github
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at | closed_at | author_association | pull_request | body | repo | type | active_lock_reason | performed_via_github_app | reactions | draft | state_reason |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 644283211 | MDU6SXNzdWU2NDQyODMyMTE= | 863 | {{ csrftoken() }} doesn't work with datasette.render_template() | 9599 | closed | 0 | 5533512 | 0 | 2020-06-24T03:11:49Z | 2020-06-24T04:30:30Z | 2020-06-24T03:24:01Z | OWNER | The documentation here suggests that it will work: https://github.com/simonw/datasette/blob/eed116ac0599c7d21b7129af94d58ce03a923e4e/docs/internals.rst#L540-L546 But right now the `csrftoken` variable is set in BaseView.render, which means it's not visible to plugins that try to render templates using `datasette.render_template`: https://github.com/simonw/datasette/blob/799c5d53570d773203527f19530cf772dc2eeb24/datasette/views/base.py#L99-L106 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/863/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 637409144 | MDU6SXNzdWU2Mzc0MDkxNDQ= | 839 | {"$file": ...} mechanism is broken | 9599 | closed | 0 | 5512395 | 0 | 2020-06-12T00:46:24Z | 2020-06-12T00:48:26Z | 2020-06-12T00:48:26Z | OWNER | https://travis-ci.org/github/simonw/datasette/jobs/697445318 ``` def test_plugin_config_file(app_client): open(TEMP_PLUGIN_SECRET_FILE, "w").write("FROM_FILE") > assert {"foo": "FROM_FILE"} == app_client.ds.plugin_config("file-plugin") E AssertionError: assert {'foo': 'FROM_FILE'} == {'foo': {'$fi...ugin-secret'}} E Differing items: E {'foo': 'FROM_FILE'} != {'foo': {'$file': '/tmp/plugin-secret'}} E Use -v to get the full diff ``` Broken in https://github.com/simonw/datasette/commit/fba8ff6e76253af2b03749ed8dd6e28985a7fb8f as part of #837 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/839/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 1393903845 | I_kwDOBm6k_c5TFUjl | 1828 | word-wrap: anywhere resulting in weird display | 9599 | closed | 0 | 2 | 2022-10-02T21:25:03Z | 2022-10-02T23:01:17Z | 2022-10-02T23:01:17Z | OWNER | e.g. on https://github-to-sqlite.dogsheep.net/github/commits <img width="893" alt="image" src="https://user-images.githubusercontent.com/9599/193476890-a96fae4f-4883-4698-816d-90f9cf6efd6c.png"> This is from a change introduced here: https://github.com/simonw/datasette/commit/bf8d84af5422606597be893cedd375020cb2b369 in #1805 https://github.com/simonw/datasette/blob/bf8d84af5422606597be893cedd375020cb2b369/datasette/static/app.css#L447-L450 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1828/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1089529555 | I_kwDOBm6k_c5A8ObT | 1581 | when hashed urls are turned on, the _memory db has improperly long-lived cache expiry | 536941 | closed | 0 | 1 | 2021-12-28T00:05:48Z | 2022-03-24T04:08:18Z | 2022-03-24T04:08:18Z | CONTRIBUTOR | if hashed_urls are on, then a -000 suffix is added to the `_memory` database, and the cache settings are set just as if it was a normal hashed database. in particular, this header is set: `cache-control: max-age=31536000` this is not appropriate because the `_memory-000` database isn't really hashed based on the contents of the databases (see #1561). Either the cache-control header should be changed, or the _memory db should have a hash suffix that does depend on the contents of the databases. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1581/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 789336592 | MDU6SXNzdWU3ODkzMzY1OTI= | 1195 | view_name = "query" for the query page | 9599 | open | 0 | 4 | 2021-01-19T20:21:36Z | 2021-01-25T04:40:08Z | OWNER | It uses `view_name` of `database` at the moment which isn't as useful. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1195/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1076057610 | I_kwDOBm6k_c5AI1YK | 1546 | validating the sql | 50336793 | closed | 0 | 1 | 2021-12-09T21:35:57Z | 2021-12-18T02:05:17Z | 2021-12-18T02:05:16Z | NONE | Could someone tell me that part of the code is responsible for validating the sql that guarantees that only a table can be read | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1546/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 795367402 | MDU6SXNzdWU3OTUzNjc0MDI= | 1209 | v0.54 500 error from sql query in custom template; code worked in v0.53; found a workaround | 11788561 | open | 0 | 1 | 2021-01-27T19:08:13Z | 2021-01-28T23:00:27Z | NONE | v0.54 500 error in sql query template; code worked in v0.53; found a workaround **schema:** CREATE TABLE "talks" ("talk" TEXT,"series" INTEGER, "talkdate" TEXT) CREATE TABLE "series" ("id" INTEGER PRIMARY KEY, "series" TEXT, talks_list TEXT default '', website TEXT default ''); **Live example of correctly rendered template in v.053:** https://cosmotalks-cy6xkkbezq-uw.a.run.app/cosmotalks/talks/1 **Description of problem:** I needed 'sql select' code in a custom row-mydatabase-mytable.html template to lookup the series name for a foreign key integer value in the talks table. So `metadata.json` specifies the `datasette-template-sql` plugin. The code below worked perfectly in v0.53 (just the relevant sql statement part is shown; full code is [here](https://github.com/jrdmb/cosmotalks-datasette/blob/main/templates/row-cosmotalks-talks.html)): ``` {# custom addition #} {% for row in display_rows %} ... {% set sname = sql("select series from series where id = ?", [row.series]) %} <strong>Series name: {{ sname[0].series }} ... {% endfor %} {# End of custom addition #} ``` **In v0.54, that code resulted in a 500 error with a 'no such table series' message.** A second query in that template also did not work but the above is fully illustrative of the problem. All templates were up-to-date along with datasette v0.54. **Workaround:** After fiddling around with trying different things, what worked was the syntax from [Querying a different database from the datasette-template-sql github repo](https://github.com/simonw/datasette-template-sql#querying-a-different-database) to add the database name to the sql statement: `{% set sname = sql("select series from series where id = ?", [row.series], database="cosmotalks") %}` Though this was found to work, it should not be necessary to add `database="cosmotalks"` since per the `datasette-template-sql` README, it's only needed when querying a different database, but here it's a table within the same databa… | 107914493 | issue | |||||||||
| 955316250 | MDU6SXNzdWU5NTUzMTYyNTA= | 1405 | utils.parse_metadata() should be a documented internal function | 9599 | closed | 0 | 3 | 2021-07-28T23:51:39Z | 2021-07-29T23:33:30Z | 2021-07-29T23:30:24Z | OWNER | Because it's used by this plugin: https://github.com/simonw/datasette-remote-metadata | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1405/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 506297048 | MDU6SXNzdWU1MDYyOTcwNDg= | 594 | upgrade to uvicorn-0.9 to be Python-3.8 friendly | 4312421 | closed | 0 | 3 | 2019-10-13T09:23:43Z | 2019-11-12T04:47:04Z | 2019-11-12T04:47:04Z | NONE | uvicorn-0.8 relies on websockets-0.7 which lacks python-3.8 compatiblity | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/594/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 527670799 | MDU6SXNzdWU1Mjc2NzA3OTk= | 639 | updating metadata.json without recreating the app | 172847 | open | 0 | 6 | 2019-11-24T09:19:53Z | 2019-11-30T06:08:50Z | NONE | I've sucessfully "uploaded" an SQLite database (with a metadata.json file) to heroku using: $ datasette publish heroku so-sales.db -m metadata.json -n so-sales The question is: how can I modify the (small) metadata.json file without having to upload the (large) SQLite database. The directions on heroku indicate I should run: heroku git:clone -a so-sales But this just results in an empty directory with a warning: warning: You appear to have cloned an empty repository. I've been able to "clone" the heroku "app" using the command: $ heroku slugs:download -a so-sales but this is not a git repository.... Ideally, it seems to me, there'd be an option of the `datasette` CLI to allow a file to be updated, or there'd be some way to create a local git "clone" of the app so that the heroku instructions for "Deploying with git" would apply. (p.s. I ran `datasette publish heroku -m metadata.json -n so-sales` in the hope that that would not cause the .db file to be wiped, but of course it was.) (p.p.s. Thanks for Datasette!) | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/639/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 950664971 | MDU6SXNzdWU5NTA2NjQ5NzE= | 1401 | unordered list is not rendering bullet points in description_html on database page | 536941 | open | 0 | 2 | 2021-07-22T13:24:18Z | 2021-10-23T13:09:10Z | CONTRIBUTOR | Thanks for this tremendous package, @simonw! In the `description_html` for a database, I [have an unordered list](https://github.com/labordata/warehouse/blob/fcea4502e5b615b0eb3e0bdcb45ec634abe20bb6/warehouse_metadata.yml#L19-L22). However, on the database page on the deployed site, it is not rendering this as a bulleted list.  Page here: https://labordata-warehouse.herokuapp.com/nlrb-9da4ae5 The documentation gives an [example of using an unordered list](https://docs.datasette.io/en/stable/metadata.html#using-yaml-for-metadata) in a `description_html`, so I expected this will work. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1401/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1363552780 | I_kwDOBm6k_c5RRioM | 1805 | truncate_cells_html does not work for links? | 562352 | open | 0 | 7 | 2022-09-06T16:41:29Z | 2022-10-03T09:18:06Z | NONE | We have many links inside our dataset (please don't blame us ;-). When I use `--settings truncate_cells_html 60` it is not working for the links. Eg. https://images.openfoodfacts.org/images/products/000/000/000/088/nutrition_fr.5.200.jpg (87 chars) is not truncated:  IMHO It would make sense that links should be treated as HTML. The link should work of course, but Datasette could truncate it: [https://images.openfoodfacts.org/images/products/00[...].jpg](https://images.openfoodfacts.org/images/products/000/000/000/088/nutrition_fr.5.200.jpg) | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1805/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
reopened | |||||||
| 1781047747 | I_kwDOBm6k_c5qKKHD | 2092 | test_homepage intermittent failure | 9599 | closed | 0 | 2 | 2023-06-29T15:20:37Z | 2023-06-29T15:26:28Z | 2023-06-29T15:24:13Z | OWNER | e.g. in https://github.com/simonw/datasette/actions/runs/5413590227/jobs/9839373852 ``` =================================== FAILURES =================================== ________________________________ test_homepage _________________________________ [gw0] linux -- Python 3.7.17 /opt/hostedtoolcache/Python/3.7.17/x64/bin/python ds_client = <datasette.app.DatasetteClient object at 0x7f85d271ef50> @pytest.mark.asyncio async def test_homepage(ds_client): response = await ds_client.get("/.json") assert response.status_code == 200 assert "application/json; charset=utf-8" == response.headers["content-type"] data = response.json() assert data.keys() == {"fixtures": 0}.keys() d = data["fixtures"] assert d["name"] == "fixtures" assert d["tables_count"] == 24 assert len(d["tables_and_views_truncated"]) == 5 assert d["tables_and_views_more"] is True # 4 hidden FTS tables + no_primary_key (hidden in metadata) assert d["hidden_tables_count"] == 6 # 201 in no_primary_key, plus 6 in other hidden tables: > assert d["hidden_table_rows_sum"] == 207, data E AssertionError: {'fixtures': {'color': '9403e5', 'hash': None, 'hidden_table_rows_sum': 0, 'hidden_tables_count': 6, ...}} E assert 0 == 207 ``` My guess is that this is a timing error, where very occasionally the "count rows but stop counting if it exceeds a time limit" thing fails. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2092/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 328171513 | MDU6SXNzdWUzMjgxNzE1MTM= | 302 | test-2.3.sqlite database filename throws a 404 | 9599 | closed | 0 | 3439337 | 2 | 2018-05-31T14:50:58Z | 2018-06-21T15:21:17Z | 2018-06-21T15:21:16Z | OWNER | The following almost works: datasette test-2.3.sqlite http://127.0.0.1:8001test-2.3-c88bc35/HighWays loads OK, but http://127.0.0.1:8001test-2.3-c88bc35 throws a 404: 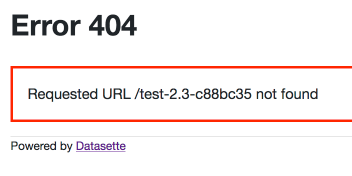 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/302/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 988553806 | MDU6SXNzdWU5ODg1NTM4MDY= | 1457 | suggestion: distinguish names in `--static` documentation | 51016 | closed | 0 | 0 | 2021-09-05T17:04:27Z | 2021-10-14T18:39:55Z | 2021-10-14T18:39:55Z | CONTRIBUTOR | Over in https://docs.datasette.io/en/stable/custom_templates.html#serving-static-files, there is the slightly comical example command - ``` datasette -m metadata.json --static static:static/ --memory ``` (now, with MORE STATIC!) It took me a while to sort out all the URLs and paths involved because I wasn't being very clever. But in the interests of simplification and distinction, I might suggest something like ``` datasette -m metadata.json --static loc:static-files/ --memory ``` I will submit a PR for your consideration. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1457/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 988556488 | MDU6SXNzdWU5ODg1NTY0ODg= | 1459 | suggestion: allow `datasette --open` to take a relative URL | 51016 | open | 0 | 1 | 2021-09-05T17:17:07Z | 2021-09-05T19:59:15Z | CONTRIBUTOR | (soft suggestion because I'm not sure I'm using datasette right yet) Over at https://github.com/ctb/2021-sourmash-datasette, I'm playing around with datasette, and I'm creating some static pages to send people to the right facets. There may well be better ways of achieving this end goal, and I will find out if so, I'm sure! But regardless I think it might be neat to support an option to allow `-o/--open` to take a relative URL, that then gets appended to the hostname and port. This would let me improve my documentation. I don't see any downsides, either, but 🤷 there may well be some :) Happy to dig in and provide a PR if it's of interest. I'm not sure off the top of my head how to support an optional value to a parameter in argparse - the current `-o` behavior is kinda nice so it'd be suboptimal to require a url for `-o`. Maybe `--open-url=` or something would work? | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1459/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 606720674 | MDU6SXNzdWU2MDY3MjA2NzQ= | 736 | strange behavior using accented characters | 30607 | closed | 0 | 3 | 2020-04-25T08:34:51Z | 2020-04-28T06:09:28Z | 2020-04-27T18:59:16Z | NONE | Hi, when I search `incompatibilità` [here](https://my-database.now.sh/commissioniComunePalermo/youtube), using full text search, it becomes `incompatibilitÃÂ ` and I have no result. If I encode the `à` char in the URL (`incompatibilit%C3%A0`) I have the right result.  | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/736/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 707849175 | MDU6SXNzdWU3MDc4NDkxNzU= | 974 | static assets and favicon aren't cached by the browser | 45416 | open | 0 | 1 | 2020-09-24T04:44:55Z | 2022-01-13T22:21:28Z | NONE | Using datasette to solve some frustrating problems with our fulfillment provider today, I was surprised to see repeated requests for assets under /-/static and the favicon. While it won't likely be a huge performance bottleneck, I bet datasette would feel a bit zippier if you had Uvicorn serving up some caching-related headers telling the browser it was safe to cache static assets. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/974/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 637342551 | MDU6SXNzdWU2MzczNDI1NTE= | 834 | startup() plugin hook | 9599 | closed | 0 | 5533512 | 6 | 2020-06-11T21:48:14Z | 2020-06-28T19:38:50Z | 2020-06-13T17:56:12Z | OWNER | It might be useful to have an `startup` hook which gets passed the `datasette` object as soon as Datasette has finished initializing. My initial use-case for this is configuration verification - checking that the `"plugins"` configuration block for this plugin contains valid details. I imagine there are plenty of other potential uses for this as well. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/834/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 1509783085 | I_kwDOBm6k_c5Z_XYt | 1969 | sql-formatter javascript is not now working with CloudFlare rocketloader | 536941 | open | 0 | 0 | 2022-12-23T21:14:06Z | 2023-01-10T01:56:33Z | CONTRIBUTOR | This is probably not a bug with datasette, but I thought you might want to know, @simonw. I noticed today that my CloudFlare proxied datasette instance lost the "Format SQL" option. I'm pretty sure it was there last week. In the CloudFlare settings, if I turn off [Rocket Loader](https://developers.cloudflare.com/fundamentals/speed/rocket-loader/), I get the "Format SQL" option back. Rocket Loader works by asynchronously loading the javascript, so maybe there was a recent change that doesn't play well with the asynch loading? I'm up to date with https://github.com/simonw/datasette/commit/e03aed00026cc2e59c09ca41f69a247e1a85cc89 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1969/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1822813627 | I_kwDOBm6k_c5spe27 | 2108 | some (many?) SQL syntax errors are not throwing errors with a .csv endpoint | 536941 | open | 0 | 0 | 2023-07-26T16:57:45Z | 2023-07-26T16:58:07Z | CONTRIBUTOR | here's a CTE query that should always fail with a syntax error: ```sql with foo as (nonsense) select * from foo; ``` when we make this query against the default endpoint, we do indeed get a 400 status code the problem is returned to the user: https://global-power-plants.datasettes.com/global-power-plants?sql=with+foo+as+%28nonsense%29+select+*+from+foo%3B but, if we use the csv endpoint, we get a 200 status code and no indication of a problem: https://global-power-plants.datasettes.com/global-power-plants.csv?sql=with+foo+as+%28nonsense%29+select+*+from+foo%3B same with this bad sql ```sql select a, from foo; ``` https://global-power-plants.datasettes.com/global-power-plants?sql=select%0D%0A++a%2C%0D%0Afrom%0D%0A++foo%3B vs https://global-power-plants.datasettes.com/global-power-plants.csv?sql=select%0D%0A++a%2C%0D%0Afrom%0D%0A++foo%3B but, datasette catches this bad sql at both endpoints: ```sql slect a from foo; ``` https://global-power-plants.datasettes.com/global-power-plants?sql=slect%0D%0A++a%0D%0Afrom%0D%0A++foo%3B https://global-power-plants.datasettes.com/global-power-plants.csv?sql=slect%0D%0A++a%0D%0Afrom%0D%0A++foo%3B | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2108/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 871304967 | MDU6SXNzdWU4NzEzMDQ5Njc= | 1315 | settings.json should be picked up by "datasette publish cloudrun" | 9599 | open | 0 | 0 | 2021-04-29T18:16:41Z | 2021-04-29T18:16:41Z | OWNER | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1315/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||||
| 718272593 | MDU6SXNzdWU3MTgyNzI1OTM= | 1007 | set-env and add-path commands have been deprecated | 9599 | open | 0 | 1 | 2020-10-09T16:21:18Z | 2020-10-09T16:23:51Z | OWNER | https://github.blog/changelog/2020-10-01-github-actions-deprecating-set-env-and-add-path-commands/ > Starting today runner version 2.273.5 will begin to warn you if you use the `add-path` or `set-env` commands. We are monitoring telemetry for the usage of these commands and plan to fully disable them in the future. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1007/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 785573793 | MDU6SXNzdWU3ODU1NzM3OTM= | 1186 | script type="module" support | 9599 | closed | 0 | 6346396 | 1 | 2021-01-14T01:17:47Z | 2021-01-24T21:21:41Z | 2021-01-14T01:50:58Z | OWNER | Custom JavaScript can be loaded in `metadata.json` like this: ```json { "extra_js_urls": [ { "url": "https://code.jquery.com/jquery-3.2.1.slim.min.js", "sri": "sha256-k2WSCIexGzOj3Euiig+TlR8gA0EmPjuc79OEeY5L45g=" } ] } ``` Add a `"module": true` option which causes the resulting script element to use `<script type="module">` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1186/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 1096536240 | I_kwDOBm6k_c5BW9Cw | 1586 | run analyze on all databases as part of start up or publishing | 536941 | open | 0 | 1 | 2022-01-07T17:52:34Z | 2022-02-02T07:13:37Z | CONTRIBUTOR | Running `analyze;` lets sqlite's query planner make *much* better use of any indices. It might be nice if the analyze was run as part of the start up of "serve" or "publish". | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1586/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 525254973 | MDU6SXNzdWU1MjUyNTQ5NzM= | 636 | rowid is not included in dropdown filter menus | 9599 | closed | 0 | 3 | 2019-11-19T20:43:04Z | 2019-11-19T23:01:17Z | 2019-11-19T23:01:17Z | OWNER | For `rowid` tables the `rowid` column isn't shown in the list of filter options: <img width="652" alt="md__md__53_805_rows_where_where_rowid___1060124_sorted_by_rowid_descending" src="https://user-images.githubusercontent.com/9599/69184590-00202680-0aca-11ea-8522-3a4690924b83.png"> This also means if you link to e.g. `?rowid__gt=1060124` the resulting filter interface will be slightly broken: clicking the "apply" button again will lose your filter for example. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/636/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1552368054 | I_kwDOBm6k_c5ch0G2 | 2000 | rewrite_sql hook | 193185 | open | 0 | 1 | 2023-01-23T01:02:52Z | 2023-01-23T06:08:01Z | CONTRIBUTOR | I'm not sold that this is a good idea, but thought it'd be worth writing up a ticket. Proposal: add a hook like ```python def rewrite_sql(datasette, database, request, fn, sql, params) ``` It would be called from Database.execute, Database.execute_write, Database.execute_write_script, Database.execute_write_many before running the user's SQL. `fn` would indicate which method was being used, in case that's relevant for the SQL inspection -- for example `execute` only permits a single statement. The hook could return a SQL statement to be executed instead, or an async function to be awaited on that returned the SQL to be executed. Plugins that could be written with this hook: - https://github.com/cldellow/datasette-ersatz-table-valued-functions would use this to avoid monkey-patching - a plugin to inspect and reject unsafe Spatialite function calls (reported by [Simon in Discord](https://discord.com/channels/823971286308356157/823971286941302908/1066438832293159004)) - a plugin to do more general rewrites of queries to enforce table or row-level security, for example, based on the currently logged in actor's ID - a plugin to maintain audit tables when users write to a table - a plugin to cache expensive queries (eg the queries that drive facets) - these could allow stale reads if previously cached, then refresh them in an offline queue Flaws with this idea: `execute_fn` and `execute_write_fn` would not go through this hook, which limits the guarantees you can make about it for security purposes. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2000/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 629541395 | MDU6SXNzdWU2Mjk1NDEzOTU= | 795 | response.set_cookie() method | 9599 | closed | 0 | 5512395 | 2 | 2020-06-02T21:57:05Z | 2020-06-09T22:33:33Z | 2020-06-09T22:19:48Z | OWNER | Mainly to clean up this code: https://github.com/simonw/datasette/blob/4fa7cf68536628344356d3ef8c92c25c249067a0/datasette/app.py#L439-L454 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/795/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 635077656 | MDU6SXNzdWU2MzUwNzc2NTY= | 822 | request.url_vars helper property | 9599 | closed | 0 | 5512395 | 2 | 2020-06-09T03:15:53Z | 2020-06-09T03:40:07Z | 2020-06-09T03:40:06Z | OWNER | This example: https://github.com/simonw/datasette/blob/f5e79adf26d0daa3831e3fba022f1b749a9efdee/docs/plugins.rst#register_routes ```python from datasette.utils.asgi import Response import html async def hello_from(scope): name = scope["url_route"]["kwargs"]["name"] return Response.html("Hello from {}".format( html.escape(name) )) @hookimpl def register_routes(): return [ (r"^/hello-from/(?P<name>.*)$"), hello_from) ] ``` Would be nicer if you could easily get `scope["url_route"]["kwargs"]["name"]` directly from the request object, without looking at the `scope`. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/822/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 626663119 | MDU6SXNzdWU2MjY2NjMxMTk= | 781 | request.url and request.scheme should obey force_https_urls config setting | 9599 | closed | 0 | 3 | 2020-05-28T16:54:47Z | 2020-05-28T17:39:54Z | 2020-05-28T17:10:13Z | OWNER | I'm trying to get the https://www.niche-museums.com/browse/feed.atom feed to validate and I git this from https://validator.w3.org/feed/check.cgi?url=https%3A%2F%2Fwww.niche-museums.com%2Fbrowse%2Ffeed.atom > This feed is valid, but interoperability with the widest range of feed readers could be improved by implementing the following recommendations. > > [line 6](https://validator.w3.org/feed/check.cgi?url=https%3A%2F%2Fwww.niche-museums.com%2Fbrowse%2Ffeed.atom#l6), column 73: Self reference doesn't match document location [[help](https://validator.w3.org/feed/docs/warning/SelfDoesntMatchLocation.html "more information about this error")] > > <link href="http://www.niche-museums.com/browse/feed.atom" rel="self"/> I tried to fix this using `force_https_urls` ([commit](https://github.com/simonw/museums/commit/5dc8e2c717c59f9e949b65e47a59878e01f929e4)) but it didn't work - because that setting isn't respected by the Request class: https://github.com/simonw/datasette/blob/40885ef24e32d91502b6b8bbad1c7376f50f2830/datasette/utils/asgi.py#L15-L32 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/781/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1978023780 | I_kwDOBm6k_c515j9k | 2205 | request.post_vars() method obliterates form keys with multiple values | 9599 | open | 0 | 8755003 | 3 | 2023-11-05T23:25:08Z | 2023-11-06T04:10:34Z | OWNER | https://github.com/simonw/datasette/blob/452a587e236ef642cbc6ae345b58767ea8420cb5/datasette/utils/asgi.py#L137-L139 In GET requests you can do `?foo=1&foo=2` - you can do the same in POST requests, but the `dict()` call here eliminates those duplicates. You can't even try calling `post_body()` and implement your own custom parsing because of: - #2204 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2205/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1978022687 | I_kwDOBm6k_c515jsf | 2204 | request.post_body() can only be called once | 9599 | open | 0 | 0 | 2023-11-05T23:22:03Z | 2023-11-05T23:23:23Z | OWNER | This code here: https://github.com/simonw/datasette/blob/452a587e236ef642cbc6ae345b58767ea8420cb5/datasette/utils/asgi.py#L127-L135 It consumes the messages, which means if you try to call it a second time you won't be able to get at the body. This is efficient - we don't end up with a `request` object property with potentially megabytes of content that we never look at again - but it's inconvenient for cases like middleware or functions where we don't know if the body has been consumed yet or not. Potential solution: set `request._body` the first time it is called, and return that on subsequent calls. Potential optimization: only do this for bodies that are shorter than a certain threshold - maybe 1MB - and raise an exception if you attempt to call `post_body()` multiple times against one of those larger bodies. I'm a bit nervous about that option though, since it could result in errors that don't show up in testing but do show up in production. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2204/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1424980545 | I_kwDOBm6k_c5U73pB | 1861 | request.headers.get("Content-Type") fails | 9599 | open | 0 | 0 | 2022-10-27T03:39:12Z | 2022-10-27T03:39:12Z | OWNER | Turns out this is case-sensitive, needs to be: request.headers.get("content-type") != "application/json" That's not great usability. It should be case insensitive. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1861/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 783714076 | MDU6SXNzdWU3ODM3MTQwNzY= | 1184 | request.full_path property | 9599 | closed | 0 | 6346396 | 0 | 2021-01-11T21:21:58Z | 2021-01-24T21:21:16Z | 2021-01-11T21:34:47Z | OWNER | > I'll also add `request.full_path` for consistency with these: https://github.com/simonw/datasette/blob/97fb10c17dd007a275ab743742e93e932335ad67/datasette/utils/asgi.py#L77-L90 _Originally posted by @simonw in https://github.com/simonw/datasette/issues/1179#issuecomment-755495387_ | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1184/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 705108492 | MDU6SXNzdWU3MDUxMDg0OTI= | 970 | request an "-o" option on "datasette server" to open the default browser at the running url | 2861690 | closed | 0 | 5971510 | 4 | 2020-09-20T13:16:34Z | 2020-10-08T23:54:27Z | 2020-09-22T14:27:04Z | NONE | This is a request for a "convenience" feature, and only a nice to have. It's based on seeing this feature in several little command line hypertext server apps. If you run, for example: datasette.exe serve --open "mydb.s3db" I would like it if default browser is launched, at the URL that is being served. The angular cli does this, for example ng serve <project> --open #see https://angular.io/cli/serve ...as does my usual mini web server of choice when inspecting local static files.... npx http-server -o # see https://www.npmjs.com/package/http-server Just a tiny thing. Love your work! | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/970/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 345821500 | MDU6SXNzdWUzNDU4MjE1MDA= | 352 | render_cell(value) plugin hook | 9599 | closed | 0 | 4 | 2018-07-30T15:56:20Z | 2020-02-10T16:18:58Z | 2018-08-05T00:14:57Z | OWNER | To allow plugins to customize how values matching a specific pattern are displayed in the HTML table view. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/352/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 963528457 | MDU6SXNzdWU5NjM1Mjg0NTc= | 1425 | render_cell() hook should support returning an awaitable | 9599 | closed | 0 | 11 | 2021-08-08T22:32:29Z | 2021-08-09T07:14:35Z | 2021-08-09T03:00:37Z | OWNER | Many of the plugin hooks can return an awaitable - e.g. https://docs.datasette.io/en/stable/plugin_hooks.html#plugin-hook-extra-template-vars - but `render_cell()` doesn't support this. I recently found myself wanting to execute an additional SQL query from that hook, but it wasn't possible to do that since I couldn't use `await`. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1425/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1515815014 | I_kwDOBm6k_c5aWYBm | 1973 | render_cell plugin hook's row object is not a sqlite.Row | 193185 | open | 0 | 4 | 2023-01-01T20:27:46Z | 2023-01-29T00:40:31Z | CONTRIBUTOR | From https://docs.datasette.io/en/stable/plugin_hooks.html#render-cell-row-value-column-table-database-datasette: > row - sqlite.Row > The SQLite row object that the value being rendered is part of This appears to actually be a [CustomRow](https://github.com/simonw/datasette/blob/f0fadc28ddb9f82e5cc1ecaa51e8a342eb6dc528/datasette/utils/__init__.py#L773-L789), but I think that's unrelated to my issue. I have a table: ```sql CREATE TABLE IF NOT EXISTS "dss_job_stats"( job_id integer not null references dss_job(id) on delete cascade, host text not null, // other columns elided as irrelevant primary key (job_id, host) ); ``` On datasette 0.63.2, the `render_cell` hook receives a `row` value that looks like: ``` CustomRow([('job_id', {'value': 2, 'label': '2'}), ('host', 'cldellow.com')]) ``` I expected the `job_id` value to be `2`, but it's actually `{'value': 2, 'label': '2'}`. I can work around this, but was wondering if this was intended behaviour? | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1973/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1388631785 | I_kwDOBm6k_c5SxNbp | 1826 | render_cell documentation example doesn't match the method signature | 66709385 | closed | 0 | 3 | 2022-09-28T02:37:59Z | 2022-09-28T04:30:28Z | 2022-09-28T04:05:16Z | NONE | Open Datasette stable doc at https://docs.datasette.io/en/stable/plugin_hooks.html?highlight=render_cell#render-cell-row-value-column-table-database-datasette render_cell plugin hook method signature is `render_cell(row, value, column, table, database, datasette)`, the example shown inline uses `render_cell(value)`.  | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1826/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 645975649 | MDU6SXNzdWU2NDU5NzU2NDk= | 867 | register_routes() should support non-async view functions too | 9599 | closed | 0 | 5533512 | 1 | 2020-06-26T03:11:25Z | 2020-06-27T18:30:41Z | 2020-06-27T18:30:40Z | OWNER | I was looking at this: https://github.com/simonw/datasette-block-robots/blob/main/datasette_block_robots/__init__.py ```python from datasette import hookimpl from datasette.utils.asgi import Response async def robots_txt(): return Response.text("User-agent: *\nDisallow: /") @hookimpl def register_routes(): return [ (r"^/robots\.txt$", robots_txt), ] ``` And I realized that if `register_routes()` could support non-async view functions it could be reduced to this: ```python @hookimpl def register_routes(): return [ (r"^/robots\.txt$", lambda: Response.text("User-agent: *\nDisallow: /")), ] ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/867/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 1485757511 | I_kwDOBm6k_c5YjtxH | 1939 | register_permissions(datasette) plugin hook | 9599 | closed | 0 | 8711695 | 20 | 2022-12-09T01:33:25Z | 2022-12-13T02:07:50Z | 2022-12-13T02:05:56Z | OWNER | A plugin hook that adds more named permissions to the list which is initially populated here: https://github.com/simonw/datasette/blob/e539c1c024bc62d88df91d9107cbe37e7f0fe55f/datasette/permissions.py#L1-L19 Originally imagined this hook in this comment: - https://github.com/simonw/datasette/issues/1881#issuecomment-1301639370 I need this for a few reasons: - https://github.com/simonw/datasette/issues/1636 - Needs it in order to validate that permissions defined in `metadata.json` are set in the right place (don't set an instance permissions at table level for example) - https://github.com/simonw/datasette/issues/1855 - Needs it to be able to register additional abbreviations for use in signed cookies - And for validation when you use `datasette create-token` and pass in extra permissions - The https://latest.datasette.io/-/permissions debug interface needs it to add extra debug options to the `<select>` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1939/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 749283032 | MDU6SXNzdWU3NDkyODMwMzI= | 1101 | register_output_renderer() should support streaming data | 9599 | open | 0 | 3268330 | 13 | 2020-11-24T02:17:09Z | 2023-01-21T22:07:19Z | OWNER | > I'd like to implement this by first extending the `register_output_renderer()` hook to support streaming huge responses, then switching CSV to use the plugin hook in addition to TSV using it. _Originally posted by @simonw in https://github.com/simonw/datasette/issues/1096#issuecomment-732542285_ | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1101/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 687681018 | MDU6SXNzdWU2ODc2ODEwMTg= | 953 | register_output_renderer render function should be able to return a Response | 9599 | closed | 0 | 5818042 | 1 | 2020-08-28T03:21:21Z | 2020-08-28T04:53:03Z | 2020-08-28T04:03:01Z | OWNER | That plugin hook was designed before Datasette had a documented Response class. It should optionally be allowed to return a Response in addition to the current custom dictionary. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/953/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 626163974 | MDU6SXNzdWU2MjYxNjM5NzQ= | 776 | register_output_renderer render callback should be optionally awaitable | 9599 | closed | 0 | 5471110 | 1 | 2020-05-28T02:26:29Z | 2020-05-28T02:43:36Z | 2020-05-28T02:43:36Z | OWNER | In #581 I made a bunch of improvements to this, including making `datasette` available to it so it could execute queries. But... it needs to be able to `await` in order to do that. Which means it should be optionally-awaitable. Original idea here: https://github.com/simonw/datasette/issues/645#issuecomment-560036740 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/776/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 625930207 | MDU6SXNzdWU2MjU5MzAyMDc= | 770 | register_output_renderer can_render mechanism | 9599 | closed | 0 | 5471110 | 4 | 2020-05-27T18:29:14Z | 2020-05-28T05:57:16Z | 2020-05-28T05:57:16Z | OWNER | I would like is the ability for renderers to opt-in / opt-out of being displayed as options on the page. https://www.niche-museums.com/browse/museums for example shows a atom link because the datasette-atom plugin is installed... but clicking it will give you a 400 error because the correct columns are not present. <img width="1113" alt="browse__museums__102_rows" src="https://user-images.githubusercontent.com/9599/83058543-62278e80-a00d-11ea-9e04-298e02745118.png"> Here's the code that passes a list of renderers to the template: https://github.com/simonw/datasette/blob/2d099ad9c657d2cab59de91cdb8bfed2da236ef6/datasette/views/base.py#L411-L423 A renderer is currently defined as a two-key dictionary: ```python @hookimpl def register_output_renderer(datasette): return { 'extension': 'test', 'callback': render_test } ``` I can add a third key, `"should_suggest"` which is a function that returns `True` or `False` for a given query. If that key is missing it is assumed to return `True`. One catch: what arguments should be passed to the `should_suggest(...)` function? UPDATE: now calling it `can_render` instead. _Originally posted by @simonw in https://github.com/simonw/datasette/issues/581#issuecomment-634856748_ | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/770/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 700728217 | MDU6SXNzdWU3MDA3MjgyMTc= | 964 | raise_404 mechanism for custom templates | 9599 | closed | 0 | 5818042 | 1 | 2020-09-14T03:22:15Z | 2020-09-14T17:49:44Z | 2020-09-14T17:39:34Z | OWNER | > Having tried this out I think it does need a `raise_404()` mechanism - which needs to be smart enough to trigger the default 404 handler without accidentally going into an infinite loop. _Originally posted by @simonw in https://github.com/simonw/datasette/issues/944#issuecomment-691788478_ | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/964/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 730210880 | MDU6SXNzdWU3MzAyMTA4ODA= | 1055 | query.html and table.html should share the same table implementation | 9599 | open | 0 | 3268330 | 0 | 2020-10-27T07:58:21Z | 2020-10-27T07:58:29Z | OWNER | In #998 I made a change that affected the table page but didn't affect the query page because I incorrectly assumed they shared rendering logic. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1055/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1163369515 | I_kwDOBm6k_c5FV5wr | 1655 | query result page is using 400mb of browser memory 40x size of html page and 400x size of csv data | 536941 | open | 0 | 8 | 2022-03-09T00:56:40Z | 2023-10-17T21:53:17Z | CONTRIBUTOR | [this page](https://labordata.bunkum.us/opdr-8335ea3?sql=with+most_recent_lu+as+%28%0D%0A++select%0D%0A++++*%0D%0A++from%0D%0A++++%28%0D%0A++++++select%0D%0A++++++++*%0D%0A++++++from%0D%0A++++++++lm_data%0D%0A++++++order+by%0D%0A++++++++f_num%2C%0D%0A++++++++receive_date+desc%0D%0A++++%29+t%0D%0A++group+by%0D%0A++++f_num%0D%0A%29%0D%0Aselect%0D%0A++aff_abbr+%7C%7C+coalesce%28%27+local+%27+%7C%7C+desig_num%2C+%27+%27+%7C%7C+unit_name%29+as+abbr_local_name%2C%0D%0A++coalesce%28%0D%0A++++regexp_match%28%27%28.*%3F%29%28%2C%3F+AFL-CIO%24%29%27%2C+union_name%29%2C%0D%0A++++regexp_match%28%27%28.*%3F%29%28+IND%24%29%27%2C+union_name%29%2C%0D%0A++++union_name%0D%0A++%29+%7C%7C+coalesce%28%27+local+%27+%7C%7C+desig_num%2C+%27+%27+%7C%7C+unit_name%29+as+full_local_name%2C%0D%0A++*%0D%0Afrom%0D%0A++most_recent_lu%0D%0Awhere+%28desig_num+IS+NOT+NULL+OR+unit_name+IS+NOT+NULL%29+AND+desig_name+%21%3D+%27HQ%27%0D%0Alimit%0D%0A++5000+offset+0) is using about 400 mb in firefox 97 on mac os x. if you download the html for the page, it's about 11mb and if you get the csv for the data its about 1mb. it's using over a 1G on chrome 99. i found this because, i was trying to figure out why editing the SQL was getting very slow. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1655/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 632673972 | MDU6SXNzdWU2MzI2NzM5NzI= | 804 | python tests/fixtures.py command has a bug | 9599 | closed | 0 | 5512395 | 6 | 2020-06-06T19:17:36Z | 2020-06-09T20:01:30Z | 2020-06-09T19:58:34Z | OWNER | This command is meant to write out `fixtures.db`, `metadata.json` and a plugins directory: ``` $ python tests/fixtures.py /tmp/fixtures.db /tmp/metadata.json /tmp/plugins/ Test tables written to /tmp/fixtures.db - metadata written to /tmp/metadata.json Traceback (most recent call last): File "tests/fixtures.py", line 833, in <module> ("my_plugin.py", PLUGIN1), NameError: name 'PLUGIN1' is not defined ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/804/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 273510781 | MDU6SXNzdWUyNzM1MTA3ODE= | 76 | publish should have required argument specifying publisher | 9599 | closed | 0 | 2857392 | 0 | 2017-11-13T17:21:26Z | 2017-11-13T18:41:01Z | 2017-11-13T18:41:01Z | OWNER | Initially the only argument will be “now” - but “hyper” can be added in the future | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/76/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 616087149 | MDU6SXNzdWU2MTYwODcxNDk= | 765 | publish heroku should default to currently tagged version | 9599 | open | 0 | 1 | 2020-05-11T18:24:06Z | 2020-05-11T18:25:43Z | OWNER | Had a report that deploying to Heroku was using the previously installed version of Datasette, not the latest. Could be because of this: https://github.com/simonw/datasette/blob/af6c6c5d6f929f951c0e63bfd1c82e37a071b50f/datasette/publish/heroku.py#L172-L179 Heroku documentation recommends pinning to specific versions https://devcenter.heroku.com/articles/python-pip So... we could ensure we default to an install value of `["datasette>=current_tag"]`. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/765/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 642388564 | MDU6SXNzdWU2NDIzODg1NjQ= | 858 | publish heroku does not work on Windows 10 | 870912 | open | 0 | 7 | 2020-06-20T14:40:28Z | 2021-06-10T17:44:09Z | NONE | When executing "datasette publish heroku schools.db" on Windows 10, I get the following error ```shell File "c:\users\dell\.virtualenvs\sec-schools-jn-cwk8z\lib\site-packages\datasette\publish\heroku.py", line 54, in heroku line.split()[0] for line in check_output(["heroku", "plugins"]).splitlines() File "c:\python38\lib\subprocess.py", line 411, in check_output return run(*popenargs, stdout=PIPE, timeout=timeout, check=True, File "c:\python38\lib\subprocess.py", line 489, in run with Popen(*popenargs, **kwargs) as process: File "c:\python38\lib\subprocess.py", line 854, in __init__ self._execute_child(args, executable, preexec_fn, close_fds, File "c:\python38\lib\subprocess.py", line 1307, in _execute_child hp, ht, pid, tid = _winapi.CreateProcess(executable, args, FileNotFoundError: [WinError 2] The system cannot find the file specified ``` Changing https://github.com/simonw/datasette/blob/55a6ffb93c57680e71a070416baae1129a0243b8/datasette/publish/heroku.py#L54 to ```python line.split()[0] for line in check_output(["heroku", "plugins"], shell=True).splitlines() ``` as well as the other `check_output()` and `call()` within the same file leads me to another recursive error about temp files | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/858/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 444749373 | MDU6SXNzdWU0NDQ3NDkzNzM= | 469 | publish commands should use new -i option | 9599 | closed | 0 | 1 | 2019-05-16T04:31:40Z | 2019-05-19T22:53:41Z | 2019-05-19T22:53:41Z | OWNER | I can make this change only after releasing 0.28 - if I make the change earlier than that `publish heroku` etc will break because they will install the latest release of Datasette which will not understand the `-i` option. This is a one-line fix: replace this: https://github.com/simonw/datasette/blob/2ad9d15cd6901654e6801e2faa29e6fc08bae5fa/datasette/utils.py#L489 With this: (need to do it for other publishers too though) ``` quoted_files = " ".join( ["-i {}".format(shlex.quote(file_name)) for file_name in file_names] ) ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/469/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 273283166 | MDU6SXNzdWUyNzMyODMxNjY= | 72 | publish command should take an optional --name argument | 9599 | closed | 0 | 2857392 | 0 | 2017-11-13T00:59:35Z | 2017-11-13T02:12:27Z | 2017-11-13T02:12:27Z | OWNER | To set the directory name so that now will inherit it as the name of the app. Defaults to datasette | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/72/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 273128608 | MDU6SXNzdWUyNzMxMjg2MDg= | 58 | publish command should detect if "now" is installed | 9599 | closed | 0 | 2857392 | 0 | 2017-11-11T08:10:17Z | 2017-11-11T16:00:07Z | 2017-11-11T16:00:07Z | OWNER | If now is not installed, it should tell you where to get it. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/58/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 306811513 | MDU6SXNzdWUzMDY4MTE1MTM= | 186 | proposal new option to disable user agents cache | 47107 | closed | 0 | 3 | 2018-03-20T10:42:20Z | 2018-03-21T09:07:22Z | 2018-03-21T01:28:31Z | NONE | I think it would be very useful for debugging an option of adding headers to http replies ``` Cache-Control: no-cache ``` especially in the html output | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/186/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 315960272 | MDU6SXNzdWUzMTU5NjAyNzI= | 227 | prepare_context() plugin hook | 9599 | closed | 0 | 8 | 2018-04-19T16:55:26Z | 2020-03-24T22:19:54Z | 2020-03-24T22:19:54Z | OWNER | This would be called with the context dictionary before each template is rendered. It would have the opportunity to modify that context. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/227/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 569253072 | MDU6SXNzdWU1NjkyNTMwNzI= | 678 | prepare_connection() plugin hook should accept optional datasette argument | 9599 | closed | 0 | 3 | 2020-02-22T00:50:26Z | 2020-02-22T03:53:19Z | 2020-02-22T02:28:51Z | OWNER | I want to build a plugin that allows users to configure certain database columns to be "masked" - so the `password` column on a users table is never revealed, for example. To do this, I need to use the `conn.set_authorizer()` SQLite mechanism. So the plugin needs to build off the `prepare_connection(conn)` hook. But that hook doesn't currently get passed `datasette` so it doesn't have a way of looking up its plugin configuration! | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/678/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1104691662 | I_kwDOBm6k_c5B2EHO | 1600 | plugins --all example should use cog | 9599 | closed | 0 | 1 | 2022-01-15T11:47:49Z | 2022-01-20T05:06:21Z | 2022-01-20T05:04:16Z | OWNER | The example output for `datasette plugins --all`on this page has got out of date: https://docs.datasette.io/en/stable/plugins.html#seeing-what-plugins-are-installed | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1600/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1023243105 | I_kwDOBm6k_c48_XNh | 1486 | pipx installation instructions for plugins don't reference pipx inject | 41546558 | closed | 0 | 0 | 2021-10-12T00:43:42Z | 2021-10-13T21:09:11Z | 2021-10-13T21:09:11Z | CONTRIBUTOR | The datasette [installation instructions](https://github.com/simonw/datasette/blob/main/docs/installation.rst) discuss how to install with pipx, how to upgrade with pipx, and how to upgrade plugins with pipx but do not mention how to install a plugin with pipx. You discussed this on your [blog](https://til.simonwillison.net/python/installing-upgrading-plugins-with-pipx) but looks like this didn't make it in when you updated the docs for pipx (#756). I'll submit a PR shortly to fix this. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1486/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 656959584 | MDU6SXNzdWU2NTY5NTk1ODQ= | 893 | pip3 install datasette not serving static on linuxbrew. | 44167 | closed | 0 | 1 | 2020-07-14T23:33:38Z | 2021-06-02T04:29:56Z | 2021-06-02T04:29:56Z | NONE | *This error wasn't thrown* ``` Traceback (most recent call last): File "/home/linuxbrew/.linuxbrew/opt/python@3.8/lib/python3.8/site-packages/datasette/utils/asgi.py", line 289, in inner_static full_path.relative_to(root_path) File "/home/linuxbrew/.linuxbrew/opt/python@3.8/lib/python3.8/pathlib.py", line 904, in relative_to raise ValueError("{!r} does not start with {!r}" ValueError: '/home/linuxbrew/.linuxbrew/lib/python3.8/site-packages/datasette/static/app.css' does not start with '/home/linuxbrew/.linuxbrew/opt/python@3.8/lib/python3.8/site-packages/datasette/static' ``` Linuxbrew install python@3.8 with symbolic links when You call the full_path.relative_to(root_path) throw ValueError. This happened when you install from pip3 when you install with python3 setup.py develop , works good. Well at the end the static wasn't serving. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/893/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 913017577 | MDU6SXNzdWU5MTMwMTc1Nzc= | 1365 | pathlib.Path breaks internal schema | 25778 | closed | 0 | 1 | 2021-06-07T01:40:37Z | 2021-06-21T15:57:39Z | 2021-06-21T15:57:39Z | CONTRIBUTOR | Ran into an issue while trying to build a plugin to render GeoJSON. I'm using pytest's `tmp_path` fixture, which is a `pathlib.Path`, to get a temporary database path. I was getting a weird error involving writes, but I was doing reads. Turns out it's the internal database trying to insert a `Path` where it wants a string. My test looked like this: ```python @pytest.mark.asyncio async def test_render_feature_collection(tmp_path): database = tmp_path / "test.db" datasette = Datasette([database]) # this will break with a path await datasette.refresh_schemas() # build a url url = datasette.urls.table(database.stem, TABLE_NAME, format="geojson") response = await datasette.client.get(url) fc = response.json() assert 200 == response.status_code ``` I only ran into this while running tests, because passing in database paths from the CLI uses strings, but it's a weird error and probably something other people have run into. The fix is easy enough: Convert the path to a string and everything works. So this: ```python @pytest.mark.asyncio async def test_render_feature_collection(tmp_path): database = tmp_path / "test.db" datasette = Datasette([str(database)]) # this is fine now await datasette.refresh_schemas() ``` This could (probably, haven't tested) be fixed [here](https://github.com/simonw/datasette/blob/03ec71193b9545536898a4bc7493274fec48bdd7/datasette/app.py#L357) by calling `str(db.path)` or by doing that conversion earlier. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1365/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1844213115 | I_kwDOBm6k_c5t7HV7 | 2138 | on_success_message_sql option for writable canned queries | 9599 | closed | 0 | 8755003 | 2 | 2023-08-10T00:20:14Z | 2023-08-10T00:39:40Z | 2023-08-10T00:34:26Z | OWNER | > Or... how about if the `on_success_message` option could define a SQL query to be executed to generate that message? Maybe `on_success_message_sql`. - https://github.com/simonw/datasette/issues/2134 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2138/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 326189744 | MDU6SXNzdWUzMjYxODk3NDQ= | 285 | num_threads and cache_max_age should be --config options | 9599 | closed | 0 | 2 | 2018-05-24T16:04:51Z | 2018-05-27T00:53:35Z | 2018-05-27T00:43:33Z | OWNER | https://github.com/simonw/datasette/blob/58b5a37dbbf13868a46bcbb284509434e66eca25/datasette/app.py#L106 And https://github.com/simonw/datasette/blob/58b5a37dbbf13868a46bcbb284509434e66eca25/datasette/views/base.py#L325 Refs #275 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/285/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1377811868 | I_kwDOBm6k_c5SH72c | 1813 | missing next and next_url in JSON responses from an instance deployed on Fly | 883348 | closed | 0 | 1 | 2022-09-19T11:32:34Z | 2022-09-19T11:34:45Z | 2022-09-19T11:34:45Z | CONTRIBUTOR | 👋 thank you for an incredibly useful project! I have noticed that my deployed instance on Fly does not include the `next` and `next_url` keys even for a truncated response : <img width="815" alt="Screenshot 2022-09-19 at 13 25 07" src="https://user-images.githubusercontent.com/883348/191007558-c0e9df03-7ee3-4e03-bd1c-26c608c3bdf9.png"> This is publically accessible here: `https://collectif-objets-datasette.fly.dev/collectif-objets.json?sql=select+*+from+mairies` However when I run the dataset server locally with the same data I get these next keys for the exact same query: <img width="695" alt="Screenshot 2022-09-19 at 13 24 05" src="https://user-images.githubusercontent.com/883348/191007464-c3905896-cd6f-46c0-8d6a-0f1c0b4471ca.png"> I am wondering if I've missed some config or something specific to deployments on Fly.io? I am running datasette v0.62, without any specific config : - locally `poetry run datasette data/collectif-objets.sqlite` - for the deploy : `poetry run datasette publish fly data/collectif-objets.sqlite` as visible in [the Makefile](https://github.com/adipasquale/collectif-objets-datasette/blob/main/Makefile). _The very limited codebase is public but the sqlite db is not versioned yet because it is too large._ | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1813/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1306984363 | I_kwDOBm6k_c5N5v-r | 1771 | minor a11y: <select> has no visual indicator when tabbed to | 1473102 | closed | 0 | 5 | 2022-07-17T04:30:14Z | 2022-12-18T06:34:20Z | 2022-12-18T06:28:12Z | NONE | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1771/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||||
| 316323336 | MDU6SXNzdWUzMTYzMjMzMzY= | 231 | metadata.json support for plugin configuration options | 9599 | closed | 0 | 4 | 2018-04-20T15:58:47Z | 2019-05-13T18:56:21Z | 2019-05-13T18:56:21Z | OWNER | My [datasette-cluster-map](https://github.com/simonw/datasette-cluster-map) plugin currently works by detecting `latitude` and `longitude` columns. I'd like to be able to configure it to look for different column names. One way to do this could be to support optional plugin configuration as part of `metadata.json`. Something like this: { "title": "Polar Bear Ear Tags, 2009-2011", "source": "USGS Alaska Science Center, Polar Bear Research Program", "source_url": "https://alaska.usgs.gov/products/data.php?dataid=130", "plugins": { "datasette_cluster_map": { "latitude_columns": [ "latitude", "Capture Latitude" ], "longitude_columns": [ "longitude", "Capture Longitude" ] } } } These settings should be supported at the root level or at the individual database or table level. They could also be exposed in the https://datasette-cluster-map-demo.now.sh/-/plugins debug tool. Refs #14 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/231/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 280014287 | MDU6SXNzdWUyODAwMTQyODc= | 165 | metadata.json support for per-database and per-table information | 9599 | closed | 0 | 2949431 | 2 | 2017-12-07T06:15:34Z | 2017-12-07T16:48:34Z | 2017-12-07T16:47:29Z | OWNER | Every database and every table should be able to support the following optional metadata: title description description_html license license_url source source_url If `description_html` is provided it over-rides `description` and will be displayed unescaped. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/165/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 753788261 | MDU6SXNzdWU3NTM3ODgyNjE= | 1118 | messagge_is_html typo | 9599 | closed | 0 | 0 | 2020-11-30T20:43:22Z | 2020-11-30T21:24:28Z | 2020-11-30T21:24:28Z | OWNER | https://ripgrep.datasette.io/-/ripgrep?pattern=messagge_is_html | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1118/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 506183241 | MDU6SXNzdWU1MDYxODMyNDE= | 593 | make uvicorn optional dependancy (because not ok on windows python yet) | 4312421 | closed | 0 | 3 | 2019-10-12T12:51:07Z | 2019-10-13T06:22:08Z | 2019-10-13T06:22:07Z | NONE | would it be possible to: - remove uvicorn mandatory dependancy ? - eventually make a fallback to hypercorn ? reason: - uvloop not yet supported on Windows/Python-3.8 and below, may happen with Python-3.9 only. - it seems a 6 lines effort (but I'm not expert) | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/593/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 733390884 | MDU6SXNzdWU3MzMzOTA4ODQ= | 1070 | load_template() example in documentation showing loading from a database | 9599 | closed | 0 | 6026070 | 1 | 2020-10-30T17:45:03Z | 2020-10-31T16:22:51Z | 2020-10-31T16:22:45Z | OWNER | > I should include an example in the documentation that shows loading templates from a database table. _Originally posted by @simonw in https://github.com/simonw/datasette/pull/1069#issuecomment-719664530_ | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1070/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 733499930 | MDU6SXNzdWU3MzM0OTk5MzA= | 1072 | load_template hook doesn't work for include/extends | 9599 | closed | 0 | 6026070 | 20 | 2020-10-30T20:33:44Z | 2020-10-31T20:48:18Z | 2020-10-30T22:50:57Z | OWNER | Includes like this one always go to disk, without hitting the `load_template` plugin hook: ```html+jinja <footer class="ft">{% block footer %}{% include "_footer.html" %}{% endblock %}</footer> ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1072/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 608058890 | MDU6SXNzdWU2MDgwNTg4OTA= | 744 | link_or_copy_directory() error - Invalid cross-device link | 30607 | closed | 0 | 28 | 2020-04-28T06:26:45Z | 2020-05-28T14:32:53Z | 2020-05-27T06:01:28Z | NONE | Hi, when I run ``` datasette publish heroku -n myapp --template-dir ./template mydb.db ``` I have this error ``` Traceback (most recent call last): File "/home/aborruso/.local/lib/python3.7/site-packages/datasette/utils/__init__.py", line 607, in link_or_copy_directory shutil.copytree(src, dst, copy_function=os.link) File "/usr/lib/python3.7/shutil.py", line 365, in copytree raise Error(errors) shutil.Error: [('/myfolder/youtubeComunePalermo/processing/./template/base.html', '/tmp/tmps9_4mzc4/templates/base.html', "[Errno 18] Invalid cross-device link: '/myfolder/youtubeComunePalermo/processing/./template/base.html' -> '/tmp/tmps9_4mzc4/templates/base.html'"), ('/myfolder/youtubeComunePalermo/processing/./template/index.html', '/tmp/tmps9_4mzc4/templates/index.html', "[Errno 18] Invalid cross-device link: '/myfolder/youtubeComunePalermo/processing/./template/index.html' -> '/tmp/tmps9_4mzc4/templates/index.html'")] During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/home/aborruso/.local/bin/datasette", line 8, in <module> sys.exit(cli()) File "/home/aborruso/.local/lib/python3.7/site-packages/click/core.py", line 829, in __call__ return self.main(*args, **kwargs) File "/home/aborruso/.local/lib/python3.7/site-packages/click/core.py", line 782, in main rv = self.invoke(ctx) File "/home/aborruso/.local/lib/python3.7/site-packages/click/core.py", line 1259, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/home/aborruso/.local/lib/python3.7/site-packages/click/core.py", line 1259, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/home/aborruso/.local/lib/python3.7/site-packages/click/core.py", line 1066, in invoke return ctx.invoke(self.callback, **ctx.params) File "/home/aborruso/.local/lib/python3.7/site-packages/click/core.py", line 610, in invoke return callback(*args, **kwargs) File "/home/aborruso/.local/lib/pytho… | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/744/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 733768037 | MDU6SXNzdWU3MzM3NjgwMzc= | 1074 | latest.datasette.io should include plugins from fixtures | 9599 | closed | 0 | 6026070 | 3 | 2020-10-31T17:23:23Z | 2020-10-31T19:47:47Z | 2020-10-31T19:47:47Z | OWNER | > It bothers me that these aren't visible in any public demos. Maybe `latest.datasette.io` should include the `my_plugins.py` and `my_plugins2.py` plugins? _Originally posted by @simonw in https://github.com/simonw/datasette/issues/1067#issuecomment-719961701_ | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1074/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 585626199 | MDU6SXNzdWU1ODU2MjYxOTk= | 705 | latest.datasette.io is no longer updating | 9599 | closed | 0 | 5234079 | 15 | 2020-03-22T01:59:30Z | 2020-03-25T02:30:24Z | 2020-03-25T02:30:24Z | OWNER | https://latest.datasette.io/-/versions is stuck on 0.35. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/705/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 1470320227 | I_kwDOBm6k_c5Xo05j | 1923 | latest.datasette.io Cloud Run deploys failing | 9599 | closed | 0 | 3 | 2022-11-30T22:49:34Z | 2022-11-30T23:04:56Z | 2022-11-30T23:04:56Z | OWNER | https://github.com/simonw/datasette/actions/runs/3587402085/jobs/6038106719v ``` Warning: "service_account_key" has been deprecated. Please switch to using google-github-actions/auth which supports both Workload Identity Federation and Service Account Key JSON authentication. For more details, see https://github.com/google-github-actions/setup-gcloud#authorization Error: google-github-actions/setup-gcloud failed with: failed to execute command `gcloud --quiet auth activate-service-account *** --key-file -`: /opt/hostedtoolcache/gcloud/275.0.0/x64/lib/googlecloudsdk/core/console/console_io.py:544: SyntaxWarning: "is" with a literal. Did you mean "=="? if answer is None or (answer is '' and default is not None): ERROR: gcloud failed to load: module 'collections' has no attribute 'MutableMapping' ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1923/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 316526433 | MDU6SXNzdWUzMTY1MjY0MzM= | 234 | label_column option in metadata.json | 9599 | closed | 0 | 3 | 2018-04-21T21:19:08Z | 2018-04-22T20:47:12Z | 2018-04-22T20:47:12Z | OWNER | Currently the column used for displaying a foreign key relationship is automatically detected by `inspect()` by looking for tables that have a primary key column and one other column. This doesn't work for tables with more than two columns. Let's allow the table section in `metadata.json` to optionally define a `label_column` which, if present, will be used for those displays. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/234/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 718484082 | MDU6SXNzdWU3MTg0ODQwODI= | 1010 | json / CSV links are broken in Datasette 0.50 | 9599 | closed | 0 | 3 | 2020-10-10T00:07:42Z | 2020-10-10T02:32:03Z | 2020-10-10T02:32:03Z | OWNER | e.g. on https://latest.datasette.io/fixtures/sortable That export link block is broken. The HTML is: ```html <p class="export-links"> This data as <a href="//fixtures/sortable.json">json</a>, <a href="//fixtures/sortable.csv?_size=max">CSV</a> (<a href="#export">advanced</a>) </p> ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1010/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 574035432 | MDU6SXNzdWU1NzQwMzU0MzI= | 692 | is_hidden_table context variable on table.html page | 9599 | open | 0 | 1 | 2020-03-02T15:03:25Z | 2020-03-02T15:03:48Z | OWNER | It's useful to know if a table is hidden when rendering that page. `datasette-configure-fts` for example may want to disallow enabling search on hidden tables. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/692/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1496652622 | I_kwDOBm6k_c5ZNRtO | 1955 | invoke_startup() is not run in some conditions, e.g. gunicorn/uvicorn workers, breaking lots of things | 32839123 | closed | 0 | 36 | 2022-12-14T13:39:56Z | 2022-12-19T04:34:16Z | 2022-12-18T02:45:18Z | NONE | In the past (pre-september 14, #1809) I had a running deployment of Datasette on Azure WebApps by emulating the call in cli.py to Gunicorn: `gunicorn -w 2 -k uvicorn.workers.UvicornWorker app:app`. My most recent deployment, however, fails loudly by shouting that `Datasette.invoke_startup()` was not called. It does not seem to be possible to call `invoke_startup` when running using a uvicorn command directly like this (I've reproduced this locally using `uvicorn`). Two candidates that I have tried: * Uvicorn has a `--factory` option, but the app factory has to be synchronous, so no `await invoke_startup` there * `asyncio.get_event_loop().run_until_complete` is also not an option because `uvicorn` already has the event loop running. One additional option is: * Use Gunicorn's [server hooks](https://docs.gunicorn.org/en/stable/settings.html#server-hooks) to call `invoke_startup`. These are also synchronous, but I might be able to get ahead of the event loop starting here. In my current deployment setup, it does not appear to be possible to use `datasette serve` directly, so I'm stuck either * Trying to rework my complete deployment setup, for instance, using Azure functions as described [here](https://github.com/simonw/azure-functions-datasette)) * Or dig into the ASGI spec and write a wrapper for the sole purpose of launching Datasette using a direct Uvicorn invocation. Questions for the maintainers: * Is this intended behaviour/will not support/etc.? If so, I'd be happy to add a PR with a couple lines in the documentation. * if this is not intended behaviour, what is a good way to fix it? I could have a go at the ASGI spec thing (I think the Azure Functions thing is related) and provide a PR with the wrapper here, but I'm all ears! Almost forgot, minimal reproducer: ```python from datasette import Datasette ds = Datasette(files=['./global-power-plants.db'])] app = ds.app() ``` Save as app.py in the same folder as global-power-plants.db, and then try running `uvicorn app:app`. O… | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1955/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1529452371 | I_kwDOBm6k_c5bKZdT | 1987 | installpython3.com is now a spam website | 9599 | closed | 0 | 4 | 2023-01-11T17:55:12Z | 2023-01-11T18:29:26Z | 2023-01-11T18:29:25Z | OWNER | Need to stop linking to it from the docs. I'll link to https://www.python.org/about/gettingstarted/ instead. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1987/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 322787470 | MDU6SXNzdWUzMjI3ODc0NzA= | 259 | inspect() should detect many-to-many relationships | 9599 | closed | 0 | 6 | 2018-05-14T12:03:58Z | 2019-05-23T03:55:37Z | 2019-05-23T03:55:37Z | OWNER | Relates to #255 - in particular supporting facets across M2M relationships. It should be possible for `.inspect()` to notice when a table has two foreign keys to two different tables, and assume that this means there is a M2M relationship between those tables. When rendering a table with a m2m relationship we could display the first X associated records as a comma separated list of hyperlinks in a new column on the table view, with a column name derived from the table on the other side. Since SQLite doesn't have RANK or an equivalent of https://www.xaprb.com/blog/2006/12/02/how-to-number-rows-in-mysql/ this would be implemented as N+1 queries (one query per cell that we want to display an m2m summary). This should be OK in SQLite: https://sqlite.org/np1queryprob.html | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/259/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 327365110 | MDU6SXNzdWUzMjczNjUxMTA= | 294 | inspect should record column types | 9599 | open | 0 | 7 | 2018-05-29T15:10:41Z | 2019-06-28T16:45:28Z | OWNER | For each table we want to know the columns, their order and what type they are. I'm going to break with SQLite defaults a little on this one and allow datasette to define additional types - to start with just a `geometry` type for columns that are detected as SpatiaLite geometries. Possible JSON design: "columns": [{ "name": "title", "type": "text" }, ...] Refs #276 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/294/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1400083043 | I_kwDOBm6k_c5Tc5Jj | 1834 | inspect data is not used for caching database hash | 536941 | closed | 0 | 0 | 2022-10-06T17:52:01Z | 2022-10-06T20:06:21Z | 2022-10-06T20:06:08Z | CONTRIBUTOR | When databases are loaded, https://github.com/simonw/datasette/blob/cb1e093fd361b758120aefc1a444df02462389a3/datasette/app.py#L257-L260 there is nothing preventing the rehashing of the database for immutable databases. https://github.com/simonw/datasette/blob/cb1e093fd361b758120aefc1a444df02462389a3/datasette/database.py#L50-L53 what i might expect is that relevant values of `inspect_data` get passed to the `Database` class to prevent re-hashing? With data that is many gigs large, this is a significant start up time. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1834/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 577578306 | MDU6SXNzdWU1Nzc1NzgzMDY= | 697 | index.html is not reliably loaded from a plugin | 9599 | closed | 0 | 7 | 2020-03-08T22:37:55Z | 2020-03-08T23:33:28Z | 2020-03-08T23:11:27Z | OWNER | Lots of detail in https://github.com/simonw/datasette-search-all/issues/2 - short version is that I have a plugin with its own `index.html` template and Datasette intermittently fails to load it and uses the default `index.html` that ships with Datasette instead. Related: * #689: "Templates considered" comment broken in >=0.35 * #693: Variables from extra_template_vars() not exposed in _context=1 (may as well fix this while I'm in there) | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/697/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 471292050 | MDU6SXNzdWU0NzEyOTIwNTA= | 563 | incorrect json url for row-level data? | 10352819 | closed | 0 | 0 | 2019-07-22T19:59:38Z | 2019-10-21T02:03:09Z | 2019-10-21T02:03:09Z | CONTRIBUTOR | While visiting [this example page](https://register-of-members-interests.datasettes.com/regmem-98dc8b7/people/uk.org.publicwhip%2Fperson%2F10001) (linked from Datasette documentation), manually clicking on [the link](https://register-of-members-interests.datasettes.com/regmem-98dc8b7/people/uk.org.publicwhip%2Fperson%2F10001?_format=json) ("This data as .json") to the json data results in an error 500 `data() got an unexpected keyword argument 'as_format'` The [JSON page linked to from the documentation](https://register-of-members-interests.datasettes.com/regmem-d22c12c/people/uk.org.publicwhip%2Fperson%2F10001.json) however is correct (the page address ends in `.json` rather than using a query string `?format=json`) This particular datasette demo page is now a few versions behind, but I was able to reproduce the issue using v0.29.2 and a downloaded copy of the demo database (and also with the current HEAD). Here is a stack trace: ``` Traceback (most recent call last): File "/home/romain/miniconda3/envs/dsbug/lib/python3.7/site-packages/datasette/utils/asgi.py", line 101, in __call__ return await view(new_scope, receive, send) File "/home/romain/miniconda3/envs/dsbug/lib/python3.7/site-packages/datasette/utils/asgi.py", line 173, in view request, **scope["url_route"]["kwargs"] File "/home/romain/miniconda3/envs/dsbug/lib/python3.7/site-packages/datasette/views/base.py", line 267, in get request, database, hash, correct_hash_provided, **kwargs File "/home/romain/miniconda3/envs/dsbug/lib/python3.7/site-packages/datasette/views/base.py", line 399, in view_get request, database, hash, **kwargs TypeError: data() got an unexpected keyword argument 'as_format' ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/563/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 855476501 | MDU6SXNzdWU4NTU0NzY1MDE= | 1298 | improve table horizontal scroll experience | 192568 | open | 0 | 4 | 2021-04-12T01:55:16Z | 2022-08-30T21:11:49Z | CONTRIBUTOR | Wide tables aren't a huge problem if you know to click and drag right. But it's not at all obvious to do that. (it also tends to blue-select any content as it's dragging.) Depending on column widths, public users might entirely miss all the columns to the right. There is a scrollbar at the bottom of the table, but I'm displaying ALL my records because it's the only way for datasette-vega to make accurate charts. So that bottom scrollbar is likely to be missed. I wonder if some sort of javascript-y mouseover to an arrow might help, similar to those seen in image carousels. Ah: here's a perfect example: 1. Visit http://google.com 2. Search for: animals endangered 3. Note the 'g-right-button' (in the code) that looks like a right-facing caret in a circle. 4. Click on that and the carousel scrolls right (and 'g-left-button' appears on the left). Might be tricky to do that on a table, rather than a one-row carousel, but it's worth experimenting with. Another option is just to put the scrollbars at the top of the table, too. Meantime, I'm trying to build a button like the "View/hide all columns on https://salaries.news.baltimoresun.com/salaries-be494cf/2019+Maryland+state+salaries Might be nice to have that available by default, with settings in the metadata showing which are on by default. (I saw some other closed issues related to horizontal scrolling, and admit I don't entirely understand them. For instance, the animated gif at https://github.com/simonw/datasette/issues/998#issuecomment-714117534 confuses me. ) | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1298/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 743011397 | MDU6SXNzdWU3NDMwMTEzOTc= | 1094 | import EX_CANTCREAT means datasette fails to work on Windows | 1049910 | closed | 0 | 1 | 2020-11-14T14:17:11Z | 2020-12-05T19:35:04Z | 2020-12-05T19:35:04Z | NONE | Trying to use datasette 0.51.1 gives the following error: ``` ImportError: cannot import name 'EX_CANTCREAT' from 'os' (C:\Users\drkan\AppData\Local\Programs\Python\Python39\lib\os.py) ``` Looks like that code is only available on unix: https://docs.python.org/3/library/os.html#os.EX_CANTCREAT Removing the line makes it work fine (`EX_CANTCREAT` doesn't seem to be used anywhere?) | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1094/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1473411197 | I_kwDOBm6k_c5X0nh9 | 1927 | ignore:true/replace:true options for /db/-/create API | 9599 | closed | 0 | 8711695 | 5 | 2022-12-02T20:32:30Z | 2022-12-15T01:47:01Z | 2022-12-08T01:43:01Z | OWNER | See also: - #1924 It turns out I want to be able to call `/db/-/create` multiple times with the `rows` argument, so that I don't have to worry about creating the table first. As such I find myself wanting support for the `"insert": true` and `"replace": true` options as well. Still TODO: - [x] A test for the case where you call `/-/create` twice with `rows` without using these options - [x] `pk` should be required if you are using these options - [x] Error if you pass `pk` and the table exists already but has a different `pk` - [x] Documentation for `insert` and `replace` - and what happens if you repeat a `/-/create` with rows generally - [x] Documentation should explain that you are allowed to call `/-/create` more than once using `rows`. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1927/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 1079111498 | I_kwDOBm6k_c5AUe9K | 1553 | if csv export is truncated in non streaming mode set informative response header | 536941 | open | 0 | 3 | 2021-12-13T22:50:44Z | 2021-12-16T19:17:28Z | CONTRIBUTOR | streaming mode is currently not enabled for custom queries, so the queries will be truncated to max row limit. it would be great if a response is truncated that an header signalling that was set in the header. i need to write some pagination code for getting full results back for a custom query and it would make the code much better if i could reliably known when there is nothing more to limit/offset | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1553/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1323346408 | I_kwDOBm6k_c5O4Kno | 1775 | i18n support | 428820 | open | 0 | 9 | 2022-07-31T02:51:04Z | 2023-02-10T18:04:40Z | NONE | I want contribute for translate UI to es, de, de and it if you share strings | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1775/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 870946764 | MDU6SXNzdWU4NzA5NDY3NjQ= | 1312 | how to query many-to-many relationship via json API? | 5268174 | open | 0 | 0 | 2021-04-29T12:09:49Z | 2021-04-29T12:09:49Z | NONE | Hi, Firstly thanks for Datasette, it's great! I'm trying to use the JSON API to query data from a Datasette instance. I have a simple 3 table many-to-many relationship, like so: `category` - list of categories `document` - list of documents `document_category` - join table (a category contains many documents, and a document can be a member of multiple categories) the `document_category` table foreign keys to the other two using their respective row_ids. Now I want to return "all documents within category X" but I cannot see a way to do this without executing two queries; the first to lookup the row_id of category X, and the second to join `document` with `document_category` where category ID is <id>. I could easily write this in SQL, but this makes programmatic handling of pagination much more difficult (we'd have to dynamically modify the SQL to select the row_id and include the correct where and limit clauses). Is there a way to achieve this using the JSON API? | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1312/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1181037277 | I_kwDOBm6k_c5GZTLd | 1686 | heroku bails if app name specifed in datasette publish is the same as existing app | 2115933 | open | 0 | 0 | 2022-03-25T17:10:34Z | 2022-03-25T17:10:34Z | NONE | Seem that `heroku` does not accept an app overwrite triggered by specifying the app name using `datasette publish`, as below: ``` datasette publish heroku some.db --name "jazzy-name" ``` The resulting error has the below traceback: ``` Creating jazzy-name... ! ▸ Name jazzy-name is already taken Traceback (most recent call last): File "/opt/homebrew/bin/datasette", line 33, in <module> sys.exit(load_entry_point('datasette==0.60.1', 'console_scripts', 'datasette')()) File "/opt/homebrew/Cellar/datasette/0.60.1/libexec/lib/python3.10/site-packages/click/core.py", line 1128, in __call__ return self.main(*args, **kwargs) File "/opt/homebrew/Cellar/datasette/0.60.1/libexec/lib/python3.10/site-packages/click/core.py", line 1053, in main rv = self.invoke(ctx) File "/opt/homebrew/Cellar/datasette/0.60.1/libexec/lib/python3.10/site-packages/click/core.py", line 1659, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/opt/homebrew/Cellar/datasette/0.60.1/libexec/lib/python3.10/site-packages/click/core.py", line 1659, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/opt/homebrew/Cellar/datasette/0.60.1/libexec/lib/python3.10/site-packages/click/core.py", line 1395, in invoke return ctx.invoke(self.callback, **ctx.params) File "/opt/homebrew/Cellar/datasette/0.60.1/libexec/lib/python3.10/site-packages/click/core.py", line 754, in invoke return __callback(*args, **kwargs) File "/opt/homebrew/Cellar/datasette/0.60.1/libexec/lib/python3.10/site-packages/datasette/publish/heroku.py", line 127, in heroku create_output = check_output(cmd).decode("utf8") File "/opt/homebrew/Cellar/python@3.10/3.10.2/Frameworks/Python.framework/Versions/3.10/lib/python3.10/subprocess.py", line 420, in check_output return run(*popenargs, stdout=PIPE, timeout=timeout, check=True, File "/opt/homebrew/Cellar/python@3.10/3.10.2/Frameworks/Python.framework/Versions/3.10/lib/python3.10/subprocess.py", line 524, in run … | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1686/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 799663959 | MDU6SXNzdWU3OTk2NjM5NTk= | 1213 | gzip support for HTML (and JSON) responses | 9599 | open | 0 | 3 | 2021-02-02T20:36:28Z | 2021-02-02T20:41:55Z | OWNER | This page https://datasette-tiles-demo.datasette.io/San_Francisco/tiles is 2MB because of all of the base64 images. Gzipped it's 1.5MB. Since Datasette is usually deployed without a frontend gzipping proxy, Datasette itself needs to solve for this. Gzipping everything won't work because some endpoints - the all-rows CSV endpoint and the download-database endpoint - are streaming and hence can't be buffered-and-gzipped. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1213/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1334628400 | I_kwDOBm6k_c5PjNAw | 1779 | google cloudrun updated their limits on maxscale based on memory and cpu count | 536941 | closed | 0 | 8303187 | 13 | 2022-08-10T13:27:21Z | 2022-08-14T19:42:59Z | 2022-08-14T17:07:34Z | CONTRIBUTOR | if you don't set an explicit limit on container scaling, then [google defaults to 100](https://cloud.google.com/run/docs/configuring/max-instances#limits) google recently updated the [limits on container scaling](https://cloud.google.com/run/docs/configuring/max-instances#limits), such that if you set up datasette to use more memory or cpu, then you need to set the maxScale argument much smaller than 100. would be nice if `datasette publish` could do this math for you and set the right maxScale. [Log of an failing publish run](https://github.com/labordata/warehouse/runs/7764725972?check_suite_focus=true#step:8:332). ``` ERROR: (gcloud.run.deploy) spec.template.spec.containers[0].resources.limits.cpu: Invalid value specified for cpu. For the specified value, maxScale may not exceed 15. Consider running your workload in a region with greater capacity, decreasing your requested cpu-per-instance, or requesting an increase in quota for this region if you are seeing sustained usage near this limit, see https://cloud.google.com/run/quotas. Your project may gain access to further scaling by adding billing information to your account. Traceback (most recent call last): File "/home/runner/.local/bin/datasette", line 8, in <module> sys.exit(cli()) File "/home/runner/.local/lib/python3.8/site-packages/click/core.py", line 1128, in __call__ return self.main(*args, **kwargs) File "/home/runner/.local/lib/python3.8/site-packages/click/core.py", line 1053, in main rv = self.invoke(ctx) File "/home/runner/.local/lib/python3.8/site-packages/click/core.py", line 1659, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/home/runner/.local/lib/python3.8/site-packages/click/core.py", line 1659, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/home/runner/.local/lib/python3.8/site-packages/click/core.py", line 1395, in invoke return ctx.invoke(self.callback, **ctx.params) File "/home/runner/.local/lib/python3.8/site-packages/… | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1779/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 1091257796 | I_kwDOBm6k_c5BC0XE | 1584 | give error with recursive sql | 58088336 | open | 0 | 0 | 2021-12-30T18:53:16Z | 2021-12-30T18:53:16Z | NONE | I got an error "near "WITH": syntax error" after I upgraded to version 0.59 from 0.52.4. This error is related to recursive sql. It works great on the previous version but it failed after upgraded. Below is an example of sql: WITH RECURSIVE manager_of(position, super_position) AS (SELECT position, case ifnull(INDIRECT_SUPER_POSITION,'') when '' then super_position else INDIRECT_SUPER_POSITION end as SUPER_POSITION FROM position where super_position<>'SGV000000001' and super_position!='' and position <> super_position),chain_manager_of_position(position, level) AS (SELECT super_position, 1 as level FROM manager_of WHERE super_position!='' and (position=:pos or position in (Select position from employee where employee=:ein)) UNION ALL SELECT super_position, level+1 as level FROM manager_of JOIN chain_manager_of_position USING(position)) SELECT * FROM chain_manager_of_position left join employee using(position) where employee is not NULL order by level limit 1 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1584/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1533673397 | I_kwDOBm6k_c5baf-1 | 1991 | fts5 tables are not auto-detected and hidden | 83819 | open | 0 | 0 | 2023-01-15T06:00:42Z | 2023-01-20T04:54:24Z | NONE | I set up a [Datasette instance](https://huggingface.co/spaces/Sygil/INE-dataset-explorer/tree/main) and was following the docs on full-text search. When I used fts4, datasette automatically hid the FTS tables and added the FTS search box where appropriate, but when I changed to fts5 it no longer does either. If I [manually set](https://huggingface.co/spaces/keturn/INED-datasette/blob/main/metadata.json#L9) `fts_table` for a view, then search does work as expected. My table and view creation code looks like this: ```py connection.execute("""CREATE TABLE IF NOT EXISTS captions(image_key text PRIMARY KEY, caption text NOT NULL) """) connection.execute("""CREATE VIRTUAL TABLE captions_fts USING fts5(caption, image_key UNINDEXED, content=captions) """) ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1991/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 539590148 | MDU6SXNzdWU1Mzk1OTAxNDg= | 651 | fts5 syntax error when using punctuation | 2181410 | closed | 0 | 3 | 2019-12-18T10:25:35Z | 2021-07-14T19:26:06Z | 2019-12-30T06:42:55Z | NONE | Hi Simon I get a syntax error when using punctuation or special characters in a fulltext search (using fts5). I created the virtual table using sqlite-utils' "enable-fts"-command. The same error appears on Niche Museums [https://www.niche-museums.com/browse/search?q=park.](https://www.niche-museums.com/browse/search?q=park.), but works fine in most of your other datasette-examples, e.g. register-of-members-interests [https://register-of-members-interests.datasettes.com/regmem-98dc8b7/items?_search=mins.](https://register-of-members-interests.datasettes.com/regmem-98dc8b7/items?_search=mins.) What am I doing wrong? Many thanks! | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/651/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 612673948 | MDU6SXNzdWU2MTI2NzM5NDg= | 759 | fts search on a column doesn't work anymore due to escape_fts | 133845 | closed | 0 | 3 | 2020-05-05T15:03:44Z | 2021-07-16T02:11:54Z | 2020-05-06T17:50:57Z | NONE | Hi and first, thank you for this awesome work you make with this projet. On a db indexed in full text search, I can't query on indexed column anymore. This request "cauvin language:ita": is running smoothly on a old version of datasette but not on the current version. Compare the current version query `select uuid, title, authors, year, series, language, formats, publisher, tags, identifiers from summary where rowid in (select rowid from summary_fts where summary_fts match escape_fts(:search)) order by uuid limit 101` To an older version: `select title, authors, series, uuid, language, identifiers, tags, publisher, formats, year, links from summary where rowid in (select rowid from summary_fts where summary_fts match :search) order by uuid limit 101` _language_ is a searchable column but now the search string is known as "cauvin language:ita" literally as a search term. columns are not parsed. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/759/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 718238967 | MDU6SXNzdWU3MTgyMzg5Njc= | 1003 | from_json jinja2 filter | 649467 | open | 0 | 4 | 2020-10-09T15:30:58Z | 2020-10-09T17:17:07Z | NONE | When JSON fields are rendered in a jinja2 template, it is handy to be able to manipulate them as data (e.g., iterate over an array of values). Ansible has a "from_json" function, which just called json.loads. It's a trivial as a datasette plugin, but it seems generally useful. Does it makes sense to add it directly into the app? | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1003/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1863810783 | I_kwDOBm6k_c5vF37f | 2150 | form label { width: 15% } is a bad default | 9599 | closed | 0 | 4 | 2023-08-23T18:22:27Z | 2023-08-23T18:37:18Z | 2023-08-23T18:35:48Z | OWNER | See: - https://github.com/simonw/datasette-configure-fts/issues/14 - https://github.com/simonw/datasette-auth-tokens/issues/12 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2150/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed |