github
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at | closed_at | author_association | pull_request | body | repo | type | active_lock_reason | performed_via_github_app | reactions | draft | state_reason |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 519979091 | MDExOlB1bGxSZXF1ZXN0MzM4NjQ3Mzc4 | 1 | Add parkrun-to-sqlite | 1101318 | closed | 0 | 0 | 2019-11-08T12:05:32Z | 2020-10-12T00:35:16Z | 2020-10-12T00:35:16Z | CONTRIBUTOR | dogsheep/dogsheep.github.io/pulls/1 | 214746582 | pull | {
"url": "https://api.github.com/repos/dogsheep/dogsheep.github.io/issues/1/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 543717994 | MDExOlB1bGxSZXF1ZXN0MzU3OTc0MzI2 | 3 | Add todoist-to-sqlite | 706257 | closed | 0 | 0 | 2019-12-30T04:02:59Z | 2020-10-12T00:35:58Z | 2020-10-12T00:35:57Z | CONTRIBUTOR | dogsheep/dogsheep.github.io/pulls/3 | Really enjoying getting into the dogsheep/datasette ecosystem. I made a downloader for Todoist, and I think/hope others might find this useful | 214746582 | pull | {
"url": "https://api.github.com/repos/dogsheep/dogsheep.github.io/issues/3/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 558715564 | MDExOlB1bGxSZXF1ZXN0MzcwMDI0Njk3 | 4 | Add beeminder-to-sqlite | 706257 | closed | 0 | 0 | 2020-02-02T15:51:36Z | 2020-10-12T00:36:16Z | 2020-10-12T00:36:16Z | CONTRIBUTOR | dogsheep/dogsheep.github.io/pulls/4 | 214746582 | pull | {
"url": "https://api.github.com/repos/dogsheep/dogsheep.github.io/issues/4/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 543355051 | MDExOlB1bGxSZXF1ZXN0MzU3NjQwMTg2 | 6 | don't break if source is missing | 78035 | closed | 0 | 1 | 2019-12-29T10:46:47Z | 2020-03-28T02:28:11Z | 2020-03-28T02:28:11Z | CONTRIBUTOR | dogsheep/swarm-to-sqlite/pulls/6 | broke for me. very old checkins in 2010 had no source set. | 205429375 | pull | {
"url": "https://api.github.com/repos/dogsheep/swarm-to-sqlite/issues/6/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 750141615 | MDExOlB1bGxSZXF1ZXN0NTI2ODQ3ODIz | 7 | Fixed conflicting CLI flags | 8944 | closed | 0 | 1 | 2020-11-24T23:25:12Z | 2022-08-21T21:11:56Z | 2022-08-21T21:11:56Z | CONTRIBUTOR | dogsheep/pocket-to-sqlite/pulls/7 | The `-a` used for the auth credentials and the shortened form of the `--all` flags were in conflict on the `fetch` command. To be consistent with other `-to-sqlite` libraries in the Dogsheep ecosystem, I removed the shortened form of the `--all` flag. | 213286752 | pull | {
"url": "https://api.github.com/repos/dogsheep/pocket-to-sqlite/issues/7/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 748370021 | MDExOlB1bGxSZXF1ZXN0NTI1MzcxMDI5 | 8 | fix import error if note has no "updated" element | 4028322 | closed | 0 | 0 | 2020-11-22T22:51:05Z | 2021-02-11T22:34:06Z | 2021-02-11T22:34:06Z | CONTRIBUTOR | dogsheep/evernote-to-sqlite/pulls/8 | I got the following error when executing evernote-to-sqlite enex evernote.db evernote.enex ``` ... File "evernote_to_sqlite/cli.py", line 31, in enex save_note(db, note) File "evernote_to_sqlite/utils.py", line 28, in save_note updated = note.find("updated").text AttributeError: 'NoneType' object has no attribute 'text' ``` Seems that in some cases the updated element is not added to the note, this is a part of the problematic note: ``` <created>20201019T074518Z</created> <note-attributes> <source>web.clip7</source> <source-application>webclipper.evernote</source-application> </note-attributes> ``` | 303218369 | pull | {
"url": "https://api.github.com/repos/dogsheep/evernote-to-sqlite/issues/8/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 405801771 | MDExOlB1bGxSZXF1ZXN0MjQ5NjgwOTQ0 | 9 | :pencil: Updates my_database.py to my_database.db | 50527 | closed | 0 | 0 | 2019-02-01T17:35:43Z | 2019-02-24T03:55:04Z | 2019-02-24T03:55:04Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/9 | I noticed that both `.py` and `.db` were used in the docs and assumed you'd prefer `.db`. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/9/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 748372469 | MDU6SXNzdWU3NDgzNzI0Njk= | 9 | ParseError: undefined entity š | 4028322 | closed | 0 | 1 | 2020-11-22T23:04:35Z | 2021-02-11T22:10:55Z | 2021-02-11T22:10:55Z | CONTRIBUTOR | I encountered a parse error if the enex file contained š or Run command: evernote-to-sqlite enex evernote.db evernote.enex ``` Traceback (most recent call last): ... File "evernote_to_sqlite/cli.py", line 31, in enex save_note(db, note) File "evernote_to_sqlite/utils.py", line 35, in save_note content = ET.tostring(ET.fromstring(content_xml)).decode("utf-8") File "/usr/lib/python3.8/xml/etree/ElementTree.py", line 1320, in XML parser.feed(text) xml.etree.ElementTree.ParseError: undefined entity š: line 3, column 35 ``` Workaround: ``` sed -i 's/š//g' evernote.enex sed -i 's/ //g' evernote.enex ``` | 303218369 | issue | {
"url": "https://api.github.com/repos/dogsheep/evernote-to-sqlite/issues/9/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 719637258 | MDExOlB1bGxSZXF1ZXN0NTAxNzkxNjYz | 10 | Update utils.py to fix sqlite3.OperationalError | 29426418 | closed | 0 | 1 | 2020-10-12T20:17:53Z | 2020-10-12T20:25:10Z | 2020-10-12T20:25:09Z | CONTRIBUTOR | dogsheep/swarm-to-sqlite/pulls/10 | Fixes the errors: - sqlite3.OperationalError: table posts has no column named text - sqlite3.OperationalError: table photos has no column named hasSticker That will cause sqlite-utils to notice if there's a missing column and add it. As recommended by @simonw | 205429375 | pull | {
"url": "https://api.github.com/repos/dogsheep/swarm-to-sqlite/issues/10/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 518725064 | MDU6SXNzdWU1MTg3MjUwNjQ= | 29 | `import` command fails on empty files | 21148 | closed | 0 | 4 | 2019-11-06T20:34:26Z | 2019-11-09T20:33:38Z | 2019-11-09T19:36:36Z | CONTRIBUTOR | If a file in the export is empty (in my case it was `account-suspensions.js`), `twitter-to-sqlite import` fails: ``` $ twitter-to-sqlite import twitter.db ~/Downloads/twitter-2019-11-06-926f4f3be4b3b1fcb1aa387c40cd14f7c8aaf9bbcdb2d78ac14d9989add501bb.zip Traceback (most recent call last): File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/bin/twitter-to-sqlite", line 10, in <module> sys.exit(cli()) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py", line 764, in __call__ return self.main(*args, **kwargs) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py", line 717, in main rv = self.invoke(ctx) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py", line 1137, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py", line 956, in invoke return ctx.invoke(self.callback, **ctx.params) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py", line 555, in invoke return callback(*args, **kwargs) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/cli.py", line 627, in import_ archive.import_from_file(db, filename, content) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/archive.py", line 224, in import_from_file db[table_name].upsert_all(rows, hash_id="pk") File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/sqlite_utils/db.py", line 1113, in upsert_all extracts=extracts, File … | 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/29/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 638375985 | MDExOlB1bGxSZXF1ZXN0NDM0MTYyMzE2 | 29 | Fixed bug in SQL query for photo scores | 41546558 | closed | 0 | 1 | 2020-06-14T15:39:22Z | 2020-12-04T22:32:36Z | 2020-12-04T22:32:27Z | CONTRIBUTOR | dogsheep/dogsheep-photos/pulls/29 | The join on ZCOMPUTEDASSETATTRIBUTES used the wrong columns. In most of the Photos database tables, table.ZASSET joins with ZGENERICASSET.Z_PK | 256834907 | pull | {
"url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/29/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 518739697 | MDU6SXNzdWU1MTg3Mzk2OTc= | 30 | `followers` fails because `transform_user` is called twice | 21148 | closed | 0 | 2 | 2019-11-06T20:44:52Z | 2019-11-09T20:15:28Z | 2019-11-09T19:55:52Z | CONTRIBUTOR | Trying to run `twitter-to-sqlite followers` errors out: ``` Traceback (most recent call last): File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/bin/twitter-to-sqlite", line 10, in <module> sys.exit(cli()) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py", line 764, in __call__ return self.main(*args, **kwargs) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py", line 717, in main rv = self.invoke(ctx) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py", line 1137, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py", line 956, in invoke return ctx.invoke(self.callback, **ctx.params) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/click/core.py", line 555, in invoke return callback(*args, **kwargs) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/cli.py", line 130, in followers go(bar.update) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/cli.py", line 116, in go utils.save_users(db, [profile]) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/utils.py", line 302, in save_users transform_user(user) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jkm-dogsheep-ezLnyXZS-py3.7/lib/python3.7/site-packages/twitter_to_sqlite/utils.py", line 181, in transform_user user["created_at"] = parser.parse(user["created_at"]) File "/Users/jacob/Librar… | 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/30/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 771511344 | MDExOlB1bGxSZXF1ZXN0NTQzMDE1ODI1 | 31 | Update for Big Sur | 41546558 | open | 0 | 7 | 2020-12-20T04:36:45Z | 2023-08-08T15:52:52Z | CONTRIBUTOR | dogsheep/dogsheep-photos/pulls/31 | Refactored out the SQL for extracting aesthetic scores to use osxphotos -- adds compatbility for Big Sur via osxphotos which has been updated for new table names in Big Sur. Have not yet refactored the SQL for extracting labels which is still compatible with Big Sur. | 256834907 | pull | {
"url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/31/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 681228542 | MDExOlB1bGxSZXF1ZXN0NDY5NjUxNzMy | 48 | Add pull requests | 755825 | closed | 0 | 2 | 2020-08-18T17:58:44Z | 2020-11-29T23:51:09Z | 2020-11-29T23:51:09Z | CONTRIBUTOR | dogsheep/github-to-sqlite/pulls/48 | ref #46 Issues don't have merge information on them, which means that PRs need to be pulled separately. Did my best to mimic the API of issues. | 207052882 | pull | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/48/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 681575714 | MDExOlB1bGxSZXF1ZXN0NDY5OTQ0OTk5 | 49 | Document the use of --stop_after with favorites, refs #20 | 370930 | closed | 0 | 1 | 2020-08-19T06:10:52Z | 2021-08-20T00:02:11Z | 2021-08-20T00:02:11Z | CONTRIBUTOR | dogsheep/twitter-to-sqlite/pulls/49 | (I discovered this trawling the issues for how to use --since with favorites) | 206156866 | pull | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/49/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 698791218 | MDU6SXNzdWU2OTg3OTEyMTg= | 50 | favorites --stop_after=N stops after min(N, 200) | 370930 | open | 0 | 2 | 2020-09-11T03:38:14Z | 2020-09-13T05:11:14Z | CONTRIBUTOR | For any number greater than 200, `favorites --stop_after` stops after getting 200 tweets, e.g. ``` $ twitter-to-sqlite favorites tweets.db --stop_after=300 Importing favorites [####################################] 199 $ ``` I don't _think_ this is a limitation of the API (if you omit `--stop_after` you get some very large number, possibly all of them), so I _think_ this is a bug. | 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/50/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 779088071 | MDU6SXNzdWU3NzkwODgwNzE= | 54 | Archive import appears to be broken on recent exports | 21148 | open | 0 | 5 | 2021-01-05T14:18:01Z | 2023-01-04T11:06:55Z | CONTRIBUTOR | I requested a Twitter export yesterday, and unfortunately they seem to have changed it such that `twitter-to-sqlite import` can't handle it anymore 😢 So far I've ran into two issues. The first was easy to work around, but the second will take more investigation. If I can find the time I'll keep working on it and update this issue accordingly. The issues (so far): ### 1. Data seems to have moved to a `data/` subdirectory Running `twitter-to-sqlite import` on the raw zip file reports a bunch of "not yet implemented" errors, and then exits without actually importing anything: ``` ❯ twitter-to-sqlite import tarchive.db twitter.zip ... data/manifest: not yet implemented data/account-creation-ip: not yet implemented data/account-suspension: not yet implemented ... (dozens of more lines like this, including critical stuff like data/tweets) ... ``` (`tarchive.db` now exists, but is empty) Workaround: unpack the zip file, and run `twitter-to-sqlite import tarchive.db path/to/archive/data` That gets further, but: ### 2. Some schema(s?) have changed At least, the `blocks` schema seems different now: ``` ❯ twitter-to-sqlite import tarchive.db archive/data direct-messages-group: not yet implemented branch-links: not yet implemented periscope-expired-broadcasts: not yet implemented direct-messages: not yet implemented mute: not yet implemented Traceback (most recent call last): File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/bin/twitter-to-sqlite", line 8, in <module> sys.exit(cli()) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/lib/python3.8/site-packages/click/core.py", line 829, in __call__ return self.main(*args, **kwargs) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN4tu-py3.8/lib/python3.8/site-packages/click/core.py", line 782, in main rv = self.invoke(ctx) File "/Users/jacob/Library/Caches/pypoetry/virtualenvs/jacobian-dogsheep-4AXaN… | 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/54/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 779211940 | MDExOlB1bGxSZXF1ZXN0NTQ5MjA0MDYz | 55 | Fix archive imports | 21148 | closed | 0 | 2 | 2021-01-05T15:54:48Z | 2021-08-20T00:02:49Z | 2021-08-20T00:02:49Z | CONTRIBUTOR | dogsheep/twitter-to-sqlite/pulls/55 | This fixes the issues discussed in #54 | 206156866 | pull | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/55/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 487847945 | MDExOlB1bGxSZXF1ZXN0MzEzMDA3NDgz | 56 | Escape the table name in populate_fts and search. | 49260 | closed | 0 | 2 | 2019-09-01T06:29:05Z | 2019-09-02T17:23:21Z | 2019-09-02T17:23:21Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/56 | The table names weren't escaped using double quotes in the populate_fts method. Reproducible case: ``` >>> import sqlite_utils >>> db = sqlite_utils.Database("abc.db") >>> db["http://example.com"].insert_all([ ... {"id": 1, "age": 4, "name": "Cleo"}, ... {"id": 2, "age": 2, "name": "Pancakes"} ... ], pk="id") <Table http://example.com (id, age, name)> >>> db["http://example.com"].enable_fts(["name"]) Traceback (most recent call last): File "<input>", line 1, in <module> db["http://example.com"].enable_fts(["name"]) File "/home/amjith/.virtualenvs/itsysearch/lib/python3.7/site-packages/sqlite_utils/db.py", l ine 705, in enable_fts self.populate_fts(columns) File "/home/amjith/.virtualenvs/itsysearch/lib/python3.7/site-packages/sqlite_utils/db.py", l ine 715, in populate_fts self.db.conn.executescript(sql) sqlite3.OperationalError: unrecognized token: ":" >>> ``` | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/56/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 487987958 | MDExOlB1bGxSZXF1ZXN0MzEzMTA1NjM0 | 57 | Add triggers while enabling FTS | 49260 | closed | 0 | 4 | 2019-09-02T04:23:40Z | 2019-09-03T01:03:59Z | 2019-09-02T23:42:29Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/57 | This adds the option for a user to set up triggers in the database to keep their FTS table in sync with the parent table. Ref: https://sqlite.org/fts5.html#external_content_and_contentless_tables I would prefer to make the creation of triggers the default behavior, but that will break existing usage where people have been calling `populate_fts` after inserting new rows. I am happy to make changes to the PR as you see fit. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/57/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 907645813 | MDU6SXNzdWU5MDc2NDU4MTM= | 57 | Error: Use either --since or --since_id, not both | 42904 | closed | 0 | 6 | 2021-05-31T18:11:04Z | 2021-08-20T00:01:31Z | 2021-08-20T00:01:31Z | CONTRIBUTOR | I'm using the following command: ``` twitter-to-sqlite user-timeline -a twitter-auth.json twitter/tweets.db --since ``` Which gives the following error: ``` Error: Use either --since or --since_id, not both ``` Running without `--since`. ``` Traceback (most recent call last): File "/usr/local/bin/twitter-to-sqlite", line 8, in <module> sys.exit(cli()) File "/usr/local/lib/python3.9/site-packages/click/core.py", line 1137, in __call__ return self.main(*args, **kwargs) File "/usr/local/lib/python3.9/site-packages/click/core.py", line 1062, in main rv = self.invoke(ctx) File "/usr/local/lib/python3.9/site-packages/click/core.py", line 1668, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/usr/local/lib/python3.9/site-packages/click/core.py", line 1404, in invoke return ctx.invoke(self.callback, **ctx.params) File "/usr/local/lib/python3.9/site-packages/click/core.py", line 763, in invoke return __callback(*args, **kwargs) File "/usr/local/lib/python3.9/site-packages/twitter_to_sqlite/cli.py", line 317, in user_timeline for tweet in bar: File "/usr/local/lib/python3.9/site-packages/click/_termui_impl.py", line 328, in generator for rv in self.iter: File "/usr/local/lib/python3.9/site-packages/twitter_to_sqlite/utils.py", line 234, in fetch_user_timeline yield from fetch_timeline( File "/usr/local/lib/python3.9/site-packages/twitter_to_sqlite/utils.py", line 202, in fetch_timeline raise Exception(str(tweets["errors"])) Exception: [{'code': 44, 'message': 'since_id parameter is invalid.'}] ``` ``` Python 3.9.5 twitter-to-sqlite, version 0.21.3 ``` | 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/57/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 488293926 | MDU6SXNzdWU0ODgyOTM5MjY= | 58 | Support enabling FTS on views | 49260 | closed | 0 | 1 | 2019-09-02T18:56:36Z | 2020-10-16T18:39:36Z | 2020-10-16T18:39:31Z | CONTRIBUTOR | Right now enable_fts() is only implemented for Table(). Technically sqlite supports enabling fts on views. But it requires deeper thought since views don't have `rowid` and the current implementation of enable_fts() relies on the presence of `rowid` column. It is possible to provide an alternative rowid using the `content_rowid` option to the FTS5() function. Ref: https://sqlite.org/fts5.html#fts5_table_creation_and_initialization > The "content_rowid" option, used to set the rowid field of an external content table. This will further complicate `enable_fts()` function by adding an extra argument. I'm wondering if that is outside the scope of this tool or should I work on that feature and send a PR? | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/58/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 984939366 | MDU6SXNzdWU5ODQ5MzkzNjY= | 58 | Error: Use either --since or --since_id, not both - still broken | 42904 | closed | 0 | 1 | 2021-09-01T09:45:28Z | 2021-09-21T17:37:41Z | 2021-09-21T17:37:41Z | CONTRIBUTOR | Hi Simon, It appears the fix for #57 doesn't fix things for me: ``` $ twitter-to-sqlite --version twitter-to-sqlite, version 0.21.4 $ python --version Python 3.9.6 ``` ``` $ twitter-to-sqlite home-timeline -a twitter-auth.json twitter/timeline.db --since Importing tweets Error: Use either --since or --since_id, not both ``` Is there any way I can help debug this? | 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/58/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 771872303 | MDExOlB1bGxSZXF1ZXN0NTQzMjQ2NTM1 | 59 | Remove unneeded exists=True for -a/--auth flag. | 631242 | closed | 0 | 3 | 2020-12-21T06:03:55Z | 2021-05-22T14:06:19Z | 2021-05-19T16:08:12Z | CONTRIBUTOR | dogsheep/github-to-sqlite/pulls/59 | The file does not need to exist when using an environment variable. | 207052882 | pull | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/59/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 984942782 | MDExOlB1bGxSZXF1ZXN0NzI0MzE3NjUw | 59 | Fix for since_id bug, closes #58 | 42904 | closed | 0 | 1 | 2021-09-01T09:49:09Z | 2021-09-21T17:37:40Z | 2021-09-21T17:37:40Z | CONTRIBUTOR | dogsheep/twitter-to-sqlite/pulls/59 | Fixes remaining instances of this bug | 206156866 | pull | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/59/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 797097140 | MDU6SXNzdWU3OTcwOTcxNDA= | 60 | Use Data from SQLite in other commands | 22578954 | open | 0 | 3 | 2021-01-29T18:35:52Z | 2021-02-12T18:29:43Z | CONTRIBUTOR | As a total beginner here how could you access data from the sqlite table to run other commands. What I am thinking is I want to get all the repos in an organization then using the repo list pull all the commit messages for each repo. I love this project by the way! | 207052882 | issue | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/60/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 797108702 | MDExOlB1bGxSZXF1ZXN0NTY0MTcyMTQw | 61 | fixing typo in get cli help text | 22578954 | closed | 0 | 1 | 2021-01-29T18:57:04Z | 2021-05-19T16:07:09Z | 2021-05-19T16:07:09Z | CONTRIBUTOR | dogsheep/github-to-sqlite/pulls/61 | 207052882 | pull | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/61/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 797784080 | MDU6SXNzdWU3OTc3ODQwODA= | 62 | Stargazers and workflows commands always require an auth file when using GITHUB_TOKEN | 631242 | open | 0 | 0 | 2021-01-31T18:56:05Z | 2021-01-31T18:56:05Z | CONTRIBUTOR | Requested fix in https://github.com/dogsheep/github-to-sqlite/pull/59 The stargazers and workflows commands always require an auth file, even when using a `GITHUB_TOKEN`. Other commands don't require the auth file. | 207052882 | issue | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/62/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1261884917 | PR_kwDODFdgUs45K1L3 | 73 | Fixing 'NoneType' object has no attribute 'items' | 1224205 | closed | 0 | 1 | 2022-06-06T13:58:11Z | 2022-07-18T19:40:12Z | 2022-07-18T19:40:12Z | CONTRIBUTOR | dogsheep/github-to-sqlite/pulls/73 | Under some conditions, GitHub caches removed starred repositories and ends up leaving dangling `None` user references. Traceback (most recent call last): File "/home/dogsheep/dogsheep/github-to-sqlite/bin/github-to-sqlite", line 8, in <module> sys.exit(cli()) File "/home/dogsheep/dogsheep/github-to-sqlite/lib64/python3.10/site-packages/click/core.py", line 1130, in __call__ return self.main(*args, **kwargs) File "/home/dogsheep/dogsheep/github-to-sqlite/lib64/python3.10/site-packages/click/core.py", line 1055, in main rv = self.invoke(ctx) File "/home/dogsheep/dogsheep/github-to-sqlite/lib64/python3.10/site-packages/click/core.py", line 1657, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/home/dogsheep/dogsheep/github-to-sqlite/lib64/python3.10/site-packages/click/core.py", line 1404, in invoke return ctx.invoke(self.callback, **ctx.params) File "/home/dogsheep/dogsheep/github-to-sqlite/lib64/python3.10/site-packages/click/core.py", line 760, in invoke return __callback(*args, **kwargs) File "/home/dogsheep/dogsheep/github-to-sqlite/lib64/python3.10/site-packages/github_to_sqlite/cli.py", line 181, in starred utils.save_stars(db, user, stars) File "/home/dogsheep/dogsheep/github-to-sqlite/lib64/python3.10/site-packages/github_to_sqlite/utils.py", line 494, in save_stars repo_id = save_repo(db, repo) File "/home/dogsheep/dogsheep/github-to-sqlite/lib64/python3.10/site-packages/github_to_sqlite/utils.py", line 308, in save_repo to_save["owner"] = save_user(db, to_save["owner"]) File "/home/dogsheep/dogsheep/github-to-sqlite/lib64/python3.10/site-packages/github_to_sqlite/utils.py", line 229, in save_user for key, value in user.items() AttributeError: 'NoneType' object has no attribute 'items' | 207052882 | pull | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/73/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 546073980 | MDU6SXNzdWU1NDYwNzM5ODA= | 74 | Test failures on openSUSE 15.1: AssertionError: Explicit other_table and other_column | 15092 | open | 0 | 3 | 2020-01-07T04:35:50Z | 2020-01-12T07:21:17Z | CONTRIBUTOR | openSUSE 15.1 is using python 3.6.5 and click-7.0 , however it has test failures while openSUSE Tumbleweed on py37 passes. Most fail on the cli exit code like ```py [ 74s] =================================== FAILURES =================================== [ 74s] _________________________________ test_tables __________________________________ [ 74s] [ 74s] db_path = '/tmp/pytest-of-abuild/pytest-0/test_tables0/test.db' [ 74s] [ 74s] def test_tables(db_path): [ 74s] result = CliRunner().invoke(cli.cli, ["tables", db_path]) [ 74s] > assert '[{"table": "Gosh"},\n {"table": "Gosh2"}]' == result.output.strip() [ 74s] E assert '[{"table": "...e": "Gosh2"}]' == '' [ 74s] E - [{"table": "Gosh"}, [ 74s] E - {"table": "Gosh2"}] [ 74s] [ 74s] tests/test_cli.py:28: AssertionError ``` packaging project at https://build.opensuse.org/package/show/home:jayvdb:py-new/python-sqlite-utils I'll keep digging into this after I have github-to-sqlite working on Tumbleweed, as I'll need openSUSE Leap 15.1 working before I can submit this into the main python repo. | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/74/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 546078359 | MDExOlB1bGxSZXF1ZXN0MzU5ODIyNzcz | 75 | Explicitly include tests and docs in sdist | 15092 | closed | 0 | 1 | 2020-01-07T04:53:20Z | 2020-01-31T00:21:27Z | 2020-01-31T00:21:27Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/75 | Also exclude 'tests' from runtime installation. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/75/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 1410548368 | I_kwDODFdgUs5UE0KQ | 77 | Feature: Support GitHub discussions | 631242 | open | 0 | 0 | 2022-10-16T16:53:38Z | 2022-10-16T16:53:38Z | CONTRIBUTOR | Hi @simonw I've been a happy user of this tool. Thank you for writing it and sharing it. I wanted to suggest a feature request to support Discussions. For example the VisiData project has discussions https://github.com/saulpw/visidata/discussions , and it would be useful if there was a way to pull that data into the database. However, I'm not offering a pull request. | 207052882 | issue | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/77/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 273595473 | MDExOlB1bGxSZXF1ZXN0MTUyMzYwNzQw | 81 | :fire: Removes DS_Store | 50527 | closed | 0 | 2 | 2017-11-13T22:07:52Z | 2017-11-14T02:24:54Z | 2017-11-13T22:16:55Z | CONTRIBUTOR | simonw/datasette/pulls/81 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/81/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 273775212 | MDU6SXNzdWUyNzM3NzUyMTI= | 88 | Add NHS England Hospitals example to wiki | 15543 | closed | 0 | 4 | 2017-11-14T12:29:10Z | 2021-03-22T23:46:36Z | 2017-11-14T22:54:06Z | CONTRIBUTOR | https://nhs-england-hospitals.now.sh and an associated map visualisation: http://run.plnkr.co/preview/cj9zlf1qc0003414y90ajkwpk/ Datasette is wonderful! | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/88/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 273816720 | MDExOlB1bGxSZXF1ZXN0MTUyNTIyNzYy | 89 | SQL syntax highlighting with CodeMirror | 15543 | closed | 0 | 1 | 2017-11-14T14:43:33Z | 2017-11-15T02:03:01Z | 2017-11-15T02:03:01Z | CONTRIBUTOR | simonw/datasette/pulls/89 | Addresses #13 Future enhancements could include autocompletion of table and column names, e.g. with ```javascript extraKeys: {"Ctrl-Space": "autocomplete"}, hintOptions: {tables: { users: ["name", "score", "birthDate"], countries: ["name", "population", "size"] }} ``` (see https://codemirror.net/doc/manual.html#addon_sql-hint and source at http://codemirror.net/mode/sql/) | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/89/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 273961179 | MDExOlB1bGxSZXF1ZXN0MTUyNjMxNTcw | 94 | Initial add simple prod ready Dockerfile refs #57 | 247192 | closed | 0 | 1 | 2017-11-14T22:09:09Z | 2017-11-15T03:08:04Z | 2017-11-15T03:08:04Z | CONTRIBUTOR | simonw/datasette/pulls/94 | Multi-stage build based off official python:3.6-slim Example usage: ``` docker run --rm -t -i -p 9000:8001 -v $(pwd)/db:/db datasette datasette serve /db/chinook.db ``` | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/94/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 589801352 | MDExOlB1bGxSZXF1ZXN0Mzk1MjU4Njg3 | 96 | Add type conversion for Panda's Timestamp | 32605365 | closed | 0 | 2 | 2020-03-29T14:13:09Z | 2020-03-31T04:40:49Z | 2020-03-31T04:40:48Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/96 | Add type conversion for Panda's Timestamp, if Panda library is present in system (thanks for this project, I was about to do the same thing from scratch) | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/96/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 610517472 | MDU6SXNzdWU2MTA1MTc0NzI= | 103 | sqlite3.OperationalError: too many SQL variables in insert_all when using rows with varying numbers of columns | 32605365 | closed | 0 | 8 | 2020-05-01T02:26:14Z | 2020-05-14T00:18:57Z | 2020-05-14T00:18:57Z | CONTRIBUTOR | If using insert_all to put in 1000 rows of data with varying number of columns, it comes up with this message `sqlite3.OperationalError: too many SQL variables` if the number of columns is larger in later records (past the first row) I've reduced `SQLITE_MAX_VARS` by 100 to 899 at the top of `db.py` to add wiggle room, so that if the column count increases it wont go past SQLite's batch limit as calculated by this line of code based on the count of the first row's dict keys batch_size = max(1, min(batch_size, SQLITE_MAX_VARS // num_columns)) | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/103/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 274284246 | MDExOlB1bGxSZXF1ZXN0MTUyODcwMDMw | 104 | [WIP] Add publish to heroku support | 21148 | closed | 0 | 6 | 2017-11-15T19:56:22Z | 2017-11-21T20:55:05Z | 2017-11-21T20:55:05Z | CONTRIBUTOR | simonw/datasette/pulls/104 | Refs #90 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/104/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 274343647 | MDExOlB1bGxSZXF1ZXN0MTUyOTE0NDgw | 107 | add support for ?field__isnull=1 | 3433657 | closed | 0 | 4 | 2017-11-15T23:36:36Z | 2017-11-17T15:12:29Z | 2017-11-17T13:29:22Z | CONTRIBUTOR | simonw/datasette/pulls/107 | Is this what you had in mind for [this issue](https://github.com/simonw/datasette/issues/64)? | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/107/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 274733145 | MDExOlB1bGxSZXF1ZXN0MTUzMjAxOTQ1 | 114 | Add spatialite, switch to debian and local build | 54999 | closed | 0 | 1 | 2017-11-17T02:37:09Z | 2017-11-17T03:50:52Z | 2017-11-17T03:50:52Z | CONTRIBUTOR | simonw/datasette/pulls/114 | Improves the Dockerfile to support spatial datasets, work with the local datasette code (Friendly with git tags and Dockerhub) and moves to slim debian, a small image easy to extend via apt packages for sqlite. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/114/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 274877366 | MDExOlB1bGxSZXF1ZXN0MTUzMzA2ODgy | 115 | Add keyboard shortcut to execute SQL query | 198537 | closed | 0 | 1 | 2017-11-17T14:13:33Z | 2017-11-17T15:16:34Z | 2017-11-17T14:22:56Z | CONTRIBUTOR | simonw/datasette/pulls/115 | Very cool tool, thanks a lot! This PR adds a `Shift-Enter` short cut to execute the SQL query. I used CodeMirrors keyboard handling. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/115/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 274900388 | MDExOlB1bGxSZXF1ZXN0MTUzMzI0MzAx | 117 | Don't prevent tabbing to `Run SQL` button | 198537 | closed | 0 | 1 | 2017-11-17T15:27:50Z | 2017-11-19T20:30:24Z | 2017-11-18T00:53:43Z | CONTRIBUTOR | simonw/datasette/pulls/117 | Mentioned in #115 Here you go! | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/117/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 651844316 | MDExOlB1bGxSZXF1ZXN0NDQ1MDIzMzI2 | 118 | Add insert --truncate option | 79913 | closed | 0 | 9 | 2020-07-06T21:58:40Z | 2020-07-08T17:26:21Z | 2020-07-08T17:26:21Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/118 | Deletes all rows in the table (if it exists) before inserting new rows. SQLite doesn't implement a TRUNCATE TABLE statement but does optimize an unqualified DELETE FROM. This can be handy if you want to refresh the entire contents of a table but a) don't have a PK (so can't use --replace), b) don't want the table to disappear (even briefly) for other connections, and c) have to handle records that used to exist being deleted. Ideally the replacement of rows would appear instantaneous to other connections by putting the DELETE + INSERT in a transaction, but this is very difficult without breaking other code as the current transaction handling is inconsistent and non-systematic. There exists the possibility for the DELETE to succeed but the INSERT to fail, leaving an empty table. This is not much worse, however, than the current possibility of one chunked INSERT succeeding and being committed while the next chunked INSERT fails, leaving a partially complete operation. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/118/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 652816158 | MDExOlB1bGxSZXF1ZXN0NDQ1ODMzOTA4 | 120 | Fix query command's support for DML | 79913 | closed | 0 | 1 | 2020-07-08T01:36:34Z | 2020-07-08T05:14:04Z | 2020-07-08T05:14:04Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/120 | See commit messages for details. I ran into this while investigating another feature/issue. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/120/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 686978131 | MDU6SXNzdWU2ODY5NzgxMzE= | 139 | insert_all(..., alter=True) should work for new columns introduced after the first 100 records | 96218 | closed | 0 | 7 | 2020-08-27T06:25:25Z | 2020-08-28T22:48:51Z | 2020-08-28T22:30:14Z | CONTRIBUTOR | Is there a way to make `.insert_all()` work properly when new columns are introduced outside the first 100 records (with or without the `alter=True` argument)? I'm using `.insert_all()` to bulk insert ~3-4k records at a time and it is common for records to need to introduce new columns. However, if new columns are introduced after the first 100 records, `sqlite_utils` doesn't even raise the `OperationalError: table ... has no column named ...` exception; it just silently drops the extra data and moves on. It took me a while to find this little snippet in the [documentation for `.insert_all()`](https://sqlite-utils.readthedocs.io/en/stable/python-api.html#bulk-inserts) (it's not mentioned under [Adding columns automatically on insert/update](https://sqlite-utils.readthedocs.io/en/stable/python-api.html#bulk-inserts)): > The column types used in the CREATE TABLE statement are automatically derived from the types of data in that first batch of rows. **_Any additional or missing columns in subsequent batches will be ignored._** I tried changing the `batch_size` argument to the total number of records, but it seems only to effect the number of rows that are committed at a time, and has no influence on this problem. Is there a way around this that you would suggest? It seems like it should raise an exception at least. | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/139/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275814941 | MDU6SXNzdWUyNzU4MTQ5NDE= | 141 | datasette publish can fail if /tmp is on a different device | 21148 | closed | 0 | 2949431 | 5 | 2017-11-21T18:28:05Z | 2020-04-29T03:27:54Z | 2017-12-08T16:06:36Z | CONTRIBUTOR | `datasette publish` uses hard links to avoid copying the db into a tmp directory. This can fail if `/tmp` is on another device, because hardlinks can't cross devices. You'll see something like this: ``` $ datasette publish heroku whatever.db ... OSError: [Errno 18] Invalid cross-device link: '/mnt/c/Users/jacob/c/datasette/whatever.db' -> '/tmp/tmpvxq2yof6/whatever.db' ``` [In my case this is failing because I'm on a Windows machine, using WSL, so my code's on a different virtual filesystem from the Linux subsystem, Because Reasons.] I'm not sure if it's possible to detect this (can you figure out which device `/tmp` is on?), or what the fallback should be (soft link? copy?). | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/141/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 688386219 | MDExOlB1bGxSZXF1ZXN0NDc1NjY1OTg0 | 142 | insert_all(..., alter=True) should work for new columns introduced after the first 100 records | 96218 | closed | 0 | 3 | 2020-08-28T22:22:57Z | 2020-08-30T07:28:23Z | 2020-08-28T22:30:14Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/142 | Closes #139. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/142/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 688659182 | MDU6SXNzdWU2ODg2NTkxODI= | 145 | Bug when first record contains fewer columns than subsequent records | 96218 | closed | 0 | 2 | 2020-08-30T05:44:44Z | 2020-09-08T23:21:23Z | 2020-09-08T23:21:23Z | CONTRIBUTOR | `insert_all()` selects the maximum batch size based on the number of fields in the first record. If the first record has fewer fields than subsequent records (and `alter=True` is passed), this can result in SQL statements with more than the maximum permitted number of host parameters. This situation is perhaps unlikely to occur, but could happen if the first record had, say, 10 columns, such that `batch_size` (based on `SQLITE_MAX_VARIABLE_NUMBER = 999`) would be 99. If the next 98 rows had 11 columns, the resulting SQL statement for the first batch would have `10 * 1 + 11 * 98 = 1088` host parameters (and subsequent batches, if the data were consistent from thereon out, would have `99 * 11 = 1089`). I suspect that this bug is masked somewhat by the fact that while: > [`SQLITE_MAX_VARIABLE_NUMBER`](https://www.sqlite.org/limits.html#max_variable_number) ... defaults to 999 for SQLite versions prior to 3.32.0 (2020-05-22) or 32766 for SQLite versions after 3.32.0. it is common that it is increased at compile time. Debian-based systems, for example, seem to ship with a version of sqlite compiled with `SQLITE_MAX_VARIABLE_NUMBER` set to 250,000, and I believe this is the case for homebrew installations too. A test for this issue might look like this: ```python def test_columns_not_in_first_record_should_not_cause_batch_to_be_too_large(fresh_db): # sqlite on homebrew and Debian/Ubuntu etc. is typically compiled with # SQLITE_MAX_VARIABLE_NUMBER set to 250,000, so we need to exceed this value to # trigger the error on these systems. THRESHOLD = 250000 extra_columns = 1 + (THRESHOLD - 1) // 99 records = [ {"c0": "first record"}, # one column in first record -> batch_size = 100 # fill out the batch with 99 records with enough columns to exceed THRESHOLD *[ dict([("c{}".format(i), j) for i in range(extra_columns)]) for j in range(99) ] ] try: fresh_db["too_many_columns"].insert_all(records, a… | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/145/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 688668680 | MDExOlB1bGxSZXF1ZXN0NDc1ODc0NDkz | 146 | Handle case where subsequent records (after first batch) include extra columns | 96218 | closed | 0 | 5 | 2020-08-30T07:13:58Z | 2020-09-08T23:20:37Z | 2020-09-08T23:20:37Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/146 | Addresses #145. I think this should do the job. If it meets with your approval I'll update this PR to include an update to the documentation -- I came across this bug while preparing a PR to update the documentation around `batch_size` in any event. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/146/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 688670158 | MDU6SXNzdWU2ODg2NzAxNTg= | 147 | SQLITE_MAX_VARS maybe hard-coded too low | 96218 | open | 0 | 7 | 2020-08-30T07:26:45Z | 2021-02-15T21:27:55Z | CONTRIBUTOR | I came across this while about to open an issue and PR against the documentation for `batch_size`, which is a bit incomplete. As mentioned in #145, while: > [`SQLITE_MAX_VARIABLE_NUMBER`](https://www.sqlite.org/limits.html#max_variable_number) ... defaults to 999 for SQLite versions prior to 3.32.0 (2020-05-22) or 32766 for SQLite versions after 3.32.0. it is common that it is increased at compile time. Debian-based systems, for example, seem to ship with a version of sqlite compiled with SQLITE_MAX_VARIABLE_NUMBER set to 250,000, and I believe this is the case for homebrew installations too. In working to understand what `batch_size` was actually doing and why, I realized that by setting `SQLITE_MAX_VARS` in `db.py` to match the value my sqlite was compiled with (I'm on Debian), I was able to decrease the time to `insert_all()` my test data set (~128k records across 7 tables) from ~26.5s to ~3.5s. Given that this about .05% of my total dataset, this is time I am keen to save... Unfortunately, it seems that `sqlite3` in the python standard library doesn't expose the `get_limit()` C API (even though `pysqlite` used to), so it's hard to know what value sqlite has been compiled with (note that this could mean, I suppose, that it's less than 999, and even hardcoding `SQLITE_MAX_VARS` to the conservative default might not be adequate. It can also be lowered -- but not raised -- at runtime). The best I could come up with is `echo "" | sqlite3 -cmd ".limits variable_number"` (only available in `sqlite >= 2015-05-07 (3.8.10)`). Obviously this couldn't be relied upon in `sqlite_utils`, but I wonder what your opinion would be about exposing `SQLITE_MAX_VARS` as a user-configurable parameter (with suitable "here be dragons" warnings)? I'm going to go ahead and monkey-patch it for my purposes in any event, but it seems like it might be worth considering. | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/147/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 697030843 | MDExOlB1bGxSZXF1ZXN0NDgzMDI3NTg3 | 156 | Typos in tests | 96218 | closed | 0 | 1 | 2020-09-09T18:00:58Z | 2020-09-09T18:24:50Z | 2020-09-09T18:21:23Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/156 | One of these is my fault, and the other is one I just happened to come across. They're harmless, but might as well be fixed. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/156/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 697203800 | MDExOlB1bGxSZXF1ZXN0NDgzMTc1NTA5 | 158 | Fix accidental mega long line in docs | 167319 | closed | 0 | 1 | 2020-09-09T22:31:23Z | 2020-09-16T06:21:43Z | 2020-09-16T06:21:43Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/158 | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/158/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 286938589 | MDU6SXNzdWUyODY5Mzg1ODk= | 177 | Publishing to Heroku - metadata file not uploaded? | 82988 | closed | 0 | 0 | 2018-01-09T01:04:31Z | 2018-01-25T16:45:32Z | 2018-01-25T16:45:32Z | CONTRIBUTOR | Trying to run *datasette* (version 0.14) on Heroku with a `metadata.json` doesn't seem to be picking up the `metadata.json` file? On a Mac with dodgy `tar` support: ``` ▸ Couldn't detect GNU tar. Builds could fail due to decompression errors ▸ See ▸ https://devcenter.heroku.com/articles/platform-api-deploying-slugs#create-slug-archive ▸ Please install it, or specify the '--tar' option ▸ Falling back to node's built-in compressor ``` Could that be causing the issue? Also, I'm not seeing custom query links anywhere obvious when I run the metadata file with a local *datasette* server? | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/177/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 287240246 | MDExOlB1bGxSZXF1ZXN0MTYxOTgyNzEx | 178 | If metadata exists, add it to heroku launch command | 82988 | closed | 0 | 1 | 2018-01-09T21:42:21Z | 2018-01-15T09:42:46Z | 2018-01-14T21:05:16Z | CONTRIBUTOR | simonw/datasette/pulls/178 | The heroku build does seem to make use of any provided `metadata.json` file. Add the `--metadata` switch to the Heroku web launch command if a `metadata.json` file is available. Addresses: https://github.com/simonw/datasette/issues/177 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/178/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 709043182 | MDExOlB1bGxSZXF1ZXN0NDkzMTYyNzY3 | 178 | Update README.md | 19921 | closed | 0 | 1 | 2020-09-25T15:52:11Z | 2020-10-01T14:18:30Z | 2020-09-30T20:29:28Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/178 | The `sqlite-utils insert releases.db releases - --pk` is missing the pk field name, added ` "id"` to fix it. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/178/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 289375133 | MDExOlB1bGxSZXF1ZXN0MTYzNTIzOTc2 | 180 | make html title more readable in query template | 56477 | closed | 0 | 0 | 2018-01-17T18:56:03Z | 2018-04-03T16:03:38Z | 2018-04-03T15:24:05Z | CONTRIBUTOR | simonw/datasette/pulls/180 | tiny tweak to make this easier to visually parse—I think it matches your style in other templates | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/180/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 291451116 | MDExOlB1bGxSZXF1ZXN0MTY1MDI5ODA3 | 182 | Add db filesize next to download link | 3433657 | closed | 0 | 0 | 2018-01-25T04:58:56Z | 2019-03-22T13:50:57Z | 2019-02-06T04:59:38Z | CONTRIBUTOR | simonw/datasette/pulls/182 | Took a stab at #172, will this do the trick? | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/182/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 291639118 | MDU6SXNzdWUyOTE2MzkxMTg= | 183 | Custom Queries - escaping strings | 82988 | closed | 0 | 2 | 2018-01-25T16:49:13Z | 2019-06-24T06:45:07Z | 2019-06-24T06:45:07Z | CONTRIBUTOR | If a SQLite table column name contains spaces, they are usually referred to in double quotes: `SELECT * FROM mytable WHERE "gappy column name"="my value";` In the JSON metadata file, this is passed by escaping the double quotes: `"queries": {"my query": "SELECT * FROM mytable WHERE \"gappy column name\"=\"my value\";"}` When specifying a custom query in `metadata.json` using double quotes, these are then rendered in the *datasette* query box using single quotes: `SELECT * FROM mytable WHERE 'gappy column name'='my value';` which does not work. Alternatively, a valid custom query can be passed using backticks (\`) to quote the column name and single (unescaped) quotes for the matched value: ``"queries": {"my query": "SELECT * FROM mytable WHERE `gappy column name`='my value';"}`` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/183/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 729818242 | MDExOlB1bGxSZXF1ZXN0NTEwMjM1OTA5 | 189 | Allow iterables other than Lists in m2m records | 35681 | closed | 0 | 3 | 2020-10-26T18:47:44Z | 2020-10-27T16:28:37Z | 2020-10-27T16:24:21Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/189 | I was playing around with sqlite-utils, creating a Roam Research dogsheep-style importer for Datasette, and ran into a slight snag. I wanted to use a generator to add an order column in an importer. It looked something like: ``` def order_generator(iterable, attr=None): if attr is None: attr = "order" order: int = 0 for i in iterable: i[attr] = order order += 1 yield i ``` When I used this with `insert_all` and other things, it worked fine--but it didn't work as the `records` argument to `m2m`. I dug into it, and sqlite-utils is explicitly checking if the records argument is a list or a tuple. I flipped the check upside down, and now it checks if the argument is a mapping. If it's a mapping, it wraps it in a list, otherwise it leaves it alone. (I get that it might not really make sense to put the order column on the second table. I changed my import schema a bit, and no longer have a real example, but maybe this change still makes sense.) The automated tests still pass, but I did not add any new ones. Let me know what you think! I'm really loving Datasette and its ecosystem; thanks for everything! | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/189/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 313494458 | MDExOlB1bGxSZXF1ZXN0MTgxMDMzMDI0 | 200 | Hide Spatialite system tables | 45057 | closed | 0 | 3 | 2018-04-11T21:26:58Z | 2018-04-12T21:34:48Z | 2018-04-12T21:34:48Z | CONTRIBUTOR | simonw/datasette/pulls/200 | They were getting on my nerves. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/200/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 313785206 | MDExOlB1bGxSZXF1ZXN0MTgxMjQ3NTY4 | 202 | Raise 404 on nonexistent table URLs | 45057 | closed | 0 | 2 | 2018-04-12T15:47:06Z | 2018-04-13T19:22:56Z | 2018-04-13T18:19:15Z | CONTRIBUTOR | simonw/datasette/pulls/202 | Currently they just 500. Also cleaned the logic up a bit, I hope I didn't miss anything. This is issue #184. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/202/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 313837303 | MDU6SXNzdWUzMTM4MzczMDM= | 203 | Support for units | 45057 | closed | 0 | 10 | 2018-04-12T18:24:28Z | 2018-04-16T21:59:17Z | 2018-04-16T21:59:17Z | CONTRIBUTOR | It would be nice to be able to attach a unit to a column in the metadata, and have it rendered with that unit (and SI prefix) when it's displayed. It would also be nice to support entering the prefixes in variables when querying. With my radio licensing app I've put all frequencies in Hz. It's easy enough to special-case the row rendering to add the SI prefixes, but it's pretty unusable when querying by that field. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/203/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 314256802 | MDExOlB1bGxSZXF1ZXN0MTgxNjAwOTI2 | 204 | Initial units support | 45057 | closed | 0 | 0 | 2018-04-13T21:32:49Z | 2018-04-14T09:44:33Z | 2018-04-14T03:32:54Z | CONTRIBUTOR | simonw/datasette/pulls/204 | Add support for specifying units for a column in metadata.json and rendering them on display using [pint](https://pint.readthedocs.io/en/latest/). Example table metadata: ```json "license_frequency": { "units": { "frequency": "Hz", "channel_width": "Hz", "height": "m", "antenna_height": "m", "azimuth": "degrees" } } ``` [Example result](https://wtr-api.herokuapp.com/wtr-663ea99/license_frequency/1) This works surprisingly well! I'd like to add support for using units when querying but this is PR is pretty usable as-is. (Pint doesn't seem to support decibels though - it thinks they're decibytes - which is an annoying omission.) (ref ticket #203) | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/204/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 752888228 | MDExOlB1bGxSZXF1ZXN0NTI5MDkwNTYw | 204 | use jsonify_if_need for sql updates | 78035 | closed | 0 | 1 | 2020-11-29T10:49:00Z | 2020-12-08T17:49:42Z | 2020-12-08T17:49:42Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/204 | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/204/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 314319372 | MDExOlB1bGxSZXF1ZXN0MTgxNjQyMTE0 | 205 | Support filtering with units and more | 45057 | closed | 0 | 3 | 2018-04-14T10:47:51Z | 2018-04-14T15:24:04Z | 2018-04-14T15:24:04Z | CONTRIBUTOR | simonw/datasette/pulls/205 | The first commit: * Adds units to exported JSON * Adds units key to metadata skeleton * Adds some docs for units The second commit adds filtering by units by the first method I mentioned in #203:  [Try it here](https://wtr-api.herokuapp.com/wtr-663ea99/license_frequency?frequency__gt=50GHz&height__lt=50ft). I think it integrates pretty neatly. The third commit adds support for registering custom units with Pint from metadata.json. Probably pretty niche, but I need decibels! | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/205/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 314323977 | MDExOlB1bGxSZXF1ZXN0MTgxNjQ0ODA1 | 206 | Fix sqlite error when loading rows with no incoming FKs | 45057 | closed | 0 | 0 | 2018-04-14T12:08:17Z | 2018-04-14T14:32:42Z | 2018-04-14T14:24:25Z | CONTRIBUTOR | simonw/datasette/pulls/206 | This fixes `ERROR: conn=<sqlite3.Connection object at 0x10bbb9f10>, sql = 'select ', params = {'id': '1'}` caused by an invalid query loading incoming FKs when none exist. The error was ignored due to async but it still got printed to the console. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/206/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 314329002 | MDExOlB1bGxSZXF1ZXN0MTgxNjQ3NzE3 | 207 | Link foreign keys which don't have labels | 45057 | closed | 0 | 1 | 2018-04-14T13:27:14Z | 2018-04-14T15:00:00Z | 2018-04-14T15:00:00Z | CONTRIBUTOR | simonw/datasette/pulls/207 | This renders unlabeled FKs as simple links. I can't see why this would cause any major problems.  Also includes bonus fixes for two minor issues: * In foreign key link hrefs the primary key was escaped using HTML escaping rather than URL escaping. This broke some non-integer PKs. * Print tracebacks to console when handling 500 errors. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/207/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 314340944 | MDExOlB1bGxSZXF1ZXN0MTgxNjU0ODM5 | 208 | Return HTTP 405 on InvalidUsage rather than 500 | 45057 | closed | 0 | 0 | 2018-04-14T16:12:50Z | 2018-04-14T18:00:39Z | 2018-04-14T18:00:39Z | CONTRIBUTOR | simonw/datasette/pulls/208 | This also stops it filling up the logs. This happens for HEAD requests at the moment - which perhaps should be handled better, but that's a different issue. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/208/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 314455877 | MDExOlB1bGxSZXF1ZXN0MTgxNzIzMzAz | 209 | Don't duplicate simple primary keys in the link column | 45057 | closed | 0 | 6 | 2018-04-15T21:56:15Z | 2018-04-18T08:40:37Z | 2018-04-18T01:13:04Z | CONTRIBUTOR | simonw/datasette/pulls/209 | When there's a simple (single-column) primary key, it looks weird to duplicate it in the link column. This change removes the second PK column and treats the link column as if it were the PK column from a header/sorting perspective. This might make it a bit more difficult to tell what the link for the row is, I'm not sure yet. I feel like the alternative is to change the link column to just have the text "view" or something, instead of repeating the PK. (I doubt it makes much more sense with compound PKs.) Bonus change in this PR: fix urlencoding of links in the displayed HTML. Before:  After:  | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/209/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 766156875 | MDU6SXNzdWU3NjYxNTY4NzU= | 209 | Test failure with sqlite 3.34 in test_cli.py::test_optimize | 191622 | closed | 0 | 1 | 2020-12-14T08:58:18Z | 2021-01-01T23:52:46Z | 2021-01-01T23:52:46Z | CONTRIBUTOR | pytest output: ``` ... ============================== short test summary info =============================== FAILED tests/test_cli.py::test_optimize[tables0] - assert 1662976 < 1662976 FAILED tests/test_cli.py::test_optimize[tables1] - assert 1667072 < 1662976 ===================== 2 failed, 538 passed, 3 skipped in 34.32s ====================== ``` Came across this while packaging `sqlite-utils` for NixOS, but it can be recreated it using the `alpine:edge` docker image as well as follows: ``` docker run --rm -it alpine:edge /bin/sh # apk update && apk add git sqlite python3 gcc python3-dev musl-dev && python3 -m ensurepip # git clone https://github.com/simonw/sqlite-utils.git # cd sqlite-utils/ # pip3 install -e .[test] # pytest ``` This definitely works on sqlite v3.33. | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/209/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 314834783 | MDU6SXNzdWUzMTQ4MzQ3ODM= | 219 | Expose units in the JSON API? | 45057 | open | 0 | 0 | 2018-04-16T22:04:25Z | 2018-04-16T22:04:25Z | CONTRIBUTOR | From #203: it would be nice for the JSON API to (optionally) return columns rendered with units in them - if, for example, you're consuming the JSON to render the rows on a map. I'm not entirely sure how useful this will be though - at the moment my map queries are custom SQL queries (a few have joins in, the rest might be fetching large amounts of data so it makes sense to limit columns fetched). Perhaps the SQL function is a better approach in general. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/219/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 316365426 | MDExOlB1bGxSZXF1ZXN0MTgzMTM1NjA0 | 232 | Fix a typo | 45281 | closed | 0 | 1 | 2018-04-20T18:20:04Z | 2018-04-21T00:19:08Z | 2018-04-21T00:19:08Z | CONTRIBUTOR | simonw/datasette/pulls/232 | It looks like this was the only instance of it: https://github.com/simonw/datasette/search?utf8=%E2%9C%93&q=SOLite&type= | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/232/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 817989436 | MDU6SXNzdWU4MTc5ODk0MzY= | 242 | Async support | 25778 | open | 0 | 13 | 2021-02-27T18:29:38Z | 2021-10-28T14:37:56Z | CONTRIBUTOR | Following our conversation last week, want to note this here before I forget. I've had a couple situations where I'd like to do a bunch of updates in an async event loop, but I run into SQLite's issues with concurrent writes. This feels like something sqlite-utils could help with. PeeWee ORM has a [SQLite write queue](http://docs.peewee-orm.com/en/latest/peewee/playhouse.html#sqliteq) that might be a good model. It's using threads or gevent, but I _think_ that approach would translate well enough to asyncio. Happy to help with this, too. | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/242/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 820468864 | MDExOlB1bGxSZXF1ZXN0NTgzNDA3OTg5 | 244 | Typo in upsert example | 387669 | closed | 0 | 1 | 2021-03-02T23:14:14Z | 2021-05-19T02:58:21Z | 2021-05-19T02:58:21Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/244 | Remove extra `[` | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/244/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 830803173 | MDExOlB1bGxSZXF1ZXN0NTkyMjg5MzI0 | 245 | Correct some typos | 1076745 | closed | 0 | 1 | 2021-03-13T04:26:56Z | 2021-05-19T02:58:04Z | 2021-05-19T02:58:04Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/245 | Noticed a typo in the docs and followed that up with a spellcheck. Had to bite my tongue at some of the British spellings. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/245/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 831751367 | MDU6SXNzdWU4MzE3NTEzNjc= | 246 | Escaping FTS search strings | 16001974 | closed | 0 | 4 | 2021-03-15T12:15:09Z | 2021-08-18T18:57:13Z | 2021-08-18T18:43:12Z | CONTRIBUTOR | Thanks for the excellent library, it's very nice to use! I've been building some in memory search functionality for a data annotation tool i'm making, and I got tripped up a little bit with escaping the full text search queries. First I tried using `db.quote(q)`, which doesn't work, because sqlite FTS has it's own (separate)[ query syntax](https://www2.sqlite.org/fts5.html#full_text_query_syntax). You can see this happening here also: http://search-24ways.herokuapp.com/24ways-f8f455f/articles?_search=acces%2A I got around this by aggressively escaping quotes inside the query string like this: ```python quoted = q.replace('"', '""') quoted = f'"{quoted}"' print(quoted) results = db["data"].search(quoted, columns=["id"]) return [x["id"] for x in results] ``` This works in the sense it doesn't crash, but it also removes access to the search query syntax. Given the well specified definition, it might be possible for sqlite-utils to provide a `db.quote_query(q)` which would intelligently escape a query whilst leaving the syntax intact. This would be very nice! | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/246/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 832687563 | MDExOlB1bGxSZXF1ZXN0NTkzODA1ODA0 | 247 | FTS quote functionality from datasette | 16001974 | closed | 0 | 2 | 2021-03-16T11:17:34Z | 2021-08-18T18:43:12Z | 2021-08-18T18:43:12Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/247 | Addresses #246 - this is a bit of a kludge because it doesn't actually *validate* the FTS string, just makes sure that it will not crash when executed, but I figured that building a query parser is a bit out of the scope of sqlite-utils and if you actually want to use the query language, you probably need to parse that yourself. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/247/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 857280617 | MDExOlB1bGxSZXF1ZXN0NjE0NzI3MDM2 | 254 | Fix incorrect create-table cli description | 1935268 | closed | 0 | 1 | 2021-04-13T20:03:15Z | 2021-05-19T04:43:46Z | 2021-05-19T02:57:26Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/254 | The description for `create-table` was duplicated from `create-index`. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/254/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 868188068 | MDU6SXNzdWU4NjgxODgwNjg= | 257 | Insert from JSON containing strings with non-ascii characters are escaped as unicode for lists, tuples, dicts. | 6586811 | closed | 0 | 0 | 2021-04-26T20:46:25Z | 2021-05-19T02:57:05Z | 2021-05-19T02:57:05Z | CONTRIBUTOR | JSON Test File (test.json): ```json [ { "id": 123, "text": "FR Théâtre" }, { "id": 223, "text": [ "FR Théâtre" ] } ] ``` Command to import: ```bash sqlite-utils insert test.db text test.json --pk=id ``` Resulting table view from datasette: 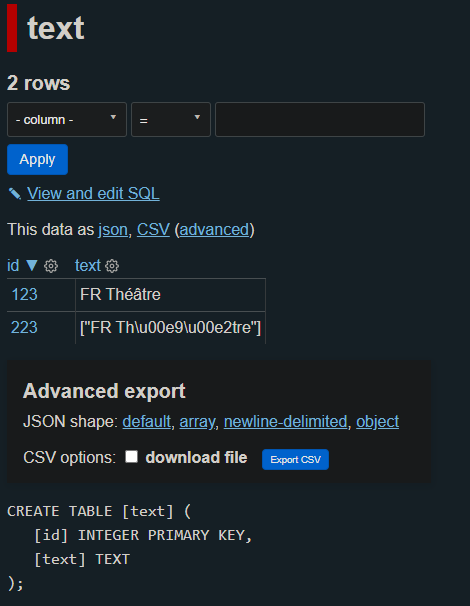 Original, db.py line 2225: ```python return json.dumps(value, default=repr) ``` Fix, db.py line 2225: ```python return json.dumps(value, default=repr, ensure_ascii=False) ``` | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/257/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 868191959 | MDExOlB1bGxSZXF1ZXN0NjIzNzU1NzIz | 258 | Fixing insert from JSON containing strings with non-ascii characters … | 6586811 | closed | 0 | 1 | 2021-04-26T20:50:00Z | 2021-05-19T02:47:44Z | 2021-05-19T02:47:44Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/258 | …are escaped aps unicode for lists, tuples, dicts Fix of #257 | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/258/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 907642546 | MDU6SXNzdWU5MDc2NDI1NDY= | 264 | Supporting additional output formats, like GeoJSON | 25778 | closed | 0 | 3 | 2021-05-31T18:03:32Z | 2021-06-03T05:12:21Z | 2021-06-03T05:12:21Z | CONTRIBUTOR | I have a project going where it would be useful to do some spatial processing in SQLite (instead of large files) and then output GeoJSON. So my workflow would be something like this: 1. Read Shapefiles, GeoJSON, CSVs into a SQLite database 2. Join, filter, prune as needed 3. Export GeoJSON for just the stuff I need at that moment, while still having a database of things that will be useful later I'm wondering if this is worth adding to SQLite-utils itself (GeoJSON, at least), or if it's better to make a counterpart to the ecosystem of `*-to-sqlite` tools, say a suite of `sqlite-to-*` things. Or would it be crazy to have a plugin system? | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/264/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 324835838 | MDU6SXNzdWUzMjQ4MzU4Mzg= | 276 | Handle spatialite geometry columns better | 45057 | closed | 0 | 21 | 2018-05-21T08:46:55Z | 2022-03-21T22:22:20Z | 2022-03-21T22:22:20Z | CONTRIBUTOR | I'd like to see spatialite geometry columns rendered more sensibly - at the moment they come through as well-known-binary unless you use custom SQL, and WKB isn't of much use to anyone on the web. In HTML: they should be shown either as simple lat/long (if it's just a point, for example), or as a sensible placeholder if they're more complex geometries. In JSON: they should be GeoJSON geometries, (which means they can be automatically fed into a leaflet map with no further messing around). In CSV: they should be WKT. I briefly wondered if this should go into a plugin, but I suspect it needs hooking in at a deeper level than the plugin architecture will support any time soon. | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/276/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 923602693 | MDU6SXNzdWU5MjM2MDI2OTM= | 276 | support small help flag -h | 601708 | closed | 0 | 0 | 2021-06-17T07:59:31Z | 2021-06-18T14:56:59Z | 2021-06-18T14:56:59Z | CONTRIBUTOR | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/276/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||||
| 324836533 | MDExOlB1bGxSZXF1ZXN0MTg5MzE4NDUz | 277 | Refactor inspect logic | 45057 | closed | 0 | 2 | 2018-05-21T08:49:31Z | 2018-05-22T16:07:24Z | 2018-05-22T14:03:07Z | CONTRIBUTOR | simonw/datasette/pulls/277 | This pulls the logic for inspect out into a new file which makes it a bit easier to understand. This was going to be the first part of an implementation for #276, but it seems like that might take a while so I'm going to PR a few bits of refactoring individually. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/277/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 923612361 | MDExOlB1bGxSZXF1ZXN0NjcyMzU5NjA5 | 277 | add -h support closes #276 | 601708 | closed | 0 | 2 | 2021-06-17T08:08:26Z | 2021-06-18T14:56:59Z | 2021-06-18T14:56:59Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/277 | This appears to be the [canonical solution](https://click.palletsprojects.com/en/7.x/documentation/#help-parameter-customization). | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/277/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 923697888 | MDU6SXNzdWU5MjM2OTc4ODg= | 278 | Support db as first parameter before subcommand, or as environment variable | 601708 | closed | 0 | 3 | 2021-06-17T09:26:29Z | 2021-06-20T22:39:57Z | 2021-06-18T15:43:19Z | CONTRIBUTOR | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/278/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||||
| 325352370 | MDExOlB1bGxSZXF1ZXN0MTg5NzA3Mzc0 | 279 | Add version number support with Versioneer | 198537 | closed | 0 | 4 | 2018-05-22T15:39:45Z | 2018-05-22T19:35:23Z | 2018-05-22T19:35:22Z | CONTRIBUTOR | simonw/datasette/pulls/279 | I think that's all for getting Versioneer support, I've been happily using it in a couple of projects ... ``` In [2]: datasette.__version__ Out[2]: '0.22+3.g6e12445' ``` Repo: https://github.com/warner/python-versioneer Versioneer Licence: Public Domain (CC0-1.0) Closes #273 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/279/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 325373747 | MDExOlB1bGxSZXF1ZXN0MTg5NzIzNzE2 | 280 | Build Dockerfile with recent Sqlite + Spatialite | 565628 | closed | 0 | 10 | 2018-05-22T16:33:50Z | 2018-06-28T11:26:23Z | 2018-05-23T17:43:35Z | CONTRIBUTOR | simonw/datasette/pulls/280 | This solves #278 without bloating the Dockerfile too much, the image size is now 495MB (original was ~240MB) but it could be reduced significantly if we only copied the output of the compilation of spatialite and friends to /usr/local/lib, instead of the entirety of it however that will take more time. In the python code change references to `import sqlite3` to `import pysqlite3` and it should use the compiled version of sqlite3.23.1. You don't need to try/except because pysqlite3 falls back to builtin sqlite3 if there is no compiled version. ```bash $ docker run --rm -it datasette spatialite SpatiaLite version ..: 4.4.0-RC0 Supported Extensions: - 'VirtualShape' [direct Shapefile access] - 'VirtualDbf' [direct DBF access] - 'VirtualXL' [direct XLS access] - 'VirtualText' [direct CSV/TXT access] - 'VirtualNetwork' [Dijkstra shortest path] - 'RTree' [Spatial Index - R*Tree] - 'MbrCache' [Spatial Index - MBR cache] - 'VirtualSpatialIndex' [R*Tree metahandler] - 'VirtualElementary' [ElemGeoms metahandler] - 'VirtualKNN' [K-Nearest Neighbors metahandler] - 'VirtualXPath' [XML Path Language - XPath] - 'VirtualFDO' [FDO-OGR interoperability] - 'VirtualGPKG' [OGC GeoPackage interoperability] - 'VirtualBBox' [BoundingBox tables] - 'SpatiaLite' [Spatial SQL - OGC] PROJ.4 version ......: Rel. 4.9.3, 15 August 2016 GEOS version ........: 3.5.1-CAPI-1.9.1 r4246 TARGET CPU ..........: x86_64-linux-gnu the SPATIAL_REF_SYS table already contains some row(s) SQLite version ......: 3.23.1 Enter ".help" for instructions SQLite version 3.23.1 2018-04-10 17:39:29 Enter ".help" for instructions Enter SQL statements terminated with a ";" spatialite> ``` ```bash $ docker run --rm -it datasette python -c "import pysqlite3; print(pysqlite3.sqlite_version)" 3.23.1 ``` | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/280/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 979612115 | MDExOlB1bGxSZXF1ZXN0NzE5OTk4MjI1 | 322 | Add dict type to be mapped as TEXT in sqllite | 2496189 | closed | 0 | 1 | 2021-08-25T20:54:26Z | 2021-11-15T00:27:40Z | 2021-11-15T00:27:40Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/322 | the library deal with Postgres type jsonb as dictionary, add dict type as a TEXT for mapping to sqlite | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/322/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 988013247 | MDExOlB1bGxSZXF1ZXN0NzI3MDEyOTk2 | 324 | Use python-dateutil package instead of dateutils | 191622 | closed | 0 | 1 | 2021-09-03T18:31:19Z | 2021-11-14T23:25:40Z | 2021-11-14T23:25:40Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/324 | While working on updating `sqlite-utils` for NixOS/Nixpkgs, I came a cross the following: In 5ec6686153e29ae10d4921a1ad4c841f192f20e2, a new dependency was added on `dateutils` (https://pypi.org/project/dateutils/). I believe this is unintentional, and instead `python-dateutil` (https://pypi.org/project/python-dateutil/) was intended. My reasoning is: - `python-dateutil` is imported here in [recipes.py](https://github.com/simonw/sqlite-utils/blob/5ec6686153e29ae10d4921a1ad4c841f192f20e2/sqlite_utils/recipes.py#L1) - The `mypy` `type-python-dateutil` dependency in [setup.py](https://github.com/simonw/sqlite-utils/blob/5ec6686153e29ae10d4921a1ad4c841f192f20e2/setup.py#L36) - `python-dateutil` is a dependency of `dateutils` as seen in the output in [docs/tutorial.ipynb](https://github.com/simonw/sqlite-utils/blob/77c240df56068341561e95e4a412cbfa24dc5bc7/docs/tutorial.ipynb#L43) Seems like the trailing "s" seems to be the source of confusion 😅 I've swapped the dependencies out, hope this helps. | 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/324/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 336924199 | MDU6SXNzdWUzMzY5MjQxOTk= | 330 | Limit text display in cells containing large amounts of text | 82988 | closed | 0 | 4 | 2018-06-29T09:15:22Z | 2018-07-24T04:53:20Z | 2018-07-10T16:20:48Z | CONTRIBUTOR | The default preview of a database shows all columns (is the row count limited?) which is fine in many cases but can take a long time to load / offer a large overhead if the table is a SpatiaLite table containing geometry columns that include large shapefiles. Would it make sense to have a setting that can limit the amount of text displayed in any given cell in the table preview, or (less useful?) suppress (with notification) the display of overlong columns unless enabled by the user? An issue then arises if a user does want to see all the text in a cell: 1) for a particular cell; 2) for every cell in the table; 3) for all cells in a particular column or columns (I haven't checked but what if a column contains e.g. raw image data? Does this display as raw data? Or can this be rendered in a context aware way as an image preview? I guess a custom template would be one way to do that?) | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/330/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 336936010 | MDU6SXNzdWUzMzY5MzYwMTA= | 331 | Datasette throws error when loading spatialite db without extension loaded | 82988 | closed | 0 | 2 | 2018-06-29T09:51:14Z | 2022-01-20T21:29:40Z | 2018-07-10T15:13:36Z | CONTRIBUTOR | When starting datasette on a SpatialLite database *without* loading the SpatiaLite extension (using eg `--load-extension=/usr/local/lib/mod_spatialite.dylib`) an error is thrown and the server fails to start: ``` datasette -p 8003 adminboundaries.db Serve! files=('adminboundaries.db',) on port 8003 Traceback (most recent call last): File "/Users/ajh59/anaconda3/bin/datasette", line 11, in <module> sys.exit(cli()) File "/Users/ajh59/anaconda3/lib/python3.6/site-packages/click/core.py", line 722, in __call__ return self.main(*args, **kwargs) File "/Users/ajh59/anaconda3/lib/python3.6/site-packages/click/core.py", line 697, in main rv = self.invoke(ctx) File "/Users/ajh59/anaconda3/lib/python3.6/site-packages/click/core.py", line 1066, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/Users/ajh59/anaconda3/lib/python3.6/site-packages/click/core.py", line 895, in invoke return ctx.invoke(self.callback, **ctx.params) File "/Users/ajh59/anaconda3/lib/python3.6/site-packages/click/core.py", line 535, in invoke return callback(*args, **kwargs) File "/Users/ajh59/anaconda3/lib/python3.6/site-packages/datasette/cli.py", line 552, in serve ds.inspect() File "/Users/ajh59/anaconda3/lib/python3.6/site-packages/datasette/app.py", line 273, in inspect "tables": inspect_tables(conn, self.metadata.get("databases", {}).get(name, {})) File "/Users/ajh59/anaconda3/lib/python3.6/site-packages/datasette/inspect.py", line 79, in inspect_tables "PRAGMA table_info({});".format(escape_sqlite(table)) sqlite3.OperationalError: no such module: VirtualSpatialIndex ``` It would be nice to trap this and return a message saying something like: ``` It looks like you're trying to load a SpatiaLite database? Make sure you load in the SpatiaLite extension when starting datasette. Read more: https://datasette.readthedocs.io/en/latest/spatialite.html ``` | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/331/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1044267332 | I_kwDOCGYnMM4-PkFE | 336 | sqlite-util tranform --column-order mangles columns of type "timestamp" | 536941 | closed | 0 | 1 | 2021-11-04T01:15:38Z | 2023-05-08T21:13:38Z | 2023-05-08T21:13:38Z | CONTRIBUTOR | Reproducible code below: ```bash > echo 'create table bar (baz text, created_at timestamp default CURRENT_TIMESTAMP)' | sqlite3 foo.db > sqlite3 foo.db SQLite version 3.36.0 2021-06-18 18:36:39 Enter ".help" for usage hints. sqlite> .schema bar CREATE TABLE bar (baz text, created_at timestamp default CURRENT_TIMESTAMP); sqlite> .exit > sqlite-utils transform foo.db bar --column-order baz sqlite3 foo.db SQLite version 3.36.0 2021-06-18 18:36:39 Enter ".help" for usage hints. sqlite> .schema bar CREATE TABLE IF NOT EXISTS "bar" ( [baz] TEXT, [created_at] FLOAT DEFAULT 'CURRENT_TIMESTAMP' ); sqlite> .exit > sqlite-utils transform foo.db bar --column-order baz > sqlite3 foo.db SQLite version 3.36.0 2021-06-18 18:36:39 Enter ".help" for usage hints. sqlite> .schema bar CREATE TABLE IF NOT EXISTS "bar" ( [baz] TEXT, [created_at] FLOAT DEFAULT '''CURRENT_TIMESTAMP''' ); ``` | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/336/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 341228846 | MDU6SXNzdWUzNDEyMjg4NDY= | 343 | Render boolean fields better by default | 45057 | open | 0 | 1 | 2018-07-14T11:10:29Z | 2018-07-14T14:17:14Z | CONTRIBUTOR | These show up as 0 or 1 because sqlite. I think Yes/No would be fine in most cases? | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/343/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 341229113 | MDU6SXNzdWUzNDEyMjkxMTM= | 344 | datasette publish heroku fails without name provided | 45057 | closed | 0 | 1 | 2018-07-14T11:15:56Z | 2018-07-14T13:00:48Z | 2018-07-14T13:00:48Z | CONTRIBUTOR | It fails with the following JSON traceback if the `-n` option isn't provided, despite the fact that the command line help says that's not needed for heroku publishes. <details> ``` Traceback (most recent call last): File "/usr/local/bin/datasette", line 11, in <module> sys.exit(cli()) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 722, in __call__ return self.main(*args, **kwargs) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 697, in main rv = self.invoke(ctx) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 1066, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 895, in invoke return ctx.invoke(self.callback, **ctx.params) File "/usr/local/lib/python3.6/site-packages/click/core.py", line 535, in invoke return callback(*args, **kwargs) File "/usr/local/lib/python3.6/site-packages/datasette/cli.py", line 265, in publish app_name = json.loads(create_output)["name"] File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/__init__.py", line 354, in loads return _default_decoder.decode(s) File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/decoder.py", line 339, in decode obj, end = self.raw_decode(s, idx=_w(s, 0).end()) File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/decoder.py", line 357, in raw_decode raise JSONDecodeError("Expecting value", s, err.value) from None json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0) ``` </details> | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/344/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 341235633 | MDExOlB1bGxSZXF1ZXN0MjAxNDUxMzMy | 345 | Allow app names for `datasette publish heroku` | 45057 | closed | 0 | 1 | 2018-07-14T13:12:34Z | 2018-07-14T14:09:54Z | 2018-07-14T14:04:44Z | CONTRIBUTOR | simonw/datasette/pulls/345 | Lets you supply the `-n` parameter for Heroku deploys, which also lets you update existing Heroku deployments. | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/345/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 1077102934 | I_kwDOCGYnMM5AM0lW | 353 | Allow passing a file of code to "sqlite-utils convert" | 536941 | closed | 0 | 8 | 2021-12-10T18:06:14Z | 2021-12-11T01:38:29Z | 2021-12-11T01:09:39Z | CONTRIBUTOR | sqlite-utils is so nice, but the ergonomics of the multiline code in kind of tough. It's really hard (maybe impossible) to make the newlines play well with Makefiles. it would be great to write your code fragment in a separate file and direct it into the sqlite-utils either like ```sqlite-utils convert my.db my_table my_column < custom_code.py``` or ```sqlite-utils convert my.db my_table my_column --custom-code=custom_code.py``` Thanks, as ever, for these great tools! | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/353/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 361764460 | MDExOlB1bGxSZXF1ZXN0MjE2NjUxMzE3 | 365 | fix small doc typo | 418191 | closed | 0 | 2 | 2018-09-19T14:02:02Z | 2019-12-19T02:30:33Z | 2018-09-19T17:15:43Z | CONTRIBUTOR | simonw/datasette/pulls/365 | 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/365/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 1096558279 | I_kwDOCGYnMM5BXCbH | 365 | create-index should run analyze after creating index | 536941 | closed | 0 | 7558727 | 16 | 2022-01-07T18:21:25Z | 2022-01-11T02:43:34Z | 2022-01-11T01:36:48Z | CONTRIBUTOR | sqlite's query planner depends upon analyze to make good use of indices. It would be nice if analyze was run as part of the create-index command. If data is inserted later, things can get out date, but it would still probably be a net win. | 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/365/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 369716228 | MDU6SXNzdWUzNjk3MTYyMjg= | 366 | Default built image size over Zeit Now 100MiB limit | 416374 | closed | 0 | 2 | 2018-10-12T21:27:17Z | 2018-11-05T06:23:32Z | 2018-11-05T06:23:32Z | CONTRIBUTOR | Using `dataset publish now` with no other custom options on a small (43KB) sqlite database leads to the error "The built image size (373.5M) exceeds the 100MiB limit". I think this is because of a recent Zeit change: https://github.com/zeit/now-cli/issues/1523 | 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/366/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed |