id,node_id,number,title,user,state,locked,assignee,milestone,comments,created_at,updated_at,closed_at,author_association,pull_request,body,repo,type,active_lock_reason,performed_via_github_app,reactions,draft,state_reason
1976986318,I_kwDOCGYnMM511mrO,599,Cannot find spatialite on arm64 linux,37802088,closed,0,,,1,2023-11-03T22:05:51Z,2023-11-04T01:06:31Z,2023-11-04T00:33:28Z,CONTRIBUTOR,,"Initially, I found an issue in `datasette` where it wouldn’t find `spatialite` when running on my Radxa Rock 5B - an RK3588 powered SBC, running the arm64 build of Debian Bullseye. I confirmed the same behaviour on my Raspberry Pi 4 - a BCM2711 powered SBC, running the arm64 build of Debian Bookworm.
```
$ datasette --load-extension=spatialite example.db
Error: Could not find SpatiaLite extension
```
I did some digging and realised the issue originates in this project. Even with the `libsqlite3-mod-spatialite` package installed, `pytest` skips all of the GIS tests in the project.
```
$ apt list --installed | grep spatial
[…]
libsqlite3-mod-spatialite/stable,now 5.0.1-3 arm64 [installed]
$ ls -l /usr/lib/*/*spatial*
lrwxrwxrwx 1 root root 23 Dec 1 2022 /usr/lib/aarch64-linux-gnu/mod_spatialite.so -> mod_spatialite.so.7.1.0
lrwxrwxrwx 1 root root 23 Dec 1 2022 /usr/lib/aarch64-linux-gnu/mod_spatialite.so.7 -> mod_spatialite.so.7.1.0
-rw-r--r-- 1 root root 7348584 Dec 1 2022 /usr/lib/aarch64-linux-gnu/mod_spatialite.so.7.1.0
```
```
$ pytest
tests/test_get.py ...... [ 73%]
tests/test_gis.py ssssssssssss [ 75%]
tests/test_hypothesis.py .... [ 75%]
```
I tracked the issue down to the [`find_sqlite()` function in the `utils.py`](https://github.com/simonw/sqlite-utils/blob/622c3a5a7dd53a09c029e2af40c2643fe7579340/sqlite_utils/utils.py#L60) file. The [`SPATIALITE_PATHS`](https://github.com/simonw/sqlite-utils/blob/main/sqlite_utils/utils.py#L34-L39) array doesn’t have an entry for the location of this module on arm64 linux.
",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/599/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1239034903,I_kwDOCGYnMM5J2iwX,433,CLI eats my cursor,7908073,closed,0,,,10,2022-05-17T18:52:52Z,2023-11-04T00:46:30Z,2023-11-04T00:46:30Z,CONTRIBUTOR,,"I'm not sure why this happens but `sqlite-utils` makes my terminal cursor disappear after running commands like `sqlite-utils insert`. I've only noticed this behavior in `sqlite-utils`, not in any other CLI tools
I can still type commands after it runs but the text cursor is invisible",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/433/reactions"", ""total_count"": 5, ""+1"": 5, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1801394744,I_kwDOCGYnMM5rXxo4,567,Plugin system,15178711,closed,0,,,9,2023-07-12T17:02:14Z,2023-07-22T22:59:37Z,2023-07-22T22:59:36Z,CONTRIBUTOR,,"I'd like there to be a plugin system for sqlite-utils, similar to the datasette/llm plugins. I'd like to make plugins that would do things like:
- Register SQLite extensions for more SQL functions + virtual tables
- Register new subcommands
- Different input file formats for `sqlite-utils memory`
- Different output file formats (in addition to `--csv` `--tsv` `--nl` etc.
A few real-world use-cases of plugins I'd like to see in sqlite-utils:
- Register many of my sqlite extensions in sqlite-utils (`sqlite-http`, `sqlite-lines`, `sqlite-regex`, etc.)
- New subcommands to work with `sqlite-vss` vector tables
- Input/ouput Parquet/Avro/Arrow IPC files with `sqlite-arrow`",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/567/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1655860104,I_kwDOCGYnMM5ismuI,535,rows: --transpose or psql extended view-like functionality,7908073,closed,0,,,2,2023-04-05T15:37:33Z,2023-06-15T08:39:49Z,2023-06-14T22:05:28Z,CONTRIBUTOR,,"It would be nice if the rows subcommand had a flag, perhaps called `--transpose` which would print in long form instead of wide. Similar to extended display mode in psql (`\x`)
In other words instead of this:
```
sqlite-utils rows --limit 5 --fmt github track_metadata.db songs
```
| track_id | title | song_id | release | artist_id | artist_mbid | artist_name | duration | artist_familiarity | artist_hotttnesss | year | track_7digitalid | shs_perf | shs_work |
|--------------------|-------------------|--------------------|--------------------------------------|--------------------|--------------------------------------|------------------|------------|----------------------|---------------------|--------|--------------------|------------|------------|
| TRMMMYQ128F932D901 | Silent Night | SOQMMHC12AB0180CB8 | Monster Ballads X-Mas | ARYZTJS1187B98C555 | 357ff05d-848a-44cf-b608-cb34b5701ae5 | Faster Pussy cat | 252.055 | 0.649822 | 0.394032 | 2003 | 7032331 | -1 | 0 |
| TRMMMKD128F425225D | Tanssi vaan | SOVFVAK12A8C1350D9 | Karkuteillä | ARMVN3U1187FB3A1EB | 8d7ef530-a6fd-4f8f-b2e2-74aec765e0f9 | Karkkiautomaatti | 156.551 | 0.439604 | 0.356992 | 1995 | 1514808 | -1 | 0 |
| TRMMMRX128F93187D9 | No One Could Ever | SOGTUKN12AB017F4F1 | Butter | ARGEKB01187FB50750 | 3d403d44-36ce-465c-ad43-ae877e65adc4 | Hudson Mohawke | 138.971 | 0.643681 | 0.437504 | 2006 | 6945353 | -1 | 0 |
| TRMMMCH128F425532C | Si Vos Querés | SOBNYVR12A8C13558C | De Culo | ARNWYLR1187B9B2F9C | 12be7648-7094-495f-90e6-df4189d68615 | Yerba Brava | 145.058 | 0.448501 | 0.372349 | 2003 | 2168257 | -1 | 0 |
| TRMMMWA128F426B589 | Tangle Of Aspens | SOHSBXH12A8C13B0DF | Rene Ablaze Presents Winter Sessions | AREQDTE1269FB37231 | | Der Mystic | 514.298 | 0 | 0 | 0 | 2264873 | -1 | 0 |
The output would look something like this:
```
$ for col in (sqlite-columns track_metadata.db songs)
sqlite-utils --fmt github track_metadata.db ""select $col from songs order by rowid desc limit 5""
end
```
| track_id |
|--------------------|
| TRYYYVU12903CD01E3 |
| TRYYYDJ128F9310A21 |
| TRYYYMG128F4260ECA |
| TRYYYJO128F426DA37 |
| TRYYYUS12903CD2DF0 |
| title |
|-------------------------------------|
| Fernweh feat. Sektion Kuchikäschtli |
| Faraday |
| Novemba |
| Jago Chhadeo |
| O Samba Da Vida |
| song_id |
|--------------------|
| SOWXJXQ12AB0189F43 |
| SOLXGOR12A81C21EB7 |
| SOHODZI12A8C137BB3 |
| SOXQYIQ12A8C137FBB |
| SOTXAME12AB018F136 |
| release |
|---------------------------------|
| So Oder So |
| The Trance Collection Vol. 2 |
| Dub_Connected: electronic music |
| Naale Baba Lassi Pee Gya |
| Pacha V.I.P. |
| artist_id |
|--------------------|
| AR7PLM21187B990D08 |
| ARCMCOK1187B9B1073 |
| ARZ3R6M1187B9AF750 |
| ART5FZD1187B9A7FCF |
| AR7Z4J81187FB3FC59 |
| artist_mbid |
|--------------------------------------|
| 3af2b07e-c91c-4160-9bda-f0b9e3144ed3 |
| 4ac5f3de-c5ad-475e-ad50-41f1ef9dba20 |
| 8b97e9c8-61f5-4615-9a96-276f24204e34 |
| 2357c400-9109-42b6-b3fe-9e2d9f8e3872 |
| 9d50cb20-7e42-45cc-b0dd-154c3e92a577 |
| artist_name |
|----------------|
| Texta |
| Elude |
| Gabriel Le Mar |
| Kuldeep Manak |
| Kiko Navarro |
| duration |
|------------|
| 295.079 |
| 484.519 |
| 553.038 |
| 244.166 |
| 217.443 |
| artist_familiarity |
|----------------------|
| 0.552977 |
| 0.403668 |
| 0.556918 |
| 0.4015 |
| 0.528617 |
| artist_hotttnesss |
|---------------------|
| 0.454869 |
| 0.256935 |
| 0.336914 |
| 0.374866 |
| 0.411595 |
| year |
|--------|
| 2004 |
| 0 |
| 0 |
| 0 |
| 0 |
| track_7digitalid |
|--------------------|
| 8486723 |
| 5472456 |
| 2219291 |
| 1632096 |
| 7522478 |
| shs_perf |
|------------|
| -1 |
| -1 |
| -1 |
| -1 |
| -1 |
| shs_work |
|------------|
| 0 |
| 0 |
| 0 |
| 0 |
| 0 |
",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/535/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1581090327,I_kwDOCGYnMM5ePYYX,529,Microsoft line endings,7908073,closed,0,,,1,2023-02-12T02:20:48Z,2023-06-14T23:12:12Z,2023-06-14T23:11:47Z,CONTRIBUTOR,,"sqlite-utils prints `\r\n` but [it should probably](https://devblogs.microsoft.com/commandline/extended-eol-in-notepad/) print `\n` (unless the platform is detected as Windows?)
It has tripped me up a few times when piping the output of sqlite-utils to other programs:
```
$ sqlite-utils --no-headers --csv ~/lb/fs/d.db 'select path from media limit 1' | cat -A
/mnt/d7/file^M$
$ sqlite-utils --no-headers --csv ~/lb/fs/d.db 'select path from media limit 1' | tr -d '\r' | cat -A
/mnt/d7/file$
```",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/529/reactions"", ""total_count"": 1, ""+1"": 1, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1740150327,I_kwDOCGYnMM5nuJY3,557,Aliased ROWID option for tables created from alter=True commands,7908073,closed,0,,,2,2023-06-04T05:29:28Z,2023-06-14T06:09:21Z,2023-06-05T19:26:26Z,CONTRIBUTOR,,"> If you use INTEGER PRIMARY KEY column, the VACUUM does not change the values of that column. However, if you use unaliased rowid, the VACUUM command will reset the rowid values.
ROWID should never be used with foreign keys but the simple act of aliasing rowid to id (which is what happens when one does `id integer primary key` DDL) makes it OK.
It would be convenient if there were more options to use a string column (eg. filepath) as the PK, and be able to use it during upserts, but when creating a foreign key, to create an integer column which aliases rowid
I made an attempt to switch to integer primary keys here but it is not going well... In my usecase the path column is a business key. Yes, it should be as simple as including the `id` column in any select statement where I plan on using `upsert` but it would be nice if this could be abstracted away somehow https://github.com/chapmanjacobd/library/commit/788cd125be01d76f0fe2153335d9f6b21db1343c
https://github.com/chapmanjacobd/library/actions/runs/5173602136/jobs/9319024777",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/557/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1578790070,I_kwDOCGYnMM5eGmy2,527,`Table.convert()` skips falsey values,167893,closed,0,,,5,2023-02-10T00:00:52Z,2023-05-09T21:15:05Z,2023-05-08T21:03:24Z,CONTRIBUTOR,,"# Summary
By design, `Table.convert()` does [not attempt](https://github.com/simonw/sqlite-utils/blob/fc221f9b62ed8624b1d2098e564f525c84497969/sqlite_utils/db.py#L2663) conversion of falsey values (`None`, `""""`, `0`, ...). This is surprising (directly contradicts the docstring) and `convert()` may quietly skip cells where the user assumed a conversion would take place.
# Example
Increment a column of integers by one
``` python
from sqlite_utils import Database
db = Database(memory=True)
table = db['table']
col = 'x'
table.insert_all([{col: 0}, {col:1}])
print(table.get(1)) # 0
print(table.get(2)) # 1
print()
table.convert(col, lambda x: x+1)
print(table.get(1)) # got 0, expected 1 ⚠⚠⚠
print(table.get(2)) # got 2, expected 2
```
Another example might be, say, transforming cells containing empty string to `NULL`.
# Discussion
This was, I think, a pragmatic choice so that consumers can skip writing guard clauses for these falsey values (particularly from the CLI). But this surprising undocumented behavior can lead to incorrect data. I don't think this is a good trade-off between convenience and correctness.
In the absence of this convenience users will either have to write guard clauses into their conversion expressions (or adapt the called function to do the same), so:
``` python
fn(value) if value else value
```
instead of:
``` python
fn(value)
```
This is more typing and sometimes I will forget, and there will be errors. (But they will be noisy errors, which is a good thing).
Such a change will certainly inconvenience some existing consumers; there will be some breakage. But I think this is worth it to avoid quietly not converting some values by default, which can lead to quietly bad data.
I have a PR that I will attach, please take a look and see what you think.",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/527/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1575131737,I_kwDOCGYnMM5d4ppZ,525,Repeated calls to `Table.convert()` fail,167893,closed,0,,,4,2023-02-07T22:40:47Z,2023-05-08T21:59:41Z,2023-05-08T21:54:02Z,CONTRIBUTOR,,"## Summary
When using the API, repeated calls to `Table.convert()` do not work correctly since all conversions quietly use the callable (function, lambda) from the first call to `convert()` only. Subsequent invocations with different callables use the callable from the first invocation only.
## Example
```python
from sqlite_utils import Database
db = Database(memory=True)
table = db['table']
col = 'x'
table.insert_all([{col: 1}])
print(table.get(1))
table.convert(col, lambda x: x*2)
print(table.get(1))
def zeroize(x):
return 0
#zeroize = lambda x: 0
#zeroize.__name__ = 'zeroize'
table.convert(col, zeroize)
print(table.get(1))
```
Output:
```
{'x': 1}
{'x': 2}
{'x': 4}
```
Expected:
```
{'x': 1}
{'x': 2}
{'x': 0}
```
## Explanation
This is some relevant [documentation](https://github.com/simonw/sqlite-utils/blob/1491b66dd7439dd87cd5cd4c4684f46eb3c5751b/docs/python-api.rst#registering-custom-sql-functions:~:text=By%20default%20registering%20a%20function%20with%20the%20same%20name%20and%20number%20of%20arguments%20will%20have%20no%20effect).
* `Table.convert()` takes a `Callable` to perform data conversion on a column
* The `Callable` is passed to `Database.register_function()`
* `Database.register_function()` uses the callable's `__name__` attribute for registration
* (Aside: all lambdas have a `__name__` of `<lambda>`: I thought this was the problem, and it was close, but not quite)
* However `convert()` first wraps the callable by local function [`convert_value()`](https://github.com/simonw/sqlite-utils/blob/fc221f9b62ed8624b1d2098e564f525c84497969/sqlite_utils/db.py#L2661)
* Consequently `register_function()` sees name `convert_value` for all invocations from `convert()`
* `register_function()` silently ignores registrations using the same name, retaining only the first such registration
There's a mismatch between the comments and the code: https://github.com/simonw/sqlite-utils/blob/fc221f9b62ed8624b1d2098e564f525c84497969/sqlite_utils/db.py#L404
but actually the existing function is returned/used instead (as the ""registering custom sql functions"" doc I linked above says too). Seems like this can be rectified to match the comment?
## Suggested fix
I think there are four things:
1. The call to `register_function()` from `convert()`should have an explicit `name=` parameter (to continue using `convert_value()` and the progress bar).
2. For functions, this name can be the real function name. (I understand the sqlite api needs a name, and it's nice if those are recognizable names where possible). For lambdas would `'lambda-{uuid}'` or similar be acceptable?
3. `register_function()` really should throw an error on repeated attempts to register a duplicate (function, arity)-pair.
4. A test? I haven't looked at the test framework here but seems this should be testable.
## See also
- #458 ",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/525/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1044267332,I_kwDOCGYnMM4-PkFE,336,"sqlite-util tranform --column-order mangles columns of type ""timestamp""",536941,closed,0,,,1,2021-11-04T01:15:38Z,2023-05-08T21:13:38Z,2023-05-08T21:13:38Z,CONTRIBUTOR,,"Reproducible code below:
```bash
> echo 'create table bar (baz text, created_at timestamp default CURRENT_TIMESTAMP)' | sqlite3 foo.db
> sqlite3 foo.db
SQLite version 3.36.0 2021-06-18 18:36:39
Enter "".help"" for usage hints.
sqlite> .schema bar
CREATE TABLE bar (baz text, created_at timestamp default CURRENT_TIMESTAMP);
sqlite> .exit
> sqlite-utils transform foo.db bar --column-order baz
sqlite3 foo.db
SQLite version 3.36.0 2021-06-18 18:36:39
Enter "".help"" for usage hints.
sqlite> .schema bar
CREATE TABLE IF NOT EXISTS ""bar"" (
[baz] TEXT,
[created_at] FLOAT DEFAULT 'CURRENT_TIMESTAMP'
);
sqlite> .exit
> sqlite-utils transform foo.db bar --column-order baz
> sqlite3 foo.db
SQLite version 3.36.0 2021-06-18 18:36:39
Enter "".help"" for usage hints.
sqlite> .schema bar
CREATE TABLE IF NOT EXISTS ""bar"" (
[baz] TEXT,
[created_at] FLOAT DEFAULT '''CURRENT_TIMESTAMP'''
);
```
",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/336/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1436539554,I_kwDOCGYnMM5Vn9qi,511,"[insert_all, upsert_all] IntegrityError: constraint failed",7908073,closed,0,,,2,2022-11-04T19:21:48Z,2022-11-04T22:59:54Z,2022-11-04T22:54:09Z,CONTRIBUTOR,,"My understand is that `INSERT OR IGNORE` will ignore when inserts would cause duplicate keys so I'm not sure exactly why the error is raised from `sqlite3`.
```
import argparse
from pathlib import Path
from xklb import db, utils
from xklb.utils import log
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument(""database"")
parser.add_argument(""dbs"", nargs=""*"")
parser.add_argument(""--upsert"")
parser.add_argument(""--db"", ""-db"", help=argparse.SUPPRESS)
parser.add_argument(""--verbose"", ""-v"", action=""count"", default=0)
args = parser.parse_args()
if args.db:
args.database = args.db
Path(args.database).touch()
args.db = db.connect(args)
log.info(utils.dict_filter_bool(args.__dict__))
return args
def merge_db(args, source_db):
source_db = str(Path(source_db).resolve())
s_db = db.connect(argparse.Namespace(database=source_db, verbose=args.verbose))
for table in [s for s in s_db.table_names() if not ""_fts"" in s and not s.startswith(""sqlite_"")]:
log.info(""[%s]: %s"", source_db, table)
with s_db.conn:
data = s_db[table].rows
with args.db.conn:
if args.upsert:
args.db[table].upsert_all(data, pk=args.upsert.split("",""), alter=True)
else:
args.db[table].insert_all(data, alter=True, replace=True)
def merge_dbs():
args = parse_args()
for s_db in args.dbs:
merge_db(args, s_db)
if __name__ == ""__main__"":
merge_dbs()
```
```
$ lb-dev merge video.db tube_71.db --upsert path -vv
SQL: INSERT OR IGNORE INTO [media]([path]) VALUES(?); - params: ['https://archive.org/details/088ghostofachanceroygetssackedrevengeofthelivinglunchdvdripxvidphz']
...
File ~/.local/lib/python3.10/site-packages/sqlite_utils/db.py:3122, in Table.insert_all(self, records, pk, foreign_keys, column_order, not_null, defaults, batch_size, hash_id, hash_id_columns, alter, ignore, replace, truncate, extracts, conversions, columns, upsert, analyze)
3116 all_columns += [
3117 column for column in record if column not in all_columns
3118 ]
3120 first = False
-> 3122 self.insert_chunk(
3123 alter,
3124 extracts,
3125 chunk,
3126 all_columns,
3127 hash_id,
3128 hash_id_columns,
3129 upsert,
3130 pk,
3131 conversions,
3132 num_records_processed,
3133 replace,
3134 ignore,
3135 )
3137 if analyze:
3138 self.analyze()
File ~/.local/lib/python3.10/site-packages/sqlite_utils/db.py:2887, in Table.insert_chunk(self, alter, extracts, chunk, all_columns, hash_id, hash_id_columns, upsert, pk, conversions, num_records_processed, replace, ignore)
2885 for query, params in queries_and_params:
2886 try:
-> 2887 result = self.db.execute(query, params)
2888 except OperationalError as e:
2889 if alter and ("" column"" in e.args[0]):
2890 # Attempt to add any missing columns, then try again
File ~/.local/lib/python3.10/site-packages/sqlite_utils/db.py:484, in Database.execute(self, sql, parameters)
482 self._tracer(sql, parameters)
483 if parameters is not None:
--> 484 return self.conn.execute(sql, parameters)
485 else:
486 return self.conn.execute(sql)
IntegrityError: constraint failed
> /home/xk/.local/lib/python3.10/site-packages/sqlite_utils/db.py(484)execute()
482 self._tracer(sql, parameters)
483 if parameters is not None:
--> 484 return self.conn.execute(sql, parameters)
485 else:
486 return self.conn.execute(sql)
```
```
sqlite3 --version
3.36.0 2021-06-18 18:36:39
```",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/511/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1430325103,I_kwDOCGYnMM5VQQdv,507,conn.execute: UnicodeEncodeError: 'utf-8' codec can't encode character,7908073,closed,0,,,1,2022-10-31T18:49:51Z,2022-11-01T00:40:17Z,2022-11-01T00:40:16Z,CONTRIBUTOR,,"I'm not really sure what caused this and it happened in the middle of my program (after running for 35775 seconds).
```
Extracting metadata 49.9% (chunk 9893 of 19831)
...
File ""/home/xk/.local/lib/python3.10/site-packages/xklb/fs_extract.py"", line 90, in extract_chunk
args.db[""media""].insert_all(utils.list_dict_filter_bool(media), pk=""path"", alter=True, replace=True)
File ""/home/xk/.local/lib/python3.10/site-packages/sqlite_utils/db.py"", line 3107, in insert_all
self.insert_chunk(
File ""/home/xk/.local/lib/python3.10/site-packages/sqlite_utils/db.py"", line 2872, in insert_chunk
result = self.db.execute(query, params)
File ""/home/xk/.local/lib/python3.10/site-packages/sqlite_utils/db.py"", line 483, in execute
return self.conn.execute(sql, parameters)
UnicodeEncodeError: 'utf-8' codec can't encode character '\udcc3' in position 62: surrogates not allowed
```
This might be relevant: https://stackoverflow.com/questions/31898353/python-cant-encode-with-surrogateescape
I'm going to try re-running with
```py
def execute(
self, sql: str, parameters: Optional[Union[Iterable, dict]] = None
) -> sqlite3.Cursor:
""""""
Execute SQL query and return a ``sqlite3.Cursor``.
:param sql: SQL query to execute
:param parameters: Parameters to use in that query - an iterable for ``where id = ?``
parameters, or a dictionary for ``where id = :id``
""""""
try:
if self._tracer:
self._tracer(sql, parameters)
if parameters is not None:
return self.conn.execute(sql, parameters)
else:
return self.conn.execute(sql)
except UnicodeEncodeError:
sql = sql.encode('utf-8', 'surrogatepass').decode('utf-8')
if parameters is not None:
parameters = parameters.encode('utf-8', 'surrogatepass').decode('utf-8')
return self.execute(sql, parameters)
```",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/507/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1393212964,I_kwDOCGYnMM5TCr4k,497,column_names,7908073,closed,0,,,1,2022-10-01T03:34:21Z,2022-10-25T21:09:28Z,2022-10-25T21:09:28Z,CONTRIBUTOR,,"It would be nice to have a `column_names`. Similar to `table_names`.
Or if you could get one or all of the following syntax to work for both Database and Table that might be even better:
Style 1
- `if 'table1' in db`
- `if 'col1' in db['table1']`
Style 2
- `if 'table1' in db.tables`
- `if 'col1' in db['table1'].columns`
maybe the table ones actually work but I'm too lazy to check. I just know that I have to do:
`[c.name for c in db['table1'].columns]`
Edit: This is possible with `columns_dict`. I have actually used that before but I forgot about it. Feel free to close, but I do think accessing this data could be more consistent and intuitive.",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/497/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1361355564,I_kwDOCGYnMM5RJKMs,482,balanced table default column_order,7908073,closed,0,,,1,2022-09-05T03:00:18Z,2022-10-10T17:43:02Z,2022-09-06T20:17:27Z,CONTRIBUTOR,,"Is there any performance or size difference with column order in SQLITE ? similar to this https://www.cybertec-postgresql.com/en/column-order-in-postgresql-does-matter/
It might be interesting to have an option to create with an optimized column order. I'm assuming this would look something like INTEGER columns, REAL columns, BLOB columns, TEXT columns, NULL columns. NULL columns at the end because they are more likely to be TEXT and it is impossible to know if they will become INTEGER
(Of course, any schema evolution would reduce optimization but maybe column order could also be re-evaluated when schema changes)
edit:
this is easy to accomplish with the existing `transform` method:
```
int_columns = [k for k, v in table_columns.items() if v == int]
db[table].transform(column_order=[*int_columns])
```",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/482/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1366423176,I_kwDOCGYnMM5RcfaI,485,Progressbar not shown when inserting/upserting jsonlines file,99098079,closed,0,,,1,2022-09-08T14:13:18Z,2022-09-15T20:39:52Z,2022-09-15T20:37:52Z,CONTRIBUTOR,,"When inserting or upserting a jsonlines file, no progressbar is shown. Expected behavior is that, just like with .csv/.tsv files, also for a jsonlines file (--nl), unless --silent is provided, a progressbar is shown.
```bash
sql-utils upsert mydb.db posts posts.jl --nl --pk post_id
(silence)
```
Currently `file_progress` is only called within the tsv/csv logic, however I think it can be safely wrapped around all the all the input formats that use `decoded`: https://github.com/simonw/sqlite-utils/blob/main/sqlite_utils/cli.py#L963",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/485/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1279863844,I_kwDOCGYnMM5MSSwk,449,Utilities for duplicating tables and creating a table with the results of a query,1690072,closed,0,,,4,2022-06-22T09:41:43Z,2022-07-15T21:46:13Z,2022-07-15T21:21:36Z,CONTRIBUTOR,,"is there a duplicate table functionality? Otherwise, I'd be happy to submit a PR.
In sqlite3 it would look like:
```python
import sqlite3 as sl
con = sl.connect('prompt-tune.db')
def db_duplicate_table(table_name, table_name_new, con=con):
# Duplicates table `table_name` to a new table `table_name_new`.
try:
cur = con.cursor()
cur.execute(f""""""CREATE TABLE {table_name_new} AS SELECT * FROM {table_name}"""""")
except Exception as e:
print(e)
finally:
cur.close()
db_duplicate_table('orig_table', 'new_table')
```",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/449/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1178456794,I_kwDOCGYnMM5GPdLa,418,Add generated files to .gitignore,25778,closed,0,,,0,2022-03-23T17:48:12Z,2022-03-24T21:01:44Z,2022-03-24T21:01:44Z,CONTRIBUTOR,,"I end up with these in my local directory:
.hypothesis/
Pipfile
Pipfile.lock
pyproject.toml
Might as well gitignore them.",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/418/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1124237013,I_kwDOCGYnMM5DAn7V,398,Add SpatiaLite helpers to CLI,25778,closed,0,,,9,2022-02-04T14:01:28Z,2022-02-16T01:02:29Z,2022-02-16T00:58:07Z,CONTRIBUTOR,,"Now that #385 is merged, add CLI versions of those methods.
```sh
# init spatialite
sqlite-utils init-spatialite database.db
# or maybe/also
sqlite-utils create database.db --enable-wal --spatialite
# add geometry columns
# needs a database, table, geometry column name, type, with optional SRID and not-null
# this needs to create a table if it doesn't already exist
sqlite-utils add-geometry-column database.db table-name geometry --srid 4326 --not-null
# spatial index an existing table/column
sqlite-utils create-spatial-index database.db table-name geometry
```
Should be mostly straightforward. The one thing worth highlighting in docs is that geometry columns can only be added to existing tables. Trying to add a geometry column to a table that doesn't exist yet might mean you have a schema like `{""rowid"": int, ""geometry"": bytes}`. Might be worth nudging people to explicitly create a table first, then add geometry columns.
",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/398/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1126692066,I_kwDOCGYnMM5DJ_Ti,403,Document how to add a primary key to a rowid table using `sqlite-utils transform --pk`,536941,closed,0,,,4,2022-02-08T01:39:40Z,2022-02-09T04:22:43Z,2022-02-08T19:33:59Z,CONTRIBUTOR,,"*Original title: Add option for adding a new, serial, primary key*
sometimes we have tables that don't have primary keys, but ought to have them. we *can* use rowid for that, but it would often be nicer to have an explicit primary key. using the current value of rowid would be fine.",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/403/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1096558279,I_kwDOCGYnMM5BXCbH,365,create-index should run analyze after creating index,536941,closed,0,,7558727,16,2022-01-07T18:21:25Z,2022-01-11T02:43:34Z,2022-01-11T01:36:48Z,CONTRIBUTOR,,"sqlite's query planner depends upon analyze to make good use of indices. It would be nice if analyze was run as part of the create-index command.
If data is inserted later, things can get out date, but it would still probably be a net win. ",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/365/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
1077102934,I_kwDOCGYnMM5AM0lW,353,"Allow passing a file of code to ""sqlite-utils convert""",536941,closed,0,,,8,2021-12-10T18:06:14Z,2021-12-11T01:38:29Z,2021-12-11T01:09:39Z,CONTRIBUTOR,,"sqlite-utils is so nice, but the ergonomics of the multiline code in kind of tough. It's really hard (maybe impossible) to make the newlines play well with Makefiles.
it would be great to write your code fragment in a separate file and direct it into the sqlite-utils
either like
```sqlite-utils convert my.db my_table my_column < custom_code.py```
or
```sqlite-utils convert my.db my_table my_column --custom-code=custom_code.py```
Thanks, as ever, for these great tools!",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/353/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
831751367,MDU6SXNzdWU4MzE3NTEzNjc=,246,Escaping FTS search strings,16001974,closed,0,,,4,2021-03-15T12:15:09Z,2021-08-18T18:57:13Z,2021-08-18T18:43:12Z,CONTRIBUTOR,,"
Thanks for the excellent library, it's very nice to use!
I've been building some in memory search functionality for a data annotation tool i'm making, and I got tripped up a little bit with escaping the full text search queries. First I tried using `db.quote(q)`, which doesn't work, because sqlite FTS has it's own (separate)[ query syntax](https://www2.sqlite.org/fts5.html#full_text_query_syntax). You can see this happening here also:
http://search-24ways.herokuapp.com/24ways-f8f455f/articles?_search=acces%2A
I got around this by aggressively escaping quotes inside the query string like this:
```python
quoted = q.replace('""', '""""')
quoted = f'""{quoted}""'
print(quoted)
results = db[""data""].search(quoted, columns=[""id""])
return [x[""id""] for x in results]
```
This works in the sense it doesn't crash, but it also removes access to the search query syntax. Given the well specified definition, it might be possible for sqlite-utils to provide a `db.quote_query(q)` which would intelligently escape a query whilst leaving the syntax intact. This would be very nice!
",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/246/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
923697888,MDU6SXNzdWU5MjM2OTc4ODg=,278,"Support db as first parameter before subcommand, or as environment variable",601708,closed,0,,,3,2021-06-17T09:26:29Z,2021-06-20T22:39:57Z,2021-06-18T15:43:19Z,CONTRIBUTOR,,,140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/278/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
923602693,MDU6SXNzdWU5MjM2MDI2OTM=,276,support small help flag -h,601708,closed,0,,,0,2021-06-17T07:59:31Z,2021-06-18T14:56:59Z,2021-06-18T14:56:59Z,CONTRIBUTOR,,,140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/276/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
907642546,MDU6SXNzdWU5MDc2NDI1NDY=,264,"Supporting additional output formats, like GeoJSON",25778,closed,0,,,3,2021-05-31T18:03:32Z,2021-06-03T05:12:21Z,2021-06-03T05:12:21Z,CONTRIBUTOR,,"I have a project going where it would be useful to do some spatial processing in SQLite (instead of large files) and then output GeoJSON. So my workflow would be something like this:
1. Read Shapefiles, GeoJSON, CSVs into a SQLite database
2. Join, filter, prune as needed
3. Export GeoJSON for just the stuff I need at that moment, while still having a database of things that will be useful later
I'm wondering if this is worth adding to SQLite-utils itself (GeoJSON, at least), or if it's better to make a counterpart to the ecosystem of `*-to-sqlite` tools, say a suite of `sqlite-to-*` things. Or would it be crazy to have a plugin system?",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/264/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
868188068,MDU6SXNzdWU4NjgxODgwNjg=,257,"Insert from JSON containing strings with non-ascii characters are escaped as unicode for lists, tuples, dicts.",6586811,closed,0,,,0,2021-04-26T20:46:25Z,2021-05-19T02:57:05Z,2021-05-19T02:57:05Z,CONTRIBUTOR,,"JSON Test File (test.json):
```json
[
{
""id"": 123,
""text"": ""FR Théâtre""
},
{
""id"": 223,
""text"": [
""FR Théâtre""
]
}
]
```
Command to import:
```bash
sqlite-utils insert test.db text test.json --pk=id
```
Resulting table view from datasette:
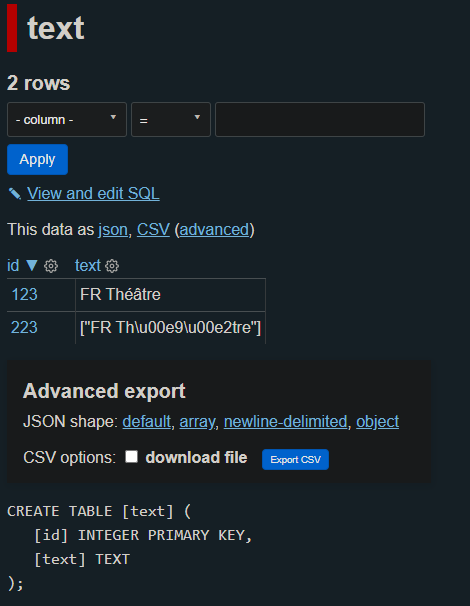
Original, db.py line 2225:
```python
return json.dumps(value, default=repr)
```
Fix, db.py line 2225:
```python
return json.dumps(value, default=repr, ensure_ascii=False)
```",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/257/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
766156875,MDU6SXNzdWU3NjYxNTY4NzU=,209,Test failure with sqlite 3.34 in test_cli.py::test_optimize,191622,closed,0,,,1,2020-12-14T08:58:18Z,2021-01-01T23:52:46Z,2021-01-01T23:52:46Z,CONTRIBUTOR,,"pytest output:
```
...
============================== short test summary info ===============================
FAILED tests/test_cli.py::test_optimize[tables0] - assert 1662976 < 1662976
FAILED tests/test_cli.py::test_optimize[tables1] - assert 1667072 < 1662976
===================== 2 failed, 538 passed, 3 skipped in 34.32s ======================
```
Came across this while packaging `sqlite-utils` for NixOS, but it can be recreated it using the `alpine:edge` docker image as well as follows:
```
docker run --rm -it alpine:edge /bin/sh
# apk update && apk add git sqlite python3 gcc python3-dev musl-dev && python3 -m ensurepip
# git clone https://github.com/simonw/sqlite-utils.git
# cd sqlite-utils/
# pip3 install -e .[test]
# pytest
```
This definitely works on sqlite v3.33.",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/209/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
488293926,MDU6SXNzdWU0ODgyOTM5MjY=,58,Support enabling FTS on views,49260,closed,0,,,1,2019-09-02T18:56:36Z,2020-10-16T18:39:36Z,2020-10-16T18:39:31Z,CONTRIBUTOR,,"Right now enable_fts() is only implemented for Table(). Technically sqlite supports enabling fts on views. But it requires deeper thought since views don't have `rowid` and the current implementation of enable_fts() relies on the presence of `rowid` column.
It is possible to provide an alternative rowid using the `content_rowid` option to the FTS5() function.
Ref: https://sqlite.org/fts5.html#fts5_table_creation_and_initialization
> The ""content_rowid"" option, used to set the rowid field of an external content table.
This will further complicate `enable_fts()` function by adding an extra argument. I'm wondering if that is outside the scope of this tool or should I work on that feature and send a PR? ",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/58/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
688659182,MDU6SXNzdWU2ODg2NTkxODI=,145,Bug when first record contains fewer columns than subsequent records,96218,closed,0,,,2,2020-08-30T05:44:44Z,2020-09-08T23:21:23Z,2020-09-08T23:21:23Z,CONTRIBUTOR,,"`insert_all()` selects the maximum batch size based on the number of fields in the first record. If the first record has fewer fields than subsequent records (and `alter=True` is passed), this can result in SQL statements with more than the maximum permitted number of host parameters. This situation is perhaps unlikely to occur, but could happen if the first record had, say, 10 columns, such that `batch_size` (based on `SQLITE_MAX_VARIABLE_NUMBER = 999`) would be 99. If the next 98 rows had 11 columns, the resulting SQL statement for the first batch would have `10 * 1 + 11 * 98 = 1088` host parameters (and subsequent batches, if the data were consistent from thereon out, would have `99 * 11 = 1089`).
I suspect that this bug is masked somewhat by the fact that while:
> [`SQLITE_MAX_VARIABLE_NUMBER`](https://www.sqlite.org/limits.html#max_variable_number) ... defaults to 999 for SQLite versions prior to 3.32.0 (2020-05-22) or 32766 for SQLite versions after 3.32.0.
it is common that it is increased at compile time. Debian-based systems, for example, seem to ship with a version of sqlite compiled with `SQLITE_MAX_VARIABLE_NUMBER` set to 250,000, and I believe this is the case for homebrew installations too.
A test for this issue might look like this:
```python
def test_columns_not_in_first_record_should_not_cause_batch_to_be_too_large(fresh_db):
# sqlite on homebrew and Debian/Ubuntu etc. is typically compiled with
# SQLITE_MAX_VARIABLE_NUMBER set to 250,000, so we need to exceed this value to
# trigger the error on these systems.
THRESHOLD = 250000
extra_columns = 1 + (THRESHOLD - 1) // 99
records = [
{""c0"": ""first record""}, # one column in first record -> batch_size = 100
# fill out the batch with 99 records with enough columns to exceed THRESHOLD
*[
dict([(""c{}"".format(i), j) for i in range(extra_columns)])
for j in range(99)
]
]
try:
fresh_db[""too_many_columns""].insert_all(records, alter=True)
except sqlite3.OperationalError:
raise
```
The best solution, I think, is simply to process all the records when determining columns, column types, and the batch size. In my tests this doesn't seem to be particularly costly at all, and cuts out a lot of complications (including obviating my implementation of #139 at #142). I'll raise a PR for your consideration.
",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/145/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
686978131,MDU6SXNzdWU2ODY5NzgxMzE=,139,"insert_all(..., alter=True) should work for new columns introduced after the first 100 records",96218,closed,0,,,7,2020-08-27T06:25:25Z,2020-08-28T22:48:51Z,2020-08-28T22:30:14Z,CONTRIBUTOR,,"Is there a way to make `.insert_all()` work properly when new columns are introduced outside the first 100 records (with or without the `alter=True` argument)?
I'm using `.insert_all()` to bulk insert ~3-4k records at a time and it is common for records to need to introduce new columns. However, if new columns are introduced after the first 100 records, `sqlite_utils` doesn't even raise the `OperationalError: table ... has no column named ...` exception; it just silently drops the extra data and moves on.
It took me a while to find this little snippet in the [documentation for `.insert_all()`](https://sqlite-utils.readthedocs.io/en/stable/python-api.html#bulk-inserts) (it's not mentioned under [Adding columns automatically on insert/update](https://sqlite-utils.readthedocs.io/en/stable/python-api.html#bulk-inserts)):
> The column types used in the CREATE TABLE statement are automatically derived from the types of data in that first batch of rows. **_Any additional or missing columns in subsequent batches will be ignored._**
I tried changing the `batch_size` argument to the total number of records, but it seems only to effect the number of rows that are committed at a time, and has no influence on this problem.
Is there a way around this that you would suggest? It seems like it should raise an exception at least.",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/139/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed
610517472,MDU6SXNzdWU2MTA1MTc0NzI=,103,sqlite3.OperationalError: too many SQL variables in insert_all when using rows with varying numbers of columns,32605365,closed,0,,,8,2020-05-01T02:26:14Z,2020-05-14T00:18:57Z,2020-05-14T00:18:57Z,CONTRIBUTOR,,"If using insert_all to put in 1000 rows of data with varying number of columns, it comes up with this message `sqlite3.OperationalError: too many SQL variables` if the number of columns is larger in later records (past the first row)
I've reduced `SQLITE_MAX_VARS` by 100 to 899 at the top of `db.py` to add wiggle room, so that if the column count increases it wont go past SQLite's batch limit as calculated by this line of code based on the count of the first row's dict keys
batch_size = max(1, min(batch_size, SQLITE_MAX_VARS // num_columns))",140912432,issue,,,"{""url"": ""https://api.github.com/repos/simonw/sqlite-utils/issues/103/reactions"", ""total_count"": 0, ""+1"": 0, ""-1"": 0, ""laugh"": 0, ""hooray"": 0, ""confused"": 0, ""heart"": 0, ""rocket"": 0, ""eyes"": 0}",,completed