{"html_url": "https://github.com/simonw/datasette/pull/1348#issuecomment-850077261", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1348", "id": 850077261, "node_id": "MDEyOklzc3VlQ29tbWVudDg1MDA3NzI2MQ==", "user": {"value": 10801138, "label": "blairdrummond"}, "created_at": "2021-05-28T03:05:38Z", "updated_at": "2021-05-28T03:05:38Z", "author_association": "CONTRIBUTOR", "body": "Note, the CVEs are probably resolvable with this https://github.com/simonw/datasette/pull/1296 . My experience is that Ubuntu seems to manage these better? Though that is surprising :/ ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 904598267, "label": "DRAFT: add test and scan for docker images"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/pull/59#issuecomment-846413174", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/59", "id": 846413174, "node_id": "MDEyOklzc3VlQ29tbWVudDg0NjQxMzE3NA==", "user": {"value": 631242, "label": "frosencrantz"}, "created_at": "2021-05-22T14:06:19Z", "updated_at": "2021-05-22T14:06:19Z", "author_association": "CONTRIBUTOR", "body": "Thanks Simon!", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 771872303, "label": "Remove unneeded exists=True for -a/--auth flag."}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1236#issuecomment-842798043", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1236", "id": 842798043, "node_id": "MDEyOklzc3VlQ29tbWVudDg0Mjc5ODA0Mw==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-05-18T03:28:25Z", "updated_at": "2021-05-18T03:28:25Z", "author_association": "CONTRIBUTOR", "body": "That corner handle looks like a hamburger menu to me. Note that the default resize handle is not limited to two-way resize: http://jsfiddle.net/LLrh7Lte/", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 812228314, "label": "Ability to increase size of the SQL editor window"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1318#issuecomment-838449572", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1318", "id": 838449572, "node_id": "MDEyOklzc3VlQ29tbWVudDgzODQ0OTU3Mg==", "user": {"value": 49699333, "label": "dependabot[bot]"}, "created_at": "2021-05-11T13:12:30Z", "updated_at": "2021-05-11T13:12:30Z", "author_association": "CONTRIBUTOR", "body": "Superseded by #1321.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 876431852, "label": "Bump black from 21.4b2 to 21.5b0"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1280#issuecomment-837166862", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1280", "id": 837166862, "node_id": "MDEyOklzc3VlQ29tbWVudDgzNzE2Njg2Mg==", "user": {"value": 10801138, "label": "blairdrummond"}, "created_at": "2021-05-10T19:07:46Z", "updated_at": "2021-05-10T19:07:46Z", "author_association": "CONTRIBUTOR", "body": "Do you have a list of sqlite versions you want to test against?\r\n\r\nOne cool thing I saw recently (that we started using) was using `import docker` within python, and then writing pytest functions which executed against the container\r\n\r\n[setup](https://github.com/StatCan/kubeflow-containers/blob/3c7dcfb5e7188982fb8ebcded82e84292720f720/conftest.py#L85)\r\n\r\n[example](https://github.com/StatCan/kubeflow-containers/blob/master/tests/jupyterlab-cpu/test_julia.py#L8-L18)\r\n\r\nThe inspiration for this came from the [jupyter docker-stacks](https://github.com/jupyter/docker-stacks/blob/09fb66007615ea68d9bce8f8e1a2cf9402f1e432/test/test_packages.py#L107)\r\n\r\nSo off the top of my head, could look at building the container with different sqlite versions as a build-arg, then run tests against the containers. Just brainstorming though", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 842862708, "label": "Ability to run CI against multiple SQLite versions"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1296#issuecomment-835491318", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1296", "id": 835491318, "node_id": "MDEyOklzc3VlQ29tbWVudDgzNTQ5MTMxOA==", "user": {"value": 10801138, "label": "blairdrummond"}, "created_at": "2021-05-08T19:59:01Z", "updated_at": "2021-05-08T19:59:01Z", "author_association": "CONTRIBUTOR", "body": "I have also found that ubuntu has fewer vulnerabilities than the buster based images.\r\n\r\n```\r\n\u279c ~ docker pull python:3-buster\r\n\u279c ~ trivy image python:3-buster | head \r\n2021-04-28T17:14:29.313-0400 INFO Detecting Debian vulnerabilities...\r\n2021-04-28T17:14:29.393-0400 INFO Trivy skips scanning programming language libraries because no supported file was detected\r\npython:3-buster (debian 10.9)\r\n=============================\r\nTotal: 1621 (UNKNOWN: 13, LOW: 1106, MEDIUM: 343, HIGH: 145, CRITICAL: 14)\r\n+------------------------------+---------------------+----------+------------------------------+---------------+--------------------------------------------------------------+\r\n| LIBRARY | VULNERABILITY ID | SEVERITY | INSTALLED VERSION | FIXED VERSION | TITLE |\r\n+------------------------------+---------------------+----------+------------------------------+---------------+--------------------------------------------------------------+\r\n```", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 855446829, "label": "Dockerfile: use Ubuntu 20.10 as base"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1300#issuecomment-833132571", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1300", "id": 833132571, "node_id": "MDEyOklzc3VlQ29tbWVudDgzMzEzMjU3MQ==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2021-05-06T00:16:50Z", "updated_at": "2021-05-06T00:18:05Z", "author_association": "CONTRIBUTOR", "body": "I ended up using some JS as a workaround. \r\n\r\nFirst, add a JS file in `metadata.yaml`:\r\n\r\n```yaml\r\nextra_js_urls:\r\n - '/static/app.js'\r\n```\r\nthen inside the script, find the blob download links and replace `.blob` extension in the url with `.jpg` and replace the links with `` elements. \r\nYou need to add an output formatter to serve `BLOB` columns as JPG. You can find the code in the first post.\r\n~~Replacing `.blob` -> `.jpg` might not even be necessary, because browsers only care about the mime type, so you only need to serve the binary content with the right `content-type` header.~~. You need to replace the extension, otherwise the output renderer will not run.\r\n\r\n```js\r\nwindow.addEventListener('DOMContentLoaded', () => {\r\n function renderBlobImages() {\r\n document.querySelectorAll('a[href*=\".blob\"]').forEach(el => {\r\n const img = document.createElement('img');\r\n img.className = 'blob-image';\r\n img.loading = 'lazy';\r\n img.src = el.href.replace('.blob', '.jpg');\r\n el.parentElement.replaceChild(img, el);\r\n });\r\n }\r\n\r\n renderBlobImages();\r\n});\r\n```\r\n\r\nwhile this does the job, I'd prefer handling this in Python where it belongs.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 860625833, "label": "Make row available to `render_cell` plugin hook"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1313#issuecomment-829352402", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1313", "id": 829352402, "node_id": "MDEyOklzc3VlQ29tbWVudDgyOTM1MjQwMg==", "user": {"value": 27856297, "label": "dependabot-preview[bot]"}, "created_at": "2021-04-29T15:47:23Z", "updated_at": "2021-04-29T15:47:23Z", "author_association": "CONTRIBUTOR", "body": "This pull request will no longer be automatically closed when a new version is found as this pull request was created by Dependabot Preview and this repo is using a `version: 2` config file. You can close this pull request and let Dependabot re-create it the next time it checks for updates.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 871046111, "label": "Bump black from 20.8b1 to 21.4b2"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1311#issuecomment-829260725", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1311", "id": 829260725, "node_id": "MDEyOklzc3VlQ29tbWVudDgyOTI2MDcyNQ==", "user": {"value": 27856297, "label": "dependabot-preview[bot]"}, "created_at": "2021-04-29T13:58:08Z", "updated_at": "2021-04-29T13:58:08Z", "author_association": "CONTRIBUTOR", "body": "Superseded by #1313.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 870227815, "label": "Bump black from 20.8b1 to 21.4b1"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1309#issuecomment-828679943", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1309", "id": 828679943, "node_id": "MDEyOklzc3VlQ29tbWVudDgyODY3OTk0Mw==", "user": {"value": 27856297, "label": "dependabot-preview[bot]"}, "created_at": "2021-04-28T18:26:03Z", "updated_at": "2021-04-28T18:26:03Z", "author_association": "CONTRIBUTOR", "body": "Superseded by #1311.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 869237023, "label": "Bump black from 20.8b1 to 21.4b0"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1298#issuecomment-823093669", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1298", "id": 823093669, "node_id": "MDEyOklzc3VlQ29tbWVudDgyMzA5MzY2OQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-04-20T08:38:10Z", "updated_at": "2021-04-20T08:40:22Z", "author_association": "CONTRIBUTOR", "body": "@dracos I appreciate your ideas!\r\n\r\n1. Ooh, I like this: https://codepen.io/astro87/pen/LYRQNbd?editors=1100 (That's the codepen from your linked stackoverflow.)\r\n2. I worry that a max height will be a problem when my facets are open. (I've got 35 active ingredients, and so I've set the default_facet_size to 35.)\r\n3. I don't understand this one. I'm observing the screenshot... very helpful! (Ah, okay, TR = Top Right and BR = Bottom Right. Absolute grid refers to position style.) All the scroll bars look a little wonky to me. I've also got a lot of facets, and prefer the extra horizontal space so that not as many facets disappear below the fold. My site also has end users... some will be on mobile... not sure what the absolute grid would do there... \r\n4. (I still think a hover-arrow that scrolls upon click would help, too...)\r\n\r\nBut meanwhile, I'm going to go ahead and see if I can apply that shadow. (Never would've thought of that.) Hmmm... I'm not an SCSS person. This looks helpful! https://jsonformatter.org/scss-to-css", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 855476501, "label": "improve table horizontal scroll experience"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1300#issuecomment-821971059", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1300", "id": 821971059, "node_id": "MDEyOklzc3VlQ29tbWVudDgyMTk3MTA1OQ==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2021-04-18T10:42:19Z", "updated_at": "2021-04-18T10:42:19Z", "author_association": "CONTRIBUTOR", "body": "If there's a simpler way to generate a URL for a specific row, I'm all ears", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 860625833, "label": "Make row available to `render_cell` plugin hook"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1300#issuecomment-821970965", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1300", "id": 821970965, "node_id": "MDEyOklzc3VlQ29tbWVudDgyMTk3MDk2NQ==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2021-04-18T10:41:15Z", "updated_at": "2021-04-18T10:41:15Z", "author_association": "CONTRIBUTOR", "body": "If I change the hookspec and add a row parameter, it works\r\n\r\nhttps://github.com/simonw/datasette/blob/7a2ed9f8a119e220b66d67c7b9e07cbab47b1196/datasette/hookspecs.py#L58\r\n\r\n```\r\ndef render_cell(value, column, row, table, database, datasette):\r\n```\r\n\r\nBut to generate a URL, I need the primary keys, but I can't call `pks = await db.primary_keys(table)` inside a sync function. I can't call `datasette.utils.detect_primary_keys` either, because the db connection is not publicly exposed (AFAICT).\r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 860625833, "label": "Make row available to `render_cell` plugin hook"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1296#issuecomment-819467759", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1296", "id": 819467759, "node_id": "MDEyOklzc3VlQ29tbWVudDgxOTQ2Nzc1OQ==", "user": {"value": 295329, "label": "camallen"}, "created_at": "2021-04-14T12:07:37Z", "updated_at": "2021-04-14T12:11:36Z", "author_association": "CONTRIBUTOR", "body": "> Removing /var/lib/apt and /var/lib/dpkg makes apt and dpkg unusable in\r\nimages based on this one. Running `apt-get clean` and removing\r\n/var/lib/apt/lists achieves similar size savings.\r\n\r\nthis PR helps me as removing the /var/lib/apt and /var/lib/dpkg directories breaks my ability to add packages when using `datasetteproject/datasette:0.56` as a base image.\r\n\r\n\r\n---- \r\nShorterm workaround for me was to use this in my Dockerfile\r\n```\r\nFROM datasetteproject/datasette:0.56\r\n\r\nRUN mkdir -p /var/lib/apt\r\nRUN mkdir -p /var/lib/dpkg\r\nRUN mkdir -p /var/lib/dpkg/updates\r\nRUN mkdir -p /var/lib/dpkg/info\r\nRUN touch /var/lib/dpkg/status\r\n\r\nRUN apt-get update # and install your packages etc\r\n```\r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 855446829, "label": "Dockerfile: use Ubuntu 20.10 as base"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/830#issuecomment-817414881", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/830", "id": 817414881, "node_id": "MDEyOklzc3VlQ29tbWVudDgxNzQxNDg4MQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-04-12T01:06:34Z", "updated_at": "2021-04-12T01:07:27Z", "author_association": "CONTRIBUTOR", "body": "Related: #1285, including arguments for natural breaks, equal interval, etc. modeled after choropleth map legends.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 636511683, "label": "Redesign register_facet_classes plugin hook"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1286#issuecomment-815978405", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1286", "id": 815978405, "node_id": "MDEyOklzc3VlQ29tbWVudDgxNTk3ODQwNQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-04-08T16:47:29Z", "updated_at": "2021-04-10T03:59:00Z", "author_association": "CONTRIBUTOR", "body": "This worked for me: \r\n`
`\r\n\r\nI'm sure there is a prettier (and more flexible) way, but for now, this is ever-so-much more pleasant to look at. \r\n\r\n------ AFTER:\r\n\r\n\r\n------ BEFORE:\r\n\r\n\r\n\r\n\r\n(Note: I didn't figure out how to have one item have no semicolon, while multi-items close with a semicolon, but this is good enough for now. I also didn't figure out how to set up a new jinja filter. I don't want to add to /datasette/utils/__init__.py as I assume that would get overwritten when upgrading datasette. Having a starter guide on creating jinja filters in datasette would be helpful. (The jinja documentation isn't datasette-specific enough for me to quite nail it.)\r\n", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 849220154, "label": "Better default display of arrays of items"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/502#issuecomment-812813732", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/502", "id": 812813732, "node_id": "MDEyOklzc3VlQ29tbWVudDgxMjgxMzczMg==", "user": {"value": 5413548, "label": "louispotok"}, "created_at": "2021-04-03T05:16:54Z", "updated_at": "2021-04-03T05:16:54Z", "author_association": "CONTRIBUTOR", "body": "For what it's worth, if anyone finds this in the future, I was having the same issue. \r\n\r\nAfter digging through the code, it turned out that the database download is only available if it the db served in immutable mode, so `datasette serve -i xyz.db` rather than the doc's quickstart recommendation of `datasette serve xyz.db`.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 453131917, "label": "Exporting sqlite database(s)?"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1286#issuecomment-812679221", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1286", "id": 812679221, "node_id": "MDEyOklzc3VlQ29tbWVudDgxMjY3OTIyMQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-04-02T19:34:01Z", "updated_at": "2021-04-02T19:34:01Z", "author_association": "CONTRIBUTOR", "body": "This shows the city in a different color (and not the comma), but I get the idea, and I like it. (Ooh, could be nice to have the gear have an option in array fields to show as bullets or commas or semicolons...)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 849220154, "label": "Better default display of arrays of items"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1284#issuecomment-810779928", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1284", "id": 810779928, "node_id": "MDEyOklzc3VlQ29tbWVudDgxMDc3OTkyOA==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-31T05:40:12Z", "updated_at": "2021-03-31T05:40:12Z", "author_association": "CONTRIBUTOR", "body": "Maybe the addition of two template files: 'one_database_index.html' and 'one_table_index.html' would be a better idea than the documentation diff idea. (They could include commented instructions to rename the preferred template 'index.html', along with any other necessary guidance.)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 845794436, "label": "Feature or Documentation Request: Individual table as home page template"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1274#issuecomment-805214307", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1274", "id": 805214307, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNTIxNDMwNw==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-03-23T20:12:29Z", "updated_at": "2021-03-23T20:12:29Z", "author_association": "CONTRIBUTOR", "body": "One issue I could see with adding first class support for metadata in hjson format is that this would require adding an additional dependency to handle this, for a feature that would be unused by many users. I wonder if this could fit in as a plugin instead; if a hook existed for loading metadata (maybe as part of https://github.com/simonw/datasette/issues/860) the metadata could then come from any source, as specified by plugins, e.g. hjson, toml, XML, a database table etc.\r\n\r\nUntil/unless this exists, a few ideas for how you could add comments:\r\n- Using YAML as you suggest.\r\n- A common pattern is adding a `\"comment\"` key for comments to any object in JSON - I don't think including an unnecessary key like this would break anything in Datasette, but not certain.\r\n- You could use another tool as a preprocessor for your JSON metadata - e.g. hjson or Jsonnet. You'd write the metadata in that format, and then convert that into JSON to actually use as your final metadata.", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 839008371, "label": "Might there be some way to comment metadata.json?"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1153#issuecomment-804640440", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1153", "id": 804640440, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDY0MDQ0MA==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T05:58:20Z", "updated_at": "2021-03-23T05:58:20Z", "author_association": "CONTRIBUTOR", "body": "Could there be a little widget that offers conversion from one to the other? ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 771202454, "label": "Use YAML examples in documentation by default, not JSON"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1159#issuecomment-804639427", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1159", "id": 804639427, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDYzOTQyNw==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T05:56:02Z", "updated_at": "2021-03-23T05:56:02Z", "author_association": "CONTRIBUTOR", "body": "With just three facets, I like it, but it does take more horizontal space. Would be nice to have a switch somewhere, enabling either original compact option or this proposed more-readable option. Also some control over word wrap (width setting) and facet spacing. ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 774332247, "label": "Improve the display of facets information"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/164#issuecomment-804541064", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/164", "id": 804541064, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDU0MTA2NA==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T02:45:12Z", "updated_at": "2021-03-23T02:45:12Z", "author_association": "CONTRIBUTOR", "body": "\"datasette skeleton\" feature removed #476", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 280013907, "label": "datasette skeleton command for kick-starting database and table metadata"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/163#issuecomment-804539729", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/163", "id": 804539729, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDUzOTcyOQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T02:41:14Z", "updated_at": "2021-03-23T02:41:14Z", "author_association": "CONTRIBUTOR", "body": "I'm visiting old issues for context while learning datasette. Let me know if okay to make the occasional comment like this one.\r\nquerystring argument now located at:\r\nhttps://docs.datasette.io/en/latest/settings.html#sql-time-limit-ms", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 279547886, "label": "Document the querystring argument for setting a different time limit"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/88#issuecomment-804471733", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/88", "id": 804471733, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDQ3MTczMw==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-22T23:46:36Z", "updated_at": "2021-03-22T23:46:36Z", "author_association": "CONTRIBUTOR", "body": "Google Map API limits seem to prevent https://nhs-england-map.netlify.com from being a working demo.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 273775212, "label": "Add NHS England Hospitals example to wiki"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1149#issuecomment-804415619", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1149", "id": 804415619, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDQxNTYxOQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-22T21:43:16Z", "updated_at": "2021-03-22T21:43:16Z", "author_association": "CONTRIBUTOR", "body": "Sounds like a good idea.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 769520939, "label": "Make it easier to theme Datasette with CSS"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/942#issuecomment-803631102", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/942", "id": 803631102, "node_id": "MDEyOklzc3VlQ29tbWVudDgwMzYzMTEwMg==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-21T17:48:42Z", "updated_at": "2021-03-21T17:48:42Z", "author_association": "CONTRIBUTOR", "body": "I like this idea. Though it might be nice to have some kind of automated system from database to file, so that developers could easily track diffs.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 681334912, "label": "Support column descriptions in metadata.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1265#issuecomment-802923254", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1265", "id": 802923254, "node_id": "MDEyOklzc3VlQ29tbWVudDgwMjkyMzI1NA==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-03-19T15:39:15Z", "updated_at": "2021-03-19T15:39:15Z", "author_association": "CONTRIBUTOR", "body": "It doesn't use basic auth, but you can put a whole datasette instance, or parts of this, behind a username/password prompt using https://github.com/simonw/datasette-auth-passwords", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 836123030, "label": "Support for HTTP Basic Authentication"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1262#issuecomment-802095132", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1262", "id": 802095132, "node_id": "MDEyOklzc3VlQ29tbWVudDgwMjA5NTEzMg==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-03-18T16:37:45Z", "updated_at": "2021-03-18T16:37:45Z", "author_association": "CONTRIBUTOR", "body": "This sounds like a good use case for a plugin, since this will only be useful for a subset of Datasette users. It shouldn't be too difficult to add a button to do this with the available plugin hooks - have you taken a look at https://docs.datasette.io/en/latest/writing_plugins.html?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 834602299, "label": "Plugin hook that could support 'order by random()' for table view"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/236#issuecomment-799003172", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/236", "id": 799003172, "node_id": "MDEyOklzc3VlQ29tbWVudDc5OTAwMzE3Mg==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-03-14T23:42:57Z", "updated_at": "2021-03-14T23:42:57Z", "author_association": "CONTRIBUTOR", "body": "Oh, and the container image can be up to 10GB, so the EFS step might not be needed except for pretty big stuff.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 317001500, "label": "datasette publish lambda plugin"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/236#issuecomment-799002993", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/236", "id": 799002993, "node_id": "MDEyOklzc3VlQ29tbWVudDc5OTAwMjk5Mw==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-03-14T23:41:51Z", "updated_at": "2021-03-14T23:41:51Z", "author_association": "CONTRIBUTOR", "body": "Now that [Lambda supports Docker](https://aws.amazon.com/blogs/aws/new-for-aws-lambda-container-image-support/), this probably is a bit easier and may be able to build on top of the existing package command.\r\n\r\nThere are weirdnesses in how the command actually gets invoked; the [aws-lambda-python image](https://hub.docker.com/r/amazon/aws-lambda-python) shows a bit of that. So Datasette would probably need some sort of Lambda-specific entry point to make this work.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 317001500, "label": "datasette publish lambda plugin"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1256#issuecomment-795112935", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1256", "id": 795112935, "node_id": "MDEyOklzc3VlQ29tbWVudDc5NTExMjkzNQ==", "user": {"value": 6371750, "label": "JBPressac"}, "created_at": "2021-03-10T08:59:45Z", "updated_at": "2021-03-10T08:59:45Z", "author_association": "CONTRIBUTOR", "body": "Sorry, I meant \"minor typo\" not \"minor type\".", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 827341657, "label": "Minor type in IP adress"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/766#issuecomment-791509910", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/766", "id": 791509910, "node_id": "MDEyOklzc3VlQ29tbWVudDc5MTUwOTkxMA==", "user": {"value": 6371750, "label": "JBPressac"}, "created_at": "2021-03-05T15:57:35Z", "updated_at": "2021-03-05T16:35:21Z", "author_association": "CONTRIBUTOR", "body": "Hello, \r\nI have the same wildcards search problems with an instance of Datasette. http://crbc-dataset.huma-num.fr/inventaires/fonds_auguste_dupouy_1872_1967?_search=gwerz&_sort=rowid is OK but http://crbc-dataset.huma-num.fr/inventaires/fonds_auguste_dupouy_1872_1967?_search=gwe* is not (FTS is activated on \"Reference\" \"IntituleAnalyse\" \"NomDuProducteur\" \"PresentationDuContenu\" \"Notes\"). \r\n\r\nNotice that a SQL query as below launched directly from SQLite in the server's shell, retrieves results.\r\n\r\n`select * from fonds_auguste_dupouy_1872_1967_fts where IntituleAnalyse MATCH \"gwe*\";`\r\n\r\nThanks,", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 617323873, "label": "Enable wildcard-searches by default"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1238#issuecomment-789186458", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1238", "id": 789186458, "node_id": "MDEyOklzc3VlQ29tbWVudDc4OTE4NjQ1OA==", "user": {"value": 198537, "label": "rgieseke"}, "created_at": "2021-03-02T20:19:30Z", "updated_at": "2021-03-02T20:19:30Z", "author_association": "CONTRIBUTOR", "body": "A custom `templates/index.html` seems to work and custom `pages` as a workaround with moving them to `pages/base_url_dir`.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 813899472, "label": "Custom pages don't work with base_url setting"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/242#issuecomment-787121933", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/242", "id": 787121933, "node_id": "MDEyOklzc3VlQ29tbWVudDc4NzEyMTkzMw==", "user": {"value": 25778, "label": "eyeseast"}, "created_at": "2021-02-27T19:18:57Z", "updated_at": "2021-02-27T19:18:57Z", "author_association": "CONTRIBUTOR", "body": "I think HTTPX gets it exactly right, with a clear separation between sync and async clients, each with a basically identical API. (I'm about to switch [feed-to-sqlite](https://github.com/eyeseast/feed-to-sqlite) over to it, from Requests, to eventually make way for async support.)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 817989436, "label": "Async support"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1212#issuecomment-782430028", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1212", "id": 782430028, "node_id": "MDEyOklzc3VlQ29tbWVudDc4MjQzMDAyOA==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-19T22:54:13Z", "updated_at": "2021-02-19T22:54:13Z", "author_association": "CONTRIBUTOR", "body": "I will close this issue since it appears only in my particular setup.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797651831, "label": "Tests are very slow. "}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1229#issuecomment-782053455", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1229", "id": 782053455, "node_id": "MDEyOklzc3VlQ29tbWVudDc4MjA1MzQ1NQ==", "user": {"value": 295329, "label": "camallen"}, "created_at": "2021-02-19T12:47:19Z", "updated_at": "2021-02-19T12:47:19Z", "author_association": "CONTRIBUTOR", "body": "I believe this pr and #1031 are related and fix the same issue.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 810507413, "label": "ensure immutable databses when starting in configuration directory mode with"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1220#issuecomment-778439617", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1220", "id": 778439617, "node_id": "MDEyOklzc3VlQ29tbWVudDc3ODQzOTYxNw==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-02-12T20:33:27Z", "updated_at": "2021-02-12T20:33:27Z", "author_association": "CONTRIBUTOR", "body": "That Docker command will mount your current directory inside the Docker container at `/mnt` - so you shouldn't need to change anything locally, just run\r\n\r\n```\r\ndocker run -p 8001:8001 -v `pwd`:/mnt \\\r\n datasetteproject/datasette \\\r\n datasette -p 8001 -h 0.0.0.0 /mnt/fixtures.db\r\n```\r\n\r\nand it will use the `fixtures.db` file within your current directory", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 806743116, "label": "Installing datasette via docker: Path 'fixtures.db' does not exist"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/issues/60#issuecomment-770069864", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/60", "id": 770069864, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MDA2OTg2NA==", "user": {"value": 22578954, "label": "daniel-butler"}, "created_at": "2021-01-29T21:52:05Z", "updated_at": "2021-02-12T18:29:43Z", "author_association": "CONTRIBUTOR", "body": "For the purposes below I am assuming the organization I would get all the repositories and their related commits from is called `gh-organization`. The github's owner id of gh-orgnization is `123456789`.\r\n\r\n```bash\r\ngithub-to-sqlite repos github.db gh-organization\r\n```\r\n\r\nI'm on a windows computer running git bash to be able to use the `|` command. This works for me\r\n```bash\r\nsqlite3 github.db \"SELECT full_name FROM repos WHERE owner = '123456789';\" | tr '\\n\\r' ' ' | xargs | { read repos; github-to-sqlite commits github.db $repos; }\r\n```\r\n\r\nOn a pure linux system I think this would work because the new line character is normally `\\n`\r\n```bash\r\nsqlite3 github.db \"SELECT full_name FROM repos WHERE owner = '123456789';\" | tr '\\n' ' ' | xargs | { read repos; github-to-sqlite commits github.db $repos; }`\r\n```\r\n\r\nAs expected I ran into rate limit issues #51 \r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797097140, "label": "Use Data from SQLite in other commands"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/issues/33#issuecomment-778246347", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/33", "id": 778246347, "node_id": "MDEyOklzc3VlQ29tbWVudDc3ODI0NjM0Nw==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2021-02-12T15:00:43Z", "updated_at": "2021-02-12T15:00:43Z", "author_association": "CONTRIBUTOR", "body": "Yes, Big Sur Photos database doesn't have `ZGENERICASSET` table. PR #31 will fix this.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 803338729, "label": "photo-to-sqlite: command not found"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1220#issuecomment-777927946", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1220", "id": 777927946, "node_id": "MDEyOklzc3VlQ29tbWVudDc3NzkyNzk0Ng==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-02-12T02:29:54Z", "updated_at": "2021-02-12T02:29:54Z", "author_association": "CONTRIBUTOR", "body": "According to https://github.com/simonw/datasette/blob/master/docs/installation.rst#using-docker it should be\r\n\r\n```\r\ndocker run -p 8001:8001 -v `pwd`:/mnt \\\r\n datasetteproject/datasette \\\r\n datasette -p 8001 -h 0.0.0.0 /mnt/fixtures.db\r\n```\r\n\r\nThis uses `/mnt/fixtures.db` whereas you're using `fixtures.db` - did you try using this path instead?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 806743116, "label": "Installing datasette via docker: Path 'fixtures.db' does not exist"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1200#issuecomment-777132761", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1200", "id": 777132761, "node_id": "MDEyOklzc3VlQ29tbWVudDc3NzEzMjc2MQ==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-02-11T00:29:52Z", "updated_at": "2021-02-11T00:29:52Z", "author_association": "CONTRIBUTOR", "body": "I'm probably missing something but what's the use case here - what would this offer over adding `limit 10` to the query?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 792890765, "label": "?_size=10 option for the arbitrary query page would be useful"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1208#issuecomment-774286962", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1208", "id": 774286962, "node_id": "MDEyOklzc3VlQ29tbWVudDc3NDI4Njk2Mg==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-05T21:02:39Z", "updated_at": "2021-02-05T21:02:39Z", "author_association": "CONTRIBUTOR", "body": "@simonw could you please take a look at the PR 1211 that fixes this issue?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 794554881, "label": "A lot of open(file) functions are used without a context manager thus producing ResourceWarning: unclosed file <_io.TextIOWrapper"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1212#issuecomment-772007663", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1212", "id": 772007663, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MjAwNzY2Mw==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-02T21:36:56Z", "updated_at": "2021-02-02T21:36:56Z", "author_association": "CONTRIBUTOR", "body": "How do you get 4-5 minutes?\r\nI run my tests in WSL 2, so may be i need to try a real linux VM.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797651831, "label": "Tests are very slow. "}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1211#issuecomment-771127458", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1211", "id": 771127458, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MTEyNzQ1OA==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-01T20:13:39Z", "updated_at": "2021-02-01T20:13:39Z", "author_association": "CONTRIBUTOR", "body": "Ping @simonw ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797649915, "label": "Use context manager instead of plain open"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/issues/51#issuecomment-770150526", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/51", "id": 770150526, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MDE1MDUyNg==", "user": {"value": 22578954, "label": "daniel-butler"}, "created_at": "2021-01-30T03:44:19Z", "updated_at": "2021-01-30T03:47:24Z", "author_association": "CONTRIBUTOR", "body": "I don't have much experience with github's rate limiting. In my day job we use the [tenacity library](https://github.com/jd/tenacity) to handle http errors we get.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 703246031, "label": "github-to-sqlite should handle rate limits better"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/issues/60#issuecomment-770112248", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/60", "id": 770112248, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MDExMjI0OA==", "user": {"value": 22578954, "label": "daniel-butler"}, "created_at": "2021-01-30T00:01:03Z", "updated_at": "2021-01-30T01:14:42Z", "author_association": "CONTRIBUTOR", "body": "Yes that would be cool! I wouldn't mind helping. Is this the meat of it? https://github.com/dogsheep/twitter-to-sqlite/blob/21fc1cad6dd6348c67acff90a785b458d3a81275/twitter_to_sqlite/utils.py#L512\r\n\r\nIt looks like the cli option is added with this decorator : https://github.com/dogsheep/twitter-to-sqlite/blob/21fc1cad6dd6348c67acff90a785b458d3a81275/twitter_to_sqlite/cli.py#L14\r\n\r\nI looked a bit at utils.py in the GitHub repository. I was surprised at the amount of manual mapping of the API response you had to do to get this to work.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797097140, "label": "Use Data from SQLite in other commands"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/pull/55#issuecomment-760950128", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/55", "id": 760950128, "node_id": "MDEyOklzc3VlQ29tbWVudDc2MDk1MDEyOA==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-15T13:44:52Z", "updated_at": "2021-01-15T13:44:52Z", "author_association": "CONTRIBUTOR", "body": "I found and fixed another bug, this one around importing the tweets table. @simonw let me know if you'd prefer this broken out into multiple PRs, happy to do that if it makes review/merging easier.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779211940, "label": "Fix archive imports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/issues/54#issuecomment-754729035", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/54", "id": 754729035, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDcyOTAzNQ==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-05T16:03:29Z", "updated_at": "2021-01-05T16:03:29Z", "author_association": "CONTRIBUTOR", "body": "I was able to fix this, at least enough to get _my_ archive to import. Not sure if there's more work to be done here or not.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779088071, "label": "Archive import appears to be broken on recent exports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/pull/55#issuecomment-754728696", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/55", "id": 754728696, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDcyODY5Ng==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-05T16:02:55Z", "updated_at": "2021-01-05T16:02:55Z", "author_association": "CONTRIBUTOR", "body": "This now works for me, though I'm entirely ensure if it's a just-my-export thing or a wider issue. Also, this doesn't contain any tests. So I'm not sure if there's more work to be done here, or if this is good enough.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779211940, "label": "Fix archive imports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/issues/54#issuecomment-754721153", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/54", "id": 754721153, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDcyMTE1Mw==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-05T15:51:09Z", "updated_at": "2021-01-05T15:51:09Z", "author_association": "CONTRIBUTOR", "body": "Correction: the failure is on `lists-member.js` (I was thrown by the `block` variable name, but that's just a coincidence)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779088071, "label": "Archive import appears to be broken on recent exports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1167#issuecomment-754619930", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1167", "id": 754619930, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDYxOTkzMA==", "user": {"value": 3637, "label": "benpickles"}, "created_at": "2021-01-05T12:57:57Z", "updated_at": "2021-01-05T12:57:57Z", "author_association": "CONTRIBUTOR", "body": "Not sure where exactly to put the actual docs (presumably somewhere in [docs/contributing.rst](https://github.com/simonw/datasette/blob/main/docs/contributing.rst)) but I've made a slight change to make it easier to run locally (copying [the approach in excalidraw](https://github.com/excalidraw/excalidraw/blob/ade2565f497243a5e428f4906d8ed80c872fd981/package.json#L90-L94)): https://github.com/simonw/datasette/compare/main...benpickles:prettier-docs\r\n\r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 777145954, "label": "Add Prettier to contributing documentation"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/859#issuecomment-647922203", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/859", "id": 647922203, "node_id": "MDEyOklzc3VlQ29tbWVudDY0NzkyMjIwMw==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-06-23T05:44:58Z", "updated_at": "2021-01-05T08:22:43Z", "author_association": "CONTRIBUTOR", "body": "I'm seeing the problem on database page. Index page and table page runs quite fast.\r\n\r\n- Tables have <10 columns (`id`, `url`, `title`, `body_html`, `date`, `author`, `meta` (for keeping unstructured json)). I've added index on `date` columns (using `sqlite-utils`) in addition to the index present on `id` columns. \r\n- All tables have FTS enabled on `text` and `varchar` columns (`title`, `body_html` etc) to speed up searching.\r\n- There are couple of tables related with foreign keys (think a thread in a forum and posts in that thread, related with `thread_id`)\r\n\r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 642572841, "label": "Database page loads too slowly with many large tables (due to table counts)"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1169#issuecomment-754007242", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1169", "id": 754007242, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDAwNzI0Mg==", "user": {"value": 3637, "label": "benpickles"}, "created_at": "2021-01-04T14:29:57Z", "updated_at": "2021-01-04T14:29:57Z", "author_association": "CONTRIBUTOR", "body": "I somewhat share your reluctance to add a package.json to seemingly every project out there but ultimately if they're project dependencies it's important they're managed within the codebase.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 777677671, "label": "Prettier package not actually being cached"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1170#issuecomment-754004715", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1170", "id": 754004715, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDAwNDcxNQ==", "user": {"value": 3637, "label": "benpickles"}, "created_at": "2021-01-04T14:25:44Z", "updated_at": "2021-01-04T14:25:44Z", "author_association": "CONTRIBUTOR", "body": "I was going to re-add the filter to only run Prettier when there have been changes in `datasette/static` but that would mean it wouldn't run when the package is updated. That plus the fact that [the last run of the job took only 8 seconds](https://github.com/benpickles/datasette/runs/1640121514) is why I decided not to re-add the filter.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 778126516, "label": "Install Prettier via package.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1012#issuecomment-753531657", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1012", "id": 753531657, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MzUzMTY1Nw==", "user": {"value": 45380, "label": "bollwyvl"}, "created_at": "2021-01-02T21:25:36Z", "updated_at": "2021-01-02T21:25:36Z", "author_association": "CONTRIBUTOR", "body": "Actually, on more research, I found out this is handled by the [trove-classifiers package](https://github.com/pypa/trove-classifiers/blob/master/src/trove_classifiers/__init__.py#L2) now, so it's just a one-liner pr instead of fire-up-a-docker-container-and-do-some-migrations", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 718540751, "label": "For 1.0 update trove classifier in setup.py"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/417#issuecomment-752098906", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/417", "id": 752098906, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MjA5ODkwNg==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-12-29T14:34:30Z", "updated_at": "2020-12-29T14:34:50Z", "author_association": "CONTRIBUTOR", "body": "FWIW, I had a look at `watchdog` for a `datasette` powered Jupyter notebook search tool: https://github.com/ouseful-testing/nbsearch/blob/main/nbsearch/nbwatchdog.py\r\n\r\nNot a production thing, just an experiment trying to explore what might be possible...", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 421546944, "label": "Datasette Library"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/pull/59#issuecomment-751375487", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/59", "id": 751375487, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MTM3NTQ4Nw==", "user": {"value": 631242, "label": "frosencrantz"}, "created_at": "2020-12-26T17:08:44Z", "updated_at": "2020-12-26T17:08:44Z", "author_association": "CONTRIBUTOR", "body": "Hi @simonw, do I need to do anything else for this PR to be considered to be included? I've tried using this project and it is quite nice to be able to explore a repository, but noticed that a couple commands don't allow you to use authorization from the environment variable.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 771872303, "label": "Remove unneeded exists=True for -a/--auth flag."}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1158#issuecomment-750389683", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1158", "id": 750389683, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MDM4OTY4Mw==", "user": {"value": 6774676, "label": "eumiro"}, "created_at": "2020-12-23T17:02:50Z", "updated_at": "2020-12-23T17:02:50Z", "author_association": "CONTRIBUTOR", "body": "The dict/set suggestion comes from `pyupgrade --py36-plus`, but then had to `black` the change.\r\n\r\nThe rest comes from PyCharm's Inspect code function. I reviewed all the suggestions and fixed a thing or two, such as leading/trailing spaces in the docstrings or turned around the chained conditions.\r\n\r\nThen I tried to convert all `os.path/glob/open` to `Path`, but there were some local test issues, so I'll have to start over in smaller chunks if you want to have that too.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 773913793, "label": "Modernize code to Python 3.6+"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/pull/31#issuecomment-748562330", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/31", "id": 748562330, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODU2MjMzMA==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2020-12-20T04:45:08Z", "updated_at": "2020-12-20T04:45:08Z", "author_association": "CONTRIBUTOR", "body": "Fixes the issue mentioned here: https://github.com/dogsheep/dogsheep-photos/issues/15#issuecomment-748436115", "reactions": "{\"total_count\": 1, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 1, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 771511344, "label": "Update for Big Sur"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/issues/15#issuecomment-748562288", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/15", "id": 748562288, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODU2MjI4OA==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2020-12-20T04:44:22Z", "updated_at": "2020-12-20T04:44:22Z", "author_association": "CONTRIBUTOR", "body": "@nickvazz @simonw I opened a [PR](https://github.com/dogsheep/dogsheep-photos/pull/31) that replaces the SQL for `ZCOMPUTEDASSETATTRIBUTES` to use osxphotos which now exposes all this data and has been updated for Big Sur. I did regression tests to confirm the extracted data is identical, with one exception which should not affect operation: the old code pulled data from `ZCOMPUTEDASSETATTRIBUTES` for missing photos while the main loop ignores missing photos and does not add them to `apple_photos`. The new code does not add rows to the `apple_photos_scores` table for missing photos.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 612151767, "label": "Expose scores from ZCOMPUTEDASSETATTRIBUTES"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/issues/15#issuecomment-748436779", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/15", "id": 748436779, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODQzNjc3OQ==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2020-12-19T07:49:00Z", "updated_at": "2020-12-19T07:49:00Z", "author_association": "CONTRIBUTOR", "body": "@nickvazz ZGENERICASSET changed to ZASSET in Big Sur. Here's a list of other changes to the schema in Big Sur: https://github.com/RhetTbull/osxphotos/wiki/Changes-in-Photos-6---Big-Sur", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 612151767, "label": "Expose scores from ZCOMPUTEDASSETATTRIBUTES"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/493#issuecomment-748305976", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/493", "id": 748305976, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODMwNTk3Ng==", "user": {"value": 50527, "label": "jefftriplett"}, "created_at": "2020-12-18T20:34:39Z", "updated_at": "2020-12-18T20:34:39Z", "author_association": "CONTRIBUTOR", "body": "I can't keep up with the renaming contexts, but I like having the ability to run datasette+ datasette-ripgrep against different configs: \r\n\r\n```shell\r\ndatasette serve --metadata=./metadata.json\r\n```\r\n\r\nI have one for all of my code and one per client who has lots of code. So as long as I can point to datasette to something, it's easy to work with. ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 449886319, "label": "Rename metadata.json to config.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/998#issuecomment-743080047", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/998", "id": 743080047, "node_id": "MDEyOklzc3VlQ29tbWVudDc0MzA4MDA0Nw==", "user": {"value": 6371750, "label": "JBPressac"}, "created_at": "2020-12-11T09:25:09Z", "updated_at": "2020-12-11T09:25:09Z", "author_association": "CONTRIBUTOR", "body": "Hello Simon,\r\nI have a similar problem with horizontal scrollbar display with Datasette version 0.51 and superior for a table with more than 30 rows. With Datasette 0.50, the horizontal scrollbar is displayed, if I upgrade Datasette to 0.51 and superior, the horizontal scrollbar disappears.\r\n\r\nDatasette 0.50: horizontal scrollbar\r\n\r\n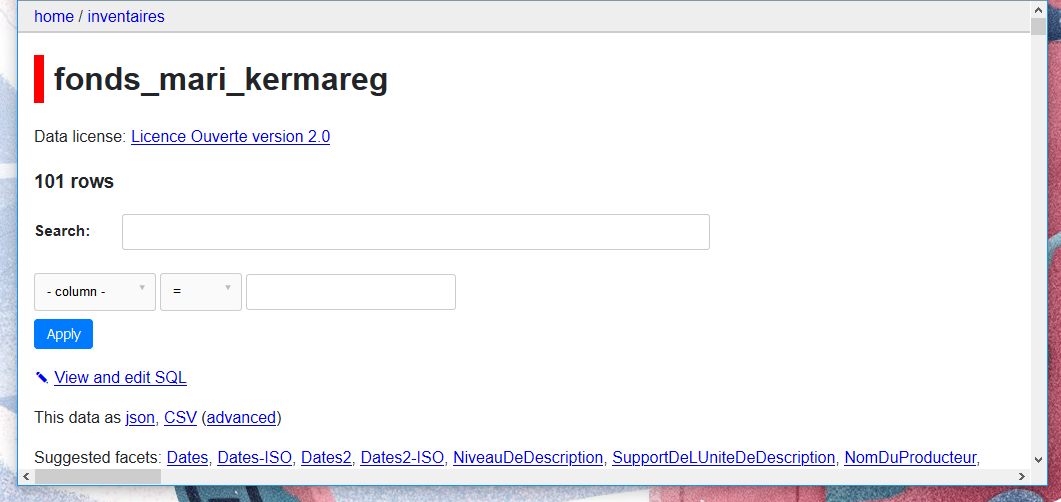\r\n\r\nDatasette 0.51 and superior: no horizontal scrollbar\r\n\r\n\r\n\r\nThanks,", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 717699884, "label": "Wide tables should scroll horizontally within the page"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1130#issuecomment-738907852", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1130", "id": 738907852, "node_id": "MDEyOklzc3VlQ29tbWVudDczODkwNzg1Mg==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-12-04T17:22:29Z", "updated_at": "2020-12-04T17:31:25Z", "author_association": "CONTRIBUTOR", "body": "EDIT: I misunderstood the problem. This seems like a fix better suited for Safari. But I don't have any Apple device to test it.\r\n\r\n```css\r\nbody {\r\n min-height: 100vh;\r\n min-height: -webkit-fill-available;\r\n}\r\nhtml {\r\n height: -webkit-fill-available;\r\n}\r\n```\r\nhttps://css-tricks.com/css-fix-for-100vh-in-mobile-webkit/\r\n\r\n---\r\n\r\nIt's actually not that difficult to fix.\r\nWell, this is actually a workaround to keep viewport in place.\r\n\r\nI usually put a transition (forgot to do it here) that keeps page from resizing.\r\n\r\n```css\r\n.container {\r\n min-height: 100vh;\r\n transition: height 10000s steps(0);\r\n}\r\n```\r\n\r\n`steps()` function prevents excessive layout calculations, and lets the page snap back into place (10000s ~= 3h later) in a single step.\r\nThis fix also prevents page from jumping around when the keyboard pops up and down.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 756876238, "label": "Fix footer not sticking to bottom in short pages"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1111#issuecomment-736322290", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1111", "id": 736322290, "node_id": "MDEyOklzc3VlQ29tbWVudDczNjMyMjI5MA==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-12-01T08:54:47Z", "updated_at": "2020-12-01T08:54:47Z", "author_association": "CONTRIBUTOR", "body": "Somewhat related: https://github.com/simonw/datasette/issues/859\r\nI fixed the issue with forking and disabling the counts for hidden tables.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 751195017, "label": "Accessing a database's `.json` is slow for very large SQLite files"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1114#issuecomment-735436014", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1114", "id": 735436014, "node_id": "MDEyOklzc3VlQ29tbWVudDczNTQzNjAxNA==", "user": {"value": 2182, "label": "danp"}, "created_at": "2020-11-29T18:33:30Z", "updated_at": "2020-11-29T18:33:30Z", "author_association": "CONTRIBUTOR", "body": "Thank you!", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 752966476, "label": "--load-extension=spatialite not working with datasetteproject/datasette docker image"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/493#issuecomment-735281577", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/493", "id": 735281577, "node_id": "MDEyOklzc3VlQ29tbWVudDczNTI4MTU3Nw==", "user": {"value": 50527, "label": "jefftriplett"}, "created_at": "2020-11-28T19:39:53Z", "updated_at": "2020-11-28T19:39:53Z", "author_association": "CONTRIBUTOR", "body": "I was confused by `--config` and I tried passing the json from datasette-ripgrep into `config.json` just as a wild guess. \r\n\r\nA short term solution might be pointing out in plugins that their snippet json can go in `metadata.json` at least makes it easier to search for config options or to know where to start if someone is new. ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 449886319, "label": "Rename metadata.json to config.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1112#issuecomment-735279355", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1112", "id": 735279355, "node_id": "MDEyOklzc3VlQ29tbWVudDczNTI3OTM1NQ==", "user": {"value": 50527, "label": "jefftriplett"}, "created_at": "2020-11-28T19:21:09Z", "updated_at": "2020-11-28T19:21:09Z", "author_association": "CONTRIBUTOR", "body": "(Even more annoying is that I see my editor leaked an extra delete space at the end of the line. I'm happy to rebuild this to be less annoying, but you probably don't want the changelog update either way)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 752749485, "label": "Fix --metadata doc usage"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/838#issuecomment-720354227", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/838", "id": 720354227, "node_id": "MDEyOklzc3VlQ29tbWVudDcyMDM1NDIyNw==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-11-02T09:33:58Z", "updated_at": "2020-11-02T09:33:58Z", "author_association": "CONTRIBUTOR", "body": "Thanks; just a note that the `datasette.urls.static(path)` and `datasette.urls.static_plugins(plugin_name, path)` items both seem to be repeated and appear in the docs twice?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 637395097, "label": "Incorrect URLs when served behind a proxy with base_url set"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1049#issuecomment-718528252", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1049", "id": 718528252, "node_id": "MDEyOklzc3VlQ29tbWVudDcxODUyODI1Mg==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-29T09:20:34Z", "updated_at": "2020-10-29T09:20:34Z", "author_association": "CONTRIBUTOR", "body": "That workaround is probably fine. I was trying to work out whether there might be other situations where a pre-external package load might be useful but couldn't offhand bring any other examples to mind. The static plugins option also looks interesting.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 729017519, "label": "Add template block prior to extra URL loaders"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/189#issuecomment-717359145", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/189", "id": 717359145, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNzM1OTE0NQ==", "user": {"value": 35681, "label": "adamwolf"}, "created_at": "2020-10-27T16:20:32Z", "updated_at": "2020-10-27T16:20:32Z", "author_association": "CONTRIBUTOR", "body": "No problem. I added a test. Let me know if it looks sufficient or if you want me to to tweak something!\r\n\r\nIf you don't mind, would you tag this PR as \"hacktoberfest-accepted\"? If you do mind, no problem and I'm sorry for asking :) My kiddos like the shirts.", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 729818242, "label": "Allow iterables other than Lists in m2m records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1043#issuecomment-716237524", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1043", "id": 716237524, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNjIzNzUyNA==", "user": {"value": 45380, "label": "bollwyvl"}, "created_at": "2020-10-26T00:14:57Z", "updated_at": "2020-10-26T00:14:57Z", "author_association": "CONTRIBUTOR", "body": "Sorry, I was out of the loop this weekend. The missing sdists were in some the `datasette-*` plugins... i'll capture my findings more concretely in one spot when i have a chance...", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 727915394, "label": "Include LICENSE in sdist"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/838#issuecomment-716123598", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/838", "id": 716123598, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNjEyMzU5OA==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-25T10:20:12Z", "updated_at": "2020-10-25T10:53:24Z", "author_association": "CONTRIBUTOR", "body": "I'm trying to [run something behind a MyBinder proxy](https://github.com/ouseful-testing/nbsearch), but seem to have something set up incorrectly and not sure what the fix is?\r\n\r\nI'm starting datasette with jupyter-server-proxy setup:\r\n\r\n```\r\n# __init__.py\r\ndef setup_nbsearch():\r\n\r\n return {\r\n \"command\": [\r\n \"datasette\",\r\n \"serve\",\r\n f\"{_NBSEARCH_DB_PATH}\",\r\n \"-p\",\r\n \"{port}\",\r\n \"--config\",\r\n \"base_url:{base_url}nbsearch/\"\r\n ],\r\n \"absolute_url\": True,\r\n # The following needs a the labextension installing.\r\n # eg in postBuild: jupyter labextension install jupyterlab-server-proxy\r\n \"launcher_entry\": {\r\n \"enabled\": True,\r\n \"title\": \"nbsearch\",\r\n },\r\n }\r\n```\r\n\r\nwhere the `base_url` gets automatically populated by the server-proxy. I define the loaders as:\r\n\r\n```\r\n# __init__.py\r\nfrom datasette import hookimpl\r\n\r\n@hookimpl\r\ndef extra_css_urls(database, table, columns, view_name, datasette):\r\n return [\r\n \"/-/static-plugins/nbsearch/prism.css\",\r\n \"/-/static-plugins/nbsearch/nbsearch.css\",\r\n ]\r\n```\r\nbut these seem to also need a base_url prefix set somehow?\r\n\r\nCurrently, the generated HTML loads properly but internal links are incorrect; eg they take the form `` which resolves to eg `https://notebooks.gesis.org/hub/-/static-plugins/nbsearch/prism.css` rather than required URL of form `https://notebooks.gesis.org/binder/jupyter/user/ouseful-testing-nbsearch-0fx1mx67/nbsearch/-/static-plugins/nbsearch/prism.css`.\r\n\r\nThe main css is loaded correctly: ``", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 637395097, "label": "Incorrect URLs when served behind a proxy with base_url set"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1033#issuecomment-716066000", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1033", "id": 716066000, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNjA2NjAwMA==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-24T22:58:33Z", "updated_at": "2020-10-24T22:58:33Z", "author_association": "CONTRIBUTOR", "body": "From [the docs](https://docs.datasette.io/en/latest/internals.html#datasette-urls), I note:\r\n\r\n```\r\ndatasette.urls.instance()\r\nReturns the URL to the Datasette instance root page. This is usually \"/\"\r\n```\r\n\r\nWhat about the proxy case? Eg if I am using jupyter-server-proxy on a MyBinder or local Jupyter notebook server site, `https://example.com:PORT/weirdpath/datasette`, what does `datasette.urls.instance()` refer to?\r\n\r\n- [ ] `https://example.com:PORT/weirdpath/datasette`\r\n- [ ] `https://example.com:PORT/weirdpath/`\r\n- [ ] `https://example.com:PORT/`\r\n- [ ] `https://example.com`\r\n- [ ] something else?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 725099777, "label": "datasette.urls.static_plugins(...) method"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1012#issuecomment-714908859", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1012", "id": 714908859, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNDkwODg1OQ==", "user": {"value": 45380, "label": "bollwyvl"}, "created_at": "2020-10-23T04:49:20Z", "updated_at": "2020-10-23T04:49:20Z", "author_association": "CONTRIBUTOR", "body": "Good luck on 1.0! It may also be worth lobbying for a `Framework::Datasette::1.0` classifier. This would be a nice way to allow the ecosystem to self-document a bit more [discoverably](https://pypi.org/search/?q=&o=&c=Framework+%3A%3A+Datasette%3A%3A+1.0). \r\n\r\nI was surprised to see the [PR for `Framework::Jupyter`](https://github.com/pypa/warehouse/pull/1905/files) is a... database migration! Of course, there may be more workflow to it!", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 718540751, "label": "For 1.0 update trove classifier in setup.py"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1033#issuecomment-714657366", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1033", "id": 714657366, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNDY1NzM2Ng==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-22T17:51:29Z", "updated_at": "2020-10-22T17:51:29Z", "author_association": "CONTRIBUTOR", "body": "How does `/-/static` relate to [current guidance docs around `static`](https://docs.datasette.io/en/latest/custom_templates.html?highlight=static#serving-static-files) regarding the `--static option` and metadata formulations such as `\"extra_js_urls\": [ \"/static/app.js\"]` (I've not managed to get this to work in a Jupyter server proxied set up; the [datasette / jupyter server proxy repo](https://github.com/simonw/jupyterserverproxy-datasette-demo) may provide a useful test example, eg via MyBinder, for folk to crib from?) ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 725099777, "label": "datasette.urls.static_plugins(...) method"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1019#issuecomment-708520800", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1019", "id": 708520800, "node_id": "MDEyOklzc3VlQ29tbWVudDcwODUyMDgwMA==", "user": {"value": 639012, "label": "jsfenfen"}, "created_at": "2020-10-14T16:37:19Z", "updated_at": "2020-10-14T16:37:19Z", "author_association": "CONTRIBUTOR", "body": "\ud83c\udf89 Thanks so much @simonw ! \ud83c\udf89 ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 721050815, "label": "\"Edit SQL\" button on canned queries"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/swarm-to-sqlite/pull/10#issuecomment-707326192", "issue_url": "https://api.github.com/repos/dogsheep/swarm-to-sqlite/issues/10", "id": 707326192, "node_id": "MDEyOklzc3VlQ29tbWVudDcwNzMyNjE5Mg==", "user": {"value": 29426418, "label": "mattiaborsoi"}, "created_at": "2020-10-12T20:20:02Z", "updated_at": "2020-10-12T20:20:02Z", "author_association": "CONTRIBUTOR", "body": "This closes issue #8 ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 719637258, "label": "Update utils.py to fix sqlite3.OperationalError"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/pull/48#issuecomment-704503719", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/48", "id": 704503719, "node_id": "MDEyOklzc3VlQ29tbWVudDcwNDUwMzcxOQ==", "user": {"value": 755825, "label": "adamjonas"}, "created_at": "2020-10-06T19:26:59Z", "updated_at": "2020-10-06T19:26:59Z", "author_association": "CONTRIBUTOR", "body": "ref #46 ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 681228542, "label": "Add pull requests"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/issues/50#issuecomment-690860653", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/50", "id": 690860653, "node_id": "MDEyOklzc3VlQ29tbWVudDY5MDg2MDY1Mw==", "user": {"value": 370930, "label": "mikepqr"}, "created_at": "2020-09-11T04:04:08Z", "updated_at": "2020-09-11T04:04:08Z", "author_association": "CONTRIBUTOR", "body": "There's probably a nicer way of doing (hence this is a comment rather than a PR), but this appears to fix it:\r\n```diff\r\n--- a/twitter_to_sqlite/utils.py\r\n+++ b/twitter_to_sqlite/utils.py\r\n@@ -181,6 +181,7 @@ def fetch_timeline(\r\n args[\"tweet_mode\"] = \"extended\"\r\n min_seen_id = None\r\n num_rate_limit_errors = 0\r\n+ seen_count = 0\r\n while True:\r\n if min_seen_id is not None:\r\n args[\"max_id\"] = min_seen_id - 1\r\n@@ -208,6 +209,7 @@ def fetch_timeline(\r\n yield tweet\r\n min_seen_id = min(t[\"id\"] for t in tweets)\r\n max_seen_id = max(t[\"id\"] for t in tweets)\r\n+ seen_count += len(tweets)\r\n if last_since_id is not None:\r\n max_seen_id = max((last_since_id, max_seen_id))\r\n last_since_id = max_seen_id\r\n@@ -217,7 +219,9 @@ def fetch_timeline(\r\n replace=True,\r\n )\r\n if stop_after is not None:\r\n- break\r\n+ if seen_count >= stop_after:\r\n+ break\r\n+ args[\"count\"] = min(args[\"count\"], stop_after - seen_count)\r\n time.sleep(sleep)\r\n```", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 698791218, "label": "favorites --stop_after=N stops after min(N, 200)"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/146#issuecomment-688573964", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/146", "id": 688573964, "node_id": "MDEyOklzc3VlQ29tbWVudDY4ODU3Mzk2NA==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-09-08T01:55:07Z", "updated_at": "2020-09-08T01:55:07Z", "author_association": "CONTRIBUTOR", "body": "Okay, I've rewritten this PR to preserve the batching behaviour but still fix #145, and rebased the branch to account for the `db.execute()` api change. It's not terribly sophisticated -- if it attempts to insert a batch which has too many variables, the exception is caught, the batch is split in two and each half is inserted separately, and then it carries on as before with the same `batch_size`. In the edge case where this gets triggered, subsequent batches will all be inserted in two groups too if they continue to have the same number of columns (which is presumably reasonably likely). Do you reckon this is acceptable when set against the awkwardness of recalculating the `batch_size` on the fly?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688668680, "label": "Handle case where subsequent records (after first batch) include extra columns"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/146#issuecomment-688481317", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/146", "id": 688481317, "node_id": "MDEyOklzc3VlQ29tbWVudDY4ODQ4MTMxNw==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-09-07T19:18:55Z", "updated_at": "2020-09-07T19:18:55Z", "author_association": "CONTRIBUTOR", "body": "Just force-pushed to update d042f9c with more formatting changes to satisfy `black==20.8b1` and pass the GitHub Actions \"Test\" workflow.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688668680, "label": "Handle case where subsequent records (after first batch) include extra columns"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/146#issuecomment-688479163", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/146", "id": 688479163, "node_id": "MDEyOklzc3VlQ29tbWVudDY4ODQ3OTE2Mw==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-09-07T19:10:33Z", "updated_at": "2020-09-07T19:11:57Z", "author_association": "CONTRIBUTOR", "body": "@simonw -- I've gone ahead updated the documentation to reflect the changes introduced in this PR. IMO it's ready to merge now.\r\n\r\nIn writing the documentation changes, I begin to wonder about the value and role of `batch_size` at all, tbh. May I assume it was originally intended to prevent using the entire row set to determine columns and column types, and that this was a performance consideration? If so, this PR entirely undermines its purpose. I've been passing in excess of 500,000 rows at a time to `insert_all()` with these changes and although I'm sure the performance difference is measurable it's not really noticeable; given #145, I don't know that any performance advantages outweigh the problems doing it this way removes. What do you think about just dropping the argument and defaulting to the maximum `batch_size` permissible given `SQLITE_MAX_VARS`? Are there other reasons one might want to restrict `batch_size` that I've overlooked? I could open a new issue to discuss/implement this.\r\n\r\nOf course the documentation will need to change again too if/when something is done about #147.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688668680, "label": "Handle case where subsequent records (after first batch) include extra columns"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/952#issuecomment-686061028", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/952", "id": 686061028, "node_id": "MDEyOklzc3VlQ29tbWVudDY4NjA2MTAyOA==", "user": {"value": 27856297, "label": "dependabot-preview[bot]"}, "created_at": "2020-09-02T22:26:14Z", "updated_at": "2020-09-02T22:26:14Z", "author_association": "CONTRIBUTOR", "body": "Looks like black is up-to-date now, so this is no longer needed.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 687245650, "label": "Update black requirement from ~=19.10b0 to >=19.10,<21.0"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/145#issuecomment-683382252", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/145", "id": 683382252, "node_id": "MDEyOklzc3VlQ29tbWVudDY4MzM4MjI1Mg==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-08-30T06:27:25Z", "updated_at": "2020-08-30T06:27:52Z", "author_association": "CONTRIBUTOR", "body": "Note: had to adjust the test above because trying to exhaust a `SQLITE_MAX_VARIABLE_NUMBER` of 250000 in 99 records requires 2526 columns, and trips the ` \"Rows can have a maximum of {} columns\".format(SQLITE_MAX_VARS)` check even before it trips the default `SQLITE_MAX_COLUMN` value (2000).", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688659182, "label": "Bug when first record contains fewer columns than subsequent records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682815377", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/139", "id": 682815377, "node_id": "MDEyOklzc3VlQ29tbWVudDY4MjgxNTM3Nw==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-08-28T16:14:58Z", "updated_at": "2020-08-28T16:14:58Z", "author_association": "CONTRIBUTOR", "body": "Thanks! And yeah, I had updating the docs on my list too :) Will try to get to it this afternoon (budgeting time is fraught with uncertainty at the moment!).", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 686978131, "label": "insert_all(..., alter=True) should work for new columns introduced after the first 100 records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682182178", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/139", "id": 682182178, "node_id": "MDEyOklzc3VlQ29tbWVudDY4MjE4MjE3OA==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-08-27T20:46:18Z", "updated_at": "2020-08-27T20:46:18Z", "author_association": "CONTRIBUTOR", "body": "> I tried changing the batch_size argument to the total number of records, but it seems only to effect the number of rows that are committed at a time, and has no influence on this problem.\r\n\r\nSo the reason for this is that the `batch_size` for import is limited (of necessity) here: https://github.com/simonw/sqlite-utils/blob/main/sqlite_utils/db.py#L1048\r\n\r\nWith regard to the issue of ignoring columns, however, I made a fork and hacked a temporary fix that looks like this:\r\nhttps://github.com/simonwiles/sqlite-utils/commit/3901f43c6a712a1a3efc340b5b8d8fd0cbe8ee63\r\n\r\nIt doesn't seem to affect performance enormously (but I've not tested it thoroughly), and it now does what I need (and would expect, tbh), but it now fails the test here:\r\nhttps://github.com/simonw/sqlite-utils/blob/main/tests/test_create.py#L710-L716\r\n\r\nThe existence of this test suggests that `insert_all()` is behaving as intended, of course. It seems odd to me that this would be a desirable default behaviour (let alone the only behaviour), and its not very prominently flagged-up, either.\r\n\r\n@simonw is this something you'd be willing to look at a PR for? I assume you wouldn't want to change the default behaviour at this point, but perhaps an option could be provided, or at least a bit more of a warning in the docs. Are there oversights in the implementation that I've made?\r\n\r\nWould be grateful for your thoughts! Thanks!\r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 686978131, "label": "insert_all(..., alter=True) should work for new columns introduced after the first 100 records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/456#issuecomment-661524006", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/456", "id": 661524006, "node_id": "MDEyOklzc3VlQ29tbWVudDY2MTUyNDAwNg==", "user": {"value": 32467826, "label": "abeyerpath"}, "created_at": "2020-07-21T01:15:07Z", "updated_at": "2020-07-21T01:15:07Z", "author_association": "CONTRIBUTOR", "body": "Bumping this, as the previous fix is passing the wrong type, and not actually addressing the issue...\r\n\r\nThe `exclude` argument needs an iterable of packages instead of a single string (but since `str` is iterable, it's currently excluding packages `t`, `e`, and `s`.)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 442327592, "label": "Installing installs the tests package"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/121#issuecomment-655898722", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/121", "id": 655898722, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTg5ODcyMg==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-09T04:53:08Z", "updated_at": "2020-07-09T04:53:08Z", "author_association": "CONTRIBUTOR", "body": "Yep, I agree that makes more sense for backwards compat and more casual use cases. I think it should be possible for the Database/Queryable methods to DTRT based on seeing if it's within a context-manager-managed transaction.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 652961907, "label": "Improved (and better documented) support for transactions"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/121#issuecomment-655652679", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/121", "id": 655652679, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTY1MjY3OQ==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-08T17:24:46Z", "updated_at": "2020-07-08T17:24:46Z", "author_association": "CONTRIBUTOR", "body": "Better transaction handling would be really great. Some of my thoughts on implementing better transaction discipline are in https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655239728.\r\n\r\nMy preferences:\r\n\r\n- Each CLI command should operate in a single transaction so that either the whole thing succeeds or the whole thing is rolled back. This avoids partially completed operations when an error occurs part way through processing. Partially completed operations are typically much harder to recovery from gracefully and may cause inconsistent data states.\r\n\r\n- The Python API should be transaction-agnostic and rely on the caller to coordinate transactions. Only the caller knows how individual insert, create, update, etc operations/methods should be bundled conceptually into transactions. When the caller is the CLI, for example, that bundling would be at the CLI command-level. Other callers might want to break up operations into multiple transactions. Transactions are usually most useful when controlled at the application-level (like logging configuration) instead of the library level. The library needs to provide an API that's conducive to transaction use, though.\r\n\r\n- The Python API should provide a context manager to provide consistent transactions handling with more useful defaults than Python's `sqlite3` module. The latter issues implicit `BEGIN` statements by default for most DML (`INSERT`, `UPDATE`, `DELETE`, \u2026 but not `SELECT`, I believe), but **not** DDL (`CREATE TABLE`, `DROP TABLE`, `CREATE VIEW`, \u2026). Notably, the `sqlite3` module doesn't issue the implicit `BEGIN` until the first DML statement. It _does not_ issue it when entering the `with conn` block, like other DBAPI2-compatible modules do. The `with conn` block for `sqlite3` only arranges to commit or rollback an existing transaction when exiting. Including DDL and `SELECT`s in transactions is important for operation consistency, though. There are several existing bugs.python.org tickets about this and future changes are in the works, but sqlite-utils can provide its own API sooner. sqlite-utils's `Database` class could itself be a context manager (built on the `sqlite3` connection context manager) which additionally issues an explicit `BEGIN` when entering. This would then let Python API callers do something like:\r\n\r\n```python\r\ndb = sqlite_utils.Database(path)\r\n\r\nwith db: # \u2190 BEGIN issued here by Database.__enter__\r\n db.insert(\u2026)\r\n db.create_view(\u2026)\r\n# \u2190 COMMIT/ROLLBACK issue here by sqlite3.connection.__exit__\r\n```", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 652961907, "label": "Improved (and better documented) support for transactions"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655643078", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655643078, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTY0MzA3OA==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-08T17:05:59Z", "updated_at": "2020-07-08T17:05:59Z", "author_association": "CONTRIBUTOR", "body": "> The only thing missing from this PR is updates to the documentation.\r\n\r\nAh, yes, thanks for this reminder! I've repushed with doc bits added.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655239728", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655239728, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTIzOTcyOA==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-08T02:16:42Z", "updated_at": "2020-07-08T02:16:42Z", "author_association": "CONTRIBUTOR", "body": "I fixed my original oops by moving the `DELETE FROM $table` out of the chunking loop and repushed. I think this change can be considered in isolation from issues around transactions, which I discuss next.\r\n\r\nI wanted to make the DELETE + INSERT happen all in the same transaction so it was robust, but that was more complicated than I expected. The transaction handling in the Database/Table classes isn't systematic, and this poses big hurdles to making `Table.insert_all` (or other operations) consistent and robust in the face of errors.\r\n\r\nFor example, I wanted to do this (whitespace ignored in diff, so indentation change not highlighted):\r\n\r\n```diff\r\ndiff --git a/sqlite_utils/db.py b/sqlite_utils/db.py\r\nindex d6b9ecf..4107ceb 100644\r\n--- a/sqlite_utils/db.py\r\n+++ b/sqlite_utils/db.py\r\n@@ -1028,6 +1028,11 @@ class Table(Queryable):\r\n batch_size = max(1, min(batch_size, SQLITE_MAX_VARS // num_columns))\r\n self.last_rowid = None\r\n self.last_pk = None\r\n+ with self.db.conn:\r\n+ # Explicit BEGIN is necessary because Python's sqlite3 doesn't\r\n+ # issue implicit BEGINs for DDL, only DML. We mix DDL and DML\r\n+ # below and might execute DDL first, e.g. for table creation.\r\n+ self.db.conn.execute(\"BEGIN\")\r\n if truncate and self.exists():\r\n self.db.conn.execute(\"DELETE FROM [{}];\".format(self.name))\r\n for chunk in chunks(itertools.chain([first_record], records), batch_size):\r\n@@ -1038,7 +1043,11 @@ class Table(Queryable):\r\n # Use the first batch to derive the table names\r\n column_types = suggest_column_types(chunk)\r\n column_types.update(columns or {})\r\n- self.create(\r\n+ # Not self.create() because that is wrapped in its own\r\n+ # transaction and Python's sqlite3 doesn't support\r\n+ # nested transactions.\r\n+ self.db.create_table(\r\n+ self.name,\r\n column_types,\r\n pk,\r\n foreign_keys,\r\n@@ -1139,7 +1148,6 @@ class Table(Queryable):\r\n flat_values = list(itertools.chain(*values))\r\n queries_and_params = [(sql, flat_values)]\r\n \r\n- with self.db.conn:\r\n for query, params in queries_and_params:\r\n try:\r\n result = self.db.conn.execute(query, params)\r\n```\r\n\r\nbut that fails in tests because other methods call `insert/upsert/insert_all/upsert_all` in the middle of their transactions, so the BEGIN statement throws an error (no nested transactions allowed).\r\n\r\nStepping back, it would be nice to make the transaction handling systematic and predictable. One way to do this is to make the `sqlite_utils/db.py` code generally not begin or commit any transactions, and require the caller to do that instead. This lets the caller mix and match the Python API calls into transactions as appropriate (which is impossible for the API methods themselves to fully determine). Then, make `sqlite_utils/cli.py` begin and commit a transaction in each `@cli.command` function, making each command robust and consistent in the face of errors. The big change here, and why I didn't just submit a patch, is that it dramatically changes the Python API to _require_ callers to begin a transaction rather than just immediately calling methods.\r\n\r\nThere is also the caveat that for each transaction, an explicit `BEGIN` is also necessary so that DDL as well as DML (as well as `SELECT`s) are consistent and rolled back on error. There are several bugs.python.org discussions around this particular problem of DDL and some plans to make it better and consistent with DBAPI2, eventually. In the meantime, the sqlite-utils Database class could be a context manager which supports the incantations necessary to do proper transactions. This would still be a Python API change for callers but wouldn't expose them to the weirdness of the sqlite3's default transaction handling.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655052451", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655052451, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTA1MjQ1MQ==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-07T18:45:23Z", "updated_at": "2020-07-07T18:45:23Z", "author_association": "CONTRIBUTOR", "body": "Ah, I see the problem. The truncate is inside a loop I didn't realize was there.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655018966", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655018966, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTAxODk2Ng==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-07T17:41:06Z", "updated_at": "2020-07-07T17:41:06Z", "author_association": "CONTRIBUTOR", "body": "Hmm, while tests pass, this may not work as intended on larger datasets. Looking into it.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/889#issuecomment-653002499", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/889", "id": 653002499, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MzAwMjQ5OQ==", "user": {"value": 49260, "label": "amjith"}, "created_at": "2020-07-02T13:22:13Z", "updated_at": "2020-07-02T13:22:13Z", "author_association": "CONTRIBUTOR", "body": "I was able to narrow this down to the fact that lifespan protocol is turned on. \r\n\r\nI see the workaround you've used here: https://github.com/simonw/datasette-debug-asgi/commit/72d568d32a3159c763ce908c0b269736935c6987\r\n\r\nIf so, maybe it's time to update some of the asg_wrapper [plugins](https://datasette.readthedocs.io/en/stable/plugin_hooks.html#asgi-wrapper-datasette). ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 649907676, "label": "asgi_wrapper plugin hook is crashing at startup"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/889#issuecomment-652990131", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/889", "id": 652990131, "node_id": "MDEyOklzc3VlQ29tbWVudDY1Mjk5MDEzMQ==", "user": {"value": 49260, "label": "amjith"}, "created_at": "2020-07-02T12:58:11Z", "updated_at": "2020-07-02T13:00:18Z", "author_association": "CONTRIBUTOR", "body": "FWIW, this error does NOT happen in datasette 0.45a4.\r\n\r\nIt only started on 0.45a5", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 649907676, "label": "asgi_wrapper plugin hook is crashing at startup"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/883#issuecomment-652394742", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/883", "id": 652394742, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MjM5NDc0Mg==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-07-01T12:41:13Z", "updated_at": "2020-07-01T12:41:13Z", "author_association": "CONTRIBUTOR", "body": "Well tests need to be updated.\r\n \r\nI need to get tests working on Windows.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 648749062, "label": "Skip counting hidden tables"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/883#issuecomment-652297139", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/883", "id": 652297139, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MjI5NzEzOQ==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-07-01T09:11:29Z", "updated_at": "2020-07-01T09:11:29Z", "author_association": "CONTRIBUTOR", "body": "Turns out we should include hidden tables in the result dict, or we're breaking tests. I've committed a refactor https://github.com/simonw/datasette/pull/883/commits/4f06e1bf6fbe4b73be770b87f610bf7c0e6e3ea7", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 648749062, "label": "Skip counting hidden tables"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/877#issuecomment-652255960", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/877", "id": 652255960, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MjI1NTk2MA==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-07-01T07:52:25Z", "updated_at": "2020-07-01T08:10:00Z", "author_association": "CONTRIBUTOR", "body": "I am calling the API from another origin, so injecting CSRF token into templates wouldn't work.\r\n\r\nEDIT:\r\n\r\nI'll try the new version, it sounds promising", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 648421105, "label": "Consider dropping explicit CSRF protection entirely?"}, "performed_via_github_app": null}
 \r\n\r\n------ BEFORE:\r\n
\r\n\r\n------ BEFORE:\r\n \r\n\r\n\r\n\r\n(Note: I didn't figure out how to have one item have no semicolon, while multi-items close with a semicolon, but this is good enough for now. I also didn't figure out how to set up a new jinja filter. I don't want to add to /datasette/utils/__init__.py as I assume that would get overwritten when upgrading datasette. Having a starter guide on creating jinja filters in datasette would be helpful. (The jinja documentation isn't datasette-specific enough for me to quite nail it.)\r\n", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 849220154, "label": "Better default display of arrays of items"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/502#issuecomment-812813732", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/502", "id": 812813732, "node_id": "MDEyOklzc3VlQ29tbWVudDgxMjgxMzczMg==", "user": {"value": 5413548, "label": "louispotok"}, "created_at": "2021-04-03T05:16:54Z", "updated_at": "2021-04-03T05:16:54Z", "author_association": "CONTRIBUTOR", "body": "For what it's worth, if anyone finds this in the future, I was having the same issue. \r\n\r\nAfter digging through the code, it turned out that the database download is only available if it the db served in immutable mode, so `datasette serve -i xyz.db` rather than the doc's quickstart recommendation of `datasette serve xyz.db`.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 453131917, "label": "Exporting sqlite database(s)?"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1286#issuecomment-812679221", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1286", "id": 812679221, "node_id": "MDEyOklzc3VlQ29tbWVudDgxMjY3OTIyMQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-04-02T19:34:01Z", "updated_at": "2021-04-02T19:34:01Z", "author_association": "CONTRIBUTOR", "body": "This shows the city in a different color (and not the comma), but I get the idea, and I like it. (Ooh, could be nice to have the gear have an option in array fields to show as bullets or commas or semicolons...)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 849220154, "label": "Better default display of arrays of items"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1284#issuecomment-810779928", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1284", "id": 810779928, "node_id": "MDEyOklzc3VlQ29tbWVudDgxMDc3OTkyOA==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-31T05:40:12Z", "updated_at": "2021-03-31T05:40:12Z", "author_association": "CONTRIBUTOR", "body": "Maybe the addition of two template files: 'one_database_index.html' and 'one_table_index.html' would be a better idea than the documentation diff idea. (They could include commented instructions to rename the preferred template 'index.html', along with any other necessary guidance.)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 845794436, "label": "Feature or Documentation Request: Individual table as home page template"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1274#issuecomment-805214307", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1274", "id": 805214307, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNTIxNDMwNw==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-03-23T20:12:29Z", "updated_at": "2021-03-23T20:12:29Z", "author_association": "CONTRIBUTOR", "body": "One issue I could see with adding first class support for metadata in hjson format is that this would require adding an additional dependency to handle this, for a feature that would be unused by many users. I wonder if this could fit in as a plugin instead; if a hook existed for loading metadata (maybe as part of https://github.com/simonw/datasette/issues/860) the metadata could then come from any source, as specified by plugins, e.g. hjson, toml, XML, a database table etc.\r\n\r\nUntil/unless this exists, a few ideas for how you could add comments:\r\n- Using YAML as you suggest.\r\n- A common pattern is adding a `\"comment\"` key for comments to any object in JSON - I don't think including an unnecessary key like this would break anything in Datasette, but not certain.\r\n- You could use another tool as a preprocessor for your JSON metadata - e.g. hjson or Jsonnet. You'd write the metadata in that format, and then convert that into JSON to actually use as your final metadata.", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 839008371, "label": "Might there be some way to comment metadata.json?"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1153#issuecomment-804640440", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1153", "id": 804640440, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDY0MDQ0MA==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T05:58:20Z", "updated_at": "2021-03-23T05:58:20Z", "author_association": "CONTRIBUTOR", "body": "Could there be a little widget that offers conversion from one to the other? ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 771202454, "label": "Use YAML examples in documentation by default, not JSON"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1159#issuecomment-804639427", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1159", "id": 804639427, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDYzOTQyNw==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T05:56:02Z", "updated_at": "2021-03-23T05:56:02Z", "author_association": "CONTRIBUTOR", "body": "With just three facets, I like it, but it does take more horizontal space. Would be nice to have a switch somewhere, enabling either original compact option or this proposed more-readable option. Also some control over word wrap (width setting) and facet spacing. ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 774332247, "label": "Improve the display of facets information"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/164#issuecomment-804541064", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/164", "id": 804541064, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDU0MTA2NA==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T02:45:12Z", "updated_at": "2021-03-23T02:45:12Z", "author_association": "CONTRIBUTOR", "body": "\"datasette skeleton\" feature removed #476", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 280013907, "label": "datasette skeleton command for kick-starting database and table metadata"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/163#issuecomment-804539729", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/163", "id": 804539729, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDUzOTcyOQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T02:41:14Z", "updated_at": "2021-03-23T02:41:14Z", "author_association": "CONTRIBUTOR", "body": "I'm visiting old issues for context while learning datasette. Let me know if okay to make the occasional comment like this one.\r\nquerystring argument now located at:\r\nhttps://docs.datasette.io/en/latest/settings.html#sql-time-limit-ms", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 279547886, "label": "Document the querystring argument for setting a different time limit"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/88#issuecomment-804471733", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/88", "id": 804471733, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDQ3MTczMw==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-22T23:46:36Z", "updated_at": "2021-03-22T23:46:36Z", "author_association": "CONTRIBUTOR", "body": "Google Map API limits seem to prevent https://nhs-england-map.netlify.com from being a working demo.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 273775212, "label": "Add NHS England Hospitals example to wiki"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1149#issuecomment-804415619", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1149", "id": 804415619, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDQxNTYxOQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-22T21:43:16Z", "updated_at": "2021-03-22T21:43:16Z", "author_association": "CONTRIBUTOR", "body": "Sounds like a good idea.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 769520939, "label": "Make it easier to theme Datasette with CSS"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/942#issuecomment-803631102", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/942", "id": 803631102, "node_id": "MDEyOklzc3VlQ29tbWVudDgwMzYzMTEwMg==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-21T17:48:42Z", "updated_at": "2021-03-21T17:48:42Z", "author_association": "CONTRIBUTOR", "body": "I like this idea. Though it might be nice to have some kind of automated system from database to file, so that developers could easily track diffs.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 681334912, "label": "Support column descriptions in metadata.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1265#issuecomment-802923254", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1265", "id": 802923254, "node_id": "MDEyOklzc3VlQ29tbWVudDgwMjkyMzI1NA==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-03-19T15:39:15Z", "updated_at": "2021-03-19T15:39:15Z", "author_association": "CONTRIBUTOR", "body": "It doesn't use basic auth, but you can put a whole datasette instance, or parts of this, behind a username/password prompt using https://github.com/simonw/datasette-auth-passwords", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 836123030, "label": "Support for HTTP Basic Authentication"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1262#issuecomment-802095132", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1262", "id": 802095132, "node_id": "MDEyOklzc3VlQ29tbWVudDgwMjA5NTEzMg==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-03-18T16:37:45Z", "updated_at": "2021-03-18T16:37:45Z", "author_association": "CONTRIBUTOR", "body": "This sounds like a good use case for a plugin, since this will only be useful for a subset of Datasette users. It shouldn't be too difficult to add a button to do this with the available plugin hooks - have you taken a look at https://docs.datasette.io/en/latest/writing_plugins.html?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 834602299, "label": "Plugin hook that could support 'order by random()' for table view"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/236#issuecomment-799003172", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/236", "id": 799003172, "node_id": "MDEyOklzc3VlQ29tbWVudDc5OTAwMzE3Mg==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-03-14T23:42:57Z", "updated_at": "2021-03-14T23:42:57Z", "author_association": "CONTRIBUTOR", "body": "Oh, and the container image can be up to 10GB, so the EFS step might not be needed except for pretty big stuff.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 317001500, "label": "datasette publish lambda plugin"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/236#issuecomment-799002993", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/236", "id": 799002993, "node_id": "MDEyOklzc3VlQ29tbWVudDc5OTAwMjk5Mw==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-03-14T23:41:51Z", "updated_at": "2021-03-14T23:41:51Z", "author_association": "CONTRIBUTOR", "body": "Now that [Lambda supports Docker](https://aws.amazon.com/blogs/aws/new-for-aws-lambda-container-image-support/), this probably is a bit easier and may be able to build on top of the existing package command.\r\n\r\nThere are weirdnesses in how the command actually gets invoked; the [aws-lambda-python image](https://hub.docker.com/r/amazon/aws-lambda-python) shows a bit of that. So Datasette would probably need some sort of Lambda-specific entry point to make this work.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 317001500, "label": "datasette publish lambda plugin"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1256#issuecomment-795112935", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1256", "id": 795112935, "node_id": "MDEyOklzc3VlQ29tbWVudDc5NTExMjkzNQ==", "user": {"value": 6371750, "label": "JBPressac"}, "created_at": "2021-03-10T08:59:45Z", "updated_at": "2021-03-10T08:59:45Z", "author_association": "CONTRIBUTOR", "body": "Sorry, I meant \"minor typo\" not \"minor type\".", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 827341657, "label": "Minor type in IP adress"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/766#issuecomment-791509910", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/766", "id": 791509910, "node_id": "MDEyOklzc3VlQ29tbWVudDc5MTUwOTkxMA==", "user": {"value": 6371750, "label": "JBPressac"}, "created_at": "2021-03-05T15:57:35Z", "updated_at": "2021-03-05T16:35:21Z", "author_association": "CONTRIBUTOR", "body": "Hello, \r\nI have the same wildcards search problems with an instance of Datasette. http://crbc-dataset.huma-num.fr/inventaires/fonds_auguste_dupouy_1872_1967?_search=gwerz&_sort=rowid is OK but http://crbc-dataset.huma-num.fr/inventaires/fonds_auguste_dupouy_1872_1967?_search=gwe* is not (FTS is activated on \"Reference\" \"IntituleAnalyse\" \"NomDuProducteur\" \"PresentationDuContenu\" \"Notes\"). \r\n\r\nNotice that a SQL query as below launched directly from SQLite in the server's shell, retrieves results.\r\n\r\n`select * from fonds_auguste_dupouy_1872_1967_fts where IntituleAnalyse MATCH \"gwe*\";`\r\n\r\nThanks,", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 617323873, "label": "Enable wildcard-searches by default"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1238#issuecomment-789186458", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1238", "id": 789186458, "node_id": "MDEyOklzc3VlQ29tbWVudDc4OTE4NjQ1OA==", "user": {"value": 198537, "label": "rgieseke"}, "created_at": "2021-03-02T20:19:30Z", "updated_at": "2021-03-02T20:19:30Z", "author_association": "CONTRIBUTOR", "body": "A custom `templates/index.html` seems to work and custom `pages` as a workaround with moving them to `pages/base_url_dir`.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 813899472, "label": "Custom pages don't work with base_url setting"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/242#issuecomment-787121933", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/242", "id": 787121933, "node_id": "MDEyOklzc3VlQ29tbWVudDc4NzEyMTkzMw==", "user": {"value": 25778, "label": "eyeseast"}, "created_at": "2021-02-27T19:18:57Z", "updated_at": "2021-02-27T19:18:57Z", "author_association": "CONTRIBUTOR", "body": "I think HTTPX gets it exactly right, with a clear separation between sync and async clients, each with a basically identical API. (I'm about to switch [feed-to-sqlite](https://github.com/eyeseast/feed-to-sqlite) over to it, from Requests, to eventually make way for async support.)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 817989436, "label": "Async support"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1212#issuecomment-782430028", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1212", "id": 782430028, "node_id": "MDEyOklzc3VlQ29tbWVudDc4MjQzMDAyOA==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-19T22:54:13Z", "updated_at": "2021-02-19T22:54:13Z", "author_association": "CONTRIBUTOR", "body": "I will close this issue since it appears only in my particular setup.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797651831, "label": "Tests are very slow. "}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1229#issuecomment-782053455", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1229", "id": 782053455, "node_id": "MDEyOklzc3VlQ29tbWVudDc4MjA1MzQ1NQ==", "user": {"value": 295329, "label": "camallen"}, "created_at": "2021-02-19T12:47:19Z", "updated_at": "2021-02-19T12:47:19Z", "author_association": "CONTRIBUTOR", "body": "I believe this pr and #1031 are related and fix the same issue.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 810507413, "label": "ensure immutable databses when starting in configuration directory mode with"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1220#issuecomment-778439617", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1220", "id": 778439617, "node_id": "MDEyOklzc3VlQ29tbWVudDc3ODQzOTYxNw==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-02-12T20:33:27Z", "updated_at": "2021-02-12T20:33:27Z", "author_association": "CONTRIBUTOR", "body": "That Docker command will mount your current directory inside the Docker container at `/mnt` - so you shouldn't need to change anything locally, just run\r\n\r\n```\r\ndocker run -p 8001:8001 -v `pwd`:/mnt \\\r\n datasetteproject/datasette \\\r\n datasette -p 8001 -h 0.0.0.0 /mnt/fixtures.db\r\n```\r\n\r\nand it will use the `fixtures.db` file within your current directory", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 806743116, "label": "Installing datasette via docker: Path 'fixtures.db' does not exist"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/issues/60#issuecomment-770069864", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/60", "id": 770069864, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MDA2OTg2NA==", "user": {"value": 22578954, "label": "daniel-butler"}, "created_at": "2021-01-29T21:52:05Z", "updated_at": "2021-02-12T18:29:43Z", "author_association": "CONTRIBUTOR", "body": "For the purposes below I am assuming the organization I would get all the repositories and their related commits from is called `gh-organization`. The github's owner id of gh-orgnization is `123456789`.\r\n\r\n```bash\r\ngithub-to-sqlite repos github.db gh-organization\r\n```\r\n\r\nI'm on a windows computer running git bash to be able to use the `|` command. This works for me\r\n```bash\r\nsqlite3 github.db \"SELECT full_name FROM repos WHERE owner = '123456789';\" | tr '\\n\\r' ' ' | xargs | { read repos; github-to-sqlite commits github.db $repos; }\r\n```\r\n\r\nOn a pure linux system I think this would work because the new line character is normally `\\n`\r\n```bash\r\nsqlite3 github.db \"SELECT full_name FROM repos WHERE owner = '123456789';\" | tr '\\n' ' ' | xargs | { read repos; github-to-sqlite commits github.db $repos; }`\r\n```\r\n\r\nAs expected I ran into rate limit issues #51 \r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797097140, "label": "Use Data from SQLite in other commands"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/issues/33#issuecomment-778246347", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/33", "id": 778246347, "node_id": "MDEyOklzc3VlQ29tbWVudDc3ODI0NjM0Nw==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2021-02-12T15:00:43Z", "updated_at": "2021-02-12T15:00:43Z", "author_association": "CONTRIBUTOR", "body": "Yes, Big Sur Photos database doesn't have `ZGENERICASSET` table. PR #31 will fix this.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 803338729, "label": "photo-to-sqlite: command not found"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1220#issuecomment-777927946", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1220", "id": 777927946, "node_id": "MDEyOklzc3VlQ29tbWVudDc3NzkyNzk0Ng==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-02-12T02:29:54Z", "updated_at": "2021-02-12T02:29:54Z", "author_association": "CONTRIBUTOR", "body": "According to https://github.com/simonw/datasette/blob/master/docs/installation.rst#using-docker it should be\r\n\r\n```\r\ndocker run -p 8001:8001 -v `pwd`:/mnt \\\r\n datasetteproject/datasette \\\r\n datasette -p 8001 -h 0.0.0.0 /mnt/fixtures.db\r\n```\r\n\r\nThis uses `/mnt/fixtures.db` whereas you're using `fixtures.db` - did you try using this path instead?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 806743116, "label": "Installing datasette via docker: Path 'fixtures.db' does not exist"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1200#issuecomment-777132761", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1200", "id": 777132761, "node_id": "MDEyOklzc3VlQ29tbWVudDc3NzEzMjc2MQ==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-02-11T00:29:52Z", "updated_at": "2021-02-11T00:29:52Z", "author_association": "CONTRIBUTOR", "body": "I'm probably missing something but what's the use case here - what would this offer over adding `limit 10` to the query?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 792890765, "label": "?_size=10 option for the arbitrary query page would be useful"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1208#issuecomment-774286962", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1208", "id": 774286962, "node_id": "MDEyOklzc3VlQ29tbWVudDc3NDI4Njk2Mg==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-05T21:02:39Z", "updated_at": "2021-02-05T21:02:39Z", "author_association": "CONTRIBUTOR", "body": "@simonw could you please take a look at the PR 1211 that fixes this issue?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 794554881, "label": "A lot of open(file) functions are used without a context manager thus producing ResourceWarning: unclosed file <_io.TextIOWrapper"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1212#issuecomment-772007663", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1212", "id": 772007663, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MjAwNzY2Mw==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-02T21:36:56Z", "updated_at": "2021-02-02T21:36:56Z", "author_association": "CONTRIBUTOR", "body": "How do you get 4-5 minutes?\r\nI run my tests in WSL 2, so may be i need to try a real linux VM.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797651831, "label": "Tests are very slow. "}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1211#issuecomment-771127458", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1211", "id": 771127458, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MTEyNzQ1OA==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-01T20:13:39Z", "updated_at": "2021-02-01T20:13:39Z", "author_association": "CONTRIBUTOR", "body": "Ping @simonw ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797649915, "label": "Use context manager instead of plain open"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/issues/51#issuecomment-770150526", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/51", "id": 770150526, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MDE1MDUyNg==", "user": {"value": 22578954, "label": "daniel-butler"}, "created_at": "2021-01-30T03:44:19Z", "updated_at": "2021-01-30T03:47:24Z", "author_association": "CONTRIBUTOR", "body": "I don't have much experience with github's rate limiting. In my day job we use the [tenacity library](https://github.com/jd/tenacity) to handle http errors we get.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 703246031, "label": "github-to-sqlite should handle rate limits better"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/issues/60#issuecomment-770112248", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/60", "id": 770112248, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MDExMjI0OA==", "user": {"value": 22578954, "label": "daniel-butler"}, "created_at": "2021-01-30T00:01:03Z", "updated_at": "2021-01-30T01:14:42Z", "author_association": "CONTRIBUTOR", "body": "Yes that would be cool! I wouldn't mind helping. Is this the meat of it? https://github.com/dogsheep/twitter-to-sqlite/blob/21fc1cad6dd6348c67acff90a785b458d3a81275/twitter_to_sqlite/utils.py#L512\r\n\r\nIt looks like the cli option is added with this decorator : https://github.com/dogsheep/twitter-to-sqlite/blob/21fc1cad6dd6348c67acff90a785b458d3a81275/twitter_to_sqlite/cli.py#L14\r\n\r\nI looked a bit at utils.py in the GitHub repository. I was surprised at the amount of manual mapping of the API response you had to do to get this to work.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797097140, "label": "Use Data from SQLite in other commands"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/pull/55#issuecomment-760950128", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/55", "id": 760950128, "node_id": "MDEyOklzc3VlQ29tbWVudDc2MDk1MDEyOA==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-15T13:44:52Z", "updated_at": "2021-01-15T13:44:52Z", "author_association": "CONTRIBUTOR", "body": "I found and fixed another bug, this one around importing the tweets table. @simonw let me know if you'd prefer this broken out into multiple PRs, happy to do that if it makes review/merging easier.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779211940, "label": "Fix archive imports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/issues/54#issuecomment-754729035", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/54", "id": 754729035, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDcyOTAzNQ==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-05T16:03:29Z", "updated_at": "2021-01-05T16:03:29Z", "author_association": "CONTRIBUTOR", "body": "I was able to fix this, at least enough to get _my_ archive to import. Not sure if there's more work to be done here or not.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779088071, "label": "Archive import appears to be broken on recent exports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/pull/55#issuecomment-754728696", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/55", "id": 754728696, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDcyODY5Ng==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-05T16:02:55Z", "updated_at": "2021-01-05T16:02:55Z", "author_association": "CONTRIBUTOR", "body": "This now works for me, though I'm entirely ensure if it's a just-my-export thing or a wider issue. Also, this doesn't contain any tests. So I'm not sure if there's more work to be done here, or if this is good enough.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779211940, "label": "Fix archive imports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/issues/54#issuecomment-754721153", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/54", "id": 754721153, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDcyMTE1Mw==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-05T15:51:09Z", "updated_at": "2021-01-05T15:51:09Z", "author_association": "CONTRIBUTOR", "body": "Correction: the failure is on `lists-member.js` (I was thrown by the `block` variable name, but that's just a coincidence)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779088071, "label": "Archive import appears to be broken on recent exports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1167#issuecomment-754619930", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1167", "id": 754619930, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDYxOTkzMA==", "user": {"value": 3637, "label": "benpickles"}, "created_at": "2021-01-05T12:57:57Z", "updated_at": "2021-01-05T12:57:57Z", "author_association": "CONTRIBUTOR", "body": "Not sure where exactly to put the actual docs (presumably somewhere in [docs/contributing.rst](https://github.com/simonw/datasette/blob/main/docs/contributing.rst)) but I've made a slight change to make it easier to run locally (copying [the approach in excalidraw](https://github.com/excalidraw/excalidraw/blob/ade2565f497243a5e428f4906d8ed80c872fd981/package.json#L90-L94)): https://github.com/simonw/datasette/compare/main...benpickles:prettier-docs\r\n\r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 777145954, "label": "Add Prettier to contributing documentation"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/859#issuecomment-647922203", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/859", "id": 647922203, "node_id": "MDEyOklzc3VlQ29tbWVudDY0NzkyMjIwMw==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-06-23T05:44:58Z", "updated_at": "2021-01-05T08:22:43Z", "author_association": "CONTRIBUTOR", "body": "I'm seeing the problem on database page. Index page and table page runs quite fast.\r\n\r\n- Tables have <10 columns (`id`, `url`, `title`, `body_html`, `date`, `author`, `meta` (for keeping unstructured json)). I've added index on `date` columns (using `sqlite-utils`) in addition to the index present on `id` columns. \r\n- All tables have FTS enabled on `text` and `varchar` columns (`title`, `body_html` etc) to speed up searching.\r\n- There are couple of tables related with foreign keys (think a thread in a forum and posts in that thread, related with `thread_id`)\r\n\r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 642572841, "label": "Database page loads too slowly with many large tables (due to table counts)"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1169#issuecomment-754007242", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1169", "id": 754007242, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDAwNzI0Mg==", "user": {"value": 3637, "label": "benpickles"}, "created_at": "2021-01-04T14:29:57Z", "updated_at": "2021-01-04T14:29:57Z", "author_association": "CONTRIBUTOR", "body": "I somewhat share your reluctance to add a package.json to seemingly every project out there but ultimately if they're project dependencies it's important they're managed within the codebase.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 777677671, "label": "Prettier package not actually being cached"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1170#issuecomment-754004715", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1170", "id": 754004715, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDAwNDcxNQ==", "user": {"value": 3637, "label": "benpickles"}, "created_at": "2021-01-04T14:25:44Z", "updated_at": "2021-01-04T14:25:44Z", "author_association": "CONTRIBUTOR", "body": "I was going to re-add the filter to only run Prettier when there have been changes in `datasette/static` but that would mean it wouldn't run when the package is updated. That plus the fact that [the last run of the job took only 8 seconds](https://github.com/benpickles/datasette/runs/1640121514) is why I decided not to re-add the filter.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 778126516, "label": "Install Prettier via package.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1012#issuecomment-753531657", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1012", "id": 753531657, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MzUzMTY1Nw==", "user": {"value": 45380, "label": "bollwyvl"}, "created_at": "2021-01-02T21:25:36Z", "updated_at": "2021-01-02T21:25:36Z", "author_association": "CONTRIBUTOR", "body": "Actually, on more research, I found out this is handled by the [trove-classifiers package](https://github.com/pypa/trove-classifiers/blob/master/src/trove_classifiers/__init__.py#L2) now, so it's just a one-liner pr instead of fire-up-a-docker-container-and-do-some-migrations", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 718540751, "label": "For 1.0 update trove classifier in setup.py"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/417#issuecomment-752098906", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/417", "id": 752098906, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MjA5ODkwNg==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-12-29T14:34:30Z", "updated_at": "2020-12-29T14:34:50Z", "author_association": "CONTRIBUTOR", "body": "FWIW, I had a look at `watchdog` for a `datasette` powered Jupyter notebook search tool: https://github.com/ouseful-testing/nbsearch/blob/main/nbsearch/nbwatchdog.py\r\n\r\nNot a production thing, just an experiment trying to explore what might be possible...", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 421546944, "label": "Datasette Library"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/pull/59#issuecomment-751375487", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/59", "id": 751375487, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MTM3NTQ4Nw==", "user": {"value": 631242, "label": "frosencrantz"}, "created_at": "2020-12-26T17:08:44Z", "updated_at": "2020-12-26T17:08:44Z", "author_association": "CONTRIBUTOR", "body": "Hi @simonw, do I need to do anything else for this PR to be considered to be included? I've tried using this project and it is quite nice to be able to explore a repository, but noticed that a couple commands don't allow you to use authorization from the environment variable.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 771872303, "label": "Remove unneeded exists=True for -a/--auth flag."}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1158#issuecomment-750389683", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1158", "id": 750389683, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MDM4OTY4Mw==", "user": {"value": 6774676, "label": "eumiro"}, "created_at": "2020-12-23T17:02:50Z", "updated_at": "2020-12-23T17:02:50Z", "author_association": "CONTRIBUTOR", "body": "The dict/set suggestion comes from `pyupgrade --py36-plus`, but then had to `black` the change.\r\n\r\nThe rest comes from PyCharm's Inspect code function. I reviewed all the suggestions and fixed a thing or two, such as leading/trailing spaces in the docstrings or turned around the chained conditions.\r\n\r\nThen I tried to convert all `os.path/glob/open` to `Path`, but there were some local test issues, so I'll have to start over in smaller chunks if you want to have that too.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 773913793, "label": "Modernize code to Python 3.6+"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/pull/31#issuecomment-748562330", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/31", "id": 748562330, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODU2MjMzMA==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2020-12-20T04:45:08Z", "updated_at": "2020-12-20T04:45:08Z", "author_association": "CONTRIBUTOR", "body": "Fixes the issue mentioned here: https://github.com/dogsheep/dogsheep-photos/issues/15#issuecomment-748436115", "reactions": "{\"total_count\": 1, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 1, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 771511344, "label": "Update for Big Sur"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/issues/15#issuecomment-748562288", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/15", "id": 748562288, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODU2MjI4OA==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2020-12-20T04:44:22Z", "updated_at": "2020-12-20T04:44:22Z", "author_association": "CONTRIBUTOR", "body": "@nickvazz @simonw I opened a [PR](https://github.com/dogsheep/dogsheep-photos/pull/31) that replaces the SQL for `ZCOMPUTEDASSETATTRIBUTES` to use osxphotos which now exposes all this data and has been updated for Big Sur. I did regression tests to confirm the extracted data is identical, with one exception which should not affect operation: the old code pulled data from `ZCOMPUTEDASSETATTRIBUTES` for missing photos while the main loop ignores missing photos and does not add them to `apple_photos`. The new code does not add rows to the `apple_photos_scores` table for missing photos.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 612151767, "label": "Expose scores from ZCOMPUTEDASSETATTRIBUTES"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/issues/15#issuecomment-748436779", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/15", "id": 748436779, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODQzNjc3OQ==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2020-12-19T07:49:00Z", "updated_at": "2020-12-19T07:49:00Z", "author_association": "CONTRIBUTOR", "body": "@nickvazz ZGENERICASSET changed to ZASSET in Big Sur. Here's a list of other changes to the schema in Big Sur: https://github.com/RhetTbull/osxphotos/wiki/Changes-in-Photos-6---Big-Sur", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 612151767, "label": "Expose scores from ZCOMPUTEDASSETATTRIBUTES"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/493#issuecomment-748305976", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/493", "id": 748305976, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODMwNTk3Ng==", "user": {"value": 50527, "label": "jefftriplett"}, "created_at": "2020-12-18T20:34:39Z", "updated_at": "2020-12-18T20:34:39Z", "author_association": "CONTRIBUTOR", "body": "I can't keep up with the renaming contexts, but I like having the ability to run datasette+ datasette-ripgrep against different configs: \r\n\r\n```shell\r\ndatasette serve --metadata=./metadata.json\r\n```\r\n\r\nI have one for all of my code and one per client who has lots of code. So as long as I can point to datasette to something, it's easy to work with. ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 449886319, "label": "Rename metadata.json to config.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/998#issuecomment-743080047", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/998", "id": 743080047, "node_id": "MDEyOklzc3VlQ29tbWVudDc0MzA4MDA0Nw==", "user": {"value": 6371750, "label": "JBPressac"}, "created_at": "2020-12-11T09:25:09Z", "updated_at": "2020-12-11T09:25:09Z", "author_association": "CONTRIBUTOR", "body": "Hello Simon,\r\nI have a similar problem with horizontal scrollbar display with Datasette version 0.51 and superior for a table with more than 30 rows. With Datasette 0.50, the horizontal scrollbar is displayed, if I upgrade Datasette to 0.51 and superior, the horizontal scrollbar disappears.\r\n\r\nDatasette 0.50: horizontal scrollbar\r\n\r\n\r\n\r\nDatasette 0.51 and superior: no horizontal scrollbar\r\n\r\n\r\n\r\nThanks,", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 717699884, "label": "Wide tables should scroll horizontally within the page"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1130#issuecomment-738907852", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1130", "id": 738907852, "node_id": "MDEyOklzc3VlQ29tbWVudDczODkwNzg1Mg==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-12-04T17:22:29Z", "updated_at": "2020-12-04T17:31:25Z", "author_association": "CONTRIBUTOR", "body": "EDIT: I misunderstood the problem. This seems like a fix better suited for Safari. But I don't have any Apple device to test it.\r\n\r\n```css\r\nbody {\r\n min-height: 100vh;\r\n min-height: -webkit-fill-available;\r\n}\r\nhtml {\r\n height: -webkit-fill-available;\r\n}\r\n```\r\nhttps://css-tricks.com/css-fix-for-100vh-in-mobile-webkit/\r\n\r\n---\r\n\r\nIt's actually not that difficult to fix.\r\nWell, this is actually a workaround to keep viewport in place.\r\n\r\nI usually put a transition (forgot to do it here) that keeps page from resizing.\r\n\r\n```css\r\n.container {\r\n min-height: 100vh;\r\n transition: height 10000s steps(0);\r\n}\r\n```\r\n\r\n`steps()` function prevents excessive layout calculations, and lets the page snap back into place (10000s ~= 3h later) in a single step.\r\nThis fix also prevents page from jumping around when the keyboard pops up and down.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 756876238, "label": "Fix footer not sticking to bottom in short pages"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1111#issuecomment-736322290", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1111", "id": 736322290, "node_id": "MDEyOklzc3VlQ29tbWVudDczNjMyMjI5MA==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-12-01T08:54:47Z", "updated_at": "2020-12-01T08:54:47Z", "author_association": "CONTRIBUTOR", "body": "Somewhat related: https://github.com/simonw/datasette/issues/859\r\nI fixed the issue with forking and disabling the counts for hidden tables.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 751195017, "label": "Accessing a database's `.json` is slow for very large SQLite files"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1114#issuecomment-735436014", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1114", "id": 735436014, "node_id": "MDEyOklzc3VlQ29tbWVudDczNTQzNjAxNA==", "user": {"value": 2182, "label": "danp"}, "created_at": "2020-11-29T18:33:30Z", "updated_at": "2020-11-29T18:33:30Z", "author_association": "CONTRIBUTOR", "body": "Thank you!", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 752966476, "label": "--load-extension=spatialite not working with datasetteproject/datasette docker image"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/493#issuecomment-735281577", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/493", "id": 735281577, "node_id": "MDEyOklzc3VlQ29tbWVudDczNTI4MTU3Nw==", "user": {"value": 50527, "label": "jefftriplett"}, "created_at": "2020-11-28T19:39:53Z", "updated_at": "2020-11-28T19:39:53Z", "author_association": "CONTRIBUTOR", "body": "I was confused by `--config` and I tried passing the json from datasette-ripgrep into `config.json` just as a wild guess. \r\n\r\nA short term solution might be pointing out in plugins that their snippet json can go in `metadata.json` at least makes it easier to search for config options or to know where to start if someone is new. ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 449886319, "label": "Rename metadata.json to config.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1112#issuecomment-735279355", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1112", "id": 735279355, "node_id": "MDEyOklzc3VlQ29tbWVudDczNTI3OTM1NQ==", "user": {"value": 50527, "label": "jefftriplett"}, "created_at": "2020-11-28T19:21:09Z", "updated_at": "2020-11-28T19:21:09Z", "author_association": "CONTRIBUTOR", "body": "(Even more annoying is that I see my editor leaked an extra delete space at the end of the line. I'm happy to rebuild this to be less annoying, but you probably don't want the changelog update either way)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 752749485, "label": "Fix --metadata doc usage"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/838#issuecomment-720354227", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/838", "id": 720354227, "node_id": "MDEyOklzc3VlQ29tbWVudDcyMDM1NDIyNw==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-11-02T09:33:58Z", "updated_at": "2020-11-02T09:33:58Z", "author_association": "CONTRIBUTOR", "body": "Thanks; just a note that the `datasette.urls.static(path)` and `datasette.urls.static_plugins(plugin_name, path)` items both seem to be repeated and appear in the docs twice?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 637395097, "label": "Incorrect URLs when served behind a proxy with base_url set"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1049#issuecomment-718528252", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1049", "id": 718528252, "node_id": "MDEyOklzc3VlQ29tbWVudDcxODUyODI1Mg==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-29T09:20:34Z", "updated_at": "2020-10-29T09:20:34Z", "author_association": "CONTRIBUTOR", "body": "That workaround is probably fine. I was trying to work out whether there might be other situations where a pre-external package load might be useful but couldn't offhand bring any other examples to mind. The static plugins option also looks interesting.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 729017519, "label": "Add template block prior to extra URL loaders"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/189#issuecomment-717359145", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/189", "id": 717359145, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNzM1OTE0NQ==", "user": {"value": 35681, "label": "adamwolf"}, "created_at": "2020-10-27T16:20:32Z", "updated_at": "2020-10-27T16:20:32Z", "author_association": "CONTRIBUTOR", "body": "No problem. I added a test. Let me know if it looks sufficient or if you want me to to tweak something!\r\n\r\nIf you don't mind, would you tag this PR as \"hacktoberfest-accepted\"? If you do mind, no problem and I'm sorry for asking :) My kiddos like the shirts.", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 729818242, "label": "Allow iterables other than Lists in m2m records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1043#issuecomment-716237524", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1043", "id": 716237524, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNjIzNzUyNA==", "user": {"value": 45380, "label": "bollwyvl"}, "created_at": "2020-10-26T00:14:57Z", "updated_at": "2020-10-26T00:14:57Z", "author_association": "CONTRIBUTOR", "body": "Sorry, I was out of the loop this weekend. The missing sdists were in some the `datasette-*` plugins... i'll capture my findings more concretely in one spot when i have a chance...", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 727915394, "label": "Include LICENSE in sdist"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/838#issuecomment-716123598", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/838", "id": 716123598, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNjEyMzU5OA==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-25T10:20:12Z", "updated_at": "2020-10-25T10:53:24Z", "author_association": "CONTRIBUTOR", "body": "I'm trying to [run something behind a MyBinder proxy](https://github.com/ouseful-testing/nbsearch), but seem to have something set up incorrectly and not sure what the fix is?\r\n\r\nI'm starting datasette with jupyter-server-proxy setup:\r\n\r\n```\r\n# __init__.py\r\ndef setup_nbsearch():\r\n\r\n return {\r\n \"command\": [\r\n \"datasette\",\r\n \"serve\",\r\n f\"{_NBSEARCH_DB_PATH}\",\r\n \"-p\",\r\n \"{port}\",\r\n \"--config\",\r\n \"base_url:{base_url}nbsearch/\"\r\n ],\r\n \"absolute_url\": True,\r\n # The following needs a the labextension installing.\r\n # eg in postBuild: jupyter labextension install jupyterlab-server-proxy\r\n \"launcher_entry\": {\r\n \"enabled\": True,\r\n \"title\": \"nbsearch\",\r\n },\r\n }\r\n```\r\n\r\nwhere the `base_url` gets automatically populated by the server-proxy. I define the loaders as:\r\n\r\n```\r\n# __init__.py\r\nfrom datasette import hookimpl\r\n\r\n@hookimpl\r\ndef extra_css_urls(database, table, columns, view_name, datasette):\r\n return [\r\n \"/-/static-plugins/nbsearch/prism.css\",\r\n \"/-/static-plugins/nbsearch/nbsearch.css\",\r\n ]\r\n```\r\nbut these seem to also need a base_url prefix set somehow?\r\n\r\nCurrently, the generated HTML loads properly but internal links are incorrect; eg they take the form `` which resolves to eg `https://notebooks.gesis.org/hub/-/static-plugins/nbsearch/prism.css` rather than required URL of form `https://notebooks.gesis.org/binder/jupyter/user/ouseful-testing-nbsearch-0fx1mx67/nbsearch/-/static-plugins/nbsearch/prism.css`.\r\n\r\nThe main css is loaded correctly: ``", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 637395097, "label": "Incorrect URLs when served behind a proxy with base_url set"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1033#issuecomment-716066000", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1033", "id": 716066000, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNjA2NjAwMA==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-24T22:58:33Z", "updated_at": "2020-10-24T22:58:33Z", "author_association": "CONTRIBUTOR", "body": "From [the docs](https://docs.datasette.io/en/latest/internals.html#datasette-urls), I note:\r\n\r\n```\r\ndatasette.urls.instance()\r\nReturns the URL to the Datasette instance root page. This is usually \"/\"\r\n```\r\n\r\nWhat about the proxy case? Eg if I am using jupyter-server-proxy on a MyBinder or local Jupyter notebook server site, `https://example.com:PORT/weirdpath/datasette`, what does `datasette.urls.instance()` refer to?\r\n\r\n- [ ] `https://example.com:PORT/weirdpath/datasette`\r\n- [ ] `https://example.com:PORT/weirdpath/`\r\n- [ ] `https://example.com:PORT/`\r\n- [ ] `https://example.com`\r\n- [ ] something else?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 725099777, "label": "datasette.urls.static_plugins(...) method"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1012#issuecomment-714908859", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1012", "id": 714908859, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNDkwODg1OQ==", "user": {"value": 45380, "label": "bollwyvl"}, "created_at": "2020-10-23T04:49:20Z", "updated_at": "2020-10-23T04:49:20Z", "author_association": "CONTRIBUTOR", "body": "Good luck on 1.0! It may also be worth lobbying for a `Framework::Datasette::1.0` classifier. This would be a nice way to allow the ecosystem to self-document a bit more [discoverably](https://pypi.org/search/?q=&o=&c=Framework+%3A%3A+Datasette%3A%3A+1.0). \r\n\r\nI was surprised to see the [PR for `Framework::Jupyter`](https://github.com/pypa/warehouse/pull/1905/files) is a... database migration! Of course, there may be more workflow to it!", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 718540751, "label": "For 1.0 update trove classifier in setup.py"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1033#issuecomment-714657366", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1033", "id": 714657366, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNDY1NzM2Ng==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-22T17:51:29Z", "updated_at": "2020-10-22T17:51:29Z", "author_association": "CONTRIBUTOR", "body": "How does `/-/static` relate to [current guidance docs around `static`](https://docs.datasette.io/en/latest/custom_templates.html?highlight=static#serving-static-files) regarding the `--static option` and metadata formulations such as `\"extra_js_urls\": [ \"/static/app.js\"]` (I've not managed to get this to work in a Jupyter server proxied set up; the [datasette / jupyter server proxy repo](https://github.com/simonw/jupyterserverproxy-datasette-demo) may provide a useful test example, eg via MyBinder, for folk to crib from?) ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 725099777, "label": "datasette.urls.static_plugins(...) method"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1019#issuecomment-708520800", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1019", "id": 708520800, "node_id": "MDEyOklzc3VlQ29tbWVudDcwODUyMDgwMA==", "user": {"value": 639012, "label": "jsfenfen"}, "created_at": "2020-10-14T16:37:19Z", "updated_at": "2020-10-14T16:37:19Z", "author_association": "CONTRIBUTOR", "body": "\ud83c\udf89 Thanks so much @simonw ! \ud83c\udf89 ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 721050815, "label": "\"Edit SQL\" button on canned queries"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/swarm-to-sqlite/pull/10#issuecomment-707326192", "issue_url": "https://api.github.com/repos/dogsheep/swarm-to-sqlite/issues/10", "id": 707326192, "node_id": "MDEyOklzc3VlQ29tbWVudDcwNzMyNjE5Mg==", "user": {"value": 29426418, "label": "mattiaborsoi"}, "created_at": "2020-10-12T20:20:02Z", "updated_at": "2020-10-12T20:20:02Z", "author_association": "CONTRIBUTOR", "body": "This closes issue #8 ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 719637258, "label": "Update utils.py to fix sqlite3.OperationalError"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/pull/48#issuecomment-704503719", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/48", "id": 704503719, "node_id": "MDEyOklzc3VlQ29tbWVudDcwNDUwMzcxOQ==", "user": {"value": 755825, "label": "adamjonas"}, "created_at": "2020-10-06T19:26:59Z", "updated_at": "2020-10-06T19:26:59Z", "author_association": "CONTRIBUTOR", "body": "ref #46 ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 681228542, "label": "Add pull requests"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/issues/50#issuecomment-690860653", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/50", "id": 690860653, "node_id": "MDEyOklzc3VlQ29tbWVudDY5MDg2MDY1Mw==", "user": {"value": 370930, "label": "mikepqr"}, "created_at": "2020-09-11T04:04:08Z", "updated_at": "2020-09-11T04:04:08Z", "author_association": "CONTRIBUTOR", "body": "There's probably a nicer way of doing (hence this is a comment rather than a PR), but this appears to fix it:\r\n```diff\r\n--- a/twitter_to_sqlite/utils.py\r\n+++ b/twitter_to_sqlite/utils.py\r\n@@ -181,6 +181,7 @@ def fetch_timeline(\r\n args[\"tweet_mode\"] = \"extended\"\r\n min_seen_id = None\r\n num_rate_limit_errors = 0\r\n+ seen_count = 0\r\n while True:\r\n if min_seen_id is not None:\r\n args[\"max_id\"] = min_seen_id - 1\r\n@@ -208,6 +209,7 @@ def fetch_timeline(\r\n yield tweet\r\n min_seen_id = min(t[\"id\"] for t in tweets)\r\n max_seen_id = max(t[\"id\"] for t in tweets)\r\n+ seen_count += len(tweets)\r\n if last_since_id is not None:\r\n max_seen_id = max((last_since_id, max_seen_id))\r\n last_since_id = max_seen_id\r\n@@ -217,7 +219,9 @@ def fetch_timeline(\r\n replace=True,\r\n )\r\n if stop_after is not None:\r\n- break\r\n+ if seen_count >= stop_after:\r\n+ break\r\n+ args[\"count\"] = min(args[\"count\"], stop_after - seen_count)\r\n time.sleep(sleep)\r\n```", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 698791218, "label": "favorites --stop_after=N stops after min(N, 200)"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/146#issuecomment-688573964", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/146", "id": 688573964, "node_id": "MDEyOklzc3VlQ29tbWVudDY4ODU3Mzk2NA==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-09-08T01:55:07Z", "updated_at": "2020-09-08T01:55:07Z", "author_association": "CONTRIBUTOR", "body": "Okay, I've rewritten this PR to preserve the batching behaviour but still fix #145, and rebased the branch to account for the `db.execute()` api change. It's not terribly sophisticated -- if it attempts to insert a batch which has too many variables, the exception is caught, the batch is split in two and each half is inserted separately, and then it carries on as before with the same `batch_size`. In the edge case where this gets triggered, subsequent batches will all be inserted in two groups too if they continue to have the same number of columns (which is presumably reasonably likely). Do you reckon this is acceptable when set against the awkwardness of recalculating the `batch_size` on the fly?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688668680, "label": "Handle case where subsequent records (after first batch) include extra columns"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/146#issuecomment-688481317", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/146", "id": 688481317, "node_id": "MDEyOklzc3VlQ29tbWVudDY4ODQ4MTMxNw==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-09-07T19:18:55Z", "updated_at": "2020-09-07T19:18:55Z", "author_association": "CONTRIBUTOR", "body": "Just force-pushed to update d042f9c with more formatting changes to satisfy `black==20.8b1` and pass the GitHub Actions \"Test\" workflow.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688668680, "label": "Handle case where subsequent records (after first batch) include extra columns"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/146#issuecomment-688479163", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/146", "id": 688479163, "node_id": "MDEyOklzc3VlQ29tbWVudDY4ODQ3OTE2Mw==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-09-07T19:10:33Z", "updated_at": "2020-09-07T19:11:57Z", "author_association": "CONTRIBUTOR", "body": "@simonw -- I've gone ahead updated the documentation to reflect the changes introduced in this PR. IMO it's ready to merge now.\r\n\r\nIn writing the documentation changes, I begin to wonder about the value and role of `batch_size` at all, tbh. May I assume it was originally intended to prevent using the entire row set to determine columns and column types, and that this was a performance consideration? If so, this PR entirely undermines its purpose. I've been passing in excess of 500,000 rows at a time to `insert_all()` with these changes and although I'm sure the performance difference is measurable it's not really noticeable; given #145, I don't know that any performance advantages outweigh the problems doing it this way removes. What do you think about just dropping the argument and defaulting to the maximum `batch_size` permissible given `SQLITE_MAX_VARS`? Are there other reasons one might want to restrict `batch_size` that I've overlooked? I could open a new issue to discuss/implement this.\r\n\r\nOf course the documentation will need to change again too if/when something is done about #147.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688668680, "label": "Handle case where subsequent records (after first batch) include extra columns"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/952#issuecomment-686061028", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/952", "id": 686061028, "node_id": "MDEyOklzc3VlQ29tbWVudDY4NjA2MTAyOA==", "user": {"value": 27856297, "label": "dependabot-preview[bot]"}, "created_at": "2020-09-02T22:26:14Z", "updated_at": "2020-09-02T22:26:14Z", "author_association": "CONTRIBUTOR", "body": "Looks like black is up-to-date now, so this is no longer needed.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 687245650, "label": "Update black requirement from ~=19.10b0 to >=19.10,<21.0"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/145#issuecomment-683382252", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/145", "id": 683382252, "node_id": "MDEyOklzc3VlQ29tbWVudDY4MzM4MjI1Mg==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-08-30T06:27:25Z", "updated_at": "2020-08-30T06:27:52Z", "author_association": "CONTRIBUTOR", "body": "Note: had to adjust the test above because trying to exhaust a `SQLITE_MAX_VARIABLE_NUMBER` of 250000 in 99 records requires 2526 columns, and trips the ` \"Rows can have a maximum of {} columns\".format(SQLITE_MAX_VARS)` check even before it trips the default `SQLITE_MAX_COLUMN` value (2000).", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688659182, "label": "Bug when first record contains fewer columns than subsequent records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682815377", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/139", "id": 682815377, "node_id": "MDEyOklzc3VlQ29tbWVudDY4MjgxNTM3Nw==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-08-28T16:14:58Z", "updated_at": "2020-08-28T16:14:58Z", "author_association": "CONTRIBUTOR", "body": "Thanks! And yeah, I had updating the docs on my list too :) Will try to get to it this afternoon (budgeting time is fraught with uncertainty at the moment!).", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 686978131, "label": "insert_all(..., alter=True) should work for new columns introduced after the first 100 records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682182178", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/139", "id": 682182178, "node_id": "MDEyOklzc3VlQ29tbWVudDY4MjE4MjE3OA==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-08-27T20:46:18Z", "updated_at": "2020-08-27T20:46:18Z", "author_association": "CONTRIBUTOR", "body": "> I tried changing the batch_size argument to the total number of records, but it seems only to effect the number of rows that are committed at a time, and has no influence on this problem.\r\n\r\nSo the reason for this is that the `batch_size` for import is limited (of necessity) here: https://github.com/simonw/sqlite-utils/blob/main/sqlite_utils/db.py#L1048\r\n\r\nWith regard to the issue of ignoring columns, however, I made a fork and hacked a temporary fix that looks like this:\r\nhttps://github.com/simonwiles/sqlite-utils/commit/3901f43c6a712a1a3efc340b5b8d8fd0cbe8ee63\r\n\r\nIt doesn't seem to affect performance enormously (but I've not tested it thoroughly), and it now does what I need (and would expect, tbh), but it now fails the test here:\r\nhttps://github.com/simonw/sqlite-utils/blob/main/tests/test_create.py#L710-L716\r\n\r\nThe existence of this test suggests that `insert_all()` is behaving as intended, of course. It seems odd to me that this would be a desirable default behaviour (let alone the only behaviour), and its not very prominently flagged-up, either.\r\n\r\n@simonw is this something you'd be willing to look at a PR for? I assume you wouldn't want to change the default behaviour at this point, but perhaps an option could be provided, or at least a bit more of a warning in the docs. Are there oversights in the implementation that I've made?\r\n\r\nWould be grateful for your thoughts! Thanks!\r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 686978131, "label": "insert_all(..., alter=True) should work for new columns introduced after the first 100 records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/456#issuecomment-661524006", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/456", "id": 661524006, "node_id": "MDEyOklzc3VlQ29tbWVudDY2MTUyNDAwNg==", "user": {"value": 32467826, "label": "abeyerpath"}, "created_at": "2020-07-21T01:15:07Z", "updated_at": "2020-07-21T01:15:07Z", "author_association": "CONTRIBUTOR", "body": "Bumping this, as the previous fix is passing the wrong type, and not actually addressing the issue...\r\n\r\nThe `exclude` argument needs an iterable of packages instead of a single string (but since `str` is iterable, it's currently excluding packages `t`, `e`, and `s`.)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 442327592, "label": "Installing installs the tests package"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/121#issuecomment-655898722", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/121", "id": 655898722, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTg5ODcyMg==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-09T04:53:08Z", "updated_at": "2020-07-09T04:53:08Z", "author_association": "CONTRIBUTOR", "body": "Yep, I agree that makes more sense for backwards compat and more casual use cases. I think it should be possible for the Database/Queryable methods to DTRT based on seeing if it's within a context-manager-managed transaction.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 652961907, "label": "Improved (and better documented) support for transactions"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/121#issuecomment-655652679", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/121", "id": 655652679, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTY1MjY3OQ==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-08T17:24:46Z", "updated_at": "2020-07-08T17:24:46Z", "author_association": "CONTRIBUTOR", "body": "Better transaction handling would be really great. Some of my thoughts on implementing better transaction discipline are in https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655239728.\r\n\r\nMy preferences:\r\n\r\n- Each CLI command should operate in a single transaction so that either the whole thing succeeds or the whole thing is rolled back. This avoids partially completed operations when an error occurs part way through processing. Partially completed operations are typically much harder to recovery from gracefully and may cause inconsistent data states.\r\n\r\n- The Python API should be transaction-agnostic and rely on the caller to coordinate transactions. Only the caller knows how individual insert, create, update, etc operations/methods should be bundled conceptually into transactions. When the caller is the CLI, for example, that bundling would be at the CLI command-level. Other callers might want to break up operations into multiple transactions. Transactions are usually most useful when controlled at the application-level (like logging configuration) instead of the library level. The library needs to provide an API that's conducive to transaction use, though.\r\n\r\n- The Python API should provide a context manager to provide consistent transactions handling with more useful defaults than Python's `sqlite3` module. The latter issues implicit `BEGIN` statements by default for most DML (`INSERT`, `UPDATE`, `DELETE`, \u2026 but not `SELECT`, I believe), but **not** DDL (`CREATE TABLE`, `DROP TABLE`, `CREATE VIEW`, \u2026). Notably, the `sqlite3` module doesn't issue the implicit `BEGIN` until the first DML statement. It _does not_ issue it when entering the `with conn` block, like other DBAPI2-compatible modules do. The `with conn` block for `sqlite3` only arranges to commit or rollback an existing transaction when exiting. Including DDL and `SELECT`s in transactions is important for operation consistency, though. There are several existing bugs.python.org tickets about this and future changes are in the works, but sqlite-utils can provide its own API sooner. sqlite-utils's `Database` class could itself be a context manager (built on the `sqlite3` connection context manager) which additionally issues an explicit `BEGIN` when entering. This would then let Python API callers do something like:\r\n\r\n```python\r\ndb = sqlite_utils.Database(path)\r\n\r\nwith db: # \u2190 BEGIN issued here by Database.__enter__\r\n db.insert(\u2026)\r\n db.create_view(\u2026)\r\n# \u2190 COMMIT/ROLLBACK issue here by sqlite3.connection.__exit__\r\n```", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 652961907, "label": "Improved (and better documented) support for transactions"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655643078", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655643078, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTY0MzA3OA==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-08T17:05:59Z", "updated_at": "2020-07-08T17:05:59Z", "author_association": "CONTRIBUTOR", "body": "> The only thing missing from this PR is updates to the documentation.\r\n\r\nAh, yes, thanks for this reminder! I've repushed with doc bits added.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655239728", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655239728, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTIzOTcyOA==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-08T02:16:42Z", "updated_at": "2020-07-08T02:16:42Z", "author_association": "CONTRIBUTOR", "body": "I fixed my original oops by moving the `DELETE FROM $table` out of the chunking loop and repushed. I think this change can be considered in isolation from issues around transactions, which I discuss next.\r\n\r\nI wanted to make the DELETE + INSERT happen all in the same transaction so it was robust, but that was more complicated than I expected. The transaction handling in the Database/Table classes isn't systematic, and this poses big hurdles to making `Table.insert_all` (or other operations) consistent and robust in the face of errors.\r\n\r\nFor example, I wanted to do this (whitespace ignored in diff, so indentation change not highlighted):\r\n\r\n```diff\r\ndiff --git a/sqlite_utils/db.py b/sqlite_utils/db.py\r\nindex d6b9ecf..4107ceb 100644\r\n--- a/sqlite_utils/db.py\r\n+++ b/sqlite_utils/db.py\r\n@@ -1028,6 +1028,11 @@ class Table(Queryable):\r\n batch_size = max(1, min(batch_size, SQLITE_MAX_VARS // num_columns))\r\n self.last_rowid = None\r\n self.last_pk = None\r\n+ with self.db.conn:\r\n+ # Explicit BEGIN is necessary because Python's sqlite3 doesn't\r\n+ # issue implicit BEGINs for DDL, only DML. We mix DDL and DML\r\n+ # below and might execute DDL first, e.g. for table creation.\r\n+ self.db.conn.execute(\"BEGIN\")\r\n if truncate and self.exists():\r\n self.db.conn.execute(\"DELETE FROM [{}];\".format(self.name))\r\n for chunk in chunks(itertools.chain([first_record], records), batch_size):\r\n@@ -1038,7 +1043,11 @@ class Table(Queryable):\r\n # Use the first batch to derive the table names\r\n column_types = suggest_column_types(chunk)\r\n column_types.update(columns or {})\r\n- self.create(\r\n+ # Not self.create() because that is wrapped in its own\r\n+ # transaction and Python's sqlite3 doesn't support\r\n+ # nested transactions.\r\n+ self.db.create_table(\r\n+ self.name,\r\n column_types,\r\n pk,\r\n foreign_keys,\r\n@@ -1139,7 +1148,6 @@ class Table(Queryable):\r\n flat_values = list(itertools.chain(*values))\r\n queries_and_params = [(sql, flat_values)]\r\n \r\n- with self.db.conn:\r\n for query, params in queries_and_params:\r\n try:\r\n result = self.db.conn.execute(query, params)\r\n```\r\n\r\nbut that fails in tests because other methods call `insert/upsert/insert_all/upsert_all` in the middle of their transactions, so the BEGIN statement throws an error (no nested transactions allowed).\r\n\r\nStepping back, it would be nice to make the transaction handling systematic and predictable. One way to do this is to make the `sqlite_utils/db.py` code generally not begin or commit any transactions, and require the caller to do that instead. This lets the caller mix and match the Python API calls into transactions as appropriate (which is impossible for the API methods themselves to fully determine). Then, make `sqlite_utils/cli.py` begin and commit a transaction in each `@cli.command` function, making each command robust and consistent in the face of errors. The big change here, and why I didn't just submit a patch, is that it dramatically changes the Python API to _require_ callers to begin a transaction rather than just immediately calling methods.\r\n\r\nThere is also the caveat that for each transaction, an explicit `BEGIN` is also necessary so that DDL as well as DML (as well as `SELECT`s) are consistent and rolled back on error. There are several bugs.python.org discussions around this particular problem of DDL and some plans to make it better and consistent with DBAPI2, eventually. In the meantime, the sqlite-utils Database class could be a context manager which supports the incantations necessary to do proper transactions. This would still be a Python API change for callers but wouldn't expose them to the weirdness of the sqlite3's default transaction handling.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655052451", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655052451, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTA1MjQ1MQ==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-07T18:45:23Z", "updated_at": "2020-07-07T18:45:23Z", "author_association": "CONTRIBUTOR", "body": "Ah, I see the problem. The truncate is inside a loop I didn't realize was there.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655018966", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655018966, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTAxODk2Ng==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-07T17:41:06Z", "updated_at": "2020-07-07T17:41:06Z", "author_association": "CONTRIBUTOR", "body": "Hmm, while tests pass, this may not work as intended on larger datasets. Looking into it.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/889#issuecomment-653002499", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/889", "id": 653002499, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MzAwMjQ5OQ==", "user": {"value": 49260, "label": "amjith"}, "created_at": "2020-07-02T13:22:13Z", "updated_at": "2020-07-02T13:22:13Z", "author_association": "CONTRIBUTOR", "body": "I was able to narrow this down to the fact that lifespan protocol is turned on. \r\n\r\nI see the workaround you've used here: https://github.com/simonw/datasette-debug-asgi/commit/72d568d32a3159c763ce908c0b269736935c6987\r\n\r\nIf so, maybe it's time to update some of the asg_wrapper [plugins](https://datasette.readthedocs.io/en/stable/plugin_hooks.html#asgi-wrapper-datasette). ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 649907676, "label": "asgi_wrapper plugin hook is crashing at startup"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/889#issuecomment-652990131", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/889", "id": 652990131, "node_id": "MDEyOklzc3VlQ29tbWVudDY1Mjk5MDEzMQ==", "user": {"value": 49260, "label": "amjith"}, "created_at": "2020-07-02T12:58:11Z", "updated_at": "2020-07-02T13:00:18Z", "author_association": "CONTRIBUTOR", "body": "FWIW, this error does NOT happen in datasette 0.45a4.\r\n\r\nIt only started on 0.45a5", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 649907676, "label": "asgi_wrapper plugin hook is crashing at startup"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/883#issuecomment-652394742", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/883", "id": 652394742, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MjM5NDc0Mg==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-07-01T12:41:13Z", "updated_at": "2020-07-01T12:41:13Z", "author_association": "CONTRIBUTOR", "body": "Well tests need to be updated.\r\n \r\nI need to get tests working on Windows.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 648749062, "label": "Skip counting hidden tables"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/883#issuecomment-652297139", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/883", "id": 652297139, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MjI5NzEzOQ==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-07-01T09:11:29Z", "updated_at": "2020-07-01T09:11:29Z", "author_association": "CONTRIBUTOR", "body": "Turns out we should include hidden tables in the result dict, or we're breaking tests. I've committed a refactor https://github.com/simonw/datasette/pull/883/commits/4f06e1bf6fbe4b73be770b87f610bf7c0e6e3ea7", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 648749062, "label": "Skip counting hidden tables"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/877#issuecomment-652255960", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/877", "id": 652255960, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MjI1NTk2MA==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-07-01T07:52:25Z", "updated_at": "2020-07-01T08:10:00Z", "author_association": "CONTRIBUTOR", "body": "I am calling the API from another origin, so injecting CSRF token into templates wouldn't work.\r\n\r\nEDIT:\r\n\r\nI'll try the new version, it sounds promising", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 648421105, "label": "Consider dropping explicit CSRF protection entirely?"}, "performed_via_github_app": null}
\r\n\r\n\r\n\r\n(Note: I didn't figure out how to have one item have no semicolon, while multi-items close with a semicolon, but this is good enough for now. I also didn't figure out how to set up a new jinja filter. I don't want to add to /datasette/utils/__init__.py as I assume that would get overwritten when upgrading datasette. Having a starter guide on creating jinja filters in datasette would be helpful. (The jinja documentation isn't datasette-specific enough for me to quite nail it.)\r\n", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 849220154, "label": "Better default display of arrays of items"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/502#issuecomment-812813732", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/502", "id": 812813732, "node_id": "MDEyOklzc3VlQ29tbWVudDgxMjgxMzczMg==", "user": {"value": 5413548, "label": "louispotok"}, "created_at": "2021-04-03T05:16:54Z", "updated_at": "2021-04-03T05:16:54Z", "author_association": "CONTRIBUTOR", "body": "For what it's worth, if anyone finds this in the future, I was having the same issue. \r\n\r\nAfter digging through the code, it turned out that the database download is only available if it the db served in immutable mode, so `datasette serve -i xyz.db` rather than the doc's quickstart recommendation of `datasette serve xyz.db`.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 453131917, "label": "Exporting sqlite database(s)?"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1286#issuecomment-812679221", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1286", "id": 812679221, "node_id": "MDEyOklzc3VlQ29tbWVudDgxMjY3OTIyMQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-04-02T19:34:01Z", "updated_at": "2021-04-02T19:34:01Z", "author_association": "CONTRIBUTOR", "body": "This shows the city in a different color (and not the comma), but I get the idea, and I like it. (Ooh, could be nice to have the gear have an option in array fields to show as bullets or commas or semicolons...)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 849220154, "label": "Better default display of arrays of items"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1284#issuecomment-810779928", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1284", "id": 810779928, "node_id": "MDEyOklzc3VlQ29tbWVudDgxMDc3OTkyOA==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-31T05:40:12Z", "updated_at": "2021-03-31T05:40:12Z", "author_association": "CONTRIBUTOR", "body": "Maybe the addition of two template files: 'one_database_index.html' and 'one_table_index.html' would be a better idea than the documentation diff idea. (They could include commented instructions to rename the preferred template 'index.html', along with any other necessary guidance.)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 845794436, "label": "Feature or Documentation Request: Individual table as home page template"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1274#issuecomment-805214307", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1274", "id": 805214307, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNTIxNDMwNw==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-03-23T20:12:29Z", "updated_at": "2021-03-23T20:12:29Z", "author_association": "CONTRIBUTOR", "body": "One issue I could see with adding first class support for metadata in hjson format is that this would require adding an additional dependency to handle this, for a feature that would be unused by many users. I wonder if this could fit in as a plugin instead; if a hook existed for loading metadata (maybe as part of https://github.com/simonw/datasette/issues/860) the metadata could then come from any source, as specified by plugins, e.g. hjson, toml, XML, a database table etc.\r\n\r\nUntil/unless this exists, a few ideas for how you could add comments:\r\n- Using YAML as you suggest.\r\n- A common pattern is adding a `\"comment\"` key for comments to any object in JSON - I don't think including an unnecessary key like this would break anything in Datasette, but not certain.\r\n- You could use another tool as a preprocessor for your JSON metadata - e.g. hjson or Jsonnet. You'd write the metadata in that format, and then convert that into JSON to actually use as your final metadata.", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 839008371, "label": "Might there be some way to comment metadata.json?"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1153#issuecomment-804640440", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1153", "id": 804640440, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDY0MDQ0MA==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T05:58:20Z", "updated_at": "2021-03-23T05:58:20Z", "author_association": "CONTRIBUTOR", "body": "Could there be a little widget that offers conversion from one to the other? ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 771202454, "label": "Use YAML examples in documentation by default, not JSON"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1159#issuecomment-804639427", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1159", "id": 804639427, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDYzOTQyNw==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T05:56:02Z", "updated_at": "2021-03-23T05:56:02Z", "author_association": "CONTRIBUTOR", "body": "With just three facets, I like it, but it does take more horizontal space. Would be nice to have a switch somewhere, enabling either original compact option or this proposed more-readable option. Also some control over word wrap (width setting) and facet spacing. ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 774332247, "label": "Improve the display of facets information"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/164#issuecomment-804541064", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/164", "id": 804541064, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDU0MTA2NA==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T02:45:12Z", "updated_at": "2021-03-23T02:45:12Z", "author_association": "CONTRIBUTOR", "body": "\"datasette skeleton\" feature removed #476", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 280013907, "label": "datasette skeleton command for kick-starting database and table metadata"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/163#issuecomment-804539729", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/163", "id": 804539729, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDUzOTcyOQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-23T02:41:14Z", "updated_at": "2021-03-23T02:41:14Z", "author_association": "CONTRIBUTOR", "body": "I'm visiting old issues for context while learning datasette. Let me know if okay to make the occasional comment like this one.\r\nquerystring argument now located at:\r\nhttps://docs.datasette.io/en/latest/settings.html#sql-time-limit-ms", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 279547886, "label": "Document the querystring argument for setting a different time limit"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/88#issuecomment-804471733", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/88", "id": 804471733, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDQ3MTczMw==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-22T23:46:36Z", "updated_at": "2021-03-22T23:46:36Z", "author_association": "CONTRIBUTOR", "body": "Google Map API limits seem to prevent https://nhs-england-map.netlify.com from being a working demo.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 273775212, "label": "Add NHS England Hospitals example to wiki"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1149#issuecomment-804415619", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1149", "id": 804415619, "node_id": "MDEyOklzc3VlQ29tbWVudDgwNDQxNTYxOQ==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-22T21:43:16Z", "updated_at": "2021-03-22T21:43:16Z", "author_association": "CONTRIBUTOR", "body": "Sounds like a good idea.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 769520939, "label": "Make it easier to theme Datasette with CSS"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/942#issuecomment-803631102", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/942", "id": 803631102, "node_id": "MDEyOklzc3VlQ29tbWVudDgwMzYzMTEwMg==", "user": {"value": 192568, "label": "mroswell"}, "created_at": "2021-03-21T17:48:42Z", "updated_at": "2021-03-21T17:48:42Z", "author_association": "CONTRIBUTOR", "body": "I like this idea. Though it might be nice to have some kind of automated system from database to file, so that developers could easily track diffs.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 681334912, "label": "Support column descriptions in metadata.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1265#issuecomment-802923254", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1265", "id": 802923254, "node_id": "MDEyOklzc3VlQ29tbWVudDgwMjkyMzI1NA==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-03-19T15:39:15Z", "updated_at": "2021-03-19T15:39:15Z", "author_association": "CONTRIBUTOR", "body": "It doesn't use basic auth, but you can put a whole datasette instance, or parts of this, behind a username/password prompt using https://github.com/simonw/datasette-auth-passwords", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 836123030, "label": "Support for HTTP Basic Authentication"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1262#issuecomment-802095132", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1262", "id": 802095132, "node_id": "MDEyOklzc3VlQ29tbWVudDgwMjA5NTEzMg==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-03-18T16:37:45Z", "updated_at": "2021-03-18T16:37:45Z", "author_association": "CONTRIBUTOR", "body": "This sounds like a good use case for a plugin, since this will only be useful for a subset of Datasette users. It shouldn't be too difficult to add a button to do this with the available plugin hooks - have you taken a look at https://docs.datasette.io/en/latest/writing_plugins.html?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 834602299, "label": "Plugin hook that could support 'order by random()' for table view"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/236#issuecomment-799003172", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/236", "id": 799003172, "node_id": "MDEyOklzc3VlQ29tbWVudDc5OTAwMzE3Mg==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-03-14T23:42:57Z", "updated_at": "2021-03-14T23:42:57Z", "author_association": "CONTRIBUTOR", "body": "Oh, and the container image can be up to 10GB, so the EFS step might not be needed except for pretty big stuff.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 317001500, "label": "datasette publish lambda plugin"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/236#issuecomment-799002993", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/236", "id": 799002993, "node_id": "MDEyOklzc3VlQ29tbWVudDc5OTAwMjk5Mw==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-03-14T23:41:51Z", "updated_at": "2021-03-14T23:41:51Z", "author_association": "CONTRIBUTOR", "body": "Now that [Lambda supports Docker](https://aws.amazon.com/blogs/aws/new-for-aws-lambda-container-image-support/), this probably is a bit easier and may be able to build on top of the existing package command.\r\n\r\nThere are weirdnesses in how the command actually gets invoked; the [aws-lambda-python image](https://hub.docker.com/r/amazon/aws-lambda-python) shows a bit of that. So Datasette would probably need some sort of Lambda-specific entry point to make this work.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 317001500, "label": "datasette publish lambda plugin"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1256#issuecomment-795112935", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1256", "id": 795112935, "node_id": "MDEyOklzc3VlQ29tbWVudDc5NTExMjkzNQ==", "user": {"value": 6371750, "label": "JBPressac"}, "created_at": "2021-03-10T08:59:45Z", "updated_at": "2021-03-10T08:59:45Z", "author_association": "CONTRIBUTOR", "body": "Sorry, I meant \"minor typo\" not \"minor type\".", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 827341657, "label": "Minor type in IP adress"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/766#issuecomment-791509910", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/766", "id": 791509910, "node_id": "MDEyOklzc3VlQ29tbWVudDc5MTUwOTkxMA==", "user": {"value": 6371750, "label": "JBPressac"}, "created_at": "2021-03-05T15:57:35Z", "updated_at": "2021-03-05T16:35:21Z", "author_association": "CONTRIBUTOR", "body": "Hello, \r\nI have the same wildcards search problems with an instance of Datasette. http://crbc-dataset.huma-num.fr/inventaires/fonds_auguste_dupouy_1872_1967?_search=gwerz&_sort=rowid is OK but http://crbc-dataset.huma-num.fr/inventaires/fonds_auguste_dupouy_1872_1967?_search=gwe* is not (FTS is activated on \"Reference\" \"IntituleAnalyse\" \"NomDuProducteur\" \"PresentationDuContenu\" \"Notes\"). \r\n\r\nNotice that a SQL query as below launched directly from SQLite in the server's shell, retrieves results.\r\n\r\n`select * from fonds_auguste_dupouy_1872_1967_fts where IntituleAnalyse MATCH \"gwe*\";`\r\n\r\nThanks,", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 617323873, "label": "Enable wildcard-searches by default"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1238#issuecomment-789186458", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1238", "id": 789186458, "node_id": "MDEyOklzc3VlQ29tbWVudDc4OTE4NjQ1OA==", "user": {"value": 198537, "label": "rgieseke"}, "created_at": "2021-03-02T20:19:30Z", "updated_at": "2021-03-02T20:19:30Z", "author_association": "CONTRIBUTOR", "body": "A custom `templates/index.html` seems to work and custom `pages` as a workaround with moving them to `pages/base_url_dir`.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 813899472, "label": "Custom pages don't work with base_url setting"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/242#issuecomment-787121933", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/242", "id": 787121933, "node_id": "MDEyOklzc3VlQ29tbWVudDc4NzEyMTkzMw==", "user": {"value": 25778, "label": "eyeseast"}, "created_at": "2021-02-27T19:18:57Z", "updated_at": "2021-02-27T19:18:57Z", "author_association": "CONTRIBUTOR", "body": "I think HTTPX gets it exactly right, with a clear separation between sync and async clients, each with a basically identical API. (I'm about to switch [feed-to-sqlite](https://github.com/eyeseast/feed-to-sqlite) over to it, from Requests, to eventually make way for async support.)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 817989436, "label": "Async support"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1212#issuecomment-782430028", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1212", "id": 782430028, "node_id": "MDEyOklzc3VlQ29tbWVudDc4MjQzMDAyOA==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-19T22:54:13Z", "updated_at": "2021-02-19T22:54:13Z", "author_association": "CONTRIBUTOR", "body": "I will close this issue since it appears only in my particular setup.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797651831, "label": "Tests are very slow. "}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1229#issuecomment-782053455", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1229", "id": 782053455, "node_id": "MDEyOklzc3VlQ29tbWVudDc4MjA1MzQ1NQ==", "user": {"value": 295329, "label": "camallen"}, "created_at": "2021-02-19T12:47:19Z", "updated_at": "2021-02-19T12:47:19Z", "author_association": "CONTRIBUTOR", "body": "I believe this pr and #1031 are related and fix the same issue.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 810507413, "label": "ensure immutable databses when starting in configuration directory mode with"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1220#issuecomment-778439617", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1220", "id": 778439617, "node_id": "MDEyOklzc3VlQ29tbWVudDc3ODQzOTYxNw==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-02-12T20:33:27Z", "updated_at": "2021-02-12T20:33:27Z", "author_association": "CONTRIBUTOR", "body": "That Docker command will mount your current directory inside the Docker container at `/mnt` - so you shouldn't need to change anything locally, just run\r\n\r\n```\r\ndocker run -p 8001:8001 -v `pwd`:/mnt \\\r\n datasetteproject/datasette \\\r\n datasette -p 8001 -h 0.0.0.0 /mnt/fixtures.db\r\n```\r\n\r\nand it will use the `fixtures.db` file within your current directory", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 806743116, "label": "Installing datasette via docker: Path 'fixtures.db' does not exist"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/issues/60#issuecomment-770069864", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/60", "id": 770069864, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MDA2OTg2NA==", "user": {"value": 22578954, "label": "daniel-butler"}, "created_at": "2021-01-29T21:52:05Z", "updated_at": "2021-02-12T18:29:43Z", "author_association": "CONTRIBUTOR", "body": "For the purposes below I am assuming the organization I would get all the repositories and their related commits from is called `gh-organization`. The github's owner id of gh-orgnization is `123456789`.\r\n\r\n```bash\r\ngithub-to-sqlite repos github.db gh-organization\r\n```\r\n\r\nI'm on a windows computer running git bash to be able to use the `|` command. This works for me\r\n```bash\r\nsqlite3 github.db \"SELECT full_name FROM repos WHERE owner = '123456789';\" | tr '\\n\\r' ' ' | xargs | { read repos; github-to-sqlite commits github.db $repos; }\r\n```\r\n\r\nOn a pure linux system I think this would work because the new line character is normally `\\n`\r\n```bash\r\nsqlite3 github.db \"SELECT full_name FROM repos WHERE owner = '123456789';\" | tr '\\n' ' ' | xargs | { read repos; github-to-sqlite commits github.db $repos; }`\r\n```\r\n\r\nAs expected I ran into rate limit issues #51 \r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797097140, "label": "Use Data from SQLite in other commands"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/issues/33#issuecomment-778246347", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/33", "id": 778246347, "node_id": "MDEyOklzc3VlQ29tbWVudDc3ODI0NjM0Nw==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2021-02-12T15:00:43Z", "updated_at": "2021-02-12T15:00:43Z", "author_association": "CONTRIBUTOR", "body": "Yes, Big Sur Photos database doesn't have `ZGENERICASSET` table. PR #31 will fix this.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 803338729, "label": "photo-to-sqlite: command not found"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1220#issuecomment-777927946", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1220", "id": 777927946, "node_id": "MDEyOklzc3VlQ29tbWVudDc3NzkyNzk0Ng==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-02-12T02:29:54Z", "updated_at": "2021-02-12T02:29:54Z", "author_association": "CONTRIBUTOR", "body": "According to https://github.com/simonw/datasette/blob/master/docs/installation.rst#using-docker it should be\r\n\r\n```\r\ndocker run -p 8001:8001 -v `pwd`:/mnt \\\r\n datasetteproject/datasette \\\r\n datasette -p 8001 -h 0.0.0.0 /mnt/fixtures.db\r\n```\r\n\r\nThis uses `/mnt/fixtures.db` whereas you're using `fixtures.db` - did you try using this path instead?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 806743116, "label": "Installing datasette via docker: Path 'fixtures.db' does not exist"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1200#issuecomment-777132761", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1200", "id": 777132761, "node_id": "MDEyOklzc3VlQ29tbWVudDc3NzEzMjc2MQ==", "user": {"value": 7476523, "label": "bobwhitelock"}, "created_at": "2021-02-11T00:29:52Z", "updated_at": "2021-02-11T00:29:52Z", "author_association": "CONTRIBUTOR", "body": "I'm probably missing something but what's the use case here - what would this offer over adding `limit 10` to the query?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 792890765, "label": "?_size=10 option for the arbitrary query page would be useful"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1208#issuecomment-774286962", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1208", "id": 774286962, "node_id": "MDEyOklzc3VlQ29tbWVudDc3NDI4Njk2Mg==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-05T21:02:39Z", "updated_at": "2021-02-05T21:02:39Z", "author_association": "CONTRIBUTOR", "body": "@simonw could you please take a look at the PR 1211 that fixes this issue?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 794554881, "label": "A lot of open(file) functions are used without a context manager thus producing ResourceWarning: unclosed file <_io.TextIOWrapper"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1212#issuecomment-772007663", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1212", "id": 772007663, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MjAwNzY2Mw==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-02T21:36:56Z", "updated_at": "2021-02-02T21:36:56Z", "author_association": "CONTRIBUTOR", "body": "How do you get 4-5 minutes?\r\nI run my tests in WSL 2, so may be i need to try a real linux VM.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797651831, "label": "Tests are very slow. "}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1211#issuecomment-771127458", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1211", "id": 771127458, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MTEyNzQ1OA==", "user": {"value": 4488943, "label": "kbaikov"}, "created_at": "2021-02-01T20:13:39Z", "updated_at": "2021-02-01T20:13:39Z", "author_association": "CONTRIBUTOR", "body": "Ping @simonw ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797649915, "label": "Use context manager instead of plain open"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/issues/51#issuecomment-770150526", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/51", "id": 770150526, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MDE1MDUyNg==", "user": {"value": 22578954, "label": "daniel-butler"}, "created_at": "2021-01-30T03:44:19Z", "updated_at": "2021-01-30T03:47:24Z", "author_association": "CONTRIBUTOR", "body": "I don't have much experience with github's rate limiting. In my day job we use the [tenacity library](https://github.com/jd/tenacity) to handle http errors we get.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 703246031, "label": "github-to-sqlite should handle rate limits better"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/issues/60#issuecomment-770112248", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/60", "id": 770112248, "node_id": "MDEyOklzc3VlQ29tbWVudDc3MDExMjI0OA==", "user": {"value": 22578954, "label": "daniel-butler"}, "created_at": "2021-01-30T00:01:03Z", "updated_at": "2021-01-30T01:14:42Z", "author_association": "CONTRIBUTOR", "body": "Yes that would be cool! I wouldn't mind helping. Is this the meat of it? https://github.com/dogsheep/twitter-to-sqlite/blob/21fc1cad6dd6348c67acff90a785b458d3a81275/twitter_to_sqlite/utils.py#L512\r\n\r\nIt looks like the cli option is added with this decorator : https://github.com/dogsheep/twitter-to-sqlite/blob/21fc1cad6dd6348c67acff90a785b458d3a81275/twitter_to_sqlite/cli.py#L14\r\n\r\nI looked a bit at utils.py in the GitHub repository. I was surprised at the amount of manual mapping of the API response you had to do to get this to work.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 797097140, "label": "Use Data from SQLite in other commands"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/pull/55#issuecomment-760950128", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/55", "id": 760950128, "node_id": "MDEyOklzc3VlQ29tbWVudDc2MDk1MDEyOA==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-15T13:44:52Z", "updated_at": "2021-01-15T13:44:52Z", "author_association": "CONTRIBUTOR", "body": "I found and fixed another bug, this one around importing the tweets table. @simonw let me know if you'd prefer this broken out into multiple PRs, happy to do that if it makes review/merging easier.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779211940, "label": "Fix archive imports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/issues/54#issuecomment-754729035", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/54", "id": 754729035, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDcyOTAzNQ==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-05T16:03:29Z", "updated_at": "2021-01-05T16:03:29Z", "author_association": "CONTRIBUTOR", "body": "I was able to fix this, at least enough to get _my_ archive to import. Not sure if there's more work to be done here or not.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779088071, "label": "Archive import appears to be broken on recent exports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/pull/55#issuecomment-754728696", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/55", "id": 754728696, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDcyODY5Ng==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-05T16:02:55Z", "updated_at": "2021-01-05T16:02:55Z", "author_association": "CONTRIBUTOR", "body": "This now works for me, though I'm entirely ensure if it's a just-my-export thing or a wider issue. Also, this doesn't contain any tests. So I'm not sure if there's more work to be done here, or if this is good enough.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779211940, "label": "Fix archive imports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/issues/54#issuecomment-754721153", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/54", "id": 754721153, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDcyMTE1Mw==", "user": {"value": 21148, "label": "jacobian"}, "created_at": "2021-01-05T15:51:09Z", "updated_at": "2021-01-05T15:51:09Z", "author_association": "CONTRIBUTOR", "body": "Correction: the failure is on `lists-member.js` (I was thrown by the `block` variable name, but that's just a coincidence)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 779088071, "label": "Archive import appears to be broken on recent exports"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1167#issuecomment-754619930", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1167", "id": 754619930, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDYxOTkzMA==", "user": {"value": 3637, "label": "benpickles"}, "created_at": "2021-01-05T12:57:57Z", "updated_at": "2021-01-05T12:57:57Z", "author_association": "CONTRIBUTOR", "body": "Not sure where exactly to put the actual docs (presumably somewhere in [docs/contributing.rst](https://github.com/simonw/datasette/blob/main/docs/contributing.rst)) but I've made a slight change to make it easier to run locally (copying [the approach in excalidraw](https://github.com/excalidraw/excalidraw/blob/ade2565f497243a5e428f4906d8ed80c872fd981/package.json#L90-L94)): https://github.com/simonw/datasette/compare/main...benpickles:prettier-docs\r\n\r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 777145954, "label": "Add Prettier to contributing documentation"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/859#issuecomment-647922203", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/859", "id": 647922203, "node_id": "MDEyOklzc3VlQ29tbWVudDY0NzkyMjIwMw==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-06-23T05:44:58Z", "updated_at": "2021-01-05T08:22:43Z", "author_association": "CONTRIBUTOR", "body": "I'm seeing the problem on database page. Index page and table page runs quite fast.\r\n\r\n- Tables have <10 columns (`id`, `url`, `title`, `body_html`, `date`, `author`, `meta` (for keeping unstructured json)). I've added index on `date` columns (using `sqlite-utils`) in addition to the index present on `id` columns. \r\n- All tables have FTS enabled on `text` and `varchar` columns (`title`, `body_html` etc) to speed up searching.\r\n- There are couple of tables related with foreign keys (think a thread in a forum and posts in that thread, related with `thread_id`)\r\n\r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 642572841, "label": "Database page loads too slowly with many large tables (due to table counts)"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1169#issuecomment-754007242", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1169", "id": 754007242, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDAwNzI0Mg==", "user": {"value": 3637, "label": "benpickles"}, "created_at": "2021-01-04T14:29:57Z", "updated_at": "2021-01-04T14:29:57Z", "author_association": "CONTRIBUTOR", "body": "I somewhat share your reluctance to add a package.json to seemingly every project out there but ultimately if they're project dependencies it's important they're managed within the codebase.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 777677671, "label": "Prettier package not actually being cached"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1170#issuecomment-754004715", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1170", "id": 754004715, "node_id": "MDEyOklzc3VlQ29tbWVudDc1NDAwNDcxNQ==", "user": {"value": 3637, "label": "benpickles"}, "created_at": "2021-01-04T14:25:44Z", "updated_at": "2021-01-04T14:25:44Z", "author_association": "CONTRIBUTOR", "body": "I was going to re-add the filter to only run Prettier when there have been changes in `datasette/static` but that would mean it wouldn't run when the package is updated. That plus the fact that [the last run of the job took only 8 seconds](https://github.com/benpickles/datasette/runs/1640121514) is why I decided not to re-add the filter.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 778126516, "label": "Install Prettier via package.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1012#issuecomment-753531657", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1012", "id": 753531657, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MzUzMTY1Nw==", "user": {"value": 45380, "label": "bollwyvl"}, "created_at": "2021-01-02T21:25:36Z", "updated_at": "2021-01-02T21:25:36Z", "author_association": "CONTRIBUTOR", "body": "Actually, on more research, I found out this is handled by the [trove-classifiers package](https://github.com/pypa/trove-classifiers/blob/master/src/trove_classifiers/__init__.py#L2) now, so it's just a one-liner pr instead of fire-up-a-docker-container-and-do-some-migrations", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 718540751, "label": "For 1.0 update trove classifier in setup.py"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/417#issuecomment-752098906", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/417", "id": 752098906, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MjA5ODkwNg==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-12-29T14:34:30Z", "updated_at": "2020-12-29T14:34:50Z", "author_association": "CONTRIBUTOR", "body": "FWIW, I had a look at `watchdog` for a `datasette` powered Jupyter notebook search tool: https://github.com/ouseful-testing/nbsearch/blob/main/nbsearch/nbwatchdog.py\r\n\r\nNot a production thing, just an experiment trying to explore what might be possible...", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 421546944, "label": "Datasette Library"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/pull/59#issuecomment-751375487", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/59", "id": 751375487, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MTM3NTQ4Nw==", "user": {"value": 631242, "label": "frosencrantz"}, "created_at": "2020-12-26T17:08:44Z", "updated_at": "2020-12-26T17:08:44Z", "author_association": "CONTRIBUTOR", "body": "Hi @simonw, do I need to do anything else for this PR to be considered to be included? I've tried using this project and it is quite nice to be able to explore a repository, but noticed that a couple commands don't allow you to use authorization from the environment variable.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 771872303, "label": "Remove unneeded exists=True for -a/--auth flag."}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1158#issuecomment-750389683", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1158", "id": 750389683, "node_id": "MDEyOklzc3VlQ29tbWVudDc1MDM4OTY4Mw==", "user": {"value": 6774676, "label": "eumiro"}, "created_at": "2020-12-23T17:02:50Z", "updated_at": "2020-12-23T17:02:50Z", "author_association": "CONTRIBUTOR", "body": "The dict/set suggestion comes from `pyupgrade --py36-plus`, but then had to `black` the change.\r\n\r\nThe rest comes from PyCharm's Inspect code function. I reviewed all the suggestions and fixed a thing or two, such as leading/trailing spaces in the docstrings or turned around the chained conditions.\r\n\r\nThen I tried to convert all `os.path/glob/open` to `Path`, but there were some local test issues, so I'll have to start over in smaller chunks if you want to have that too.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 773913793, "label": "Modernize code to Python 3.6+"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/pull/31#issuecomment-748562330", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/31", "id": 748562330, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODU2MjMzMA==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2020-12-20T04:45:08Z", "updated_at": "2020-12-20T04:45:08Z", "author_association": "CONTRIBUTOR", "body": "Fixes the issue mentioned here: https://github.com/dogsheep/dogsheep-photos/issues/15#issuecomment-748436115", "reactions": "{\"total_count\": 1, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 1, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 771511344, "label": "Update for Big Sur"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/issues/15#issuecomment-748562288", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/15", "id": 748562288, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODU2MjI4OA==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2020-12-20T04:44:22Z", "updated_at": "2020-12-20T04:44:22Z", "author_association": "CONTRIBUTOR", "body": "@nickvazz @simonw I opened a [PR](https://github.com/dogsheep/dogsheep-photos/pull/31) that replaces the SQL for `ZCOMPUTEDASSETATTRIBUTES` to use osxphotos which now exposes all this data and has been updated for Big Sur. I did regression tests to confirm the extracted data is identical, with one exception which should not affect operation: the old code pulled data from `ZCOMPUTEDASSETATTRIBUTES` for missing photos while the main loop ignores missing photos and does not add them to `apple_photos`. The new code does not add rows to the `apple_photos_scores` table for missing photos.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 612151767, "label": "Expose scores from ZCOMPUTEDASSETATTRIBUTES"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/dogsheep-photos/issues/15#issuecomment-748436779", "issue_url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/15", "id": 748436779, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODQzNjc3OQ==", "user": {"value": 41546558, "label": "RhetTbull"}, "created_at": "2020-12-19T07:49:00Z", "updated_at": "2020-12-19T07:49:00Z", "author_association": "CONTRIBUTOR", "body": "@nickvazz ZGENERICASSET changed to ZASSET in Big Sur. Here's a list of other changes to the schema in Big Sur: https://github.com/RhetTbull/osxphotos/wiki/Changes-in-Photos-6---Big-Sur", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 612151767, "label": "Expose scores from ZCOMPUTEDASSETATTRIBUTES"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/493#issuecomment-748305976", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/493", "id": 748305976, "node_id": "MDEyOklzc3VlQ29tbWVudDc0ODMwNTk3Ng==", "user": {"value": 50527, "label": "jefftriplett"}, "created_at": "2020-12-18T20:34:39Z", "updated_at": "2020-12-18T20:34:39Z", "author_association": "CONTRIBUTOR", "body": "I can't keep up with the renaming contexts, but I like having the ability to run datasette+ datasette-ripgrep against different configs: \r\n\r\n```shell\r\ndatasette serve --metadata=./metadata.json\r\n```\r\n\r\nI have one for all of my code and one per client who has lots of code. So as long as I can point to datasette to something, it's easy to work with. ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 449886319, "label": "Rename metadata.json to config.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/998#issuecomment-743080047", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/998", "id": 743080047, "node_id": "MDEyOklzc3VlQ29tbWVudDc0MzA4MDA0Nw==", "user": {"value": 6371750, "label": "JBPressac"}, "created_at": "2020-12-11T09:25:09Z", "updated_at": "2020-12-11T09:25:09Z", "author_association": "CONTRIBUTOR", "body": "Hello Simon,\r\nI have a similar problem with horizontal scrollbar display with Datasette version 0.51 and superior for a table with more than 30 rows. With Datasette 0.50, the horizontal scrollbar is displayed, if I upgrade Datasette to 0.51 and superior, the horizontal scrollbar disappears.\r\n\r\nDatasette 0.50: horizontal scrollbar\r\n\r\n\r\n\r\nDatasette 0.51 and superior: no horizontal scrollbar\r\n\r\n\r\n\r\nThanks,", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 717699884, "label": "Wide tables should scroll horizontally within the page"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1130#issuecomment-738907852", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1130", "id": 738907852, "node_id": "MDEyOklzc3VlQ29tbWVudDczODkwNzg1Mg==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-12-04T17:22:29Z", "updated_at": "2020-12-04T17:31:25Z", "author_association": "CONTRIBUTOR", "body": "EDIT: I misunderstood the problem. This seems like a fix better suited for Safari. But I don't have any Apple device to test it.\r\n\r\n```css\r\nbody {\r\n min-height: 100vh;\r\n min-height: -webkit-fill-available;\r\n}\r\nhtml {\r\n height: -webkit-fill-available;\r\n}\r\n```\r\nhttps://css-tricks.com/css-fix-for-100vh-in-mobile-webkit/\r\n\r\n---\r\n\r\nIt's actually not that difficult to fix.\r\nWell, this is actually a workaround to keep viewport in place.\r\n\r\nI usually put a transition (forgot to do it here) that keeps page from resizing.\r\n\r\n```css\r\n.container {\r\n min-height: 100vh;\r\n transition: height 10000s steps(0);\r\n}\r\n```\r\n\r\n`steps()` function prevents excessive layout calculations, and lets the page snap back into place (10000s ~= 3h later) in a single step.\r\nThis fix also prevents page from jumping around when the keyboard pops up and down.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 756876238, "label": "Fix footer not sticking to bottom in short pages"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1111#issuecomment-736322290", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1111", "id": 736322290, "node_id": "MDEyOklzc3VlQ29tbWVudDczNjMyMjI5MA==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-12-01T08:54:47Z", "updated_at": "2020-12-01T08:54:47Z", "author_association": "CONTRIBUTOR", "body": "Somewhat related: https://github.com/simonw/datasette/issues/859\r\nI fixed the issue with forking and disabling the counts for hidden tables.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 751195017, "label": "Accessing a database's `.json` is slow for very large SQLite files"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1114#issuecomment-735436014", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1114", "id": 735436014, "node_id": "MDEyOklzc3VlQ29tbWVudDczNTQzNjAxNA==", "user": {"value": 2182, "label": "danp"}, "created_at": "2020-11-29T18:33:30Z", "updated_at": "2020-11-29T18:33:30Z", "author_association": "CONTRIBUTOR", "body": "Thank you!", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 752966476, "label": "--load-extension=spatialite not working with datasetteproject/datasette docker image"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/493#issuecomment-735281577", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/493", "id": 735281577, "node_id": "MDEyOklzc3VlQ29tbWVudDczNTI4MTU3Nw==", "user": {"value": 50527, "label": "jefftriplett"}, "created_at": "2020-11-28T19:39:53Z", "updated_at": "2020-11-28T19:39:53Z", "author_association": "CONTRIBUTOR", "body": "I was confused by `--config` and I tried passing the json from datasette-ripgrep into `config.json` just as a wild guess. \r\n\r\nA short term solution might be pointing out in plugins that their snippet json can go in `metadata.json` at least makes it easier to search for config options or to know where to start if someone is new. ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 449886319, "label": "Rename metadata.json to config.json"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1112#issuecomment-735279355", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1112", "id": 735279355, "node_id": "MDEyOklzc3VlQ29tbWVudDczNTI3OTM1NQ==", "user": {"value": 50527, "label": "jefftriplett"}, "created_at": "2020-11-28T19:21:09Z", "updated_at": "2020-11-28T19:21:09Z", "author_association": "CONTRIBUTOR", "body": "(Even more annoying is that I see my editor leaked an extra delete space at the end of the line. I'm happy to rebuild this to be less annoying, but you probably don't want the changelog update either way)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 752749485, "label": "Fix --metadata doc usage"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/838#issuecomment-720354227", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/838", "id": 720354227, "node_id": "MDEyOklzc3VlQ29tbWVudDcyMDM1NDIyNw==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-11-02T09:33:58Z", "updated_at": "2020-11-02T09:33:58Z", "author_association": "CONTRIBUTOR", "body": "Thanks; just a note that the `datasette.urls.static(path)` and `datasette.urls.static_plugins(plugin_name, path)` items both seem to be repeated and appear in the docs twice?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 637395097, "label": "Incorrect URLs when served behind a proxy with base_url set"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1049#issuecomment-718528252", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1049", "id": 718528252, "node_id": "MDEyOklzc3VlQ29tbWVudDcxODUyODI1Mg==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-29T09:20:34Z", "updated_at": "2020-10-29T09:20:34Z", "author_association": "CONTRIBUTOR", "body": "That workaround is probably fine. I was trying to work out whether there might be other situations where a pre-external package load might be useful but couldn't offhand bring any other examples to mind. The static plugins option also looks interesting.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 729017519, "label": "Add template block prior to extra URL loaders"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/189#issuecomment-717359145", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/189", "id": 717359145, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNzM1OTE0NQ==", "user": {"value": 35681, "label": "adamwolf"}, "created_at": "2020-10-27T16:20:32Z", "updated_at": "2020-10-27T16:20:32Z", "author_association": "CONTRIBUTOR", "body": "No problem. I added a test. Let me know if it looks sufficient or if you want me to to tweak something!\r\n\r\nIf you don't mind, would you tag this PR as \"hacktoberfest-accepted\"? If you do mind, no problem and I'm sorry for asking :) My kiddos like the shirts.", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 729818242, "label": "Allow iterables other than Lists in m2m records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/1043#issuecomment-716237524", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1043", "id": 716237524, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNjIzNzUyNA==", "user": {"value": 45380, "label": "bollwyvl"}, "created_at": "2020-10-26T00:14:57Z", "updated_at": "2020-10-26T00:14:57Z", "author_association": "CONTRIBUTOR", "body": "Sorry, I was out of the loop this weekend. The missing sdists were in some the `datasette-*` plugins... i'll capture my findings more concretely in one spot when i have a chance...", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 727915394, "label": "Include LICENSE in sdist"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/838#issuecomment-716123598", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/838", "id": 716123598, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNjEyMzU5OA==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-25T10:20:12Z", "updated_at": "2020-10-25T10:53:24Z", "author_association": "CONTRIBUTOR", "body": "I'm trying to [run something behind a MyBinder proxy](https://github.com/ouseful-testing/nbsearch), but seem to have something set up incorrectly and not sure what the fix is?\r\n\r\nI'm starting datasette with jupyter-server-proxy setup:\r\n\r\n```\r\n# __init__.py\r\ndef setup_nbsearch():\r\n\r\n return {\r\n \"command\": [\r\n \"datasette\",\r\n \"serve\",\r\n f\"{_NBSEARCH_DB_PATH}\",\r\n \"-p\",\r\n \"{port}\",\r\n \"--config\",\r\n \"base_url:{base_url}nbsearch/\"\r\n ],\r\n \"absolute_url\": True,\r\n # The following needs a the labextension installing.\r\n # eg in postBuild: jupyter labextension install jupyterlab-server-proxy\r\n \"launcher_entry\": {\r\n \"enabled\": True,\r\n \"title\": \"nbsearch\",\r\n },\r\n }\r\n```\r\n\r\nwhere the `base_url` gets automatically populated by the server-proxy. I define the loaders as:\r\n\r\n```\r\n# __init__.py\r\nfrom datasette import hookimpl\r\n\r\n@hookimpl\r\ndef extra_css_urls(database, table, columns, view_name, datasette):\r\n return [\r\n \"/-/static-plugins/nbsearch/prism.css\",\r\n \"/-/static-plugins/nbsearch/nbsearch.css\",\r\n ]\r\n```\r\nbut these seem to also need a base_url prefix set somehow?\r\n\r\nCurrently, the generated HTML loads properly but internal links are incorrect; eg they take the form `` which resolves to eg `https://notebooks.gesis.org/hub/-/static-plugins/nbsearch/prism.css` rather than required URL of form `https://notebooks.gesis.org/binder/jupyter/user/ouseful-testing-nbsearch-0fx1mx67/nbsearch/-/static-plugins/nbsearch/prism.css`.\r\n\r\nThe main css is loaded correctly: ``", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 637395097, "label": "Incorrect URLs when served behind a proxy with base_url set"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1033#issuecomment-716066000", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1033", "id": 716066000, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNjA2NjAwMA==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-24T22:58:33Z", "updated_at": "2020-10-24T22:58:33Z", "author_association": "CONTRIBUTOR", "body": "From [the docs](https://docs.datasette.io/en/latest/internals.html#datasette-urls), I note:\r\n\r\n```\r\ndatasette.urls.instance()\r\nReturns the URL to the Datasette instance root page. This is usually \"/\"\r\n```\r\n\r\nWhat about the proxy case? Eg if I am using jupyter-server-proxy on a MyBinder or local Jupyter notebook server site, `https://example.com:PORT/weirdpath/datasette`, what does `datasette.urls.instance()` refer to?\r\n\r\n- [ ] `https://example.com:PORT/weirdpath/datasette`\r\n- [ ] `https://example.com:PORT/weirdpath/`\r\n- [ ] `https://example.com:PORT/`\r\n- [ ] `https://example.com`\r\n- [ ] something else?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 725099777, "label": "datasette.urls.static_plugins(...) method"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1012#issuecomment-714908859", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1012", "id": 714908859, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNDkwODg1OQ==", "user": {"value": 45380, "label": "bollwyvl"}, "created_at": "2020-10-23T04:49:20Z", "updated_at": "2020-10-23T04:49:20Z", "author_association": "CONTRIBUTOR", "body": "Good luck on 1.0! It may also be worth lobbying for a `Framework::Datasette::1.0` classifier. This would be a nice way to allow the ecosystem to self-document a bit more [discoverably](https://pypi.org/search/?q=&o=&c=Framework+%3A%3A+Datasette%3A%3A+1.0). \r\n\r\nI was surprised to see the [PR for `Framework::Jupyter`](https://github.com/pypa/warehouse/pull/1905/files) is a... database migration! Of course, there may be more workflow to it!", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 718540751, "label": "For 1.0 update trove classifier in setup.py"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1033#issuecomment-714657366", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1033", "id": 714657366, "node_id": "MDEyOklzc3VlQ29tbWVudDcxNDY1NzM2Ng==", "user": {"value": 82988, "label": "psychemedia"}, "created_at": "2020-10-22T17:51:29Z", "updated_at": "2020-10-22T17:51:29Z", "author_association": "CONTRIBUTOR", "body": "How does `/-/static` relate to [current guidance docs around `static`](https://docs.datasette.io/en/latest/custom_templates.html?highlight=static#serving-static-files) regarding the `--static option` and metadata formulations such as `\"extra_js_urls\": [ \"/static/app.js\"]` (I've not managed to get this to work in a Jupyter server proxied set up; the [datasette / jupyter server proxy repo](https://github.com/simonw/jupyterserverproxy-datasette-demo) may provide a useful test example, eg via MyBinder, for folk to crib from?) ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 725099777, "label": "datasette.urls.static_plugins(...) method"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/1019#issuecomment-708520800", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/1019", "id": 708520800, "node_id": "MDEyOklzc3VlQ29tbWVudDcwODUyMDgwMA==", "user": {"value": 639012, "label": "jsfenfen"}, "created_at": "2020-10-14T16:37:19Z", "updated_at": "2020-10-14T16:37:19Z", "author_association": "CONTRIBUTOR", "body": "\ud83c\udf89 Thanks so much @simonw ! \ud83c\udf89 ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 721050815, "label": "\"Edit SQL\" button on canned queries"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/swarm-to-sqlite/pull/10#issuecomment-707326192", "issue_url": "https://api.github.com/repos/dogsheep/swarm-to-sqlite/issues/10", "id": 707326192, "node_id": "MDEyOklzc3VlQ29tbWVudDcwNzMyNjE5Mg==", "user": {"value": 29426418, "label": "mattiaborsoi"}, "created_at": "2020-10-12T20:20:02Z", "updated_at": "2020-10-12T20:20:02Z", "author_association": "CONTRIBUTOR", "body": "This closes issue #8 ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 719637258, "label": "Update utils.py to fix sqlite3.OperationalError"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/github-to-sqlite/pull/48#issuecomment-704503719", "issue_url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/48", "id": 704503719, "node_id": "MDEyOklzc3VlQ29tbWVudDcwNDUwMzcxOQ==", "user": {"value": 755825, "label": "adamjonas"}, "created_at": "2020-10-06T19:26:59Z", "updated_at": "2020-10-06T19:26:59Z", "author_association": "CONTRIBUTOR", "body": "ref #46 ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 681228542, "label": "Add pull requests"}, "performed_via_github_app": null}
{"html_url": "https://github.com/dogsheep/twitter-to-sqlite/issues/50#issuecomment-690860653", "issue_url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/50", "id": 690860653, "node_id": "MDEyOklzc3VlQ29tbWVudDY5MDg2MDY1Mw==", "user": {"value": 370930, "label": "mikepqr"}, "created_at": "2020-09-11T04:04:08Z", "updated_at": "2020-09-11T04:04:08Z", "author_association": "CONTRIBUTOR", "body": "There's probably a nicer way of doing (hence this is a comment rather than a PR), but this appears to fix it:\r\n```diff\r\n--- a/twitter_to_sqlite/utils.py\r\n+++ b/twitter_to_sqlite/utils.py\r\n@@ -181,6 +181,7 @@ def fetch_timeline(\r\n args[\"tweet_mode\"] = \"extended\"\r\n min_seen_id = None\r\n num_rate_limit_errors = 0\r\n+ seen_count = 0\r\n while True:\r\n if min_seen_id is not None:\r\n args[\"max_id\"] = min_seen_id - 1\r\n@@ -208,6 +209,7 @@ def fetch_timeline(\r\n yield tweet\r\n min_seen_id = min(t[\"id\"] for t in tweets)\r\n max_seen_id = max(t[\"id\"] for t in tweets)\r\n+ seen_count += len(tweets)\r\n if last_since_id is not None:\r\n max_seen_id = max((last_since_id, max_seen_id))\r\n last_since_id = max_seen_id\r\n@@ -217,7 +219,9 @@ def fetch_timeline(\r\n replace=True,\r\n )\r\n if stop_after is not None:\r\n- break\r\n+ if seen_count >= stop_after:\r\n+ break\r\n+ args[\"count\"] = min(args[\"count\"], stop_after - seen_count)\r\n time.sleep(sleep)\r\n```", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 698791218, "label": "favorites --stop_after=N stops after min(N, 200)"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/146#issuecomment-688573964", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/146", "id": 688573964, "node_id": "MDEyOklzc3VlQ29tbWVudDY4ODU3Mzk2NA==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-09-08T01:55:07Z", "updated_at": "2020-09-08T01:55:07Z", "author_association": "CONTRIBUTOR", "body": "Okay, I've rewritten this PR to preserve the batching behaviour but still fix #145, and rebased the branch to account for the `db.execute()` api change. It's not terribly sophisticated -- if it attempts to insert a batch which has too many variables, the exception is caught, the batch is split in two and each half is inserted separately, and then it carries on as before with the same `batch_size`. In the edge case where this gets triggered, subsequent batches will all be inserted in two groups too if they continue to have the same number of columns (which is presumably reasonably likely). Do you reckon this is acceptable when set against the awkwardness of recalculating the `batch_size` on the fly?", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688668680, "label": "Handle case where subsequent records (after first batch) include extra columns"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/146#issuecomment-688481317", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/146", "id": 688481317, "node_id": "MDEyOklzc3VlQ29tbWVudDY4ODQ4MTMxNw==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-09-07T19:18:55Z", "updated_at": "2020-09-07T19:18:55Z", "author_association": "CONTRIBUTOR", "body": "Just force-pushed to update d042f9c with more formatting changes to satisfy `black==20.8b1` and pass the GitHub Actions \"Test\" workflow.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688668680, "label": "Handle case where subsequent records (after first batch) include extra columns"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/146#issuecomment-688479163", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/146", "id": 688479163, "node_id": "MDEyOklzc3VlQ29tbWVudDY4ODQ3OTE2Mw==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-09-07T19:10:33Z", "updated_at": "2020-09-07T19:11:57Z", "author_association": "CONTRIBUTOR", "body": "@simonw -- I've gone ahead updated the documentation to reflect the changes introduced in this PR. IMO it's ready to merge now.\r\n\r\nIn writing the documentation changes, I begin to wonder about the value and role of `batch_size` at all, tbh. May I assume it was originally intended to prevent using the entire row set to determine columns and column types, and that this was a performance consideration? If so, this PR entirely undermines its purpose. I've been passing in excess of 500,000 rows at a time to `insert_all()` with these changes and although I'm sure the performance difference is measurable it's not really noticeable; given #145, I don't know that any performance advantages outweigh the problems doing it this way removes. What do you think about just dropping the argument and defaulting to the maximum `batch_size` permissible given `SQLITE_MAX_VARS`? Are there other reasons one might want to restrict `batch_size` that I've overlooked? I could open a new issue to discuss/implement this.\r\n\r\nOf course the documentation will need to change again too if/when something is done about #147.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688668680, "label": "Handle case where subsequent records (after first batch) include extra columns"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/952#issuecomment-686061028", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/952", "id": 686061028, "node_id": "MDEyOklzc3VlQ29tbWVudDY4NjA2MTAyOA==", "user": {"value": 27856297, "label": "dependabot-preview[bot]"}, "created_at": "2020-09-02T22:26:14Z", "updated_at": "2020-09-02T22:26:14Z", "author_association": "CONTRIBUTOR", "body": "Looks like black is up-to-date now, so this is no longer needed.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 687245650, "label": "Update black requirement from ~=19.10b0 to >=19.10,<21.0"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/145#issuecomment-683382252", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/145", "id": 683382252, "node_id": "MDEyOklzc3VlQ29tbWVudDY4MzM4MjI1Mg==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-08-30T06:27:25Z", "updated_at": "2020-08-30T06:27:52Z", "author_association": "CONTRIBUTOR", "body": "Note: had to adjust the test above because trying to exhaust a `SQLITE_MAX_VARIABLE_NUMBER` of 250000 in 99 records requires 2526 columns, and trips the ` \"Rows can have a maximum of {} columns\".format(SQLITE_MAX_VARS)` check even before it trips the default `SQLITE_MAX_COLUMN` value (2000).", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 688659182, "label": "Bug when first record contains fewer columns than subsequent records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682815377", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/139", "id": 682815377, "node_id": "MDEyOklzc3VlQ29tbWVudDY4MjgxNTM3Nw==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-08-28T16:14:58Z", "updated_at": "2020-08-28T16:14:58Z", "author_association": "CONTRIBUTOR", "body": "Thanks! And yeah, I had updating the docs on my list too :) Will try to get to it this afternoon (budgeting time is fraught with uncertainty at the moment!).", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 686978131, "label": "insert_all(..., alter=True) should work for new columns introduced after the first 100 records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682182178", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/139", "id": 682182178, "node_id": "MDEyOklzc3VlQ29tbWVudDY4MjE4MjE3OA==", "user": {"value": 96218, "label": "simonwiles"}, "created_at": "2020-08-27T20:46:18Z", "updated_at": "2020-08-27T20:46:18Z", "author_association": "CONTRIBUTOR", "body": "> I tried changing the batch_size argument to the total number of records, but it seems only to effect the number of rows that are committed at a time, and has no influence on this problem.\r\n\r\nSo the reason for this is that the `batch_size` for import is limited (of necessity) here: https://github.com/simonw/sqlite-utils/blob/main/sqlite_utils/db.py#L1048\r\n\r\nWith regard to the issue of ignoring columns, however, I made a fork and hacked a temporary fix that looks like this:\r\nhttps://github.com/simonwiles/sqlite-utils/commit/3901f43c6a712a1a3efc340b5b8d8fd0cbe8ee63\r\n\r\nIt doesn't seem to affect performance enormously (but I've not tested it thoroughly), and it now does what I need (and would expect, tbh), but it now fails the test here:\r\nhttps://github.com/simonw/sqlite-utils/blob/main/tests/test_create.py#L710-L716\r\n\r\nThe existence of this test suggests that `insert_all()` is behaving as intended, of course. It seems odd to me that this would be a desirable default behaviour (let alone the only behaviour), and its not very prominently flagged-up, either.\r\n\r\n@simonw is this something you'd be willing to look at a PR for? I assume you wouldn't want to change the default behaviour at this point, but perhaps an option could be provided, or at least a bit more of a warning in the docs. Are there oversights in the implementation that I've made?\r\n\r\nWould be grateful for your thoughts! Thanks!\r\n", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 686978131, "label": "insert_all(..., alter=True) should work for new columns introduced after the first 100 records"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/456#issuecomment-661524006", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/456", "id": 661524006, "node_id": "MDEyOklzc3VlQ29tbWVudDY2MTUyNDAwNg==", "user": {"value": 32467826, "label": "abeyerpath"}, "created_at": "2020-07-21T01:15:07Z", "updated_at": "2020-07-21T01:15:07Z", "author_association": "CONTRIBUTOR", "body": "Bumping this, as the previous fix is passing the wrong type, and not actually addressing the issue...\r\n\r\nThe `exclude` argument needs an iterable of packages instead of a single string (but since `str` is iterable, it's currently excluding packages `t`, `e`, and `s`.)", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 442327592, "label": "Installing installs the tests package"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/121#issuecomment-655898722", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/121", "id": 655898722, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTg5ODcyMg==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-09T04:53:08Z", "updated_at": "2020-07-09T04:53:08Z", "author_association": "CONTRIBUTOR", "body": "Yep, I agree that makes more sense for backwards compat and more casual use cases. I think it should be possible for the Database/Queryable methods to DTRT based on seeing if it's within a context-manager-managed transaction.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 652961907, "label": "Improved (and better documented) support for transactions"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/issues/121#issuecomment-655652679", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/121", "id": 655652679, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTY1MjY3OQ==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-08T17:24:46Z", "updated_at": "2020-07-08T17:24:46Z", "author_association": "CONTRIBUTOR", "body": "Better transaction handling would be really great. Some of my thoughts on implementing better transaction discipline are in https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655239728.\r\n\r\nMy preferences:\r\n\r\n- Each CLI command should operate in a single transaction so that either the whole thing succeeds or the whole thing is rolled back. This avoids partially completed operations when an error occurs part way through processing. Partially completed operations are typically much harder to recovery from gracefully and may cause inconsistent data states.\r\n\r\n- The Python API should be transaction-agnostic and rely on the caller to coordinate transactions. Only the caller knows how individual insert, create, update, etc operations/methods should be bundled conceptually into transactions. When the caller is the CLI, for example, that bundling would be at the CLI command-level. Other callers might want to break up operations into multiple transactions. Transactions are usually most useful when controlled at the application-level (like logging configuration) instead of the library level. The library needs to provide an API that's conducive to transaction use, though.\r\n\r\n- The Python API should provide a context manager to provide consistent transactions handling with more useful defaults than Python's `sqlite3` module. The latter issues implicit `BEGIN` statements by default for most DML (`INSERT`, `UPDATE`, `DELETE`, \u2026 but not `SELECT`, I believe), but **not** DDL (`CREATE TABLE`, `DROP TABLE`, `CREATE VIEW`, \u2026). Notably, the `sqlite3` module doesn't issue the implicit `BEGIN` until the first DML statement. It _does not_ issue it when entering the `with conn` block, like other DBAPI2-compatible modules do. The `with conn` block for `sqlite3` only arranges to commit or rollback an existing transaction when exiting. Including DDL and `SELECT`s in transactions is important for operation consistency, though. There are several existing bugs.python.org tickets about this and future changes are in the works, but sqlite-utils can provide its own API sooner. sqlite-utils's `Database` class could itself be a context manager (built on the `sqlite3` connection context manager) which additionally issues an explicit `BEGIN` when entering. This would then let Python API callers do something like:\r\n\r\n```python\r\ndb = sqlite_utils.Database(path)\r\n\r\nwith db: # \u2190 BEGIN issued here by Database.__enter__\r\n db.insert(\u2026)\r\n db.create_view(\u2026)\r\n# \u2190 COMMIT/ROLLBACK issue here by sqlite3.connection.__exit__\r\n```", "reactions": "{\"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 652961907, "label": "Improved (and better documented) support for transactions"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655643078", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655643078, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTY0MzA3OA==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-08T17:05:59Z", "updated_at": "2020-07-08T17:05:59Z", "author_association": "CONTRIBUTOR", "body": "> The only thing missing from this PR is updates to the documentation.\r\n\r\nAh, yes, thanks for this reminder! I've repushed with doc bits added.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655239728", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655239728, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTIzOTcyOA==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-08T02:16:42Z", "updated_at": "2020-07-08T02:16:42Z", "author_association": "CONTRIBUTOR", "body": "I fixed my original oops by moving the `DELETE FROM $table` out of the chunking loop and repushed. I think this change can be considered in isolation from issues around transactions, which I discuss next.\r\n\r\nI wanted to make the DELETE + INSERT happen all in the same transaction so it was robust, but that was more complicated than I expected. The transaction handling in the Database/Table classes isn't systematic, and this poses big hurdles to making `Table.insert_all` (or other operations) consistent and robust in the face of errors.\r\n\r\nFor example, I wanted to do this (whitespace ignored in diff, so indentation change not highlighted):\r\n\r\n```diff\r\ndiff --git a/sqlite_utils/db.py b/sqlite_utils/db.py\r\nindex d6b9ecf..4107ceb 100644\r\n--- a/sqlite_utils/db.py\r\n+++ b/sqlite_utils/db.py\r\n@@ -1028,6 +1028,11 @@ class Table(Queryable):\r\n batch_size = max(1, min(batch_size, SQLITE_MAX_VARS // num_columns))\r\n self.last_rowid = None\r\n self.last_pk = None\r\n+ with self.db.conn:\r\n+ # Explicit BEGIN is necessary because Python's sqlite3 doesn't\r\n+ # issue implicit BEGINs for DDL, only DML. We mix DDL and DML\r\n+ # below and might execute DDL first, e.g. for table creation.\r\n+ self.db.conn.execute(\"BEGIN\")\r\n if truncate and self.exists():\r\n self.db.conn.execute(\"DELETE FROM [{}];\".format(self.name))\r\n for chunk in chunks(itertools.chain([first_record], records), batch_size):\r\n@@ -1038,7 +1043,11 @@ class Table(Queryable):\r\n # Use the first batch to derive the table names\r\n column_types = suggest_column_types(chunk)\r\n column_types.update(columns or {})\r\n- self.create(\r\n+ # Not self.create() because that is wrapped in its own\r\n+ # transaction and Python's sqlite3 doesn't support\r\n+ # nested transactions.\r\n+ self.db.create_table(\r\n+ self.name,\r\n column_types,\r\n pk,\r\n foreign_keys,\r\n@@ -1139,7 +1148,6 @@ class Table(Queryable):\r\n flat_values = list(itertools.chain(*values))\r\n queries_and_params = [(sql, flat_values)]\r\n \r\n- with self.db.conn:\r\n for query, params in queries_and_params:\r\n try:\r\n result = self.db.conn.execute(query, params)\r\n```\r\n\r\nbut that fails in tests because other methods call `insert/upsert/insert_all/upsert_all` in the middle of their transactions, so the BEGIN statement throws an error (no nested transactions allowed).\r\n\r\nStepping back, it would be nice to make the transaction handling systematic and predictable. One way to do this is to make the `sqlite_utils/db.py` code generally not begin or commit any transactions, and require the caller to do that instead. This lets the caller mix and match the Python API calls into transactions as appropriate (which is impossible for the API methods themselves to fully determine). Then, make `sqlite_utils/cli.py` begin and commit a transaction in each `@cli.command` function, making each command robust and consistent in the face of errors. The big change here, and why I didn't just submit a patch, is that it dramatically changes the Python API to _require_ callers to begin a transaction rather than just immediately calling methods.\r\n\r\nThere is also the caveat that for each transaction, an explicit `BEGIN` is also necessary so that DDL as well as DML (as well as `SELECT`s) are consistent and rolled back on error. There are several bugs.python.org discussions around this particular problem of DDL and some plans to make it better and consistent with DBAPI2, eventually. In the meantime, the sqlite-utils Database class could be a context manager which supports the incantations necessary to do proper transactions. This would still be a Python API change for callers but wouldn't expose them to the weirdness of the sqlite3's default transaction handling.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655052451", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655052451, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTA1MjQ1MQ==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-07T18:45:23Z", "updated_at": "2020-07-07T18:45:23Z", "author_association": "CONTRIBUTOR", "body": "Ah, I see the problem. The truncate is inside a loop I didn't realize was there.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/sqlite-utils/pull/118#issuecomment-655018966", "issue_url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118", "id": 655018966, "node_id": "MDEyOklzc3VlQ29tbWVudDY1NTAxODk2Ng==", "user": {"value": 79913, "label": "tsibley"}, "created_at": "2020-07-07T17:41:06Z", "updated_at": "2020-07-07T17:41:06Z", "author_association": "CONTRIBUTOR", "body": "Hmm, while tests pass, this may not work as intended on larger datasets. Looking into it.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 651844316, "label": "Add insert --truncate option"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/889#issuecomment-653002499", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/889", "id": 653002499, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MzAwMjQ5OQ==", "user": {"value": 49260, "label": "amjith"}, "created_at": "2020-07-02T13:22:13Z", "updated_at": "2020-07-02T13:22:13Z", "author_association": "CONTRIBUTOR", "body": "I was able to narrow this down to the fact that lifespan protocol is turned on. \r\n\r\nI see the workaround you've used here: https://github.com/simonw/datasette-debug-asgi/commit/72d568d32a3159c763ce908c0b269736935c6987\r\n\r\nIf so, maybe it's time to update some of the asg_wrapper [plugins](https://datasette.readthedocs.io/en/stable/plugin_hooks.html#asgi-wrapper-datasette). ", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 649907676, "label": "asgi_wrapper plugin hook is crashing at startup"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/889#issuecomment-652990131", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/889", "id": 652990131, "node_id": "MDEyOklzc3VlQ29tbWVudDY1Mjk5MDEzMQ==", "user": {"value": 49260, "label": "amjith"}, "created_at": "2020-07-02T12:58:11Z", "updated_at": "2020-07-02T13:00:18Z", "author_association": "CONTRIBUTOR", "body": "FWIW, this error does NOT happen in datasette 0.45a4.\r\n\r\nIt only started on 0.45a5", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 649907676, "label": "asgi_wrapper plugin hook is crashing at startup"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/883#issuecomment-652394742", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/883", "id": 652394742, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MjM5NDc0Mg==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-07-01T12:41:13Z", "updated_at": "2020-07-01T12:41:13Z", "author_association": "CONTRIBUTOR", "body": "Well tests need to be updated.\r\n \r\nI need to get tests working on Windows.", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 648749062, "label": "Skip counting hidden tables"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/pull/883#issuecomment-652297139", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/883", "id": 652297139, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MjI5NzEzOQ==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-07-01T09:11:29Z", "updated_at": "2020-07-01T09:11:29Z", "author_association": "CONTRIBUTOR", "body": "Turns out we should include hidden tables in the result dict, or we're breaking tests. I've committed a refactor https://github.com/simonw/datasette/pull/883/commits/4f06e1bf6fbe4b73be770b87f610bf7c0e6e3ea7", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 648749062, "label": "Skip counting hidden tables"}, "performed_via_github_app": null}
{"html_url": "https://github.com/simonw/datasette/issues/877#issuecomment-652255960", "issue_url": "https://api.github.com/repos/simonw/datasette/issues/877", "id": 652255960, "node_id": "MDEyOklzc3VlQ29tbWVudDY1MjI1NTk2MA==", "user": {"value": 3243482, "label": "abdusco"}, "created_at": "2020-07-01T07:52:25Z", "updated_at": "2020-07-01T08:10:00Z", "author_association": "CONTRIBUTOR", "body": "I am calling the API from another origin, so injecting CSRF token into templates wouldn't work.\r\n\r\nEDIT:\r\n\r\nI'll try the new version, it sounds promising", "reactions": "{\"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "issue": {"value": 648421105, "label": "Consider dropping explicit CSRF protection entirely?"}, "performed_via_github_app": null}