TypeError: 'str' object is not callable
INFO: 127.0.0.1:47228 - ""GET /zeropm-v0-0-3/api_ready_query HTTP/1.1"" 500 Internal Server Error
```
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1163369515,query result page is using 400mb of browser memory 40x size of html page and 400x size of csv data,
https://github.com/simonw/datasette/issues/1655#issuecomment-1767248394,https://api.github.com/repos/simonw/datasette/issues/1655,1767248394,IC_kwDOBm6k_c5pVhIK,6262071,yejiyang,2023-10-17T21:53:17Z,2023-10-17T21:53:17Z,NONE,"@fgregg, I am happy to do that and just could not find a way to create issues at your fork repo. ","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1163369515,query result page is using 400mb of browser memory 40x size of html page and 400x size of csv data,
https://github.com/simonw/datasette/pull/2202#issuecomment-1777247375,https://api.github.com/repos/simonw/datasette/issues/2202,1777247375,IC_kwDOBm6k_c5p7qSP,22429695,codecov[bot],2023-10-24T13:49:27Z,2023-10-24T13:49:27Z,NONE,"## [Codecov](https://app.codecov.io/gh/simonw/datasette/pull/2202?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report
All modified and coverable lines are covered by tests :white_check_mark:
> Comparison is base [(`452a587`)](https://app.codecov.io/gh/simonw/datasette/commit/452a587e236ef642cbc6ae345b58767ea8420cb5?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69% compared to head [(`be4d0f0`)](https://app.codecov.io/gh/simonw/datasette/pull/2202?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69%.
Additional details and impacted files
```diff
@@ Coverage Diff @@
## main #2202 +/- ##
=======================================
Coverage 92.69% 92.69%
=======================================
Files 40 40
Lines 6047 6047
=======================================
Hits 5605 5605
Misses 442 442
```
[:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/simonw/datasette/pull/2202?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison).
:loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison).
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1959278971,Bump the python-packages group with 1 update,
https://github.com/simonw/datasette/issues/411#issuecomment-1779267468,https://api.github.com/repos/simonw/datasette/issues/411,1779267468,IC_kwDOBm6k_c5qDXeM,363004,hcarter333,2023-10-25T13:23:04Z,2023-10-25T13:23:04Z,NONE,"Using the [Counties example](https://us-counties.datasette.io/counties/county_for_latitude_longitude?longitude=-122&latitude=37), I was able to pull out the MakePoint method as
MakePoint(cast(rm_rnb_history_pres.rx_lng as float), cast(rm_rnb_history_pres.rx_lat as float)) as geometry
which worked, giving me a geometry column.
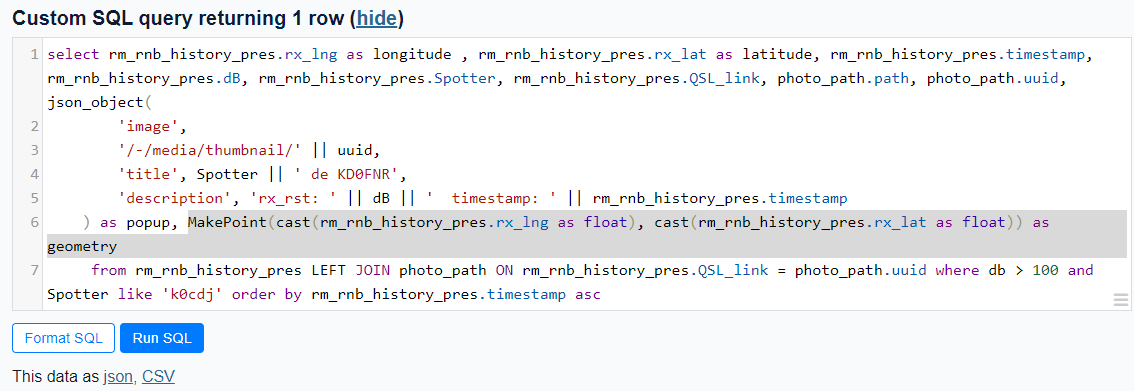
gave
I believe it's the cast to float that does the trick. Prior to using the cast, I also received a 'wrong number of arguments' eror.
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",410384988,How to pass named parameter into spatialite MakePoint() function,
https://github.com/simonw/datasette/issues/949#issuecomment-1791571572,https://api.github.com/repos/simonw/datasette/issues/949,1791571572,IC_kwDOBm6k_c5qyTZ0,498744,mhkeller,2023-11-02T21:36:24Z,2023-11-02T21:36:24Z,NONE,"FWIW, code mirror 6 now has this standard although if you want table-specific suggestions, you'd have to handle parsing out which table the user is querying yourself.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",684961449,Try out CodeMirror SQL hints,
https://github.com/simonw/sqlite-utils/pull/600#issuecomment-1793264654,https://api.github.com/repos/simonw/sqlite-utils/issues/600,1793264654,IC_kwDOCGYnMM5q4wwO,22429695,codecov[bot],2023-11-04T00:22:07Z,2023-11-04T00:27:29Z,NONE,"## [Codecov](https://app.codecov.io/gh/simonw/sqlite-utils/pull/600?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report
All modified and coverable lines are covered by tests :white_check_mark:
> Comparison is base [(`622c3a5`)](https://app.codecov.io/gh/simonw/sqlite-utils/commit/622c3a5a7dd53a09c029e2af40c2643fe7579340?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 95.77% compared to head [(`b1a6076`)](https://app.codecov.io/gh/simonw/sqlite-utils/pull/600?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 95.77%.
Additional details and impacted files
```diff
@@ Coverage Diff @@
## main #600 +/- ##
=======================================
Coverage 95.77% 95.77%
=======================================
Files 8 8
Lines 2840 2840
=======================================
Hits 2720 2720
Misses 120 120
```
| [Files](https://app.codecov.io/gh/simonw/sqlite-utils/pull/600?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) | Coverage Δ | |
|---|---|---|
| [sqlite\_utils/db.py](https://app.codecov.io/gh/simonw/sqlite-utils/pull/600?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison#diff-c3FsaXRlX3V0aWxzL2RiLnB5) | `97.22% <ø> (ø)` | |
| [sqlite\_utils/utils.py](https://app.codecov.io/gh/simonw/sqlite-utils/pull/600?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison#diff-c3FsaXRlX3V0aWxzL3V0aWxzLnB5) | `94.56% <ø> (ø)` | |
[:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/simonw/sqlite-utils/pull/600?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison).
:loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison).
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1977004379,Add spatialite arm64 linux path,"{""id"": 254, ""slug"": ""codecov"", ""node_id"": ""MDM6QXBwMjU0"", ""owner"": {""login"": ""codecov"", ""id"": 8226205, ""node_id"": ""MDEyOk9yZ2FuaXphdGlvbjgyMjYyMDU="", ""avatar_url"": ""https://avatars.githubusercontent.com/u/8226205?v=4"", ""gravatar_id"": """", ""url"": ""https://api.github.com/users/codecov"", ""html_url"": ""https://github.com/codecov"", ""followers_url"": ""https://api.github.com/users/codecov/followers"", ""following_url"": ""https://api.github.com/users/codecov/following{/other_user}"", ""gists_url"": ""https://api.github.com/users/codecov/gists{/gist_id}"", ""starred_url"": ""https://api.github.com/users/codecov/starred{/owner}{/repo}"", ""subscriptions_url"": ""https://api.github.com/users/codecov/subscriptions"", ""organizations_url"": ""https://api.github.com/users/codecov/orgs"", ""repos_url"": ""https://api.github.com/users/codecov/repos"", ""events_url"": ""https://api.github.com/users/codecov/events{/privacy}"", ""received_events_url"": ""https://api.github.com/users/codecov/received_events"", ""type"": ""Organization"", ""site_admin"": false}, ""name"": ""Codecov"", ""description"": ""Codecov provides highly integrated tools to group, merge, archive and compare coverage reports. Whether your team is comparing changes in a pull request or reviewing a single commit, Codecov will improve the code review workflow and quality.\r\n\r\n## Code coverage done right.®\r\n\r\n1. Upload coverage reports from your CI builds.\r\n2. Codecov merges all builds and languages into one beautiful coherent report.\r\n3. Get commit statuses, pull request comments and coverage overlay via our browser extension.\r\n\r\nWhen Codecov merges your uploads it keeps track of the CI provider (inc. build details) and user specified context, e.g. `#unittest` ~ `#smoketest` or `#oldcode` ~ `#newcode`. You can track the `#unittest` coverage independently of other groups. [Learn more here](\r\nhttp://docs.codecov.io/docs/flags)\r\n\r\nThrough **Codecov's Browser Extension** reports overlay directly in GitHub UI to assist in code review in [Chrome](https://chrome.google.com/webstore/detail/codecov/gedikamndpbemklijjkncpnolildpbgo) or Firefox (https://addons.mozilla.org/en-US/firefox/addon/codecov/)\r\n\r\n*Highly detailed* **pull request comments** and *customizable* **commit statuses** will improve your team's workflow and code coverage incrementally.\r\n\r\n**File backed configuration** all through the `codecov.yml`. \r\n\r\n## FAQ\r\n- Do you **merge multiple uploads** to the same commit? **Yes**\r\n- Do you **support multiple languages** in the same project? **Yes**\r\n- Can you **group coverage reports** by project and/or test type? **Yes**\r\n- How does **pricing** work? Only paid users can view reports and post statuses/comments. "", ""external_url"": ""https://codecov.io"", ""html_url"": ""https://github.com/apps/codecov"", ""created_at"": ""2016-09-25T14:18:27Z"", ""updated_at"": ""2023-09-08T15:29:16Z"", ""permissions"": {""administration"": ""read"", ""checks"": ""write"", ""contents"": ""read"", ""emails"": ""read"", ""issues"": ""read"", ""members"": ""read"", ""metadata"": ""read"", ""pull_requests"": ""write"", ""statuses"": ""write""}, ""events"": [""check_run"", ""check_suite"", ""create"", ""delete"", ""fork"", ""member"", ""membership"", ""organization"", ""public"", ""pull_request"", ""push"", ""release"", ""repository"", ""status"", ""team_add""]}"
https://github.com/simonw/datasette/issues/1415#issuecomment-1793787454,https://api.github.com/repos/simonw/datasette/issues/1415,1793787454,IC_kwDOBm6k_c5q6wY-,45269373,jimmybutton,2023-11-05T16:44:49Z,2023-11-05T16:46:59Z,NONE,"thanks for documenting this @bendnorman! got stuck at exactly the same point `gcloud builds submit ... returned non-zero exit status 1`, without a clue why this was happening. i now managed to get the github action to deploy datasette by assigning the following roles to the service account: `roles/run.admin`, `roles/storage.admin`, `roles/cloudbuild.builds.builder`, `roles/viewer`, `roles/iam.serviceAccountUser`.","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",959137143,feature request: document minimum permissions for service account for cloudrun,
https://github.com/simonw/datasette/pull/2206#issuecomment-1801888957,https://api.github.com/repos/simonw/datasette/issues/2206,1801888957,IC_kwDOBm6k_c5rZqS9,22429695,codecov[bot],2023-11-08T13:26:13Z,2023-11-08T13:26:13Z,NONE,"## [Codecov](https://app.codecov.io/gh/simonw/datasette/pull/2206?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report
All modified and coverable lines are covered by tests :white_check_mark:
> Comparison is base [(`452a587`)](https://app.codecov.io/gh/simonw/datasette/commit/452a587e236ef642cbc6ae345b58767ea8420cb5?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69% compared to head [(`eec10df`)](https://app.codecov.io/gh/simonw/datasette/pull/2206?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69%.
Additional details and impacted files
```diff
@@ Coverage Diff @@
## main #2206 +/- ##
=======================================
Coverage 92.69% 92.69%
=======================================
Files 40 40
Lines 6047 6047
=======================================
Hits 5605 5605
Misses 442 442
```
[:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/simonw/datasette/pull/2206?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison).
:loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison).
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1983600865,Bump the python-packages group with 1 update,"{""id"": 254, ""slug"": ""codecov"", ""node_id"": ""MDM6QXBwMjU0"", ""owner"": {""login"": ""codecov"", ""id"": 8226205, ""node_id"": ""MDEyOk9yZ2FuaXphdGlvbjgyMjYyMDU="", ""avatar_url"": ""https://avatars.githubusercontent.com/u/8226205?v=4"", ""gravatar_id"": """", ""url"": ""https://api.github.com/users/codecov"", ""html_url"": ""https://github.com/codecov"", ""followers_url"": ""https://api.github.com/users/codecov/followers"", ""following_url"": ""https://api.github.com/users/codecov/following{/other_user}"", ""gists_url"": ""https://api.github.com/users/codecov/gists{/gist_id}"", ""starred_url"": ""https://api.github.com/users/codecov/starred{/owner}{/repo}"", ""subscriptions_url"": ""https://api.github.com/users/codecov/subscriptions"", ""organizations_url"": ""https://api.github.com/users/codecov/orgs"", ""repos_url"": ""https://api.github.com/users/codecov/repos"", ""events_url"": ""https://api.github.com/users/codecov/events{/privacy}"", ""received_events_url"": ""https://api.github.com/users/codecov/received_events"", ""type"": ""Organization"", ""site_admin"": false}, ""name"": ""Codecov"", ""description"": ""Codecov provides highly integrated tools to group, merge, archive and compare coverage reports. Whether your team is comparing changes in a pull request or reviewing a single commit, Codecov will improve the code review workflow and quality.\r\n\r\n## Code coverage done right.®\r\n\r\n1. Upload coverage reports from your CI builds.\r\n2. Codecov merges all builds and languages into one beautiful coherent report.\r\n3. Get commit statuses, pull request comments and coverage overlay via our browser extension.\r\n\r\nWhen Codecov merges your uploads it keeps track of the CI provider (inc. build details) and user specified context, e.g. `#unittest` ~ `#smoketest` or `#oldcode` ~ `#newcode`. You can track the `#unittest` coverage independently of other groups. [Learn more here](\r\nhttp://docs.codecov.io/docs/flags)\r\n\r\nThrough **Codecov's Browser Extension** reports overlay directly in GitHub UI to assist in code review in [Chrome](https://chrome.google.com/webstore/detail/codecov/gedikamndpbemklijjkncpnolildpbgo) or Firefox (https://addons.mozilla.org/en-US/firefox/addon/codecov/)\r\n\r\n*Highly detailed* **pull request comments** and *customizable* **commit statuses** will improve your team's workflow and code coverage incrementally.\r\n\r\n**File backed configuration** all through the `codecov.yml`. \r\n\r\n## FAQ\r\n- Do you **merge multiple uploads** to the same commit? **Yes**\r\n- Do you **support multiple languages** in the same project? **Yes**\r\n- Can you **group coverage reports** by project and/or test type? **Yes**\r\n- How does **pricing** work? Only paid users can view reports and post statuses/comments. "", ""external_url"": ""https://codecov.io"", ""html_url"": ""https://github.com/apps/codecov"", ""created_at"": ""2016-09-25T14:18:27Z"", ""updated_at"": ""2023-09-08T15:29:16Z"", ""permissions"": {""administration"": ""read"", ""checks"": ""write"", ""contents"": ""read"", ""emails"": ""read"", ""issues"": ""read"", ""members"": ""read"", ""metadata"": ""read"", ""pull_requests"": ""write"", ""statuses"": ""write""}, ""events"": [""check_run"", ""check_suite"", ""create"", ""delete"", ""fork"", ""member"", ""membership"", ""organization"", ""public"", ""pull_request"", ""push"", ""release"", ""repository"", ""status"", ""team_add""]}"
https://github.com/simonw/datasette/pull/2209#issuecomment-1812753347,https://api.github.com/repos/simonw/datasette/issues/2209,1812753347,IC_kwDOBm6k_c5sDGvD,22429695,codecov[bot],2023-11-15T15:31:12Z,2023-11-15T15:31:12Z,NONE,"## [Codecov](https://app.codecov.io/gh/simonw/datasette/pull/2209?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report
All modified and coverable lines are covered by tests :white_check_mark:
> Comparison is base [(`452a587`)](https://app.codecov.io/gh/simonw/datasette/commit/452a587e236ef642cbc6ae345b58767ea8420cb5?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69% compared to head [(`c88414b`)](https://app.codecov.io/gh/simonw/datasette/pull/2209?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69%.
Additional details and impacted files
```diff
@@ Coverage Diff @@
## main #2209 +/- ##
=======================================
Coverage 92.69% 92.69%
=======================================
Files 40 40
Lines 6047 6047
=======================================
Hits 5605 5605
Misses 442 442
```
[:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/simonw/datasette/pull/2209?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison).
:loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison).
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1994861266,Fix query for suggested facets with column named value,"{""id"": 254, ""slug"": ""codecov"", ""node_id"": ""MDM6QXBwMjU0"", ""owner"": {""login"": ""codecov"", ""id"": 8226205, ""node_id"": ""MDEyOk9yZ2FuaXphdGlvbjgyMjYyMDU="", ""avatar_url"": ""https://avatars.githubusercontent.com/u/8226205?v=4"", ""gravatar_id"": """", ""url"": ""https://api.github.com/users/codecov"", ""html_url"": ""https://github.com/codecov"", ""followers_url"": ""https://api.github.com/users/codecov/followers"", ""following_url"": ""https://api.github.com/users/codecov/following{/other_user}"", ""gists_url"": ""https://api.github.com/users/codecov/gists{/gist_id}"", ""starred_url"": ""https://api.github.com/users/codecov/starred{/owner}{/repo}"", ""subscriptions_url"": ""https://api.github.com/users/codecov/subscriptions"", ""organizations_url"": ""https://api.github.com/users/codecov/orgs"", ""repos_url"": ""https://api.github.com/users/codecov/repos"", ""events_url"": ""https://api.github.com/users/codecov/events{/privacy}"", ""received_events_url"": ""https://api.github.com/users/codecov/received_events"", ""type"": ""Organization"", ""site_admin"": false}, ""name"": ""Codecov"", ""description"": ""Codecov provides highly integrated tools to group, merge, archive and compare coverage reports. Whether your team is comparing changes in a pull request or reviewing a single commit, Codecov will improve the code review workflow and quality.\r\n\r\n## Code coverage done right.®\r\n\r\n1. Upload coverage reports from your CI builds.\r\n2. Codecov merges all builds and languages into one beautiful coherent report.\r\n3. Get commit statuses, pull request comments and coverage overlay via our browser extension.\r\n\r\nWhen Codecov merges your uploads it keeps track of the CI provider (inc. build details) and user specified context, e.g. `#unittest` ~ `#smoketest` or `#oldcode` ~ `#newcode`. You can track the `#unittest` coverage independently of other groups. [Learn more here](\r\nhttp://docs.codecov.io/docs/flags)\r\n\r\nThrough **Codecov's Browser Extension** reports overlay directly in GitHub UI to assist in code review in [Chrome](https://chrome.google.com/webstore/detail/codecov/gedikamndpbemklijjkncpnolildpbgo) or Firefox (https://addons.mozilla.org/en-US/firefox/addon/codecov/)\r\n\r\n*Highly detailed* **pull request comments** and *customizable* **commit statuses** will improve your team's workflow and code coverage incrementally.\r\n\r\n**File backed configuration** all through the `codecov.yml`. \r\n\r\n## FAQ\r\n- Do you **merge multiple uploads** to the same commit? **Yes**\r\n- Do you **support multiple languages** in the same project? **Yes**\r\n- Can you **group coverage reports** by project and/or test type? **Yes**\r\n- How does **pricing** work? Only paid users can view reports and post statuses/comments. "", ""external_url"": ""https://codecov.io"", ""html_url"": ""https://github.com/apps/codecov"", ""created_at"": ""2016-09-25T14:18:27Z"", ""updated_at"": ""2023-09-08T15:29:16Z"", ""permissions"": {""administration"": ""read"", ""checks"": ""write"", ""contents"": ""read"", ""emails"": ""read"", ""issues"": ""read"", ""members"": ""read"", ""metadata"": ""read"", ""pull_requests"": ""write"", ""statuses"": ""write""}, ""events"": [""check_run"", ""check_suite"", ""create"", ""delete"", ""fork"", ""member"", ""membership"", ""organization"", ""public"", ""pull_request"", ""push"", ""release"", ""repository"", ""status"", ""team_add""]}"
https://github.com/simonw/sqlite-utils/pull/604#issuecomment-1843585454,https://api.github.com/repos/simonw/sqlite-utils/issues/604,1843585454,IC_kwDOCGYnMM5t4uGu,22429695,codecov[bot],2023-12-06T19:48:26Z,2023-12-08T05:05:03Z,NONE,"## [Codecov](https://app.codecov.io/gh/simonw/sqlite-utils/pull/604?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report
All modified and coverable lines are covered by tests :white_check_mark:
> Comparison is base [(`9286c1b`)](https://app.codecov.io/gh/simonw/sqlite-utils/commit/9286c1ba432e890b1bb4b2a1f847b15364c1fa18?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 95.77% compared to head [(`1698a9d`)](https://app.codecov.io/gh/simonw/sqlite-utils/pull/604?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 95.72%.
> Report is 1 commits behind head on main.
> :exclamation: Current head 1698a9d differs from pull request most recent head 61c6e26. Consider uploading reports for the commit 61c6e26 to get more accurate results
Additional details and impacted files
```diff
@@ Coverage Diff @@
## main #604 +/- ##
==========================================
- Coverage 95.77% 95.72% -0.06%
==========================================
Files 8 8
Lines 2842 2852 +10
==========================================
+ Hits 2722 2730 +8
- Misses 120 122 +2
```
[:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/simonw/sqlite-utils/pull/604?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison).
:loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison).
","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",2001006157,Add more STRICT table support,"{""id"": 254, ""slug"": ""codecov"", ""node_id"": ""MDM6QXBwMjU0"", ""owner"": {""login"": ""codecov"", ""id"": 8226205, ""node_id"": ""MDEyOk9yZ2FuaXphdGlvbjgyMjYyMDU="", ""avatar_url"": ""https://avatars.githubusercontent.com/u/8226205?v=4"", ""gravatar_id"": """", ""url"": ""https://api.github.com/users/codecov"", ""html_url"": ""https://github.com/codecov"", ""followers_url"": ""https://api.github.com/users/codecov/followers"", ""following_url"": ""https://api.github.com/users/codecov/following{/other_user}"", ""gists_url"": ""https://api.github.com/users/codecov/gists{/gist_id}"", ""starred_url"": ""https://api.github.com/users/codecov/starred{/owner}{/repo}"", ""subscriptions_url"": ""https://api.github.com/users/codecov/subscriptions"", ""organizations_url"": ""https://api.github.com/users/codecov/orgs"", ""repos_url"": ""https://api.github.com/users/codecov/repos"", ""events_url"": ""https://api.github.com/users/codecov/events{/privacy}"", ""received_events_url"": ""https://api.github.com/users/codecov/received_events"", ""type"": ""Organization"", ""site_admin"": false}, ""name"": ""Codecov"", ""description"": ""Codecov provides highly integrated tools to group, merge, archive and compare coverage reports. Whether your team is comparing changes in a pull request or reviewing a single commit, Codecov will improve the code review workflow and quality.\r\n\r\n## Code coverage done right.®\r\n\r\n1. Upload coverage reports from your CI builds.\r\n2. Codecov merges all builds and languages into one beautiful coherent report.\r\n3. Get commit statuses, pull request comments and coverage overlay via our browser extension.\r\n\r\nWhen Codecov merges your uploads it keeps track of the CI provider (inc. build details) and user specified context, e.g. `#unittest` ~ `#smoketest` or `#oldcode` ~ `#newcode`. You can track the `#unittest` coverage independently of other groups. [Learn more here](\r\nhttp://docs.codecov.io/docs/flags)\r\n\r\nThrough **Codecov's Browser Extension** reports overlay directly in GitHub UI to assist in code review in [Chrome](https://chrome.google.com/webstore/detail/codecov/gedikamndpbemklijjkncpnolildpbgo) or Firefox (https://addons.mozilla.org/en-US/firefox/addon/codecov/)\r\n\r\n*Highly detailed* **pull request comments** and *customizable* **commit statuses** will improve your team's workflow and code coverage incrementally.\r\n\r\n**File backed configuration** all through the `codecov.yml`. \r\n\r\n## FAQ\r\n- Do you **merge multiple uploads** to the same commit? **Yes**\r\n- Do you **support multiple languages** in the same project? **Yes**\r\n- Can you **group coverage reports** by project and/or test type? **Yes**\r\n- How does **pricing** work? Only paid users can view reports and post statuses/comments. "", ""external_url"": ""https://codecov.io"", ""html_url"": ""https://github.com/apps/codecov"", ""created_at"": ""2016-09-25T14:18:27Z"", ""updated_at"": ""2023-09-08T15:29:16Z"", ""permissions"": {""administration"": ""read"", ""checks"": ""write"", ""contents"": ""read"", ""emails"": ""read"", ""issues"": ""read"", ""members"": ""read"", ""metadata"": ""read"", ""pull_requests"": ""write"", ""statuses"": ""write""}, ""events"": [""check_run"", ""check_suite"", ""create"", ""delete"", ""fork"", ""member"", ""membership"", ""organization"", ""public"", ""pull_request"", ""push"", ""release"", ""repository"", ""status"", ""team_add""]}"
https://github.com/simonw/datasette/issues/2214#issuecomment-1844819002,https://api.github.com/repos/simonw/datasette/issues/2214,1844819002,IC_kwDOBm6k_c5t9bQ6,2874,precipice,2023-12-07T07:36:33Z,2023-12-07T07:36:33Z,NONE,"If I uncheck `expand labels` in the Advanced CSV export dialog, the error does not occur. Re-checking that box and re-running the export does cause the error to occur.

","{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",2029908157,CSV export fails for some `text` foreign key references,
https://github.com/dogsheep/github-to-sqlite/issues/79#issuecomment-1847317568,https://api.github.com/repos/dogsheep/github-to-sqlite/issues/79,1847317568,IC_kwDODFdgUs5uG9RA,23789,nedbat,2023-12-08T14:50:13Z,2023-12-08T14:50:13Z,NONE,Adding `&per_page=100` would reduce the number of API requests by 3x.,"{""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1570375808,Deploy demo job is failing due to rate limit,
https://github.com/simonw/datasette/issues/782#issuecomment-782745199,https://api.github.com/repos/simonw/datasette/issues/782,782745199,MDEyOklzc3VlQ29tbWVudDc4Mjc0NTE5OQ==,30665,frankieroberto,2021-02-20T20:32:03Z,2021-02-20T20:32:03Z,NONE,"I think it’s a good idea if the top level item of the response JSON is always an object, rather than an array, at least as the default. Mainly because it allows you to add extra keys in a backwards-compatible way. Also just seems more expected somehow.
The API design guidance for the UK government also recommends this: https://www.gov.uk/guidance/gds-api-technical-and-data-standards#use-json
I also strongly dislike having versioned APIs (eg with a `/v1/` path prefix, as it invariably means that old versions stop working at some point, even though the bit of the API you’re using might not have changed at all.","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 1}",627794879,Redesign default .json format,
https://github.com/simonw/datasette/issues/260#issuecomment-1235079469,https://api.github.com/repos/simonw/datasette/issues/260,1235079469,IC_kwDOBm6k_c5JndEt,596279,zaneselvans,2022-09-02T05:24:59Z,2022-09-02T05:24:59Z,NONE,@zschira is working with Pydantic while converting between and validating JSON frictionless datapackage descriptors that annotate an SQLite DB ([extracted from FERC's XBRL data](https://github.com/catalyst-cooperative/ferc-xbrl-extractor)) and the Datasette YAML metadata [so we can publish them with Datasette](https://github.com/catalyst-cooperative/pudl/pull/1831). Maybe there's some overlap? We've been loving Pydantic.,"{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 1}",323223872,Validate metadata.json on startup,
https://github.com/simonw/datasette/pull/1870#issuecomment-1745568725,https://api.github.com/repos/simonw/datasette/issues/1870,1745568725,IC_kwDOBm6k_c5oC0PV,2495794,jdangerx,2023-10-03T19:12:37Z,2023-10-03T19:12:37Z,NONE,"Hello! Resurrecting this issue since we're running into something similar with data.catalyst.coop as our database files have ballooned up to several GB. Our Cloud Run revisions now require huge amounts of RAM to start up without receiving a SIGBUS.
I'd love to see this fix merged in. It sounds like we want to make the immutable/read-only mode decision more flexible before doing so, so that we can use `ro` in Docker and `immutable` outside. If that sounds right, I'm happy to take a crack at adding that as a command-line flag or something that gets set automatically based on the expected execution environment.","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 1}",1426379903,"don't use immutable=1, only mode=ro",
https://github.com/simonw/datasette/issues/187#issuecomment-489353316,https://api.github.com/repos/simonw/datasette/issues/187,489353316,MDEyOklzc3VlQ29tbWVudDQ4OTM1MzMxNg==,46059,carsonyl,2019-05-04T18:36:36Z,2019-05-04T18:36:36Z,NONE,"Hi @simonw - I just hit this issue when trying out Datasette after your PyCon talk today. Datasette is pinned to Sanic 0.7.0, but it looks like 0.8.0 added the option to remove the uvloop dependency for Windows by having an environment variable `SANIC_NO_UVLOOP` at install time. Maybe that'll be sufficient before a port to Starlette?","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 1, ""eyes"": 0}",309033998,Windows installation error,
https://github.com/simonw/datasette/issues/1091#issuecomment-758280611,https://api.github.com/repos/simonw/datasette/issues/1091,758280611,MDEyOklzc3VlQ29tbWVudDc1ODI4MDYxMQ==,6739646,tballison,2021-01-11T23:06:10Z,2021-01-11T23:06:10Z,NONE,"+1
Yep! Fixes it. If I navigate to https://corpora.tika.apache.org/datasette, I get a 404 (database not found: datasette), but if I navigate to https://corpora.tika.apache.org/datasette/file_profiles/, everything WORKS!
Thank you!","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 1, ""eyes"": 0}",742011049,.json and .csv exports fail to apply base_url,
https://github.com/simonw/datasette/issues/1415#issuecomment-1255603780,https://api.github.com/repos/simonw/datasette/issues/1415,1255603780,IC_kwDOBm6k_c5K1v5E,17532695,bendnorman,2022-09-22T22:06:10Z,2022-09-22T22:06:10Z,NONE,"This would be great! I just went through the process of figuring out the minimum permissions for a service account to run `datasette publish cloudrun` for [PUDL](https://github.com/catalyst-cooperative/pudl)'s [datasette deployment](https://data.catalyst.coop/). These are the roles I gave the service account (disclaim: I'm not sure these are the minimum permissions):
- Cloud Build Service Account: The SA needs this role to publish the build on Cloud Build.
- Cloud Run Admin for the Cloud Run datasette service so the SA can deploy the build.
- I gave the SA the Storage Admin role on the bucket Cloud Build creates to store the build tar files.
- The Viewer Role is [required for storing build logs in the default bucket](https://cloud.google.com/build/docs/running-builds/submit-build-via-cli-api#permissions). More on this below!
The Viewer Role is a Basic IAM role that [Google does not recommend using](https://cloud.google.com/build/docs/running-builds/submit-build-via-cli-api#permissions):
> Caution: Basic roles include thousands of permissions across all Google Cloud services. In production environments, do not grant basic roles unless there is no alternative. Instead, grant the most limited [predefined roles](https://cloud.google.com/iam/docs/understanding-roles#predefined_roles) or [custom roles](https://cloud.google.com/iam/docs/understanding-custom-roles) that meet your needs.
If you don't grant the Viewer role the `gcloud builds submit` command will successfully create a build but returns exit code 1, preventing the script from getting to the cloud run step:
```
ERROR: (gcloud.builds.submit)
The build is running, and logs are being written to the default logs bucket.
This tool can only stream logs if you are Viewer/Owner of the project and, if applicable, allowed by your VPC-SC security policy.
The default logs bucket is always outside any VPC-SC security perimeter.
If you want your logs saved inside your VPC-SC perimeter, use your own bucket.
See https://cloud.google.com/build/docs/securing-builds/store-manage-build-logs.
```
long stack trace...
```
CalledProcessError: Command 'gcloud builds submit --tag gcr.io/catalyst-cooperative-pudl/datasette' returned non-zero exit status 1.
```
You can store Cloud Build logs in a [user-created bucket](https://cloud.google.com/build/docs/securing-builds/store-manage-build-logs#store-custom-bucket) which only requires the Storage Admin role. However, you have to pass a config file to `gcloud builds submit`, which isn't possible with the current options for `datasette publish cloudrun`.
I propose we add an additional CLI option to `datasette publish cloudrun` called `--build-config` that allows users to pass a [config file](https://cloud.google.com/build/docs/running-builds/submit-build-via-cli-api#running_builds) specifying a user create Cloud Build log bucket. ","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 1, ""eyes"": 0}",959137143,feature request: document minimum permissions for service account for cloudrun,
https://github.com/simonw/datasette/issues/594#issuecomment-547373739,https://api.github.com/repos/simonw/datasette/issues/594,547373739,MDEyOklzc3VlQ29tbWVudDU0NzM3MzczOQ==,2680980,willingc,2019-10-29T11:21:52Z,2019-10-29T11:21:52Z,NONE,"Just an FYI for folks wishing to run datasette with Python 3.8, I was able to successfully use datasette with the following in a virtual environment:
```
pip install uvloop==0.14.0rc1
pip install uvicorn==0.9.1
```
","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 1, ""rocket"": 0, ""eyes"": 0}",506297048,upgrade to uvicorn-0.9 to be Python-3.8 friendly,
https://github.com/simonw/datasette/issues/394#issuecomment-642522285,https://api.github.com/repos/simonw/datasette/issues/394,642522285,MDEyOklzc3VlQ29tbWVudDY0MjUyMjI4NQ==,58298410,LVerneyPEReN,2020-06-11T09:15:19Z,2020-06-11T09:15:19Z,NONE,"Hi @wragge,
This looks great, thanks for the share! I refactored it into a self-contained function, binding on a random available TCP port (multi-user context). I am using subprocess API directly since the `%run` magic was leaving defunct process behind :/

```python
import socket
from signal import SIGINT
from subprocess import Popen, PIPE
from IPython.display import display, HTML
from notebook.notebookapp import list_running_servers
def get_free_tcp_port():
""""""
Get a free TCP port.
""""""
tcp = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp.bind(('', 0))
_, port = tcp.getsockname()
tcp.close()
return port
def datasette(database):
""""""
Run datasette on an SQLite database.
""""""
# Get current running servers
servers = list_running_servers()
# Get the current base url
base_url = next(servers)['base_url']
# Get a free port
port = get_free_tcp_port()
# Create a base url for Datasette suing the proxy path
proxy_url = f'{base_url}proxy/absolute/{port}/'
# Display a link to Datasette
display(HTML(f'
View Datasette (Click on the stop button to close the Datasette server)
'))
# Launch Datasette
with Popen(
[
'python', '-m', 'datasette', '--',
database,
'--port', str(port),
'--config', f'base_url:{proxy_url}'
],
stdout=PIPE,
stderr=PIPE,
bufsize=1,
universal_newlines=True
) as p:
print(p.stdout.readline(), end='')
while True:
try:
line = p.stderr.readline()
if not line:
break
print(line, end='')
exit_code = p.poll()
except KeyboardInterrupt:
p.send_signal(SIGINT)
```
Ideally, I'd like some extra magic to notify users when they are leaving the closing the notebook tab and make them terminate the running datasette processes. I'll be looking for it.","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 1, ""rocket"": 0, ""eyes"": 0}",396212021,base_url configuration setting,
https://github.com/simonw/datasette/issues/1171#issuecomment-754911290,https://api.github.com/repos/simonw/datasette/issues/1171,754911290,MDEyOklzc3VlQ29tbWVudDc1NDkxMTI5MA==,59874,rcoup,2021-01-05T21:31:15Z,2021-01-05T21:31:15Z,NONE,"We did this for [Sno](https://sno.earth) under macOS — it's a PyInstaller binary/setup which uses [Packages](http://s.sudre.free.fr/Software/Packages/about.html) for packaging.
* [Building & Signing](https://github.com/koordinates/sno/blob/master/platforms/Makefile#L67-L95)
* [Packaging & Notarizing](https://github.com/koordinates/sno/blob/master/platforms/Makefile#L121-L215)
* [Github Workflow](https://github.com/koordinates/sno/blob/master/.github/workflows/build.yml#L228-L269) has the CI side of it
FYI (if you ever get to it) for Windows you need to get a code signing certificate. And if you want automated CI, you'll want to get an ""EV CodeSigning for HSM"" certificate from GlobalSign, which then lets you put the certificate into Azure Key Vault. Which you can use with [azuresigntool](https://github.com/vcsjones/AzureSignTool) to sign your code & installer. (Non-EV certificates are a waste of time, the user still gets big warnings at install time).
","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 1, ""rocket"": 0, ""eyes"": 0}",778450486,GitHub Actions workflow to build and sign macOS binary executables,
https://github.com/simonw/datasette/issues/1528#issuecomment-988468238,https://api.github.com/repos/simonw/datasette/issues/1528,988468238,IC_kwDOBm6k_c466tQO,30934,20after4,2021-12-08T03:35:45Z,2021-12-08T03:35:45Z,NONE,"FWIW I implemented something similar with a bit of plugin code:
```python
@hookimpl
def canned_queries(datasette: Datasette, database: str) -> Mapping[str, str]:
# load ""canned queries"" from the filesystem under
# www/sql/db/query_name.sql
queries = {}
sqldir = Path(__file__).parent.parent / ""sql""
if database:
sqldir = sqldir / database
if not sqldir.is_dir():
return queries
for f in sqldir.glob('*.sql'):
try:
sql = f.read_text('utf8').strip()
if not len(sql):
log(f""Skipping empty canned query file: {f}"")
continue
queries[f.stem] = { ""sql"": sql }
except OSError as err:
log(err)
return queries
```","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 1, ""rocket"": 0, ""eyes"": 0}",1060631257,"Add new `""sql_file""` key to Canned Queries in metadata?",
https://github.com/simonw/datasette/pull/2052#issuecomment-1722943484,https://api.github.com/repos/simonw/datasette/issues/2052,1722943484,IC_kwDOBm6k_c5msgf8,30934,20after4,2023-09-18T08:14:47Z,2023-09-18T08:14:47Z,NONE,This is such a well thought out contribution. I don't think I've seen such a thoroughly considered PR on any project in recent memory.,"{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 1, ""rocket"": 0, ""eyes"": 0}",1651082214,"feat: Javascript Plugin API (Custom panels, column menu items with JS actions)",
https://github.com/simonw/datasette/issues/1994#issuecomment-1399957897,https://api.github.com/repos/simonw/datasette/issues/1994,1399957897,IC_kwDOBm6k_c5TcamJ,201897,julienma,2023-01-23T08:21:08Z,2023-01-23T08:21:08Z,NONE,"Me too, on a M1. Not sure if it's compatible?","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 1, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1536851861,Stuck on loading screen,
https://github.com/simonw/datasette/issues/1310#issuecomment-829885904,https://api.github.com/repos/simonw/datasette/issues/1310,829885904,MDEyOklzc3VlQ29tbWVudDgyOTg4NTkwNA==,3747136,ColinMaudry,2021-04-30T06:58:46Z,2021-04-30T07:26:11Z,NONE,"I made it work with openpyxl. I'm not sure all the code under `@hookimpl` is necessary... but it works :)
```python
from datasette import hookimpl
from datasette.utils.asgi import Response
from openpyxl import Workbook
from openpyxl.writer.excel import save_virtual_workbook
from openpyxl.cell import WriteOnlyCell
from openpyxl.styles import Alignment, Font, PatternFill
from tempfile import NamedTemporaryFile
def render_spreadsheet(rows):
wb = Workbook(write_only=True)
ws = wb.create_sheet()
ws = wb.active
ws.title = ""decp""
columns = rows[0].keys()
headers = []
for col in columns :
c = WriteOnlyCell(ws, col)
c.fill = PatternFill(""solid"", fgColor=""DDEFFF"")
headers.append(c)
ws.append(headers)
for row in rows:
wsRow = []
for col in columns:
c = WriteOnlyCell(ws, row[col])
if col == ""objet"" :
c.alignment = Alignment(wrapText = True)
wsRow.append(c)
ws.append(wsRow)
with NamedTemporaryFile() as tmp:
wb.save(tmp.name)
tmp.seek(0)
return Response(
tmp.read(),
headers={
'Content-Disposition': 'attachment; filename=decp.xlsx',
'Content-type': 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'
}
)
@hookimpl
def register_output_renderer():
return {""extension"": ""xlsx"",
""render"": render_spreadsheet,
""can_render"": lambda: False}
```
The key part was to find the right function to wrap the spreadsheet object `wb`. `NamedTemporaryFile()` did it!
I'll update this issue when the plugin is packaged and ready for broader use.","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 1, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",870125126,I'm creating a plugin to export a spreadsheet file (.ods or .xlsx),
https://github.com/simonw/datasette/issues/1380#issuecomment-967801997,https://api.github.com/repos/simonw/datasette/issues/1380,967801997,IC_kwDOBm6k_c45r3yN,7094907,Segerberg,2021-11-13T08:05:37Z,2021-11-13T08:09:11Z,NONE,"@glasnt yeah I guess that could be an option. I run datasette on large databases > 75gb and the startup time is a bit slow for me even with -i --inspect-file options. Here's a quick sketch for a plugin that will reload db's in a folder that you set for the plugin in metadata.json. If you request /-reload-db new db's will be added. (You probably want to implement some authentication for this =) )
https://gist.github.com/Segerberg/b96a0e0a5389dce2396497323cda7042
","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 1, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",924748955,Serve all db files in a folder,
https://github.com/simonw/datasette/issues/1886#issuecomment-1312898318,https://api.github.com/repos/simonw/datasette/issues/1886,1312898318,IC_kwDOBm6k_c5OQT0O,19851673,eigenfoo,2022-11-14T00:52:16Z,2022-11-14T00:52:16Z,NONE,"I'm a cryptic crossword enthusiast and have spent a lot of time scraping and parsing cryptic crossword clues from various blogs, forums and publications. The result is over **half a million clues from cryptic crosswords over the past twelve years**, including the clue, answer, puzzle date, puzzle name and a link to the original source. This is all hosted using Datasette, which has been a delight to use: https://cryptics.georgeho.org/
This dataset is a significant work of crossword archivism and scholarship, as acquiring historical crosswords and structuring their contents require focused effort and tedious cleaning that few are willing to do for such trivial data - for example, according to [this 2004 selection guide](https://cryptics.georgeho.org/static/documents/Selection_AppendixE_v2.pdf), the Library of Congress explicitly does not collect crossword puzzles. Anecdotally, I know that many constructors/setters of cryptic crosswords use this dataset as a resource, and some even simply call it ""the database"" - this is probably one of the most impactful data projects I've worked on!","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 1, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1447050738,"Call for birthday presents: if you're using Datasette, let us know how you're using it here",
https://github.com/simonw/datasette/issues/394#issuecomment-602916580,https://api.github.com/repos/simonw/datasette/issues/394,602916580,MDEyOklzc3VlQ29tbWVudDYwMjkxNjU4MA==,132978,terrycojones,2020-03-23T23:37:06Z,2020-03-23T23:37:06Z,NONE,"@simonw You're welcome - I was just trying it out back in December as I thought it should work. Now there's a pandemic to work on though.... so no time at all for more at the moment. BTW, I have datasette running on several protein and full (virus) genome databases I build, and it's great - thank you! Hi and best regards to you & Nat :-)","{""total_count"": 1, ""+1"": 0, ""-1"": 0, ""laugh"": 1, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",396212021,base_url configuration setting,
https://github.com/simonw/datasette/issues/176#issuecomment-431867885,https://api.github.com/repos/simonw/datasette/issues/176,431867885,MDEyOklzc3VlQ29tbWVudDQzMTg2Nzg4NQ==,634572,eads,2018-10-22T15:24:57Z,2018-10-22T15:24:57Z,NONE,"I'd like this as well. It would let me access Datasette-driven projects from GatsbyJS the same way I can access Postgres DBs via Hasura. While I don't see SQLite replacing Postgres for the 50m row datasets I sometimes have to work with, there's a whole class of smaller datasets that are great with Datasette but currently would find another option.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",285168503,Add GraphQL endpoint,
https://github.com/simonw/datasette/issues/120#issuecomment-439421164,https://api.github.com/repos/simonw/datasette/issues/120,439421164,MDEyOklzc3VlQ29tbWVudDQzOTQyMTE2NA==,36796532,ad-si,2018-11-16T15:05:18Z,2018-11-16T15:05:18Z,NONE,This would be an awesome feature ❤️ ,"{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",275087397,Plugin that adds an authentication layer of some sort,
https://github.com/simonw/datasette/issues/514#issuecomment-509154312,https://api.github.com/repos/simonw/datasette/issues/514,509154312,MDEyOklzc3VlQ29tbWVudDUwOTE1NDMxMg==,4363711,JesperTreetop,2019-07-08T09:36:25Z,2019-07-08T09:40:33Z,NONE,"@chrismp: Ports 1024 and under are privileged and can usually only be bound by a root or supervisor user, so it makes sense if you're running as the user `chris` that port 8000 works but 80 doesn't.
See [this generic question-and-answer](https://superuser.com/questions/710253/allow-non-root-process-to-bind-to-port-80-and-443) and [this systemd question-and-answer](https://stackoverflow.com/questions/40865775/linux-systemd-service-on-port-80) for more information about ways to skin this cat. Without knowing your specific circumstances, either extending those privileges to that service/executable/user, proxying them through something like nginx or indeed looking at what the nginx systemd job has to do to listen at port 80 all sound like good ways to start.
At this point, this is more generic systemd/Linux support than a Datasette issue, which is why a complete rando like me is able to contribute anything. ","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",459397625,Documentation with recommendations on running Datasette in production without using Docker,
https://github.com/simonw/datasette/issues/662#issuecomment-579798917,https://api.github.com/repos/simonw/datasette/issues/662,579798917,MDEyOklzc3VlQ29tbWVudDU3OTc5ODkxNw==,2181410,clausjuhl,2020-01-29T15:08:57Z,2020-01-29T15:08:57Z,NONE,"Hi Simon
Thankt you for a quick reply. Here are a few examples of urls, where I search the 'cases_fts'-virtual table for tokens in the title-column. It returns the same results, wether the other query-params are present or not.
Searching for sky
http://localhost:8001/db-7596a4e/cases?_search_title=sky&year__gte=1997&year__lte=2017&_sort_desc=last_deliberation_date
Returns searchresults
Searching for sky*
http://localhost:8001/db-7596a4e/cases?_search_title=sky*&year__gte=1997&year__lte=2017&_sort_desc=last_deliberation_date
Returns searchresults
Searching for sky-tog
http://localhost:8001/db-7596a4e/cases?_search_title=sky-tog&year__gte=1997&year__lte=2017&_sort_desc=last_deliberation_date
Throws: No such column: tog
searching for sky+
http://localhost:8001/db-7596a4e/cases?_search_title=sky%2B&year__gte=1997&year__lte=2017&_sort_desc=last_deliberation_date
Throws: Invalid SQL: fts5: syntax error near """"
Searching for ""madpakke"" (including double quotes)
http://localhost:8001/db-7596a4e/cases?_search_title=%22madpakke%22&year__gte=1997&year__lte=2017&_sort_desc=last_deliberation_date
Returns searchresults even though 'madpakke' only appears in the fulltextindex without quotes
As I said, my other plugins work just fine, and I just copied your sql_functions.py from the datasette-repo.
Thanks!","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",556814876,Escape_fts5_query-hookimplementation does not work with queries to standard tables,
https://github.com/simonw/datasette/issues/662#issuecomment-579864036,https://api.github.com/repos/simonw/datasette/issues/662,579864036,MDEyOklzc3VlQ29tbWVudDU3OTg2NDAzNg==,2181410,clausjuhl,2020-01-29T17:17:01Z,2020-01-29T17:17:01Z,NONE,This is excellent news. I'll wait until version 0.34. It would be tiresome to rewrite all standard-queries into custom queries. Thank you!,"{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",556814876,Escape_fts5_query-hookimplementation does not work with queries to standard tables,
https://github.com/simonw/datasette/issues/176#issuecomment-617208503,https://api.github.com/repos/simonw/datasette/issues/176,617208503,MDEyOklzc3VlQ29tbWVudDYxNzIwODUwMw==,12976,nkirsch,2020-04-21T14:16:24Z,2020-04-21T14:16:24Z,NONE,"@eads I'm interested in helping, if there's still a need...","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",285168503,Add GraphQL endpoint,
https://github.com/dogsheep/github-to-sqlite/issues/33#issuecomment-622279374,https://api.github.com/repos/dogsheep/github-to-sqlite/issues/33,622279374,MDEyOklzc3VlQ29tbWVudDYyMjI3OTM3NA==,2029,garethr,2020-05-01T07:12:47Z,2020-05-01T07:12:47Z,NONE,"I also go it working with:
```yaml
run: echo ${{ secrets.github_token }} | github-to-sqlite auth
```","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",609950090,Fall back to authentication via ENV,
https://github.com/dogsheep/twitter-to-sqlite/issues/50#issuecomment-691501132,https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/50,691501132,MDEyOklzc3VlQ29tbWVudDY5MTUwMTEzMg==,706257,bcongdon,2020-09-12T14:48:10Z,2020-09-12T14:48:10Z,NONE,"This seems to be an issue even with larger values of `--stop_after`:
```
$ twitter-to-sqlite favorites twitter.db --stop_after=2000
Importing favorites [####################################] 198
$
```","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",698791218,"favorites --stop_after=N stops after min(N, 200)",
https://github.com/simonw/datasette/issues/619#issuecomment-697973420,https://api.github.com/repos/simonw/datasette/issues/619,697973420,MDEyOklzc3VlQ29tbWVudDY5Nzk3MzQyMA==,45416,obra,2020-09-23T21:07:58Z,2020-09-23T21:07:58Z,NONE,"I've just run into this after crafting a complex query and discovered that hitting back loses my query.
Even showing me the whole bad query would be a huge improvement over the current status quo.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",520655983,"""Invalid SQL"" page should let you edit the SQL",
https://github.com/simonw/datasette/issues/782#issuecomment-712569695,https://api.github.com/repos/simonw/datasette/issues/782,712569695,MDEyOklzc3VlQ29tbWVudDcxMjU2OTY5NQ==,222245,carlmjohnson,2020-10-20T03:45:48Z,2020-10-20T03:46:14Z,NONE,"I vote against headers. It has a lot of strikes against it: poor discoverability, new developers often don’t know how to use them, makes CORS harder, makes it hard to use eg with JQ, needs ad hoc specification for each bit of metadata, etc.
The only advantage of headers is that you don’t need to do .rows, but that’s actually good as a data validation step anyway—if .rows is missing assume there’s an error and do your error handling path instead of parsing the rest.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",627794879,Redesign default .json format,
https://github.com/simonw/datasette/issues/766#issuecomment-741665253,https://api.github.com/repos/simonw/datasette/issues/766,741665253,MDEyOklzc3VlQ29tbWVudDc0MTY2NTI1Mw==,2181410,clausjuhl,2020-12-09T09:59:05Z,2020-12-09T09:59:05Z,NONE,Hi Simon. Any news on using wildcard-searches with datasette? Thanks!,"{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",617323873,Enable wildcard-searches by default,
https://github.com/simonw/datasette/issues/1142#issuecomment-743998792,https://api.github.com/repos/simonw/datasette/issues/1142,743998792,MDEyOklzc3VlQ29tbWVudDc0Mzk5ODc5Mg==,6622733,nitinpaultifr,2020-12-13T12:14:06Z,2020-12-13T12:14:06Z,NONE,"Agreed, it would definitely provide better controls. However, I do feel it makes for a bit of inconsistent UX for the 'Advanced export' section, with links to download for JSON, checkboxes and radio buttons + button to download for CSV. Do you think this example makes the UX a bit nicer/consistent?

I could give it a try if you'd like but I've never contributed to an actual project!
","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",763361458,"""Stream all rows"" is not at all obvious",
https://github.com/simonw/datasette/issues/276#issuecomment-744461856,https://api.github.com/repos/simonw/datasette/issues/276,744461856,MDEyOklzc3VlQ29tbWVudDc0NDQ2MTg1Ng==,296686,robintw,2020-12-14T14:04:57Z,2020-12-14T14:04:57Z,NONE,"I'm looking into using datasette with a database with spatialite geometry columns, and came across this issue. Has there been any progress on this since 2018?
In one of my tables I'm just storing lat/lon points in a spatialite point geometry, and I've managed to make datasette-cluster-map display the points by extracting the lat and lon in SQL - using something like `select ... ST_X(location) as longitude, ST_Y(location) as latitude from Blah`. Something more 'built-in' would be great though - particularly for the tables I have that store more complex geometries.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",324835838,Handle spatialite geometry columns better,
https://github.com/simonw/datasette/issues/1144#issuecomment-744489028,https://api.github.com/repos/simonw/datasette/issues/1144,744489028,MDEyOklzc3VlQ29tbWVudDc0NDQ4OTAyOA==,475613,MarkusH,2020-12-14T14:47:11Z,2020-12-14T14:47:11Z,NONE,"Thanks for opening the issue, @simonw. Let me elaborate on my Tweets.
[datasette-chartjs](https://github.com/MarkusH/datasette-chartjs) provides drop down lists to pick the chart visualization (e.g. bar, line, doughnut, pie, ...) as well as the column used for the ""x axis"" (e.g. time).
A user can change the values on-demand. The chart will be redrawn w/o querying the database again.
However, if a user wants to change the underlying query, they will use the SQL field provided by datasette or any of the other datasette built-in features to amend a query. In order to maintain a user's selections for the plugin, datasette-chartjs copies some parts of [datasette-vega](https://github.com/simonw/datasette-vega) which persist the chosen visualization and column in the hash part of a URL (the stuff behind the `#`). The plugin load the config from the hash upon initialization on the next page and use it accordingly.
Additionally, datasette-vega and datasette-chartjs need to make sure to include the hash in all links and forms that cause a reload of the page. This is, such that the config persists between clicks.
This ticket is about moving thes parts into datasette that provide the functionality to do so. This includes:
1. a way to load config options with a given prefix from the current URL hash
1. a way to update the current URL hash with a new config value or a bunch of config options
1. updating all necessary links and forms on the current page to include the URL hash whenever its updated
1. to prevent leaking config options to external pages, only ""internal"" links should be updated
There's another, optional, feature that we might want to think about during the design phase: the scope of the config. Links within a datasette instance have 1 of 3 scopes:
1. global, for the whole datasette project
1. database, for all tables in a database
1. table, only for a table within a database
When updating the links and forms as pointed out in 3. above, it might be worth considering which links need to be updated. I could imagine a plugin that wants to persist some setting across all tables within a database but another setting only within a table.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",765637324,JavaScript to help plugins interact with the fragment part of the URL,
https://github.com/simonw/datasette/issues/1142#issuecomment-744522099,https://api.github.com/repos/simonw/datasette/issues/1142,744522099,MDEyOklzc3VlQ29tbWVudDc0NDUyMjA5OQ==,6622733,nitinpaultifr,2020-12-14T15:37:47Z,2020-12-14T15:37:47Z,NONE,"Alright I could give it a try! This might be a stupid question, can you tell me how to run the server from my fork? So that I can test the changes?","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",763361458,"""Stream all rows"" is not at all obvious",
https://github.com/simonw/sqlite-utils/issues/220#issuecomment-761015218,https://api.github.com/repos/simonw/sqlite-utils/issues/220,761015218,MDEyOklzc3VlQ29tbWVudDc2MTAxNTIxOA==,649467,mhalle,2021-01-15T15:40:08Z,2021-01-15T15:40:08Z,NONE,"Make sense. If you're coming from the sqlite3 side of things, rather than the datasette side, wanting the fts methods to work for views makes more sense. sqlite3 allows fts5 tables on views, so I was looking for CLI functionality to build the fts virtual tables. Ultimately, though, sharing fts virtual tables across tables and derivative views is likely more efficient.
Maybe an explicit error message like, ""fts is not supported for views"" rather than just throwing an exception that the method doesn't exist"" might be helpful. Not critical though.
Thanks.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",783778672,Better error message for *_fts methods against views,
https://github.com/simonw/datasette/issues/1217#issuecomment-774385092,https://api.github.com/repos/simonw/datasette/issues/1217,774385092,MDEyOklzc3VlQ29tbWVudDc3NDM4NTA5Mg==,6165713,plpxsk,2021-02-06T02:49:11Z,2021-02-06T02:49:11Z,NONE,"A good reference seems to be the note to run `datasette` as a module in https://github.com/simonw/datasette/pull/556
","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",802513359,Possible to deploy as a python app (for Rstudio connect server)?,
https://github.com/simonw/datasette/issues/1220#issuecomment-778467759,https://api.github.com/repos/simonw/datasette/issues/1220,778467759,MDEyOklzc3VlQ29tbWVudDc3ODQ2Nzc1OQ==,30607,aborruso,2021-02-12T21:35:17Z,2021-02-12T21:35:17Z,NONE,Thank you,"{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",806743116,Installing datasette via docker: Path 'fixtures.db' does not exist,
https://github.com/dogsheep/google-takeout-to-sqlite/issues/4#issuecomment-790198930,https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/4,790198930,MDEyOklzc3VlQ29tbWVudDc5MDE5ODkzMA==,203343,Btibert3,2021-03-04T00:58:40Z,2021-03-04T00:58:40Z,NONE,"I am just seeing this sorry, yes! I will kick the tires later on tonight. My apologies for the delay.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",778380836,Feature Request: Gmail,
https://github.com/dogsheep/google-takeout-to-sqlite/pull/5#issuecomment-790389335,https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/5,790389335,MDEyOklzc3VlQ29tbWVudDc5MDM4OTMzNQ==,306240,UtahDave,2021-03-04T07:32:04Z,2021-03-04T07:32:04Z,NONE,"> The command takes quite a while to start running, presumably because this line causes it to have to scan the WHOLE file in order to generate a count:
>
> https://github.com/dogsheep/google-takeout-to-sqlite/blob/a3de045eba0fae4b309da21aa3119102b0efc576/google_takeout_to_sqlite/utils.py#L66-L67
>
> I'm fine with waiting though. It's not like this is a command people run every day - and without that count we can't show a progress bar, which seems pretty important for a process that takes this long.
The wait is from python loading the mbox file. This happens regardless if you're getting the length of the mbox. The mbox module is on the slow side. It is possible to do one's own parsing of the mbox, but I kind of wanted to avoid doing that.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",813880401,WIP: Add Gmail takeout mbox import,
https://github.com/simonw/datasette/issues/1238#issuecomment-790857004,https://api.github.com/repos/simonw/datasette/issues/1238,790857004,MDEyOklzc3VlQ29tbWVudDc5MDg1NzAwNA==,79913,tsibley,2021-03-04T19:06:55Z,2021-03-04T19:06:55Z,NONE,"@rgieseke Ah, that's super helpful. Thank you for the workaround for now!","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",813899472,Custom pages don't work with base_url setting,
https://github.com/simonw/sqlite-utils/issues/159#issuecomment-802032152,https://api.github.com/repos/simonw/sqlite-utils/issues/159,802032152,MDEyOklzc3VlQ29tbWVudDgwMjAzMjE1Mg==,1025224,limar,2021-03-18T15:42:52Z,2021-03-18T15:42:52Z,NONE,"I confirm the bug. Happens for me in version 3.6. I use the call to delete all the records:
`table.delete_where()`
This does not delete anything.
I see that `delete()` method DOES use context manager `with self.db.conn:` which should help. You may want to align the code of both methods.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",702386948,.delete_where() does not auto-commit (unlike .insert() or .upsert()),
https://github.com/dogsheep/dogsheep-photos/pull/31#issuecomment-811362316,https://api.github.com/repos/dogsheep/dogsheep-photos/issues/31,811362316,MDEyOklzc3VlQ29tbWVudDgxMTM2MjMxNg==,871250,PabloLerma,2021-03-31T19:14:39Z,2021-03-31T19:14:39Z,NONE,👋 could I help somehow for this to be merged? As Big Sur is going to be more used as the time goes I think it would be nice to merge and publish a new version. Nice work!,"{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",771511344,Update for Big Sur,
https://github.com/simonw/datasette/issues/1255#issuecomment-812710120,https://api.github.com/repos/simonw/datasette/issues/1255,812710120,MDEyOklzc3VlQ29tbWVudDgxMjcxMDEyMA==,1111743,jungle-boogie,2021-04-02T20:50:08Z,2021-04-02T20:50:08Z,NONE,"Hello again,
I was able to get my facets running with this `settings.json`, which was lifted from one of Simon's datasette's and slightly modified.
```
{
""default_page_size"": 100,
""max_returned_rows"": 1000,
""num_sql_threads"": 3,
""sql_time_limit_ms"": 9000,
""default_facet_size"": 10,
""facet_time_limit_ms"": 9000,
""facet_suggest_time_limit_ms"": 500,
""hash_urls"": false,
""allow_facet"": true,
""suggest_facets"": false,
""default_cache_ttl"": 5,
""default_cache_ttl_hashed"": 31536000,
""cache_size_kb"": 0,
""allow_csv_stream"": true,
""max_csv_mb"": 100,
""truncate_cells_html"": 2048,
""template_debug"": false,
""base_url"": ""/""
}
```","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",826700095,Facets timing out but work when filtering,
https://github.com/simonw/datasette/issues/1375#issuecomment-860548546,https://api.github.com/repos/simonw/datasette/issues/1375,860548546,MDEyOklzc3VlQ29tbWVudDg2MDU0ODU0Ng==,4068,frafra,2021-06-14T09:41:59Z,2021-06-14T09:41:59Z,NONE,"> There is a feature for this at the moment, but it's a little bit hidden: you can use `?_json=col` to tell
> Datasette that you would like a specific column to be exported as nested JSON: https://docs.datasette.io/en/stable/json_api.html#special-json-arguments
Thanks :)
> I considered trying to make this automatic - so it detects columns that appear to contain valid JSON and outputs them as nested objects - but the problem with that is that it can lead to inconsistent results - you might hit the API and find that not every column contains valid JSON (compared to the previous day) resulting in the API retuning string instead of the expected dictionary and breaking your code.
If a developer is not sure if the JSON fields are valid, but then retrieves and parse them, it should handle errors too. Handling inconsistent data is necessary due to the nature of SQLite. A global or dataset option to render the data as they have been defined (JSON, boolean, etc.) when requesting JSON could allow the user to download a regular JSON from the browser without having to rely on APIs. I would guess someone could just make a custom template with an extra JSON-parsed download button otherwise :)","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",919508498,JSON export dumps JSON fields as TEXT,
https://github.com/simonw/datasette/issues/1304#issuecomment-981980048,https://api.github.com/repos/simonw/datasette/issues/1304,981980048,IC_kwDOBm6k_c46h9OQ,30934,20after4,2021-11-29T20:13:53Z,2021-11-29T20:14:11Z,NONE,There isn't any way to do this with sqlite as far as I know. The only option is to insert the right number of ? placeholders into the sql template and then provide an array of values.,"{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",863884805,"Document how to send multiple values for ""Named parameters"" ",
https://github.com/simonw/datasette/issues/1304#issuecomment-988463455,https://api.github.com/repos/simonw/datasette/issues/1304,988463455,IC_kwDOBm6k_c466sFf,30934,20after4,2021-12-08T03:23:14Z,2021-12-08T03:23:14Z,NONE,I actually think it would be a useful thing to add support for in datasette. It wouldn't be difficult to unwind an array of params and add the placeholders automatically.,"{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",863884805,"Document how to send multiple values for ""Named parameters"" ",
https://github.com/simonw/datasette/issues/236#issuecomment-1033772902,https://api.github.com/repos/simonw/datasette/issues/236,1033772902,IC_kwDOBm6k_c49nh9m,1376648,jordaneremieff,2022-02-09T13:40:52Z,2022-02-09T13:40:52Z,NONE,"Hi @simonw,
I've received some inquiries over the last year or so about Datasette and how it might be supported by [Mangum](https://github.com/jordaneremieff/mangum). I maintain Mangum which is, as far as I know, the only project that provides support for ASGI applications in AWS Lambda.
If there is anything that I can help with here, please let me know because I think what Datasette provides to the community (even beyond OSS) is noble and worthy of special consideration.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",317001500,datasette publish lambda plugin,
https://github.com/dogsheep/dogsheep-photos/pull/31#issuecomment-1035717429,https://api.github.com/repos/dogsheep/dogsheep-photos/issues/31,1035717429,IC_kwDOD079W849u8s1,18504,harperreed,2022-02-11T01:55:38Z,2022-02-11T01:55:38Z,NONE,I would love this merged! ,"{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",771511344,Update for Big Sur,
https://github.com/simonw/sqlite-utils/issues/510#issuecomment-1320394127,https://api.github.com/repos/simonw/sqlite-utils/issues/510,1320394127,IC_kwDOCGYnMM5Os52P,1176293,ar-jan,2022-11-18T18:37:51Z,2022-11-18T18:37:51Z,NONE,"I guess it is not incorrect when it says the version is `4`, though it is confusing. Maybe it doesn't even refer to FTS4/FTS5 versions, but something else? In any case, it's not related to sqlite-utils, but SQLite itself.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1434911255,Cannot enable FTS5 despite it being available,
https://github.com/simonw/datasette/issues/1886#issuecomment-1356842576,https://api.github.com/repos/simonw/datasette/issues/1886,1356842576,IC_kwDOBm6k_c5Q38ZQ,18738650,stevecrawshaw,2022-12-18T17:34:20Z,2022-12-18T17:34:20Z,NONE,"A bit late to this, but I have made an app to publish air quality data in Bristol, UK.
[air quality data in Bristol, UK.](https://brisaq-wfzqhmj43q-ew.a.run.app/)
Next step to see if I can make a streamlit app based on this to produce some nice charts.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1447050738,"Call for birthday presents: if you're using Datasette, let us know how you're using it here",
https://github.com/simonw/sqlite-utils/issues/524#issuecomment-1419734229,https://api.github.com/repos/simonw/sqlite-utils/issues/524,1419734229,IC_kwDOCGYnMM5Un2zV,193185,cldellow,2023-02-06T20:53:28Z,2023-02-06T21:16:29Z,NONE,"I think it's not currently possible: sqlite-utils requires that it be one of `integer`, `text`, `float`, `blob` ([see code](https://github.com/simonw/sqlite-utils/blob/fc221f9b62ed8624b1d2098e564f525c84497969/sqlite_utils/cli.py#L2266))
IMO, this is a bit of friction and it would be nice if it was more permissive. SQLite permits developers to use any data type when creating a table. For example, this is a perfectly cromulent sqlite session that creates a table with columns of type `baz` and `bar`:
```
sqlite> create table foo(column1 baz, column2 bar);
sqlite> .schema foo
CREATE TABLE foo(column1 baz, column2 bar);
sqlite> select * from pragma_table_info('foo');
cid name type notnull dflt_value pk
---------- ---------- ---------- ---------- ---------- ----------
0 column1 baz 0 0
1 column2 bar 0 0
```
The idea is that the application developer will know what meaning to ascribe to those types. For example, I'm working on a plugin to Datasette. Dates are tricky to handle. If you have some existing rows, you can look at the values in them to know how a user is serializing the dates -- as an ISO 8601 string? An RFC 3339 string? With millisecond precision? With timezone offset? But if you don't yet have any rows, you have to guess. If the column is of type `TEXT`, you don't even know that it's meant to hold a date! In this case, my plugin will look to see if the column is of type `DATE` or `DATETIME`, and assume a certain representation when writing.
Perhaps there is an argument that sqlite-utils is trying to conform to SQLite's strict mode, and that is why it limits the choices. In strict mode, SQLite requires that the data type be one of `INT`, `INTEGER`, `REAL`, `TEXT`, `BLOB`, `ANY`. But that can't be the case -- sqlite-utils supports `FLOAT`, which is not one of the valid types in strict mode, and it rejects `INT`, `REAL` and `ANY`, which _are_ valid.","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1572766460,Transformation type `--type DATETIME`,
https://github.com/simonw/sqlite-utils/issues/399#issuecomment-1548913065,https://api.github.com/repos/simonw/sqlite-utils/issues/399,1548913065,IC_kwDOCGYnMM5cUomp,433780,chrislkeller,2023-05-16T03:11:03Z,2023-05-16T03:11:52Z,NONE,"Using this thread and some [other resources](https://sqlite-utils.datasette.io/en/stable/cli.html#spatialite-helpers) I managed to cobble together a couple of sqlite-utils lines to add a geometry column for a table that already has a lat/lng column.
```
# add a geometry column
sqlite-utils add-geometry-column [db name] [table name] geometry --type POINT --srid 4326
# add a point for each row to geometry column
sqlite-utils --load-extension=spatialite [db name] 'update [table name] SET Geometry=MakePoint(longitude, latitude, 4326);'
```","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1124731464,"Make it easier to insert geometries, with documentation and maybe code",
https://github.com/dogsheep/dogsheep-photos/pull/31#issuecomment-1656696679,https://api.github.com/repos/dogsheep/dogsheep-photos/issues/31,1656696679,IC_kwDOD079W85ivy9n,319473,coldclimate,2023-07-29T10:10:29Z,2023-07-29T10:10:29Z,NONE,"+1 to getting this merged down.
For future googlers, I installed by...
```
git clone git@github.com:RhetTbull/dogsheep-photos.git
cd dogsheep-photos
git checkout update_for_bigsur
python setup.py install
```","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",771511344,Update for Big Sur,
https://github.com/simonw/datasette/issues/2143#issuecomment-1685263948,https://api.github.com/repos/simonw/datasette/issues/2143,1685263948,IC_kwDOBm6k_c5kcxZM,11784304,dvizard,2023-08-20T11:50:10Z,2023-08-20T11:50:10Z,NONE,"This also makes it simple to separate out secrets.
`datasette --config settings.yaml --config secrets.yaml --config db-docs.yaml --config db-fixtures.yaml`
settings.yaml
```
settings:
default_page_size: 10
max_returned_rows: 3000
sql_time_limit_ms"": 8000
plugins:
datasette-ripgrep:
path: /usr/local/lib/python3.11/site-packages
```
secrets.yaml
```
plugins:
datasette-auth-github:
client_secret: SUCH_SECRET
```
db-docs.yaml
```
databases:
docs:
permissions:
create-table:
id: editor
```
db-fixtures.yaml
```
databases:
fixtures:
tables:
no_primary_key:
hidden: true
queries:
neighborhood_search:
sql: |-
select neighborhood, facet_cities.name, state
from facetable join facet_cities on facetable.city_id = facet_cities.id
where neighborhood like '%' || :text || '%' order by neighborhood;
title: Search neighborhoods
description_html: |-
This demonstrates basic LIKE search
```","{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1855885427,De-tangling Metadata before Datasette 1.0,
https://github.com/simonw/datasette/pull/2155#issuecomment-1737906995,https://api.github.com/repos/simonw/datasette/issues/2155,1737906995,IC_kwDOBm6k_c5nllsz,79087,cadeef,2023-09-27T18:44:02Z,2023-09-27T18:44:02Z,NONE,@simonw Any chance we can get this tiny patch merged for an upcoming release?,"{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1865572575,Fix hupper.start_reloader entry point,
https://github.com/simonw/datasette/issues/670#issuecomment-1816642044,https://api.github.com/repos/simonw/datasette/issues/670,1816642044,IC_kwDOBm6k_c5sR8H8,16142258,tf13,2023-11-17T15:32:20Z,2023-11-17T15:32:20Z,NONE,Any progress on this? It would be very helpful on my end as well. Thanks!,"{""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",564833696,Prototoype for Datasette on PostgreSQL,
https://github.com/simonw/datasette/issues/1175#issuecomment-762488336,https://api.github.com/repos/simonw/datasette/issues/1175,762488336,MDEyOklzc3VlQ29tbWVudDc2MjQ4ODMzNg==,758858,hannseman,2021-01-18T21:59:28Z,2021-01-18T22:00:31Z,NONE,"I encountered your issue when trying to find a solution and came up with the following, maybe it can help.
```python
import logging.config
from typing import Tuple
import structlog
import uvicorn
from example.config import settings
shared_processors: Tuple[structlog.types.Processor, ...] = (
structlog.contextvars.merge_contextvars,
structlog.stdlib.add_logger_name,
structlog.stdlib.add_log_level,
structlog.processors.TimeStamper(fmt=""iso""),
)
logging_config = {
""version"": 1,
""disable_existing_loggers"": False,
""formatters"": {
""json"": {
""()"": structlog.stdlib.ProcessorFormatter,
""processor"": structlog.processors.JSONRenderer(),
""foreign_pre_chain"": shared_processors,
},
""console"": {
""()"": structlog.stdlib.ProcessorFormatter,
""processor"": structlog.dev.ConsoleRenderer(),
""foreign_pre_chain"": shared_processors,
},
**uvicorn.config.LOGGING_CONFIG[""formatters""],
},
""handlers"": {
""default"": {
""level"": ""DEBUG"",
""class"": ""logging.StreamHandler"",
""formatter"": ""json"" if not settings.debug else ""console"",
},
""uvicorn.access"": {
""level"": ""INFO"",
""class"": ""logging.StreamHandler"",
""formatter"": ""access"",
},
""uvicorn.default"": {
""level"": ""INFO"",
""class"": ""logging.StreamHandler"",
""formatter"": ""default"",
},
},
""loggers"": {
"""": {""handlers"": [""default""], ""level"": ""INFO""},
""uvicorn.error"": {
""handlers"": [""default"" if not settings.debug else ""uvicorn.default""],
""level"": ""INFO"",
""propagate"": False,
},
""uvicorn.access"": {
""handlers"": [""default"" if not settings.debug else ""uvicorn.access""],
""level"": ""INFO"",
""propagate"": False,
},
},
}
def setup_logging() -> None:
structlog.configure(
processors=[
structlog.stdlib.filter_by_level,
*shared_processors,
structlog.stdlib.PositionalArgumentsFormatter(),
structlog.processors.StackInfoRenderer(),
structlog.processors.format_exc_info,
structlog.stdlib.ProcessorFormatter.wrap_for_formatter,
],
context_class=dict,
logger_factory=structlog.stdlib.LoggerFactory(),
wrapper_class=structlog.stdlib.AsyncBoundLogger,
cache_logger_on_first_use=True,
)
logging.config.dictConfig(logging_config)
```
And then it'll be run on the startup event:
```python
@app.on_event(""startup"")
async def startup_event() -> None:
setup_logging()
```
It depends on a setting called `debug` which controls if it should output the regular uvicorn logging or json. ","{""total_count"": 15, ""+1"": 7, ""-1"": 0, ""laugh"": 1, ""hooray"": 1, ""confused"": 0, ""heart"": 5, ""rocket"": 1, ""eyes"": 0}",779156520,Use structlog for logging,
https://github.com/simonw/datasette/issues/176#issuecomment-356175667,https://api.github.com/repos/simonw/datasette/issues/176,356175667,MDEyOklzc3VlQ29tbWVudDM1NjE3NTY2Nw==,4313116,wulfmann,2018-01-09T04:19:03Z,2018-01-09T04:19:03Z,NONE,"@yozlet Yes I think that I was confused when I posted my original comment. I see your main point now and am in agreement.
","{""total_count"": 2, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 2, ""rocket"": 0, ""eyes"": 0}",285168503,Add GraphQL endpoint,
https://github.com/simonw/datasette/issues/176#issuecomment-548508237,https://api.github.com/repos/simonw/datasette/issues/176,548508237,MDEyOklzc3VlQ29tbWVudDU0ODUwODIzNw==,634572,eads,2019-10-31T18:25:44Z,2019-10-31T18:25:44Z,NONE,"👋 I'd be interested in building this out in Q1 or Q2 of 2020 if nobody has tackled it by then. I would love to integrate Datasette into @thechicagoreporter's practice, but we're also fully committed to GraphQL moving forward.","{""total_count"": 2, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 2, ""rocket"": 0, ""eyes"": 0}",285168503,Add GraphQL endpoint,
https://github.com/simonw/datasette/issues/1134#issuecomment-742260116,https://api.github.com/repos/simonw/datasette/issues/1134,742260116,MDEyOklzc3VlQ29tbWVudDc0MjI2MDExNg==,2181410,clausjuhl,2020-12-10T05:57:17Z,2020-12-10T05:57:17Z,NONE,"Hi Simon
Thank you for the quick fix! And glad you like our use of Datasette (launches 1. january 2021). It's a site that currently (more to come) makes all minutes and their annexes from Aarhus City Council and the major committees (1997-2019) available to the public. So we're putting Datasette to good use :)","{""total_count"": 2, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 2, ""rocket"": 0, ""eyes"": 0}",760312579,"""_searchmode=raw"" throws an index out of range error when combined with ""_search_COLUMN""",
https://github.com/simonw/datasette/issues/670#issuecomment-696163452,https://api.github.com/repos/simonw/datasette/issues/670,696163452,MDEyOklzc3VlQ29tbWVudDY5NjE2MzQ1Mg==,652285,snth,2020-09-21T14:46:10Z,2020-09-21T14:46:10Z,NONE,I'm currently using PostgREST to serve OpenAPI APIs off Postgresql databases. I would like to try out datasette once this becomes available on Postgres.,"{""total_count"": 2, ""+1"": 2, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",564833696,Prototoype for Datasette on PostgreSQL,
https://github.com/simonw/datasette/issues/417#issuecomment-751504136,https://api.github.com/repos/simonw/datasette/issues/417,751504136,MDEyOklzc3VlQ29tbWVudDc1MTUwNDEzNg==,212369,drewda,2020-12-27T19:02:06Z,2020-12-27T19:02:06Z,NONE,"Very much looking forward to seeing this functionality come together. This is probably out-of-scope for an initial release, but in the future it could be useful to also think of how to run this is a container'ized context. For example, an immutable datasette container that points to an S3 bucket of SQLite DBs or CSVs. Or an immutable datasette container pointing to a NFS volume elsewhere on a Kubernetes cluster.","{""total_count"": 2, ""+1"": 2, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",421546944,Datasette Library,
https://github.com/simonw/sqlite-utils/issues/412#issuecomment-1059652834,https://api.github.com/repos/simonw/sqlite-utils/issues/412,1059652834,IC_kwDOCGYnMM4_KQTi,596279,zaneselvans,2022-03-05T02:14:40Z,2022-03-05T02:14:40Z,NONE,"We do a lot of `df.to_sql()` to write into sqlite, mostly in [this moddule](https://github.com/catalyst-cooperative/pudl/blob/main/src/pudl/load.py#L25)","{""total_count"": 2, ""+1"": 2, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1160182768,Optional Pandas integration,
https://github.com/simonw/sqlite-utils/issues/159#issuecomment-1111506339,https://api.github.com/repos/simonw/sqlite-utils/issues/159,1111506339,IC_kwDOCGYnMM5CQD2j,154364,dracos,2022-04-27T21:35:13Z,2022-04-27T21:35:13Z,NONE,"Just stumbled across this, wondering why none of my deletes were working.","{""total_count"": 2, ""+1"": 2, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",702386948,.delete_where() does not auto-commit (unlike .insert() or .upsert()),
https://github.com/simonw/sqlite-utils/issues/456#issuecomment-1190449764,https://api.github.com/repos/simonw/sqlite-utils/issues/456,1190449764,IC_kwDOCGYnMM5G9NJk,45919695,jcmkk3,2022-07-20T15:45:54Z,2022-07-20T15:45:54Z,NONE,"> hadley wickham's melt and reshape could be good inspo: http://had.co.nz/reshape/introduction.pdf
Note that Hadley has since implemented `pivot_longer` and `pivot_wider` instead of the previous verbs/functions that he used. Those can be found in the tidyr package and are probably the best reference which includes all of the learnings from years of user feedback. https://tidyr.tidyverse.org/articles/pivot.html","{""total_count"": 2, ""+1"": 2, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1310243385,feature request: pivot command,
https://github.com/simonw/sqlite-utils/issues/235#issuecomment-1223378004,https://api.github.com/repos/simonw/sqlite-utils/issues/235,1223378004,IC_kwDOCGYnMM5I60RU,1558033,wpears,2022-08-23T00:44:11Z,2022-08-23T00:44:11Z,NONE,"This bug affects me as well. Env:
```
Python 3.8.12
sqlite-utils, version 3.28
sqlite3 3.32.3
MacOS Big Sur 11.6.7
Intel
```
Similar to @mdrovdahl, I was able to work around this bug by piping the SQL string constructed in `add_foreign_keys` to the `sqlite3` command itself. Specifically, if you're trying to patch this yourself, replace [lines 1026-1039 of db.py in your site packages](https://github.com/simonw/sqlite-utils/blob/main/sqlite_utils/db.py#L1026-L1039) with something similar to the following:
```
print(""PRAGMA writable_schema = 1;"")
for table_name, new_sql in table_sql.items():
print(""UPDATE sqlite_master SET sql = '{}' WHERE name = '{}';"".format(
new_sql, table_name)
)
print(""PRAGMA writable_schema = 0;"")
print(""VACUUM;"")
```
Then from your terminal:
`db-to-sqlite """" your.db --all > output.sql && sqlite3 your.db < output.sql`
If you want to run this with `-p`, you'll have to actually open a file in code to write to instead of redirecting the output.","{""total_count"": 3, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 3, ""rocket"": 0, ""eyes"": 0}",810618495,Extract columns cannot create foreign key relation: sqlite3.OperationalError: table sqlite_master may not be modified,
https://github.com/dogsheep/google-takeout-to-sqlite/pull/5#issuecomment-791530093,https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/5,791530093,MDEyOklzc3VlQ29tbWVudDc5MTUzMDA5Mw==,306240,UtahDave,2021-03-05T16:28:07Z,2021-03-05T16:28:07Z,NONE,"> I just tried to run this on a small VPS instance with 2GB of memory and it crashed out of memory while processing a 12GB mbox from Takeout.
>
> Is it possible to stream the emails to sqlite instead of loading it all into memory and upserting at once?
@maxhawkins a limitation of the python mbox module is it loads the entire mbox into memory. I did find another approach to this problem that didn't use the builtin python mbox module and created a generator so that it didn't have to load the whole mbox into memory. I was hoping to use standard library modules, but this might be a good reason to investigate that approach a bit more. My worry is making sure a custom processor handles all the ins and outs of the mbox format correctly.
Hm. As I'm writing this, I thought of something. I think I can parse each message one at a time, and then use an mbox function to load each message using the python mbox module. That way the mbox module can still deal with the specifics of the mbox format, but I can use a generator.
I'll give that a try. Thanks for the feedback @maxhawkins and @simonw. I'll give that a try.
@simonw can we hold off on merging this until I can test this new approach?","{""total_count"": 3, ""+1"": 3, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",813880401,WIP: Add Gmail takeout mbox import,
https://github.com/dogsheep/dogsheep-photos/pull/31#issuecomment-1190995982,https://api.github.com/repos/dogsheep/dogsheep-photos/issues/31,1190995982,IC_kwDOD079W85G_SgO,19231792,jakewilkins,2022-07-21T03:26:38Z,2023-04-14T22:41:31Z,NONE,"👋 Any update on getting this merged?
Alternatively, is there a work around for this issue to unblock myself?
edit to add: huge fan of both this project and `osxphotos`, thanks so much for your work here 🙏 If I had any experience with Python I would offer to help but somehow I've managed to not write any Python in 10+ years of programming 😅
Edit again to add:
> Alternatively, is there a work around for this issue to unblock myself?
Yes, there is. I was able to apply the patch of this PR and it applies (mostly) cleanly and works.
- verified I have a high enough version of `osxphotos`
- downloaded the .patch of this (by appending `.patch` to the URL)
- edited the patch to remove the `setup.py` changes
- `cd` to the directory containing `dogsheep-photos` and `git apply 31.patch`
","{""total_count"": 4, ""+1"": 4, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",771511344,Update for Big Sur,
https://github.com/simonw/sqlite-utils/issues/425#issuecomment-1129332959,https://api.github.com/repos/simonw/sqlite-utils/issues/425,1129332959,IC_kwDOCGYnMM5DUEDf,102771161,McEazy2700,2022-05-17T21:27:02Z,2022-05-17T21:27:02Z,NONE,"Hi, I'm trying to deploy my site using elasticbeanstalk and I keep getting this same error :
deterministic=True requires SQLite 3.8.3 or higher
I saw your previous solution that involves editing sqlite-utils/sqlite_utils/db.py file, but I'm curious as to how that will work in production.","{""total_count"": 5, ""+1"": 5, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",1203842656,`sqlite3.NotSupportedError`: deterministic=True requires SQLite 3.8.3 or higher,