issue_comments
18 rows where issue = 973139047 and "updated_at" is on date 2022-02-18 sorted by reactions
This data as json, CSV (advanced)
Suggested facets: created_at (date)
issue 1
- Rethink how .ext formats (v.s. ?_format=) works before 1.0 · 18 ✖
| id | html_url | issue_url | node_id | user | created_at | updated_at | author_association | body | reactions ▼ | issue | performed_via_github_app |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1045024276 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045024276 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-Sc4U | simonw 9599 | 2022-02-18T19:01:42Z | 2022-02-18T19:55:24Z | OWNER |
def dash_decode(s): return s.replace("-/", "/").replace("-.", ".").replace("--", "-") ``` ```pycon
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045027067 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045027067 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-Sdj7 | simonw 9599 | 2022-02-18T19:03:26Z | 2022-02-18T19:03:26Z | OWNER | (If I make this change it may break some existing Datasette installations when they upgrade - I could try and build a plugin for them which triggers on 404s and checks to see if the old format would return a 200 response, then returns that.) |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045032377 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045032377 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-Se25 | simonw 9599 | 2022-02-18T19:06:50Z | 2022-02-18T19:06:50Z | OWNER | How does URL routing for https://latest.datasette.io/fixtures/table%2Fwith%2Fslashes.csv work? Right now it's https://github.com/simonw/datasette/blob/7d24fd405f3c60e4c852c5d746c91aa2ba23cf5b/datasette/app.py#L1098-L1101 That's not going to capture the dot-dash encoding version of that table name: ```pycon
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
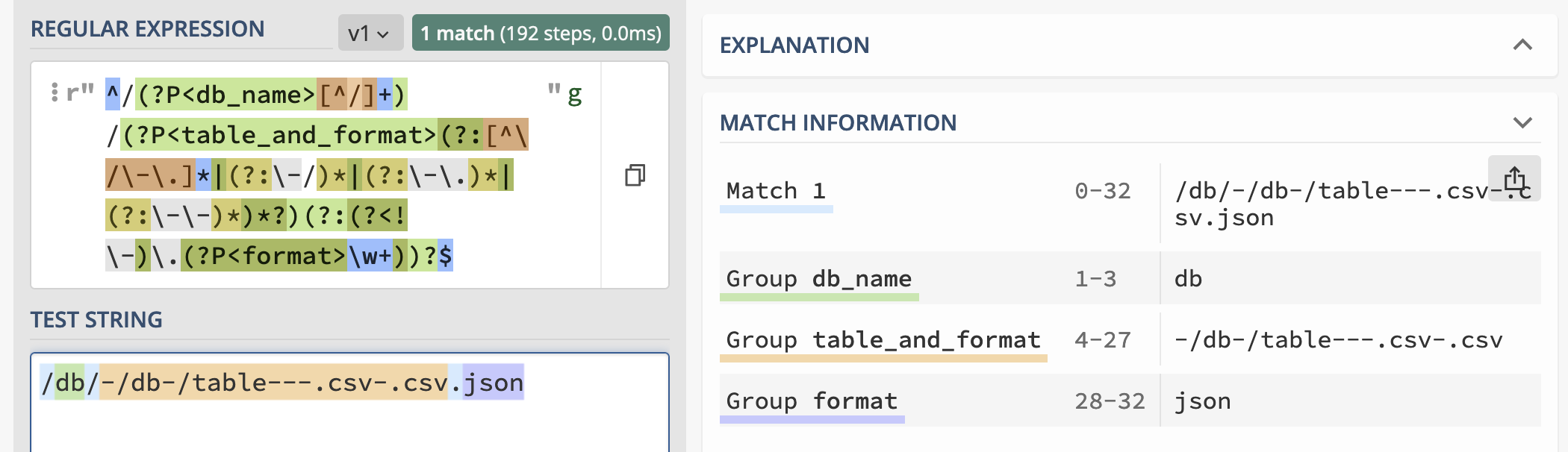
| 1045055772 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045055772 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-Skkc | simonw 9599 | 2022-02-18T19:23:33Z | 2022-02-18T19:25:42Z | OWNER | I want a match for this URL: Maybe this: Here we are matching a sequence of: So a combination of not-slashes OR -/ or -. Or -- sequences
Try that with non-capturing bits:
Here's the explanation on regex101.com https://regex101.com/r/CPnsIO/1
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045059427 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045059427 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-Sldj | simonw 9599 | 2022-02-18T19:26:25Z | 2022-02-18T19:26:25Z | OWNER | With this new pattern I could probably extract out the optional |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045075207 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045075207 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-SpUH | simonw 9599 | 2022-02-18T19:39:35Z | 2022-02-18T19:40:13Z | OWNER |
Here's what those look like with the updated version of
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045077590 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045077590 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-Sp5W | simonw 9599 | 2022-02-18T19:41:37Z | 2022-02-18T19:42:41Z | OWNER | Ugh, one disadvantage I just spotted with this: Datasette already has a And I've thought about adding Maybe change this system to use |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045081042 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045081042 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-SqvS | simonw 9599 | 2022-02-18T19:44:12Z | 2022-02-18T19:51:34Z | OWNER | ```python def dot_encode(s): return s.replace(".", "..").replace("/", "./") def dot_decode(s): return s.replace("./", "/").replace("..", ".") ``` No need for hyphen encoding in this variant at all, which simplifies things a bit. (Update: this is flawed, see https://github.com/simonw/datasette/issues/1439#issuecomment-1045086033) |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045082891 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045082891 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-SrML | simonw 9599 | 2022-02-18T19:45:32Z | 2022-02-18T19:45:32Z | OWNER | ```pycon
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045086033 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045086033 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-Sr9R | simonw 9599 | 2022-02-18T19:47:43Z | 2022-02-18T19:51:11Z | OWNER |
Do both of those survive the round-trip to populate No! In both cases the It looks like this might even be a client issue - ``` ~ % curl -vv -i 'https://datasette.io/-/asgi-scope/db/./db./table-..csv..csv' * Trying 216.239.32.21:443... * Connected to datasette.io (216.239.32.21) port 443 (#0) * ALPN, offering http/1.1 * TLS 1.2 connection using TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 * Server certificate: datasette.io * Server certificate: R3 * Server certificate: ISRG Root X1
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045095348 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045095348 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-SuO0 | simonw 9599 | 2022-02-18T19:53:48Z | 2022-02-18T19:53:48Z | OWNER |
I don't think this matters. The new regex does indeed capture that kind of page:
But Datasette goes through configured route regular expressions in order - so I can have the regex that captures |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045099290 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045099290 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-SvMa | simonw 9599 | 2022-02-18T19:56:18Z | 2022-02-18T19:56:30Z | OWNER |
I think dash-encoding (new name for this) is the right way forward here. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045108611 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045108611 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-SxeD | simonw 9599 | 2022-02-18T20:02:19Z | 2022-02-18T20:08:34Z | OWNER | One other potential variant: ```python def dash_encode(s): return s.replace("-", "-dash-").replace(".", "-dot-").replace("/", "-slash-") def dash_decode(s):
return s.replace("-slash-", "/").replace("-dot-", ".").replace("-dash-", "-")
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045111309 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045111309 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-SyIN | simonw 9599 | 2022-02-18T20:04:24Z | 2022-02-18T20:05:40Z | OWNER | This made me worry that my current
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045117304 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045117304 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-Szl4 | simonw 9599 | 2022-02-18T20:09:22Z | 2022-02-18T20:09:22Z | OWNER | Adopting this could result in supporting database files with surprising characters in their filename too. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045131086 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045131086 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-S29O | simonw 9599 | 2022-02-18T20:22:13Z | 2022-02-18T20:22:47Z | OWNER | Should it encode Is it worth expanding dash-encoding outside of just |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045134050 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045134050 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-S3ri | simonw 9599 | 2022-02-18T20:25:04Z | 2022-02-18T20:25:04Z | OWNER | Here's a useful modern spec for how existing URL percentage encoding is supposed to work: https://url.spec.whatwg.org/#percent-encoded-bytes |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 | |
| 1045269544 | https://github.com/simonw/datasette/issues/1439#issuecomment-1045269544 | https://api.github.com/repos/simonw/datasette/issues/1439 | IC_kwDOBm6k_c4-TYwo | simonw 9599 | 2022-02-18T22:19:29Z | 2022-02-18T22:19:29Z | OWNER | Note that I've ruled out using |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rethink how .ext formats (v.s. ?_format=) works before 1.0 973139047 |




Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issue_comments] (
[html_url] TEXT,
[issue_url] TEXT,
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[created_at] TEXT,
[updated_at] TEXT,
[author_association] TEXT,
[body] TEXT,
[reactions] TEXT,
[issue] INTEGER REFERENCES [issues]([id])
, [performed_via_github_app] TEXT);
CREATE INDEX [idx_issue_comments_issue]
ON [issue_comments] ([issue]);
CREATE INDEX [idx_issue_comments_user]
ON [issue_comments] ([user]);
user 1