from pluggy import HookimplMarker
ModuleNotFoundError: No module named 'pluggy'
```
Looks like I've run into point 6 on https://packaging.python.org/guides/single-sourcing-package-version/ :
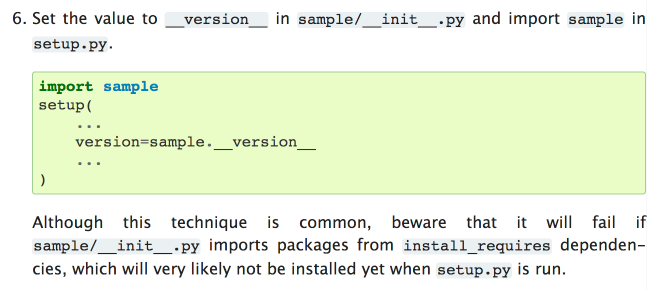
",17608,
381455054,"I think Vega-Lite is the way to go here: https://vega.github.io/vega-lite/
I've been playing around with it and Datasette with some really positive initial results:
https://vega.github.io/editor/#/gist/vega-lite/simonw/89100ce80573d062d70f780d10e5e609/decada131575825875c0a076e418c661c2adb014/vice-shootings-gender-race-by-department.vl.json
https://vega.github.io/editor/#/gist/vega-lite/simonw/5f69fbe29380b0d5d95f31a385f49ee4/7087b64df03cf9dba44a5258a606f29182cb8619/trees-san-francisco.vl.json",17608,
381456434,"The easiest way to implement this in Python 2 would be `execfile(...)` - but that was removed in Python 3. According to https://stackoverflow.com/a/437857/6083 `2to3` replaces that with this, which ensures the filename is associated with the code for debugging purposes:
```
with open(""somefile.py"") as f:
code = compile(f.read(), ""somefile.py"", 'exec')
exec(code, global_vars, local_vars)
```
Implementing it this way would force this kind of plugin to be self-contained in a single file. I think that's OK: if you want a more complex plugin you can use the standard pluggy-powered setuptools mechanism to build it.",17608,
381462005,This needs unit tests. I also need to manually test the `datasette package` and `datesette publish` commands.,17608,
381478217,"Here's the result of running:
datasette publish now fivethirtyeight.db \
--plugins-dir=plugins/ --title=""FiveThirtyEight"" --branch=plugins-dir
https://datasette-phjtvzwwzl.now.sh/fivethirtyeight-2628db9?sql=select+convert_units%28100%2C+%27m%27%2C+%27ft%27%29
Where `plugins/pint_plugin.py` contains the following:
```
from datasette import hookimpl
import pint
ureg = pint.UnitRegistry()
@hookimpl
def prepare_connection(conn):
def convert_units(amount, from_, to_):
""select convert_units(100, 'm', 'ft');""
return (amount * ureg(from_)).to(to_).to_tuple()[0]
conn.create_function('convert_units', 3, convert_units)
```",17608,
381478253,"This worked as well:
datasette package fivethirtyeight.db \
--plugins-dir=plugins/ --title=""FiveThirtyEight"" --branch=plugins-dir
",17608,
381481990,Added unit tests in 33c6bcadb962457be6b0c7f369826b404e2bcef5,17608,
381482407,"Here's the result of running this:
datasette publish heroku fivethirtyeight.db \
--plugins-dir=plugins/ --title=""FiveThirtyEight"" --branch=plugins-dir
https://intense-river-24599.herokuapp.com/fivethirtyeight-2628db9?sql=select+convert_units%28100%2C+%27m%27%2C+%27ft%27%29",17608,
381483301,I think this is a good improvement. If you fix the tests I'll merge it.,17608,
381488049,"I think this is pretty hard. @coleifer has done some work in this direction, including https://github.com/coleifer/pysqlite3 which ports the standalone pysqlite module to Python 3. ",17608,
381490361,"Packaging JS and CSS in a pip installable wheel is fiddly but possible. http://peak.telecommunity.com/DevCenter/PythonEggs#accessing-package-resources
from pkg_resources import resource_string
foo_config = resource_string(__name__, 'foo.conf')",17608,
381491707,This looks like a good example: https://github.com/funkey/nyroglancer/commit/d4438ab42171360b2b8e9020f672846dd70c8d80,17608,
381602005,I don't think it should be too difficult... you can look at what @ghaering did with pysqlite (and similarly what I copied for pysqlite3). You would theoretically take an amalgamation build of Sqlite (all code in a single .c and .h file). The `AmalgamationLibSqliteBuilder` class detects the presence of this amalgamated source file and builds a statically-linked pysqlite.,17608,
381611738,I should check if it's possible to have two template registration function plugins in a single plugin module. If it isn't maybe I should use class plugins instead of module plugins.,17608,
381612585,`resource_stream` returns a file-like object which may be better for serving from Sanic.,17608,
381621338,"Annoyingly, the following only results in the last of the two `prepare_connection` hooks being registered:
```
from datasette import hookimpl
import pint
import random
ureg = pint.UnitRegistry()
@hookimpl
def prepare_connection(conn):
def convert_units(amount, from_, to_):
""select convert_units(100, 'm', 'ft');""
return (amount * ureg(from_)).to(to_).to_tuple()[0]
conn.create_function('convert_units', 3, convert_units)
@hookimpl
def prepare_connection(conn):
conn.create_function('random_integer', 2, random.randint)
```",17608,
381622793,"I think that's OK. The two plugins I've implemented so far (`prepare_connection` and `prepare_jinja2_environment`) both make sense if they can only be defined once-per-plugin. For the moment I'll assume I can define future hooks to work well with the same limitation.
The syntactic sugar idea in #220 can help here too.",17608,
381643173,"Yikes, definitely a bug.",17608,
381644355,"So there are two tricky problems to solve here:
* I need a way of encoding `null` into that `_next=` that is unambiguous from the string `None` or `null`. This means introducing some kind of escaping mechanism in those strings. I already use URL encoding as part of the construction of those components here, maybe that can help here?
* I need to figure out what the SQL should be for the ""next"" set of results if the previous value was null. Thankfully we use the primary key as a tie-breaker so this shouldn't be impossible.",17608,
381645274,"Relevant code:
https://github.com/simonw/datasette/blob/904f1c75a3c17671d25c53b91e177c249d14ab3b/datasette/app.py#L828-L832",17608,
381645973,"I could use `$null` as a magic value that means None. Since I'm applying `quote_plus()` to actual values, any legit strings that look like this will be encoded as `%24null`:
```
>>> urllib.parse.quote_plus('$null')
'%24null'
```",17608,
381648053,"I think the correct SQL is this: https://datasette-issue-189-demo-3.now.sh/salaries-7859114-7859114?sql=select+rowid%2C+*+from+%5B2017+Maryland+state+salaries%5D%0D%0Awhere+%28middle_initial+is+not+null+or+%28middle_initial+is+null+and+rowid+%3E+%3Ap0%29%29%0D%0Aorder+by+middle_initial+limit+101&p0=391
```
select rowid, * from [2017 Maryland state salaries]
where (middle_initial is not null or (middle_initial is null and rowid > :p0))
order by middle_initial limit 101
```
Though this will also need to be taken into account for #198 ",17608,
381649140,But what would that SQL look like for `_sort_desc`?,17608,
381649437,"Here's where that SQL gets constructed at the moment:
https://github.com/simonw/datasette/blob/10a34f995c70daa37a8a2aa02c3135a4b023a24c/datasette/app.py#L761-L771",17608,
381738137,"Tests now fixed, honest. The failing test on Travis looks like an intermittent sqlite failure which should resolve itself on a retry...",17608,
381763651,"Ah, I had no idea you could bind python functions into sqlite!
I think the primary purpose of this issue has been served now - I'm going to close this and create a new issue for the only bit of this that hasn't been touched yet, which is (optionally) exposing units in the JSON API.",17608,
381777108,This could also help workaround the current predicament that a single plugin can only define one prepare_connection hook.,17608,
381786522,"Weird... tests are failing in Travis, despite passing on my local machine. https://travis-ci.org/simonw/datasette/builds/367423706",17608,
381788051,Still failing. This is very odd.,17608,
381794744,I'm reverting this out of master until I can figure out why the tests are failing.,17608,
381798786,"Here's the test that's failing:
https://github.com/simonw/datasette/blob/59a3aa859c0e782aeda9a515b1b52c358e8458a2/tests/test_api.py#L437-L470
I got Travis to spit out the `fetched` and `expected` variables.
`expected` has 201 items in it and is identical to what I get on my local laptop.
`fetched` has 250 items in it, so it's clearly different from my local environment.
I've managed to replicate the bug in production! I created a test database like this:
python tests/fixtures.py sortable.db
Then deployed that database like so:
datasette publish now sortable.db \
--extra-options=""--page_size=50"" --branch=debug-travis-issue-216
And... if you click ""next"" on this page https://datasette-issue-216-pagination.now.sh/sortable-5679797/sortable?_sort_desc=sortable_with_nulls five times you get back 250 results, when you should only get back 201.",17608,
381799267,"The version that I deployed which exhibits the bug is running SQLite `3.8.7.1` - https://datasette-issue-216-pagination.now.sh/sortable-5679797?sql=select+sqlite_version%28%29
The version that I have running locally which does NOT exhibit the bug is running SQLite `3.23.0`",17608,
381799408,"... which is VERY surprising, because `3.23.0` only came out on 2nd April this year: https://www.sqlite.org/changes.html - I have no idea how I came to be running that version on my laptop.",17608,
381801302,"This is the SQL that returns differing results in production and on my laptop: https://datasette-issue-216-pagination.now.sh/sortable-5679797?sql=select+%2A+from+sortable+where+%28sortable_with_nulls+is+null+and+%28%28pk1+%3E+%3Ap0%29%0A++or%0A%28pk1+%3D+%3Ap0+and+pk2+%3E+%3Ap1%29%29%29+order+by+sortable_with_nulls+desc+limit+51&p0=b&p1=t
```
select * from sortable where (sortable_with_nulls is null and ((pk1 > :p0)
or
(pk1 = :p0 and pk2 > :p1))) order by sortable_with_nulls desc limit 51
```
I think that `order by sortable_with_nulls desc` bit is at fault - the primary keys should be included in that order by as well.
Sure enough, changing the query to this one returns the same results across both environments:
```
select * from sortable where (sortable_with_nulls is null and ((pk1 > :p0)
or
(pk1 = :p0 and pk2 > :p1))) order by sortable_with_nulls desc, pk1, pk2 limit 51
```",17608,
381803157,Fixed!,17608,
381809998,I just shipped Datasette 0.19 with where I'm at so far: https://github.com/simonw/datasette/releases/tag/0.19,17608,
381905593,"I've added another commit which puts classes a class on each `` by default with its column name, and I've also made the PK column bold.
Unfortunately the tests are still failing on 3.6, which is weird. I can't reproduce locally...",17608,
382038613,"I figured out the recipe for bundling static assets in a plugin: https://github.com/simonw/datasette-plugin-demos/commit/26c5548f4ab7c6cc6d398df17767950be50d0edf (and then `python3 setup.py bdist_wheel`)
Having done that, I ran `pip install ../datasette-plugin-demos/dist/datasette_plugin_demos-0.2-py3-none-any.whl` from my Datasette virtual environment and then did the following:
```
>>> import pkg_resources
>>> pkg_resources.resource_stream(
... 'datasette_plugin_demos', 'static/plugin.js'
... ).read()
b""alert('hello');\n""
>>> pkg_resources.resource_filename(
... 'datasette_plugin_demos', 'static/plugin.js'
... )
'..../venv/lib/python3.6/site-packages/datasette_plugin_demos/static/plugin.js'
>>> pkg_resources.resource_string(
... 'datasette_plugin_demos', 'static/plugin.js'
... )
b""alert('hello');\n""
```",17608,
382048582,"One possible option: let plugins bundle their own `static/` directory and then register themselves with Datasette, then have `/-/static-plugins/name-of-plugin/...` serve files from that directory.",17608,
382069980,"Even if we automatically serve ALL `static/` content from installed plugins, we'll still need them to register which files need to be linked to from `extra_css_urls` and `extra_js_urls`",17608,
382205189,"I managed to get a better error message out of that test. The server is returning this (but only on Python 3.6, not on Python 3.5 - and only in Travis, not in my local environment):
```{'error': 'interrupted', 'ok': False, 'status': 400, 'title': 'Invalid SQL'}```
https://travis-ci.org/simonw/datasette/jobs/367929134",17608,
382210976,"OK, aaf59db570ab7688af72c08bb5bc1edc145e3e07 should mean that the tests pass when I merge that.",17608,
382256729,I added a mechanism for plugins to serve static files and define custom CSS and JS URLs in #214 - see new documentation on http://datasette.readthedocs.io/en/latest/plugins.html#static-assets and http://datasette.readthedocs.io/en/latest/plugins.html#extra-css-urls,17608,
382408128,"Demo:
datasette publish now sortable.db --install datasette-plugin-demos --branch=master
Produced this deployment, with both the `random_integer()` function and the static file from https://github.com/simonw/datasette-plugin-demos/tree/0.2
https://datasette-issue-223.now.sh/-/static-plugins/datasette_plugin_demos/plugin.js
https://datasette-issue-223.now.sh/sortable-4bbaa6f?sql=select+random_integer%280%2C+10%29
",17608,
382409989,"Tested on Heroku as well.
datasette publish heroku sortable.db --install datasette-plugin-demos --branch=master
https://morning-tor-45944.herokuapp.com/-/static-plugins/datasette_plugin_demos/plugin.js
https://morning-tor-45944.herokuapp.com/sortable-4bbaa6f?sql=select+random_integer%280%2C+10%29",17608,
382413121,"And tested `datasette package` - this time exercising the ability to pass more than one `--install` option:
```
$ datasette package sortable.db --branch=master --install requests --install datasette-plugin-demos
Sending build context to Docker daemon 125.4kB
Step 1/7 : FROM python:3
---> 79e1dc9af1c1
Step 2/7 : COPY . /app
---> 6e8e40bce378
Step 3/7 : WORKDIR /app
Removing intermediate container 7cdc9ab20d09
---> f42258c2211f
Step 4/7 : RUN pip install https://github.com/simonw/datasette/archive/master.zip requests datasette-plugin-demos
---> Running in a0f17cec08a4
Collecting ...
Removing intermediate container a0f17cec08a4
---> beea84e73271
Step 5/7 : RUN datasette inspect sortable.db --inspect-file inspect-data.json
---> Running in 4daa28792348
Removing intermediate container 4daa28792348
---> c60312d21b99
Step 6/7 : EXPOSE 8001
---> Running in fa728468482d
Removing intermediate container fa728468482d
---> 8f219a61fddc
Step 7/7 : CMD [""datasette"", ""serve"", ""--host"", ""0.0.0.0"", ""sortable.db"", ""--cors"", ""--port"", ""8001"", ""--inspect-file"", ""inspect-data.json""]
---> Running in cd4eaeb2ce9e
Removing intermediate container cd4eaeb2ce9e
---> 066e257c7c44
Successfully built 066e257c7c44
(venv) datasette $ docker run -p 8081:8001 066e257c7c44
Serve! files=('sortable.db',) on port 8001
[2018-04-18 14:40:18 +0000] [1] [INFO] Goin' Fast @ http://0.0.0.0:8001
[2018-04-18 14:40:18 +0000] [1] [INFO] Starting worker [1]
[2018-04-18 14:46:01 +0000] - (sanic.access)[INFO][1:7]: GET http://localhost:8081/-/static-plugins/datasette_plugin_demos/plugin.js 200 16
``` ",17608,
382616527,"No need to use `PackageLoader` after all, we can use the same mechanism we used for the static path:
https://github.com/simonw/datasette/blob/b55809a1e20986bb2e638b698815a77902e8708d/datasette/utils.py#L694-L695",17608,
382808266,"Maybe this should have a second argument indicating which codepath was being handled. That way plugins could say ""only inject this extra context variable on the row page"".",17608,
382924910,"Hiding tables with the `idx_` prefix should be good enough here, since false positives aren't very harmful.",17608,
382958693,"A better way to do this would be with many different plugin hooks, one for each view.",17608,
382959857,"Plus a generic prepare_context() hook called in the common render method.
prepare_context_table(), prepare_context_row() etc
Arguments are context, request, self (hence can access self.ds)
",17608,
382964794,"What if the context needs to make await calls?
One possible option: plugins can either manipulate the context in place OR they can return an awaitable. If they do that, the caller will await it.",17608,
382966604,Should this differentiate between preparing the data to be sent back as JSON and preparing the context for the template?,17608,
382967238,Maybe prepare_table_data() vs prepare_table_context(),17608,
383109984,Refs #229,17608,
383139889,"I released everything we have so far in [Datasette 0.20](https://github.com/simonw/datasette/releases/tag/0.20) and built and released an example plugin, [datasette-cluster-map](https://pypi.org/project/datasette-cluster-map/). Here's my blog entry about it: https://simonwillison.net/2018/Apr/20/datasette-plugins/",17608,
383140111,Here's a link demonstrating my new plugin: https://datasette-cluster-map-demo.now.sh/polar-bears-455fe3a/USGS_WC_eartags_output_files_2009-2011-Status,17608,
383252624,Thanks!,17608,
383315348,"I could also have an `""autodetect"": false` option for that plugin to turn off autodetecting entirely.
Would be useful if the plugin didn't append its JavaScript in pages that it wasn't used for - that might require making the `extra_js_urls()` hook optionally aware of the columns and table and metadata.",17608,
383398182,"```{
""databases"": {
""database1"": {
""tables"": {
""example_table"": {
""label_column"": ""name""
}
}
}
}
}
```",17608,
383399762,Docs here: http://datasette.readthedocs.io/en/latest/metadata.html#specifying-the-label-column-for-a-table,17608,
383410146,"I built this wrong: my implementation is looking for the `label_column` on the table-being-displayed, but it should be looking for it on the table-the-foreign-key-links-to.",17608,
383727973,"There might also be something clever we can do here with PRAGMA statements: https://stackoverflow.com/questions/14146881/limit-the-maximum-amount-of-memory-sqlite3-uses
And https://www.sqlite.org/pragma.html",17608,
383764533,The `resource` module in he standard library has the ability to set limits on memory usage for the current process: https://pymotw.com/2/resource/,17608,
384362028,"On further thought: this is actually only an issue for immutable deployments to platforms like Zeit Now and Heroku.
As such, adding it to `datasette serve` feels clumsy. Maybe `datasette publish` should instead gain the ability to optionally install an extra mechanism that periodically pulls a fresh copy of `metadata.json` from a URL.",17608,
384500327,"```
{
""databases"": {
""database1"": {
""tables"": {
""example_table"": {
""hidden"": true
}
}
}
}
}
```",17608,
384503873,Documentation: http://datasette.readthedocs.io/en/latest/metadata.html#hiding-tables,17608,
384512192,Documentation: http://datasette.readthedocs.io/en/latest/json_api.html#special-table-arguments,17608,
384675792,"Docs now live at http://datasette.readthedocs.io/
I still need to document a few more parts of the API before closing this.",17608,
384676488,Remaining work for this is tracked in #150,17608,
384678319,"I shipped this last week as the first plugin: https://simonwillison.net/2018/Apr/20/datasette-plugins/
Demo: https://datasette-cluster-map-demo.datasettes.com/polar-bears-455fe3a/USGS_WC_eartags_output_files_2009-2011-Status
Plugin: https://github.com/simonw/datasette-cluster-map",17608,
386309928,Demo: https://datasette-versions-and-shape-demo.now.sh/-/versions,17608,
386310149,"Demos:
* https://datasette-versions-and-shape-demo.now.sh/sf-trees-02c8ef1/qSpecies.json?_shape=array
* https://datasette-versions-and-shape-demo.now.sh/sf-trees-02c8ef1/qSpecies.json?_shape=object
* https://datasette-versions-and-shape-demo.now.sh/sf-trees-02c8ef1/qSpecies.json?_shape=arrays
* https://datasette-versions-and-shape-demo.now.sh/sf-trees-02c8ef1/qSpecies.json?_shape=objects",17608,
386357645,"Even better: use `plugin_manager.list_plugin_distinfo()` from pluggy to get back a list of tuples, the second item in each tuple is a `pkg_resources.DistInfoDistribution` with a `.version` attribute.",17608,
386692333,Demo: https://datasette-plugins-and-max-size-demo.now.sh/-/plugins,17608,
386692534,Demo: https://datasette-plugins-and-max-size-demo.now.sh/sf-trees/Street_Tree_List.json?_size=max,17608,
386840307,Documented here: http://datasette.readthedocs.io/en/latest/json_api.html#special-table-arguments,17608,
386840806,"Demo:
datasette publish now ../datasettes/san-francisco/sf-film-locations.db --branch=master --name datasette-column-search-demo
https://datasette-column-search-demo.now.sh/sf-film-locations/Film_Locations_in_San_Francisco?_search_Locations=justin",17608,
386879509,"We can solve this using the `sqlite_timelimit(conn, 20)` helper, which can tell SQLite to give up after 20ms. We can wrap that around the following SQL:
select distinct COLUMN from TABLE limit 21;
Then we look at the number of rows returned. If it's 21 or more we know that this table had more than 21 distinct values, so we'll treat it as ""unlimited"". Likewise, if the SQL times out before 20ms is up we will skip this introspection.",17608,
386879840,"Here's a quick demo of that exploration: https://datasette-distinct-column-values.now.sh/-/inspect
Example output:
```
{
""antiquities-act/actions_under_antiquities_act"": {
""columns"": [
""current_name"",
""states"",
""original_name"",
""current_agency"",
""action"",
""date"",
""year"",
""pres_or_congress"",
""acres_affected""
],
""count"": 344,
""distinct_values_by_column"": {
""acres_affected"": null,
""action"": null,
""current_agency"": [
""NPS"",
""State of Montana"",
""BLM"",
""State of Arizona"",
""USFS"",
""State of North Dakota"",
""NPS, BLM"",
""State of South Carolina"",
""State of New York"",
""FWS"",
""FWS, NOAA"",
""NPS, FWS"",
""NOAA"",
""BLM, USFS"",
""NOAA, FWS""
],
""current_name"": null,
""date"": null,
""original_name"": null,
""pres_or_congress"": null,
""states"": null,
""year"": null
},
""foreign_keys"": {
""incoming"": [],
""outgoing"": []
},
""fts_table"": null,
""hidden"": false,
""label_column"": null,
""name"": ""antiquities-act/actions_under_antiquities_act"",
""primary_keys"": []
}
}
```",17608,
386879878,If I'm going to expand column introspection in this way it would be useful to also capture column type information.,17608,
388360255,"Do you have an example I can look at?
I think I have a possible route for fixing this, but it's pretty tricky (it involves adding a full SQL statement parser, but that's needed for some other potential improvements as well).
In the meantime, is this causing actual errors for you or is it more of an inconvenience (form fields being displayed that don't actually do anything)?
Another potential solution here could be to allow canned queries to optionally declare their parameters in metadata.json",17608,
388367027,"An example deployment @ https://datasette-zkcvlwdrhl.now.sh/simplestreams-270f20c/cloudimage?content_id__exact=com.ubuntu.cloud%3Areleased%3Adownload
It is not causing errors, more of an inconvenience. I have worked around it using a `like` query instead. ",17608,
388497467,"Got it, this seems to trigger the problem: https://datasette-zkcvlwdrhl.now.sh/simplestreams-270f20c?sql=select+*+from+cloudimage+where+%22content_id%22+%3D+%22com.ubuntu.cloud%3Areleased%3Adownload%22+order+by+id+limit+10",17608,
388525357,Facet counts will be generated by extra SQL queries with their own aggressive time limit.,17608,
388550742,http://datasette.readthedocs.io/en/latest/full_text_search.html,17608,
388587855,Adding some TODOs to the original description (so they show up as a todo progress bar),17608,
388588011,Initial documentation: http://datasette.readthedocs.io/en/latest/facets.html,17608,
388588998,"A few demos:
* https://datasette-facets-demo.now.sh/fivethirtyeight-2628db9/college-majors%2Fall-ages?_facet=Major_category
* https://datasette-facets-demo.now.sh/fivethirtyeight-2628db9/congress-age%2Fcongress-terms?_facet=chamber&_facet=state&_facet=party&_facet=incumbent
* https://datasette-facets-demo.now.sh/fivethirtyeight-2628db9/bechdel%2Fmovies?_facet=binary&_facet=test",17608,
388589072,"I need to decide how to display these. They currently look like this:
https://datasette-facets-demo.now.sh/fivethirtyeight-2628db9/congress-age%2Fcongress-terms?_facet=chamber&_facet=state&_facet=party&_facet=incumbent&state=MO

",17608,
388625703,"I'm still seeing intermittent Python 3.5 failures due to dictionary ordering differences.
https://travis-ci.org/simonw/datasette/jobs/378356802
```
> assert expected_facet_results == facet_results
E AssertionError: assert {'city': [{'c...alue': 'MI'}]} == {'city': [{'co...alue': 'MI'}]}
E Omitting 1 identical items, use -vv to show
E Differing items:
E {'city': [{'count': 4, 'toggle_url': '_facet=state&_facet=city&state=MI&city=Detroit', 'value': 'Detroit'}]} != {'city': [{'count': 4, 'toggle_url': 'state=MI&_facet=state&_facet=city&city=Detroit', 'value': 'Detroit'}]}
E Use -v to get the full diff
```
To solve these cleanly I need to be able to run Python 3.5 on my local laptop rather than relying on Travis every time.",17608,
388626721,"I managed to get Python 3.5.0 running on my laptop using [pyenv](https://github.com/pyenv/pyenv). Here's the incantation I used:
```
# Install pyenv using homebrew (turns out I already had it)
brew install pyenv
# Check which versions of Python I have installed
pyenv versions
# Install Python 3.5.0
pyenv install 3.5.0
# Figure out where pyenv has been installing things
pyenv root
# Check I can run my newly installed Python 3.5.0
/Users/simonw/.pyenv/versions/3.5.0/bin/python
# Use it to create a new virtualenv
/Users/simonw/.pyenv/versions/3.5.0/bin/python -mvenv venv35
source venv35/bin/activate
# Install datasette into that virtualenv
python setup.py install
```",17608,
388626804,"Unfortunately, running `python setup.py test` on my laptop using Python 3.5.0 in that virtualenv results in a flow of weird Sanic-related errors:
```
File ""/Users/simonw/Dropbox/Development/datasette/venv35/lib/python3.5/site-packages/sanic-0.7.0-py3.5.egg/sanic/testing.py"", line 16, in _local_request
import aiohttp
File ""/Users/simonw/Dropbox/Development/datasette/.eggs/aiohttp-2.3.2-py3.5-macosx-10.13-x86_64.egg/aiohttp/__init__.py"", line 6, in
from .client import * # noqa
File ""/Users/simonw/Dropbox/Development/datasette/.eggs/aiohttp-2.3.2-py3.5-macosx-10.13-x86_64.egg/aiohttp/client.py"", line 13, in
from yarl import URL
File ""/Users/simonw/Dropbox/Development/datasette/.eggs/yarl-1.2.4-py3.5-macosx-10.13-x86_64.egg/yarl/__init__.py"", line 11, in
from .quoting import _Quoter, _Unquoter
File ""/Users/simonw/Dropbox/Development/datasette/.eggs/yarl-1.2.4-py3.5-macosx-10.13-x86_64.egg/yarl/quoting.py"", line 3, in
from typing import Optional, TYPE_CHECKING, cast
ImportError: cannot import name 'TYPE_CHECKING'
```",17608,
388627281,"https://github.com/rtfd/readthedocs.org/issues/3812#issuecomment-373780860 suggests Python 3.5.2 may have the fix.
Yup, that worked:
```
pyenv install 3.5.2
rm -rf venv35
/Users/simonw/.pyenv/versions/3.5.2/bin/python -mvenv venv35
source venv35/bin/activate
# Not sure why I need this in my local environment but I do:
pip install datasette_plugin_demos
python setup.py test
```
This is now giving me the same test failure locally that I am seeing in Travis.",17608,
388628966,"Running specific tests:
```
venv35/bin/pip install pytest beautifulsoup4 aiohttp
venv35/bin/pytest tests/test_utils.py
```",17608,
388645828,I may be able to run the SQL for all of the facet counts in one go using a WITH CTE query - will have to microbenchmark this to make sure it is worthwhile: https://datasette-facets-demo.now.sh/fivethirtyeight-2628db9?sql=with+blah+as+%28select+*+from+%5Bcollege-majors%2Fall-ages%5D%29%0D%0Aselect+*+from+%28select+%22Major_category%22%2C+Major_category%2C+count%28*%29+as+n+from%0D%0Ablah+group+by+Major_category+order+by+n+desc+limit+10%29%0D%0Aunion+all%0D%0Aselect+*+from+%28select+%22Major_category2%22%2C+Major_category%2C+count%28*%29+as+n+from%0D%0Ablah+group+by+Major_category+order+by+n+desc+limit+10%29,17608,
388684356,"I just landed pull request #257 - I haven't refactored the tests, I may do that later if it looks worthwhile.",17608,
388686463,It would be neat if there was a mechanism for calculating aggregates per facet - e.g. calculating the sum() of specific columns against each facet result on https://datasette-facets-demo.now.sh/fivethirtyeight-2628db9/nba-elo%2Fnbaallelo?_facet=lg_id&_facet=fran_id&lg_id=ABA&_facet=team_id,17608,
388784063,"Can I get facets working across many2many relationships?
This would be fiendishly useful, but the querystring and `metadata.json` syntax is non-obvious.",17608,
388784787,"To decide which facets to suggest: for each column, is the unique value count less than the number of rows matching the current query or is it less than 20 (if we are showing more than 20 rows)?
Maybe only do this if there are less than ten non-float columns. Or always try for foreign keys and booleans, then if there are none of those try indexed text and integer fields, then finally try non-indexed text and integer fields but only if there are less than ten.",17608,
388797919,"For M2M to work we will need a mechanism for applying IN queries to the table view, so you can select multiple M2M filters. Maybe this would work:
?_m2m_category=123&_m2m_category=865",17608,
388987044,This work is now happening in the facets branch. Closing this in favor of #255.,17608,
389145872,Activity has now moved to this branch: https://github.com/simonw/datasette/commits/suggested-facets,17608,
389147608,"New demo (published with `datasette publish now --branch=suggested-facets fivethirtyeight.db sf-trees.db --name=datastte-suggested-facets-demo`): https://datasette-suggested-facets-demo.now.sh/fivethirtyeight-2628db9/comic-characters%2Fmarvel-wikia-data
After turning on a couple of suggested facets... https://datasette-suggested-facets-demo.now.sh/fivethirtyeight-2628db9/comic-characters%2Fmarvel-wikia-data?_facet=SEX&_facet=ID

",17608,
389386142,"The URL does persist across deployments already, in that you can use the URL without the hash and it will redirect to the current location. Here's an example of that: https://san-francisco.datasettes.com/sf-trees/Street_Tree_List.json
This also works if you attempt to hit the incorrect hash, e.g. if you have deployed a new version of the database with an updated hash. The old hash will redirect, e.g. https://san-francisco.datasettes.com/sf-trees-c4b972c/Street_Tree_List.json
If you serve Datasette from a HTTP/2 proxy (I've been using Cloudflare for this) you won't even have to pay the cost of the redirect - Datasette sends a `Link: ; rel=preload` header with those redirects, which causes Cloudflare to push out the redirected source as part of that HTTP/2 request. You can fire up the Chrome DevTools to watch this happen.
https://github.com/simonw/datasette/blob/2b79f2bdeb1efa86e0756e741292d625f91cb93d/datasette/views/base.py#L91
All of that said... I'm not at all opposed to this feature. For consistency with other Datasette options (e.g. `--cors`) I'd prefer to do this as an optional argument to the `datasette serve` command - something like this:
datasette serve mydb.db --no-url-hash",17608,
389386919,"I updated that demo to demonstrate the new foreign key label expansions: https://datasette-suggested-facets-demo.now.sh/sf-trees-02c8ef1/Street_Tree_List?_facet=qLegalStatus

",17608,
389397457,Maybe `suggested_facets` should only be calculated for the HTML view.,17608,
389536870,"The principle benefit provided by the hash URLs is that Datasette can set a far-future cache expiry header on every response. This is particularly useful for JavaScript API work as it makes fantastic use of the browser's cache. It also means that if you are serving your API from behind a caching proxy like Cloudflare you get a fantastic cache hit rate.
An option to serve without persistent hashes would also need to turn off the cache headers.
Maybe the option should support both? If you hit a page with the hash in the URL you still get the cache headers, but hits to the URL without the hash serve uncashed content directly.",17608,
389546040,"Latest demo - now with multiple columns: https://datasette-suggested-facets-demo.now.sh/sf-trees-02c8ef1/Street_Tree_List?_facet=qCaretaker&_facet=qCareAssistant&_facet=qLegalStatus

",17608,
389562708,"This is now landed in master, ready for the next release.",17608,
389563719,The underlying mechanics for the `_extras` mechanism described in #262 may help with this.,17608,
389566147,"An official demo instance of Datasette dedicated to this use-case would be useful, especially if it was automatically deployed by Travis for every commit to master that passes the tests.
Maybe there should be a permanent version of it deployed for each released version too?",17608,
389570841,"At the most basic level, this will work based on an extension. Most places you currently put a `.json` extension should also allow a `.csv` extension.
By default this will return the exact results you see on the current page (default max will remain 1000).
## Streaming all records
Where things get interested is *streaming mode*. This will be an option which returns ALL matching records as a streaming CSV file, even if that ends up being millions of records.
I think the best way to build this will be on top of the existing mechanism used to efficiently implement keyset pagination via `_next=` tokens.
## Expanding foreign keys
For tables with foreign key references it would be useful if the CSV format could expand those references to include the labels from `label_column` - maybe via an additional `?_expand=1` option.
When expanding each foreign key column will be shown twice:
rowid,city_id,city_id_label,state",17608,
389572201,"This will likely be implemented in the `BaseView` class, which needs to know how to spot the `.csv` extension, call the underlying JSON generating function and then return the `columns` and `rows` as correctly formatted CSV.
https://github.com/simonw/datasette/blob/9959a9e4deec8e3e178f919e8b494214d5faa7fd/datasette/views/base.py#L201-L207
This means it will take ALL arguments that are available to the `.json` view. It may ignore some (e.g. `_facet=` makes no sense since CSV tables don't have space to show the facet results).
In streaming mode, things will behave a little bit differently - in particular, if `_stream=1` then `_next=` will be forbidden.
It can't include a length header because we don't know how many bytes it will be
CSV output will throw an error if the endpoint doesn't have rows and columns keys eg `/-/inspect.json`
So the implementation...
- looks for the `.csv` extension
- internally fetches the `.json` data instead
- If no `_stream` it just transposes that JSON to CSV with the correct content type header
- If `_stream=1` - checks for `_next=` and throws an error if it was provided
- Otherwise... fetch first page and emit CSV header and first set of rows
- Then start async looping, emitting more CSV rows and following the `_next=` internal reference until done
I like that this takes advantage of efficient pagination. It may not work so well for views which use offset/limit though.
It won't work at all for custom SQL because custom SQL doesn't support _next= pagination. That's fine.
For views... easiest fix is to cut off after first X000 records. That seems OK. View JSON would need to include a property that the mechanism can identify.",17608,
389579363,I started a thread on Twitter discussing various CSV output dialects: https://twitter.com/simonw/status/996783395504979968 - I want to pick defaults which will work as well as possible for whatever tools people might be using to consume the data.,17608,
389579762,"> I basically want someone to tell me which arguments I can pass to Python's csv.writer() function that will result in the least complaints from people who try to parse the results :)
https://twitter.com/simonw/status/996786815938977792",17608,
389592566,Let's provide a CSV Dialect definition too: https://frictionlessdata.io/specs/csv-dialect/ - via https://twitter.com/drewdaraabrams/status/996794915680997382,17608,
389608473,"There are some code examples in this issue which should help with the streaming part: https://github.com/channelcat/sanic/issues/1067
Also https://github.com/channelcat/sanic/blob/master/docs/sanic/streaming.md#response-streaming",17608,
389626715,"> I’d recommend using the Windows-1252 encoding for maximum compatibility, unless you have any characters not in that set, in which case use UTF8 with a byte order mark. Bit of a pain, but some progams (eg various versions of Excel) don’t read UTF8.
**frankieroberto** https://twitter.com/frankieroberto/status/996823071947460616
> There is software that consumes CSV and doesn't speak UTF8!? Huh. Well I can't just use Windows-1252 because I need to support the full UTF8 range of potential data - maybe I should support an optional ?_encoding=windows-1252 argument
**simonw** https://twitter.com/simonw/status/996824677245857793",17608,
389702480,Idea: `?_extra=sqllog` could output a lot of every individual SQL statement that was executed in order to generate the page - useful for seeing how foreign key expansion and faceting actually works.,17608,
389893810,Idea: add a `supports_csv = False` property to `BaseView` and over-ride it to `True` just on the view classes that should support CSV (Table and Row). Slight subtlety: the `DatabaseView` class only supports CSV in the `custom_sql()` path. Maybe that needs to be refactored a bit.,17608,
389894382,"I should definitely sanity check if the `_next=` route really is the most efficient way to build this. It may turn out that iterating over a SQLite cursor with a million rows in it is super-efficient and would provide much more reliable performance (plus solve the problem for retrieving full custom SQL queries where we can't do keyset pagination).
Problem here is that we run SQL queries in a thread pool. A query that returns millions of rows would presumably tie up a SQL thread until it has finished, which could block the server. This may be a reason to stick with `_next=` keyset pagination - since it ensures each SQL thread yields back again after each 1,000 rows.",17608,
389989015,"This is a departure from how Datasette has been designed so far, and it may turn out that it's not feasible or it requires too many philosophical changes to be worthwhile.
If we CAN do it though it would mean Datasette could stay running pointed at a directory on disk and new SQLite databases could be dropped into that directory by another process and served directly as they become available.",17608,
389989615,"From https://www.sqlite.org/c3ref/open.html
> **immutable**: The immutable parameter is a boolean query parameter that indicates that the database file is stored on read-only media. When immutable is set, SQLite assumes that the database file cannot be changed, even by a process with higher privilege, and so the database is opened read-only and all locking and change detection is disabled. Caution: Setting the immutable property on a database file that does in fact change can result in incorrect query results and/or SQLITE_CORRUPT errors. See also: SQLITE_IOCAP_IMMUTABLE.
So this would probably have to be a new mode, `datasette serve --detect-db-changes`, which no longer opens in immutable mode. Or maybe current behavior becomes not-the-default and you opt into it with `datasette serve --immutable`",17608,
390105147,I'm going to add a `/-/limits` page that shows the current limits.,17608,
390105943,Docs: http://datasette.readthedocs.io/en/latest/limits.html#default-facet-size,17608,
390250253,"Shouldn't [versioneer](https://github.com/warner/python-versioneer) do that?
E.g. 0.21+2.g1076c97
You'd need to install via `pip install git+https://github.com/simow/datasette.git` though, this does a temp git clone.",17608,
390433040,Could also support these as optional environment variables - `DATASETTE_NAMEOFSETTING`,17608,
390496376,http://datasette.readthedocs.io/en/latest/config.html,17608,
390577711,"Excellent, I was not aware of the auto redirect to the new hash. My bad
This solves my use case.
I do agree that your suggested --no-url-hash approach is much neater. I will investigate ",17608,
390689406,"I've changed my mind about the way to support external connectors aside of SQLite and I'm working in a more simple style that respects the original Datasette, i.e. less refactoring. I present you [a version of Datasette wich supports other database connectors](https://github.com/jsancho-gpl/datasette/tree/external-connectors) and [a Datasette connector for HDF5/PyTables files](https://github.com/jsancho-gpl/datasette-pytables).",17608,
390707183,"This is definitely a big improvement.
I'd like to refactor the unit tests that cover .inspect() too - currently they are a huge ugly blob at the top of test_api.py",17608,
390707760,"This probably needs to be in a plugin simply because getting Spatialite compiled and installed is a bit of a pain.
It's a great opportunity to expand the plugin hooks in useful ways though.",17608,
390795067,"Well, we do have the capability to detect spatialite so my intention certainly wasn't to require it.
I can see the advantage of having it as a plugin but it does touch a number of points in the code. I think I'm going to attack this by refactoring the necessary bits and seeing where that leads (which was my plan anyway).
I think my main concern is - if I add certain plugin hooks for this, is anything else ever going to use them? I'm not sure I have an answer to that question yet, either way.",17608,
390804333,"We should merge this before refactoring the tests though, because that way we don't couple the new tests to the verification of this change.",17608,
390991640,For SpatiaLite this example may be useful - though it's building 4.3.0 and not 4.4.0: https://github.com/terranodo/spatialite-docker/blob/master/Dockerfile,17608,
390993397,"Useful GitHub code search: https://github.com/search?utf8=✓&q=%22libspatialite-4.4.0%22+%22RC0%22&type=Code
",17608,
390993861,If we can't get `import sqlite3` to load the latest version but we can get `import pysqlite3` to work that's fine too - I can teach Datasette to import the best available version.,17608,
390999055,This shipped in Datasette 0.22. Here's my blog post about it: https://simonwillison.net/2018/May/20/datasette-facets/,17608,
391000659,"Right now the plugin stuff is early enough that I'd like to get as many potential plugin hooks as possible crafted out A much easier to judge if they should be added as actual hooks if we have a working branch prototype of them.
Some kind of mechanism for custom column display is already needed - eg there are columns where I want to say ""render this as markdown"" or ""URLify any links in this text"" - or even ""use this date format"" or ""add commas to this integer"".
You can do it with a custom template but a lower-level mechanism would be nicer. ",17608,
391003285,"That looks great. I don't think it's possible to derive the current commit version from the .zip downloaded directly from GitHub, so needing to pip install via git+https feels reasonable to me.",17608,
391011268,"I think I can do this almost entirely within my existing BaseView class structure.
First, decouple the async data() methods by teaching them to take a querystring object as an argument instead of a Sanic request object. The get() method can then send that new object instead of a request.
Next teach the base class how to obey the ASGI protocol.
I should be able to get support for both Sanic and uvicorn/daphne working in the same codebase, which will make it easy to compare their performance. ",17608,
391025841,"The other reason I mention plugins is that I have an idea to outlaw JavaScript entirely from Datasette core and instead encourage ALL JavaScript functionality to move into plugins.right now that just means CodeMirror. I may set up some of those plugins (like CodeMirror) as default dependencies so you get them from ""pip install datasette"".
I like the neatness of saying that core Datasette is a very simple JSON + HTML application, then encouraging people to go completely wild with JavaScript in the plugins.",17608,
391030083,See also #278,17608,
391050113,"Yup, I'll have a think about it. My current thoughts are for spatialite we'll need to hook into the following places:
* Inspection, so we can detect which columns are geometry columns. (We also currently ignore spatialite tables during inspection, it may be worth moving that to the plugin as well.)
* After data load, so we can convert WKB into the correct intermediate format for display. The alternative here is to alter the select SQL itself and get spatialite to do this conversion, but that strikes me as a bit more complex and possibly not as useful.
* HTML rendering.
* Querying?
The rendering and querying hooks could also potentially be used to move the units support into a plugin.",17608,
391055490,"This is fantastic!
I think I prefer the aesthetics of just ""0.22"" for the version string if it's a tagged release with no additional changes - does that work?
I'd like to continue to provide a tuple that can be imported from the version.py module as well, as seen here:
https://github.com/simonw/datasette/blob/558d9d7bfef3dd633eb16389281b67d42c9bdeef/datasette/version.py#L1
Presumably we can generate that from the versioneer string?
",17608,
391059008,"```python
>>> import sqlite3
>>> sqlite3.sqlite_version
'3.23.1'
>>>
```
running the above in the container seems to show 3.23.1 too so maybe we don't need pysqlite3 at all?",17608,
391073009,"> I think I prefer the aesthetics of just ""0.22"" for the version string if it's a tagged release with no additional changes - does that work?
Yes! That's the default versioneer behaviour.
> I'd like to continue to provide a tuple that can be imported from the version.py module as well, as seen here:
Should work now, it can be a two (for a tagged version), three or four items tuple.
```
In [2]: datasette.__version__
Out[2]: '0.12+292.ga70c2a8.dirty'
In [3]: datasette.__version_info__
Out[3]: ('0', '12+292', 'ga70c2a8', 'dirty')
```",17608,
391073267,"Sorry, just realised you rely on `version` being a module ...",17608,
391076239,This looks amazing! Can't wait to try this out this evening.,17608,
391076458,Yeah let's try this without pysqlite3 and see if we still get the correct version.,17608,
391077700,"Alright, that should work now -- let me know if you would prefer any different behaviour.",17608,
391141391,"I'm going to clean this up for consistency tomorrow morning so hold off
merging until then please
On Tue, May 22, 2018 at 6:34 PM, Simon Willison
wrote:
> Yeah let's try this without pysqlite3 and see if we still get the correct
> version.
>
> —
> You are receiving this because you authored the thread.
> Reply to this email directly, view it on GitHub
> , or mute
> the thread
>
> .
>
",17608,
391190497,"I grabbed just your Dockerfile and built it like this:
docker build . -t datasette
Once it had built, I ran it like this:
docker run -p 8001:8001 -v `pwd`:/mnt datasette \
datasette -p 8001 -h 0.0.0.0 /mnt/fixtures.db \
--load-extension=/usr/local/lib/mod_spatialite.so
(The fixtures.db file is created by running `python tests/fixtures.py fixtures.db`)
Then I visited http://localhost:8001/-/versions and I got this:
{
""datasette"": {
""version"": ""0+unknown""
},
""python"": {
""full"": ""3.6.3 (default, Dec 12 2017, 06:37:05) \n[GCC 6.3.0 20170516]"",
""version"": ""3.6.3""
},
""sqlite"": {
""extensions"": {
""json1"": null,
""spatialite"": ""4.4.0-RC0""
},
""fts_versions"": [
""FTS4"",
""FTS3""
],
""version"": ""3.23.1""
}
}
Fantastic! I'm getting SQLite `3.23.1` and SpatiaLite `4.4.0-RC0`",17608,
391290271,"Running:
```bash
docker run -p 8001:8001 -v `pwd`:/mnt datasette \
datasette -p 8001 -h 0.0.0.0 /mnt/fixtures.db \
--load-extension=/usr/local/lib/mod_spatialite.so
```
is now returning FTS5 enabled in the versions output:
```json
{
""datasette"": {
""version"": ""0.22""
},
""python"": {
""full"": ""3.6.5 (default, May 5 2018, 03:07:21) \n[GCC 6.3.0 20170516]"",
""version"": ""3.6.5""
},
""sqlite"": {
""extensions"": {
""json1"": null,
""spatialite"": ""4.4.0-RC0""
},
""fts_versions"": [
""FTS5"",
""FTS4"",
""FTS3""
],
""version"": ""3.23.1""
}
}
```
The old query didn't work because specifying `(t TEXT)` caused an error",17608,
391354237,@r4vi any objections to me merging this?,17608,
391355030,"No objections;
It's good to go @simonw
On Wed, 23 May 2018, 14:51 Simon Willison, wrote:
> @r4vi any objections to me merging this?
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> , or mute
> the thread
>
> .
>
",17608,
391355099,Confirmed fixed: https://fivethirtyeight-datasette-mipwbeadvr.now.sh/fivethirtyeight-5de27e3/nba-elo%2Fnbaallelo?_facet=lg_id&_next=100 ,17608,
391437199,Thank you very much! This is most excellent.,17608,
391437462,I'm afraid I just merged #280 which means this no longer applies. You're very welcome to see if you can further optimize the new Dockerfile though.,17608,
391504199,"I'm not keen on anything that modifies the SQLite file itself on startup - part of the datasette contract is that it should work with any SQLite file you throw at it without having any side-effects.
A neat thing about SQLite is that because everything happens in the same process there's very little additional overhead involved in executing extra SQL queries - even if we ran a query-per-row to transform data in one specific column it shouldn't add more than a few ms to the total page load time (whereas with MySQL all of the extra query overhead would kill us).",17608,
391504757,"That said, it looks like we may be able to use a library like https://github.com/geomet/geomet to run the conversion from WKB entirely in Python space.",17608,
391505930,"> I'm not keen on anything that modifies the SQLite file itself on startup
Ah I didn't mean that - I meant altering the SELECT query to fetch the data so that it ran a spatialite function to transform that specific column.
I think that's less useful as a general-purpose plugin hook though, and it's not that hard to parse the WKB in Python (my default approach would be to use [shapely](https://github.com/Toblerity/Shapely), which is great, but geomet looks like an interesting pure-python alternative).",17608,
391583528,"The challenge here is which database should be the ""default"" database. The first database attached to SQLite is treated as the default - if no database is specified in a query, that's the database that queries will be executed against.
Currently, each database URL in Datasette (e.g. https://san-francisco.datasettes.com/sf-film-locations-84594a7 v.s. https://san-francisco.datasettes.com/sf-trees-ebc2ad9 ) gets its own independent connection, and all queries within that base URL run against that database.
If we're going to attach multiple databases to the same connection, how do we set which database gets to be the default?
The easiest thing to do here will be to have a special database (maybe which is turned off by default and can be enabled using `datasette serve --enable-cross-database-joins` or similar) which attaches to ALL the databases. Perhaps it starts as an in-memory database, maybe at `/memory`?
",17608,
391584112,"I built a very rough prototype of this to prove it could work. It's deployed here - and here's an example of a query that joins across two different databases:
https://datasette-cross-database-joins-prototype.now.sh/memory?sql=select+fivethirtyeight.%5Blove-actually%2Flove_actually_adjacencies%5D.rowid%2C%0D%0Afivethirtyeight.%5Blove-actually%2Flove_actually_adjacencies%5D.actors%2C%0D%0A%5Bgoogle-trends%5D.%5B20150430_UKDebate%5D.city%0D%0Afrom+fivethirtyeight.%5Blove-actually%2Flove_actually_adjacencies%5D%0D%0Ajoin+%5Bgoogle-trends%5D.%5B20150430_UKDebate%5D%0D%0A++on+%5Bgoogle-trends%5D.%5B20150430_UKDebate%5D.rowid+%3D+fivethirtyeight.%5Blove-actually%2Flove_actually_adjacencies%5D.rowid
```
select fivethirtyeight.[love-actually/love_actually_adjacencies].rowid,
fivethirtyeight.[love-actually/love_actually_adjacencies].actors,
[google-trends].[20150430_UKDebate].city
from fivethirtyeight.[love-actually/love_actually_adjacencies]
join [google-trends].[20150430_UKDebate]
on [google-trends].[20150430_UKDebate].rowid = fivethirtyeight.[love-actually/love_actually_adjacencies].rowid
```
I deployed it like this:
datasette publish now --branch=cross-database-joins fivethirtyeight.db google-trends.db --name=datasette-cross-database-joins-prototype
",17608,
391584366,"I used some pretty ugly hacks, like faking an entire `.inspect()` block for the `:memory:` database just to get past the errors I was seeing. To ship this as a feature it will need quite a bit of code refactoring to make those hacks unnecessary.
https://github.com/simonw/datasette/blob/7a3040f5782375373b2b66e5969bc2c49b3a6f0e/datasette/views/database.py#L18-L26",17608,
391584527,Rather than stealing the `/memory` namespace for this it would be nicer if these cross-database joins could be executed at the very top-level URL of the Datasette instance - `https://example.com/?sql=...`,17608,
391752218,Most of the time Datasette is used with just a single database file. So maybe it makes sense for this option to be turned on by default and to ALWAYS be available on the Datasette instance homepage unless the user has explicitly disabled it.,17608,
391752425,"This would make Datasett's SQL features a lot more instantly obvious to people who land on a homepage, which is probably a good thing.",17608,
391752629,"Should this support canned queries too? I think it should, though that raises interesting questions regarding their URL structure.",17608,
391752882,Another option: give this the `/-/all` URL namespace.,17608,
391754506,"Giving it `/all/` would be easier since that way the existing URL routes (including canned queries) would all work... but I would have to teach it NOT to expect a database content hash on that URL.
Or maybe it should still have a content hash (to enable far-future cache expiry headers on query results) but the hash should be constructed out of all of the other database hashes concatenated together.
That way the URLs would be `/all-5de27e3` and `/all-5de27e3/canned-query-name`
Only downside: this would make it impossible to have a database file with the name `all.db`. I think that's probably an OK trade-off. You could turn the feature off with a config flag if you really want to use that filename (for whatever reason).
How about `/-all-5de27e3/` instead to avoid collisions?",17608,
391755300,On the `/-all-5de27e3` page we can show the regular https://fivethirtyeight.datasettes.com/fivethirtyeight-5de27e3 interface but instead of the list of tables we can show a list of attached databases plus some help text showing how to construct a cross-database join.,17608,
391756841,"For an example query that pre-populates that textarea... maybe a UNION that pulls the first 10 rows from the first table of each of the first two databases?
```
select * from (select rowid, actors from fivethirtyeight.[love-actually/love_actually_adjacencies] limit 10)
union all
select * from (select rowid, city from [google-trends].[20150430_UKDebate] limit 10)
```
https://datasette-cross-database-joins-prototype.now.sh/memory?sql=select+*+from+%28select+rowid%2C+actors+from+fivethirtyeight.%5Blove-actually%2Flove_actually_adjacencies%5D+limit+10%29%0D%0A+++union+all%0D%0Aselect+*+from+%28select+rowid%2C+city+from+%5Bgoogle-trends%5D.%5B20150430_UKDebate%5D+limit+10%29",17608,
391765706,I'm not crazy about the `enable_` prefix on these.,17608,
391765973,This will also give us a mechanism for turning on and off the cross-database joins feature from #283,17608,
391766420,"Maybe `allow_sql`, `allow_facet` and `allow_download`",17608,
391768302,I like `/-/all-5de27e3` for this (with `/-/all` redirecting to the correct hash),17608,
391771202,"So the lookup priority order should be:
* table level in metadata
* database level in metadata
* root level in metadata
* `--config` options passed to `datasette serve`
* `DATASETTE_X` environment variables",17608,
391771658,It feels slightly weird continuing to call it `metadata.json` as it starts to grow support for config options (which already started with the `units` and `facets` keys) but I can live with that.,17608,
391912392,`allow_sql` should only affect the `?sql=` parameter and whether or not the form is displayed. You should still be able to use and execute canned queries even if this option is turned off.,17608,
391950691,"Demo:
datasette publish now --branch=master fixtures.db \
--source=""#284 Demo"" \
--source_url=""https://github.com/simonw/datasette/issues/284"" \
--extra-options ""--config allow_sql:off --config allow_facet:off --config allow_download:off"" \
--name=datasette-demo-284
now alias https://datasette-demo-284-jogjwngegj.now.sh datasette-demo-284.now.sh
https://datasette-demo-284.now.sh/
Note the following:
* https://datasette-demo-284.now.sh/fixtures-fda0fea has no SQL input textarea
* https://datasette-demo-284.now.sh/fixtures-fda0fea has no database download link
* https://datasette-demo-284.now.sh/fixtures-fda0fea.db returns 403 forbidden
* https://datasette-demo-284.now.sh/fixtures-fda0fea?sql=select%20*%20from%20sqlite_master throws error 400
* https://datasette-demo-284.now.sh/fixtures-fda0fea/facetable shows no suggested facets
* https://datasette-demo-284.now.sh/fixtures-fda0fea/facetable?_facet=city_id throws error 400",17608,
392118755,"Thinking about this further, maybe I should embrace ASGI turtles-all-the-way-down and teach each datasette view class to take a scope to the constructor and act entirely as an ASGI component. Would be a nice way of diving deep into ASGI and I can add utility helpers for things like querystring evaluation as I need them.",17608,
392121500,"A few extra thoughts:
* Some users may want to opt out of this. We could have `--config version_in_hash:false`
* should this affect the filename for the downloadable copy of the SQLite database? Maybe that should stay as just the hash of the contents, but that's a fair bit more complex
* What about users who stick with the same version of datasette but deploy changes to their custom templates - how can we help them cache bust? Maybe with `--config cache_version:2`",17608,
392121743,This is also a great excuse to finally write up some detailed documentation on Datasette's caching strategy,17608,
392121905,See also #286,17608,
392212119,"This should detect any table which can be linked to the current table via some other table, based on the other table having a foreign key to them both.
These join tables could be arbitrarily complicated. They might have foreign keys to more than two other tables, maybe even multiple foreign keys to the same column.
Ideally M2M defection would catch all of these cases. Maybe the resulting inspect data looks something like this:
```
""artists"": {
...
""m2m"": [{
""other_table"": ""festivals"",
""through"": ""performances"",
""our_fk"": ""artist_id"",
""other_fk"": ""performance_id""
}]
```
Let's ignore compound primary keys: we k it detect m2m relationships where the join table has foreign keys to a single primary key on the other two tables.",17608,
392214791,"We may need to derive a usable name for each of these relationships that can be used in eg querystring parameters.
The name of the join table is a reasonable choice here. Say the join table is called `event_tags` - the querystring for returning all events that are tagged `badger` could be `/db/events?_m2m_event_tags__tag=badger` perhaps?
But what if `event_tags` has more than one foreign key back to `events`? Might need to specify the column in `events` that is referred back to by `event_tags` somehow in that case.",17608,
392279508,Related: I started the documentation for using SpatiaLite with Datasette here: https://datasette.readthedocs.io/en/latest/spatialite.html,17608,
392279644,"I've been thinking a bit about modifying the SQL select statement used for the table view recently. I've run into a few examples of SQLite database that slow to a crawl when viewed with datasette because the rows are too big, so there's definitely scope for supporting custom select clauses (avoiding some columns, showing length(colname) for others).",17608,
392288531,"This might also be an opportunity to support an __in= operator - though that's an odd one as it acts equivalent to an OR whereas every other parameter is combined with an AND
UPDATE 15th April 2019: I implemented `?column__in=` in a different way, see #433 ",17608,
392288990,An example of a query where you might want to use this option: https://fivethirtyeight.datasettes.com/fivethirtyeight-5de27e3?sql=select+rowid%2C+*+from+%5Balcohol-consumption%2Fdrinks%5D+order+by+random%28%29+limit+1,17608,
392291605,Documented here https://datasette.readthedocs.io/en/latest/json_api.html#special-table-arguments and here: https://datasette.readthedocs.io/en/latest/config.html#default-cache-ttl,17608,
392291716,Demo: hit refresh on https://fivethirtyeight.datasettes.com/fivethirtyeight-5de27e3?sql=select+rowid%2C+*+from+%5Balcohol-consumption%2Fdrinks%5D+order+by+random%28%29+limit+1&_ttl=0,17608,
392296758,Docs: https://datasette.readthedocs.io/en/latest/json_api.html#different-shapes,17608,
392297392,"I ran a very rough micro-benchmark on the new `num_sql_threads` config option.
datasette --config num_sql_threads:1 fivethirtyeight.db
Then
ab -n 100 -c 10 'http://127.0.0.1:8011/fivethirtyeight-2628db9/twitter-ratio%2Fsenators'
| Number of threads | Requests/second |
|---|---|
| 1 | 4.57 |
| 3 | 9.77 |
| 10 | 13.53 |
| 20 | 15.24
| 50 | 8.21 |
",17608,
392297508,Documentation: http://datasette.readthedocs.io/en/latest/config.html#num-sql-threads,17608,
392302406,"My first attempt at this was to have plugins depend on each other - so there would be a `datasette-leaflet` plugin which adds Leaflet to the page, and the `datasette-cluster-map` and `datasette-leaflet-geojson` plugins would depend on that plugin.
I tried this and it didn't work, because it turns out the order in which plugins are loaded isn't predictable. `datasette-cluster-map` ended up adding it's script link before Leaflet had been loaded by `datasette-leaflet`, resulting in JavaScript errors.",17608,
392302416,For the moment then I'm going with a really simple solution: when iterating through `extra_css_urls` and `extra_js_urls` de-dupe by URL and avoid outputting the same link twice.,17608,
392302456,The big gap in this solution is conflicting versions: I don't yet have a story for what happens if two plugins attempt to load different versions of Leaflet. ,17608,
392305776,These plugin config options should be exposed to JavaScript as `datasette.config.plugins`,17608,
392316250,It looks like we can use the `geometry_columns` table to introspect which columns are SpatiaLite geometries. It includes a `geometry_type` integer which is documented here: https://www.gaia-gis.it/fossil/libspatialite/wiki?name=switching-to-4.0,17608,
392316306,Relevant to this ticket: I've been playing with a plugin that automatically renders any GeoJSON cells as leaflet maps: https://github.com/simonw/datasette-leaflet-geojson,17608,
392316673,Open question: how should this affect the row page? Just because columns were hidden on the table page doesn't necessarily mean they should be hidden on the row page as well. ,17608,
392316701,I could certainly see people wanting different custom column selects for the row page compared to the table page.,17608,
392338130,"Here's my first sketch at a metadata format for this:
* `columns`: optional list of columns to include - if missing, shows all
* `column_selects`: dictionary mapping column names to alternative select clauses
`column_selects` can also invent new keys and use them to create derived columns. These new keys will be selected at the end of the list of columns UNLESS they are mentioned in `columns`, in which case that sequence will define the order.
Can you facet by things that are customized using `column_selects`? Yes, and let's try running suggested facets against those columns as well.
```
{
""databases"": {
""databasename"": {
""tables"": {
""tablename"": {
""columns"": [
""id"", ""name"", ""size""
],
""column_selects"": {
""name"": ""upper(name)"",
""geo_json"": ""AsGeoJSON(Geometry)""
}
""row_columns"": [...]
""row_column_selects"": {...}
}
```
The `row_columns` and `row_column_selects` properties work the same as the `column*` ones, except they are applied on the row page instead.
If omitted, the `column*` ones will be used on the row page as well.
If you want the row page to switch back to Datasette's default behaviour you can set `""row_columns"": [], ""row_column_selects"": {}`.",17608,
392342269,"Here's the metadata I tried against that first working prototype:
```
{
""databases"": {
""timezones"": {
""tables"": {
""timezones"": {
""columns"": [""PK_UID""],
""column_selects"": {
""upper_tzid"": ""upper(tzid)"",
""Geometry"": ""AsGeoJSON(Geometry)""
}
}
}
},
""wtr"": {
""tables"": {
""license_frequency"": {
""columns"": [""id"", ""license"", ""tx_rx"", ""frequency""],
""column_selects"": {
""latitude"": ""Y(Geometry)"",
""longitude"": ""X(Geometry)""
}
}
}
}
}
}
```
Run using this:
datasette timezones.db wtr.db \
--reload --debug --load-extension=/usr/local/lib/mod_spatialite.dylib \
-m column-metadata.json --config sql_time_limit_ms:10000
Usefully, the `--reload` flag detects changes to the `metadata.json` file as well as Datasette's own Python code.",17608,
392342947,I'd still like to be able to over-ride this using querystring arguments.,17608,
392343690,"Turns out it's actually possible to pull data from other tables using the mechanism in the prototype:
```
{
""databases"": {
""wtr"": {
""tables"": {
""license"": {
""column_selects"": {
""count"": ""(select count(*) from license_frequency where license_frequency.license = license.id)""
}
}
}
}
}
}
```
Performance using this technique is pretty terrible though:

",17608,
392343839,"The more efficient way of doing this kind of count would be to provide a mechanism which can also add extra fragments to a `GROUP BY` clause used for the `SELECT`.
Or... how about a mechanism similar to Django's `prefetch_related` which lets you define extra queries that will be called with a list of primary keys (or values from other columns) and used to populate a new column? A little unconventional but could be extremely useful and efficient.
Related to that: since the per-query overhead in SQLite is tiny, could even define an extra query to be run once-per-row before returning results.",17608,
392345062,There needs to be a way to turn this off and return to Datasette default bahviour. Maybe a `?_raw=1` querystring parameter for the table view.,17608,
392350495,"Querystring design:
* `?_column=a&_column=b` - equivalent of `""columns"": [""a"", ""b""]` in `metadata.json`
* `?_select_nameupper=upper(name)` - equivalent of `""column_selects"": {""nameupper"": ""upper(name)""}`",17608,
392350568,"If any `?_column=` parameters are provided the metadata version is completely ignored.
",17608,
392350980,"Should `?_raw=1` also turn off foreign key expansions? No, we will eventually provide a separate mechanism for that (or leave it to nerds who care to figure out using JSON or CSV export).",17608,
392568047,Closing this as obsolete since we have facets now.,17608,
392574208,"I'm handling this as separate documentation sections instead, e.g. http://datasette.readthedocs.io/en/latest/spatialite.html",17608,
392574358,Closing this as obsolete in favor of other issues [tagged documentation](https://github.com/simonw/datasette/labels/documentation).,17608,
392574415,I implemented this as `?_ttl=0` in #289 ,17608,
392575160,"I've changed my mind about this.
""Select every record on the 3rd day of the month"" doesn't strike me as an actually useful feature.
""Select every record in 2018 / in May 2018 / on 1st May 2018"", if you are using the SQLite-preferred datestring format, are already supported using LIKE queries (or the startswith filter):
* https://fivethirtyeight.datasettes.com/fivethirtyeight/inconvenient-sequel%2Fratings?timestamp__startswith=2017
* https://fivethirtyeight.datasettes.com/fivethirtyeight/inconvenient-sequel%2Fratings?timestamp__startswith=2017-08
* https://fivethirtyeight.datasettes.com/fivethirtyeight/inconvenient-sequel%2Fratings?timestamp__startswith=2017-08-29
",17608,
392575448,"This shouldn't be a comma-separated list, it should be an argument you can pass multiple times to better match #255 and #292
Maybe `?_json=foo&_json=bar`
",17608,
392580715,"Oops, that commit should have referenced #121 ",17608,
392580902,"Implemented in 76d11eb768e2f05f593c4d37a25280c0fcdf8fd6
Documented here: http://datasette.readthedocs.io/en/latest/json_api.html#special-json-arguments",17608,
392600866,"This is an accidental duplicate, work is now taking place in #266",17608,
392601114,I think the way Datasette executes SQL queries in a thread pool introduced in #45 is a good solution for this ticket.,17608,
392601478,I'm going to close this as WONTFIX for the moment. Once Plugins #14 grows the ability to add extra URL paths and views someone who needs this could build it as a plugin instead.,17608,
392602334,"The `/.json` endpoint is more of an implementation detail of the homepage at this point. A better, documented ( http://datasette.readthedocs.io/en/stable/introspection.html#inspect ) endpoint for finding all of the databases and tables is https://parlgov.datasettes.com/-/inspect.json",17608,
392602558,I'll have the error message display a link to the documentation.,17608,
392605574,"
",17608,
392606044,"The other major limitation of APSW is its treatment of unicode: https://rogerbinns.github.io/apsw/types.html - it tells you that it is your responsibility to ensure that TEXT columns in your SQLite database are correctly encoded.
Since Datasette is designed to work against ANY SQLite database that someone may have already created, I see that as a show-stopping limitation.
Thanks to https://github.com/coleifer/sqlite-vtfunc I now have a working mechanism for virtual tables (I've even built a demo plugin with them - https://github.com/simonw/datasette-sql-scraper ) which was the main thing that interested me about APSW.
I'm going to close this as WONTFIX - I think Python's built-in `sqlite3` is good enough, and is now so firmly embedded in the project that making it pluggable would be more trouble than it's worth.",17608,
392606418,"> It could also be useful to allow users to import a python file containing custom functions that can that be loaded into scope and made available to custom templates.
That's now covered by the plugins mechanism - you can create plugins that define custom template functions: http://datasette.readthedocs.io/en/stable/plugins.html#prepare-jinja2-environment-env",17608,
392815673,"I'm coming round to the idea that this should be baked into Datasette core - see above referenced issues for some of the explorations I've been doing around this area.
Datasette should absolutely work without SpatiaLite, but it's such a huge bonus part of the SQLite ecosystem that I'm happy to ship features that take advantage of it without being relegated to plugins.
I'm also becoming aware that there aren't really that many other interesting loadable extensions for SQLite. If SpatiaLite was one of dozens I'd feel that a rule that ""anything dependent on an extension lives in a plugin"" would make sense, but as it stands I think 99% of the time the only loadable extensions people will be using will be SpatiaLite and json1 (and json1 is available in the amalgamation anyway).
",17608,
392822050,"I don't know how it happened, but I've somehow got myself into a state where my local SQLite for Python 3 on OS X is `3.23.1`:
```
~ $ python3
Python 3.6.5 (default, Mar 30 2018, 06:41:53)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin
Type ""help"", ""copyright"", ""credits"" or ""license"" for more information.
>>> import sqlite3
>>> sqlite3.connect(':memory:').execute('select sqlite_version()').fetchall()
[('3.23.1',)]
>>>
```
Maybe I did something in homebrew that changed this? I'd love to understand what exactly I did to get to this state.",17608,
392825746,"I haven't had time to look further into this, but if doing this as a plugin results in useful hooks then I think we should do it that way. We could always require the plugin as a standard dependency.
I think this is going to result in quite a bit of refactoring anyway so it's a good time to add hooks regardless.
On the other hand, if we have to add lots of specialist hooks for it then maybe it's worth integrating into the core.",17608,
392828475,"Python standard-library SQLite dynamically links against the system sqlite3. So presumably you installed a more up-to-date sqlite3 somewhere on your `LD_LIBRARY_PATH`.
To compile a statically-linked pysqlite you need to include an amalgamation in the project root when building the extension. Read the relevant setup.py.",17608,
392831543,"I ran an informal survey on twitter and most people were on 3.21 - https://twitter.com/simonw/status/1001487546289815553
Maybe this is from upgrading to the latest OS X release.",17608,
392840811,"Since #275 will allow configs to be overridden at the table and database level it also makes sense to expose a completely evaluated list of configs at:
* `/dbname/-/config`
* `/dbname/tablename/-/config`
Similar to https://fivethirtyeight.datasettes.com/-/config",17608,
392890045,"Just about to ask for this! Move this page https://github.com/simonw/datasette/wiki/Datasettes
into a datasette, with some concept of versioning as well.",17608,
392895733,Do you have an existing example with views?,17608,
392917380,Creating URLs using concatenation as seen in `('https://twitter.com/' || user) as user_url` is likely to have all sorts of useful applications for ad-hoc analysis.,17608,
392918311,Should the `tablename` ones also work for views and canned queries? Probably not.,17608,
392969173,The more time I spend with SpatiaLite the more convinced I am that this should be default behavior. There's nothing useful about the binary Geometry representation - it's not even valid WKB. I'm on board with WKT as the default display in HTML and GeoJSON as the default for `.json`,17608,
393003340,Funny you should mention that... I'm planning on doing that as part of the official Datasette website at some point soon. A Datasette instance that lists other Datasette instances feels pleasingly appropriate.,17608,
393014943,I just realised a problem with GeoJSON is that it assumes that the underlying geometry is WGS 84 latitude/longitude points - but it's very possible for a SpatiaLite geometry to contain geometric data that's nothing to do with geospatial projections.,17608,
393020749,"Challenge: how to deal with tables where the name ends in `.csv`? I actually have one of these in the test suite at the moment:
https://github.com/simonw/datasette/blob/d69ebce53385b7c6fafb85fdab3b136dbf3f332c/tests/fixtures.py#L234-L237",17608,
393064224,"https://datasette-registry.now.sh Is now live, powered by https://github.com/simonw/datasette-registry - still needs plenty of work but it's an interesting start.",17608,
393106520,"I don't think it's unreasonable to only support spatialite geometries in a coordinate reference system which is at least transformable to WGS84. It would be nice to support different CRSes in the database so conversion to spatialite from the source data is lossless.
I think the working CRS for datasette should be WGS84 though (leaflet requires it, for example) - it's just a case of calling `ST_Transform(geom, 4326)` on the column while we're loading the data.",17608,
393534579,I actually started doing this in 45e502aace6cc1198cc5f9a04d61b4a1860a012b,17608,
393544357,"Demo: https://datasette-publish-spatialite-demo.now.sh/spatialite-test-c88bc35?sql=select+AsText(Geometry)+from+HighWays+limit+1%3B
Published using `datasette publish now --spatialite /tmp/spatialite-test.db`",17608,
393547960,"SpatialLite columns are actually quite a bit more interesting than this - they also have a `geometry_type` (point, polygon, linestring etc), a `coord_dimension` (usually 2 but can be higher) and an `srid`.
For example:
https://datasette-publish-spatialite-demo.now.sh/spatialite-test-c88bc35/geometry_columns

The SRID here is particularly interesting, because it helps hint at the fact that the results from these queries won't be latitude/longitude co-ordinates - which means that `AsGeoJSON()` won't return results that can be easily rendered by Leaflet:
https://datasette-publish-spatialite-demo.now.sh/spatialite-test-c88bc35?sql=select+AsGeoJSON(Geometry)+from+HighWays%20limit1
Compare with https://timezones-api.now.sh/timezones-a99b2e3/geometry_columns:

",17608,
393548602,Presumably the difference in primary key structure between those two is caused by the fact that the `spatialite-test` database (actually https://www.gaia-gis.it/spatialite-2.3.1/test-2.3.sqlite.gz downloaded from https://www.gaia-gis.it/spatialite-2.3.1/resources.html ) was created by a much older version of SpatialLite - presumably v2.3.1,17608,
393549215,"Also of note: `spatialite-test` uses readable strings in the `type` column, while `timezones` has a `geometry_type` column with integers in it.
Those integers are documented here: https://www.gaia-gis.it/fossil/libspatialite/wiki?name=switching-to-4.0

",17608,
393554151,I fixed this in https://github.com/simonw/datasette/commit/b18e4515855c3f1eeca3dfcccdbb6df05869084a,17608,
393557406,"Our test fixtures currently have a table with a name ending in `.csv`:
https://github.com/simonw/datasette/blob/d69ebce53385b7c6fafb85fdab3b136dbf3f332c/tests/fixtures.py#L234-L237",17608,
393557968,"I'm not sure what the best JSON shape for this would be considering the potential complexity of geospatial columns. I do think it's worth exposing these in the inspect JSON though, mainly so Datasette Registry can keep track of all of the openly available geodata out there.",17608,
393599840,The interesting thing about this is that it requires URL routing to become aware of the names of all of the available tables.,17608,
393600441,"Here's a nasty challenge: what happens if a database has the following two tables:
* `blah`
* `blah.json`
What would the URL be for the JSON endpoint for the `blah` table?",17608,
393610731,I prototyped this a while ago here https://github.com/simonw/datasette/commit/04476ead53758044a5f272ae8696b63d6703115e before we had the ``--config`` mechanism.,17608,
394037368,"Solution for he above: support an optional `?_format=json/csv` parameter on the regular table view.
Then if you have tables with the above colliding names you can use `/db/blah.json?_format=json` ",17608,
394400419,"In the interest of getting this shipped, I'm going to ignore the `3.7.10` issue.",17608,
394412217,Docs: http://datasette.readthedocs.io/en/latest/config.html#cache-size-kb,17608,
394412784,I think this is related to #303,17608,
394417567,"When serving streaming responses, I need to check that a large CSV file doesn't completely max out the CPU in a way that is harmful to the rest of the instance.
If it does, one option may be to insert an async sleep call in between each chunk that is streamed back. This could be controlled by a `csv_pause_ms` config setting, defaulting to maybe 5 but can be disabled entirely by setting to 0.
That's only if testing proves that this is a necessary mechanism.",17608,
394431323,I built this ASGI debugging tool to help with this migration: https://asgi-scope.now.sh/fivethirtyeight-34d6604/most-common-name%2Fsurnames.json?foo=bar&bazoeuto=onetuh&a=.,17608,
394503399,Results of an extremely simple micro-benchmark comparing the two shows that uvicorn is at least as fast as Sanic (benchmarks a little faster with a very simple payload): https://gist.github.com/simonw/418950af178c01c416363cc057420851,17608,
394764713,"https://github.com/encode/uvicorn/blob/572b5fe6c811b63298d5350a06b664839624c860/uvicorn/run.py#L63 is how you start a Uvicorn server from code as opposed to the `uvicorn` CLI
from uvicorn.run import UvicornServer
UvicornServer().run(app, host=host, port=port)
",17608,
394894500,"Input:
- function that says if a name is a valid database
- Function that says if a table exists
- URL
Output:
- view class
- Arguments
- Redirect (if it should redirect)",17608,
394894910,I'm going to use a named tuple for the output. That way I can support either tuple destructing or explicit property access on the returned value.,17608,
394895267,To support a future where Datasette is an ASGI app that can be attached to a URL within a larger application the routing function should have the option to accept a path prefix which will then be automatically attached to any resulting redirects.,17608,
394895750,"A neat trick could be that if the router returns a redirect it could then resolve that redirect to see if it will 404 (or redirect itself) before returning that response.
This would need its own counter to guard against infinite redirects.
I'm not going to do this though: any view that results in a chain of redirects like this is a bug that should be fixed at the source.",17608,
395463497,"I started sketching this out in a branch, see pull request #307 - but I've decided I don't like it. I'm going to close this ticket and stick with regular expression URL routing for the moment. If I change my mind in the future the code in #307 lives in separate files (`datasette/routes.py` and `tests/test_routes.py`) so bringing it back into the project will be trivial.",17608,
395463598,Closing this pull request for reasons outlined here: https://github.com/simonw/datasette/issues/306#issuecomment-395463497,17608,
396048471,https://github.com/kubernetes/community/blob/master/contributors/devel/help-wanted.md Is worth stealing from too.,17608,
397534196,"The first version of this is now shipped to master. I ended up rewriting most of the experimental branch to deal with the nasty issue described in #303
Demo is available on https://fivethirtyeight.datasettes.com/fivethirtyeight-ab24e01/most-common-name%2Fsurnames

Here's the CSV version of that page: https://fivethirtyeight.datasettes.com/fivethirtyeight-ab24e01/most-common-name%2Fsurnames.csv",17608,
397534404,"Still to add: the streaming version that iterates through all of the pages, as seen in experimental commit https://github.com/simonw/datasette/commit/ced379ea325787b8c3bf0a614daba1fa4856a3bd",17608,
397534498,Also needs documentation.,17608,
397637302,"I'm going with the terminology ""labels"" here. You'll be able to add ``?_labels=1`` and the JSON will look something like this:
```
{
""rowid"": 233,
""TreeID"": 121240,
""qLegalStatus"": {
""value"" 2,
""label"": ""Private""
}
""qSpecies"": {
""value"": 16,
""label"": ""Sycamore""
}
""qAddress"": ""91 Commonwealth Ave"",
...
}
```
I need this to help build foreign key expansions for CSV files, see #266 ",17608,
397648080,"I considered including a `""table""` key like this:
```
""qLegalStatus"": {
""value"" 2,
""label"": ""Private"",
""table"": ""qLegalStatus""
}
```
This would help generate the HTML links using just the JSON data. But... I realized that in a list of 50 rows that value would be duplicated 50 times which is a bit nasty.",17608,
397663968,"Nearly done, but I need the HTML view to ignore the `?_labels=1` param (it throws an error at the moment).",17608,
397668427,Demo: https://datasette-json-labels-demo.now.sh/fixtures-fda0fea/facetable.json?_labels=1&_shape=array,17608,
397729319,I'm also going to add the ability to specify individual columns that you want to expand using `?_label=city_id&_label=state_id`,17608,
397729500,The `.json` and `.csv` links displayed on the table page should default to using `?_labels=1` if Datasette detects that there are foreign key expansions available for the page.,17608,
397729945,"The ""This data as ..."" area of the page is getting a bit untidy, especially if I'm going to add other download options in the future. I think I'll move the HTML to the page footer (less concerns about taking up lots of space there) and then have a bit of JavaScript that turns it into a show/hide menu of some sort in its current location.",17608,
397823913,"Still todo:
- [ ] HTML view to obey the ?_labels=1 param (it throws an error at the moment)
- [ ] `?_label=one&_label=2` support for only expanding specific labels
- [ ] Better docs",17608,
397824991,"I'm going to support `?_labels=` on HTML views, but I'll allow it to be used to turn them off (they are on by default) using `?_labels=off`.
Related: 7e0caa1e62607c6579101cc0e62bec8899013715 where I added a new `value_as_boolean` helper extracted from how `--config` works in `cli.py`.",17608,
397825583,This is already covered by #292 ,17608,
397839482,Should facets always have their labels expanded or should they also obey the `_labels` and `_label` querystring arguments?,17608,
397839583,"I'm a bit torn on naming - choices are:
* `?_labels=on` and `?_label=col1&_label=col2`
* `?_expands=on` (or `?_expand_all=on`) and `?_expand=col1&_expand=col2`",17608,
397840676,For the moment I'm going with `_labels=`.,17608,
397841968,I merged this manually in ed631e690b81e34fcaeaba1f16c9166f1c505990,17608,
397842194,"Some demos:
* https://datasette-labels-demo.now.sh/sf-trees-02c8ef1/Street_Tree_List - regular HTML view
* https://datasette-labels-demo.now.sh/sf-trees-02c8ef1/Street_Tree_List?_labels=off - no labels
* https://datasette-labels-demo.now.sh/sf-trees-02c8ef1/Street_Tree_List.json?_labels=on - JSON with all labels
* https://datasette-labels-demo.now.sh/sf-trees-02c8ef1/Street_Tree_List.json?_label=qSpecies&_shape=array - JSON with specific labels in array shape
* https://datasette-labels-demo.now.sh/sf-trees-02c8ef1/Street_Tree_List.csv?_labels=on - CSV with all labels
* https://datasette-labels-demo.now.sh/sf-trees-02c8ef1/Street_Tree_List.csv?_label=qSpecies - CSV with specific labels",17608,
397842246,"Two demos of the new functionality in #233 as it applies to CSV:
* https://datasette-labels-demo.now.sh/sf-trees-02c8ef1/Street_Tree_List.csv?_labels=on - CSV with all foreign key columns expanded
* https://datasette-labels-demo.now.sh/sf-trees-02c8ef1/Street_Tree_List.csv?_label=qSpecies - CSV with specific columns expanded",17608,
397842667,"Still todo:
- [x] Streaming version
- [ ] Tidy up the ""This data as ..."" UI
- [x] Default .csv (and .json) links to use `?_labels=on` (only if at least one foreign key detected)
",17608,
397900434,This will require some relatively sophisticated Travis build steps. Useful docs: https://docs.travis-ci.com/user/build-stages/ - useful example: https://docs.travis-ci.com/user/build-stages/deploy-heroku/,17608,
397907987,"This very nearly works...
* https://latest.datasette.io/
* https://f0c1722.datasette.io/
But... https://f0c1722.datasette.io/-/versions isn't showing the correct note:
```
{
""datasette"": {
""version"": ""0.22.1""
}
...
```
There should be a `""note""` field there with the full commit hash.",17608,
397908093,"It looks like all of my test deploys ended up going to the same Zeit deployment ID: https://zeit.co/simonw/datasette-latest/rbmtcedvlj
This is strange... the Dockerfile should be different for each one (due to the differing version-note).
https://github.com/simonw/datasette/commit/db1e6bc182d11f333e6addaa1a6be87625a4e12b#diff-34418c57343344c73271e13b01b7fcd9R255",17608,
397908185,"```
The command ""datasette publish now fixtures.db -m fixtures.json --token=$NOW_TOKEN --branch=$TRAVIS_COMMIT --version-note=$TRAVIS_COMMIT"" exited with 0.
```
Partial log of the ``datasette publish now`` output:
```
> Step 5/7 : RUN datasette inspect fixtures.db --inspect-file inspect-data.json
> ---> Running in d373f330e53e
> ---> 09bab386aaa3
> Removing intermediate container d373f330e53e
> Step 6/7 : EXPOSE 8001
> ---> Running in e0fe37b3061c
> ---> 47798440e214
> Removing intermediate container e0fe37b3061c
> Step 7/7 : CMD datasette serve --host 0.0.0.0 fixtures.db --cors --port 8001 --inspect-file inspect-data.json --metadata metadata.json --version-note f0c17229b7a7914d3da02e087dfd0e25d8321448
```
So it looks like `--version-note` is being correctly set there.",17608,
397908614,"Aha!
```1.03s$ now alias --token=$NOW_TOKEN
> Error! Couldn't find a deployment to alias. Please provide one as an argument.
The command ""now alias --token=$NOW_TOKEN"" exited with 1.
```
That explains it. I need to set the same alias in my call to `datasette publish`.",17608,
397908947,"That fixed it! https://958b75c.datasette.io/-/versions
```
{
""python"": {
""version"": ""3.6.5"",
""full"": ""3.6.5 (default, Jun 6 2018, 19:19:24) \n[GCC 6.3.0 20170516]""
},
""datasette"": {
""version"": ""0+unknown"",
""note"": ""958b75c69841ef5913da86e0eb2df634a9b95fda""
},
""sqlite"": {
""version"": ""3.16.2"",
""fts_versions"": [
""FTS5"",
""FTS4"",
""FTS3""
],
""extensions"": {
""json1"": null
}
}
}
```",17608,
397912840,"This worked! https://github.com/simonw/datasette/commit/5a0a82faf9cf9dd109d76181ed00eea19472087c - it spat out a 76MB CSV when I ran it against the sf-trees demo database.
It was just a quick hack though - it currently ignores `_labels=` and `_dl=` which need to be supported.
I'm going to add a config option for turning full CSV export off just in case any Datasette users are uncomfortable with URLs that churn out that much data in one go.
```
ConfigOption(""allow_csv_stream"", True, """"""
Allow .csv?_stream=1 to download all rows (ignoring max_returned_rows)
"""""".strip()),
```",17608,
397915258,Someone malicious could use a UNION to generate an unpleasantly large CSV response. I'll add another config setting which limits the response size to 100MB but can be turned off by setting it to 0.,17608,
397915403,"Since CSV streaming export doesn't work for custom SQL queries (since they don't support `_next=` pagination) there's no need to provide a option that disables streams just for custom SQL.
Related: the UI should not show the option to download everything on custom SQL pages.",17608,
397916091,I was also worried about the performance of pagination over custom `_sort` orders or views which use offset pagination - but Datasette's SQL time limits should prevent those from getting out of hand. This does mean that a streaming CSV file may be truncated with an error - if this happens we should ensure the error is written out as the last line of the CSV so anyone who tried to import it gets a relevant error message informing them that the export did not complete.,17608,
397916321,The export UI could be a GET form controlling various parameters. This would discourage crawlers from hitting the export links and would also allow us to express the full range of export options.,17608,
397918264,"Simpler design: the top of the page will link to basic .json and .csv and ""advanced"" - which will fragment link to an advanced export format the bottom of the page.",17608,
397923253,Ideally the downloadable filenames of exported CSVs would differ across different querystring parameters. Maybe S`treet_Trees-56cbd54.csv` where `56cbd54` is a hash of the querystring?,17608,
397949002,"Advanced export pane:

",17608,
397952129,Advanced export pane demo: https://latest.datasette.io/fixtures-35b6eb6/facetable?_size=4,17608,
398030903,"I should add that I'm using datasette version 0.22, Python 2.7.10 on Mac OS X. Happy to send more info if helpful.",17608,
398098582,This is now released in Datasette 0.23! http://datasette.readthedocs.io/en/latest/changelog.html#v0-23,17608,
398101670,"Wow, I've gone as high as 7GB but I've never tried it against 600GB.
`datasette inspect` is indeed expected to take a long time for large databases. That's why it's available as a separate command: by running `datasette inspect` to generate `inspect-data.json` you can execute it just once against a large database and then have `datasette serve` take advantage of that cached metadata (hence avoiding `datasette serve` hanging on startup).
As you spotted, most of the time is spent in those counts. I imagine you don't need those row counts in order for the rest of Datasette to function correctly (they are mainly used for display purposes - on the https://latest.datasette.io/fixtures index page for example).
If your database changes infrequently, for the moment I recommend running `datasette inspect` once to generate the `inspect-data.json` file (let me know how long it takes) and then passing that file to `datasette serve mydb.db --inspect-file=inspect-data.json`
If your database DOES change frequently then this workaround won't help you much. Let me know and I'll see how much work it would take to have those row counts be optional rather than required.",17608,
398102537,https://latest.datasette.io/ now always hosts the latest version of the code. I've started linking to it from our documentation.,17608,
398109204,"Hi Simon,
Thanks for the response. Ok I'll try running `datasette inspect` up front.
In principle the db won't change. However, the site's in development and it's likely I'll need to add views and some auxiliary (smaller) tables as I go along. I will need to be careful with this if it involves an inspect step in each iteration, though.
g.
",17608,
398133159,"For #271 I've been contemplating having Datasette work against an on-disk database that gets modified without needing to restart the server.
For that to work, I'll have to dramatically change the inspect() mechanism. It may be that inspect becomes an optional optimization in the future.",17608,
398133924,"As seen in #316 inspect is already taking a VERY long time to run against large (600GB) databases.
To get this working I may have to make inspect an optional optimization and run introspection for columns and primary keys in demand.
The one catch here is the `count(*)` queries - Datasette may need to learn not to return full table counts in circumstances where the count has not been pre-calculates and takes more than Xms to generate.",17608,
398778485,This would be a great feature to have!,17608,
398825294,Still a bug in 0.23,17608,
398826108,This depends on #272 - Datasette ported to ASGI.,17608,
398973176,"This is a little bit fiddly, but it's possible to do it using SQLite string concatenation. Here's an example:
```
select * from facetable
where neighborhood like ""%"" || :text || ""%"";
```
Try it here: https://latest.datasette.io/fixtures-35b6eb6?sql=select+*+from+facetable+where+neighborhood+like+%22%25%22+%7C%7C+%3Atext+%7C%7C+%22%25%22%3B&text=town
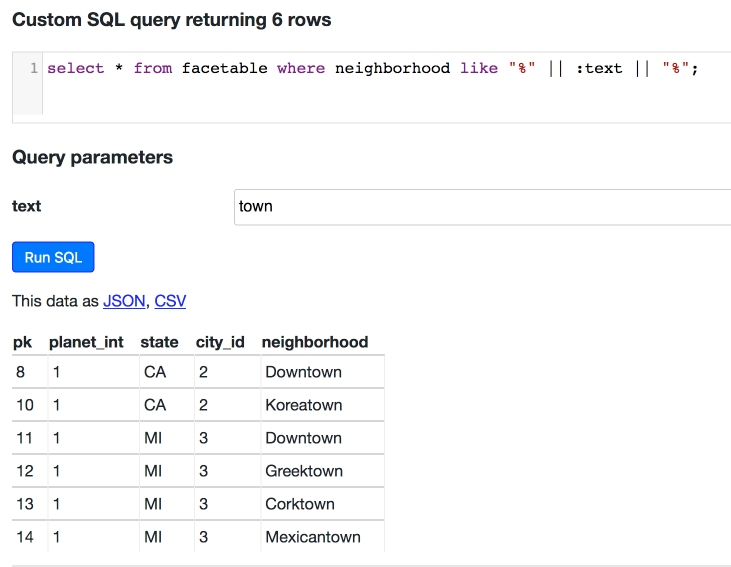
",17608,
398973309,"Demo of fix: the `on_earth` facet on https://latest.datasette.io/fixtures-cafd088/facetable?_facet=planet_int&_facet=on_earth&_facet=city_id

",17608,
398976488,"I've added this to the unit tests and the documentation.
Docs: http://datasette.readthedocs.io/en/latest/sql_queries.html#canned-queries
Canned query demo: https://latest.datasette.io/fixtures/neighborhood_search?text=town
New unit test:
https://github.com/simonw/datasette/blob/3683a6b626b2e79f4dc9600d45853ca4ae8de11a/tests/test_api.py#L333-L344
https://github.com/simonw/datasette/blob/3683a6b626b2e79f4dc9600d45853ca4ae8de11a/tests/fixtures.py#L145-L153",17608,
399098080,"Perfect, thank you!!",17608,
399106871,"One thing I've noticed with this approach is that the query is executed with no parameters which I do not believe was the case previously. In the case the table contains a lot of data, this adds some time executing the query before the user can enter their input and run it with the parameters they want.",17608,
399126228,"This seems to fix that:
```
select neighborhood, facet_cities.name, state
from facetable
join facet_cities on facetable.city_id = facet_cities.id
where :text != '' and neighborhood like '%' || :text || '%'
order by neighborhood;
```
Compare this (with empty string): https://latest.datasette.io/fixtures-cafd088?sql=select+neighborhood%2C+facet_cities.name%2C+state%0D%0Afrom+facetable%0D%0A++++join+facet_cities+on+facetable.city_id+%3D+facet_cities.id%0D%0Awhere+%3Atext+%21%3D+%22%22+and+neighborhood+like+%27%25%27+%7C%7C+%3Atext+%7C%7C+%27%25%27%0D%0Aorder+by+neighborhood%3B
To this: https://latest.datasette.io/fixtures-cafd088?sql=select+neighborhood%2C+facet_cities.name%2C+state%0D%0Afrom+facetable%0D%0A++++join+facet_cities+on+facetable.city_id+%3D+facet_cities.id%0D%0Awhere+%3Atext+%21%3D+%22%22+and+neighborhood+like+%27%25%27+%7C%7C+%3Atext+%7C%7C+%27%25%27%0D%0Aorder+by+neighborhood%3B&text=town",17608,
399129220,Those queries look identical. How can this be prevented if the queries are in a metadata.json file?,17608,
399134680,I can use Sanic middleware for this: http://sanic.readthedocs.io/en/latest/sanic/middleware.html#responding-early,17608,
399139462,"Demo of fix: https://latest.datasette.io/fixtures-e14e080/searchable_tags

",17608,
399142274,Demo: https://latest.datasette.io/fixtures-e14e080/,17608,
399144688,"From https://docs.travis-ci.com/user/deployment/pypi/
> Note that if your PyPI password contains special characters you need to escape them before encrypting your password. Some people have [reported difficulties](https://github.com/travis-ci/dpl/issues/377) connecting to PyPI with passwords containing anything except alphanumeric characters.
",17608,
399150285,That fixed it! https://travis-ci.org/simonw/datasette/jobs/395078407 ran successfully and https://pypi.org/project/datasette/ now hosts Datasette 0.23.1 deployed via Travis.,17608,
399154550,Fixed here too now: https://registry.datasette.io/registry-c10707b/datasette_tags,17608,
399156960,"Demo of fix: https://latest.datasette.io/fixtures-e14e080/simple_view

",17608,
399157944,Thanks to #319 the test suite now includes a m2m table: https://latest.datasette.io/fixtures-e14e080/searchable_tags,17608,
399171239,"I may have misunderstood your problem here.
I understood that the problem is that when using the `""%"" || :text || ""%""` construct the first hit to that page (with an empty string for `:text`) results in a `where neighborhood like ""%%""` query which is slow because it matches every row in the database.
My fix was to add this to the where clause:
where :text != '' and ...
Which means that when you first load the page the where fails to match any rows and you get no results (and hopefully instant loading times assuming SQLite is smart enough to optimize this away). That's why you don't see any rows returned on this page: https://latest.datasette.io/fixtures-cafd088?sql=select+neighborhood%2C+facet_cities.name%2C+state%0D%0Afrom+facetable%0D%0A++++join+facet_cities+on+facetable.city_id+%3D+facet_cities.id%0D%0Awhere+%3Atext+%21%3D+%22%22+and+neighborhood+like+%27%25%27+%7C%7C+%3Atext+%7C%7C+%27%25%27%0D%0Aorder+by+neighborhood%3B",17608,
399173916,"Oh I see.. My issue is that the query executes with an empty string prior to the user submitting the parameters. I'll try adding your workaround to some of my queries. Thanks again,",17608,
399721346,"Demo: go to https://vega.github.io/editor/ and paste in the following:
```
{
""data"": {
""url"": ""https://fivethirtyeight.datasettes.com/fivethirtyeight/twitter-ratio%2Fsenators.csv?_size=max&_sort_desc=replies"",
""format"": {
""type"": ""csv""
}
},
""mark"": ""bar"",
""encoding"": {
""x"": {
""field"": ""created_at"",
""type"": ""temporal""
},
""y"": {
""field"": ""replies"",
""type"": ""quantitative""
},
""color"": {
""field"": ""user"",
""type"": ""nominal""
}
}
}
```

",17608,
400166540,This looks VERY relevant: https://github.com/encode/starlette,17608,
400571521,"I’m up for helping with this.
Looks like you’d need static files support, which I’m planning on adding a component for. Anything else obviously missing?
For a quick overview it looks very doable - the test client ought to me your test cases stay roughly the same.
Are you using any middleware or other components for the Sanic ecosystem? Do you use cookies or sessions at all?",17608,
400903687,Need to ship docker image: #57 ,17608,
400903871,"Shipped to Docker Hub: https://hub.docker.com/r/datasetteproject/datasette/
I did this manually the first time. I'll set Travis up to do this automatically in #329",17608,
400904514,https://datasette.readthedocs.io/en/latest/installation.html#using-docker,17608,
401003061,I pushed this to Docker Hub https://hub.docker.com/r/datasetteproject/datasette/ and added notes on how to use it to the documentation: http://datasette.readthedocs.io/en/latest/installation.html#using-docker,17608,
401310732,"@russs Different map projections can presumably be handled on the client side using a leaflet plugin to transform the geometry (eg [kartena/Proj4Leaflet](https://kartena.github.io/Proj4Leaflet/)) although the leaflet side would need to detect or be informed of the original projection?
Another possibility would be to provide an easy way/guidance for users to create an FK'd table containing the WGS84 projection of a non-WGS84 geometry in the original/principle table? This could then as a proxy for serving GeoJSON to the leaflet map?",17608,
401312981,"> @RusSs Different map projections can presumably be handled on the client side using a leaflet plugin to transform the geometry (eg kartena/Proj4Leaflet) although the leaflet side would need to detect or be informed of the original projection?
Well, as @simonw mentioned, GeoJSON only supports WGS84, and GeoJSON (and/or TopoJSON) is the standard we probably want to aim for. On-the-fly reprojection in spatialite is not an issue anyway, and in general I think you want to be serving stuff to web maps in WGS84 or Web Mercator.",17608,
401477622,"https://docs.python.org/3/library/json.html#json.dump
> **json.dump**(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)¶
> If `allow_nan` is false (default: True), then it will be a ValueError to serialize out of range float values (nan, inf, -inf) in strict compliance of the JSON specification. If allow_nan is true, their JavaScript equivalents (NaN, Infinity, -Infinity) will be used.",17608,
401478223,"I'm not sure what the correct thing to do here is. I don't want to throw a `ValueError` when trying to render that data as JSON, but I also want to produce JSON that doesn't break when fetched by JavaScript.",17608,
402243153,"I think I'm going to return `null` in the JSON for infinity/nan values by default, but if you send `_nan=1` I will instead return invalid JSON with `Infinity` or `NaN` in it (since you have opted in to getting those and hence should be able to handle them).",17608,
403263890,Fixed: https://v0-23-2.datasette.io/fixtures-e14e080/table%2Fwith%2Fslashes.csv / https://v0-23-2.datasette.io/fixtures-e14e080/table%2Fwith%2Fslashes.csv/3,17608,
403526263,Yup that's definitely a bug.,17608,
403672561,"Tested with `datasette publish heroku fixtures.db --extra-options=""--config sql_time_limit_ms:4000""`
https://blooming-anchorage-31561.herokuapp.com/-/config",17608,
403855639,I'm satisified with the improvement we got from the pip wheel cache.,17608,
403855963,This relates to #276 - I'm definitely convinced now that displaying a giant `b'...'` blob on the page is not a useful default.,17608,
403856114,Great idea.,17608,
403858949,"```
$ datasette airports.sqlite
Serve! files=('airports.sqlite',) on port 8001
Usage: datasette airports.sqlite [OPTIONS] [FILES]...
Error: It looks like you're trying to load a SpatiaLite database without first loading the SpatiaLite module.
Read more: https://datasette.readthedocs.io/en/latest/spatialite.html
```",17608,
403863927,Here are some useful examples of other Python apps that have been packaged using the recipe described above: https://github.com/Homebrew/homebrew-core/search?utf8=%E2%9C%93&q=virtualenv_install_with_resources&type=,17608,
403865063,"Huh... from https://docs.brew.sh/Acceptable-Formulae
> We frown on authors submitting their own work unless it is very popular.
Marking this one as ""help wanted"" :)",17608,
403866099,"I can host a custom tap without needing to get anything accepted into homebrew-core: https://docs.brew.sh/How-to-Create-and-Maintain-a-Tap
Since my principle goal here is ensuring an easy installation path for people who are familiar with `brew` but don't know how to use pip and Python 3 that could be a good option.",17608,
403868584,"I think this makes sense for the HTML view (not for JSON or CSV). It could be controlled be a new [config option](http://datasette.readthedocs.io/en/latest/config.html), `truncate_cells_html` - which is on by default but can be turned off.",17608,
403906747,"```
datasette publish now timezones.db --spatialite \
--extra-options=""--config truncate_cells_html:200"" \
--name=datasette-issue-330-demo \
--branch=master
```
https://datasette-issue-330-demo-sbelwxttfn.now.sh/timezones-3cb9f64/timezones

But https://datasette-issue-330-demo-sbelwxttfn.now.sh/timezones-3cb9f64/timezones/1 displays the full blob.",17608,
403907193,Documentation: http://datasette.readthedocs.io/en/latest/config.html#truncate-cells-html,17608,
403908704,I consider this resolved by #46 ,17608,
403909389,This is done! https://github.com/simonw/datasette-vega,17608,
403909469,This is now a dupe of https://github.com/simonw/datasette-vega/issues/4,17608,
403909671,This was fixed by https://github.com/simonw/datasette/commit/6a32684ebba89dfe882e1147b23aa8778479f5d8#diff-354f30a63fb0907d4ad57269548329e3,17608,
403910318,This would be a nice example plugin to demonstrate plugin configuration options in #231,17608,
403910774,I consider this handled by https://github.com/simonw/datasette-vega,17608,
403939399,Building this using Svelte would also produce a neat example of a plugin that uses Svelte: https://svelte.technology/guide - and if I like it I might part datasette-vega to it.,17608,
403959704,"No cookies or sessions - no POST requests in fact, Datasette just cares about GET (path and querystring) and being able to return custom HTTP headers.",17608,
403996143,Easiest way to do this I think would be to make those help blocks separate files in the docs/ directory (publish-help.txt perhaps) and then include them with a sphinx directive: https://reinout.vanrees.org/weblog/2010/12/08/include-external-in-sphinx.html,17608,
404021589,http://datasette.readthedocs.io/en/latest/publish.html,17608,
404021890,"I decided against the unit tests, instead I have a new script called `./update-docs-help.sh` which I can run any time I want to refresh the included documentation: https://github.com/simonw/datasette/commit/aec3ae53237e43b0c268dbf9b58fa265ef38cfe1#diff-cb15a1e5a244bb82ad4afce67f252543",17608,
404208602,Here's a good example of a homebrew tap: https://github.com/saulpw/homebrew-vd,17608,
404209205,"Oops, opened this in the wrong repo - moved it here: https://github.com/simonw/datasette-vega/issues/13",17608,
404338345,"It sounds like you're running into the Sanic default response timeout value of 60 seconds: https://github.com/channelcat/sanic/blob/master/docs/sanic/config.md#builtin-configuration-values
For the moment you can over-ride that using an environment variable like this:
SANIC_RESPONSE_TIMEOUT=6000 datasette fivethirtyeight.db -p 8008 --config sql_time_limit_ms:600000",17608,
404514973,"Okay. I reckon the latest version should have all the kinds of components you'd need:
Recently added ASGI components for Routing and Static Files support, as well as making few tweaks to make sure requests and responses are instantiated efficiently.
Don't have any redirect-to-slash / redirect-to-non-slash stuff out of the box yet, which it looks like you might miss.",17608,
404565566,I'm going to turn this into an issue about better supporting the above option.,17608,
404567587,Here's how plotly handled this issue: https://github.com/plotly/plotly.py/pull/203 - see also https://github.com/plotly/plotly.py/blob/213602df6c89b45ce2b811ed2591171c961408e7/plotly/utils.py#L137,17608,
404569003,And here's how django-rest-framework did it: https://github.com/encode/django-rest-framework/pull/4918/files,17608,
404574598,Since my data is all flat lists of values I don't think I need to customize the JSON encoder itself (no need to deal with nested values). I'll fix the data on its way into the encoder instead. This will also help if I decide to move to uJSON for better performance #48,17608,
404576136,Thanks for the quick reply. Looks like that is working well.,17608,
404923318,Relevant: https://code.fb.com/data-infrastructure/xars-a-more-efficient-open-source-system-for-self-contained-executables/,17608,
404953877,That's a good idea. We already do this for tables - e.g. on https://fivethirtyeight.datasettes.com/fivethirtyeight-ac35616/most-common-name%2Fsurnames - so having it as an option for canned queries definitely makes sense.,17608,
404954202,"https://timezones-api.now.sh/-/metadata currently shows this:
```
{
""databases"": {
""timezones"": {
""license"": ""ODbL"",
""license_url"": ""http://opendatacommons.org/licenses/odbl/"",
""queries"": {
""by_point"": ""select tzid\nfrom\n timezones\nwhere\n within(GeomFromText(\u0027POINT(\u0027 || :longitude || \u0027 \u0027 || :latitude || \u0027)\u0027), timezones.Geometry)\n and rowid in (\n SELECT pkid FROM idx_timezones_Geometry\n where xmin \u003c :longitude\n and xmax \u003e :longitude\n and ymin \u003c :latitude\n and ymax \u003e :latitude\n )""
},
""source"": ""timezone-boundary-builder"",
""source_url"": ""https://github.com/evansiroky/timezone-boundary-builder"",
""tables"": {
""timezones"": {
""license"": ""ODbL"",
""license_url"": ""http://opendatacommons.org/licenses/odbl/"",
""sortable_columns"": [
""tzid""
],
""source"": ""timezone-boundary-builder"",
""source_url"": ""https://github.com/evansiroky/timezone-boundary-builder""
}
}
}
},
""license"": ""ODbL"",
""license_url"": ""http://opendatacommons.org/licenses/odbl/"",
""source"": ""timezone-boundary-builder"",
""source_url"": ""https://github.com/evansiroky/timezone-boundary-builder"",
""title"": ""OpenStreetMap Time Zone Boundaries""
}
```
We could support the value part of the `""queries""` array optionally being a dictionary with the same set of metadata fields supported for a table, plus a new `""sql""` key to hold the SQL for the query.
",17608,
404954672,"So it would look like this:
```
{
""databases"": {
""timezones"": {
""license"": ""ODbL"",
""license_url"": ""http://opendatacommons.org/licenses/odbl/"",
""queries"": {
""by_point"": {
""title"": ""Timezones by point"",
""description"": ""Find the timezone for a latitude/longitude point"",
""sql"": ""select tzid\nfrom\n timezones\nwhere\n within(GeomFromText('POINT(' || :longitude || ' ' || :latitude || ')'), timezones.Geometry)\n and rowid in (\n SELECT pkid FROM idx_timezones_Geometry\n where xmin < :longitude\n and xmax > :longitude\n and ymin < :latitude\n and ymax > :latitude\n )""
}
}
}
}
}
```",17608,
405022335,"Looks like this was a red herring actually, and heroku had a blip when I was testing it...",17608,
405025731,"Fantastic, we really needed this.",17608,
405026441,This probably depends on #294.,17608,
405026800,"I had a quick look at this in relation to #343 and I feel like it might be worth modelling the inspected table metadata internally as an object rather than a dict. (We'd still have to serialise it back to JSON.)
There are a few places where we rely on the structure of this metadata dict for various reasons, including in templates (and potentially also in user templates). It would be nice to have a reasonably well defined API for accessing metadata internally so that it's clearer what we're breaking.",17608,
405138460,"Demos:
* https://latest.datasette.io/fixtures/neighborhood_search
* https://timezones-api.now.sh/timezones/by_point
Documentation: http://datasette.readthedocs.io/en/latest/sql_queries.html#canned-queries",17608,
405968983,Maybe argument should be `?_json_nan=1` since that makes it more explicitly obvious what is going on here.,17608,
405971920,"It looks like there are a few extra options we should support:
https://devcenter.heroku.com/articles/heroku-cli-commands
```
-t, --team=team team to use
--region=region specify region for the app to run in
--space=space the private space to create the app in
```
Since these differ from the options for Zeit Now I think this means splitting up `datasette publish now` and `datasette publish Heroku` into separate subcommands.",17608,
405975025,"A `force_https_api_urls` config option would work here - if set, Datasette will ignore the incoming protocol and always use https. The `datasette deploy now` command could then add that as an option passed to `datasette serve`.
This is the pattern which is producing incorrect URLs on Zeit Now, because the Sanic `request.url` property is not being correctly set.
https://github.com/simonw/datasette/blob/6e37f091edec35e2706197489f54fff5d890c63c/datasette/views/table.py#L653-L655
Suggested help text:
> Always use https:// for URLs output as part of Datasette API responses",17608,
405988035,"I'll add a `absolute_url(request, path)` method on the base view class which knows to check the new config option.",17608,
407109113,I still need to modify `datasette publish now` to set this config option on the instances that it deploys.,17608,
407262311,Actually SQLite doesn't handle NaN at all (it treats it as null) so I'm going to change this ticket to just deal with Infinity and -Infinity.,17608,
407262436,I'm going with `_json_infinity=1` as the querystring argument.,17608,
407262561,According to https://www.mail-archive.com/sqlite-users@mailinglists.sqlite.org/msg110573.html you can insert Infinity/-Infinity in raw SQL (as used by our fixtures) using 1e999 and -1e999.,17608,
407267707,"Demo:
* https://700d83d.datasette.io/fixtures-dcc1dbf/infinity.json - Infinity converted to Null
* https://700d83d.datasette.io/fixtures-dcc1dbf/infinity.json?_json_infinity=on - invalid JSON containing `Infinity` and `-Infinity`",17608,
407267762,Documentation: http://datasette.readthedocs.io/en/latest/json_api.html#special-json-arguments,17608,
407267966,Demo: https://700d83d.datasette.io/fixtures-dcc1dbf/facetable.json?_facet=state&_size=5&_labels=on,17608,
407269243,"* No primary key => no ""object"" option: https://latest.datasette.io/fixtures-dcc1dbf/no_primary_key
* Has a primary key => show ""object"" option: https://latest.datasette.io/fixtures-dcc1dbf/complex_foreign_keys
* Has a next page => has ""stream all rows"" option: https://latest.datasette.io/fixtures-dcc1dbf/no_primary_key
* Has foreign key references = show default-checked ""expand labels"" option: https://latest.datasette.io/fixtures-dcc1dbf/complex_foreign_keys
* Does not have a next page => do not show ""stream all rows"" option: https://latest.datasette.io/fixtures-dcc1dbf/complex_foreign_keys
",17608,
407274059,Demo: https://latest.datasette.io/fixtures-dcc1dbf?sql=select+%28%27https%3A%2F%2Ftwitter.com%2F%27+%7C%7C+%27simonw%27%29+as+user_url%3B,17608,
407275996,Hopefully this will do the trick: https://github.com/simonw/datasette/commit/2bdab66772dca51b0c729b4e1063610cb2edd890,17608,
407280689,"It almost worked... but I had to fix the `docker login` command: https://github.com/simonw/datasette/commit/3a46d5e3c4278e74c3694f36995ea134bff800bc
Hopefully the next release will be published correctly.",17608,
407450815,Actually I do like the idea of a unit test that reminds me if I've forgotten to update the included files.,17608,
407979065,This code now lives in https://github.com/simonw/datasette/blob/master/datasette/publish/heroku.py,17608,
407980050,Documentation: http://datasette.readthedocs.io/en/latest/plugins.html#publish-subcommand-publish,17608,
407980716,"Documentation here: http://datasette.readthedocs.io/en/latest/plugins.html#publish-subcommand-publish
The best way to write a new publish plugin is to check out how the Heroku and Now default plugins are implemented: https://github.com/simonw/datasette/tree/master/datasette/publish",17608,
407983375,"Oops, forgot to commit those unit tests.",17608,
408093480,"I'm now hacking around with an initial version of this in the [starlette branch](https://github.com/simonw/datasette/tree/starlette).
Here's my work in progress, deployed using `datasette publish now fixtures.db -n datasette-starlette-demo --branch=starlette --extra-options=""--asgi""`
https://datasette-starlette-demo.now.sh/
Lots more work to do - the CSS isn't being served correctly for example, it's showing this error when I hit `/-/static/app.css`:
```
INFO: 127.0.0.1 - ""GET /-/static/app.css HTTP/1.1"" 200
ERROR: Exception in ASGI application
Traceback (most recent call last):
File ""/Users/simonw/Dropbox/Development/datasette/venv/lib/python3.6/site-packages/uvicorn/protocols/http/httptools_impl.py"", line 363, in run_asgi
result = await asgi(self.receive, self.send)
File ""/Users/simonw/Dropbox/Development/datasette/venv/lib/python3.6/site-packages/starlette/staticfiles.py"", line 91, in __call__
await response(receive, send)
File ""/Users/simonw/Dropbox/Development/datasette/venv/lib/python3.6/site-packages/starlette/response.py"", line 180, in __call__
{""type"": ""http.response.body"", ""body"": chunk, ""more_body"": False}
File ""/Users/simonw/Dropbox/Development/datasette/venv/lib/python3.6/site-packages/uvicorn/protocols/http/httptools_impl.py"", line 483, in send
raise RuntimeError(""Response content shorter than Content-Length"")
RuntimeError: Response content shorter than Content-Length
```",17608,
408097719,It looks like that's a bug in Starlette - filed here: https://github.com/encode/starlette/issues/32,17608,
408105251,"Tom shipped my fix for that bug already, so https://datasette-starlette-demo.now.sh/ is now serving CSS!",17608,
408478935,"Refs
https://github.com/encode/uvicorn/issues/168",17608,
408581551,New documentation is now online here: https://datasette.readthedocs.io/en/latest/pages.html,17608,
409087501,Parent ticket: #354,17608,
409087871,"I started playing with this in the `m2m` branch - work so far: https://github.com/simonw/datasette/compare/295d005ca48747faf046ed30c3c61e7563c61ed2...af4ce463e7518f9d7828b846efd5b528a1905eca
Here's a demo: https://datasette-m2m-work-in-progress.now.sh/russian-ads-e8e09e2/ads?_m2m_ad_targets__target_id=ec3ac&_m2m_ad_targets__target_id=e128e",17608,
409088967,"Here's the query I'm playing with for facet counts:
https://datasette-m2m-work-in-progress.now.sh/russian-ads-e8e09e2?sql=select+target_id%2C+count%28*%29+as+n+from+ad_targets%0D%0Awhere%0D%0A++target_id+not+in+%28%22ec3ac%22%2C+%22e128e%22%29%0D%0A++and+ad_id+in+%28select+ad_id+from+ad_targets+where+target_id+%3D+%22ec3ac%22%29%0D%0A++and+ad_id+in+%28select+ad_id+from+ad_targets+where+target_id+%3D+%22e128e%22%29%0D%0Agroup+by+target_id+order+by+n+desc%3B
```
select target_id, count(*) as n from ad_targets
where
target_id not in (""ec3ac"", ""e128e"")
and ad_id in (select ad_id from ad_targets where target_id = ""ec3ac"")
and ad_id in (select ad_id from ad_targets where target_id = ""e128e"")
group by target_id order by n desc;
```",17608,
409715112,The hook is currently only used on the custom SQL results page - it needs to run on table/view pages as well.,17608,
410485995,"First plugin using this hook: https://github.com/simonw/datasette-json-html
Hook documentation: http://datasette.readthedocs.io/en/latest/plugins.html#render-cell-value",17608,
410580202,I used `datasette-json-html` to build this: https://russian-ira-facebook-ads-datasette-whmbonekoj.now.sh/russian-ads-919cbfd/display_ads,17608,
410818501,Another potential use-case for this hook: loading metadata via a URL,17608,
412290986,This was fixed in https://github.com/simonw/datasette/commit/89d9fbb91bfc0dd9091b34dbf3cf540ab849cc44,17608,
412291327,"Potential problem: the existing `metadata.json` format looks like this:
```
{
""title"": ""Custom title for your index page"",
""description"": ""Some description text can go here"",
""license"": ""ODbL"",
""license_url"": ""https://opendatacommons.org/licenses/odbl/"",
""databases"": {
""database1"": {
""source"": ""Alternative source"",
""source_url"": ""http://example.com/"",
""tables"": {
""example_table"": {
""description_html"": ""Custom table description"",
""license"": ""CC BY 3.0 US"",
""license_url"": ""https://creativecommons.org/licenses/by/3.0/us/""
}
}
}
}
}
```
This doesn't make sense for metadata that is bundled with a specific database - there's no point in having the `databases` key, instead the content of `database1` in the above example should be at the top level. This also means that if you rename the `*.db` file you won't have to edit its metadata at the same time.
Calling such an embedded file `metadata.json` when the shape is different could be confusing. Maybe call it `database-metadata.json` instead.",17608,
412291395,"I'm going to separate the issue of enabling and disabling plugins from the existence of the `plugins` key. The format will simply be:
```
{
""plugins"": {
""name-of-plugin"": {
... any structures you like go here, defined by the plugin ...
}
}
}
```",17608,
412291437,"On further thought, I'd much rather implement this using some kind of metadata plugin hook - see #357",17608,
412299013,"I've been worrying about how this one relates to #260 - I'd like to validate metadata (to help protect against people e.g. misspelling `license_url` and then being confused when their license isn't displayed properly), but this issue requests the ability to add arbitrary additional keys to the metadata structure.
I think the solution is to introduce a metadata key called `extra_metadata_keys` which allows you to specifically list the extra keys that you want to enable. Something like this:
```
{
""title"": ""My title"",
""source"": ""Source"",
""source_url"": ""https://www.example.com/"",
""release_date"": ""2018-04-01"",
""extra_metadata_keys"": [""release_date""]
}
```
",17608,
412356537,"Example table: https://latest-code.datasette.io/code/definitions
Here's a query that does facet counting against that column:
https://latest-code.datasette.io/code-a26fa3c?sql=select+count%28*%29+as+n%2C+j.value+from+definitions+join+json_each%28params%29+j+group+by+j.value+order+by+n+desc%3B
```
select count(*) as n, j.value
from definitions join json_each(params) j
group by j.value order by n desc;
```",17608,
412356746,"And here's the query for pulling back every record tagged with a specific tag:
https://latest-code.datasette.io/code-a26fa3c?sql=select+*+from+definitions+where+rowid+in+%28%0D%0A++select+definitions.rowid%0D%0A++from+definitions+join+json_each%28params%29+j%0D%0A++where+j.value+%3D+%3Atag%0D%0A%29&tag=filename
```
select * from definitions where rowid in (
select definitions.rowid
from definitions join json_each(params) j
where j.value = :tag
)
```",17608,
412357691,"Note that there doesn't seem to be a way to use indexes (even [indexes on expressions](https://www.sqlite.org/expridx.html)) to speed these up, so this will only ever be effective on smaller data sets, probably in the 10,000-100,000 range. Datasette is often used with smaller data sets so this is still worth pursuing.",17608,
412663658,That seems good to me.,17608,
413386332,Relevant: https://github.com/coleifer/pysqlite3/issues/2,17608,
413387424,"I deployed a working demo of this here: https://pysqlite3-datasette.now.sh
I used this command to deploy it:
datasette publish now \
fixtures.db fivethirtyeight.db \
--branch=pysqlite3 \
--install=https://github.com/karlb/pysqlite3/archive/master.zip \
-n pysqlite3-datasette
https://pysqlite3-datasette.now.sh/-/versions confirms version of SQLite is `3.25.0`",17608,
413396812,"Now that this has merged into master the command for deploying it can use `--branch=master` instead:
datasette publish now \
fixtures.db fivethirtyeight.db \
--branch=master \
--install=https://github.com/karlb/pysqlite3/archive/master.zip \
-n pysqlite3-datasette
",17608,
414860009,"Looks to me like hashing, redirects and caching were documented as part of https://github.com/simonw/datasette/commit/788a542d3c739da5207db7d1fb91789603cdd336#diff-3021b0e065dce289c34c3b49b3952a07 - so perhaps this can be closed? :tada:",17608,
416659043,Closed in https://github.com/simonw/datasette/commit/0bd41d4cb0a42d7d2baf8b49675418d1482ae39b,17608,
416667565,https://b7257a2.datasette.io/-/plugins is now correctly returning an empty list.,17608,
416727898,"Are you talking about these filters here?

I haven't thought much about how those could be made more usable - right now they basically expose all available options, but customizing them for particular use-cases is certainly an interesting potential space.
Could you sketch out a bit more about how your ideal interface here would work?",17608,
417684877,"It looks like the check passed, not sure why it's showing as running in GH.",17608,
418106781,Now that I've split the heroku command out into a separate default plugin this is a much easier thing to add: https://github.com/simonw/datasette/blob/master/datasette/publish/heroku.py,17608,
418695115,"Some notes:
* Starlette just got a bump to 0.3.0 - there's some renamings in there. It's got enough functionality now that you can treat it either as a framework or as a toolkit. Either way the component design is all just *here's an ASGI app* all the way through.
* Uvicorn got a bump to 0.3.3 - Removed some cyclical references that were causing garbage collection to impact performance. Ought to be a decent speed bump.
* Wrt. passing config - Either use a single envvar that points to a config, or use multiple envvars for the config. Uvicorn could get a flag to read a `.env` file, but I don't see ASGI itself having a specific interface there.",17608,
420295524,I close this PR because it's better to use the new one #364 ,17608,
422821483,"I'm using the docker image (0.23.2) and notice some differences/bugs between the docs and the published version with canned queries. (submitted a tiny doc fix also)
I was able to build the docker container locally using `master` and I'm using that for now.
Would it be possible to manually push 0.24 to DockerHub until the TravisCI stuff is fixed?
I would like to run this in our Kubernetes cluster but don't want to publish a version in our internal registry if I don't have to.
Thanks!",17608,
422885014,Thanks!,17608,
422903031,"The new 0.25 release has been successfully pushed to Docker Hub! https://hub.docker.com/r/datasetteproject/datasette/tags/
One catch: it looks like it didn't update the ""latest"" tag to point at it. Looking into that now.",17608,
422908130,"I fixed that by running the following on my laptop:
$ docker pull datasetteproject/datasette:0.25
$ docker tag datasetteproject/datasette:0.25 datasetteproject/datasette:latest
$ docker push datasetteproject/datasette
The `latest` tag now points to the most recent release.",17608,
422915450,"That works for me. Was able to pull the public image and no errors on my canned query. (~although a small rendering bug. I'll create an issue and if I have time today, a PR to fix~ this turned out to be my error.)
Thanks for the quick response!",17608,
423543060,"I keep on finding new reasons that I want this.
The latest is that I'm playing with the more advanced features of FTS5 - in particular the highlight() function and the ability to sort by rank.
The problem is... in order to do this, I need to properly join against the `_fts` table. Here's an example query:
select
highlight(events_fts, 0, '', ''),
events_fts.rank,
events.*
from events
join events_fts on events.rowid = events_fts.rowid
where events_fts match :search
order by rank
Note that this is a different query from the usual FTS one (which does `where rowid in (select rowid from events_fts...)`) because I need the rank column somewhere I can sort against.
I'd like to be able to use this on the table view page so I can get faceting etc for free, but this is a completely different query from the default. Maybe I need a way to customize the entire query? That feels weird though - why am I not using a view in that case?
Answer: because views can't accept `:search` style parameters. I could use a canned query, but canned queries don't get faceting etc.",17608,
427261369,"```
~ $ docker pull datasetteproject/datasette
~ $ docker run -p 8001:8001 -v `pwd`:/mnt datasetteproject/datasette datasette -p 8001 -h 0.0.0.0 /mnt/fixtures.db
Usage: datasette -p [OPTIONS] [FILES]...
Error: Invalid value for ""files"": Path ""/mnt/fixtures.db"" does not exist.
```",17608,
427943710,"I have same error:
```
Collecting uvloop
Using cached https://files.pythonhosted.org/packages/5c/37/6daa39aac42b2deda6ee77f408bec0419b600e27b89b374b0d440af32b10/uvloop-0.11.2.tar.gz
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File """", line 1, in
File ""C:\Users\sageev\AppData\Local\Temp\pip-install-bq64l8jy\uvloop\setup.py"", line 15, in
raise RuntimeError('uvloop does not support Windows at the moment')
RuntimeError: uvloop does not support Windows at the moment
```",17608,
429737929,"Very hacky solution is to write now.json file forcing the usage of v1 of Zeit cloud, see https://github.com/slygent/datasette/commit/3ab824793ec6534b6dd87078aa46b11c4fa78ea3
This does work, at least.",17608,
431867885,"I'd like this as well. It would let me access Datasette-driven projects from GatsbyJS the same way I can access Postgres DBs via Hasura. While I don't see SQLite replacing Postgres for the 50m row datasets I sometimes have to work with, there's a whole class of smaller datasets that are great with Datasette but currently would find another option.",17608,
433680598,I've just started running into this as well. Looks like I'll have to anchor to v1 for the moment - I'm hoping the discussion on https://github.com/zeit/now-cli/issues/1523 encourages an increase in this limit policy :/,17608,
435767775,"This would be fantastic - that tutorial looks like many of the details needed for this.
Do you know if Digital Ocean have the ability to provision URLs for a droplet without you needing to buy your own domain name? Heroku have https://example.herokuapp.com/ and Zeit have https://blah.now.sh/ - does Digital Ocean have an equivalent?
",17608,
435767827,"This is a good idea. Basically a version of this bug but on the custom SQL query page:

",17608,
435768450,"That would be ideal, but you know better than me whether the CSV streaming trick works for custom SQL queries.",17608,
435772031,"This works now! The `0.25.1` release was the first release which successfully pushed to Docker Hub: https://hub.docker.com/r/datasetteproject/datasette/tags/

Here's the log from the successful Travis release job: https://travis-ci.org/simonw/datasette/jobs/450714602
",17608,
435862009,I think you need to register a domain name you own separately in order to get a non-IP address address? https://www.digitalocean.com/docs/networking/dns/,17608,
435974786,"I've been thinking a bit about ways of using Jupyter Notebook more effectively with Datasette (thinks like a `publish_dataframes(df1, df2, df3)` function which publishes some Pandas dataframes and returns you a URL to a new hosted Datasette instance) but you're right, Jupyter Lab is potentially a much more interesting fit.",17608,
435976262,"I think there is a useful way forward here though: the image size may be limited to 100MB, but once the instance launches it gets access to a filesystem with a lot more space than that (possibly as much as 15GB given my initial poking around).
So... one potential solution here is to teach Datasette to launch from a smaller image and then download a larger SQLite file from a known URL as part of its initial startup.
Combined with the ability to get Now to always run at least one copy of an instance this could allow Datasette to host much larger SQLite databases on that platform while playing nicely with the Zeit v2 platform.
See also https://github.com/zeit/now-cli/issues/1523",17608,
436037692,"In terms of integration with `pandas`, I was pondering two different ways `datasette`/`csvs_to_sqlite` integration may work:
- like [`pandasql`](https://github.com/yhat/pandasql), to provide a SQL query layer either by a direct connection to the sqlite db or via `datasette` API;
- as an improvement of `pandas.to_sql()`, which is a bit ropey (e.g. `pandas.to_sql_from_csvs()`, routing the dataframe to sqlite via `csvs_tosqlite` rather than the dodgy mapping that `pandas` supports).
The `pandas.publish_*` idea could be quite interesting though... Would it be useful/fruitful to think about `publish_` as a complement to [`pandas.to_`](https://pandas.pydata.org/pandas-docs/stable/api.html#id12)?",17608,
436042445,"Another route would be something like creating a `datasette` IPython magic for notebooks to take a dataframe and easily render it as a `datasette`. You'd need to run the app in the background rather than block execution in the notebook. Related to that, or to publishing a dataframe in notebook cell for use in other cells in a non-blocking way, there may be cribs in something like https://github.com/micahscopes/nbmultitask .",17608,
439194286,I'm diving back into https://salaries.news.baltimoresun.com and what I really want is the ability to inject the request into my context.,17608,
439421164,This would be an awesome feature ❤️ ,17608,
439762759,"It turned out Zeit didn't end up shipping the new 100MB-limit Docker-based Zeit 2.0 after all - they ended up going in a completely different direction, towards lambdas instead (which don't really fit the Datasette model): https://zeit.co/blog/now-2
But... as far as I can tell they have introduced the 100MB image size for all free Zeit accounts ever against their 1.0 platform. So we still need to solve this, or free Zeit users won't be able to use `datasette publish now` even while 1.0 is still available.
I made some notes on this here: https://simonwillison.net/2018/Nov/19/smaller-python-docker-images/
I've got it working for the Datasette Publish webapp, but I still need to fix `datasette publish now` to create much smaller patterns.
I know how to do this for regular datasette, but I haven't yet figured out an Alpine Linux pattern for spatialite extras:
https://github.com/simonw/datasette/blob/5e3a432a0caa23837fa58134f69e2f82e4f632a6/datasette/utils.py#L287-L300",17608,
439763196,This looks like it might be a recipe for spatialite Python on Alpine Linux: https://github.com/bentrm/geopython/blob/8e52062d9545f4b7c1f04a3516354a5a9155e31f/Dockerfile,17608,
439763268,Another example that might be useful: https://github.com/poc-flask/alpine/blob/8e9f48a2351e106347dab36d08cf21dee865993e/Dockerfile,17608,
440128762,"The problem is Sanic. Here's the error I'm getting:
```
(venv) datasette $ pytest -x
============================================================= test session starts ==============================================================
platform darwin -- Python 3.7.1, pytest-4.0.0, py-1.7.0, pluggy-0.8.0
rootdir: /Users/simonw/Dropbox/Development/datasette, inifile:
collected 258 items
tests/test_api.py ...................F
=================================================================== FAILURES ===================================================================
_______________________________________________________ test_table_with_slashes_in_name ________________________________________________________
app_client =
def test_table_with_slashes_in_name(app_client):
response = app_client.get('/fixtures/table%2Fwith%2Fslashes.csv?_shape=objects&_format=json')
> assert response.status == 200
E AssertionError: assert 404 == 200
```
That's because something about how Sanic handles escape characters in URLs changed between 0.7.0 and 0.8.3.",17608,
447677798,Thanks for spotting this!,17608,
448437245,"Closing this as Zeit went on a different direction with Now v2, so the 100MB limit is no longer a concern.",17608,
450943172,"Definitely a bug, thanks.",17608,
450943632,"This is the code which is meant to add those options as hidden form fields:
https://github.com/simonw/datasette/blob/fe5b6ea95a973534fe8a44907c0ea2449aae7602/datasette/templates/table.html#L150-L155
It's clearly not working. Need to fix this and add a corresponding unit test.",17608,
450944166,"Here's the test that needs updating:
https://github.com/simonw/datasette/blob/8b8ae55e7c8b9e1dceef53f55a330b596ca44d41/tests/test_html.py#L427-L435",17608,
450964512,"Thanks, I've fixed this. I had to re-alias it against now:
```
~ $ now alias google-trends-pnwhfwvgqf.now.sh https://google-trends.datasettes.com/
> Assigning alias google-trends.datasettes.com to deployment google-trends-pnwhfwvgqf.now.sh
> Certificate for google-trends.datasettes.com (cert_uXaADIuNooHS3tZ) created [18s]
> Success! google-trends.datasettes.com now points to google-trends-pnwhfwvgqf.now.sh [20s]
```",17608,
451046123,The fix was released as part of Datasette 0.26 - you can see the fix working here: https://v0-26.datasette.io/fixtures-dd88475/facetable?_facet=planet_int&planet_int=1#export,17608,
451047426,https://fivethirtyeight.datasettes.com/-/versions is now running 0.26 - so your initial bug demo is now fixed: https://fivethirtyeight.datasettes.com/fivethirtyeight-c300360/classic-rock%2Fclassic-rock-song-list?Release+Year__exact=1989#export,17608,
451415063,Awesome - will get myself up and running on 0.26,17608,
451704724,"I found a really nice pattern for writing the unit tests for this (though it would look even nicer with a solution to #395)
```python
@pytest.mark.parametrize(""prefix"", [""/prefix/"", ""https://example.com/""])
@pytest.mark.parametrize(""path"", [
""/"",
""/fixtures"",
""/fixtures/compound_three_primary_keys"",
""/fixtures/compound_three_primary_keys/a,a,a"",
""/fixtures/paginated_view"",
])
def test_url_prefix_config(prefix, path):
for client in make_app_client(config={
""url_prefix"": prefix,
}):
response = client.get(path)
soup = Soup(response.body, ""html.parser"")
for a in soup.findAll(""a""):
href = a[""href""]
if href not in {
""https://github.com/simonw/datasette"",
""https://github.com/simonw/datasette/blob/master/LICENSE"",
""https://github.com/simonw/datasette/blob/master/tests/fixtures.py"",
}:
assert href.startswith(prefix), (href, a.parent)
```",17608,
453251589,"What version of SQLite are you seeing in Datasette? You can tell by hitting http://localhost:8001/-/versions - e.g. here: https://latest.datasette.io/-/versions
My best guess is that your Python SQLite module is running an older version that doesn't support window functions.
One way you can fix that is with the `pysqlite3` module - try running this in your virtual environment:
pip install git+git://github.com/karlb/pysqlite3
That's using a fork of the official module that embeds a full recent SQLite. See this issue thread for more details: https://github.com/coleifer/pysqlite3/issues/2",17608,
453252024,"Oh I just saw you're using the official Datasette docker package - yeah, that's not bundled with a recent SQLite at the moment. We should update that:
https://github.com/simonw/datasette/blob/5b026115126bedbb66457767e169139146d1c9fd/Dockerfile#L9-L11",17608,
453262703,It turns out this was much easier to support than I expected: https://github.com/simonw/datasette/commit/eac08f0dfc61a99e8887442fc247656d419c76f8,17608,
453324601,Demo: https://latest.datasette.io/-/versions,17608,
453330680,"If you pull [the latest image](https://hub.docker.com/r/datasetteproject/datasette) you should get the right SQLite version now:
docker pull datasetteproject/datasette
docker run -p 8001:8001 \
datasetteproject/datasette \
datasette -p 8001 -h 0.0.0.0
http://0.0.0.0:8001/-/versions now gives me:
```
""version"": ""3.26.0""
```",17608,
453795040,I'm really excited about this - it looks like it could be a great plugin.,17608,
453874429,"It looks like there are two reasons for this:
- The `.git` directory was listed in `.dockerignore` so it wasn't being copied into the build process
- The docker build stage wasn't installing the `git` executable, so it couldn't read the current version
",17608,
453876023,"```
docker pull datasetteproject/datasette
docker run -p 8001:8001 datasetteproject/datasette datasette -p 8001 -h 0.0.0.0
```
http://0.0.0.0:8001/-/versions now returns:
```
{
""datasette"": {
""version"": ""0.26.2+0.ga418c8b.dirty""
},
```
I'm not sure why it's showing `.dirty` there.
",17608,
455223551,"It's new in SQLite 3.26.0 so I will need to figure out how to only apply it in that version or higher.
https://sqlite.org/releaselog/3_26_0.html",17608,
455224327,https://sqlite.org/security.html has other recommmendations for apps that accept SQLite files from untrusted sources that we should apply.,17608,
455230501,"Datasette-cluster-map doesn't use the new plugin configuration mechanism yet - it really should!
The best example of how to use this mechanism right now is embedded in the Datasette unit tests:
https://github.com/simonw/datasette/blob/b7257a21bf3dfa7353980f343c83a616da44daa7/tests/fixtures.py#L266-L270
https://github.com/simonw/datasette/blob/b7257a21bf3dfa7353980f343c83a616da44daa7/tests/test_plugins.py#L139-L145",17608,
455231411,Unfortunately it looks like there isn't currently a mechanism in the Python sqlite3 library for setting configuration flags like SQLITE_DBCONFIG_DEFENSIVE,17608,
455445069,I've released a new version of the datasette-cluster-map plugin to illustrate how plugin configuration can work: https://github.com/simonw/datasette-cluster-map/commit/fcc86c450e3df3e6b81c41f31df458923181527a,17608,
455445392,"I talk about that a bit here: https://simonwillison.net/2018/Oct/4/datasette-ideas/#Bundling_the_data_with_the_code
One of the key ideas behind Datasette is that if your data is read-only you can package it up with the rest of your code - so the normal limitations that apply with hosting services like now.sh no longer prevent you from including a database. The SQLite database is just another static binary file that gets packaged up as part of your deployment.",17608,
455520561,"Thanks. I'll take a look at your changes.
I must admit I was struggling to see how to pass info from the python code in __init__.py into the javascript document.addEventListener function.",17608,
455752238,Ah. That makes much more sense. Interesting approach.,17608,
457975075,Implemented in https://github.com/simonw/datasette/commit/b5dd83981a7dbff571284d4d90a950c740245b05,17608,
457975857,"Demo: https://latest.datasette.io/fixtures-dd88475/facetable.json?_shape=array&_nl=on
Also https://b5dd839.datasette.io/fixtures-dd88475/facetable.json?_shape=array&_nl=on",17608,
457976864,"This failed in Python 3.5:
```
File ""/home/travis/virtualenv/python3.5.6/lib/python3.5/site-packages/jinja2/environment.py"", line 1020, in render_async
raise NotImplementedError('This feature is not available for this '
NotImplementedError: This feature is not available for this version of Python
```
It looks like this is caused by this feature detection code:
https://github.com/pallets/jinja/blob/a7ba0b637805c53d442e975e3864d3ea38d8743f/jinja2/utils.py#L633-L638",17608,
457978729,Will need to solve #7 for this to become truly efficient.,17608,
457980966,"Remember to remove this TODO (and turn the `[]` into `()` on this line) as part of this task:
https://github.com/simonw/sqlite-utils/blob/5309c5c7755818323a0f5353bad0de98ecc866be/sqlite_utils/cli.py#L78-L80",17608,
458011885,Re-opening for the second bit involving the cli tool.,17608,
458011906,"I tested this with a script called `churn_em_out.py`
```
i = 0
while True:
i += 1
print(
'{""id"": I, ""another"": ""row"", ""number"": J}'.replace(""I"", str(i)).replace(
""J"", str(i + 1)
)
)
```
Then I ran this:
```
python churn_em_out.py | \
sqlite-utils insert /tmp/getbig.db stats - \
--nl --batch-size=10000
```
And used `watch 'ls -lah /tmp/getbig.db'` to watch the file growing as it had 10,000 lines of junk committed in batches. The memory used by the process never grew about around 50MB.",17608,
459915995,"Do you have any simple working examples of how to use `--static`? Inspection of default served files suggests locations such as `http://example.com/-/static/app.css?0e06ee`.
If `datasette` is being proxied to `http://example.com/foo/datasette`, what form should arguments to `--static` take so that static files are correctly referenced?
Use case is here: https://github.com/psychemedia/jupyterserverproxy-datasette-demo Trying to do a really simple `datasette` demo in MyBinder using jupyter-server-proxy.",17608,
460897973,This helped my figure out what to do: https://github.com/heroku/heroku-builds/issues/36,17608,
460901857,"I'd really like to use the content-length header here, but Sanic hasn't yet fixed the bug I filed about it: https://github.com/huge-success/sanic/issues/1194",17608,
460902824,"Demo: https://latest.datasette.io/fixtures-dd88475
![]() ",17608,
463917744,is this supported or not? you can comment if it is not supported so that people like me can stop trying.,17608,
464341721,We also get an error if a column name contains a `.`,17608,
466325528,"I ran into the same issue when trying to install datasette on windows after successfully using it on linux. Unfortunately, there has not been any progress in implementing uvloop for windows - so I recommend not to use it on win. You can read about this issue here:
[https://github.com/MagicStack/uvloop/issues/14](url)",17608,
466695500,"Fixed in https://github.com/simonw/sqlite-utils/commit/228d595f7d10994f34e948888093c2cd290267c4
",17608,
463917744,is this supported or not? you can comment if it is not supported so that people like me can stop trying.,17608,
464341721,We also get an error if a column name contains a `.`,17608,
466325528,"I ran into the same issue when trying to install datasette on windows after successfully using it on linux. Unfortunately, there has not been any progress in implementing uvloop for windows - so I recommend not to use it on win. You can read about this issue here:
[https://github.com/MagicStack/uvloop/issues/14](url)",17608,
466695500,"Fixed in https://github.com/simonw/sqlite-utils/commit/228d595f7d10994f34e948888093c2cd290267c4
![]() ",17608,
466695672,"Rough sketch:
```
+try:
+ import numpy
+except ImportError:
+ numpy = None
+
Column = namedtuple(
""Column"", (""cid"", ""name"", ""type"", ""notnull"", ""default_value"", ""is_pk"")
)
@@ -70,6 +79,22 @@ class Database:
datetime.time: ""TEXT"",
None.__class__: ""TEXT"",
}
+ # If numpy is available, add more types
+ if numpy:
+ col_type_mapping.update({
+ numpy.int8: ""INTEGER"",
+ numpy.int16: ""INTEGER"",
+ numpy.int32: ""INTEGER"",
+ numpy.int64: ""INTEGER"",
+ numpy.uint8: ""INTEGER"",
+ numpy.uint16: ""INTEGER"",
+ numpy.uint32: ""INTEGER"",
+ numpy.uint64: ""INTEGER"",
+ numpy.float16: ""FLOAT"",
+ numpy.float32: ""FLOAT"",
+ numpy.float64: ""FLOAT"",
+ numpy.float128: ""FLOAT"",
+ })
```",17608,
466695695,Need to test this both with and without `numpy` installed.,17608,
466732039,"Example: http://api.nobelprize.org/v1/laureate.json
This includes affiliations which look like this:
""affiliations"": [
{
""name"": ""Sorbonne University"",
""city"": ""Paris"",
""country"": ""France""
}
]",17608,
466794069,"This was fixed by https://github.com/simonw/sqlite-utils/commit/228d595f7d10994f34e948888093c2cd290267c4 - see also #8
```
>>> db = sqlite_utils.Database("":memory:"")
>>> dfX=pd.DataFrame({'order':range(3),'col2':range(3)})
>>> db[""test""].upsert_all(dfX.to_dict(orient='records'))
",17608,
466695672,"Rough sketch:
```
+try:
+ import numpy
+except ImportError:
+ numpy = None
+
Column = namedtuple(
""Column"", (""cid"", ""name"", ""type"", ""notnull"", ""default_value"", ""is_pk"")
)
@@ -70,6 +79,22 @@ class Database:
datetime.time: ""TEXT"",
None.__class__: ""TEXT"",
}
+ # If numpy is available, add more types
+ if numpy:
+ col_type_mapping.update({
+ numpy.int8: ""INTEGER"",
+ numpy.int16: ""INTEGER"",
+ numpy.int32: ""INTEGER"",
+ numpy.int64: ""INTEGER"",
+ numpy.uint8: ""INTEGER"",
+ numpy.uint16: ""INTEGER"",
+ numpy.uint32: ""INTEGER"",
+ numpy.uint64: ""INTEGER"",
+ numpy.float16: ""FLOAT"",
+ numpy.float32: ""FLOAT"",
+ numpy.float64: ""FLOAT"",
+ numpy.float128: ""FLOAT"",
+ })
```",17608,
466695695,Need to test this both with and without `numpy` installed.,17608,
466732039,"Example: http://api.nobelprize.org/v1/laureate.json
This includes affiliations which look like this:
""affiliations"": [
{
""name"": ""Sorbonne University"",
""city"": ""Paris"",
""country"": ""France""
}
]",17608,
466794069,"This was fixed by https://github.com/simonw/sqlite-utils/commit/228d595f7d10994f34e948888093c2cd290267c4 - see also #8
```
>>> db = sqlite_utils.Database("":memory:"")
>>> dfX=pd.DataFrame({'order':range(3),'col2':range(3)})
>>> db[""test""].upsert_all(dfX.to_dict(orient='records'))
```",17608,
466794369,"https://www.sqlite.org/lang_createindex.html

May as well support ``--if-not-exists`` as well.",17608,
466800090,"The `WHERE` clause can be used to create partial indexes: https://www.sqlite.org/partialindex.html
I'm going to ignore it for the moment.",17608,
466800210,Likewise I'm going to ignore indexes on expressions (as opposed to just columns): https://www.sqlite.org/expridx.html,17608,
466807308,"Python API:
db[""articles""].add_foreign_key(""author_id"", ""authors"", ""id"")
CLI:
$ sqlite-utils add-foreign-key articles author_id authors id
",17608,
466820167,"It looks like the type information isn't actually used for anything at all, so this:
https://github.com/simonw/sqlite-utils/blob/f8d3b7cfe5c1950b0749d40eb2640df50b52f651/tests/test_create.py#L97-L103
Could actually be written like this:
```
fresh_db[""m2m""].insert(
{""one_id"": 1, ""two_id"": 1},
foreign_keys=(
(""one_id"", ""one"", ""id""),
(""two_id"", ""two"", ""id""),
),
)
```
",17608,
466820188,Sanity checking those foreign keys would be worthwhile.,17608,
466821200,"This involves a breaking API change. I need to call that out in the README and also fix my two other projects which use the old four-tuple version of `foreign_keys=`:
https://github.com/simonw/db-to-sqlite/blob/c2f8e93bc6bbdfd135de3656ea0f497859ae49ff/db_to_sqlite/cli.py#L30-L42
And
https://github.com/simonw/russian-ira-facebook-ads-datasette/blob/e7106710abdd7bdcae035bedd8bdaba75ae56a12/fetch_and_build_russian_ads.py#L71-L74
I'll also need to set a minimum version for `sqlite-utils` in the `db-to-sqlite` setup.py:
https://github.com/simonw/db-to-sqlite/blob/c2f8e93bc6bbdfd135de3656ea0f497859ae49ff/setup.py#L25",17608,
466823422,Re-opening this until I've fixed the other two projects.,17608,
466827533,Need to put out a new release of `sqlite-utils` so `db-to-sqlite` can depend on it.,17608,
466828503,Released: https://sqlite-utils.readthedocs.io/en/latest/changelog.html#v0-14,17608,
466830869,Both projects have been upgraded.,17608,
467264937,I'm working on a port of Datasette to Starlette which I think would fix this issue: https://github.com/encode/starlette,17608,
472844001,It seems this affects the Datasette Publish -site as well: https://github.com/simonw/datasette-publish-support/issues/3,17608,
472875713,also linking this zeit issue in case it is helpful: https://github.com/zeit/now-examples/issues/163#issuecomment-440125769,17608,
473154643,"Deployed a demo: https://datasette-optional-hash-demo.now.sh/
datasette publish now \
../demo-databses/russian-ads.db \
../demo-databses/polar-bears.db \
--branch=optional-hash \
-n datasette-optional-hash \
--alias datasette-optional-hash-demo \
--install=datasette-cluster-map \
--install=datasette-json-html
",17608,
473156513,"Still TODO: need to figure out what to do about cache TTL. Defaulting to 365 days no longer makes sense without the hash_urls setting.
Maybe drop that setting default to 0?
Here's the setting:
https://github.com/simonw/datasette/blob/9743e1d91b5f0a2b3c1c0bd6ffce8739341f43c4/datasette/app.py#L84-L86
And here's where it takes affect:
https://github.com/simonw/datasette/blob/4462a5ab2817ac0d9ffe20dafbbf27c5c5b81466/datasette/views/base.py#L491-L501",17608,
473156774,"This has been bothering me as well, especially when I try to install `datasette` and `sqlite-utils` at the same time.",17608,
473156905,"Have you tried this?
MakePoint(:Long || "", "" || :Lat)
",17608,
473157770,"Interesting idea. I can see how this would make sense if you are dealing with really long SQL queries.
My own example of a long query that might benefit from this: https://russian-ads-demo.herokuapp.com/russian-ads-a42c4e8?sql=select%0D%0A++++target_id%2C%0D%0A++++targets.name%2C%0D%0A++++count(*)+as+n%2C%0D%0A++++json_object(%0D%0A++++++++%22href%22%2C+%22%2Frussian-ads%2Ffaceted-targets%3Ftargets%3D%22+||+%0D%0A++++++++++++json_insert(%3Atargets%2C+%27%24[%27+||+json_array_length(%3Atargets)+||+%27]%27%2C+target_id)%0D%0A++++++++%2C%0D%0A++++++++%22label%22%2C+json_insert(%3Atargets%2C+%27%24[%27+||+json_array_length(%3Atargets)+||+%27]%27%2C+target_id)%0D%0A++++)+as+apply_this_facet%2C%0D%0A++++json_object(%0D%0A++++++++%22href%22%2C+%22%2Frussian-ads%2Fdisplay_ads%3F_targets_json%3D%22+||+%0D%0A++++++++++++json_insert(%3Atargets%2C+%27%24[%27+||+json_array_length(%3Atargets)+||+%27]%27%2C+target_id)%0D%0A++++++++%2C%0D%0A++++++++%22label%22%2C+%22See+%22+||+count(*)+||+%22+ads+matching+%22+||+json_insert(%3Atargets%2C+%27%24[%27+||+json_array_length(%3Atargets)+||+%27]%27%2C+target_id)%0D%0A++++)+as+browse_these_ads%0D%0Afrom+ad_targets%0D%0Ajoin+targets+on+ad_targets.target_id+%3D+targets.id%0D%0Awhere%0D%0A++++json_array_length(%3Atargets)+%3D%3D+0+or%0D%0A++++ad_id+in+(%0D%0A++++++++select+ad_id%0D%0A++++++++from+%22ad_targets%22%0D%0A++++++++where+%22ad_targets%22.target_id+in+(select+value+from+json_each(%3Atargets))%0D%0A++++++++group+by+%22ad_targets%22.ad_id%0D%0A++++++++having+count(distinct+%22ad_targets%22.target_id)+%3D+json_array_length(%3Atargets)%0D%0A++++)%0D%0A++++and+target_id+not+in+(select+value+from+json_each(%3Atargets))%0D%0Agroup+by%0D%0A++++target_id+order+by+n+desc%0D%0A&targets=[%22e6200%22]
Having a `show/hide` link would be an easy way to support this in the UI, and those could add/remove a `_hide_sql=1` parameter.",17608,
473158506,"I've been thinking about how Datasette instances could query each other for a while - it's a really interesting direction.
There are some tricky problems to solve to get this to work. There's a SQLite mechanism called ""virtual table functions"" which can implement things like this, but it's not supported by Python's `sqlite3` module out of the box.
https://github.com/coleifer/sqlite-vtfunc is a library that enables this feature. I experimented with using that to implement a function that scrapes HTML content (with an eye to accessing data from other APIs and Datasette instances) a while ago: https://github.com/coleifer/sqlite-vtfunc/issues/6
The bigger challenge is how to get this kind of thing to behave well within a Python 3 async environment. I have some ideas here but they're going to require some very crafty engineering.",17608,
473159679,"Also: if the option is False and the user visits a URL with a hash in it, should we redirect them?
I'm inclined to say no: furthermore, I'd be OK continuing to serve a far-future cache header for that case.",17608,
473160476,Thanks!,17608,
473160702,This also needs extensive tests to ensure that with the option turned on all of the redirects behave as they should.,17608,
473164038,"Demo: https://latest.datasette.io/fixtures-dd88475?sql=select+%2A+from+sortable+order+by+pk1%2C+pk2+limit+101
![]() v.s. https://latest.datasette.io/fixtures-dd88475?sql=select+%2A+from+sortable+order+by+pk1%2C+pk2+limit+101&_hide_sql=1
v.s. https://latest.datasette.io/fixtures-dd88475?sql=select+%2A+from+sortable+order+by+pk1%2C+pk2+limit+101&_hide_sql=1
![]() ",17608,
473217334,"Awesome, thanks! 😁 ",17608,
473308631,"This would allow Datasette to be easily used as a ""data library"" (like a data warehouse but less expectation of big data querying technology such as Presto).
One of the things I learned at the NICAR CAR 2019 conference in Newport Beach is that there is a very real need for some kind of easily accessible data library at most newsrooms.",17608,
473310026,See #418 ,17608,
473312514,"A neat ability of Datasette Library would be if it can work against other files that have been dropped into the folder. In particular: if a user drops a CSV file into the folder, how about automatically converting that CSV file to SQLite using [sqlite-utils](https://github.com/simonw/sqlite-utils)?",17608,
473313975,"I'm reopening this one as part of #417.
Further experience with Python's CSV standard library module has convinced me that pandas is not a required dependency for this. My [sqlite-utils](https://github.com/simonw/sqlite-utils) package can do most of the work here with very few dependencies.",17608,
473323329,"How would Datasette accepting URLs work?
I want to support not just SQLite files and CSVs but other extensible formats (geojson, Atom, shapefiles etc) as well.
So `datasette serve` needs to be able to take filepaths or URLs to a variety of different content types.
If it's a URL, we can use the first 200 downloaded bytes to decide which type of file it is. This is likely more reliable than hoping the web server provided the correct content-type.
Also: let's have a threshold for downloading to disk. We will start downloading to a temp file (location controlled by an environment variable) if either the content length header is above that threshold OR we hit that much data cached in memory already and don't know how much more is still to come.
There needs to be a command line option for saying ""grab from this URL but force treat it as CSV"" - same thing for files on disk.
datasette mydb.db --type=db http://blah/blah --type=csv
If you provide less `--type` options thatn you did URLs then the default behavior is used for all of the subsequent URLs.
Auto detection could be tricky. Probably do this with a plugin hook.
https://github.com/h2non/filetype.py is interesting but deals with images video etc so not right for this purpose.
I think we need our own simple content sniffing code via a plugin hook.
What if two plugin type hooks can both potentially handle a sniffed file? The CLI can quit and return an error saying content is ambiguous and you need to specify a `--type`, picking from the following list.
",17608,
473708724,"Thinking about this further: I think I may have made a mistake establishing ""immutable"" as the default mode for databases opened by Datasette.
What would it look like if files were NOT opened in immutable mode by default?
Maybe the command to start Datasette looks like this:
datasette mutable1.db mutable2.db --immutable=this_is_immutable.db --immutable=this_is_immutable2.db
So regular file arguments are treated as mutable (and opened in `?mode=ro`) while file arguments passed using the new `--immutable` option are opened in immutable mode.
The `-i` shortcut has not yet been taken, so this could be abbreviated to:
datasette mutable1.db mutable2.db -i this_is_immutable.db -i this_is_immutable2.db",17608,
473708941,"Some problems to solve:
* Right now Datasette assumes it can always show the count of rows in a table, because this has been pre-calculated. If a database is mutable the pre-calculation trick no longer works, and for giant tables a `select count(*) from X` query can be expensive to run. Maybe we set a time limit on these? If time limit expires show ""many rows""?
* Maintaining a content hash of the table no longer makes sense if it is changing (though interestingly there's a `.sha3sum` built-in SQLite CLI command which takes a hash of the content and stays the same even through vacuum runs). Without that we need a different mechanism for calculating table colours. It also means that we can't do the special dbname-hash URL trick (see #418) at all if the database is opened as mutable.",17608,
473709815,"In #419 I'm now proposing that Datasette default to opening files in ""mutable"" mode, in which case it would not make sense to support hash URLs for those files at all. So actually this feature will only be available for files that are explicitly opened in immutable mode.",17608,
473709883,"Could I persist the last calculated count for a table and somehow detect if that table has been changed in any way by another process, hence invalidating the cached count (and potentially scheduling a new count)?
https://www.sqlite.org/c3ref/update_hook.html says that `sqlite3_update_hook()` can be used to register a handler invoked on almost all update/insert/delete operations to a specific table... except that it misses out on deletes triggered by `ON CONFLICT REPLACE` and only works for `ROWID` tables.
Also this hook is not exposed in the Python `sqlite3` library - though it may be available using some terrifying `ctypes` hacks: https://stackoverflow.com/a/16920926
So on further research, I think the answer is *no*: I should assume that it won't be possible to cache counts and magically invalidate the cache when the underlying file is changed by another process.
Instead I need to assume that counts will be an expensive operation.
As such, I can introduce a time limit on counts and use that anywhere a count is displayed. If the time limit is exceeded by the `count(*)` query I can show ""many"" instead.
That said... running `count(*)` against a table with 200,000 rows in only takes about 3ms, so even a timeout of 20ms is likely to work fine for tables of around a million rows.
It would be really neat if I could generate a lower bound count in a limited amount of time. If I counted up to 4m rows before the timeout I could show ""more than 4m rows"". No idea if that would be possible though.
Relevant: https://stackoverflow.com/questions/8988915/sqlite-count-slow-on-big-tables - reports of very slow counts on 6GB database file. Consensus seems to be ""yeah, that's just how SQLite is built"" - though there was a suggestion that you can use `select max(ROWID) from table` provided you are certain there have been no deletions.
Also relevant: http://sqlite.1065341.n5.nabble.com/sqlite3-performance-on-select-count-very-slow-for-16-GB-file-td80176.html",17608,
473712820,"So the differences here are:
* For immutable databases we calculate content hash and table counts; mutable databases we do not
* Immutable databasse open with `file:{}?immutable=1`, mutable databases open with `file:{}?mode=ro`
* Anywhere that shows a table count now needs to call a new method which knows to run `count(*)` with a timeout for mutable databases, read from the precalculated counts for immutable databases
* The url-hash option should no longer be available at all for mutable databases
* New command-line tool syntax: `datasette mutable.db` v.s. `datasette -i immutable.db`",17608,
",17608,
473217334,"Awesome, thanks! 😁 ",17608,
473308631,"This would allow Datasette to be easily used as a ""data library"" (like a data warehouse but less expectation of big data querying technology such as Presto).
One of the things I learned at the NICAR CAR 2019 conference in Newport Beach is that there is a very real need for some kind of easily accessible data library at most newsrooms.",17608,
473310026,See #418 ,17608,
473312514,"A neat ability of Datasette Library would be if it can work against other files that have been dropped into the folder. In particular: if a user drops a CSV file into the folder, how about automatically converting that CSV file to SQLite using [sqlite-utils](https://github.com/simonw/sqlite-utils)?",17608,
473313975,"I'm reopening this one as part of #417.
Further experience with Python's CSV standard library module has convinced me that pandas is not a required dependency for this. My [sqlite-utils](https://github.com/simonw/sqlite-utils) package can do most of the work here with very few dependencies.",17608,
473323329,"How would Datasette accepting URLs work?
I want to support not just SQLite files and CSVs but other extensible formats (geojson, Atom, shapefiles etc) as well.
So `datasette serve` needs to be able to take filepaths or URLs to a variety of different content types.
If it's a URL, we can use the first 200 downloaded bytes to decide which type of file it is. This is likely more reliable than hoping the web server provided the correct content-type.
Also: let's have a threshold for downloading to disk. We will start downloading to a temp file (location controlled by an environment variable) if either the content length header is above that threshold OR we hit that much data cached in memory already and don't know how much more is still to come.
There needs to be a command line option for saying ""grab from this URL but force treat it as CSV"" - same thing for files on disk.
datasette mydb.db --type=db http://blah/blah --type=csv
If you provide less `--type` options thatn you did URLs then the default behavior is used for all of the subsequent URLs.
Auto detection could be tricky. Probably do this with a plugin hook.
https://github.com/h2non/filetype.py is interesting but deals with images video etc so not right for this purpose.
I think we need our own simple content sniffing code via a plugin hook.
What if two plugin type hooks can both potentially handle a sniffed file? The CLI can quit and return an error saying content is ambiguous and you need to specify a `--type`, picking from the following list.
",17608,
473708724,"Thinking about this further: I think I may have made a mistake establishing ""immutable"" as the default mode for databases opened by Datasette.
What would it look like if files were NOT opened in immutable mode by default?
Maybe the command to start Datasette looks like this:
datasette mutable1.db mutable2.db --immutable=this_is_immutable.db --immutable=this_is_immutable2.db
So regular file arguments are treated as mutable (and opened in `?mode=ro`) while file arguments passed using the new `--immutable` option are opened in immutable mode.
The `-i` shortcut has not yet been taken, so this could be abbreviated to:
datasette mutable1.db mutable2.db -i this_is_immutable.db -i this_is_immutable2.db",17608,
473708941,"Some problems to solve:
* Right now Datasette assumes it can always show the count of rows in a table, because this has been pre-calculated. If a database is mutable the pre-calculation trick no longer works, and for giant tables a `select count(*) from X` query can be expensive to run. Maybe we set a time limit on these? If time limit expires show ""many rows""?
* Maintaining a content hash of the table no longer makes sense if it is changing (though interestingly there's a `.sha3sum` built-in SQLite CLI command which takes a hash of the content and stays the same even through vacuum runs). Without that we need a different mechanism for calculating table colours. It also means that we can't do the special dbname-hash URL trick (see #418) at all if the database is opened as mutable.",17608,
473709815,"In #419 I'm now proposing that Datasette default to opening files in ""mutable"" mode, in which case it would not make sense to support hash URLs for those files at all. So actually this feature will only be available for files that are explicitly opened in immutable mode.",17608,
473709883,"Could I persist the last calculated count for a table and somehow detect if that table has been changed in any way by another process, hence invalidating the cached count (and potentially scheduling a new count)?
https://www.sqlite.org/c3ref/update_hook.html says that `sqlite3_update_hook()` can be used to register a handler invoked on almost all update/insert/delete operations to a specific table... except that it misses out on deletes triggered by `ON CONFLICT REPLACE` and only works for `ROWID` tables.
Also this hook is not exposed in the Python `sqlite3` library - though it may be available using some terrifying `ctypes` hacks: https://stackoverflow.com/a/16920926
So on further research, I think the answer is *no*: I should assume that it won't be possible to cache counts and magically invalidate the cache when the underlying file is changed by another process.
Instead I need to assume that counts will be an expensive operation.
As such, I can introduce a time limit on counts and use that anywhere a count is displayed. If the time limit is exceeded by the `count(*)` query I can show ""many"" instead.
That said... running `count(*)` against a table with 200,000 rows in only takes about 3ms, so even a timeout of 20ms is likely to work fine for tables of around a million rows.
It would be really neat if I could generate a lower bound count in a limited amount of time. If I counted up to 4m rows before the timeout I could show ""more than 4m rows"". No idea if that would be possible though.
Relevant: https://stackoverflow.com/questions/8988915/sqlite-count-slow-on-big-tables - reports of very slow counts on 6GB database file. Consensus seems to be ""yeah, that's just how SQLite is built"" - though there was a suggestion that you can use `select max(ROWID) from table` provided you are certain there have been no deletions.
Also relevant: http://sqlite.1065341.n5.nabble.com/sqlite3-performance-on-select-count-very-slow-for-16-GB-file-td80176.html",17608,
473712820,"So the differences here are:
* For immutable databases we calculate content hash and table counts; mutable databases we do not
* Immutable databasse open with `file:{}?immutable=1`, mutable databases open with `file:{}?mode=ro`
* Anywhere that shows a table count now needs to call a new method which knows to run `count(*)` with a timeout for mutable databases, read from the precalculated counts for immutable databases
* The url-hash option should no longer be available at all for mutable databases
* New command-line tool syntax: `datasette mutable.db` v.s. `datasette -i immutable.db`",17608,
|