirements file as `datasette >= 0.41`
These are the lines that gave me an idea on how to solve it:
https://github.com/simonw/datasette/blob/182e5c8745c94576718315f7596ccc81e5e2417b/datasette/publish/heroku.py#L164-L186","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",534492501,
https://github.com/simonw/sqlite-utils/issues/69#issuecomment-710768396,https://api.github.com/repos/simonw/sqlite-utils/issues/69,710768396,MDEyOklzc3VlQ29tbWVudDcxMDc2ODM5Ng==,30607,2020-10-17T07:46:59Z,2020-10-17T07:46:59Z,NONE,Great @simonw thank you very much,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",534507142,
https://github.com/simonw/sqlite-utils/issues/70#issuecomment-575799104,https://api.github.com/repos/simonw/sqlite-utils/issues/70,575799104,MDEyOklzc3VlQ29tbWVudDU3NTc5OTEwNA==,26292069,2020-01-17T21:20:17Z,2020-01-17T21:20:17Z,NONE,"Omg sorry I took so long to reply!
On SQL we can say how the foreign key behaves when it is deleted or updated on the parent table (see https://www.sqlitetutorial.net/sqlite-foreign-key/ for more details).
I did not see clearly how to create tables with this feature on sqlite-utils library.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",539204432,