{"id": 273775212, "node_id": "MDU6SXNzdWUyNzM3NzUyMTI=", "number": 88, "title": "Add NHS England Hospitals example to wiki", "user": {"value": 15543, "label": "tomdyson"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2017-11-14T12:29:10Z", "updated_at": "2021-03-22T23:46:36Z", "closed_at": "2017-11-14T22:54:06Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "https://nhs-england-hospitals.now.sh\r\n\r\nand an associated map visualisation:\r\n\r\nhttp://run.plnkr.co/preview/cj9zlf1qc0003414y90ajkwpk/\r\n\r\nDatasette is wonderful!\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/88/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 275814941, "node_id": "MDU6SXNzdWUyNzU4MTQ5NDE=", "number": 141, "title": "datasette publish can fail if /tmp is on a different device", "user": {"value": 21148, "label": "jacobian"}, "state": "closed", "locked": 0, "assignee": null, "milestone": {"value": 2949431, "label": "Custom templates edition"}, "comments": 5, "created_at": "2017-11-21T18:28:05Z", "updated_at": "2020-04-29T03:27:54Z", "closed_at": "2017-12-08T16:06:36Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "`datasette publish` uses hard links to avoid copying the db into a tmp directory. This can fail if `/tmp` is on another device, because hardlinks can't cross devices. You'll see something like this:\r\n\r\n```\r\n$ datasette publish heroku whatever.db\r\n...\r\nOSError: [Errno 18] Invalid cross-device link: '/mnt/c/Users/jacob/c/datasette/whatever.db' -> '/tmp/tmpvxq2yof6/whatever.db'\r\n```\r\n[In my case this is failing because I'm on a Windows machine, using WSL, so my code's on a different virtual filesystem from the Linux subsystem, Because Reasons.]\r\n\r\nI'm not sure if it's possible to detect this (can you figure out which device `/tmp` is on?), or what the fallback should be (soft link? copy?).", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/141/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 286938589, "node_id": "MDU6SXNzdWUyODY5Mzg1ODk=", "number": 177, "title": "Publishing to Heroku - metadata file not uploaded?", "user": {"value": 82988, "label": "psychemedia"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2018-01-09T01:04:31Z", "updated_at": "2018-01-25T16:45:32Z", "closed_at": "2018-01-25T16:45:32Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Trying to run *datasette* (version 0.14) on Heroku with a `metadata.json` doesn't seem to be picking up the `metadata.json` file? \r\n\r\nOn a Mac with dodgy `tar` support:\r\n\r\n```\r\n \u25b8 Couldn't detect GNU tar. Builds could fail due to decompression errors\r\n \u25b8 See\r\n \u25b8 https://devcenter.heroku.com/articles/platform-api-deploying-slugs#create-slug-archive\r\n \u25b8 Please install it, or specify the '--tar' option\r\n \u25b8 Falling back to node's built-in compressor\r\n```\r\n\r\nCould that be causing the issue?\r\n\r\nAlso, I'm not seeing custom query links anywhere obvious when I run the metadata file with a local *datasette* server?\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/177/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 291639118, "node_id": "MDU6SXNzdWUyOTE2MzkxMTg=", "number": 183, "title": "Custom Queries - escaping strings", "user": {"value": 82988, "label": "psychemedia"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2018-01-25T16:49:13Z", "updated_at": "2019-06-24T06:45:07Z", "closed_at": "2019-06-24T06:45:07Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "If a SQLite table column name contains spaces, they are usually referred to in double quotes:\r\n\r\n`SELECT * FROM mytable WHERE \"gappy column name\"=\"my value\";`\r\n\r\nIn the JSON metadata file, this is passed by escaping the double quotes:\r\n\r\n`\"queries\": {\"my query\": \"SELECT * FROM mytable WHERE \\\"gappy column name\\\"=\\\"my value\\\";\"}`\r\n\r\nWhen specifying a custom query in `metadata.json` using double quotes, these are then rendered in the *datasette* query box using single quotes:\r\n\r\n`SELECT * FROM mytable WHERE 'gappy column name'='my value';`\r\n\r\nwhich does not work.\r\n\r\nAlternatively, a valid custom query can be passed using backticks (\\`) to quote the column name and single (unescaped) quotes for the matched value:\r\n\r\n``\"queries\": {\"my query\": \"SELECT * FROM mytable WHERE `gappy column name`='my value';\"}``\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/183/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 313837303, "node_id": "MDU6SXNzdWUzMTM4MzczMDM=", "number": 203, "title": "Support for units", "user": {"value": 45057, "label": "russss"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 10, "created_at": "2018-04-12T18:24:28Z", "updated_at": "2018-04-16T21:59:17Z", "closed_at": "2018-04-16T21:59:17Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "It would be nice to be able to attach a unit to a column in the metadata, and have it rendered with that unit (and SI prefix) when it's displayed.\r\n\r\nIt would also be nice to support entering the prefixes in variables when querying.\r\n\r\nWith my radio licensing app I've put all frequencies in Hz. It's easy enough to special-case the row rendering to add the SI prefixes, but it's pretty unusable when querying by that field.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/203/reactions\", \"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 314834783, "node_id": "MDU6SXNzdWUzMTQ4MzQ3ODM=", "number": 219, "title": "Expose units in the JSON API?", "user": {"value": 45057, "label": "russss"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2018-04-16T22:04:25Z", "updated_at": "2018-04-16T22:04:25Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "From #203: it would be nice for the JSON API to (optionally) return columns rendered with units in them - if, for example, you're consuming the JSON to render the rows on a map.\r\n\r\nI'm not entirely sure how useful this will be though - at the moment my map queries are custom SQL queries (a few have joins in, the rest might be fetching large amounts of data so it makes sense to limit columns fetched). Perhaps the SQL function is a better approach in general.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/219/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 324835838, "node_id": "MDU6SXNzdWUzMjQ4MzU4Mzg=", "number": 276, "title": "Handle spatialite geometry columns better", "user": {"value": 45057, "label": "russss"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 21, "created_at": "2018-05-21T08:46:55Z", "updated_at": "2022-03-21T22:22:20Z", "closed_at": "2022-03-21T22:22:20Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I'd like to see spatialite geometry columns rendered more sensibly - at the moment they come through as well-known-binary unless you use custom SQL, and WKB isn't of much use to anyone on the web.\r\n\r\nIn HTML: they should be shown either as simple lat/long (if it's just a point, for example), or as a sensible placeholder if they're more complex geometries.\r\n\r\nIn JSON: they should be GeoJSON geometries, (which means they can be automatically fed into a leaflet map with no further messing around).\r\n\r\nIn CSV: they should be WKT.\r\n\r\nI briefly wondered if this should go into a plugin, but I suspect it needs hooking in at a deeper level than the plugin architecture will support any time soon.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/276/reactions\", \"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 336924199, "node_id": "MDU6SXNzdWUzMzY5MjQxOTk=", "number": 330, "title": "Limit text display in cells containing large amounts of text", "user": {"value": 82988, "label": "psychemedia"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2018-06-29T09:15:22Z", "updated_at": "2018-07-24T04:53:20Z", "closed_at": "2018-07-10T16:20:48Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "The default preview of a database shows all columns (is the row count limited?) which is fine in many cases but can take a long time to load / offer a large overhead if the table is a SpatiaLite table containing geometry columns that include large shapefiles.\r\n\r\nWould it make sense to have a setting that can limit the amount of text displayed in any given cell in the table preview, or (less useful?) suppress (with notification) the display of overlong columns unless enabled by the user?\r\n\r\nAn issue then arises if a user does want to see all the text in a cell:\r\n\r\n 1) for a particular cell;\r\n 2) for every cell in the table;\r\n 3) for all cells in a particular column or columns\r\n\r\n(I haven't checked but what if a column contains e.g. raw image data? Does this display as raw data? Or can this be rendered in a context aware way as an image preview? I guess a custom template would be one way to do that?)", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/330/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 336936010, "node_id": "MDU6SXNzdWUzMzY5MzYwMTA=", "number": 331, "title": "Datasette throws error when loading spatialite db without extension loaded", "user": {"value": 82988, "label": "psychemedia"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2018-06-29T09:51:14Z", "updated_at": "2022-01-20T21:29:40Z", "closed_at": "2018-07-10T15:13:36Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "When starting datasette on a SpatialLite database *without* loading the SpatiaLite extension (using eg `--load-extension=/usr/local/lib/mod_spatialite.dylib`) an error is thrown and the server fails to start:\r\n\r\n```\r\ndatasette -p 8003 adminboundaries.db \r\nServe! files=('adminboundaries.db',) on port 8003\r\nTraceback (most recent call last):\r\n File \"/Users/ajh59/anaconda3/bin/datasette\", line 11, in <module>\r\n sys.exit(cli())\r\n File \"/Users/ajh59/anaconda3/lib/python3.6/site-packages/click/core.py\", line 722, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/Users/ajh59/anaconda3/lib/python3.6/site-packages/click/core.py\", line 697, in main\r\n rv = self.invoke(ctx)\r\n File \"/Users/ajh59/anaconda3/lib/python3.6/site-packages/click/core.py\", line 1066, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/Users/ajh59/anaconda3/lib/python3.6/site-packages/click/core.py\", line 895, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/Users/ajh59/anaconda3/lib/python3.6/site-packages/click/core.py\", line 535, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/Users/ajh59/anaconda3/lib/python3.6/site-packages/datasette/cli.py\", line 552, in serve\r\n ds.inspect()\r\n File \"/Users/ajh59/anaconda3/lib/python3.6/site-packages/datasette/app.py\", line 273, in inspect\r\n \"tables\": inspect_tables(conn, self.metadata.get(\"databases\", {}).get(name, {}))\r\n File \"/Users/ajh59/anaconda3/lib/python3.6/site-packages/datasette/inspect.py\", line 79, in inspect_tables\r\n \"PRAGMA table_info({});\".format(escape_sqlite(table))\r\nsqlite3.OperationalError: no such module: VirtualSpatialIndex\r\n``` \r\n\r\nIt would be nice to trap this and return a message saying something like:\r\n\r\n```\r\nIt looks like you're trying to load a SpatiaLite database? Make sure you load in the SpatiaLite extension when starting datasette.\r\n\r\nRead more: https://datasette.readthedocs.io/en/latest/spatialite.html\r\n```\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/331/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 341228846, "node_id": "MDU6SXNzdWUzNDEyMjg4NDY=", "number": 343, "title": "Render boolean fields better by default", "user": {"value": 45057, "label": "russss"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2018-07-14T11:10:29Z", "updated_at": "2018-07-14T14:17:14Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "These show up as 0 or 1 because sqlite. I think Yes/No would be fine in most cases?", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/343/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 341229113, "node_id": "MDU6SXNzdWUzNDEyMjkxMTM=", "number": 344, "title": "datasette publish heroku fails without name provided", "user": {"value": 45057, "label": "russss"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2018-07-14T11:15:56Z", "updated_at": "2018-07-14T13:00:48Z", "closed_at": "2018-07-14T13:00:48Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "It fails with the following JSON traceback if the `-n` option isn't provided, despite the fact that the command line help says that's not needed for heroku publishes.\r\n\r\n<details>\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/datasette\", line 11, in <module>\r\n sys.exit(cli())\r\n File \"/usr/local/lib/python3.6/site-packages/click/core.py\", line 722, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.6/site-packages/click/core.py\", line 697, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.6/site-packages/click/core.py\", line 1066, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/usr/local/lib/python3.6/site-packages/click/core.py\", line 895, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/usr/local/lib/python3.6/site-packages/click/core.py\", line 535, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/usr/local/lib/python3.6/site-packages/datasette/cli.py\", line 265, in publish\r\n app_name = json.loads(create_output)[\"name\"]\r\n File \"/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/__init__.py\", line 354, in loads\r\n return _default_decoder.decode(s)\r\n File \"/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/decoder.py\", line 339, in decode\r\n obj, end = self.raw_decode(s, idx=_w(s, 0).end())\r\n File \"/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/decoder.py\", line 357, in raw_decode\r\n raise JSONDecodeError(\"Expecting value\", s, err.value) from None\r\njson.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)\r\n```\r\n\r\n</details>", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/344/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 369716228, "node_id": "MDU6SXNzdWUzNjk3MTYyMjg=", "number": 366, "title": "Default built image size over Zeit Now 100MiB limit", "user": {"value": 416374, "label": "gfrmin"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2018-10-12T21:27:17Z", "updated_at": "2018-11-05T06:23:32Z", "closed_at": "2018-11-05T06:23:32Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Using `dataset publish now` with no other custom options on a small (43KB) sqlite database leads to the error \"The built image size (373.5M) exceeds the 100MiB limit\". I think this is because of a recent Zeit change: https://github.com/zeit/now-cli/issues/1523", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/366/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 374953006, "node_id": "MDU6SXNzdWUzNzQ5NTMwMDY=", "number": 369, "title": "Interface should show same JSON shape options for custom SQL queries", "user": {"value": 416374, "label": "gfrmin"}, "state": "open", "locked": 0, "assignee": null, "milestone": {"value": 3268330, "label": "Datasette 1.0"}, "comments": 2, "created_at": "2018-10-29T10:39:15Z", "updated_at": "2020-05-30T17:24:06Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "At the moment the page returning a custom SQL query shows the JSON and CSV APIs, but not the multiple JSON shapes. However, adding the `_shape` parameter to the JSON API URL manually still works, so perhaps there should be consistency in the interface by having the same \"Advanced Export\" box for custom SQL queries.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/369/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 377155320, "node_id": "MDU6SXNzdWUzNzcxNTUzMjA=", "number": 370, "title": "Integration with JupyterLab", "user": {"value": 82988, "label": "psychemedia"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2018-11-04T13:57:13Z", "updated_at": "2022-09-29T08:17:47Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I just watched a demo video for the [JupyterLab Chart Editor](https://www.crowdcast.io/e/introducing-JupyterLab-Chart-Editor/) which wraps the plotly chart editor app in a JupyterLab panel and lets you open a plotly chart JSON file in that editor. Essentially, it pops an HTML app into a panel in JupyterLab, and I think registers the app as a file viewer for a particular file type. (I'm not completely taken by it, tbh, because it means you can do irreproducible things to the chart definition file, but that's another issue).\r\n\r\nJupyterLab extensions can also open files from a dialogue as the iframe/html previewer shows: https://github.com/timkpaine/jupyterlab_iframe.\r\n\r\nThis made me wonder about what `datasette` integration with JupyterLab might do.\r\n\r\nFor example, by right-clicking on a CSV file (for which there is already a CSV table view) in the file browser, offer a *View / Run as datasette* file viewer option that will:\r\n\r\n- run the CSV file through `csvs-to-sqlite`;\r\n- launch the `datasette` server and display the `datasette` view in a JupyterLab panel.\r\n\r\n(? Create a new SQLite db for each CSV file and launch each datasette view on a new port? Or have a JupyterLab (session?) SQLite db that stores all `datasette` viewed CSVs and runs on a single port?) \r\n\r\nAs a freebie, the `datasette` API would allow you to run efficient SQL queries against the file eg using using `pandas.read_sql()` queries in a notebook in the same space.\r\n\r\nRelated:\r\n\r\n- [JupyterLab extensions docs](https://jupyterlab.readthedocs.io/en/stable/user/extensions.html)\r\n- a [cookiecutter for wrting JupyterLab extensions using Javascript](https://github.com/jupyterlab/extension-cookiecutter-js)\r\n- a [cookiecutter for writing JupyterLab extensions using Typescript](https://github.com/jupyterlab/extension-cookiecutter-ts)\r\n- tutorial: [Let\u2019s Make an xkcd JupyterLab Extension](https://jupyterlab.readthedocs.io/en/stable/developer/xkcd_extension_tutorial.html)", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/370/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 377156339, "node_id": "MDU6SXNzdWUzNzcxNTYzMzk=", "number": 371, "title": "datasette publish digitalocean plugin", "user": {"value": 82988, "label": "psychemedia"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2018-11-04T14:07:41Z", "updated_at": "2021-01-04T20:14:28Z", "closed_at": "2021-01-04T20:14:28Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Provide support for launching `datasette` on Digital Ocean.\r\n\r\nExample: [Deploy Docker containers into Digital Ocean](https://blog.machinebox.io/deploy-machine-box-in-digital-ocean-385265fbeafd).\r\n\r\nDigital Ocean also has a preconfigured VM running Docker that can be launched from the command line via the Digital Ocean API: [Docker One-Click Application](https://www.digitalocean.com/docs/one-clicks/docker/).\r\n\r\nRelated:\r\n- Launching containers in Digital Ocean servers running docker: [How To Provision and Manage Remote Docker Hosts with Docker Machine on Ubuntu 16.04](https://www.digitalocean.com/community/tutorials/how-to-provision-and-manage-remote-docker-hosts-with-docker-machine-on-ubuntu-16-04)\r\n- [How To Use Doctl, the Official DigitalOcean Command-Line Client](https://www.digitalocean.com/community/tutorials/how-to-use-doctl-the-official-digitalocean-command-line-client)", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/371/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 377166793, "node_id": "MDU6SXNzdWUzNzcxNjY3OTM=", "number": 372, "title": "Docker build tools", "user": {"value": 82988, "label": "psychemedia"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2018-11-04T16:02:35Z", "updated_at": "2018-11-04T16:02:35Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "In terms of small pieces lightly joined, I note that there are several tools starting to appear for building generating Dockerfiles and building Docker containers from simpler components such as `requirements.txt` files.\r\n\r\nIf plugin/extensions builders want to include additional packages, then things like incremental builds of composable builds that add additional items into a base `datasette` container may be required.\r\n\r\nExamples of Dockerfile generators / container builders:\r\n\r\n- [openshift/source-to-image (s2i)](https://github.com/openshift/source-to-image)\r\n- [jupyter/repo2docker](https://github.com/jupyter/repo2docker)\r\n- [stencila/dockter](https://github.com/stencila/dockter)\r\n\r\nDiscussions / threads (via Binderhub gitter) on:\r\n- [why `repo2docker` not `s2i`](http://words.yuvi.in/post/why-not-s2i/)\r\n- [why `dockter` not `repo2docker`](https://twitter.com/choldgraf/status/1058499607309647872)\r\n- [composability in `s2i`](https://trello.com/c/AexIVZNf/1008-8-composable-builds-builds-evg)\r\n\r\nRelates to things like:\r\n\r\n- https://github.com/simonw/datasette/pull/280", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/372/reactions\", \"total_count\": 2, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 2, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 377266351, "node_id": "MDU6SXNzdWUzNzcyNjYzNTE=", "number": 373, "title": "Views should be shown on root/index page along with tables", "user": {"value": 416374, "label": "gfrmin"}, "state": "closed", "locked": 0, "assignee": null, "milestone": {"value": 4305096, "label": "0.28"}, "comments": 1, "created_at": "2018-11-05T06:28:41Z", "updated_at": "2019-05-16T00:29:22Z", "closed_at": "2019-05-16T00:29:22Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "At the moment the number of views is given on a datasette \"homepage\", but not links to any views themselves", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/373/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 398559195, "node_id": "MDU6SXNzdWUzOTg1NTkxOTU=", "number": 400, "title": "datasette publish cloudrun plugin", "user": {"value": 10352819, "label": "rprimet"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2019-01-12T14:35:11Z", "updated_at": "2019-05-03T16:57:35Z", "closed_at": "2019-05-03T16:57:35Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Google announced that they may launch a simple service for running Docker containers (previously serverless containers, now called \"cloud run\" -- link to alpha [here](https://services.google.com/fb/forms/serverlesscontainers/)). If/when this happens, it might be a good fit for publishing datasettes? (at least using the current version, manually publishing a datasette seems relatively painless).", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/400/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 415575624, "node_id": "MDU6SXNzdWU0MTU1NzU2MjQ=", "number": 414, "title": "datasette requires specific version of Click", "user": {"value": 82988, "label": "psychemedia"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2019-02-28T11:24:59Z", "updated_at": "2019-03-15T04:42:13Z", "closed_at": "2019-03-15T04:42:13Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Is `datasette` beholden to version `click==6.7`?\r\n\r\nCurrent release is at 7.0. Can the requirement be liberalised, eg to `>=6.7`?", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/414/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 432870248, "node_id": "MDU6SXNzdWU0MzI4NzAyNDg=", "number": 431, "title": "Datasette doesn't reload when database file changes", "user": {"value": 82988, "label": "psychemedia"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2019-04-13T16:50:43Z", "updated_at": "2019-05-02T05:13:55Z", "closed_at": "2019-05-02T05:13:54Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "My understanding of the `--reload` option was that if the database file changed `datasette` would automatically reload.\r\n\r\nI'm running on a Mac and from the `datasette` UI queries don't seem to be picking up data in a newly changed db (I checked the db timestamp - it certainly updated).\r\n\r\nI was also expecting to see some sort of log statement in the datasette logging to say that it had detected a file change and restarted, but don't see anything there?\r\n\r\nWill try to check on an Ubuntu box when I get a chance to see if this is a Mac thing.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/431/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 438200529, "node_id": "MDU6SXNzdWU0MzgyMDA1Mjk=", "number": 438, "title": "Plugins are loaded when running pytest", "user": {"value": 45057, "label": "russss"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2019-04-29T08:25:58Z", "updated_at": "2019-05-02T05:09:18Z", "closed_at": "2019-05-02T05:09:11Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "If I have a datasette plugin installed on my system, its hooks are called when running the main datasette tests. This is probably undesirable, especially with the inspect hook in #437, as the plugin may rely on inspected state that the tests don't know about.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/438/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 438259941, "node_id": "MDU6SXNzdWU0MzgyNTk5NDE=", "number": 440, "title": "Plugin hook for additional data export formats", "user": {"value": 45057, "label": "russss"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2019-04-29T11:01:39Z", "updated_at": "2019-05-01T23:01:57Z", "closed_at": "2019-05-01T23:01:57Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "It would be nice to have a simple way for plugins to provide additional data export formats. Might require a bit of work on the internals. I can work around this at a lower level with the `prepare_sanic` hook from #437 in the mean time.\r\n\r\nI guess plugins should be able to register a function which takes a row or list of rows and returns the rendered data. They'll also need to provide a file extension and probably a Content-Type.\r\n\r\nDatasette could then automatically include this format in the list of export formats on each page.\r\n\r\nLooks like this is related to #119.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/440/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 442327592, "node_id": "MDU6SXNzdWU0NDIzMjc1OTI=", "number": 456, "title": "Installing installs the tests package", "user": {"value": 7725188, "label": "hellerve"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2019-05-09T16:35:16Z", "updated_at": "2020-07-24T20:39:54Z", "closed_at": "2020-07-24T20:39:54Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Because `setup.py` uses `find_packages` and `tests` is on the top-level, `pip install datasette` will install a top-level package called `tests`, which is probably not desired behavior.\r\n\r\nThe offending line is here:\r\nhttps://github.com/simonw/datasette/blob/bfa2ae0d16d39bb82dbe4da4f3fdc3c7f6257418/setup.py#L40\r\n\r\nAnd only `pip uninstall datasette` with a conflicting package would warn you by default; apparently another package had the same problem, which is why I get this message when uninstalling:\r\n\r\n```\r\n$ pip uninstall datasette\r\nUninstalling datasette-0.27:\r\n Would remove:\r\n /usr/local/bin/datasette\r\n /usr/local/lib/python3.7/site-packages/datasette-0.27.dist-info/*\r\n /usr/local/lib/python3.7/site-packages/datasette/*\r\n /usr/local/lib/python3.7/site-packages/tests/*\r\n Would not remove (might be manually added):\r\n [ .. snip .. ]\r\nProceed (y/n)? \r\n```\r\n\r\nThis should be a relatively simple fix, and I could drop a PR if desired!\r\n\r\nCheers", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/456/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 459627549, "node_id": "MDU6SXNzdWU0NTk2Mjc1NDk=", "number": 523, "title": "Show total/unfiltered row count when filtering", "user": {"value": 2657547, "label": "rixx"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2019-06-23T22:56:48Z", "updated_at": "2019-06-24T01:38:14Z", "closed_at": "2019-06-24T01:38:14Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "When I'm seeing a filtered view of a table, I'd like to be able to see something like '2 rows where status != \"closed\" (of 1000 total)' to have a context for the data I'm seeing \u2013 e.g. currently my database is being filled by an importer, so this information would be super helpful.\r\n\r\nSince this information would be a performance hit, maybe something like '12 rows where status != \"closed\" (of ??? total)' with lazy-loading on-click(?) could be applied (Or via a \"How many total?\" tooltip, or \u2026)", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/523/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 465731062, "node_id": "MDU6SXNzdWU0NjU3MzEwNjI=", "number": 555, "title": "Static mounts with relative paths not working", "user": {"value": 3243482, "label": "abdusco"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2019-07-09T11:38:35Z", "updated_at": "2019-07-11T16:13:22Z", "closed_at": "2019-07-11T16:13:22Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Datasette fails to serve files from static mounts that are created using relative paths `datasette --static mystatic:rel/path/to/static/dir`. \r\nI've explained the problem and the solution in the pull request: https://github.com/simonw/datasette/pull/554", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/555/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 471292050, "node_id": "MDU6SXNzdWU0NzEyOTIwNTA=", "number": 563, "title": "incorrect json url for row-level data?", "user": {"value": 10352819, "label": "rprimet"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2019-07-22T19:59:38Z", "updated_at": "2019-10-21T02:03:09Z", "closed_at": "2019-10-21T02:03:09Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "While visiting [this example page](https://register-of-members-interests.datasettes.com/regmem-98dc8b7/people/uk.org.publicwhip%2Fperson%2F10001) (linked from Datasette documentation), manually clicking on [the link](https://register-of-members-interests.datasettes.com/regmem-98dc8b7/people/uk.org.publicwhip%2Fperson%2F10001?_format=json) (\"This data as .json\") to the json data results in an error 500 `data() got an unexpected keyword argument 'as_format'`\r\n\r\nThe [JSON page linked to from the documentation](https://register-of-members-interests.datasettes.com/regmem-d22c12c/people/uk.org.publicwhip%2Fperson%2F10001.json) however is correct (the page address ends in `.json` rather than using a query string `?format=json`)\r\n\r\nThis particular datasette demo page is now a few versions behind, but I was able to reproduce the issue using v0.29.2 and a downloaded copy of the demo database (and also with the current HEAD).\r\n\r\nHere is a stack trace:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/romain/miniconda3/envs/dsbug/lib/python3.7/site-packages/datasette/utils/asgi.py\", line 101, in __call__\r\n return await view(new_scope, receive, send)\r\n File \"/home/romain/miniconda3/envs/dsbug/lib/python3.7/site-packages/datasette/utils/asgi.py\", line 173, in view\r\n request, **scope[\"url_route\"][\"kwargs\"]\r\n File \"/home/romain/miniconda3/envs/dsbug/lib/python3.7/site-packages/datasette/views/base.py\", line 267, in get\r\n request, database, hash, correct_hash_provided, **kwargs\r\n File \"/home/romain/miniconda3/envs/dsbug/lib/python3.7/site-packages/datasette/views/base.py\", line 399, in view_get\r\n request, database, hash, **kwargs\r\nTypeError: data() got an unexpected keyword argument 'as_format'\r\n\r\n```", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/563/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 488293926, "node_id": "MDU6SXNzdWU0ODgyOTM5MjY=", "number": 58, "title": "Support enabling FTS on views", "user": {"value": 49260, "label": "amjith"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2019-09-02T18:56:36Z", "updated_at": "2020-10-16T18:39:36Z", "closed_at": "2020-10-16T18:39:31Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Right now enable_fts() is only implemented for Table(). Technically sqlite supports enabling fts on views. But it requires deeper thought since views don't have `rowid` and the current implementation of enable_fts() relies on the presence of `rowid` column. \r\n\r\nIt is possible to provide an alternative rowid using the `content_rowid` option to the FTS5() function. \r\n\r\nRef: https://sqlite.org/fts5.html#fts5_table_creation_and_initialization\r\n\r\n> The \"content_rowid\" option, used to set the rowid field of an external content table. \r\n\r\nThis will further complicate `enable_fts()` function by adding an extra argument. I'm wondering if that is outside the scope of this tool or should I work on that feature and send a PR? ", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/58/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 492153532, "node_id": "MDU6SXNzdWU0OTIxNTM1MzI=", "number": 573, "title": "Exposing Datasette via Jupyter-server-proxy", "user": {"value": 82988, "label": "psychemedia"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2019-09-11T10:32:36Z", "updated_at": "2020-03-26T09:41:30Z", "closed_at": "2020-03-26T09:41:30Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "It is possible to expose a running `datasette` service in a Jupyter environment such as a MyBinder environment using the [`jupyter-server-proxy`](https://github.com/jupyterhub/jupyter-server-proxy).\r\n\r\nFor example, using [this demo Binder](https://mybinder.org/v2/gh/binder-examples/r/master?filepath=index.ipynb) which has the server proxy installed, we can then upload a simple test database from the notebook homepage, from a Jupyter termianl install datasette and set it running against the test db on eg port 8001 and then view it via the path `proxy/8001`.\r\n\r\nClicking links results in 404s though because the `datasette` links aren't relative to the current path?\r\n\r\n\r\n\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/573/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 518725064, "node_id": "MDU6SXNzdWU1MTg3MjUwNjQ=", "number": 29, "title": "`import` command fails on empty files", "user": {"value": 21148, "label": "jacobian"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2019-11-06T20:34:26Z", "updated_at": "2019-11-09T20:33:38Z", "closed_at": "2019-11-09T19:36:36Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "If a file in the export is empty (in my case it was `account-suspensions.js`), `twitter-to-sqlite import` fails:\r\n\r\n```\r\n$ twitter-to-sqlite import twitter.db ~/Downloads/twitter-2019-11-06-926f4f3be4b3b1fcb1aa387c40cd14f7c8aaf9bbcdb2d78ac14d9989add501bb.zip\r\nTraceback (most recent call last):\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/bin/twitter-to-sqlite\", line 10, in <module>\r\n sys.exit(cli())\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py\", line 764, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py\", line 717, in main\r\n rv = self.invoke(ctx)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py\", line 1137, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py\", line 956, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py\", line 555, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/cli.py\", line 627, in import_\r\n archive.import_from_file(db, filename, content)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/archive.py\", line 224, in import_from_file\r\n db[table_name].upsert_all(rows, hash_id=\"pk\")\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/sqlite_utils/db.py\", line 1113, in upsert_all\r\n extracts=extracts,\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/sqlite_utils/db.py\", line 980, in insert_all\r\n first_record = next(records)\r\nStopIteration\r\n```\r\n\r\nThis appears to be because `db.upsert_all` is called with no rows -- I think? \r\n\r\nI hacked around this by modifying `import_from_file` to have an `if rows:` clause:\r\n\r\n```\r\n for table, rows in to_insert.items():\r\n if rows:\r\n table_name = \"archive_{}\".format(table.replace(\"-\", \"_\"))\r\n ...\r\n```\r\n\r\nI'm happy to work up a real PR if that's the right approach, but I'm not sure it is.", "repo": {"value": 206156866, "label": "twitter-to-sqlite"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/29/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 518739697, "node_id": "MDU6SXNzdWU1MTg3Mzk2OTc=", "number": 30, "title": "`followers` fails because `transform_user` is called twice", "user": {"value": 21148, "label": "jacobian"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2019-11-06T20:44:52Z", "updated_at": "2019-11-09T20:15:28Z", "closed_at": "2019-11-09T19:55:52Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Trying to run `twitter-to-sqlite followers` errors out:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/bin/twitter-to-sqlite\", line 10, in <module>\r\n sys.exit(cli())\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py\", line 764, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py\", line 717, in main\r\n rv = self.invoke(ctx)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py\", line 1137, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py\", line 956, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py\", line 555, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/cli.py\", line 130, in followers\r\n go(bar.update)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/cli.py\", line 116, in go\r\n utils.save_users(db, [profile])\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/utils.py\", line 302, in save_users\r\n transform_user(user)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/utils.py\", line 181, in transform_user\r\n user[\"created_at\"] = parser.parse(user[\"created_at\"])\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/dateutil/parser/_parser.py\", line 1374, in parse\r\n return DEFAULTPARSER.parse(timestr, **kwargs)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/dateutil/parser/_parser.py\", line 646, in parse\r\n res, skipped_tokens = self._parse(timestr, **kwargs)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/dateutil/parser/_parser.py\", line 725, in _parse\r\n l = _timelex.split(timestr) # Splits the timestr into tokens\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/dateutil/parser/_parser.py\", line 207, in split\r\n return list(cls(s))\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/dateutil/parser/_parser.py\", line 76, in __init__\r\n '{itype}'.format(itype=instream.__class__.__name__))\r\nTypeError: Parser must be a string or character stream, not datetime\r\n```\r\n\r\nThis appears to be because https://github.com/dogsheep/twitter-to-sqlite/blob/master/twitter_to_sqlite/cli.py#L111 calls `transform_user`, and then https://github.com/dogsheep/twitter-to-sqlite/blob/master/twitter_to_sqlite/cli.py#L116 calls `transform_user` again, which fails because the user is already transformed.\r\n\r\nI was able to work around this by commenting out https://github.com/dogsheep/twitter-to-sqlite/blob/master/twitter_to_sqlite/cli.py#L116. \r\n\r\nShall I work up a patch for that, or is there a better approach?", "repo": {"value": 206156866, "label": "twitter-to-sqlite"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/30/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 527710055, "node_id": "MDU6SXNzdWU1Mjc3MTAwNTU=", "number": 640, "title": "Nicer error message for heroku publish name clash", "user": {"value": 82988, "label": "psychemedia"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2019-11-24T14:57:07Z", "updated_at": "2019-12-06T07:19:34Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "If you try to publish to Heroku using no set name (i.e. the default `datasette` name) and a project already exists under that name, you get a meaningful error report on the first line followed by Py error messages that drown it out:\r\n\r\n```\r\nCreating datasette... !\r\n \u25b8 Name datasette is already taken\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/datasette\", line 10, in <module>\r\n sys.exit(cli())\r\n File \"/usr/local/lib/python3.7/site-packages/click/core.py\", line 764, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.7/site-packages/click/core.py\", line 717, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.7/site-packages/click/core.py\", line 1137, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/usr/local/lib/python3.7/site-packages/click/core.py\", line 1137, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/usr/local/lib/python3.7/site-packages/click/core.py\", line 956, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/usr/local/lib/python3.7/site-packages/click/core.py\", line 555, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/Users/NNNNN/Library/Python/3.7/lib/python/site-packages/datasette/publish/heroku.py\", line 124, in heroku\r\n create_output = check_output(cmd).decode(\"utf8\")\r\n File \"/usr/local/Cellar/python/3.7.5/Frameworks/Python.framework/Versions/3.7/lib/python3.7/subprocess.py\", line 411, in check_output\r\n **kwargs).stdout\r\n File \"/usr/local/Cellar/python/3.7.5/Frameworks/Python.framework/Versions/3.7/lib/python3.7/subprocess.py\", line 512, in run\r\n output=stdout, stderr=stderr)\r\nsubprocess.CalledProcessError: Command '['heroku', 'apps:create', 'datasette', '--json']' returned non-zero exit status 1.\r\n```\r\n\r\nIt would be neater if:\r\n\r\n- the Py error message was caught;\r\n- the report suggested setting a project name using `-n` etc.\r\n\r\nIt may also be useful to provide a command to list the current names that are being used, which I assume is available via a Heroku call?", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/640/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 546073980, "node_id": "MDU6SXNzdWU1NDYwNzM5ODA=", "number": 74, "title": "Test failures on openSUSE 15.1: AssertionError: Explicit other_table and other_column", "user": {"value": 15092, "label": "jayvdb"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2020-01-07T04:35:50Z", "updated_at": "2020-01-12T07:21:17Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "openSUSE 15.1 is using python 3.6.5 and click-7.0 , however it has test failures while openSUSE Tumbleweed on py37 passes.\r\n\r\nMost fail on the cli exit code like\r\n```py\r\n[ 74s] =================================== FAILURES ===================================\r\n[ 74s] _________________________________ test_tables __________________________________\r\n[ 74s] \r\n[ 74s] db_path = '/tmp/pytest-of-abuild/pytest-0/test_tables0/test.db'\r\n[ 74s] \r\n[ 74s] def test_tables(db_path):\r\n[ 74s] result = CliRunner().invoke(cli.cli, [\"tables\", db_path])\r\n[ 74s] > assert '[{\"table\": \"Gosh\"},\\n {\"table\": \"Gosh2\"}]' == result.output.strip()\r\n[ 74s] E assert '[{\"table\": \"...e\": \"Gosh2\"}]' == ''\r\n[ 74s] E - [{\"table\": \"Gosh\"},\r\n[ 74s] E - {\"table\": \"Gosh2\"}]\r\n[ 74s] \r\n[ 74s] tests/test_cli.py:28: AssertionError\r\n```\r\n\r\npackaging project at https://build.opensuse.org/package/show/home:jayvdb:py-new/python-sqlite-utils\r\n\r\nI'll keep digging into this after I have github-to-sqlite working on Tumbleweed, as I'll need openSUSE Leap 15.1 working before I can submit this into the main python repo.", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/74/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 546961357, "node_id": "MDU6SXNzdWU1NDY5NjEzNTc=", "number": 656, "title": "Display of the column definitions", "user": {"value": 6371750, "label": "JBPressac"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2020-01-08T16:16:53Z", "updated_at": "2020-01-20T14:17:11Z", "closed_at": "2020-01-20T14:14:33Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Hello,\r\nIs the nice display of headers and definitions at the top of https://fivethirtyeight.datasettes.com/fivethirtyeight-ac35616/antiquities-act%2Factions_under_antiquities_act is configured in the metadata.json file ?\r\nThank you,", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/656/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 600120439, "node_id": "MDU6SXNzdWU2MDAxMjA0Mzk=", "number": 726, "title": "Foreign key : case of a link to the associated row not displayed", "user": {"value": 6371750, "label": "JBPressac"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2020-04-15T08:31:27Z", "updated_at": "2020-04-27T22:05:47Z", "closed_at": "2020-04-27T22:05:46Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Hello,\r\nI use Datasette to publish tsv files linked together by foreign keys declared thanks to sqlite-utils. In one table, [prelib_personne](http://crbc-dataset.huma-num.fr/prelib/prelib_personne), the foreign keys are properly noticed by a link to the associated row (for instance ville_naissance_id is properly linked to prelib_ville). But every link to the foreign key prelib_oeuvre.id fails. For instance, [prelib_ecritoeuvre](http://crbc-dataset.huma-num.fr/prelib/prelib_ecritoeuvre) has links to prelib_personne but none to prelib_oeuvre. In despite of the schema:\r\n\r\nCREATE TABLE \"prelib_ecritoeuvre\" (\r\n\"id\" INTEGER,\r\n \"fonction_id\" INTEGER,\r\n \"oeuvre_id\" INTEGER,\r\n \"personne_id\" INTEGER\r\n ,PRIMARY KEY ([id]),\r\n FOREIGN KEY(fonction_id) REFERENCES prelib_fonctionecritoeuvre(id),\r\n FOREIGN KEY(personne_id) REFERENCES prelib_personne(id),\r\n FOREIGN KEY(oeuvre_id) REFERENCES prelib_oeuvre(id)\r\n); \r\n\r\nWould you have any clue to investigate the reason of this problem?\r\nThanks,", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/726/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 610517472, "node_id": "MDU6SXNzdWU2MTA1MTc0NzI=", "number": 103, "title": "sqlite3.OperationalError: too many SQL variables in insert_all when using rows with varying numbers of columns", "user": {"value": 32605365, "label": "b0b5h4rp13"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 8, "created_at": "2020-05-01T02:26:14Z", "updated_at": "2020-05-14T00:18:57Z", "closed_at": "2020-05-14T00:18:57Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "If using insert_all to put in 1000 rows of data with varying number of columns, it comes up with this message `sqlite3.OperationalError: too many SQL variables` if the number of columns is larger in later records (past the first row)\r\n\r\nI've reduced `SQLITE_MAX_VARS` by 100 to 899 at the top of `db.py` to add wiggle room, so that if the column count increases it wont go past SQLite's batch limit as calculated by this line of code based on the count of the first row's dict keys\r\n\r\n batch_size = max(1, min(batch_size, SQLITE_MAX_VARS // num_columns))", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/103/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 620969465, "node_id": "MDU6SXNzdWU2MjA5Njk0NjU=", "number": 767, "title": "Allow to specify a URL fragment for canned queries", "user": {"value": 2657547, "label": "rixx"}, "state": "closed", "locked": 0, "assignee": null, "milestone": {"value": 5471110, "label": "Datasette 0.43"}, "comments": 2, "created_at": "2020-05-19T13:17:42Z", "updated_at": "2020-05-27T21:52:25Z", "closed_at": "2020-05-27T21:52:25Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Canned queries are very useful to direct users to prepared data and views. I like to use them with charts using datasette-vega a lot, because people get a direct impression at first glance.\r\n\r\ndatasette-vega doesn't show up by default though, and users have to click through to it. Also, datasette-vega does not always guess the best way to render columns correctly though, so it would be nice if I could specify a URL fragment in my canned queries to make sure people see what I want them to see.\r\n\r\nMy current workaround is to include a fragement link in ``description_html`` and ask people to reload the page, like [here](https://data.rixx.de/songs/show_by_bpm#g.mark=bar&g.x_column=bpm_floor&g.x_type=ordinal&g.y_column=bpm_count&g.y_type=quantitative), which is a bit hacky.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/767/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 640330278, "node_id": "MDU6SXNzdWU2NDAzMzAyNzg=", "number": 851, "title": "Having trouble getting writable canned queries to work", "user": {"value": 3243482, "label": "abdusco"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2020-06-17T10:30:28Z", "updated_at": "2020-06-17T10:33:25Z", "closed_at": "2020-06-17T10:32:33Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Hey,\r\n\r\nI'm trying to get canned inserts to work. I have an DB with following metadata:\r\n\r\n```text\r\nsqlite> .mode line\r\n\r\nsqlite> select name, sql from sqlite_master where name like '%search%';\r\n name = search\r\n sql = CREATE TABLE \"search\" (\"id\" INTEGER NOT NULL PRIMARY KEY, \"name\" VARCHAR(255) NOT NULL, \"url\" VARCHAR(255) NOT NULL)\r\n```\r\n\r\n```yaml\r\n# ...\r\nqueries:\r\n add_search:\r\n sql: insert into search(name, url) VALUES (:name, :url),\r\n write: true\r\n```\r\nwhich renders a form as expected, but when I submit the form I get `incomplete input` error.\r\n\r\n\r\n\r\nbut when submit post the form\r\n\r\nI've attached a debugger to see where the error comes from, because `incomplete input` string doesn't appear in datasette codebase.\r\n\r\nInside `datasette.database.Database.execute_write_fn` \r\n\r\nhttps://github.com/simonw/datasette/blob/4fa7cf68536628344356d3ef8c92c25c249067a0/datasette/database.py#L69\r\n\r\n```py\r\nresult = await reply_queue.async_q.get()\r\n```\r\n\r\nthis line raises an exception. \r\n\r\nThat led me to believe I had something wrong with my SQL. But running the command in `sqlite3` inserts the record just fine.\r\n\r\n```text\r\nsqlite> insert into search (name, url) values ('my name', 'my url');\r\nsqlite> SELECT last_insert_rowid();\r\nlast_insert_rowid() = 3\r\n```\r\n\r\nSo I'm a bit lost here.\r\n\r\n---\r\n- datasette, version 0.44\r\n- Python 3.8.1", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/851/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 642572841, "node_id": "MDU6SXNzdWU2NDI1NzI4NDE=", "number": 859, "title": "Database page loads too slowly with many large tables (due to table counts)", "user": {"value": 3243482, "label": "abdusco"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 21, "created_at": "2020-06-21T14:23:17Z", "updated_at": "2021-08-25T21:59:55Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Hey,\r\nI have a database that I save in HTML from couple of web scrapers. There are around 200k+, 50+ rows in a couple of tables, with sqlite file weighing around 600MB.\r\n\r\nThe app runs on a VPS with 2 core CPU, 4GB RAM and refreshing database page regularly takes more than 10 seconds. I was suspecting that counting tables was the culprit, but manually running `select count(*) from table_name` for the largest table finishes under a second.\r\n\r\nI've looked at the source code. There's a check for index page for mutable databases larger than 100MB\r\nhttps://github.com/simonw/datasette/blob/799c5d53570d773203527f19530cf772dc2eeb24/datasette/views/index.py#L15\r\n\r\nbut this check is not performed for database page. \r\nI've manually crippled `Database::table_counts` method\r\n```py\r\nasync def table_counts(self, limit=10):\r\n if not self.is_mutable and self.cached_table_counts is not None:\r\n return self.cached_table_counts\r\n # Try to get counts for each table, $limit timeout for each count\r\n counts = {}\r\n for table in await self.table_names():\r\n try:\r\n # table_count = (\r\n # await self.execute(\r\n # \"select count(*) from [{}]\".format(table),\r\n # custom_time_limit=limit,\r\n # )\r\n # ).rows[0][0]\r\n counts[table] = 10 # table_count\r\n # In some cases I saw \"SQL Logic Error\" here in addition to\r\n # QueryInterrupted - so we catch that too:\r\n except (QueryInterrupted, sqlite3.OperationalError, sqlite3.DatabaseError):\r\n counts[table] = None\r\n if not self.is_mutable:\r\n self.cached_table_counts = counts\r\n return counts\r\n```\r\n\r\nnow the page loads in <100ms.\r\n\r\nIs it possible to apply size check on database page too?\r\n\r\n<details>\r\n<summary>\r\n/-/versions output\r\n</summary>\r\n<pre>\r\n{\r\n \"python\": {\r\n \"version\": \"3.8.0\",\r\n \"full\": \"3.8.0 (default, Oct 28 2019, 16:14:01) \\n[GCC 8.3.0]\"\r\n },\r\n \"datasette\": {\r\n \"version\": \"0.44\"\r\n },\r\n \"asgi\": \"3.0\",\r\n \"uvicorn\": \"0.11.5\",\r\n \"sqlite\": {\r\n \"version\": \"3.22.0\",\r\n \"fts_versions\": [\r\n \"FTS5\",\r\n \"FTS4\",\r\n \"FTS3\"\r\n ],\r\n \"extensions\": {\r\n \"json1\": null\r\n },\r\n \"compile_options\": [\r\n \"COMPILER=gcc-7.4.0\",\r\n \"ENABLE_COLUMN_METADATA\",\r\n \"ENABLE_DBSTAT_VTAB\",\r\n \"ENABLE_FTS3\",\r\n \"ENABLE_FTS3_PARENTHESIS\",\r\n \"ENABLE_FTS3_TOKENIZER\",\r\n \"ENABLE_FTS4\",\r\n \"ENABLE_FTS5\",\r\n \"ENABLE_JSON1\",\r\n \"ENABLE_LOAD_EXTENSION\",\r\n \"ENABLE_PREUPDATE_HOOK\",\r\n \"ENABLE_RTREE\",\r\n \"ENABLE_SESSION\",\r\n \"ENABLE_STMTVTAB\",\r\n \"ENABLE_UNLOCK_NOTIFY\",\r\n \"ENABLE_UPDATE_DELETE_LIMIT\",\r\n \"HAVE_ISNAN\",\r\n \"LIKE_DOESNT_MATCH_BLOBS\",\r\n \"MAX_SCHEMA_RETRY=25\",\r\n \"MAX_VARIABLE_NUMBER=250000\",\r\n \"OMIT_LOOKASIDE\",\r\n \"SECURE_DELETE\",\r\n \"SOUNDEX\",\r\n \"TEMP_STORE=1\",\r\n \"THREADSAFE=1\"\r\n ]\r\n }\r\n}\r\n</pre>\r\n</details>", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/859/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 649702801, "node_id": "MDU6SXNzdWU2NDk3MDI4MDE=", "number": 888, "title": "URLs in release notes point to 127.0.0.1", "user": {"value": 3243482, "label": "abdusco"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2020-07-02T07:28:04Z", "updated_at": "2020-09-15T20:39:50Z", "closed_at": "2020-09-15T20:39:49Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Just a quick heads up:\r\n\r\nRelease notes for 0.45 include urls that point to localhost. \r\n\r\nhttps://github.com/simonw/datasette/releases/tag/0.45", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/888/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 649907676, "node_id": "MDU6SXNzdWU2NDk5MDc2NzY=", "number": 889, "title": "asgi_wrapper plugin hook is crashing at startup", "user": {"value": 49260, "label": "amjith"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2020-07-02T12:53:13Z", "updated_at": "2020-09-15T20:40:52Z", "closed_at": "2020-09-15T20:40:52Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Steps to reproduce: \r\n\r\n1. Install datasette-media plugin \r\n`pip install datasette-media`\r\n2. Launch datasette\r\n`datasette databasename.db`\r\n3. Error\r\n\r\n```\r\nINFO: Started server process [927704]\r\nINFO: Waiting for application startup.\r\nERROR: Exception in 'lifespan' protocol\r\nTraceback (most recent call last):\r\n File \"/home/amjith/.virtualenvs/itsysearch/lib/python3.7/site-packages/uvicorn/lifespan/on.py\", line 48, in main\r\n await app(scope, self.receive, self.send)\r\n File \"/home/amjith/.virtualenvs/itsysearch/lib/python3.7/site-packages/uvicorn/middleware/proxy_headers.py\", line 45, in __call__\r\n return await self.app(scope, receive, send)\r\n File \"/home/amjith/.virtualenvs/itsysearch/lib/python3.7/site-packages/datasette_media/__init__.py\", line 9, in wrapped_app\r\n path = scope[\"path\"]\r\nKeyError: 'path'\r\nERROR: Application startup failed. Exiting.\r\n```", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/889/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 686978131, "node_id": "MDU6SXNzdWU2ODY5NzgxMzE=", "number": 139, "title": "insert_all(..., alter=True) should work for new columns introduced after the first 100 records", "user": {"value": 96218, "label": "simonwiles"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 7, "created_at": "2020-08-27T06:25:25Z", "updated_at": "2020-08-28T22:48:51Z", "closed_at": "2020-08-28T22:30:14Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Is there a way to make `.insert_all()` work properly when new columns are introduced outside the first 100 records (with or without the `alter=True` argument)?\r\n\r\nI'm using `.insert_all()` to bulk insert ~3-4k records at a time and it is common for records to need to introduce new columns. However, if new columns are introduced after the first 100 records, `sqlite_utils` doesn't even raise the `OperationalError: table ... has no column named ...` exception; it just silently drops the extra data and moves on.\r\n\r\nIt took me a while to find this little snippet in the [documentation for `.insert_all()`](https://sqlite-utils.readthedocs.io/en/stable/python-api.html#bulk-inserts) (it's not mentioned under [Adding columns automatically on insert/update](https://sqlite-utils.readthedocs.io/en/stable/python-api.html#bulk-inserts)):\r\n\r\n> The column types used in the CREATE TABLE statement are automatically derived from the types of data in that first batch of rows. **_Any additional or missing columns in subsequent batches will be ignored._**\r\n\r\nI tried changing the `batch_size` argument to the total number of records, but it seems only to effect the number of rows that are committed at a time, and has no influence on this problem.\r\n\r\nIs there a way around this that you would suggest? It seems like it should raise an exception at least.", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/139/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 688659182, "node_id": "MDU6SXNzdWU2ODg2NTkxODI=", "number": 145, "title": "Bug when first record contains fewer columns than subsequent records", "user": {"value": 96218, "label": "simonwiles"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2020-08-30T05:44:44Z", "updated_at": "2020-09-08T23:21:23Z", "closed_at": "2020-09-08T23:21:23Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "`insert_all()` selects the maximum batch size based on the number of fields in the first record. If the first record has fewer fields than subsequent records (and `alter=True` is passed), this can result in SQL statements with more than the maximum permitted number of host parameters. This situation is perhaps unlikely to occur, but could happen if the first record had, say, 10 columns, such that `batch_size` (based on `SQLITE_MAX_VARIABLE_NUMBER = 999`) would be 99. If the next 98 rows had 11 columns, the resulting SQL statement for the first batch would have `10 * 1 + 11 * 98 = 1088` host parameters (and subsequent batches, if the data were consistent from thereon out, would have `99 * 11 = 1089`).\r\n\r\nI suspect that this bug is masked somewhat by the fact that while:\r\n> [`SQLITE_MAX_VARIABLE_NUMBER`](https://www.sqlite.org/limits.html#max_variable_number) ... defaults to 999 for SQLite versions prior to 3.32.0 (2020-05-22) or 32766 for SQLite versions after 3.32.0.\r\n\r\nit is common that it is increased at compile time. Debian-based systems, for example, seem to ship with a version of sqlite compiled with `SQLITE_MAX_VARIABLE_NUMBER` set to 250,000, and I believe this is the case for homebrew installations too.\r\n\r\nA test for this issue might look like this:\r\n```python\r\ndef test_columns_not_in_first_record_should_not_cause_batch_to_be_too_large(fresh_db):\r\n # sqlite on homebrew and Debian/Ubuntu etc. is typically compiled with\r\n # SQLITE_MAX_VARIABLE_NUMBER set to 250,000, so we need to exceed this value to\r\n # trigger the error on these systems.\r\n THRESHOLD = 250000\r\n extra_columns = 1 + (THRESHOLD - 1) // 99\r\n records = [\r\n {\"c0\": \"first record\"}, # one column in first record -> batch_size = 100\r\n # fill out the batch with 99 records with enough columns to exceed THRESHOLD\r\n *[\r\n dict([(\"c{}\".format(i), j) for i in range(extra_columns)])\r\n for j in range(99)\r\n ]\r\n ]\r\n try:\r\n fresh_db[\"too_many_columns\"].insert_all(records, alter=True)\r\n except sqlite3.OperationalError:\r\n raise\r\n```\r\n\r\nThe best solution, I think, is simply to process all the records when determining columns, column types, and the batch size. In my tests this doesn't seem to be particularly costly at all, and cuts out a lot of complications (including obviating my implementation of #139 at #142). I'll raise a PR for your consideration.\r\n\r\n", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/145/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 688670158, "node_id": "MDU6SXNzdWU2ODg2NzAxNTg=", "number": 147, "title": "SQLITE_MAX_VARS maybe hard-coded too low", "user": {"value": 96218, "label": "simonwiles"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 7, "created_at": "2020-08-30T07:26:45Z", "updated_at": "2021-02-15T21:27:55Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I came across this while about to open an issue and PR against the documentation for `batch_size`, which is a bit incomplete.\r\n\r\nAs mentioned in #145, while:\r\n\r\n> [`SQLITE_MAX_VARIABLE_NUMBER`](https://www.sqlite.org/limits.html#max_variable_number) ... defaults to 999 for SQLite versions prior to 3.32.0 (2020-05-22) or 32766 for SQLite versions after 3.32.0.\r\n\r\nit is common that it is increased at compile time. Debian-based systems, for example, seem to ship with a version of sqlite compiled with SQLITE_MAX_VARIABLE_NUMBER set to 250,000, and I believe this is the case for homebrew installations too.\r\n\r\nIn working to understand what `batch_size` was actually doing and why, I realized that by setting `SQLITE_MAX_VARS` in `db.py` to match the value my sqlite was compiled with (I'm on Debian), I was able to decrease the time to `insert_all()` my test data set (~128k records across 7 tables) from ~26.5s to ~3.5s. Given that this about .05% of my total dataset, this is time I am keen to save...\r\n\r\nUnfortunately, it seems that `sqlite3` in the python standard library doesn't expose the `get_limit()` C API (even though `pysqlite` used to), so it's hard to know what value sqlite has been compiled with (note that this could mean, I suppose, that it's less than 999, and even hardcoding `SQLITE_MAX_VARS` to the conservative default might not be adequate. It can also be lowered -- but not raised -- at runtime). The best I could come up with is `echo \"\" | sqlite3 -cmd \".limits variable_number\"` (only available in `sqlite >= 2015-05-07 (3.8.10)`).\r\n\r\nObviously this couldn't be relied upon in `sqlite_utils`, but I wonder what your opinion would be about exposing `SQLITE_MAX_VARS` as a user-configurable parameter (with suitable \"here be dragons\" warnings)? I'm going to go ahead and monkey-patch it for my purposes in any event, but it seems like it might be worth considering.", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/147/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 698791218, "node_id": "MDU6SXNzdWU2OTg3OTEyMTg=", "number": 50, "title": "favorites --stop_after=N stops after min(N, 200)", "user": {"value": 370930, "label": "mikepqr"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2020-09-11T03:38:14Z", "updated_at": "2020-09-13T05:11:14Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "For any number greater than 200, `favorites --stop_after` stops after getting 200 tweets, e.g.\r\n```\r\n$ twitter-to-sqlite favorites tweets.db --stop_after=300\r\nImporting favorites [####################################] 199\r\n$\r\n```\r\nI don't _think_ this is a limitation of the API (if you omit `--stop_after` you get some very large number, possibly all of them), so I _think_ this is a bug.", "repo": {"value": 206156866, "label": "twitter-to-sqlite"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/50/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 708185405, "node_id": "MDU6SXNzdWU3MDgxODU0MDU=", "number": 975, "title": "Dependabot couldn't authenticate with https://pypi.python.org/simple/", "user": {"value": 27856297, "label": "dependabot-preview[bot]"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2020-09-24T13:44:40Z", "updated_at": "2020-09-25T13:34:34Z", "closed_at": "2020-09-25T13:34:34Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Dependabot couldn't authenticate with https://pypi.python.org/simple/.\n\nYou can provide authentication details in your [Dependabot dashboard](https://app.dependabot.com/accounts/simonw) by clicking into the account menu (in the top right) and selecting 'Config variables'.\n\n[View the update logs](https://app.dependabot.com/accounts/simonw/update-logs/48611311).", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/975/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 721050815, "node_id": "MDU6SXNzdWU3MjEwNTA4MTU=", "number": 1019, "title": "\"Edit SQL\" button on canned queries", "user": {"value": 639012, "label": "jsfenfen"}, "state": "closed", "locked": 0, "assignee": null, "milestone": {"value": 6026070, "label": "0.51"}, "comments": 7, "created_at": "2020-10-14T00:51:39Z", "updated_at": "2020-10-23T19:44:06Z", "closed_at": "2020-10-14T03:44:23Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Feature request: Would it be possible to add an \"edit this query\" button on canned queries? Clicking it would open the canned query as an editable sql query. I think the intent is to have named parameters to allow this, but sometimes you just gotta rewrite it? ", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1019/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 748372469, "node_id": "MDU6SXNzdWU3NDgzNzI0Njk=", "number": 9, "title": "ParseError: undefined entity š", "user": {"value": 4028322, "label": "mkorosec"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2020-11-22T23:04:35Z", "updated_at": "2021-02-11T22:10:55Z", "closed_at": "2021-02-11T22:10:55Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I encountered a parse error if the enex file contained š or \r\n\r\nRun command: \r\nevernote-to-sqlite enex evernote.db evernote.enex\r\n\r\n```\r\nTraceback (most recent call last):\r\n...\r\n File \"evernote_to_sqlite/cli.py\", line 31, in enex\r\n save_note(db, note)\r\n File \"evernote_to_sqlite/utils.py\", line 35, in save_note\r\n content = ET.tostring(ET.fromstring(content_xml)).decode(\"utf-8\")\r\n File \"/usr/lib/python3.8/xml/etree/ElementTree.py\", line 1320, in XML\r\n parser.feed(text)\r\nxml.etree.ElementTree.ParseError: undefined entity š: line 3, column 35\r\n```\r\n\r\nWorkaround:\r\n```\r\nsed -i 's/š//g' evernote.enex\r\nsed -i 's/ //g' evernote.enex\r\n```", "repo": {"value": 303218369, "label": "evernote-to-sqlite"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/dogsheep/evernote-to-sqlite/issues/9/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 751195017, "node_id": "MDU6SXNzdWU3NTExOTUwMTc=", "number": 1111, "title": "Accessing a database's `.json` is slow for very large SQLite files", "user": {"value": 15178711, "label": "asg017"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2020-11-26T00:27:27Z", "updated_at": "2021-01-04T19:57:53Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I have a SQLite DB that's pretty large, 23GB and something like 300 million rows. I expect that most queries I run on it will be slow, which is fine, but there are some things that Datasette does that makes working with the DB very slow. Specifically, when I access the `.json` metadata for a table (which I believe it comes from `datasette/views/database.py`, it takes 43 seconds for the request to come in:\r\n\r\n```bash\r\n$ time curl localhost:9999/out.json\r\n{\"database\": \"out\", \"size\": 24291454976, \"tables\": [{\"name\": \"PageviewsHour\", \"columns\": [\"file\", \"code\", \"page\", \"pageviews\"], \"primary_keys\": [], \"count\": null, \"hidden\": false, \"fts_table\": null, \"foreign_keys\": {\"incoming\": [], \"outgoing\": [{\"other_table\": \"PageviewsHourFiles\", \"column\": \"file\", \"other_column\": \"file_id\"}]}, \"private\": false}, {\"name\": \"PageviewsHourFiles\", \"columns\": [\"file_id\", \"filename\", \"sha256\", \"size\", \"day\", \"hour\"], \"primary_keys\": [\"file_id\"], \"count\": null, \"hidden\": false, \"fts_table\": null, \"foreign_keys\": {\"incoming\": [{\"other_table\": \"PageviewsHour\", \"column\": \"file_id\", \"other_column\": \"file\"}], \"outgoing\": []}, \"private\": false}, {\"name\": \"sqlite_sequence\", \"columns\": [\"name\", \"seq\"], \"primary_keys\": [], \"count\": 1, \"hidden\": false, \"fts_table\": null, \"foreign_keys\": {\"incoming\": [], \"outgoing\": []}, \"private\": false}], \"hidden_count\": 0, \"views\": [], \"queries\": [], \"private\": false, \"allow_execute_sql\": true, \"query_ms\": 43340.23213386536}\r\nreal\t0m43.417s\r\nuser\t0m0.006s\r\nsys\t0m0.016s\r\n```\r\n\r\nI suspect this is because a `COUNT(*)` is happening under the hood, which, when I run it through sqlite directly, does take around the same time:\r\n\r\n```bash\r\n$ time sqlite3 out.db < <(echo \"select count(*) from PageviewsHour;\")\r\n362794272\r\n\r\nreal\t0m44.523s\r\nuser\t0m2.497s\r\nsys\t0m6.703s\r\n```\r\n\r\nI'm using the `.json` request in the [Observable Datasette Client](https://observablehq.com/@asg017/datasette-client) to 1) verify that a link passed in is a reachable Datasette instance, and 2) a quick way to look at metadata for a db. A few different solutions I can think of:\r\n\r\n1. Have some other endpoint, like `/-/datasette.json` that the Observable Datasette client can fetch from to verify that the passed in URL is a valid Datasette (doesnt solve the slow problem, feel free to split this issue into 2)\r\n2. Have a way to turn off table counts when accessing a database's `.json` view, like `?no_count=1` or something\r\n3. Maybe have a timeout on the `table_counts()` function if it takes too long. which is odd, because it seems like it already does that (I think?), I can debug a little more if that's the case\r\n\r\nMore than happy to debug further, or send a PR if you like one of the proposals above!", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1111/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 752966476, "node_id": "MDU6SXNzdWU3NTI5NjY0NzY=", "number": 1114, "title": "--load-extension=spatialite not working with datasetteproject/datasette docker image", "user": {"value": 2182, "label": "danp"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2020-11-29T17:35:20Z", "updated_at": "2022-01-20T21:29:42Z", "closed_at": "2020-11-29T17:37:45Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "https://github.com/simonw/datasette/commit/6aa5886379dd9017215904fb28567b80018902f9 added the `--load-extension=spatialite` shortcut looking for the extension in these places:\r\n\r\nhttps://github.com/simonw/datasette/blob/12877d7a48e2aa28bb5e780f929a218f7265d849/datasette/utils/__init__.py#L56-L60\r\n\r\nHowever, in the datasetteproject/datasette docker image the file is at `/usr/local/lib/mod_spatialite.so`.\r\n\r\nThis results in the example command [here](https://docs.datasette.io/en/stable/installation.html#loading-spatialite) failing:\r\n\r\n```\r\n% docker run --rm -p 8001:8001 -v `pwd`:/mnt datasetteproject/datasette datasette -p 8001 -h 0.0.0.0 /mnt/data.db --load-extension=spatialite\r\nError: Could not find SpatiaLite extension\r\n```\r\n\r\nBut it does work when given an explicit path:\r\n\r\n```\r\n% docker run --rm -p 8001:8001 -v `pwd`:/mnt datasetteproject/datasette datasette -p 8001 -h 0.0.0.0 /mnt/data.db --load-extension=/usr/local/lib/mod_spatialite.so\r\nINFO: Started server process [1]\r\nINFO: Waiting for application startup.\r\nINFO: Application startup complete.\r\nINFO: Uvicorn running on http://0.0.0.0:8001 (Press CTRL+C to quit)\r\n...\r\n```\r\n\r\nPerhaps `SPATIALITE_PATHS` should include `/usr/local/lib/mod_spatialite.so`?", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1114/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 754178780, "node_id": "MDU6SXNzdWU3NTQxNzg3ODA=", "number": 1121, "title": "Table actions cog is misaligned", "user": {"value": 3243482, "label": "abdusco"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2020-12-01T08:41:25Z", "updated_at": "2020-12-03T01:03:19Z", "closed_at": "2020-12-03T00:33:36Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "At the moment it looks like this\r\nhttps://datasette-graphql-demo.datasette.io/github/repos\r\n\r\n\r\n\r\nAdding a few flex statements fixes the alignment and centers `h1` text and the cog icon vertically.\r\n\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1121/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 756875827, "node_id": "MDU6SXNzdWU3NTY4NzU4Mjc=", "number": 1129, "title": "Fix footer to the bottom of the page", "user": {"value": 3243482, "label": "abdusco"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2020-12-04T07:28:07Z", "updated_at": "2020-12-04T16:04:29Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Footer doesn't stick to the bottom if the body content isn't long enough to reach the end of viewport.\r\n\r\n\r\n\r\n\r\nThis can be fixed using flexbox.\r\n\r\n```css\r\nbody {\r\n min-height: 100vh;\r\n display: flex;\r\n flex-direction: column;\r\n}\r\n\r\n.content {\r\n flex-grow: 1;\r\n}\r\n```\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1129/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 766156875, "node_id": "MDU6SXNzdWU3NjYxNTY4NzU=", "number": 209, "title": "Test failure with sqlite 3.34 in test_cli.py::test_optimize", "user": {"value": 191622, "label": "meatcar"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2020-12-14T08:58:18Z", "updated_at": "2021-01-01T23:52:46Z", "closed_at": "2021-01-01T23:52:46Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "pytest output:\r\n```\r\n...\r\n============================== short test summary info ===============================\r\nFAILED tests/test_cli.py::test_optimize[tables0] - assert 1662976 < 1662976\r\nFAILED tests/test_cli.py::test_optimize[tables1] - assert 1667072 < 1662976\r\n===================== 2 failed, 538 passed, 3 skipped in 34.32s ======================\r\n```\r\n\r\nCame across this while packaging `sqlite-utils` for NixOS, but it can be recreated it using the `alpine:edge` docker image as well as follows:\r\n\r\n```\r\ndocker run --rm -it alpine:edge /bin/sh\r\n# apk update && apk add git sqlite python3 gcc python3-dev musl-dev && python3 -m ensurepip\r\n# git clone https://github.com/simonw/sqlite-utils.git\r\n# cd sqlite-utils/\r\n# pip3 install -e .[test]\r\n# pytest\r\n```\r\n\r\nThis definitely works on sqlite v3.33.", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/209/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 777677671, "node_id": "MDU6SXNzdWU3Nzc2Nzc2NzE=", "number": 1169, "title": "Prettier package not actually being cached", "user": {"value": 3637, "label": "benpickles"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2021-01-03T17:04:41Z", "updated_at": "2021-01-04T19:52:34Z", "closed_at": "2021-01-04T19:52:33Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "With the current configuration Prettier seems to be installed on every run - which can been [seen from the output](https://github.com/simonw/datasette/runs/1631686028?check_suite_focus=true#step:4:4):\r\n\r\n```\r\nnpx: installed 1 in 5.166s\r\n```\r\n\r\nPrettier isn't explicitly being installed (it's surprising that actually installing the dependencies isn't included in the [actions/cache docs](https://github.com/actions/cache/blob/main/examples.md#macos-and-ubuntu)) but it turns out that `npx` will automatically install the package for the specified command (it actually _guesses_ the package name from the name of the command). I'm not sure where Prettier ends up being installed but it doesn't appear to be in `~/.npm` according to the [post-cache output](https://github.com/simonw/datasette/runs/1631686028#step:7:2) (or `./node_modules` when I tested locally):\r\n\r\n```\r\nCache hit occurred on the primary key Linux-npm-565329898f77080e58b14d45cf816ab94877e6f2ece9d395c369c533548a7ee7, not saving cache.\r\n```\r\n\r\nI think there are a couple of approaches to tackling this, you could manually install/cache Prettier within the action, or add a `package.json` with Prettier. I would go with the latter because it's a more standard and maintainable approach and it will also ensure that, along with CI, anyone working on the project will run the same version of Prettier (you'll also get Dependabot JavaScript updates).\r\n\r\nI've tested the [`package.json` approach on a branch](https://github.com/simonw/datasette/compare/main...benpickles:cache-prettier) and am happy to turn it into a pull request if you fancy.\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1169/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 779088071, "node_id": "MDU6SXNzdWU3NzkwODgwNzE=", "number": 54, "title": "Archive import appears to be broken on recent exports", "user": {"value": 21148, "label": "jacobian"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 5, "created_at": "2021-01-05T14:18:01Z", "updated_at": "2023-01-04T11:06:55Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I requested a Twitter export yesterday, and unfortunately they seem to have changed it such that `twitter-to-sqlite import` can't handle it anymore \ud83d\ude22 \r\n\r\nSo far I've ran into two issues. The first was easy to work around, but the second will take more investigation. If I can find the time I'll keep working on it and update this issue accordingly.\r\n\r\nThe issues (so far):\r\n\r\n### 1. Data seems to have moved to a `data/` subdirectory\r\n\r\nRunning `twitter-to-sqlite import` on the raw zip file reports a bunch of \"not yet implemented\" errors, and then exits without actually importing anything:\r\n\r\n```\r\n\u276f twitter-to-sqlite import tarchive.db twitter.zip\r\n...\r\ndata/manifest: not yet implemented\r\ndata/account-creation-ip: not yet implemented\r\ndata/account-suspension: not yet implemented\r\n... (dozens of more lines like this, including critical stuff like data/tweets) ...\r\n```\r\n\r\n(`tarchive.db` now exists, but is empty)\r\n\r\nWorkaround: unpack the zip file, and run `twitter-to-sqlite import tarchive.db path/to/archive/data`\r\n\r\nThat gets further, but:\r\n\r\n### 2. Some schema(s?) have changed\r\n\r\nAt least, the `blocks` schema seems different now:\r\n\r\n```\r\n\u276f twitter-to-sqlite import tarchive.db archive/data\r\ndirect-messages-group: not yet implemented\r\nbranch-links: not yet implemented\r\nperiscope-expired-broadcasts: not yet implemented\r\ndirect-messages: not yet implemented\r\nmute: not yet implemented\r\nTraceback (most recent call last):\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/bin/twitter-to-sqlite\", line 8, in <module>\r\n sys.exit(cli())\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/lib/python3.8/site-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/lib/python3.8/site-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/lib/python3.8/site-packages/click/core.py\", line 1259, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/lib/python3.8/site-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/lib/python3.8/site-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/lib/python3.8/site-packages/twitter_to_sqlite/cli.py\", line 772, in import_\r\n archive.import_from_file(db, filepath.name, open(filepath, \"rb\").read())\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/lib/python3.8/site-packages/twitter_to_sqlite/archive.py\", line 215, in import_from_file\r\n to_insert = transformer(data)\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/lib/python3.8/site-packages/twitter_to_sqlite/archive.py\", line 115, in lists_member\r\n return {\"lists-member\": _list_from_common(data)}\r\n File \"/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/lib/python3.8/site-packages/twitter_to_sqlite/archive.py\", line 200, in _list_from_common\r\n for url in block[\"userListInfo\"][\"urls\"]:\r\nKeyError: 'urls'\r\n```\r\n\r\nThat's as far as I got before I needed to work on something else. I'll report back if I get further!", "repo": {"value": 206156866, "label": "twitter-to-sqlite"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/54/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 794554881, "node_id": "MDU6SXNzdWU3OTQ1NTQ4ODE=", "number": 1208, "title": "A lot of open(file) functions are used without a context manager thus producing ResourceWarning: unclosed file <_io.TextIOWrapper", "user": {"value": 4488943, "label": "kbaikov"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2021-01-26T20:56:28Z", "updated_at": "2021-03-11T16:15:49Z", "closed_at": "2021-03-11T16:15:49Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Your code is full of open files that are never closed, especially when you deal with reading/writing json/yaml files.\r\n\r\nIf you run python with warnings enabled this problem becomes evident.\r\nThis probably contributes to some memory leaks in long running datasettes if the GC will not 'collect' those resources properly.\r\n\r\nThis is easily fixed by using a context manager instead of just using open:\r\n```python\r\nwith open('some_file', 'w') as opened_file:\r\n opened_file.write('string')\r\n```\r\n\r\nIn some newer parts of the code you use Path objects 'read_text' and 'write_text' functions which close the file properly and are prefered in some cases.\r\n\r\n\r\nIf you want I can create a PR for all places i found this pattern in.\r\n\r\n\r\nBellow is a fraction of places where i found a ResourceWarning:\r\n```python\r\n\r\nupdate-docs-help.py:\r\n 20 actual = actual.replace(\"Usage: cli \", \"Usage: datasette \")\r\n 21: open(docs_path / filename, \"w\").write(actual)\r\n 22 \r\n\r\ndatasette\\app.py:\r\n 210 ):\r\n 211: inspect_data = json.load((config_dir / \"inspect-data.json\").open())\r\n 212 if immutables is None:\r\n\r\n 266 if config_dir and (config_dir / \"settings.json\").exists() and not config:\r\n 267: config = json.load((config_dir / \"settings.json\").open())\r\n 268 self._settings = dict(DEFAULT_SETTINGS, **(config or {}))\r\n\r\n 445 self._app_css_hash = hashlib.sha1(\r\n 446: open(os.path.join(str(app_root), \"datasette/static/app.css\"))\r\n 447 .read()\r\n\r\ndatasette\\cli.py:\r\n 130 else:\r\n 131: out = open(inspect_file, \"w\")\r\n 132 loop = asyncio.get_event_loop()\r\n\r\n 459 if inspect_file:\r\n 460: inspect_data = json.load(open(inspect_file))\r\n 461 \r\n\r\n```\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1208/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 797097140, "node_id": "MDU6SXNzdWU3OTcwOTcxNDA=", "number": 60, "title": "Use Data from SQLite in other commands", "user": {"value": 22578954, "label": "daniel-butler"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2021-01-29T18:35:52Z", "updated_at": "2021-02-12T18:29:43Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "As a total beginner here how could you access data from the sqlite table to run other commands.\r\n\r\nWhat I am thinking is I want to get all the repos in an organization then using the repo list pull all the commit messages for each repo. \r\n\r\nI love this project by the way!", "repo": {"value": 207052882, "label": "github-to-sqlite"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/dogsheep/github-to-sqlite/issues/60/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 797651831, "node_id": "MDU6SXNzdWU3OTc2NTE4MzE=", "number": 1212, "title": "Tests are very slow. ", "user": {"value": 4488943, "label": "kbaikov"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2021-01-31T08:06:16Z", "updated_at": "2021-02-19T22:54:13Z", "closed_at": "2021-02-19T22:54:13Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Working on my PR i noticed that tests are very slow.\r\n\r\nThe plain pytest run took about 37 minutes for me.\r\nHowever i could shave of about 10 minutes from that if i used pytest-xdist to parallelize execution.\r\n`pytest -n 8` is run only in 28 minutes on my machine.\r\n\r\nI can create a PR to mention that in your documentation.\r\nThis will be a simple change to add pytest-xdist to requirements and change a command to run pytest in documentation.\r\n\r\nDoes that make sense to you?\r\n\r\nAfter a bit more investigation it looks like python-xdist is not an answer. It creates a race condition for tests that try to clead temp dir before run.\r\n\r\nProfiling shows that most time is spent on conn.executescript(TABLES) in make_app_client function. Which makes sense.\r\n\r\nPerhaps the better approach would be look at the app_client fixture which is already session scoped, but not used by all test cases.\r\nAnd/or use conn = sqlite3.connect(\":memory:\") which is much faster.\r\nAnd/or truncate tables after each TC instead of deleting the file and re-creating them.\r\n\r\nI can take a look which is the best approach if you give the go-ahead. ", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1212/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 797784080, "node_id": "MDU6SXNzdWU3OTc3ODQwODA=", "number": 62, "title": "Stargazers and workflows commands always require an auth file when using GITHUB_TOKEN ", "user": {"value": 631242, "label": "frosencrantz"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-01-31T18:56:05Z", "updated_at": "2021-01-31T18:56:05Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Requested fix in https://github.com/dogsheep/github-to-sqlite/pull/59\r\n\r\nThe stargazers and workflows commands always require an auth file, even when using a `GITHUB_TOKEN`. Other commands don't require the auth file.\r\n\r\n", "repo": {"value": 207052882, "label": "github-to-sqlite"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/dogsheep/github-to-sqlite/issues/62/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 807433181, "node_id": "MDU6SXNzdWU4MDc0MzMxODE=", "number": 1224, "title": "can't start immutable databases from configuration dir mode", "user": {"value": 295329, "label": "camallen"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-02-12T17:50:13Z", "updated_at": "2021-03-29T00:17:31Z", "closed_at": "2021-03-29T00:17:31Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Say I have a `/databases/` directory with multiple sqlite db files in that dir (`1.db` & `2.db`) and an `inspect-data.json` file.\r\n\r\nIf I start datasette via `datasette -h 0.0.0.0 /databases/` then the resulting databases are set to `is_mutable: true` as inspected via http://127.0.0.1:8001/-/databases.json\r\n\r\nI don't want to have to list out the databases by name, e.g. `datasette -i /databases/1.db -i /databases/2.db` as i want the system to autodetect the sqlite dbs i have in the configuration directory \r\n\r\nAccording to the docs outlined in https://docs.datasette.io/en/latest/settings.html?highlight=immutable#configuration-directory-mode this should be possible\r\n> `inspect-data.json` the result of running datasette inspect - any database files listed here will be treated as immutable, so they should not be changed while Datasette is running\r\n \r\nI believe that if the `inspect-json.json` file present, then in theory the databases will be automatically set to immutable via this code https://github.com/simonw/datasette/blob/9603d893b9b72653895318c9104d754229fdb146/datasette/app.py#L211-L216\r\n\r\nHowever it appears the Click Multiple Options will return a tuple via https://github.com/simonw/datasette/blob/9603d893b9b72653895318c9104d754229fdb146/datasette/cli.py#L311-L317\r\n\r\nThe resulting tuple is passed to the Datasette app via `kwargs` and overrides the behaviour to set the databases to immutable via this arg https://github.com/simonw/datasette/blob/9603d893b9b72653895318c9104d754229fdb146/datasette/app.py#L182\r\n\r\nIf you think this is a bug and needs fixing, I am willing to make a PR to check for the empty `immutable` tuple before calling the Datasette class initializer as I think leaving that class interface alone is the best path here.\r\n\r\nThoughts?\r\n\r\nAlso - i'm loving Datasette, it truly is a wonderful tool, thank you :)", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1224/reactions\", \"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 817989436, "node_id": "MDU6SXNzdWU4MTc5ODk0MzY=", "number": 242, "title": "Async support", "user": {"value": 25778, "label": "eyeseast"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 13, "created_at": "2021-02-27T18:29:38Z", "updated_at": "2021-10-28T14:37:56Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Following our conversation last week, want to note this here before I forget.\r\n\r\nI've had a couple situations where I'd like to do a bunch of updates in an async event loop, but I run into SQLite's issues with concurrent writes. This feels like something sqlite-utils could help with.\r\n\r\nPeeWee ORM has a [SQLite write queue](http://docs.peewee-orm.com/en/latest/peewee/playhouse.html#sqliteq) that might be a good model. It's using threads or gevent, but I _think_ that approach would translate well enough to asyncio. \r\n\r\nHappy to help with this, too.", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/242/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 831751367, "node_id": "MDU6SXNzdWU4MzE3NTEzNjc=", "number": 246, "title": "Escaping FTS search strings", "user": {"value": 16001974, "label": "DeNeutoy"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2021-03-15T12:15:09Z", "updated_at": "2021-08-18T18:57:13Z", "closed_at": "2021-08-18T18:43:12Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "\r\nThanks for the excellent library, it's very nice to use!\r\n\r\nI've been building some in memory search functionality for a data annotation tool i'm making, and I got tripped up a little bit with escaping the full text search queries. First I tried using `db.quote(q)`, which doesn't work, because sqlite FTS has it's own (separate)[ query syntax](https://www2.sqlite.org/fts5.html#full_text_query_syntax). You can see this happening here also:\r\n\r\nhttp://search-24ways.herokuapp.com/24ways-f8f455f/articles?_search=acces%2A\r\n\r\nI got around this by aggressively escaping quotes inside the query string like this:\r\n\r\n```python\r\n quoted = q.replace('\"', '\"\"')\r\n quoted = f'\"{quoted}\"'\r\n print(quoted)\r\n results = db[\"data\"].search(quoted, columns=[\"id\"])\r\n return [x[\"id\"] for x in results]\r\n\r\n```\r\n\r\nThis works in the sense it doesn't crash, but it also removes access to the search query syntax. Given the well specified definition, it might be possible for sqlite-utils to provide a `db.quote_query(q)` which would intelligently escape a query whilst leaving the syntax intact. This would be very nice!\r\n\r\n\r\n\r\n", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/246/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 839008371, "node_id": "MDU6SXNzdWU4MzkwMDgzNzE=", "number": 1274, "title": "Might there be some way to comment metadata.json?", "user": {"value": 192568, "label": "mroswell"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2021-03-23T18:33:00Z", "updated_at": "2021-03-23T20:14:54Z", "closed_at": "2021-03-23T20:14:54Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I don't know what license to use... Would be nice to be able to add a comment regarding that uncertainty in my metadata.json file\r\n\r\nI like laktak's little video comment in favor of Human json (Hjson)\r\nhttps://stackoverflow.com/questions/244777/can-comments-be-used-in-json\r\n\r\nHmmm... one of the commenters there said comments are allowed in yaml... so that's a good argument for yaml.\r\n\r\nAnyhow, just came to mind, and thought I'd mention it here. Looks like https://hjson.github.io/ has the details.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1274/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 843884745, "node_id": "MDU6SXNzdWU4NDM4ODQ3NDU=", "number": 1283, "title": "advanced #export causes unexpected scrolling", "user": {"value": 192568, "label": "mroswell"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-03-29T22:46:57Z", "updated_at": "2021-03-29T22:46:57Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "1. Visit a datasette table page\r\n2. Click on the \"(advanced)\" link. This adds a fragment identifier \"#export\" to the URL, and scrolls down to the \"Advanced export\" div with the \"export\" id.\r\n3. Manually scroll back up, and click on a suggested facet. The fragment identifier is still present, and the app scrolls back down to the \"Advanced export\" div. I think this is unwanted behavior.\r\n\r\nThe user remedy seems to be to manually remove the \"#export\" from the URL.\r\n\r\nThis behavior happens in my project, and in:\r\nhttps://covid-19.datasettes.com/covid/economist_excess_deaths (for instance) \r\nbut not in this table: \r\nhttps://global-power-plants.datasettes.com/global-power-plants/global-power-plants", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1283/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 845794436, "node_id": "MDU6SXNzdWU4NDU3OTQ0MzY=", "number": 1284, "title": "Feature or Documentation Request: Individual table as home page template", "user": {"value": 192568, "label": "mroswell"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2021-03-31T03:56:17Z", "updated_at": "2021-11-04T03:15:01Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "It would be great to have a sample showing how to move a single database that has a single table, to the index page. I'm trying it now, and find there is a real depth of Datasette and Python understanding that's required to be successful. \r\n\r\nI've got all the basic jinja concepts down... variables, template control structures, template inheritance, template overrides, css, html, the --template-dir and --static arguments, etc. \r\n\r\nBut copying the table.html file to index.html doesn't work. There are undocumented functions and filters... I can figure some of them out (yay, url_builder.py and utils/__init__.py!) but it's a slog better handled by a much stronger Python developer. \r\n\r\nOne sample would make a world of difference. The ideal form of this documentation would be a diff between the default table.html and how that would look if essentially moved to index.html. The use case is for everyone who wants to create a public-facing website to explore a single table at the root directory. (Maybe a second bit of documentation for people who have a single database with multiple tables.)\r\n\r\n(Hmm... might be cool to have a setting for that, where it happens automagically! If only one table, then home page is at the table level. if only one database, then home page is at the database level.... as an option.)\r\n\r\nI suppose I could ignore this, and somehow do this in the DNS settings once I hook up Vercel to a domain name, maybe.. and remove the breadcrumbs in table.html... but for now, a documentation request in the form of a diff... for viewing a single table (or a single database) at the root.\r\n\r\n(Actually, there's probably room for a whole expanded section on templates. Noticed some nice table metadata in one of the datasette examples, for instance... Hmm... maybe a whole library of solutions in one place... maybe a documentation hackathon! If that's of interest, of course it's a separate issue. )\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1284/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 847700726, "node_id": "MDU6SXNzdWU4NDc3MDA3MjY=", "number": 1285, "title": "Feature Request or Plugin Request: Numeric Range Facets", "user": {"value": 192568, "label": "mroswell"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-04-01T01:50:20Z", "updated_at": "2021-04-01T02:28:19Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "It would be great to offer facets for numeric data ranges. \r\n\r\nThe ranges could pull from typical GIS methods of creating choropleth maps. \r\nhttps://gisgeography.com/choropleth-maps-data-classification/\r\nOf the following, for mapping, I've always preferred a Jenks Natural Breaks, or a cross between Jenks and Pretty breaks.\r\n\r\n- Equal Intervals \r\n- Quantile (equal count) \r\n- Standard Deviation\r\n- Natural Breaks (Jenks) Classification \r\n- Pretty Breaks\r\n- Some sort of Aggregate Jenks Classification (this isn't standard, but it would be nice to be able to set classification ranges that work across tables.)\r\n\r\nHere are some links for Natural Breaks, in case this method is unfamiliar.\r\n\r\n- https://en.wikipedia.org/wiki/Jenks_natural_breaks_optimization\r\n- http://wiki.gis.com/wiki/index.php/Jenks_Natural_Breaks_Classification\r\n- https://medium.com/analytics-vidhya/jenks-natural-breaks-best-range-finder-algorithm-8d1907192051\r\n\r\nPer that last link, there is a Jenks Python module... They also describe it as data-intensive for larger datasets. Maybe this is a good plugin idea.\r\n\r\nAn example of equal Intervals would be \r\n0 \u2013 < 10\r\n10 \u2013 < 20\r\n20 \u2013 < 30\r\n30 \u2013 < 40\r\n\r\nIt's kind of confusing to have that less-than sign in there. it could also be displayed as:\r\n0 \u2013 10\r\n10 \u2013 20\r\n20 \u2013 30\r\n30 \u2013 40\r\n\r\nBut then it's not completely clear which category 10 is in, for instance.\r\n\r\n(Best to right-justify.. and use an \"en dash\" between numbers.)\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1285/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 849220154, "node_id": "MDU6SXNzdWU4NDkyMjAxNTQ=", "number": 1286, "title": "Better default display of arrays of items", "user": {"value": 192568, "label": "mroswell"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 5, "created_at": "2021-04-02T13:31:40Z", "updated_at": "2021-06-12T12:36:15Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Would be great to have template filters that convert array fields to bullets and/or delimited lists upon table display:\r\n```\r\n|to_bullets\r\n|to_comma_delimited\r\n|to_semicolon_delimited\r\n```\r\nor maybe: \r\n```\r\n|join_array(\"bullet\")\r\n|join_array(\"bullet\",\"square\")\r\n|join_array(\";\")\r\n|join_array(\",\")\r\n```\r\nKeeping in mind that bullets show up in html as \\<li\\> while other delimiting characters appear after the value.\r\n\r\nOf course, the fields themselves would remain as facetable arrays. ", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1286/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 853672224, "node_id": "MDU6SXNzdWU4NTM2NzIyMjQ=", "number": 1294, "title": "\"You can check out any time you like. But you can never leave!\"", "user": {"value": 192568, "label": "mroswell"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-04-08T17:02:15Z", "updated_at": "2021-04-08T18:35:50Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "(Feel free to rename this one.)\r\n\r\n- The column gear lets you \"Show not-blank rows.\" Then it places a parameter in the URL, which a web developer would notice, but a lot of users won't notice, or know to delete it. Would be good to toggle \"Show not-blank rows\" with \"Show all rows.\" (Also would be quite helpful to have a \"Show blank rows | Show all rows\" option)\r\n- The column gear lets you \"Sort ascending\" and \"Sort descending\" but then you're stuck with some sort of sorted version thereafter, unless you know to sort the ID column, or to remove the full _sort parameter and its value in the URL. Would be good to offer a \"Remove sort\" option in the gear.\r\n- These requests are in the same camp as: https://github.com/simonw/datasette-vega/issues/36\r\n- I suspect there are other url parameter instances where similar analysis would be helpful, but the three above are the use cases I've run across. \r\n\r\nUPDATE:\r\n- It would be helpful to have a \"Previous page\" available for all but the first table page.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1294/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 855451460, "node_id": "MDU6SXNzdWU4NTU0NTE0NjA=", "number": 1297, "title": "Documentation: json1, and introspection endpoints", "user": {"value": 192568, "label": "mroswell"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-04-12T00:38:00Z", "updated_at": "2021-04-12T01:29:33Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "https://docs.datasette.io/en/stable/facets.html notes that:\r\n> If your SQLite installation provides the json1 extension (you can check using /-/versions) Datasette will automatically detect columns that contain JSON arrays...\r\n\r\nWhen I check -/versions I see two sections relevant to json1:\r\n```\r\n \"extensions\": {\r\n \"json1\": null\r\n },\r\n \"compile_options\": [\r\n ...\r\n \"ENABLE_JSON1\",\r\n```\r\n \r\n The ENABLE_JSON1 makes me think json1 is likely available. But the `\"json1\": null` made me think it wasn't available (because of the `null`). It would help if the documentation provided clarity about how to know if json1 is installed. It would also be helpful if the `/-/versions` information signalled somehow that that is to be appended to the hostname or domain name (or whatever you want to call it, or simply show it, using `example.com/-/versions` instead of `/-/versions`. Likewise on that last point, for https://docs.datasette.io/en/stable/introspection.html#introspection , at least at some point on that page detailing where those introspection endpoints go. (Sometimes documentation can be so abbreviated that it's hard for new users to figure out what's going on.)\r\n ", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1297/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 855476501, "node_id": "MDU6SXNzdWU4NTU0NzY1MDE=", "number": 1298, "title": "improve table horizontal scroll experience", "user": {"value": 192568, "label": "mroswell"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2021-04-12T01:55:16Z", "updated_at": "2022-08-30T21:11:49Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Wide tables aren't a huge problem if you know to click and drag right. But it's not at all obvious to do that. (it also tends to blue-select any content as it's dragging.) Depending on column widths, public users might entirely miss all the columns to the right. \r\n\r\nThere is a scrollbar at the bottom of the table, but I'm displaying ALL my records because it's the only way for datasette-vega to make accurate charts. So that bottom scrollbar is likely to be missed. I wonder if some sort of javascript-y mouseover to an arrow might help, similar to those seen in image carousels. Ah: here's a perfect example:\r\n\r\n1. Visit http://google.com\r\n2. Search for: animals endangered\r\n3. Note the 'g-right-button' (in the code) that looks like a right-facing caret in a circle. \r\n4. Click on that and the carousel scrolls right (and 'g-left-button' appears on the left).\r\n\r\nMight be tricky to do that on a table, rather than a one-row carousel, but it's worth experimenting with.\r\n\r\nAnother option is just to put the scrollbars at the top of the table, too. \r\n\r\nMeantime, I'm trying to build a button like the \"View/hide all columns on https://salaries.news.baltimoresun.com/salaries-be494cf/2019+Maryland+state+salaries\r\nMight be nice to have that available by default, with settings in the metadata showing which are on by default.\r\n\r\n(I saw some other closed issues related to horizontal scrolling, and admit I don't entirely understand them. For instance, the animated gif at https://github.com/simonw/datasette/issues/998#issuecomment-714117534 confuses me. )\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1298/reactions\", \"total_count\": 4, \"+1\": 4, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 860625833, "node_id": "MDU6SXNzdWU4NjA2MjU4MzM=", "number": 1300, "title": "Make row available to `render_cell` plugin hook", "user": {"value": 3243482, "label": "abdusco"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 5, "created_at": "2021-04-18T10:14:37Z", "updated_at": "2022-07-07T16:34:05Z", "closed_at": "2022-07-07T16:31:22Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "*Original title: **Generating URL for a row inside `render_cell` hook***\r\n\r\nHey,\r\nI am using Datasette to view a database that contains video metadata. It has BLOB columns that contain video thumbnails in JPG format (around 100-500KB per row). \r\n\r\nI've registered an output formatter that extends `datasette.blob_renderer.render_blob` function and serves the column with `image/jpeg` content type.\r\n\r\n```python\r\nfrom datasette.blob_renderer import render_blob\r\n\r\nasync def render_jpg(datasette, database, rows, columns, request, table, view_name):\r\n response = await render_blob(datasette, database, rows, columns, request, table, view_name)\r\n response.content_type = \"image/jpeg\"\r\n response.headers[\"Content-Disposition\"] = f'inline; filename=\"image.jpg\"'\r\n return response\r\n\r\n\r\n@hookimpl\r\ndef register_output_renderer():\r\n return {\r\n \"extension\": \"jpg\",\r\n \"render\": render_jpg,\r\n \"can_render\": lambda: True,\r\n }\r\n```\r\n\r\nThis works well. I can visit `http://localhost:8001/mydb/videos/1.jpg?_blob_column=thumbnail` and view the image.\r\n\r\nI want to display the image directly with an `<img>` tag (lazy-loaded of course). So, I need a URL, because embedding base64 would increase the page size too much (each image > 100KB). \r\n\r\nDatasette generates a link with `.blob` extension for blob columns. It does this by calling `datasette.urls.row_blob`\r\n\r\nhttps://github.com/simonw/datasette/blob/7a2ed9f8a119e220b66d67c7b9e07cbab47b1196/datasette/views/table.py#L169-L179\r\n\r\nBut I have no way of getting the row inside the `render_cell` hook. \r\n\r\n```python\r\n@hookimpl\r\ndef render_cell(value, column, table, database, datasette):\r\n if isinstance(value, bytes) and imghdr.what(None, value):\r\n # generate url\r\n return '$renderedLink'\r\n```\r\n\r\nAny pointers?", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1300/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 860722711, "node_id": "MDU6SXNzdWU4NjA3MjI3MTE=", "number": 1301, "title": "Publishing to cloudrun with immutable mode?", "user": {"value": 5413548, "label": "louispotok"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2021-04-18T17:51:46Z", "updated_at": "2022-10-07T02:38:04Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I'm a bit confused about immutable mode and publishing to cloudrun. (I want to publish with immutable mode so that I can support database downloads.)\r\n\r\nRunning `datasette publish cloudrun --extra-options=\"-i example.db\"` leads to an error:\r\n> Error: Invalid value for '-i' / '--immutable': Path 'example.db' does not exist. \r\n\r\nHowever, running `datasette publish cloudrun example.db` not only works but seems to publish in immutable mode anyway! I'm seeing this both with `/-/databases.json` and the fact that downloads are working.\r\n\r\nWhen I just `datasette serve` locally, this succeeds both ways and works as expected.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1301/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 860734722, "node_id": "MDU6SXNzdWU4NjA3MzQ3MjI=", "number": 1302, "title": "Fix disappearing facets", "user": {"value": 192568, "label": "mroswell"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-04-18T18:42:33Z", "updated_at": "2021-04-20T07:40:15Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "1. Clone https://github.com/mroswell/list-N\r\n2. Run `datasette disinfectants.db -o`\r\n3. Select the `Safer_or_Toxic` facet.\r\n4. Select `Toxic`.\r\n5. Close out the `Safer_or_Toxic` facet.\r\n6. Examine `Suggested facets` list. `Safer_or_Toxic` is GONE.\r\n7. Try some other facets. When you select an element, and then close the list, in some cases, the facet properly returns to the `Suggested facet` list... Arrays and dates properly return to the list, but fields with strings don't return to the list. \r\n\r\nSince my site is devoted to whether disinfectants are Safer or Toxic, having the suggested facet disappear from the suggested facet list is very confusing* to end-users. This, along with a few other issues, unfortunately proved beyond my own programming ability to address. So I hired a Senior-level developer to address a number of issues, including this disappearing act.\r\n\r\n8. Open a new terminal. Run `datasette disinfectants.db -m metadata.json --static static:static/ --template-dir templates/ --plugins-dir plugins/ -p 8001 -o`\r\n9. Repeat steps 3-6, but this time, the Safer_or_Toxic facet returns to the list (and the related URL parameters are removed).\r\n\r\nI'm not sure how to do a pull request for this, because the plugin contains other functionality that goes beyond this bug. I wanted the facets sorted in a certain order (both in the suggested facet list, and the detail lists) (... the detail lists were hopping around all over the place before...) I wanted the duplicate facets removed (leaving only the one where you can facet by individual item in an array.) I wanted the arrays to be presented in a prettier fashion (I did that in the template... That could be moved over to the plugin at some point)\r\n\r\nI'm thinking it'll be very helpful if applicable parts of my project's plugin (sort_suggested_facets_plugin.py) will be able to be incorporated back into datasette, but I leave that to you to consider.\r\n\r\n(* The disappearing facet bug was especially confusing because I'm removing the filters and sql from the table page, at the request of the organization. The filters and sql detail created a lot of confusion for end users who try to find disinfectants used by Hospitals, for instance, as an '=' won't find them, since they are part of the Use_site array.) My disappearing-facet confusion was documented in my own issue: https://github.com/mroswell/list-N/issues/57 (addressed by the plugin). Other facet-related issues here: https://github.com/mroswell/list-N/issues/54 (addressed by the plugin); https://github.com/mroswell/list-N/issues/15 (addressed by template); https://github.com/mroswell/list-N/issues/53 (not yet addressed). \r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1302/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 864969683, "node_id": "MDU6SXNzdWU4NjQ5Njk2ODM=", "number": 1305, "title": "Index view crashes when any database table is not accessible to actor", "user": {"value": 416374, "label": "gfrmin"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-04-22T13:44:22Z", "updated_at": "2021-06-02T04:26:29Z", "closed_at": "2021-06-02T04:26:29Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Because of https://github.com/simonw/datasette/blob/main/datasette/views/index.py#L63, the ```tables``` dict built does not include invisible tables; however, if https://github.com/simonw/datasette/blob/main/datasette/views/index.py#L80 is reached (because table_counts was not successfully initialized, e.g. due to a very large database) then as db.get_all_foreign_keys() returns ALL tables, a KeyError will be raised.\r\n\r\nThis error can be recreated with the fixtures.db if any table is hidden, e.g. by adding something like ```\"foreign_key_references\": {\r\n \"allow\": {}\r\n }``` to fixtures-metadata.json and deleting ```or not table_counts``` from https://github.com/simonw/datasette/blob/main/datasette/views/index.py#L77.\r\n\r\nI'm not sure how to fix this error; perhaps by testing if the table is in the aforementions ```tables``` dict.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1305/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 868188068, "node_id": "MDU6SXNzdWU4NjgxODgwNjg=", "number": 257, "title": "Insert from JSON containing strings with non-ascii characters are escaped as unicode for lists, tuples, dicts.", "user": {"value": 6586811, "label": "dylan-wu"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-04-26T20:46:25Z", "updated_at": "2021-05-19T02:57:05Z", "closed_at": "2021-05-19T02:57:05Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "JSON Test File (test.json):\r\n\r\n```json\r\n[\r\n {\r\n \"id\": 123,\r\n \"text\": \"FR Th\u00e9\u00e2tre\"\r\n },\r\n {\r\n \"id\": 223,\r\n \"text\": [\r\n \"FR Th\u00e9\u00e2tre\"\r\n ]\r\n }\r\n]\r\n```\r\n\r\nCommand to import:\r\n\r\n```bash\r\nsqlite-utils insert test.db text test.json --pk=id\r\n```\r\n\r\nResulting table view from datasette:\r\n\r\n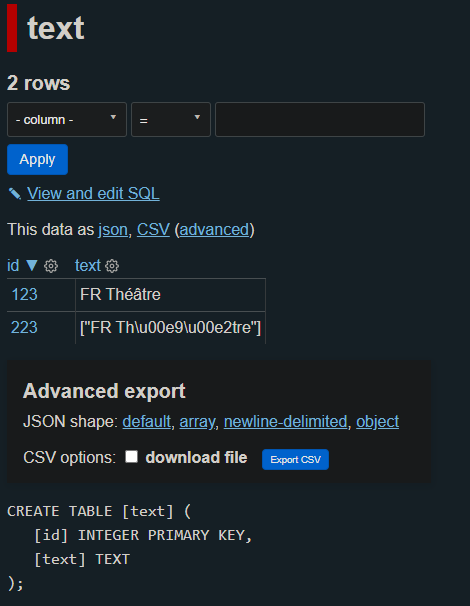\r\n\r\nOriginal, db.py line 2225:\r\n\r\n```python\r\n return json.dumps(value, default=repr)\r\n```\r\n\r\nFix, db.py line 2225:\r\n\r\n```python\r\n return json.dumps(value, default=repr, ensure_ascii=False)\r\n```", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/257/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 884952179, "node_id": "MDU6SXNzdWU4ODQ5NTIxNzk=", "number": 1320, "title": "Can't use apt-get in Dockerfile when using datasetteproj/datasette as base", "user": {"value": 2670795, "label": "brandonrobertz"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2021-05-10T19:37:27Z", "updated_at": "2021-05-24T18:15:56Z", "closed_at": "2021-05-24T18:07:08Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "The datasette base Docker image is super convenient, but there's one problem: if any of the plugins you install require additional system dependencies (e.g., xz, git, curl) then any attempt to use apt in said Dockerfile results in an explosion:\r\n\r\n```\r\n$ docker-compose build\r\nBuilding server\r\n[+] Building 9.9s (7/9)\r\n => [internal] load build definition from Dockerfile 0.0s\r\n => => transferring dockerfile: 666B 0.0s\r\n => [internal] load .dockerignore 0.0s\r\n => => transferring context: 34B 0.0s\r\n => [internal] load metadata for docker.io/datasetteproject/datasette:latest 0.6s\r\n => [base 1/4] FROM docker.io/datasetteproject/datasette@sha256:2250d0fbe57b1d615a8d6df0c9d43deb9533532e00bac68854773d8ff8dcf00a 0.0s\r\n => [internal] load build context 1.8s\r\n => => transferring context: 2.44MB 1.8s\r\n => CACHED [base 2/4] WORKDIR /datasette 0.0s\r\n => ERROR [base 3/4] RUN apt-get update && apt-get install --no-install-recommends -y git ssh curl xz-utils 9.2s\r\n------\r\n > [base 3/4] RUN apt-get update && apt-get install --no-install-recommends -y git ssh curl xz-utils:\r\n#6 0.446 Get:1 http://security.debian.org/debian-security buster/updates InRelease [65.4 kB]\r\n#6 0.449 Get:2 http://deb.debian.org/debian buster InRelease [121 kB]\r\n#6 0.459 Get:3 http://httpredir.debian.org/debian sid InRelease [157 kB]\r\n#6 0.784 Get:4 http://deb.debian.org/debian buster-updates InRelease [51.9 kB]\r\n#6 0.790 Get:5 http://httpredir.debian.org/debian sid/main amd64 Packages [8626 kB]\r\n#6 1.003 Get:6 http://deb.debian.org/debian buster/main amd64 Packages [7907 kB]\r\n#6 1.180 Get:7 http://security.debian.org/debian-security buster/updates/main amd64 Packages [286 kB]\r\n#6 7.095 Get:8 http://deb.debian.org/debian buster-updates/main amd64 Packages [10.9 kB]\r\n#6 8.058 Fetched 17.2 MB in 8s (2243 kB/s)\r\n#6 8.058 Reading package lists...\r\n#6 9.166 E: flAbsPath on /var/lib/dpkg/status failed - realpath (2: No such file or directory)\r\n#6 9.166 E: Could not open file - open (2: No such file or directory)\r\n#6 9.166 E: Problem opening\r\n#6 9.166 E: The package lists or status file could not be parsed or opened.\r\n```\r\n\r\nThe problem seems to be from completely wiping out `/var/lib/dpkg` in the upstream Dockerfile:\r\n\r\nhttps://github.com/simonw/datasette/blob/1b697539f5b53cec3fe13c0f4ada13ba655c88c7/Dockerfile#L18\r\n\r\nI've tested without removing the directory and apt works as expected.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1320/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 893890496, "node_id": "MDU6SXNzdWU4OTM4OTA0OTY=", "number": 1332, "title": "?_facet_size=X to increase number of facets results on the page", "user": {"value": 192568, "label": "mroswell"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 5, "created_at": "2021-05-18T02:40:16Z", "updated_at": "2021-05-27T16:13:07Z", "closed_at": "2021-05-23T00:34:37Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Is there a way to add a parameter to the URL to modify default_facet_size?\r\n\r\nLIkewise, a way to produce a link on the three dots to expand to all items (or match previous number of items, or add x more)?\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1332/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 907642546, "node_id": "MDU6SXNzdWU5MDc2NDI1NDY=", "number": 264, "title": "Supporting additional output formats, like GeoJSON", "user": {"value": 25778, "label": "eyeseast"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2021-05-31T18:03:32Z", "updated_at": "2021-06-03T05:12:21Z", "closed_at": "2021-06-03T05:12:21Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I have a project going where it would be useful to do some spatial processing in SQLite (instead of large files) and then output GeoJSON. So my workflow would be something like this:\r\n\r\n1. Read Shapefiles, GeoJSON, CSVs into a SQLite database\r\n2. Join, filter, prune as needed\r\n3. Export GeoJSON for just the stuff I need at that moment, while still having a database of things that will be useful later\r\n\r\nI'm wondering if this is worth adding to SQLite-utils itself (GeoJSON, at least), or if it's better to make a counterpart to the ecosystem of `*-to-sqlite` tools, say a suite of `sqlite-to-*` things. Or would it be crazy to have a plugin system?", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/264/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 907645813, "node_id": "MDU6SXNzdWU5MDc2NDU4MTM=", "number": 57, "title": "Error: Use either --since or --since_id, not both", "user": {"value": 42904, "label": "rubenv"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 6, "created_at": "2021-05-31T18:11:04Z", "updated_at": "2021-08-20T00:01:31Z", "closed_at": "2021-08-20T00:01:31Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I'm using the following command:\r\n\r\n```\r\ntwitter-to-sqlite user-timeline -a twitter-auth.json twitter/tweets.db --since\r\n```\r\n\r\nWhich gives the following error:\r\n```\r\nError: Use either --since or --since_id, not both\r\n```\r\n\r\nRunning without `--since`.\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/twitter-to-sqlite\", line 8, in <module>\r\n sys.exit(cli())\r\n File \"/usr/local/lib/python3.9/site-packages/click/core.py\", line 1137, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/click/core.py\", line 1062, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.9/site-packages/click/core.py\", line 1668, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/usr/local/lib/python3.9/site-packages/click/core.py\", line 1404, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/usr/local/lib/python3.9/site-packages/click/core.py\", line 763, in invoke\r\n return __callback(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/twitter_to_sqlite/cli.py\", line 317, in user_timeline\r\n for tweet in bar:\r\n File \"/usr/local/lib/python3.9/site-packages/click/_termui_impl.py\", line 328, in generator\r\n for rv in self.iter:\r\n File \"/usr/local/lib/python3.9/site-packages/twitter_to_sqlite/utils.py\", line 234, in fetch_user_timeline\r\n yield from fetch_timeline(\r\n File \"/usr/local/lib/python3.9/site-packages/twitter_to_sqlite/utils.py\", line 202, in fetch_timeline\r\n raise Exception(str(tweets[\"errors\"]))\r\nException: [{'code': 44, 'message': 'since_id parameter is invalid.'}]\r\n```\r\n\r\n```\r\nPython 3.9.5\r\ntwitter-to-sqlite, version 0.21.3\r\n```", "repo": {"value": 206156866, "label": "twitter-to-sqlite"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/57/reactions\", \"total_count\": 4, \"+1\": 4, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 913017577, "node_id": "MDU6SXNzdWU5MTMwMTc1Nzc=", "number": 1365, "title": "pathlib.Path breaks internal schema", "user": {"value": 25778, "label": "eyeseast"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2021-06-07T01:40:37Z", "updated_at": "2021-06-21T15:57:39Z", "closed_at": "2021-06-21T15:57:39Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Ran into an issue while trying to build a plugin to render GeoJSON. I'm using pytest's `tmp_path` fixture, which is a `pathlib.Path`, to get a temporary database path. I was getting a weird error involving writes, but I was doing reads. Turns out it's the internal database trying to insert a `Path` where it wants a string.\r\n\r\nMy test looked like this:\r\n\r\n```python\r\n@pytest.mark.asyncio\r\nasync def test_render_feature_collection(tmp_path):\r\n database = tmp_path / \"test.db\"\r\n datasette = Datasette([database])\r\n\r\n # this will break with a path\r\n await datasette.refresh_schemas()\r\n\r\n # build a url\r\n url = datasette.urls.table(database.stem, TABLE_NAME, format=\"geojson\")\r\n\r\n response = await datasette.client.get(url)\r\n fc = response.json()\r\n\r\n assert 200 == response.status_code\r\n```\r\n\r\nI only ran into this while running tests, because passing in database paths from the CLI uses strings, but it's a weird error and probably something other people have run into.\r\n\r\nThe fix is easy enough: Convert the path to a string and everything works. So this:\r\n\r\n```python\r\n@pytest.mark.asyncio\r\nasync def test_render_feature_collection(tmp_path):\r\n database = tmp_path / \"test.db\"\r\n datasette = Datasette([str(database)])\r\n\r\n # this is fine now\r\n await datasette.refresh_schemas()\r\n```\r\n\r\nThis could (probably, haven't tested) be fixed [here](https://github.com/simonw/datasette/blob/03ec71193b9545536898a4bc7493274fec48bdd7/datasette/app.py#L357) by calling `str(db.path)` or by doing that conversion earlier.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1365/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 923602693, "node_id": "MDU6SXNzdWU5MjM2MDI2OTM=", "number": 276, "title": "support small help flag -h", "user": {"value": 601708, "label": "mcint"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-06-17T07:59:31Z", "updated_at": "2021-06-18T14:56:59Z", "closed_at": "2021-06-18T14:56:59Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/276/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 923697888, "node_id": "MDU6SXNzdWU5MjM2OTc4ODg=", "number": 278, "title": "Support db as first parameter before subcommand, or as environment variable", "user": {"value": 601708, "label": "mcint"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2021-06-17T09:26:29Z", "updated_at": "2021-06-20T22:39:57Z", "closed_at": "2021-06-18T15:43:19Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/278/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 939051549, "node_id": "MDU6SXNzdWU5MzkwNTE1NDk=", "number": 1388, "title": "Serve using UNIX domain socket", "user": {"value": 80737, "label": "aslakr"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 13, "created_at": "2021-07-07T16:13:37Z", "updated_at": "2021-07-11T01:18:38Z", "closed_at": "2021-07-10T23:38:32Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Would it be possible to make datasette serve using UNIX domain socket similar to Uvicorn's ``--uds``?", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1388/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 950664971, "node_id": "MDU6SXNzdWU5NTA2NjQ5NzE=", "number": 1401, "title": "unordered list is not rendering bullet points in description_html on database page", "user": {"value": 536941, "label": "fgregg"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2021-07-22T13:24:18Z", "updated_at": "2021-10-23T13:09:10Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Thanks for this tremendous package, @simonw!\r\n\r\nIn the `description_html` for a database, I [have an unordered list](https://github.com/labordata/warehouse/blob/fcea4502e5b615b0eb3e0bdcb45ec634abe20bb6/warehouse_metadata.yml#L19-L22).\r\n\r\nHowever, on the database page on the deployed site, it is not rendering this as a bulleted list.\r\n\r\n\r\n\r\nPage here: https://labordata-warehouse.herokuapp.com/nlrb-9da4ae5\r\n\r\nThe documentation gives an [example of using an unordered list](https://docs.datasette.io/en/stable/metadata.html#using-yaml-for-metadata) in a `description_html`, so I expected this will work.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1401/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 951185411, "node_id": "MDU6SXNzdWU5NTExODU0MTE=", "number": 1402, "title": "feature request: social meta tags", "user": {"value": 536941, "label": "fgregg"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2021-07-23T01:57:23Z", "updated_at": "2021-07-26T19:31:41Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "it would be very nice if the twitter, slack, and other social media could make rich cards when people post a link to a datasette instance\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1402/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 959137143, "node_id": "MDU6SXNzdWU5NTkxMzcxNDM=", "number": 1415, "title": "feature request: document minimum permissions for service account for cloudrun", "user": {"value": 536941, "label": "fgregg"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 4, "created_at": "2021-08-03T13:48:43Z", "updated_at": "2023-11-05T16:46:59Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Thanks again for such a powerful project.\r\n\r\nFor deploying to cloudrun from github actions, I'd like to create a service account with minimal permissions.\r\n\r\nIt would be great to document what those minimum permission that need to be set in the IAM.\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1415/reactions\", \"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 959710008, "node_id": "MDU6SXNzdWU5NTk3MTAwMDg=", "number": 1419, "title": "`publish cloudrun` should deploy a more recent SQLite version", "user": {"value": 536941, "label": "fgregg"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2021-08-04T00:45:55Z", "updated_at": "2021-08-05T03:23:24Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I recently changed from deploying a datasette using `datasette publish heroku` to `datasette publish cloudrun`. [A query that ran on the heroku site](https://odpr.bunkum.us/odpr-6c2f4fc?sql=with+pivot_members+as+%28%0D%0A++select%0D%0A++++f_num%2C%0D%0A++++max%28union_name%29+as+union_name%2C%0D%0A++++max%28aff_abbr%29+as+abbreviation%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2007%0D%0A++++%29+as+%222007%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2008%0D%0A++++%29+as+%222008%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2009%0D%0A++++%29+as+%222009%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2010%0D%0A++++%29+as+%222010%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2011%0D%0A++++%29+as+%222011%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2012%0D%0A++++%29+as+%222012%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2013%0D%0A++++%29+as+%222013%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2014%0D%0A++++%29+as+%222014%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2015%0D%0A++++%29+as+%222015%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2016%0D%0A++++%29+as+%222016%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2017%0D%0A++++%29+as+%222017%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2018%0D%0A++++%29+as+%222018%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2019%0D%0A++++%29+as+%222019%22%0D%0A++from%0D%0A++++lm_data%0D%0A++++left+join+ar_membership+using+%28rpt_id%29%0D%0A++where%0D%0A++++members+%21%3D+%27%27%0D%0A++++and+trim%28desig_name%29+%3D+%27NHQ%27%0D%0A++++and+union_name+not+in+%28%0D%0A++++++%27AFL-CIO%27%2C%0D%0A++++++%27CHANGE+TO+WIN%27%2C%0D%0A++++++%27FOOD+ALLIED+SVC+TRADES+DEPT+AFL-CIO%27%0D%0A++++%29%0D%0A++++and+f_num+not+in+%28387%2C+296%2C+123%2C+347%2C+531897%2C+30410%2C+49%29%0D%0A++++and+lower%28ar_membership.category%29+IN+%28%0D%0A++++++%27active+members%27%2C%0D%0A++++++%27active+professional%27%2C%0D%0A++++++%27regular+members%27%2C%0D%0A++++++%27full+time+member%27%2C%0D%0A++++++%27full+time+members%27%2C%0D%0A++++++%27active+education+support+professional%27%2C%0D%0A++++++%27active%27%2C%0D%0A++++++%27active+member%27%2C%0D%0A++++++%27members%27%2C%0D%0A++++++%27see+item+69%27%2C%0D%0A++++++%27regular%27%2C%0D%0A++++++%27dues+paying+members%27%2C%0D%0A++++++%27building+trades+journeyman%27%2C%0D%0A++++++%27full+per+capita+tax+payers%27%2C%0D%0A++++++%27active+postal%27%2C%0D%0A++++++%27active+membership%27%2C%0D%0A++++++%27full-time+member%27%2C%0D%0A++++++%27regular+active+member%27%2C%0D%0A++++++%27journeyman%27%2C%0D%0A++++++%27member%27%2C%0D%0A++++++%27journeymen%27%2C%0D%0A++++++%27one+half+per+capita+tax+payers%27%2C%0D%0A++++++%27schedule+1%27%2C%0D%0A++++++%27active+memebers%27%2C%0D%0A++++++%27active+members+-+us%27%2C%0D%0A++++++%27dues+paying+membership%27%0D%0A++++%29%0D%0A++GROUP+by%0D%0A++++f_num%0D%0A%29%0D%0Aselect%0D%0A++*%0D%0Afrom%0D%0A++pivot_members%0D%0Aorder+by%0D%0A++%222019%22+desc%3B), now throws a syntax error on the [cloudrun site](https://labordata.bunkum.us/odpr-6c2f4fc?sql=with+pivot_members+as+%28%0D%0A++select%0D%0A++++f_num%2C%0D%0A++++max%28union_name%29+as+union_name%2C%0D%0A++++max%28aff_abbr%29+as+abbreviation%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2007%0D%0A++++%29+as+%222007%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2008%0D%0A++++%29+as+%222008%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2009%0D%0A++++%29+as+%222009%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2010%0D%0A++++%29+as+%222010%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2011%0D%0A++++%29+as+%222011%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2012%0D%0A++++%29+as+%222012%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2013%0D%0A++++%29+as+%222013%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2014%0D%0A++++%29+as+%222014%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2015%0D%0A++++%29+as+%222015%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2016%0D%0A++++%29+as+%222016%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2017%0D%0A++++%29+as+%222017%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2018%0D%0A++++%29+as+%222018%22%2C%0D%0A++++sum%28number%29+filter+%28%0D%0A++++++where%0D%0A++++++++yr_covered+%3D+2019%0D%0A++++%29+as+%222019%22%0D%0A++from%0D%0A++++lm_data%0D%0A++++left+join+ar_membership+using+%28rpt_id%29%0D%0A++where%0D%0A++++members+%21%3D+%27%27%0D%0A++++and+trim%28desig_name%29+%3D+%27NHQ%27%0D%0A++++and+union_name+not+in+%28%0D%0A++++++%27AFL-CIO%27%2C%0D%0A++++++%27CHANGE+TO+WIN%27%2C%0D%0A++++++%27FOOD+ALLIED+SVC+TRADES+DEPT+AFL-CIO%27%0D%0A++++%29%0D%0A++++and+f_num+not+in+%28387%2C+296%2C+123%2C+347%2C+531897%2C+30410%2C+49%29%0D%0A++++and+lower%28ar_membership.category%29+IN+%28%0D%0A++++++%27active+members%27%2C%0D%0A++++++%27active+professional%27%2C%0D%0A++++++%27regular+members%27%2C%0D%0A++++++%27full+time+member%27%2C%0D%0A++++++%27full+time+members%27%2C%0D%0A++++++%27active+education+support+professional%27%2C%0D%0A++++++%27active%27%2C%0D%0A++++++%27active+member%27%2C%0D%0A++++++%27members%27%2C%0D%0A++++++%27see+item+69%27%2C%0D%0A++++++%27regular%27%2C%0D%0A++++++%27dues+paying+members%27%2C%0D%0A++++++%27building+trades+journeyman%27%2C%0D%0A++++++%27full+per+capita+tax+payers%27%2C%0D%0A++++++%27active+postal%27%2C%0D%0A++++++%27active+membership%27%2C%0D%0A++++++%27full-time+member%27%2C%0D%0A++++++%27regular+active+member%27%2C%0D%0A++++++%27journeyman%27%2C%0D%0A++++++%27member%27%2C%0D%0A++++++%27journeymen%27%2C%0D%0A++++++%27one+half+per+capita+tax+payers%27%2C%0D%0A++++++%27schedule+1%27%2C%0D%0A++++++%27active+memebers%27%2C%0D%0A++++++%27active+members+-+us%27%2C%0D%0A++++++%27dues+paying+membership%27%0D%0A++++%29%0D%0A++GROUP+by%0D%0A++++f_num%0D%0A%29%0D%0Aselect%0D%0A++*%0D%0Afrom%0D%0A++pivot_members%0D%0Aorder+by%0D%0A++%222019%22+desc%3B).\r\n\r\nI suspect this is because they are running different versions of sqlite3.\r\n\r\n- Heroku: sqlite3 3.31.1 ([-/versions](https://odpr.bunkum.us/-/versions))\r\n- Cloudrun: sqlite3 3.27.2 ([-/versions](https://labordata.bunkum.us/-/versions))\r\n\r\nIf so, it would be great to\r\n\r\n1. harmonize the sqlite3 versions across platforms\r\n2. update the docker files so as to update the sqlite3 version for cloudrun", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1419/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 984939366, "node_id": "MDU6SXNzdWU5ODQ5MzkzNjY=", "number": 58, "title": "Error: Use either --since or --since_id, not both - still broken", "user": {"value": 42904, "label": "rubenv"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2021-09-01T09:45:28Z", "updated_at": "2021-09-21T17:37:41Z", "closed_at": "2021-09-21T17:37:41Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Hi Simon,\r\n\r\nIt appears the fix for #57 doesn't fix things for me:\r\n\r\n```\r\n$ twitter-to-sqlite --version\r\ntwitter-to-sqlite, version 0.21.4\r\n$ python --version\r\nPython 3.9.6\r\n```\r\n\r\n```\r\n$ twitter-to-sqlite home-timeline -a twitter-auth.json twitter/timeline.db --since\r\nImporting tweets\r\nError: Use either --since or --since_id, not both\r\n```\r\n\r\nIs there any way I can help debug this?", "repo": {"value": 206156866, "label": "twitter-to-sqlite"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/58/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 988552851, "node_id": "MDU6SXNzdWU5ODg1NTI4NTE=", "number": 1456, "title": "conda install results in non-functioning `datasette serve` due to out-of-date asgiref", "user": {"value": 51016, "label": "ctb"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-09-05T16:59:55Z", "updated_at": "2021-09-05T16:59:55Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Over in https://github.com/ctb/2021-sourmash-datasette, I discovered that the following commands fail:\r\n```\r\nconda create -n datasette4 -y datasette=0.58.1\r\nconda activate datasette4\r\ndatasette gathertax.db\r\n```\r\nwith `ImportError: cannot import name 'WebSocketScope' from 'asgiref.typing'`.\r\n\r\nThis appears to be because asgiref 3.3.4 doesn't have WebSocketScope, but later versions do - a simple\r\n\r\n```\r\npip install asgiref==3.4.1\r\n```\r\n\r\nfixes the problem for me, at least to the point where I can run datasette and poke around as usual.\r\n\r\nI note that over in the conda-forge recipe, https://github.com/conda-forge/datasette-feedstock/blob/master/recipe/meta.yaml pins asgiref to < 3.4.0, but I'm not sure why - so I'm not sure how to best resolve this issue :).", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1456/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 988553806, "node_id": "MDU6SXNzdWU5ODg1NTM4MDY=", "number": 1457, "title": "suggestion: distinguish names in `--static` documentation", "user": {"value": 51016, "label": "ctb"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-09-05T17:04:27Z", "updated_at": "2021-10-14T18:39:55Z", "closed_at": "2021-10-14T18:39:55Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Over in https://docs.datasette.io/en/stable/custom_templates.html#serving-static-files, there is the slightly comical example command -\r\n\r\n```\r\ndatasette -m metadata.json --static static:static/ --memory\r\n```\r\n\r\n(now, with MORE STATIC!)\r\n\r\nIt took me a while to sort out all the URLs and paths involved because I wasn't being very clever. But in the interests of simplification and distinction, I might suggest something like\r\n\r\n```\r\ndatasette -m metadata.json --static loc:static-files/ --memory\r\n```\r\n\r\nI will submit a PR for your consideration.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1457/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 988556488, "node_id": "MDU6SXNzdWU5ODg1NTY0ODg=", "number": 1459, "title": "suggestion: allow `datasette --open` to take a relative URL", "user": {"value": 51016, "label": "ctb"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2021-09-05T17:17:07Z", "updated_at": "2021-09-05T19:59:15Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "(soft suggestion because I'm not sure I'm using datasette right yet)\r\n\r\nOver at https://github.com/ctb/2021-sourmash-datasette, I'm playing around with datasette, and I'm creating some static pages to send people to the right facets. There may well be better ways of achieving this end goal, and I will find out if so, I'm sure!\r\n\r\nBut regardless I think it might be neat to support an option to allow `-o/--open` to take a relative URL, that then gets appended to the hostname and port. This would let me improve my documentation. I don't see any downsides, either, but \ud83e\udd37 there may well be some :)\r\n\r\nHappy to dig in and provide a PR if it's of interest. I'm not sure off the top of my head how to support an optional value to a parameter in argparse - the current `-o` behavior is kinda nice so it'd be suboptimal to require a url for `-o`. Maybe `--open-url=` or something would work?\r\n\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1459/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 989109888, "node_id": "MDU6SXNzdWU5ODkxMDk4ODg=", "number": 1460, "title": "Override column metadata with metadata from another column", "user": {"value": 72577720, "label": "MichaelTiemannOSC"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-09-06T12:13:33Z", "updated_at": "2021-09-06T12:13:33Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I have a table from the PUDL project (https://github.com/catalyst-cooperative/pudl) that looks like this:\r\n\r\n```\r\nCREATE TABLE fuel_ferc1 (\r\n\tid INTEGER NOT NULL, \r\n\trecord_id TEXT, \r\n\tutility_id_ferc1 INTEGER, \r\n\treport_year INTEGER, \r\n\tplant_name_ferc1 TEXT, \r\n\tfuel_type_code_pudl VARCHAR(7), \r\n\tfuel_unit VARCHAR(7),\r\n\tfuel_qty_burned FLOAT,\r\n\tfuel_mmbtu_per_unit FLOAT, \r\n\tfuel_cost_per_unit_burned FLOAT, \r\n\tfuel_cost_per_unit_delivered FLOAT, \r\n\tfuel_cost_per_mmbtu FLOAT, \r\n\tPRIMARY KEY (id), \r\n\tFOREIGN KEY(plant_name_ferc1, utility_id_ferc1) REFERENCES plants_ferc1 (plant_name_ferc1, utility_id_ferc1), \r\n\tCONSTRAINT fuel_ferc1_fuel_type_code_pudl_enum CHECK (fuel_type_code_pudl IN ('coal', 'oil', 'gas', 'solar', 'wind', 'hydro', 'nuclear', 'waste', 'unknown')), \r\n\tCONSTRAINT fuel_ferc1_fuel_unit_enum CHECK (fuel_unit IN ('ton', 'mcf', 'bbl', 'gal', 'kgal', 'gramsU', 'kgU', 'klbs', 'btu', 'mmbtu', 'mwdth', 'mwhth', 'unknown'))\r\n);\r\n```\r\n\r\nNote that `fuel_unit` is a unit that **pint** can understand, and that `fuel_qty_burned` is a column of data that could be expressed in terms of actual units, not merely as a dimensionless number. Ditto the `fuel_cost_per_unit_...` columns. Is there a way to give a column a default metadata unit (such as *tons* or *USD/ton*) and then let that be overridden when the metadata in another column says *barrels* or *USD/gramsU*?\r\n\r\n@catalyst-cooperative", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1460/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 991191951, "node_id": "MDU6SXNzdWU5OTExOTE5NTE=", "number": 1464, "title": "clean checkout & clean environment has test failures", "user": {"value": 51016, "label": "ctb"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 6, "created_at": "2021-09-08T14:16:23Z", "updated_at": "2021-09-13T22:17:17Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I followed the instructions [here](https://docs.datasette.io/en/stable/contributing.html#setting-up-a-development-environment), and even after running `python update-docs-help.py` I get the following failed tests -- any thoughts?\r\n\r\n```\r\nFAILED tests/test_api.py::test_searchable[/fixtures/searchable.json?_search=te*+AND+do*&_searchmode=raw-expected_rows3]\r\nFAILED tests/test_api.py::test_searchmode[table_metadata1-_search=te*+AND+do*-expected_rows1]\r\nFAILED tests/test_api.py::test_searchmode[table_metadata2-_search=te*+AND+do*&_searchmode=raw-expected_rows2]\r\n```\r\n\r\nThis is with python 3.9.7 and lots of other packages, as in attached environment listing from `conda list`.\r\n[conda-installed.txt](https://github.com/simonw/datasette/files/7129487/conda-installed.txt)\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1464/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 994390593, "node_id": "MDU6SXNzdWU5OTQzOTA1OTM=", "number": 1468, "title": "Faceting for custom SQL queries", "user": {"value": 72577720, "label": "MichaelTiemannOSC"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2021-09-13T02:52:16Z", "updated_at": "2021-09-13T04:54:22Z", "closed_at": "2021-09-13T04:54:17Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Facets are awesome. But not when I need to join to tidy tables together. Or even just running explicitly the default SQL query that simply lists all the rows and columns of a table (up to SIZE). That is to say, when I browse a table, I see facets:\r\n\r\nhttps://latest.datasette.io/fixtures/compound_three_primary_keys\r\n\r\nBut when I run a custom query, I don't:\r\n\r\nhttps://latest.datasette.io/fixtures?sql=select+pk1%2C+pk2%2C+pk3%2C+content+from+compound_three_primary_keys+order+by+pk1%2C+pk2%2C+pk3+limit+101\r\n\r\nIs there an idiom to cause custom SQL to come back with facet suggestions?", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1468/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 999902754, "node_id": "I_kwDOBm6k_c47mU4i", "number": 1473, "title": "base logo link visits `undefined` rather than href url", "user": {"value": 192568, "label": "mroswell"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2021-09-18T04:17:04Z", "updated_at": "2021-09-19T00:45:32Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I have two connected sites:\r\nhttp://www.SaferOrToxic.org \r\n(a Hugo website)\r\nand:\r\nhttp://disinfectants.SaferOrToxic.org/disinfectants/listN\r\n(a datasette table page)\r\n\r\nThe latter is linked as \"The List\" in the former's menu.\r\n(I'd love a prettier URL, but that's what I've got.)\r\n\r\nOn:\r\nhttp://disinfectants.SaferOrToxic.org/disinfectants/listN\r\n... all the other menu links should point back to:\r\nhttps://www.SaferOrToxic.org \r\nAnd they do!\r\n\r\nBut the logo, for some reason--though it has an href pointing to:\r\nhttps://www.SaferOrToxic.org\r\nKeeps going to this instead:\r\nhttps://disinfectants.saferortoxic.org/disinfectants/undefined\r\n\r\nWhat is causing that? How can I fix it?\r\n\r\nIn #1284 back in March, I was doing battle with the index.html template, in a still unresolved issue. (I wanted only a single table page at the root.)\r\n\r\nBut I thought, well, if I can't resolve that, at least I could just point the main website to the datasette page (\"The List,\") and then have the List point back to the home website.\r\n\r\nThe menu hrefs to https://www.SaferOrToxic.org work just fine, exactly as they should, from the datasette page. Even the Home link works properly.\r\n\r\nBut the logo link keeps rewriting to: https://disinfectants.saferortoxic.org/disinfectants/undefined\r\n\r\nThis is the HTML:\r\n```\r\n<a class=\"text-3xl font-bold leading-none\" href=\"https://www.saferortoxic.org\"><img src=\"https://www.saferortoxic.org/images/logo_hu26e4dce8d5931af1ea33526b28fc8383_9734_c52a4f1635ef88bda858373270551ed2.webp\" class=\"custom-logo\" alt=\"Logo: Safer or Toxic?\" width=\"300px\"></a>\r\n```\r\n\r\n\r\nIs this somehow related to cloudflare?\r\nOr something in the datasette code?\r\n\r\nI'm starting to think it's a cloudflare issue.\r\n<img width=\"1046\" alt=\"Screen Shot 2021-09-18 at 12 09 57 AM\" src=\"https://user-images.githubusercontent.com/192568/133872043-5a008e14-88cb-43fd-b921-e63ff50636fb.png\">\r\n\r\nCan I at least rule out it being a datasette issue?\r\n\r\nMy repository is here:\r\nhttps://github.com/mroswell/list-N\r\n\r\n(BTW, I couldn't figure out how to reference a local image, either, on the datasette side, which is why I'm using the image from the www home page.)\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1473/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 1006781949, "node_id": "I_kwDOBm6k_c48AkX9", "number": 1478, "title": "Documentation Request: Feature alternative ID instead of default ID", "user": {"value": 192568, "label": "mroswell"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-09-24T19:56:13Z", "updated_at": "2021-09-25T16:18:54Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "My data already has an ID that comes from a federal agency.\r\nWould love to have documentation on how to modify the template to:\r\n- Remove the generated ID from the table\r\n- Link the federal ID to the detail page\r\n- and to ensure that the JSON file uses that as the ID. I'd be happy to include the database ID in the export, but not as a key.\r\n\r\nI don't want to remove the ID from the database, though, because my experience with the federal agency is that data often has anomalies. I don't want all hell to break loose if they end up applying the same ID to multiple rows (which they haven't done yet). I just don't want it to display in the table or the data exports.\r\n\r\nPerhaps this isn't a template issue, maybe more of a db manipulation...\r\n\r\nMargie", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1478/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 1015646369, "node_id": "I_kwDOBm6k_c48iYih", "number": 1480, "title": "Exceeding Cloud Run memory limits when deploying a 4.8G database", "user": {"value": 110420, "label": "ghing"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 9, "created_at": "2021-10-04T21:20:24Z", "updated_at": "2022-10-07T04:39:10Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "When I try to deploy a 4.8G SQLite database to Google Cloud Run, I get this error message:\r\n\r\n> Memory limit of 8192M exceeded with 8826M used. Consider increasing the memory limit, see https://cloud.google.com/run/docs/configuring/memory-limits\r\n\r\nUnfortunately, the maximum amount of memory that can be allocated to an instance is 8192M.\r\n\r\nNaively profiling the memory usage of running Datasette with this database locally on my MacBook shows the following memory usage (using Activity Monitor) when I just start up Datasette locally:\r\n\r\n- Real Memory Size: 70.6 MB\r\n- Virtual Memory Size: 4.51 GB\r\n- Shared Memory Size: 2.5 MB\r\n- Private Memory Size: 57.4 MB\r\n\r\nI'm trying to understand if there's a query or other operation that gets run during container deployment that causes memory use to be so large and if this can be avoided somehow.\r\n\r\nThis is somewhat related to #1082, but on a different platform, so I decided to open a new issue.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1480/reactions\", \"total_count\": 1, \"+1\": 1, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}
{"id": 1023243105, "node_id": "I_kwDOBm6k_c48_XNh", "number": 1486, "title": "pipx installation instructions for plugins don't reference pipx inject", "user": {"value": 41546558, "label": "RhetTbull"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 0, "created_at": "2021-10-12T00:43:42Z", "updated_at": "2021-10-13T21:09:11Z", "closed_at": "2021-10-13T21:09:11Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "The datasette [installation instructions](https://github.com/simonw/datasette/blob/main/docs/installation.rst) discuss how to install with pipx, how to upgrade with pipx, and how to upgrade plugins with pipx but do not mention how to install a plugin with pipx. You discussed this on your [blog](https://til.simonwillison.net/python/installing-upgrading-plugins-with-pipx) but looks like this didn't make it in when you updated the docs for pipx (#756). \r\n\r\nI'll submit a PR shortly to fix this.", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1486/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 1044267332, "node_id": "I_kwDOCGYnMM4-PkFE", "number": 336, "title": "sqlite-util tranform --column-order mangles columns of type \"timestamp\"", "user": {"value": 536941, "label": "fgregg"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 1, "created_at": "2021-11-04T01:15:38Z", "updated_at": "2023-05-08T21:13:38Z", "closed_at": "2023-05-08T21:13:38Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Reproducible code below:\r\n\r\n```bash\r\n> echo 'create table bar (baz text, created_at timestamp default CURRENT_TIMESTAMP)' | sqlite3 foo.db\r\n> sqlite3 foo.db\r\nSQLite version 3.36.0 2021-06-18 18:36:39\r\nEnter \".help\" for usage hints.\r\nsqlite> .schema bar\r\nCREATE TABLE bar (baz text, created_at timestamp default CURRENT_TIMESTAMP);\r\nsqlite> .exit\r\n> sqlite-utils transform foo.db bar --column-order baz\r\nsqlite3 foo.db\r\nSQLite version 3.36.0 2021-06-18 18:36:39\r\nEnter \".help\" for usage hints.\r\nsqlite> .schema bar\r\nCREATE TABLE IF NOT EXISTS \"bar\" (\r\n [baz] TEXT,\r\n [created_at] FLOAT DEFAULT 'CURRENT_TIMESTAMP'\r\n);\r\nsqlite> .exit\r\n> sqlite-utils transform foo.db bar --column-order baz\r\n> sqlite3 foo.db\r\nSQLite version 3.36.0 2021-06-18 18:36:39\r\nEnter \".help\" for usage hints.\r\nsqlite> .schema bar\r\nCREATE TABLE IF NOT EXISTS \"bar\" (\r\n [baz] TEXT,\r\n [created_at] FLOAT DEFAULT '''CURRENT_TIMESTAMP'''\r\n);\r\n```\r\n\r\n", "repo": {"value": 140912432, "label": "sqlite-utils"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/sqlite-utils/issues/336/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 1059549523, "node_id": "I_kwDOBm6k_c4_J3FT", "number": 1526, "title": "Add to vercel.json, rather than overwriting it.", "user": {"value": 192568, "label": "mroswell"}, "state": "closed", "locked": 0, "assignee": null, "milestone": null, "comments": 2, "created_at": "2021-11-22T00:47:12Z", "updated_at": "2021-11-22T04:49:45Z", "closed_at": "2021-11-22T04:13:47Z", "author_association": "CONTRIBUTOR", "pull_request": null, "body": "I'd like to be able to add to vercel.json. But Datasette overwrites whatever I put in that file. I originally reported this here:\r\nhttps://github.com/simonw/datasette-publish-vercel/issues/51\r\n\r\nIn that case, I wanted to do a rewrite... and now I need to do 301 redirects (because we had to rename our site).\r\n\r\nCan this be addressed?\r\n", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1526/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": "completed"}
{"id": 1060631257, "node_id": "I_kwDOBm6k_c4_N_LZ", "number": 1528, "title": "Add new `\"sql_file\"` key to Canned Queries in metadata?", "user": {"value": 15178711, "label": "asg017"}, "state": "open", "locked": 0, "assignee": null, "milestone": null, "comments": 3, "created_at": "2021-11-22T21:58:01Z", "updated_at": "2022-06-10T03:23:08Z", "closed_at": null, "author_association": "CONTRIBUTOR", "pull_request": null, "body": "Currently for canned queries, you have to inline SQL in your `metadata.yaml` like so:\r\n\r\n```yaml\r\ndatabases:\r\n fixtures:\r\n queries:\r\n neighborhood_search:\r\n sql: |-\r\n select neighborhood, facet_cities.name, state\r\n from facetable\r\n join facet_cities on facetable.city_id = facet_cities.id\r\n where neighborhood like '%' || :text || '%'\r\n order by neighborhood\r\n title: Search neighborhoods\r\n```\r\n\r\nThis works fine, but for a few reasons, I usually have my canned queries already written in separate `.sql` files. I'd like to instead re-use those instead of re-writing it. \r\n\r\nSo, I'd like to see a new `\"sql_file\"` key that works like so:\r\n\r\n`metadata.yaml`:\r\n\r\n```yaml\r\ndatabases:\r\n fixtures:\r\n queries:\r\n neighborhood_search:\r\n sql_file: neighborhood_search.sql\r\n title: Search neighborhoods\r\n```\r\n`neighborhood_search.sql`:\r\n```sql\r\nselect neighborhood, facet_cities.name, state\r\nfrom facetable\r\njoin facet_cities on facetable.city_id = facet_cities.id\r\nwhere neighborhood like '%' || :text || '%'\r\norder by neighborhood\r\n```\r\n\r\nBoth of these would work in the exact same way, where Datasette would instead open + include `neighborhood_search.sql` on startup. \r\n\r\n\r\nA few reasons why I'd like to keep my canned queries SQL separate from metadata.yaml:\r\n\r\n- Keeping SQL in standalone SQL files means syntax highlighting and other text editor integrations in my code\r\n- Multiline strings in yaml, while functional, are a tad cumbersome and are hard to edit\r\n- Works well with other tools (can pipe `.sql` files into the `sqlite3` CLI, or use with other SQLite clients easier)\r\n- Typically my canned queries are quite long compared to everything else in my metadata.yaml, so I'd love to separate it where possible\r\n\r\nLet me know if this is a feature you'd like to see, I can try to send up a PR if this sounds right!", "repo": {"value": 107914493, "label": "datasette"}, "type": "issue", "active_lock_reason": null, "performed_via_github_app": null, "reactions": "{\"url\": \"https://api.github.com/repos/simonw/datasette/issues/1528/reactions\", \"total_count\": 0, \"+1\": 0, \"-1\": 0, \"laugh\": 0, \"hooray\": 0, \"confused\": 0, \"heart\": 0, \"rocket\": 0, \"eyes\": 0}", "draft": null, "state_reason": null}