github
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at | closed_at | author_association | pull_request | body | repo | type | active_lock_reason | performed_via_github_app | reactions | draft | state_reason |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 309471814 | MDU6SXNzdWUzMDk0NzE4MTQ= | 189 | Ability to sort (and paginate) by column | 9599 | closed | 0 | 9599 | 31 | 2018-03-28T18:04:51Z | 2018-04-15T18:54:22Z | 2018-04-09T05:16:02Z | OWNER | As requested in https://github.com/simonw/datasette/issues/185#issuecomment-376614973 I've previously avoided this for performance reasons: sort-by-column on a column without an index is likely to perform badly for hundreds of thousands of rows. That's not a good enough reason to avoid the feature entirely though. A few options: * Allow sort-by-column by default, give users the option to disable it for specific tables/columns * Disallow sort-by-column by default, give users option (probably in `metadata.json`) to enable it for specific tables/columns * Automatically detect if a column either has an index on it OR a table has less than X rows in it We already have the mechanism in place to cut off SQL queries that take more than X seconds, so if someone DOES try to sort by a column that's too expensive it won't actually hurt anything - but it would be nice to not show people a "sort" option which is guaranteed to throw a timeout error. The vast majority of datasette usage that I've seen so far is on smaller datasets where the performance penalties of sort-by-column are extremely unlikely to show up. ---- Still left to do: - [x] UI that shows which sort order is currently being applied (in HTML and in JSON) - [x] UI for applying a sort order (with rel=nofollow to avoid Google crawling it) - [x] Sort column names should be escaped correctly in generated SQL - [x] Validation that the selected sort order is a valid column - [x] Throw error if user attempts to apply _sort AND _sort_desc at the same time - [x] Ability to disable sorting (or sort only for specific columns) in metadata.json - [x] Fix "201 rows where sorted by sortable_with_nulls " bug | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/189/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 309558826 | MDU6SXNzdWUzMDk1NTg4MjY= | 190 | Keyset pagination doesn't work correctly for compound primary keys | 9599 | closed | 0 | 7 | 2018-03-28T22:45:06Z | 2018-03-30T06:31:15Z | 2018-03-30T06:26:28Z | OWNER | Consider https://datasette-issue-190-compound-pks.now.sh/compound-pks-9aafe8f/compound_primary_key  The next= link is to `d,v`: https://datasette-issue-190-compound-pks.now.sh/compound-pks-9aafe8f/compound_primary_key?_next=d%2Cv But that page starts with: 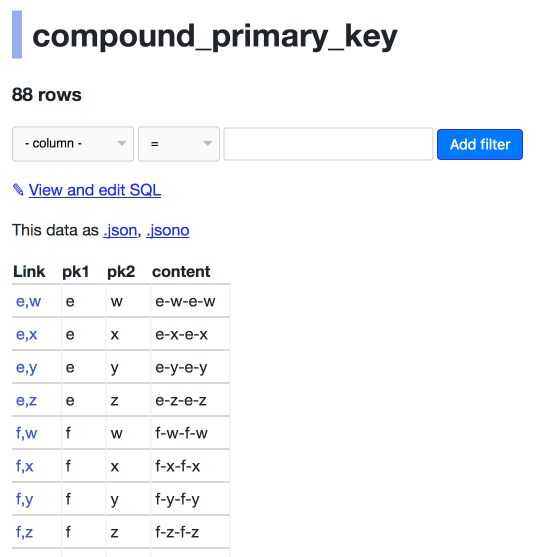 The next key in the sequence should be `d,w`. Also we should return the full a-z of the ones that start with the letter e - in this example we only return `e-w`, `e-x`, `e-y` and `e-z` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/190/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed |