issues
11 rows where "created_at" is on date 2017-11-19, state = "closed" and user = 9599 sorted by updated_at descending
This data as json, CSV (advanced)
Suggested facets: milestone, comments, created_at (date), updated_at (date), closed_at (date)
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at ▲ | closed_at | author_association | pull_request | body | repo | type | active_lock_reason | performed_via_github_app | reactions | draft | state_reason |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 275125805 | MDU6SXNzdWUyNzUxMjU4MDU= | 124 | Option to open readonly but not immutable | simonw 9599 | closed | 0 | 5 | 2017-11-19T02:11:03Z | 2019-06-24T06:43:46Z | 2019-06-24T06:43:46Z | OWNER | Immutable assumes no other process can modify the file. An option to open reqdonly instead would enable other processes to update the file in place. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/124/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275135393 | MDU6SXNzdWUyNzUxMzUzOTM= | 125 | Plot rows on a map with Leaflet and Leaflet.markercluster | simonw 9599 | closed | 0 | 2 | 2017-11-19T06:05:05Z | 2018-04-26T15:14:31Z | 2018-04-26T15:14:31Z | OWNER | https://github.com/Leaflet/Leaflet.markercluster would allow us to paginate-load in an enormous set of rows with latitude/longitude points, e.g. https://australian-dunnies.now.sh/ Here's a demo of it loading 50,000 markers: https://leaflet.github.io/Leaflet.markercluster/example/marker-clustering-realworld.50000.html - and it looks like it's easy to support progress bars for if we were iteratively loading 1,000 markers at a time using datasette pagination. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/125/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275166078 | MDU6SXNzdWUyNzUxNjYwNzg= | 130 | Rename "datasette build" to "datasette inspect" | simonw 9599 | closed | 0 | 0 | 2017-11-19T15:08:02Z | 2017-12-07T16:57:58Z | 2017-12-07T16:57:58Z | OWNER | This command introspects the databases and writes out a JSON summary. I think I'd like to use Since the internal method that does this is called |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/130/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275179724 | MDU6SXNzdWUyNzUxNzk3MjQ= | 135 | ?_search=x should work if used directly against a FTS virtual table | simonw 9599 | closed | 0 | Custom templates edition 2949431 | 3 | 2017-11-19T18:17:53Z | 2017-12-07T04:54:41Z | 2017-12-07T04:54:41Z | OWNER | datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/135/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275135535 | MDU6SXNzdWUyNzUxMzU1MzU= | 126 | Blog entry announcing foreign key support | simonw 9599 | closed | 0 | Foreign key edition 2919870 | 1 | 2017-11-19T06:09:06Z | 2017-11-30T16:49:24Z | 2017-11-30T16:49:24Z | OWNER | datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/126/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275176006 | MDU6SXNzdWUyNzUxNzYwMDY= | 133 | If view is filtered, search should apply within those filtered rows | simonw 9599 | closed | 0 | Foreign key edition 2919870 | 3 | 2017-11-19T17:25:36Z | 2017-11-24T22:30:32Z | 2017-11-24T22:30:15Z | OWNER | datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/133/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275135719 | MDU6SXNzdWUyNzUxMzU3MTk= | 127 | Filtered tables should show count of all matching rows, if fast enough | simonw 9599 | closed | 0 | Foreign key edition 2919870 | 2 | 2017-11-19T06:13:29Z | 2017-11-24T22:02:01Z | 2017-11-24T22:02:01Z | OWNER | Relates to #86. If you are viewing a filtered page e.g. https://fivethirtyeight.datasettes.com/fivethirtyeight-2628db9/bob-ross%2Felements-by-episode?CLOUDS=1 we should show the count of matching rows. Since this could be an expensive operation, we will run it with a strict time limit (maybe 50ms). If the time limit is exceeded we will display "many" instead, perhaps? Maybe even link to a count(*) query that would get the full 1000ms time limit which the user can click on if they like (that could even Ajax-in the result). |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/127/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 275175929 | MDU6SXNzdWUyNzUxNzU5Mjk= | 132 | Row view is not currently expanding foreign keys | simonw 9599 | closed | 0 | Foreign key edition 2919870 | 1 | 2017-11-19T17:24:25Z | 2017-11-23T21:51:51Z | 2017-11-23T21:51:30Z | OWNER | datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/132/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
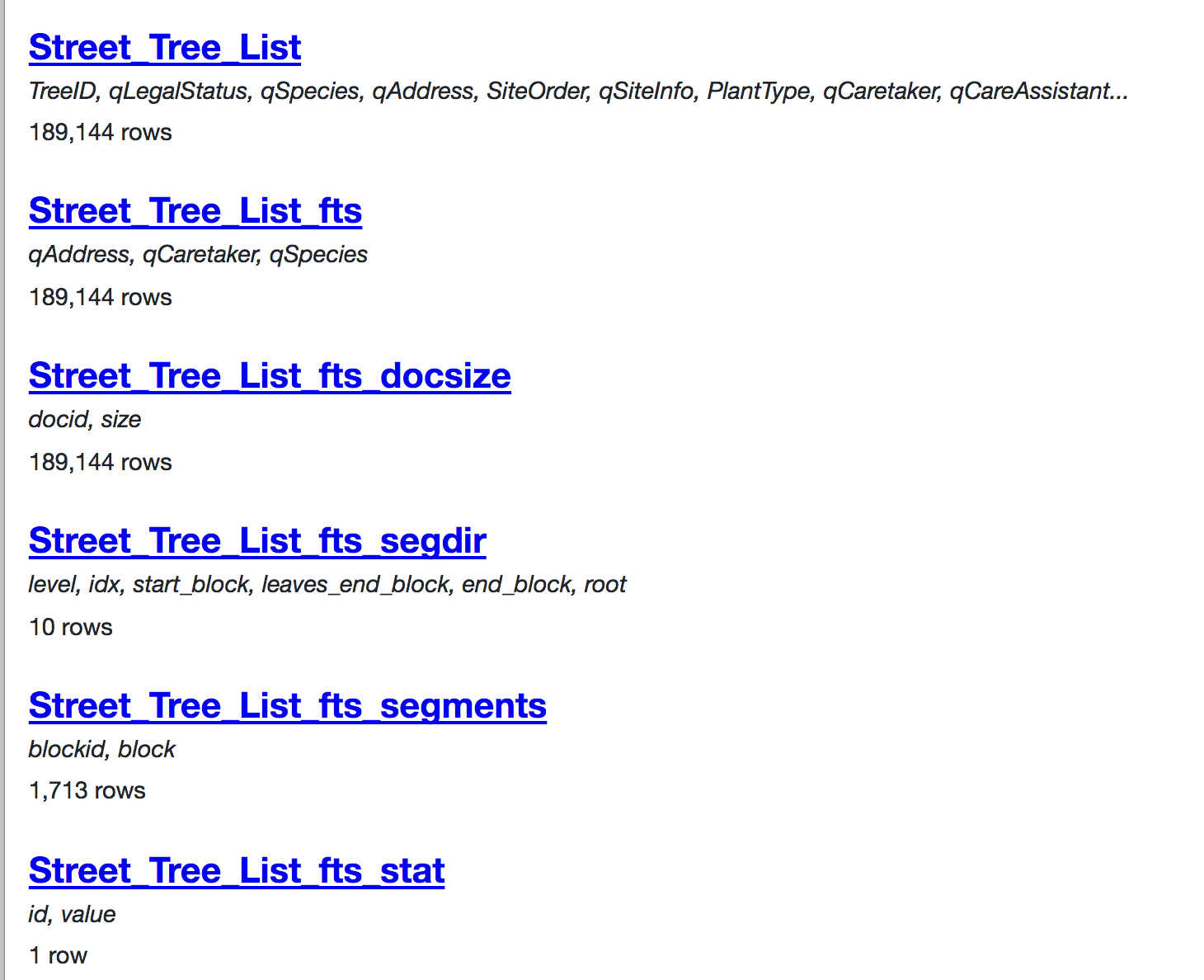
| 275164558 | MDU6SXNzdWUyNzUxNjQ1NTg= | 129 | Hide FTS-created tables by default on the database index page | simonw 9599 | closed | 0 | 2 | 2017-11-19T14:50:42Z | 2017-11-22T20:22:02Z | 2017-11-22T20:19:04Z | OWNER | SQLite databases that use FTS include a number of automatically generated tables, e.g.: https://sf-trees-search.now.sh/sf-trees-search-a899b92
Of these, only the We can detect which tables are FTS tables by first finding the virtual tables: Then parsing the above to figure out which ones are USING FTS? - then assume that any table which starts with that We won't hide these completely - instead, we'll default the database index view to not showing them with a message that says "5 hidden tables" and support ?_hidden=1 to display them. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/129/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275176094 | MDU6SXNzdWUyNzUxNzYwOTQ= | 134 | Filtered table view should show a count | simonw 9599 | closed | 0 | Foreign key edition 2919870 | 1 | 2017-11-19T17:26:53Z | 2017-11-19T18:10:49Z | 2017-11-19T18:10:49Z | OWNER | Let's do the thing where we attempt to show an accurate count if it can be done in less than 50ms |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/134/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 275166669 | MDU6SXNzdWUyNzUxNjY2Njk= | 131 | UI support for running FTS searches | simonw 9599 | closed | 0 | 3 | 2017-11-19T15:16:20Z | 2017-11-19T17:18:05Z | 2017-11-19T17:00:12Z | OWNER | Here's an example query that searches all FTS indexed columns in a table: https://sf-trees-search.now.sh/sf-trees-search-a899b92?sql=select+*+from+Street_Tree_List+where+rowid+in+%28select+rowid+from+Street_Tree_List_fts+where+Street_Tree_List_fts+match+%27grove+london+dpw%27%29%0D%0A And here's a query that searches a specific column: https://sf-trees-search.now.sh/sf-trees-search-a899b92?sql=select+*+from+Street_Tree_List+where+rowid+in+%28select+rowid+from+Street_Tree_List_fts+where+qSpecies+match+%27london%27%29%0D%0A If we detect that a table has FTS enabled (which we can do by looking for it as a content table reference in another FTS table's create definition) we should add a search box to the table page which constructs this query - maybe using <s>To support search against specified columns, we can do
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/131/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed |
Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issues] (
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[number] INTEGER,
[title] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[state] TEXT,
[locked] INTEGER,
[assignee] INTEGER REFERENCES [users]([id]),
[milestone] INTEGER REFERENCES [milestones]([id]),
[comments] INTEGER,
[created_at] TEXT,
[updated_at] TEXT,
[closed_at] TEXT,
[author_association] TEXT,
[pull_request] TEXT,
[body] TEXT,
[repo] INTEGER REFERENCES [repos]([id]),
[type] TEXT
, [active_lock_reason] TEXT, [performed_via_github_app] TEXT, [reactions] TEXT, [draft] INTEGER, [state_reason] TEXT);
CREATE INDEX [idx_issues_repo]
ON [issues] ([repo]);
CREATE INDEX [idx_issues_milestone]
ON [issues] ([milestone]);
CREATE INDEX [idx_issues_assignee]
ON [issues] ([assignee]);
CREATE INDEX [idx_issues_user]
ON [issues] ([user]);