github
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at | closed_at | author_association | pull_request | body | repo | type | active_lock_reason | performed_via_github_app | reactions | draft | state_reason |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 273296178 | MDU6SXNzdWUyNzMyOTYxNzg= | 73 | _nocache=1 query string option for use with sort-by-random | 9599 | closed | 0 | 2 | 2017-11-13T02:57:10Z | 2018-05-28T17:25:15Z | 2018-05-28T17:25:15Z | OWNER | The one place where we wouldn’t want cdching is if we have something which uses sort by random to return random items. We can offer a _nocache=1 querystring argument to support this. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/73/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 268262480 | MDU6SXNzdWUyNjgyNjI0ODA= | 36 | date, year, month and day querystring lookups | 9599 | closed | 0 | 3 | 2017-10-25T04:23:45Z | 2018-05-28T17:30:53Z | 2018-05-28T17:30:53Z | OWNER | - [ ] `?timestamp___date=2017-07-17` - return every item where the timestamp falls on that date - [ ] `?timestamp___year=2017` - return every item where the timestamp falls within 2017 - [ ] `?timestamp___month=1` - return every item where the month component is January - [ ] `?timestamp___day=10` - return every item where the day-of-the-month component is 10 Follow on from #23 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/36/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 268087542 | MDU6SXNzdWUyNjgwODc1NDI= | 31 | Idea: colour scheme based on sha256 of db | 9599 | closed | 0 | 2859414 | 1 | 2017-10-24T15:52:38Z | 2018-05-28T18:10:45Z | 2017-11-09T14:14:59Z | OWNER | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/31/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 268462768 | MDU6SXNzdWUyNjg0NjI3Njg= | 38 | Experiment with patterns for concurrent long running queries | 9599 | closed | 0 | 5 | 2017-10-25T16:23:42Z | 2018-05-28T20:47:31Z | 2018-05-28T20:47:31Z | OWNER | I want to understand how the system could perform under load with many concurrent long-running queries. Can we serve these without blocking the event loop? | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/38/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 273127443 | MDU6SXNzdWUyNzMxMjc0NDM= | 56 | Easy way to block search engine crawling in robots.txt | 9599 | closed | 0 | 1 | 2017-11-11T07:46:07Z | 2018-05-28T20:50:25Z | 2018-05-28T20:50:24Z | OWNER | For people who don't want their datasets to be crawled by search engines. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/56/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275917760 | MDU6SXNzdWUyNzU5MTc3NjA= | 142 | Show extra instructions with the interrupted | 9599 | closed | 0 | 3 | 2017-11-22T01:44:29Z | 2018-05-28T21:25:06Z | 2018-05-28T21:24:35Z | OWNER | When you are using Datasette locally for ad-hoc analysis it can be frustrating to hit the time limit. If you start it with the correct command line arguments you can disable that time limit. So how about we tell you how to do that anytime you hit the interrupted error provided you are accessing it from localhost. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/142/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 276091279 | MDU6SXNzdWUyNzYwOTEyNzk= | 144 | apsw as alternative sqlite3 binding (for full text search) | 649467 | closed | 0 | 3 | 2017-11-22T14:40:39Z | 2018-05-28T21:29:42Z | 2018-05-28T21:29:42Z | NONE | Hey there, Have you considered providing apsw support as an alternative to stock python sqlite3? I use apsw because it keeps up with sqlite3 and is straightforward to bring in extensions like FTS5. FTS really accelerates the kind of searching often done by web clients. I may be able to help (it shouldn't be much code), but there are a couple of stylistic questions that come up when supporting an optional package. Also, apsw is tricky in that it doesn't have a pypi package (author says limitations in providing options to setup.py). | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/144/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 274022950 | MDU6SXNzdWUyNzQwMjI5NTA= | 97 | Link to JSON for the list of tables | 9599 | closed | 0 | 3 | 2017-11-15T03:29:05Z | 2018-05-29T18:51:35Z | 2018-05-28T20:57:21Z | OWNER | https://twitter.com/yschimke/status/930606210855854080 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/97/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275089535 | MDU6SXNzdWUyNzUwODk1MzU= | 121 | ?_json=foo&_json=bar query string argument | 9599 | closed | 0 | 4 | 2017-11-18T16:09:55Z | 2018-05-31T13:48:12Z | 2018-05-28T18:11:51Z | OWNER | Causes the specified columns in the output to be treated as JSON, and returned deserialized in the .json or .jsono response. This will be particularly powerful when combined with https://sqlite.org/json1.html | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/121/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 318737808 | MDU6SXNzdWUzMTg3Mzc4MDg= | 243 | --spatialite option for datasette publish commands | 9599 | closed | 0 | 2 | 2018-04-29T18:19:32Z | 2018-05-31T14:17:53Z | 2018-05-31T14:17:53Z | OWNER | Performs the necessary incantations to install Spatialite on Zeit Now or Heroku and sets the corresponding environment variable to ensure the module is correctly loaded by datasette serve. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/243/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 327541975 | MDU6SXNzdWUzMjc1NDE5NzU= | 300 | Hide sort select box on larger screens | 9599 | closed | 0 | 0 | 2018-05-30T01:34:59Z | 2018-05-31T14:43:13Z | 2018-05-31T14:43:13Z | OWNER | I'm larger screens you can sort by clicking column headers, so no need to show the select box (which was added for the small screen layout that doesn't show headers) | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/300/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 327420945 | MDU6SXNzdWUzMjc0MjA5NDU= | 297 | datasette publish Dockerfile should use python:3.6-slim-stretch | 9599 | closed | 0 | 1 | 2018-05-29T17:40:08Z | 2018-05-31T14:44:37Z | 2018-05-31T14:44:37Z | OWNER | Right now the Dockerfile generated by `datasette package` and `datasette publish` uses this: https://github.com/simonw/datasette/blob/b0a95da96386ddf99816911e08df86178ffa9a89/datasette/utils.py#L269 This appears to result in a SQLite version of `3.8.7.1` - https://parlgov.datasettes.com/-/versions ``` "sqlite": { "extensions": {}, "fts_versions": [ "FTS4", "FTS3" ], "version": "3.8.7.1" } ``` Meanwhile, https://fivethirtyeight.datasettes.com/-/versions is deployed with this Dockerfile https://github.com/simonw/fivethirtyeight-datasette/blob/0849901cae06e957fe04892cd4033bdcd1fcf966/Dockerfile which uses `FROM python:3.6-slim-stretch` and results in the following version report: ``` "sqlite": { "extensions": { "json1": null }, "fts_versions": [ "FTS5", "FTS4", "FTS3" ], "version": "3.16.2" } ``` So not only do we get a more recent SQLite (including https://www.sqlite.org/rowvalue.html added in 3.15) but we also get `FTS5` and `json1` as well. Refs #191 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/297/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 328229224 | MDU6SXNzdWUzMjgyMjkyMjQ= | 304 | Ability to configure SQLite cache_size | 9599 | closed | 0 | 3 | 2018-05-31T17:28:07Z | 2018-06-04T16:13:32Z | 2018-06-04T16:03:19Z | OWNER | See https://www.sqlite.org/pragma.html#pragma_cache_size Let's call the config setting `cache_size_kb` to emphasize that we're using the negative option. Note this warning: perhaps we should raise an error if you try to use this setting against a SQLite version prior to 3.7.10 > If the argument N is positive then the suggested cache size is set to N. If the argument N is negative, then the number of cache pages is adjusted to use approximately abs(N*1024) bytes of memory. Backwards compatibility note: The behavior of cache_size with a negative N was different in prior to version 3.7.10 (2012-01-16). In version 3.7.9 and earlier, the number of pages in the cache was set to the absolute value of N. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/304/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 329661905 | MDU6SXNzdWUzMjk2NjE5MDU= | 306 | Custom URL routing with independent tests | 9599 | closed | 0 | 5 | 2018-06-05T23:40:08Z | 2018-06-07T15:29:28Z | 2018-06-07T15:29:28Z | OWNER | The more I think about #303 the more I feel that Datasette's URL routing needs go beyond Django-style regex matching. If we go custom, tests should live in `test_routing.py` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/306/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 330323860 | MDExOlB1bGxSZXF1ZXN0MTkzMzYxMzQx | 307 | Initial sketch of custom URL routing, refs #306 | 9599 | closed | 0 | 1 | 2018-06-07T15:26:48Z | 2018-06-07T15:29:54Z | 2018-06-07T15:29:41Z | OWNER | simonw/datasette/pulls/307 | See #306 for background on this. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/307/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 328172521 | MDU6SXNzdWUzMjgxNzI1MjE= | 303 | Support table names ending with .json or .csv | 9599 | closed | 0 | 4 | 2018-05-31T14:53:23Z | 2018-06-15T06:55:50Z | 2018-06-15T06:55:50Z | OWNER | This is needed for #266 - if a table name ends with `.json` or `.csv` right now our URL pattern matching will do the wrong thing. We should be smarter about this. This does mean we will have some URLs that look like this: http://localhost:8001/dbname/weird.json - returning HTML, not JSON http://localhost:8001/dbname/weird.json.json - returning JSON http://localhost:8001/dbname/weird.json.csv - returning CSV | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/303/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 332830309 | MDU6SXNzdWUzMzI4MzAzMDk= | 310 | datasette publish now is broken in master | 9599 | closed | 0 | 0 | 2018-06-15T16:01:14Z | 2018-06-16T16:29:50Z | 2018-06-16T16:29:50Z | OWNER | ``` > gcc -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes -fPIC -I/usr/local/include/python3.6m -c httptools/parser/parser.c -o build/temp.linux-x86_64-3.6/httptools/parser/parser.o -O2 > unable to execute 'gcc': No such file or directory > error: command 'gcc' failed with exit status 1 > > ---------------------------------------- > Command "/usr/local/bin/python -u -c "import setuptools, tokenize;__file__='/tmp/pip-install-s73273rj/httptools/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record /tmp/pip-record-yha7dxqq/install-record.txt --single-version-externally-managed --compile" failed with error code 1 in /tmp/pip-install-s73273rj/httptools/ ``` Turns out the `python-slim` base image I introduced in b18e4515855c3f1eeca3dfcccdbb6df05869084a doesn't include gcc: https://github.com/docker-library/python/issues/60#issuecomment-134322383 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/310/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 332998752 | MDExOlB1bGxSZXF1ZXN0MTk1MzM5MTEx | 311 | ?_labels=1 to expand foreign keys (in csv and json), refs #233 | 9599 | closed | 0 | 2 | 2018-06-16T16:31:12Z | 2018-06-16T22:20:31Z | 2018-06-16T22:20:31Z | OWNER | simonw/datasette/pulls/311 | Output looks something like this: { "rowid": 233, "TreeID": 121240, "qLegalStatus": { "value" 2, "label": "Private" } "qSpecies": { "value": 16, "label": "Sycamore" } "qAddress": "91 Commonwealth Ave", ... } | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/311/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 316444720 | MDU6SXNzdWUzMTY0NDQ3MjA= | 233 | Option to expose expanded foreign keys in JSON/CSV | 9599 | closed | 0 | 11 | 2018-04-21T00:18:25Z | 2018-06-16T22:26:21Z | 2018-06-16T22:20:14Z | OWNER | https://datasette-cluster-map-demo.datasettes.com/sf-trees-02c8ef1/Street_Tree_List?qCareAssistant=1  It would be nice if the info bubbles there could expose more than just the IDs, and if the title showed the expanded name of the selected qCareAssistant. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/233/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 333086005 | MDU6SXNzdWUzMzMwODYwMDU= | 313 | Deploy demo of Datasette on every commit that passes tests | 9599 | closed | 0 | 6 | 2018-06-17T19:19:12Z | 2018-06-17T21:52:58Z | 2018-06-17T21:52:58Z | OWNER | We can use Travis CI and Zeit Now to ensure there is always a live demo of current master. We can ship archived demos for releases as well. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/313/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 333120982 | MDExOlB1bGxSZXF1ZXN0MTk1NDEzMjQx | 315 | Streaming mode for downloading all rows as a CSV | 9599 | closed | 0 | 0 | 2018-06-18T03:06:59Z | 2018-06-18T03:29:13Z | 2018-06-18T03:21:02Z | OWNER | simonw/datasette/pulls/315 | Refs #266 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/315/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 323677499 | MDU6SXNzdWUzMjM2Nzc0OTk= | 265 | Add links to example Datasette instances to appropiate places in docs | 9599 | closed | 0 | 5 | 2018-05-16T15:40:20Z | 2018-06-18T15:52:15Z | 2018-06-18T15:52:15Z | OWNER | Links to working examples would really help, especially on these pages: * http://datasette.readthedocs.io/en/latest/json_api.html * http://datasette.readthedocs.io/en/latest/sql_queries.html * http://datasette.readthedocs.io/en/latest/facets.html * http://datasette.readthedocs.io/en/latest/full_text_search.html | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/265/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 328171513 | MDU6SXNzdWUzMjgxNzE1MTM= | 302 | test-2.3.sqlite database filename throws a 404 | 9599 | closed | 0 | 3439337 | 2 | 2018-05-31T14:50:58Z | 2018-06-21T15:21:17Z | 2018-06-21T15:21:16Z | OWNER | The following almost works: datasette test-2.3.sqlite http://127.0.0.1:8001test-2.3-c88bc35/HighWays loads OK, but http://127.0.0.1:8001test-2.3-c88bc35 throws a 404: 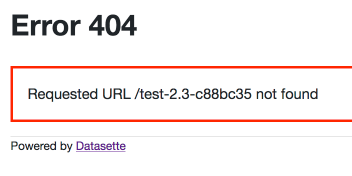 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/302/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 331343824 | MDU6SXNzdWUzMzEzNDM4MjQ= | 309 | On 404s with a trailing slash redirect to that page without a trailing slash | 9599 | closed | 0 | 3439337 | 2 | 2018-06-11T20:46:49Z | 2018-06-21T15:22:02Z | 2018-06-21T15:13:15Z | OWNER | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/309/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 333326107 | MDU6SXNzdWUzMzMzMjYxMDc= | 317 | Travis CI fails to upload new releases to PyPI | 9599 | closed | 0 | 3439337 | 2 | 2018-06-18T15:44:26Z | 2018-06-21T15:45:47Z | 2018-06-21T15:45:47Z | OWNER | https://travis-ci.org/simonw/datasette/jobs/393684139 ``` ... removing build/bdist.linux-x86_64/wheel Uploading distributions to https://upload.pypi.org/legacy/ Uploading datasette-0.23-py3-none-any.whl 100%|██████████| 201k/201k [00:00<00:00, 1.02MB/s] HTTPError: 403 Client Error: Invalid or non-existent authentication information. for url: https://upload.pypi.org/legacy/ ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/317/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 334149717 | MDU6SXNzdWUzMzQxNDk3MTc= | 319 | Incorrect display of compound primary keys with foreign key relationships | 9599 | closed | 0 | 3439337 | 2 | 2018-06-20T16:09:36Z | 2018-06-21T15:58:15Z | 2018-06-21T14:56:41Z | OWNER | https://registry.datasette.io/registry-7d4f81f/datasette_tags 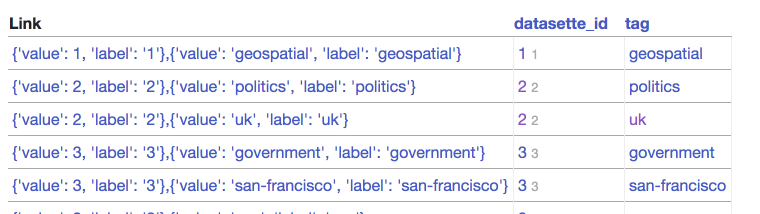 Underlying JSON looks [like this](https://registry.datasette.io/registry-7d4f81f/datasette_tags.json?_labels=on): ``` { "database": "registry", "table": "datasette_tags", "is_view": false, "human_description_en": "", "rows": [ { "datasette_id": { "value": 1, "label": "Global Power Plant Database" }, "tag": { "value": "geospatial", "label": "geospatial" } }, ```` Bug is likely somewhere in here: https://github.com/simonw/datasette/blob/e04f5b0d348ef7275a0a5ab9eb53527105132885/datasette/views/table.py#L143-L207 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/319/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 333096176 | MDU6SXNzdWUzMzMwOTYxNzY= | 314 | HTML table does not correctly display entirely blank rows | 9599 | closed | 0 | 3439337 | 1 | 2018-06-17T21:58:06Z | 2018-06-21T16:04:59Z | 2018-06-21T15:26:26Z | OWNER | https://958b75c.datasette.io/fixtures-35b6eb6/simple_view  https://958b75c.datasette.io/fixtures-35b6eb6/simple_view.json shows the underlying data: ``` "rows": [ [ "hello", "HELLO" ], [ "world", "WORLD" ], [ "", "" ] ] ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/314/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 334190959 | MDU6SXNzdWUzMzQxOTA5NTk= | 321 | Wildcard support in query parameters | 12617395 | closed | 0 | 3439337 | 8 | 2018-06-20T18:03:56Z | 2018-06-21T17:00:10Z | 2018-06-21T04:55:26Z | NONE | I haven't found a way to get the wildcard (%) inserted automatically in to a query parameter. This would be useful for cases the query parameter is followed by a LIKE clause. Wrapping the parameter name using the wildcard character within the metadata file (ie - ...where xyz like %:querystring%) does not seem to work. Can this be made possible? Or if not, can the template be extended to provide a tip to the user that they need to insert the wildcard characters themselves? | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/321/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 334592281 | MDExOlB1bGxSZXF1ZXN0MTk2NTI2ODYx | 322 | Feature/in operator | 2691848 | closed | 0 | 0 | 2018-06-21T17:41:51Z | 2018-06-21T17:45:25Z | 2018-06-21T17:45:25Z | NONE | simonw/datasette/pulls/322 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/322/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 334731076 | MDExOlB1bGxSZXF1ZXN0MTk2NjI4MzA0 | 324 | Speed up Travis by reusing pip wheel cache across builds | 9599 | closed | 0 | 0 | 2018-06-22T03:20:08Z | 2018-06-24T01:03:47Z | 2018-06-24T01:03:47Z | OWNER | simonw/datasette/pulls/324 | From https://atchai.com/blog/faster-ci/ - refs #323 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/324/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 273127694 | MDU6SXNzdWUyNzMxMjc2OTQ= | 57 | Ship a Docker image of the whole thing | 9599 | closed | 0 | 7 | 2017-11-11T07:51:28Z | 2018-06-28T04:01:51Z | 2018-06-28T04:01:38Z | OWNER | The generated Docker images can then just inherit from that. This will speed up deploys as no need to `pip install` anything. - [x] Ship that image to Docker Hub - [ ] Update the generated Dockerfile to use it | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/57/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 325373747 | MDExOlB1bGxSZXF1ZXN0MTg5NzIzNzE2 | 280 | Build Dockerfile with recent Sqlite + Spatialite | 565628 | closed | 0 | 10 | 2018-05-22T16:33:50Z | 2018-06-28T11:26:23Z | 2018-05-23T17:43:35Z | CONTRIBUTOR | simonw/datasette/pulls/280 | This solves #278 without bloating the Dockerfile too much, the image size is now 495MB (original was ~240MB) but it could be reduced significantly if we only copied the output of the compilation of spatialite and friends to /usr/local/lib, instead of the entirety of it however that will take more time. In the python code change references to `import sqlite3` to `import pysqlite3` and it should use the compiled version of sqlite3.23.1. You don't need to try/except because pysqlite3 falls back to builtin sqlite3 if there is no compiled version. ```bash $ docker run --rm -it datasette spatialite SpatiaLite version ..: 4.4.0-RC0 Supported Extensions: - 'VirtualShape' [direct Shapefile access] - 'VirtualDbf' [direct DBF access] - 'VirtualXL' [direct XLS access] - 'VirtualText' [direct CSV/TXT access] - 'VirtualNetwork' [Dijkstra shortest path] - 'RTree' [Spatial Index - R*Tree] - 'MbrCache' [Spatial Index - MBR cache] - 'VirtualSpatialIndex' [R*Tree metahandler] - 'VirtualElementary' [ElemGeoms metahandler] - 'VirtualKNN' [K-Nearest Neighbors metahandler] - 'VirtualXPath' [XML Path Language - XPath] - 'VirtualFDO' [FDO-OGR interoperability] - 'VirtualGPKG' [OGC GeoPackage interoperability] - 'VirtualBBox' [BoundingBox tables] - 'SpatiaLite' [Spatial SQL - OGC] PROJ.4 version ......: Rel. 4.9.3, 15 August 2016 GEOS version ........: 3.5.1-CAPI-1.9.1 r4246 TARGET CPU ..........: x86_64-linux-gnu the SPATIAL_REF_SYS table already contains some row(s) SQLite version ......: 3.23.1 Enter ".help" for instructions SQLite version 3.23.1 2018-04-10 17:39:29 Enter ".help" for instructions Enter SQL statements terminated with a ";" spatialite> ``` ```bash $ docker run --rm -it datasette python -c "import pysqlite3; print(pysqlite3.sqlite_version)" 3.23.1 ``` | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/280/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 335064777 | MDU6SXNzdWUzMzUwNjQ3Nzc= | 325 | Error on row page if table has slashes in the name and ends in .csv | 9599 | closed | 0 | 1 | 2018-06-23T03:43:42Z | 2018-07-09T17:28:27Z | 2018-07-08T05:21:59Z | OWNER | https://v0-23-1.datasette.io/fixtures-e14e080/table%252Fwith%252Fslashes.csv/3 > no such table: table%252Fwith%252Fslashes.csv From clicking the row link on https://v0-23-1.datasette.io/fixtures-e14e080/table%2Fwith%2Fslashes.csv | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/325/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 334698969 | MDU6SXNzdWUzMzQ2OTg5Njk= | 323 | Speed up Travis CI builds | 9599 | closed | 0 | 1 | 2018-06-21T23:55:27Z | 2018-07-10T15:03:37Z | 2018-07-10T15:03:36Z | OWNER | They've got a bit slow. Part of this is the Zeit Now deploy, but the build-and-test cycle is taking at least a couple of minutes.  | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/323/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 312395790 | MDU6SXNzdWUzMTIzOTU3OTA= | 197 | Ability to sort by more than one column | 9599 | open | 0 | 0 | 2018-04-09T05:13:30Z | 2018-07-10T17:45:37Z | OWNER | Split off from #189. I'd like to support "sort by X descending, then by Y ascending if there are dupes for X" as well. Suggested syntax for that: ?_sort_desc=X&_sort=Y we currently only allow one argument to be sent. We should allow as many arguments as there are columns, for example: ?_sort=department&_sort_desc=precinct&_sort=age&_sort_desc=size | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/197/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 312396095 | MDU6SXNzdWUzMTIzOTYwOTU= | 198 | Ability to sort with nulls last | 9599 | open | 0 | 0 | 2018-04-09T05:15:40Z | 2018-07-10T17:45:37Z | OWNER | Split off from #189 Here's how to do that in SQL: https://fivethirtyeight.datasettes.com/fivethirtyeight-2628db9?sql=select+rowid%2C+*+from+%5Bnfl-wide-receivers%2Fadvanced-historical%5D%0D%0Aorder+by+case+when+career_ranypa+is+null+then+1+else+0+end%2C+career_ranypa%2C+rowid order by case when career_ranypa is null then 1 else 0 end, career_ranypa | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/198/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 314771615 | MDU6SXNzdWUzMTQ3NzE2MTU= | 218 | Support custom unit display in order to handle "$10,000" | 9599 | open | 0 | 0 | 2018-04-16T18:39:31Z | 2018-07-10T17:45:38Z | OWNER | I tried to get Datasette to display `$10,000` using the new units support but we currently only display units as a suffix: https://github.com/simonw/datasette/blob/10a34f995c70daa37a8a2aa02c3135a4b023a24c/datasette/app.py#L563-L572 It would be neat if there was a mechanism for specifying a custom unit display - maybe something like this: ``` { "custom_units": { "us_dollar": { "unit": "us_dollar = [] = $", "format": "${:,}" } } } ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/218/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 318490133 | MDU6SXNzdWUzMTg0OTAxMzM= | 241 | Default datasette logging format should be JSON | 9599 | open | 0 | 0 | 2018-04-27T17:32:48Z | 2018-07-10T17:45:40Z | OWNER | Structured logs are better. Datasette should default to outputting it's HTTP access log lines as newline delimited JSON instead of the Sanic default format it uses at the moment. For improved greppability these logs should have keys ordered in a consistent way. Python's JSON module can do this with ordered dictionaries. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/241/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 310533258 | MDU6SXNzdWUzMTA1MzMyNTg= | 191 | Figure out how to bundle a more up-to-date SQLite | 9599 | closed | 0 | 6 | 2018-04-02T16:33:25Z | 2018-07-10T17:46:13Z | 2018-07-10T17:46:13Z | OWNER | The version of SQLite that ships with Python 3 is a bit limited - it doesn't support row values for example https://www.sqlite.org/rowvalue.html Figure out how to bundle a more recent SQLite engine with datasette. We need to figure out two cases: * Bundling a recent version in a Dockerfile build. I expect this to be quite easy. * Making a more recent version available to people hacking around in Mac OS X. I have no idea how to start on this. I want it working on Mac OS X too because I don't want to force Docker as a dependency for anyone who just want to hack around with Datasette a little and run the test suite. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/191/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275493851 | MDU6SXNzdWUyNzU0OTM4NTE= | 139 | Build a visualization plugin for Vega | 9599 | closed | 0 | 2 | 2017-11-20T20:47:41Z | 2018-07-10T17:48:18Z | 2018-07-10T17:48:18Z | OWNER | https://vega.github.io/vega/examples/population-pyramid/ for example looks pretty easy to hook up to Datasette. Depends on #14 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/139/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275939188 | MDU6SXNzdWUyNzU5MzkxODg= | 143 | Mechanism for "suggested visualizations" | 9599 | closed | 0 | 1 | 2017-11-22T04:10:25Z | 2018-07-10T17:48:34Z | 2018-07-10T17:48:34Z | OWNER | Each visualization should have a way of deciding if it might be appropriate for the current view of data. We can then offer a "suggested visualizations" prompt which shows previews. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/143/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 273709194 | MDU6SXNzdWUyNzM3MDkxOTQ= | 87 | Configure Travis to release new tags to PyPI | 9599 | closed | 0 | 1 | 2017-11-14T08:44:08Z | 2018-07-10T17:49:13Z | 2018-07-10T17:49:12Z | OWNER | https://docs.travis-ci.com/user/deployment/pypi/ | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/87/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 267886330 | MDU6SXNzdWUyNjc4ODYzMzA= | 27 | Ability to plot a simple graph | 9599 | closed | 0 | 3 | 2017-10-24T03:34:59Z | 2018-07-10T17:52:41Z | 2018-07-10T17:52:41Z | OWNER | Might be as simple as: pick he type of chart (bar, line) and then pick the column for the X axis and the column for the Y axis. Maybe also allow a pie chart. It’s up to the user to come up with SQL that gets the right values. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/27/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 340065374 | MDU6SXNzdWUzNDAwNjUzNzQ= | 337 | Documentation for datasette publish and datasette package | 9599 | closed | 0 | 1 | 2018-07-11T02:04:06Z | 2018-07-11T02:07:32Z | 2018-07-11T02:05:56Z | OWNER | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/337/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||||
| 340282796 | MDU6SXNzdWUzNDAyODI3OTY= | 338 | Only load vegaEmbed if charting tools are enabled | 9599 | closed | 0 | 1 | 2018-07-11T15:02:14Z | 2018-07-11T15:21:47Z | 2018-07-11T15:21:47Z | OWNER | vegaEmbed is a LOT of code (it bundles d3) Inspired by this tweet: https://twitter.com/thelarkinn/status/1017053567641948162 - it would be great if we loaded that code on demand the first time the "Show chart options" button was clicked, or when the page loads with #g. options in the URL. Even better: avoid the overhead if loading React unless the chart options need to be displayed. This would be a pretty major refactoring though. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/338/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 340733753 | MDExOlB1bGxSZXF1ZXN0MjAxMDc1NTMy | 341 | Bump aiohttp to fix compatibility with Python 3.7 | 9599 | closed | 0 | 0 | 2018-07-12T17:41:24Z | 2018-07-12T18:07:38Z | 2018-07-12T18:07:38Z | OWNER | simonw/datasette/pulls/341 | Tests failed here: https://travis-ci.org/simonw/datasette/jobs/403223333 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/341/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 341229113 | MDU6SXNzdWUzNDEyMjkxMTM= | 344 | datasette publish heroku fails without name provided | 45057 | closed | 0 | 1 | 2018-07-14T11:15:56Z | 2018-07-14T13:00:48Z | 2018-07-14T13:00:48Z | CONTRIBUTOR | It fails with the following JSON traceback if the `-n` option isn't provided, despite the fact that the command line help says that's not needed for heroku publishes. <details> ``` Traceback (most recent call last): File "/usr/local/bin/datasette", line 11, in <module> sys.exit(cli()) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 722, in __call__ return self.main(*args, **kwargs) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 697, in main rv = self.invoke(ctx) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 1066, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 895, in invoke return ctx.invoke(self.callback, **ctx.params) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 535, in invoke return callback(*args, **kwargs) File "/usr/local/lib/python3.6/site-packages/datasette/cli.py", line 265, in publish app_name = json.loads(create_output)["name"] File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/__init__.py", line 354, in loads return _default_decoder.decode(s) File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/decoder.py", line 339, in decode obj, end = self.raw_decode(s, idx=_w(s, 0).end()) File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/decoder.py", line 357, in raw_decode raise JSONDecodeError("Expecting value", s, err.value) from None json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0) ``` </details> | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/344/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 341235633 | MDExOlB1bGxSZXF1ZXN0MjAxNDUxMzMy | 345 | Allow app names for `datasette publish heroku` | 45057 | closed | 0 | 1 | 2018-07-14T13:12:34Z | 2018-07-14T14:09:54Z | 2018-07-14T14:04:44Z | CONTRIBUTOR | simonw/datasette/pulls/345 | Lets you supply the `-n` parameter for Heroku deploys, which also lets you update existing Heroku deployments. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/345/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 341228846 | MDU6SXNzdWUzNDEyMjg4NDY= | 343 | Render boolean fields better by default | 45057 | open | 0 | 1 | 2018-07-14T11:10:29Z | 2018-07-14T14:17:14Z | CONTRIBUTOR | These show up as 0 or 1 because sqlite. I think Yes/No would be fine in most cases? | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/343/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 327459829 | MDU6SXNzdWUzMjc0NTk4Mjk= | 298 | URLify URLs in results from custom SQL statements / views | 9599 | closed | 0 | 2 | 2018-05-29T19:41:07Z | 2018-07-24T04:53:20Z | 2018-07-24T03:56:50Z | OWNER | Consider this custom query: https://fivethirtyeight.datasettes.com/fivethirtyeight-5de27e3?sql=select+user%2C+%28%27https%3A%2F%2Ftwitter.com%2F%27+%7C%7C+user%29+as+user_url%2C+created_at%2C+text%2C+url+from+%5Btwitter-ratio%2Fsenators%5D+limit+10%3B ```select user, ('https://twitter.com/' || user) as user_url, created_at, text, url from [twitter-ratio/senators] limit 10;```  It would be nice if these URLs were turned into links, as happens on the table view page: https://fivethirtyeight.datasettes.com/fivethirtyeight-5de27e3/twitter-ratio%2Fsenators  This currently does not happen because the table view render logic takes a different path through `display_columns_and_rows()` which includes this bit: https://github.com/simonw/datasette/blob/b0a95da96386ddf99816911e08df86178ffa9a89/datasette/views/table.py#L195-L202 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/298/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 334169932 | MDU6SXNzdWUzMzQxNjk5MzI= | 320 | Need unit tests covering the different states for the advanced export box | 9599 | closed | 0 | 1 | 2018-06-20T17:03:40Z | 2018-07-24T04:53:20Z | 2018-07-24T03:38:40Z | OWNER | There are quite a few variants of this box:  Test coverage should exercise all of them, since the logic is a little unclear. https://github.com/simonw/datasette/blob/fdfbbbb9ee0d02fd4d43dfc42382252fa2287d6d/datasette/templates/table.html#L140-L159 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/320/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 336924199 | MDU6SXNzdWUzMzY5MjQxOTk= | 330 | Limit text display in cells containing large amounts of text | 82988 | closed | 0 | 4 | 2018-06-29T09:15:22Z | 2018-07-24T04:53:20Z | 2018-07-10T16:20:48Z | CONTRIBUTOR | The default preview of a database shows all columns (is the row count limited?) which is fine in many cases but can take a long time to load / offer a large overhead if the table is a SpatiaLite table containing geometry columns that include large shapefiles. Would it make sense to have a setting that can limit the amount of text displayed in any given cell in the table preview, or (less useful?) suppress (with notification) the display of overlong columns unless enabled by the user? An issue then arises if a user does want to see all the text in a cell: 1) for a particular cell; 2) for every cell in the table; 3) for all cells in a particular column or columns (I haven't checked but what if a column contains e.g. raw image data? Does this display as raw data? Or can this be rendered in a context aware way as an image preview? I guess a custom template would be one way to do that?) | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/330/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 337141108 | MDU6SXNzdWUzMzcxNDExMDg= | 332 | Sanely handle Infinity/-Infinity values in JSON using ?_json_infinity=1 | 9599 | closed | 0 | 12 | 2018-06-29T21:21:27Z | 2018-07-24T04:53:20Z | 2018-07-24T03:08:30Z | OWNER | It turns out if you load this CSV using `csvs-to-sqlite` you get an Infinity value in SQLite: ``` name,num sasha,10 terry,Inf cathy,0.5 ``` `csvs-to-sqlite infinity-bug.csv infinity-bug.db` I deployed this using: ``` datasette publish now infinity-bug.db --name=datasette-infinity-bug --install=datasette-vega ``` Datasette outputs that as `Infinity` in the JSON format, which causes JavaScript errors. Demo * https://datasette-infinity-bug.now.sh/infinity-bug-0d0224e/infinity-bug - HTML view works * https://datasette-infinity-bug.now.sh/infinity-bug-0d0224e/infinity-bug.json?_shape=array - this outputs the following: ``` [ { "rowid": 1, "name": "sasha", "num": 10.0 }, { "rowid": 2, "name": "terry", "num": Infinity }, { "rowid": 3, "name": "cathy", "num": 0.5 } ] ``` But... in Firefox that gets rendered like this:  And if you click the "Show charting options" button you get this error in the console: ``` SyntaxError: JSON.parse: unexpected character at line 1 column 83 of the JSON data ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/332/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 338768551 | MDU6SXNzdWUzMzg3Njg1NTE= | 333 | Datasette on Zeit Now returns http URLs for facet and next links | 9599 | closed | 0 | 4 | 2018-07-06T00:40:49Z | 2018-07-24T04:53:20Z | 2018-07-24T01:51:53Z | OWNER | e.g. on https://fivethirtyeight.datasettes.com/fivethirtyeight-ac35616/nba-elo%2Fnbaallelo.json?_facet=lg_id&_size=0 ``` { "facet_results": { "lg_id": { "name": "lg_id", "results": [ { "value": "NBA", "label": "NBA", "count": 118016, "toggle_url": "http://fivethirtyeight.datasettes.com/fivethirtyeight-ac35616/nba-elo%2Fnbaallelo.json?_facet=lg_id&_size=1&lg_id=NBA", "selected": false }, { "value": "ABA", "label": "ABA", "count": 8298, "toggle_url": "http://fivethirtyeight.datasettes.com/fivethirtyeight-ac35616/nba-elo%2Fnbaallelo.json?_facet=lg_id&_size=1&lg_id=ABA", "selected": false } ], "truncated": false } }, "suggested_facets": [ { "name": "_iscopy", "toggle_url": "/fivethirtyeight-ac35616/nba-elo%2Fnbaallelo.json?_facet=lg_id&_size=1&_facet=_iscopy" } ], "next_url": "http://fivethirtyeight.datasettes.com/fivethirtyeight-ac35616/nba-elo%2Fnbaallelo.json?_facet=lg_id&_size=1&_next=1", } ``` `next_url` and `facet_results` both link to `http://` when they should link to `https://`. Note that suggested facets doesn't include the full URL at all, which is a consistency bug. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/333/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 339095976 | MDU6SXNzdWUzMzkwOTU5NzY= | 334 | extra_options not passed to heroku publisher | 719357 | closed | 0 | 2 | 2018-07-06T23:26:12Z | 2018-07-24T04:53:21Z | 2018-07-10T01:46:04Z | NONE | I might be wrong but I was not able to publish to `heroku` with `--extra-options`, I think `extra_options` is not being used in this function [here](https://github.com/simonw/datasette/blob/master/datasette/utils.py#L369). Any help appreciated! | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/334/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 341123355 | MDU6SXNzdWUzNDExMjMzNTU= | 342 | Requesting support for query description | 12617395 | closed | 0 | 4 | 2018-07-13T18:50:16Z | 2018-07-24T04:53:21Z | 2018-07-16T02:33:54Z | NONE | It would be great if the metadata file allowed you to enter a description for the query. We have a lot of pre-defined queries that can only be so descriptive by their name. It would be nice if an optional description could be included underneath the name within the UI, or on hover where it currently shows the SQL. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/342/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 340039409 | MDU6SXNzdWUzNDAwMzk0MDk= | 336 | Ensure --help examples in docs are always up to date | 9599 | closed | 0 | 3 | 2018-07-10T23:20:01Z | 2018-07-24T16:01:29Z | 2018-07-24T16:01:29Z | OWNER | Ideally I would automatically generate the --help output shown in our docs, but I don't think I can get that working with readthedocs. Instead, I'm going to add a unit test that checks that those extracts in the documentation match the current output of the --help command. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/336/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 344654623 | MDU6SXNzdWUzNDQ2NTQ2MjM= | 347 | Rename "datasette package" to "datasette publish docker" | 9599 | open | 0 | 0 | 2018-07-26T00:42:46Z | 2018-07-26T00:42:46Z | OWNER | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/347/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||||
| 344695978 | MDExOlB1bGxSZXF1ZXN0MjA0MDI5MTQy | 349 | publish_subcommand hook + default plugins mechanism, used for publish heroku/now | 9599 | closed | 0 | 1 | 2018-07-26T05:03:22Z | 2018-07-26T05:28:54Z | 2018-07-26T05:16:00Z | OWNER | simonw/datasette/pulls/349 | This change introduces a new plugin hook, publish_subcommand, which can be used to implement new subcommands for the "datasette publish" command family. I've used this new hook to refactor out the "publish now" and "publish heroku" implementations into separate modules. I've also added unit tests for these two publishers, mocking the subprocess.call and subprocess.check_output functions. As part of this, I introduced a mechanism for loading default plugins. These are defined in the new "default_plugins" list inside datasette/app.py Closes #217 (Plugin support for "datasette publish") Closes #348 (Unit tests for "datasette publish") Refs #14, #59, #102, #103, #146, #236, #347 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/349/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 314725342 | MDU6SXNzdWUzMTQ3MjUzNDI= | 217 | Plugin support for datasette publish | 9599 | closed | 0 | 1 | 2018-04-16T16:17:14Z | 2018-07-26T05:33:39Z | 2018-07-26T05:16:00Z | OWNER | It should be possible to support additional deployment options by writing a plugin (see #59). As part of this, rewrite the Heroku and Now publishers to be implemented as plugins (they will still ship with datasette by default). Maybe `datasette package` should be changed to being part of publish instead, `datasette publish docker` perhaps? Refs #14 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/217/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 344656114 | MDU6SXNzdWUzNDQ2NTYxMTQ= | 348 | Unit tests for "datasette publish" | 9599 | closed | 0 | 1 | 2018-07-26T00:52:23Z | 2018-07-26T05:46:10Z | 2018-07-26T05:46:10Z | OWNER | The datasette publish family of commands all work by shelling out to heroku/now/docker from subprocess import call, check_output So in tests I should be able to mock those calls: @mock.patch('subprocess.call') | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/348/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 327461381 | MDU6SXNzdWUzMjc0NjEzODE= | 299 | Documentation covering ALL datasette URLs | 9599 | closed | 0 | 1 | 2018-05-29T19:46:15Z | 2018-07-28T04:24:05Z | 2018-07-28T04:22:30Z | OWNER | Relates to #296. We need a single page of the docs listing all of the URL patterns Datasette responds to, also detailing which templates are used to render them and linking to examples of the JSON they output when called with `.json`. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/299/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 343728754 | MDU6SXNzdWUzNDM3Mjg3NTQ= | 346 | Logo design for DATASETTE | 35750428 | closed | 0 | 0 | 2018-07-23T17:40:17Z | 2018-08-02T02:31:59Z | 2018-08-02T02:31:59Z | NONE | Hello :) , I'm a graphic designer, I'm interested in collaborating with open source projects, besides this helps me expand my portfolio. I would like to design a logo for your project. I will be happy to collaborate with you :). | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/346/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 347058326 | MDExOlB1bGxSZXF1ZXN0MjA1NzcwOTk2 | 1 | Make .indexes compatible with older SQLite versions | 9599 | closed | 0 | 0 | 2018-08-02T15:17:05Z | 2018-08-02T15:17:30Z | 2018-08-02T15:17:30Z | OWNER | simonw/sqlite-utils/pulls/1 | Older SQLite versions return a different set of columns from the PRAGMA we are using. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/1/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 345821778 | MDExOlB1bGxSZXF1ZXN0MjA0ODUxNTEx | 353 | render_cell(value) plugin hook | 9599 | closed | 0 | 0 | 2018-07-30T15:57:08Z | 2018-08-05T00:14:57Z | 2018-08-05T00:14:57Z | OWNER | simonw/datasette/pulls/353 | Closes #352. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/353/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 348534997 | MDExOlB1bGxSZXF1ZXN0MjA2ODYzODAz | 358 | Bump versions of pytest, pluggy and beautifulsoup4 | 9599 | closed | 0 | 0 | 2018-08-08T00:44:38Z | 2018-08-08T01:11:13Z | 2018-08-08T01:11:13Z | OWNER | simonw/datasette/pulls/358 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/358/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 281197863 | MDU6SXNzdWUyODExOTc4NjM= | 174 | License/Source in footer should inherit from top level | 9599 | closed | 0 | 1 | 2017-12-11T23:01:35Z | 2018-08-11T17:46:51Z | 2018-08-11T17:46:51Z | OWNER | The footer on https://vice-police-shootings.now.sh/vice-bc7c892/ViceNews_FullOISData does not show license and source information... but that Datasette has that information, it's just defined at the top level: https://vice-police-shootings.now.sh/ The footer for a row/table page should fall back on information for the database, and if there is none for the database it should fall back on the top-level metadata instead. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/174/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 351017365 | MDExOlB1bGxSZXF1ZXN0MjA4NzE5MDQz | 361 | Import pysqlite3 if available, closes #360 | 9599 | closed | 0 | 0 | 2018-08-16T00:52:21Z | 2018-08-16T00:58:57Z | 2018-08-16T00:58:57Z | OWNER | simonw/datasette/pulls/361 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/361/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 351017129 | MDU6SXNzdWUzNTEwMTcxMjk= | 360 | Use pysqlite3 if available | 9599 | closed | 0 | 3 | 2018-08-16T00:50:45Z | 2018-08-16T01:50:42Z | 2018-08-16T00:58:58Z | OWNER | [pysqlite3](https://github.com/coleifer/pysqlite3) is a way to provide access to a more recent version of SQLite than the standard library `sqlite3` module (which tends to use the version provided with the operating system - which on e.g. the Travis CI Ubuntu build environment can be as old as 3.8.0). | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/360/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 344701755 | MDU6SXNzdWUzNDQ3MDE3NTU= | 350 | Don't list default plugins on /-/plugins | 9599 | closed | 0 | 2 | 2018-07-26T05:38:00Z | 2018-08-28T17:13:50Z | 2018-08-28T16:48:19Z | OWNER | https://dbbe707.datasette.io/-/plugins is showing "datasette.publish.now" and "datasette.publish.heroku" | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/350/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 355299310 | MDExOlB1bGxSZXF1ZXN0MjExODYwNzA2 | 363 | Search all apps during heroku publish | 436032 | open | 0 | 1 | 2018-08-29T19:25:10Z | 2018-08-31T14:39:45Z | FIRST_TIME_CONTRIBUTOR | simonw/datasette/pulls/363 | Adds the `-A` option to include apps from all organizations when searching app names for publish. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/363/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 359075028 | MDExOlB1bGxSZXF1ZXN0MjE0NjUzNjQx | 364 | Support for other types of databases using external connectors | 11912854 | open | 0 | 0 | 2018-09-11T14:31:47Z | 2018-09-11T14:31:47Z | FIRST_TIME_CONTRIBUTOR | simonw/datasette/pulls/364 | This PR is related to #293, but now all commits have been merged. The purpose is to support other file formats that aren't SQLite, like files with PyTables format. I've tried to accomplish that using external connectors published with entry points. The modifications in the original datasette code are minimal and many are in a separated file. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/364/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 326987229 | MDExOlB1bGxSZXF1ZXN0MTkwOTAxNDI5 | 293 | Support for external database connectors | 11912854 | closed | 0 | 1 | 2018-05-28T11:02:45Z | 2018-09-11T14:32:45Z | 2018-09-11T14:32:45Z | FIRST_TIME_CONTRIBUTOR | simonw/datasette/pulls/293 | I think it would be nice that Datasette could work with other file formats that aren't SQLite, like files with PyTables format. I've tried to accomplish that using external connectors published with entry points. These external connectors must have a structure similar to the structure [PyTables Datasette connector](https://github.com/PyTables/datasette-pytables) has. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/293/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 330826972 | MDU6SXNzdWUzMzA4MjY5NzI= | 308 | Support extra Heroku apps:create options - region, space, team | 78156 | open | 0 | 2 | 2018-06-08T23:08:33Z | 2018-09-21T14:09:28Z | NONE | It would be useful to document how to pass Heroku CLI options on `datasette publish`, e.g. `--region eu`. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/308/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 377166793 | MDU6SXNzdWUzNzcxNjY3OTM= | 372 | Docker build tools | 82988 | open | 0 | 0 | 2018-11-04T16:02:35Z | 2018-11-04T16:02:35Z | CONTRIBUTOR | In terms of small pieces lightly joined, I note that there are several tools starting to appear for building generating Dockerfiles and building Docker containers from simpler components such as `requirements.txt` files. If plugin/extensions builders want to include additional packages, then things like incremental builds of composable builds that add additional items into a base `datasette` container may be required. Examples of Dockerfile generators / container builders: - [openshift/source-to-image (s2i)](https://github.com/openshift/source-to-image) - [jupyter/repo2docker](https://github.com/jupyter/repo2docker) - [stencila/dockter](https://github.com/stencila/dockter) Discussions / threads (via Binderhub gitter) on: - [why `repo2docker` not `s2i`](http://words.yuvi.in/post/why-not-s2i/) - [why `dockter` not `repo2docker`](https://twitter.com/choldgraf/status/1058499607309647872) - [composability in `s2i`](https://trello.com/c/AexIVZNf/1008-8-composable-builds-builds-evg) Relates to things like: - https://github.com/simonw/datasette/pull/280 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/372/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} |
||||||||
| 369716228 | MDU6SXNzdWUzNjk3MTYyMjg= | 366 | Default built image size over Zeit Now 100MiB limit | 416374 | closed | 0 | 2 | 2018-10-12T21:27:17Z | 2018-11-05T06:23:32Z | 2018-11-05T06:23:32Z | CONTRIBUTOR | Using `dataset publish now` with no other custom options on a small (43KB) sqlite database leads to the error "The built image size (373.5M) exceeds the 100MiB limit". I think this is because of a recent Zeit change: https://github.com/zeit/now-cli/issues/1523 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/366/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 336465018 | MDU6SXNzdWUzMzY0NjUwMTg= | 329 | Travis should push tagged images to Docker Hub for each release | 9599 | closed | 0 | 7 | 2018-06-28T04:01:31Z | 2018-11-05T06:54:10Z | 2018-11-05T06:53:28Z | OWNER | https://sebest.github.io/post/using-travis-ci-to-build-docker-images/ | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/329/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 377518499 | MDU6SXNzdWUzNzc1MTg0OTk= | 374 | Get Datasette working with Zeit Now v2's 100MB image size limit | 9599 | closed | 0 | 5 | 2018-11-05T18:08:29Z | 2018-12-19T01:35:59Z | 2018-12-19T01:35:59Z | OWNER | Follow-on from #366 Zeit Now's v2 cloud has a 100MB size limit on Docker images, in order to support much faster wake-ups of new instances. Fitting Datasette AND the SQLite database it is hosting in here is going to be a challenge. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/374/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 394751072 | MDExOlB1bGxSZXF1ZXN0MjQxNDE4NDQz | 392 | Fix some regex DeprecationWarnings | 9599 | closed | 0 | 0 | 2018-12-29T02:10:28Z | 2018-12-29T02:22:28Z | 2018-12-29T02:22:28Z | OWNER | simonw/datasette/pulls/392 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/392/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 392610803 | MDU6SXNzdWUzOTI2MTA4MDM= | 391 | Google Trends example doesn’t work | 229881 | closed | 0 | 1 | 2018-12-19T13:51:38Z | 2019-01-02T19:45:13Z | 2019-01-02T19:45:12Z | NONE | https://google-trends.datasettes.com/ I see a cloud flare error. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/391/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 324162476 | MDU6SXNzdWUzMjQxNjI0NzY= | 271 | Mechanism for automatically picking up changes when on-disk .db file changes | 9599 | closed | 0 | 4 | 2018-05-17T19:53:15Z | 2019-01-10T21:35:18Z | 2019-01-10T21:35:18Z | OWNER | It would be useful if Datasette could spot when a SQLite database file changes on disk and restart itself (hence re-running .inspect() and picking up the new content hash). Ideally this could happen in an atomic way so no requests get dropped during the switch-over. This may not play well with SQLite opening databases in immutable mode. Research required. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/271/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 397098882 | MDU6SXNzdWUzOTcwOTg4ODI= | 396 | Add pragma compile_options output to /-/versions | 9599 | closed | 0 | 1 | 2019-01-08T21:43:54Z | 2019-01-11T00:55:22Z | 2019-01-11T00:44:56Z | OWNER | ``` sqlite> pragma compile_options ...> ; BUG_COMPATIBLE_20160819 COMPILER=clang-9.0.0 DEFAULT_CACHE_SIZE=2000 DEFAULT_CKPTFULLFSYNC DEFAULT_JOURNAL_SIZE_LIMIT=32768 DEFAULT_PAGE_SIZE=4096 DEFAULT_SYNCHRONOUS=2 DEFAULT_WAL_SYNCHRONOUS=1 ENABLE_API_ARMOR ENABLE_COLUMN_METADATA ENABLE_DBSTAT_VTAB ENABLE_FTS3 ENABLE_FTS3_PARENTHESIS ENABLE_FTS3_TOKENIZER ENABLE_FTS4 ENABLE_FTS5 ENABLE_JSON1 ENABLE_LOCKING_STYLE=1 ENABLE_PREUPDATE_HOOK ENABLE_RTREE ENABLE_SESSION ENABLE_SNAPSHOT ENABLE_SQLLOG ENABLE_UNKNOWN_SQL_FUNCTION ENABLE_UPDATE_DELETE_LIMIT HAVE_ISNAN MAX_LENGTH=2147483645 MAX_MMAP_SIZE=1073741824 MAX_VARIABLE_NUMBER=500000 OMIT_AUTORESET OMIT_LOAD_EXTENSION STMTJRNL_SPILL=131072 THREADSAFE=2 USE_URI sqlite> ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/396/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 397129564 | MDU6SXNzdWUzOTcxMjk1NjQ= | 397 | Update official datasetteproject/datasette Docker container to SQLite 3.26.0 | 43564 | closed | 0 | 3 | 2019-01-08T22:51:50Z | 2019-01-11T01:25:33Z | 2019-01-11T00:56:18Z | NONE | I try to start datasette on a database that contains the below view It fails in a way that makes me think it does not support the window functions SQL syntax. ``` create view general_ledger as select transactions.account_number, strftime("%Y-%m-%d", verifications.verification_date) as verification_date, verifications.verification_number, verifications.verification_text, case when transactions.centi_amount >= 0 and verifications.verification_number > 0 then printf("%.2f", (transactions.centi_amount/100.0)) end as debit, case when transactions.centi_amount <= 0 and verifications.verification_number > 0 then printf("%.2f", (transactions.centi_amount/100.0)) end as credit, printf("%.2f", sum(transactions.centi_amount) over (partition by transactions.account_number order by verifications.verification_number range between unbounded preceding and current row)/100.0) from verifications inner join transactions on transactions.verification_id = verifications.id order by transactions.account_number, verifications.verification_number; ``` ``` docker run -p 8001:8001 -v `pwd`:/mnt datasetteproject/datasette datasette -p 8001 -h 0.0.0.0 /mnt/ledger.db Serve! files=('/mnt/ledger.db',) on port 8001 Traceback (most recent call last): File "/usr/local/bin/datasette", line 11, in <module> sys.exit(cli()) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 722, in __call__ return self.main(*args, **kwargs) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 697, in main rv = self.invoke(ctx) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 1066, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 895, in invoke return ctx.invoke(self.callback, **ctx.params) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 535, in invoke return callback(*args, **kwargs) File "/usr/local/lib/python3.6/site-packages/datase… | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/397/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 398089089 | MDU6SXNzdWUzOTgwODkwODk= | 399 | /-/versions for official Docker image returns wrong Datasette version | 9599 | closed | 0 | 2 | 2019-01-11T01:19:58Z | 2019-01-13T23:31:59Z | 2019-01-13T23:10:45Z | OWNER | ``` docker run -p 8001:8001 datasetteproject/datasette datasette -p 8001 -h 0.0.0.0 ``` http://0.0.0.0:8001/-/versions returns this: ``` { "datasette": { "version": "0+unknown" }, ... ``` This is because the Docker image is built by copying in the Datasette source code, which confuses versioneer. Maybe the Docker image should install the code using a wheel or similar? | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/399/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 400340905 | MDU6SXNzdWU0MDAzNDA5MDU= | 402 | Use SQLITE_DBCONFIG_DEFENSIVE plus other recommendations from SQLite security docs | 9599 | open | 0 | 3 | 2019-01-17T15:52:28Z | 2019-01-17T16:15:21Z | OWNER | > Was just having a skim through the datasette source. Given that the vuln impacts shadow tables, wasn't sure whether these are also covered by the immutable flag. Latest release introduced a SQLITE_DBCONFIG_DEFENSIVE flag that they recommend setting: https://sqlite.org/security.html https://twitter.com/ignoredambience/status/1085926961413869568 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/402/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 400229984 | MDU6SXNzdWU0MDAyMjk5ODQ= | 401 | How to pass configuration to plugins? | 1055831 | closed | 0 | 3 | 2019-01-17T11:20:41Z | 2019-01-18T11:48:13Z | 2019-01-18T06:49:07Z | NONE | Hi, Firstly, thanks for your work on datasette, it is a hugely useful tool! I've been working on a fork [https://github.com/dazzag24/datasette-cluster-map] of datasette-cluster-map to allow the tileserver to be easily switched. Primarily because the tiles being served in the current version use localised text for labels and I'd like to have English used for these names instead. It uses http://leaflet-extras.github.io/leaflet-providers/preview/ to allow you to simply set the tile provider using a call like so: ``` let tiles = L.tileLayer.provider('Esri.WorldTopoMap'); ``` instead of the current: ``` let tiles = L.tileLayer('https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png', { maxZoom: 19, detectRetina: true, attribution: '© <a href="https://www.openstreetmap.org/copyright">OpenStreetMap</a> contributors' }), ``` However I've got stuck in trying to work out how to pass the provider string to the plugin. In the documentation: https://datasette.readthedocs.io/en/stable/plugins.html you discuss configuration of plugins and use an example of passing in which latitude and longitude columns should be used. However I cannot seem to see anywhere in the current datasette-cluster-map code where these config params are passed in or used. Can you please point me to an example or how to pass configuration from the metadata.json down into a plugin. Once I've over come this issue I was wondering if you would be interested in taking this change into your version? Many thanks Darren | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/401/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 400511206 | MDU6SXNzdWU0MDA1MTEyMDY= | 403 | How does persistence work? | 1794527 | closed | 0 | 2 | 2019-01-17T23:41:57Z | 2019-01-19T05:47:55Z | 2019-01-18T06:51:14Z | NONE | I was under the impression that now.sh is for stateless microservices. So where are these SQLite databases stored and when do they get created and destroyed? | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/403/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 403028630 | MDExOlB1bGxSZXF1ZXN0MjQ3NTc2OTQy | 4 | Fts5 | 9599 | closed | 0 | 0 | 2019-01-25T06:54:05Z | 2019-01-25T06:54:33Z | 2019-01-25T06:54:33Z | OWNER | simonw/sqlite-utils/pulls/4 | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/4/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 403396009 | MDExOlB1bGxSZXF1ZXN0MjQ3ODYxNDE5 | 5 | Run Travis tests against Python 3.8-dev | 9599 | closed | 0 | 0 | 2019-01-26T02:30:55Z | 2019-01-26T02:37:54Z | 2019-01-26T02:37:54Z | OWNER | simonw/sqlite-utils/pulls/5 | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/5/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 403617881 | MDU6SXNzdWU0MDM2MTc4ODE= | 405 | .json?_nl=on option for exporting newline-delimited JSON | 9599 | closed | 0 | 2 | 2019-01-28T01:10:45Z | 2019-01-28T01:49:00Z | 2019-01-28T01:48:37Z | OWNER | The neat thing about newline-delimited JSON is that you don't have to read an entire array (of potentially thousands of objects) into memory in order to parse it - you can parse things a line at a time instead. It will look like this: `https://latest.datasette.io/fixtures/facetable.json?_shape=array&_nl=on` ``` {"pk": 1, "planet_int": 1, "on_earth": 1, "state": "CA", "city_id": 1, "neighborhood": "Mission"} {"pk": 2, "planet_int": 1, "on_earth": 1, "state": "CA", "city_id": 1, "neighborhood": "Dogpatch"} {"pk": 3, "planet_int": 1, "on_earth": 1, "state": "CA", "city_id": 1, "neighborhood": "SOMA"} {"pk": 4, "planet_int": 1, "on_earth": 1, "state": "CA", "city_id": 1, "neighborhood": "Tenderloin"} {"pk": 5, "planet_int": 1, "on_earth": 1, "state": "CA", "city_id": 1, "neighborhood": "Bernal Heights"} ``` I added this as part of the `sqlite-utils json` CLI command is this commit - I think Datasette should offer it as well: https://github.com/simonw/sqlite-utils/commit/5466c9745dfef858286146ea158ffd5a71391d10 It can be offered alongside `_stream=on` (which currently only works for CSV, but it could work for JSON as well thanks to this trick). | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/405/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 403624090 | MDU6SXNzdWU0MDM2MjQwOTA= | 6 | "sqlite-utils insert" should support newline-delimited JSON | 9599 | closed | 0 | 1 | 2019-01-28T02:00:02Z | 2019-01-28T02:17:45Z | 2019-01-28T02:17:45Z | OWNER | We can already export newline delimited JSON. We should learn to import it as well. The neat thing about importing it is that you can import GBs of data without having to read the whole lot into memory in order to decode the wrapping JSON array. Datasette can export it now: https://github.com/simonw/datasette/issues/405 Demo: https://latest.datasette.io/fixtures/facetable.json?_shape=array&_nl=on It should be possible to do this: $ curl "https://latest.datasette.io/fixtures/facetable.json?_shape=array&_nl=on" \ | sqlite-utils insert data.db facetable - --nl | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/6/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 403625674 | MDU6SXNzdWU0MDM2MjU2NzQ= | 7 | .insert_all() should accept a generator and process it efficiently | 9599 | closed | 0 | 3 | 2019-01-28T02:11:58Z | 2019-01-28T06:26:53Z | 2019-01-28T06:26:53Z | OWNER | Right now you have to load every record into memory before passing the list to `.insert_all()` and friends. If you want to process millions of rows, this is inefficient. Python has generators - we should use them! The only catch here is that part of the magic of `sqlite-utils` is that it guesses the column types and creates the table for you. This code will need to be updated to notice if the table needs creating and, if it does, create it using the first X (where x=1,000 but can be customized) records. If a record outside of those first 1,000 has a rogue column, we can crash with an error. This will free us up to make the `--nl` option added in #6 much more efficient. | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/7/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 278208011 | MDU6SXNzdWUyNzgyMDgwMTE= | 160 | Ability to bundle and serve additional static files | 9599 | closed | 0 | 2949431 | 8 | 2017-11-30T17:37:51Z | 2019-02-02T00:58:20Z | 2017-12-09T18:29:11Z | OWNER | Since we now have custom templates, we should support including custom static files with them as well. Maybe something like this: datasette mydb.db --template-dir=templates/ --static-dir=static/ This should also be supported by datasette publish - see also #157 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/160/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 407073223 | MDExOlB1bGxSZXF1ZXN0MjUwNjI4Mjc1 | 407 | Heroku --include-vcs-ignore | 9599 | closed | 0 | 1 | 2019-02-06T04:06:20Z | 2019-02-06T04:31:30Z | 2019-02-06T04:15:47Z | OWNER | simonw/datasette/pulls/407 | Should mean `datasette publish heroku` can work under Travis, unlike this failure: https://travis-ci.org/simonw/fivethirtyeight-datasette/builds/488047550 ``` 2.25s$ datasette publish heroku fivethirtyeight.db -m metadata.json -n fivethirtyeight-datasette tar: unrecognized option '--exclude-vcs-ignores' Try 'tar --help' or 'tar --usage' for more information. ▸ Command failed: tar cz -C /tmp/tmpuaxm7i8f --exclude-vcs-ignores --exclude ▸ .git --exclude .gitmodules . > ▸ /tmp/f49440e0-1bf3-4d3f-9eb0-fbc2967d1fd4.tar.gz ▸ tar: unrecognized option '--exclude-vcs-ignores' ▸ Try 'tar --help' or 'tar --usage' for more information. ▸ The command "datasette publish heroku fivethirtyeight.db -m metadata.json -n fivethirtyeight-datasette" exited with 0. ``` The fix for that issue is to call the heroku command like this: heroku builds:create -a app_name --include-vcs-ignore | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/407/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 280896290 | MDU6SXNzdWUyODA4OTYyOTA= | 172 | Show size of .db file next to download link | 9599 | closed | 0 | 1 | 2017-12-11T05:12:46Z | 2019-02-06T05:09:06Z | 2019-02-06T05:00:36Z | OWNER | Size in bytes should be calculated by datasette inspect. Template should display it in KB or MB or GB | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/172/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 405801771 | MDExOlB1bGxSZXF1ZXN0MjQ5NjgwOTQ0 | 9 | :pencil: Updates my_database.py to my_database.db | 50527 | closed | 0 | 0 | 2019-02-01T17:35:43Z | 2019-02-24T03:55:04Z | 2019-02-24T03:55:04Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/9 | I noticed that both `.py` and `.db` were used in the docs and assumed you'd prefer `.db`. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/9/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 413740684 | MDU6SXNzdWU0MTM3NDA2ODQ= | 11 | Detect numpy types when creating tables | 9599 | closed | 0 | 2 | 2019-02-23T21:09:35Z | 2019-02-24T04:02:20Z | 2019-02-24T04:02:20Z | OWNER | Inspired by #8 | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/11/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 413778585 | MDExOlB1bGxSZXF1ZXN0MjU1NjU4MTEy | 12 | Support for numpy types, closes #11 | 9599 | closed | 0 | 0 | 2019-02-24T03:57:32Z | 2019-02-24T04:02:20Z | 2019-02-24T04:02:20Z | OWNER | simonw/sqlite-utils/pulls/12 | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/12/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 413779210 | MDU6SXNzdWU0MTM3NzkyMTA= | 13 | Ability to automatically create IDs from content hash of row | 9599 | closed | 0 | 1 | 2019-02-24T04:07:08Z | 2019-02-24T04:36:48Z | 2019-02-24T04:36:48Z | OWNER | Sometimes when you are importing data the underlying source provides records without IDs that can be uniquely identified by their contents. A utility mechanism for calculating a sha1 hash of the contents and using that as a unique ID would be useful. | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/13/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 411066700 | MDU6SXNzdWU0MTEwNjY3MDA= | 10 | Error in upsert if column named 'order' | 82988 | closed | 0 | 1 | 2019-02-16T12:05:18Z | 2019-02-24T16:55:38Z | 2019-02-24T16:55:37Z | NONE | The following works fine: ``` connX = sqlite3.connect('DELME.db', timeout=10) dfX=pd.DataFrame({'col1':range(3),'col2':range(3)}) DBX = Database(connX) DBX['test'].upsert_all(dfX.to_dict(orient='records')) ``` But if a column is named `order`: ``` connX = sqlite3.connect('DELME.db', timeout=10) dfX=pd.DataFrame({'order':range(3),'col2':range(3)}) DBX = Database(connX) DBX['test'].upsert_all(dfX.to_dict(orient='records')) ``` it throws an error: ``` --------------------------------------------------------------------------- OperationalError Traceback (most recent call last) <ipython-input-130-7dba33cd806c> in <module> 3 dfX=pd.DataFrame({'order':range(3),'col2':range(3)}) 4 DBX = Database(connX) ----> 5 DBX['test'].upsert_all(dfX.to_dict(orient='records')) /usr/local/lib/python3.7/site-packages/sqlite_utils/db.py in upsert_all(self, records, pk, foreign_keys, column_order) 347 foreign_keys=foreign_keys, 348 upsert=True, --> 349 column_order=column_order, 350 ) 351 /usr/local/lib/python3.7/site-packages/sqlite_utils/db.py in insert_all(self, records, pk, foreign_keys, upsert, batch_size, column_order) 327 jsonify_if_needed(record.get(key, None)) for key in all_columns 328 ) --> 329 result = self.db.conn.execute(sql, values) 330 self.db.conn.commit() 331 self.last_id = result.lastrowid OperationalError: near "order": syntax error ``` | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/10/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 413842611 | MDU6SXNzdWU0MTM4NDI2MTE= | 14 | Utilities for adding indexes | 9599 | closed | 0 | 3 | 2019-02-24T16:57:28Z | 2019-02-24T19:11:28Z | 2019-02-24T19:11:28Z | OWNER | Both in the Python API and the CLI tool. For the CLI tool this should work: $ sqlite-utils create-index mydb.db mytable col1 col2 This will create a compound index across col1 and col2. The name of the index will be automatically chosen unless you use the `--name=...` option. Support a `--unique` option too. | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/14/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed |