github
| html_url | issue_url | id | node_id | user | created_at | updated_at | author_association | body | reactions | issue | performed_via_github_app |
|---|---|---|---|---|---|---|---|---|---|---|---|
| https://github.com/simonw/datasette/issues/1994#issuecomment-1399957897 | https://api.github.com/repos/simonw/datasette/issues/1994 | 1399957897 | IC_kwDOBm6k_c5TcamJ | 201897 | 2023-01-23T08:21:08Z | 2023-01-23T08:21:08Z | NONE | Me too, on a M1. Not sure if it's compatible? | {
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 1,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1536851861 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/issues/4#issuecomment-781451701 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/4 | 781451701 | MDEyOklzc3VlQ29tbWVudDc4MTQ1MTcwMQ== | 203343 | 2021-02-18T16:06:21Z | 2021-02-18T16:06:21Z | NONE | Awesome! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
778380836 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/issues/4#issuecomment-790198930 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/4 | 790198930 | MDEyOklzc3VlQ29tbWVudDc5MDE5ODkzMA== | 203343 | 2021-03-04T00:58:40Z | 2021-03-04T00:58:40Z | NONE | I am just seeing this sorry, yes! I will kick the tires later on tonight. My apologies for the delay. | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
778380836 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/issues/4#issuecomment-790934616 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/4 | 790934616 | MDEyOklzc3VlQ29tbWVudDc5MDkzNDYxNg== | 203343 | 2021-03-04T20:54:44Z | 2021-03-04T20:54:44Z | NONE | Sorry for the delay, I got sidetracked after class last night. I am getting the following error: ``` /content# google-takeout-to-sqlite mbox takeout.db Takeout/Mail/gmail.mbox Usage: google-takeout-to-sqlite [OPTIONS] COMMAND [ARGS]...Try 'google-takeout-to-sqlite --help' for help. Error: No such command 'mbox'. ``` On the box, I installed with pip after cloning: https://github.com/UtahDave/google-takeout-to-sqlite.git | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
778380836 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/pull/8#issuecomment-1002735370 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/8 | 1002735370 | IC_kwDODFE5qs47xIcK | 203343 | 2021-12-29T18:58:23Z | 2021-12-29T18:58:23Z | NONE | @maxhawkins how hard would it be to add an entry to the table that includes the HTML version of the email, if it exists? I just attempted your the PR branch on a very small mbox file, and it worked great. My use case is a research project and I need to access more than just the body plain text. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
954546309 | |
| https://github.com/simonw/datasette/issues/327#issuecomment-1043609198 | https://api.github.com/repos/simonw/datasette/issues/327 | 1043609198 | IC_kwDOBm6k_c4-NDZu | 208018 | 2022-02-17T23:21:36Z | 2022-02-17T23:33:01Z | NONE | On fly.io. This particular database goes from 1.4GB to 200M. Slower, part of that might be having no `--inspect-file`? ``` $ datasette publish fly ... --generate-dir /tmp/deploy-this ... $ mksquashfs large.db large.squashfs $ rm large.db # don't accidentally put it in the image $ cat Dockerfile FROM python:3.8 COPY . /app WORKDIR /app ENV DATASETTE_SECRET 'xyzzy' RUN pip install -U datasette # RUN datasette inspect large.db --inspect-file inspect-data.json ENV PORT 8080 EXPOSE 8080 CMD mount -o loop -t squashfs large.squashfs /mnt; datasette serve --host 0.0.0.0 -i /mnt/large.db --cors --port $PORT ``` It would also be possible to copy the file onto the ~6GB available on the ephemeral container filesystem on startup. A little against the spirit of the thing? On this example the whole docker image is 2.42 GB and the squashfs version is 1.14 GB. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
335200136 | |
| https://github.com/simonw/datasette/issues/327#issuecomment-1043626870 | https://api.github.com/repos/simonw/datasette/issues/327 | 1043626870 | IC_kwDOBm6k_c4-NHt2 | 208018 | 2022-02-17T23:37:24Z | 2022-02-17T23:37:24Z | NONE | On second thought any kind of quick-to-decompress-on-startup could be helpful if we're paying for the container registry and deployment bandwidth but not ephemeral storage. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
335200136 | |
| https://github.com/simonw/datasette/issues/1634#issuecomment-1065334891 | https://api.github.com/repos/simonw/datasette/issues/1634 | 1065334891 | IC_kwDOBm6k_c4_f7hr | 208018 | 2022-03-11T17:38:08Z | 2022-03-11T17:38:08Z | NONE | I noticed the image was large when using fly. Is it possible to use a -slim base? | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1131295060 | |
| https://github.com/simonw/datasette/pull/1574#issuecomment-1105464661 | https://api.github.com/repos/simonw/datasette/issues/1574 | 1105464661 | IC_kwDOBm6k_c5B5A1V | 208018 | 2022-04-21T16:51:24Z | 2022-04-21T16:51:24Z | NONE | tfw you have more ephemeral storage than upstream bandwidth ``` FROM python:3.10-slim AS base RUN apt update && apt -y install zstd ENV DATASETTE_SECRET 'sosecret' RUN --mount=type=cache,target=/root/.cache/pip pip install -U datasette datasette-pretty-json datasette-graphql ENV PORT 8080 EXPOSE 8080 FROM base AS pack COPY . /app WORKDIR /app RUN datasette inspect --inspect-file inspect-data.json RUN zstd --rm *.db FROM base AS unpack COPY --from=pack /app /app WORKDIR /app CMD ["/bin/bash", "-c", "shopt -s nullglob && zstd --rm -d *.db.zst && datasette serve --host 0.0.0.0 --cors --inspect-file inspect-data.json --metadata metadata.json --create --port $PORT *.db"] ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1084193403 | |
| https://github.com/simonw/datasette/issues/409#issuecomment-472875713 | https://api.github.com/repos/simonw/datasette/issues/409 | 472875713 | MDEyOklzc3VlQ29tbWVudDQ3Mjg3NTcxMw== | 209967 | 2019-03-14T14:14:39Z | 2019-03-14T14:14:39Z | NONE | also linking this zeit issue in case it is helpful: https://github.com/zeit/now-examples/issues/163#issuecomment-440125769 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
408376825 | |
| https://github.com/simonw/datasette/issues/417#issuecomment-751504136 | https://api.github.com/repos/simonw/datasette/issues/417 | 751504136 | MDEyOklzc3VlQ29tbWVudDc1MTUwNDEzNg== | 212369 | 2020-12-27T19:02:06Z | 2020-12-27T19:02:06Z | NONE | Very much looking forward to seeing this functionality come together. This is probably out-of-scope for an initial release, but in the future it could be useful to also think of how to run this is a container'ized context. For example, an immutable datasette container that points to an S3 bucket of SQLite DBs or CSVs. Or an immutable datasette container pointing to a NFS volume elsewhere on a Kubernetes cluster. | {
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
421546944 | |
| https://github.com/simonw/datasette/issues/185#issuecomment-370461231 | https://api.github.com/repos/simonw/datasette/issues/185 | 370461231 | MDEyOklzc3VlQ29tbWVudDM3MDQ2MTIzMQ== | 222245 | 2018-03-05T15:43:56Z | 2018-03-05T15:44:27Z | NONE | Yes. I think the simplest implementation is to change lines like ```python metadata = self.ds.metadata.get('databases', {}).get(name, {}) ``` to ```python metadata = { **self.ds.metadata, **self.ds.metadata.get('databases', {}).get(name, {}), } ``` so that specified inner values overwrite outer values, but only if they exist. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
299760684 | |
| https://github.com/simonw/datasette/issues/185#issuecomment-376590265 | https://api.github.com/repos/simonw/datasette/issues/185 | 376590265 | MDEyOklzc3VlQ29tbWVudDM3NjU5MDI2NQ== | 222245 | 2018-03-27T16:32:51Z | 2018-03-27T16:32:51Z | NONE | >I think the templates themselves should be able to indicate if they want the inherited values or not. That way we could support arbitrary key/values and avoid the application code having special knowledge of license_url etc. Yes, you could have `metadata` that works like `metadata` does currently and `inherited_metadata` that works with inheritance. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
299760684 | |
| https://github.com/simonw/datasette/issues/185#issuecomment-376592044 | https://api.github.com/repos/simonw/datasette/issues/185 | 376592044 | MDEyOklzc3VlQ29tbWVudDM3NjU5MjA0NA== | 222245 | 2018-03-27T16:38:23Z | 2018-03-27T16:38:23Z | NONE | It would be nice to also allow arbitrary keys (maybe under a parent key called params or something to prevent conflicts). For our datasette project, we just have a bunch of dictionaries defined in the base template for things like site URL and column humanized names: https://github.com/baltimore-sun-data/salaries-datasette/blob/master/templates/base.html It would be cleaner if this were in the metadata.json. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
299760684 | |
| https://github.com/simonw/datasette/issues/185#issuecomment-376614973 | https://api.github.com/repos/simonw/datasette/issues/185 | 376614973 | MDEyOklzc3VlQ29tbWVudDM3NjYxNDk3Mw== | 222245 | 2018-03-27T17:49:00Z | 2018-03-27T17:49:00Z | NONE | @simonw Other than metadata, the biggest item on wishlist for the salaries project was the ability to reorder by column. Of course, that could be done with a custom SQL query, but we didn't want to have to reimplement all the nav/pagination stuff from scratch. @carolinp, feel free to add your thoughts. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
299760684 | |
| https://github.com/simonw/datasette/issues/193#issuecomment-379142500 | https://api.github.com/repos/simonw/datasette/issues/193 | 379142500 | MDEyOklzc3VlQ29tbWVudDM3OTE0MjUwMA== | 222245 | 2018-04-06T04:05:58Z | 2018-04-06T04:05:58Z | NONE | You could try pulling out a validate query strings method. If it fails validation build the error object from the message. If it passes, you only need to go down a happy path. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
310882100 | |
| https://github.com/simonw/datasette/issues/184#issuecomment-379788103 | https://api.github.com/repos/simonw/datasette/issues/184 | 379788103 | MDEyOklzc3VlQ29tbWVudDM3OTc4ODEwMw== | 222245 | 2018-04-09T15:15:11Z | 2018-04-09T15:15:11Z | NONE | Visit https://salaries.news.baltimoresun.com/salaries/bad-table. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
292011379 | |
| https://github.com/simonw/datasette/issues/189#issuecomment-379791047 | https://api.github.com/repos/simonw/datasette/issues/189 | 379791047 | MDEyOklzc3VlQ29tbWVudDM3OTc5MTA0Nw== | 222245 | 2018-04-09T15:23:45Z | 2018-04-09T15:23:45Z | NONE | Awesome! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
309471814 | |
| https://github.com/simonw/datasette/issues/189#issuecomment-381429213 | https://api.github.com/repos/simonw/datasette/issues/189 | 381429213 | MDEyOklzc3VlQ29tbWVudDM4MTQyOTIxMw== | 222245 | 2018-04-15T18:54:22Z | 2018-04-15T18:54:22Z | NONE | I think I found a bug. I tried to sort by middle initial in my salaries set, and many middle initials are null. The next_url gets set by Datasette to: http://localhost:8001/salaries-d3a5631/2017+Maryland+state+salaries?_next=None%2C391&_sort=middle_initial But then `None` is interpreted literally and it tries to find a name with the middle initial "None" and ends up skipping ahead to O on page 2. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
309471814 | |
| https://github.com/simonw/datasette/issues/185#issuecomment-412663658 | https://api.github.com/repos/simonw/datasette/issues/185 | 412663658 | MDEyOklzc3VlQ29tbWVudDQxMjY2MzY1OA== | 222245 | 2018-08-13T21:04:11Z | 2018-08-13T21:04:11Z | NONE | That seems good to me. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
299760684 | |
| https://github.com/simonw/datasette/issues/227#issuecomment-439194286 | https://api.github.com/repos/simonw/datasette/issues/227 | 439194286 | MDEyOklzc3VlQ29tbWVudDQzOTE5NDI4Ng== | 222245 | 2018-11-15T21:20:37Z | 2018-11-15T21:20:37Z | NONE | I'm diving back into https://salaries.news.baltimoresun.com and what I really want is the ability to inject the request into my context. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
315960272 | |
| https://github.com/simonw/datasette/pull/426#issuecomment-485557574 | https://api.github.com/repos/simonw/datasette/issues/426 | 485557574 | MDEyOklzc3VlQ29tbWVudDQ4NTU1NzU3NA== | 222245 | 2019-04-22T21:23:22Z | 2019-04-22T21:23:22Z | NONE | Can you cut a new release with this? | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
431756352 | |
| https://github.com/simonw/datasette/issues/184#issuecomment-494459264 | https://api.github.com/repos/simonw/datasette/issues/184 | 494459264 | MDEyOklzc3VlQ29tbWVudDQ5NDQ1OTI2NA== | 222245 | 2019-05-21T16:17:29Z | 2019-05-21T16:17:29Z | NONE | Reopening this because it still raises 500 for incorrect table capitalization. Example: - https://salaries.news.baltimoresun.com/salaries/2018+Maryland+state+salaries/1 200 OK - https://salaries.news.baltimoresun.com/salaries/bad-table/1 400 - https://salaries.news.baltimoresun.com/salaries/2018+maryland+state+salaries/1 500 Internal Error (note lowercase 'm') I think because the table name exists but is not in its canonical form, it triggers a dict lookup error. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
292011379 | |
| https://github.com/simonw/datasette/issues/782#issuecomment-712569695 | https://api.github.com/repos/simonw/datasette/issues/782 | 712569695 | MDEyOklzc3VlQ29tbWVudDcxMjU2OTY5NQ== | 222245 | 2020-10-20T03:45:48Z | 2020-10-20T03:46:14Z | NONE | I vote against headers. It has a lot of strikes against it: poor discoverability, new developers often don’t know how to use them, makes CORS harder, makes it hard to use eg with JQ, needs ad hoc specification for each bit of metadata, etc. The only advantage of headers is that you don’t need to do .rows, but that’s actually good as a data validation step anyway—if .rows is missing assume there’s an error and do your error handling path instead of parsing the rest. | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
627794879 | |
| https://github.com/simonw/datasette/issues/983#issuecomment-754210356 | https://api.github.com/repos/simonw/datasette/issues/983 | 754210356 | MDEyOklzc3VlQ29tbWVudDc1NDIxMDM1Ng== | 222245 | 2021-01-04T20:49:05Z | 2021-01-04T20:49:05Z | NONE | For reasons [I've written about elsewhere](https://blog.carlmjohnson.net/post/2020/time-to-kill-ie11/), I'm in favor of modules. It has several beneficial effects. One, old browsers just ignore it all together. Two, if you include the same plain script on the page more than once, it will be executed twice, but if you include the same module script on a page twice, it will only execute once. Three, you get a module local namespace, instead of having to use the global window namespace or a function private namespace. OTOH, if you are going to use an old style script, the code from before isn't ideal, because you wipe out your registry if the script it included more than once. Also you may as well use object methods and splat arguments. The event based architecture probably makes more sense though. Just make up some event names prefixed with `datasette:` and listen for them on the root. The only concern with that approach is it can sometimes be tricky to make sure your plugins are run after datasette has run. Maybe ```js function mycallback(){ // whatever } if (window.datasette) { window.datasette.init(mycallback); } else { document.addEventListener('datasette:init', mycallback); } ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
712260429 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/issues/2#issuecomment-747130908 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/2 | 747130908 | MDEyOklzc3VlQ29tbWVudDc0NzEzMDkwOA== | 231498 | 2020-12-17T00:47:04Z | 2020-12-17T00:47:43Z | NONE | it looks like almost all of the memory consumption is coming from `json.load()`. another direction here may be to use the new "Semantic Location History" data which is already broken down by year and month. it also provides much more interesting data, such as estimated address, form of travel, etc. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
769376447 | |
| https://github.com/dogsheep/github-to-sqlite/issues/64#issuecomment-860895838 | https://api.github.com/repos/dogsheep/github-to-sqlite/issues/64 | 860895838 | MDEyOklzc3VlQ29tbWVudDg2MDg5NTgzOA== | 231498 | 2021-06-14T18:23:21Z | 2021-06-14T21:37:35Z | NONE | i have a basic working version at https://github.com/khimaros/github-to-sqlite this can be tested with `github-to-sqlite events.db khimaros/events` caveat: the GitHub API doesn't seem to provide a complete history of events. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
920636216 | |
| https://github.com/dogsheep/github-to-sqlite/issues/64#issuecomment-861035862 | https://api.github.com/repos/dogsheep/github-to-sqlite/issues/64 | 861035862 | MDEyOklzc3VlQ29tbWVudDg2MTAzNTg2Mg== | 231498 | 2021-06-14T22:29:20Z | 2021-06-14T22:29:20Z | NONE | it looks like the v4 GraphQL API is the only way to get data beyond 90 days from GitHub. this is significant change, but may be worth considering in the future. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
920636216 | |
| https://github.com/dogsheep/github-to-sqlite/issues/64#issuecomment-861087651 | https://api.github.com/repos/dogsheep/github-to-sqlite/issues/64 | 861087651 | MDEyOklzc3VlQ29tbWVudDg2MTA4NzY1MQ== | 231498 | 2021-06-15T00:48:37Z | 2021-06-15T00:48:37Z | NONE | @simonw -- i've created an omega-query that fetched most of what was interesting to me for a single user. found by poking around in the "Explorer" tab in https://docs.github.com/en/graphql/overview/explorer note: pagination is still required via `first` and `last` but it seems to allow unlimited history. ``` query MyQuery { __typename user(login: "<user>") { id pinnedItems(first: 100) { edges { node } } pullRequests(first: 100) { nodes { body title state createdAt } } createdAt issues(first: 100) { pageInfo { endCursor startCursor } nodes { title url createdAt body } } issueComments(first: 100) { edges { node { id updatedAt url body } } } repositories(first: 100) { nodes { createdAt description parent { name } pinnedIssues(first: 100) { edges { node { id } } } pinnedDiscussions(first: 100) { edges { node { id } } } } } starredRepositories(first: 100) { edges { node { id } } } } } ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
920636216 | |
| https://github.com/dogsheep/github-to-sqlite/pull/65#issuecomment-885964242 | https://api.github.com/repos/dogsheep/github-to-sqlite/issues/65 | 885964242 | IC_kwDODFdgUs40zr3S | 231498 | 2021-07-23T23:45:35Z | 2021-07-23T23:45:35Z | NONE | @simonw is this PR of interest to you? | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
923270900 | |
| https://github.com/dogsheep/github-to-sqlite/pull/65#issuecomment-1266141699 | https://api.github.com/repos/dogsheep/github-to-sqlite/issues/65 | 1266141699 | IC_kwDODFdgUs5Ld8oD | 231498 | 2022-10-03T22:35:03Z | 2022-10-03T22:35:03Z | NONE | @simonw rebased against latest, please let me know if i should drop this PR. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
923270900 | |
| https://github.com/simonw/datasette/issues/97#issuecomment-345509500 | https://api.github.com/repos/simonw/datasette/issues/97 | 345509500 | MDEyOklzc3VlQ29tbWVudDM0NTUwOTUwMA== | 231923 | 2017-11-19T11:26:58Z | 2017-11-19T11:26:58Z | NONE | Specifically docs should make it clearer this file exists https://parlgov.datasettes.com/.json And from that you can build https://parlgov.datasettes.com/parlgov-25f9855.json Then https://parlgov.datasettes.com/parlgov-25f9855/cabinet.json | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
274022950 | |
| https://github.com/simonw/datasette/issues/265#issuecomment-392890045 | https://api.github.com/repos/simonw/datasette/issues/265 | 392890045 | MDEyOklzc3VlQ29tbWVudDM5Mjg5MDA0NQ== | 231923 | 2018-05-29T18:37:49Z | 2018-05-29T18:37:49Z | NONE | Just about to ask for this! Move this page https://github.com/simonw/datasette/wiki/Datasettes into a datasette, with some concept of versioning as well. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
323677499 | |
| https://github.com/simonw/datasette/issues/97#issuecomment-392895733 | https://api.github.com/repos/simonw/datasette/issues/97 | 392895733 | MDEyOklzc3VlQ29tbWVudDM5Mjg5NTczMw== | 231923 | 2018-05-29T18:51:35Z | 2018-05-29T18:51:35Z | NONE | Do you have an existing example with views? | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
274022950 | |
| https://github.com/dogsheep/twitter-to-sqlite/issues/57#issuecomment-860063190 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/57 | 860063190 | MDEyOklzc3VlQ29tbWVudDg2MDA2MzE5MA== | 232237 | 2021-06-12T14:46:44Z | 2021-06-12T14:46:44Z | NONE | I'm having the same issue (same versions of python and twitter-to-sqlite). It's the `user-timeline` command. Other commands are working. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
907645813 | |
| https://github.com/simonw/datasette/issues/1032#issuecomment-712397537 | https://api.github.com/repos/simonw/datasette/issues/1032 | 712397537 | MDEyOklzc3VlQ29tbWVudDcxMjM5NzUzNw== | 236498 | 2020-10-19T19:37:55Z | 2020-10-19T19:37:55Z | NONE | python-dateutil is awesome, but it can only guess at one date at a time. So if you have a column of dates that are (presumably) in the same format, it can't use the full set of dates to deduce the format. Also, once it has parsed a date, you can't get the format it used, whether to parse or render other dates. These limitations prevent it from being a silver bullet for date parsing, though they're not enough for me to stop using it! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
724878151 | |
| https://github.com/simonw/sqlite-utils/issues/448#issuecomment-1162498734 | https://api.github.com/repos/simonw/sqlite-utils/issues/448 | 1162498734 | IC_kwDOCGYnMM5FSlKu | 236907 | 2022-06-22T00:43:45Z | 2022-06-22T00:43:45Z | NONE | Attempted to test on a machine with a new version of Python, but install failed with an error message for the 'click' package. ``` C:\WINDOWS\system32>"c:\Program Files\Python310\python.exe" Python 3.10.2 (tags/v3.10.2:a58ebcc, Jan 17 2022, 14:12:15) [MSC v.1929 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> quit() C:\WINDOWS\system32>cd C:\Users\swood\Downloads\sqlite-utils-main-20220621\sqlite-utils-main C:\Users\swood\Downloads\sqlite-utils-main-20220621\sqlite-utils-main>"c:\Program Files\Python310\python.exe" setup.py install running install running bdist_egg running egg_info ... Installed c:\program files\python310\lib\site-packages\click_default_group_wheel-1.2.2-py3.10.egg Searching for click Downloading https://files.pythonhosted.org/packages/3d/da/f3bbf30f7e71d881585d598f67f4424b2cc4c68f39849542e81183218017/click-default-group-wheel-1.2.2.tar.gz#sha256=e90da42d92c03e88a12ed0c0b69c8a29afb5d36e3dc8d29c423ba4219e6d7747 Best match: click default-group-wheel-1.2.2 Processing click-default-group-wheel-1.2.2.tar.gz Writing C:\Users\swood\AppData\Local\Temp\easy_install-aiaj0_eh\click-default-group-wheel-1.2.2\setup.cfg Running click-default-group-wheel-1.2.2\setup.py -q bdist_egg --dist-dir C:\Users\swood\AppData\Local\Temp\easy_install-aiaj0_eh\click-default-group-wheel-1.2.2\egg-dist-tmp-z61a4h8n zip_safe flag not set; analyzing archive contents... removing 'c:\program files\python310\lib\site-packages\click_default_group_wheel-1.2.2-py3.10.egg' (and everything under it) Copying click_default_group_wheel-1.2.2-py3.10.egg to c:\program files\python310\lib\site-packages click-default-group-wheel 1.2.2 is already the active version in easy-install.pth Installed c:\program files\python310\lib\site-packages\click_default_group_wheel-1.2.2-py3.10.egg error: The 'click' distribution was not found and is required by click-default-group-wheel, sqlite-utils ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1279144769 | |
| https://github.com/simonw/sqlite-utils/issues/448#issuecomment-1162500525 | https://api.github.com/repos/simonw/sqlite-utils/issues/448 | 1162500525 | IC_kwDOCGYnMM5FSlmt | 236907 | 2022-06-22T00:46:43Z | 2022-06-22T00:46:43Z | NONE | [log.txt](https://github.com/simonw/sqlite-utils/files/8953589/log.txt) | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1279144769 | |
| https://github.com/simonw/datasette/issues/254#issuecomment-388367027 | https://api.github.com/repos/simonw/datasette/issues/254 | 388367027 | MDEyOklzc3VlQ29tbWVudDM4ODM2NzAyNw== | 247131 | 2018-05-11T13:41:46Z | 2018-05-11T13:41:46Z | NONE | An example deployment @ https://datasette-zkcvlwdrhl.now.sh/simplestreams-270f20c/cloudimage?content_id__exact=com.ubuntu.cloud%3Areleased%3Adownload It is not causing errors, more of an inconvenience. I have worked around it using a `like` query instead. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
322283067 | |
| https://github.com/simonw/datasette/pull/258#issuecomment-390577711 | https://api.github.com/repos/simonw/datasette/issues/258 | 390577711 | MDEyOklzc3VlQ29tbWVudDM5MDU3NzcxMQ== | 247131 | 2018-05-21T07:38:15Z | 2018-05-21T07:38:15Z | NONE | Excellent, I was not aware of the auto redirect to the new hash. My bad This solves my use case. I do agree that your suggested --no-url-hash approach is much neater. I will investigate | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
322741659 | |
| https://github.com/simonw/datasette/issues/254#issuecomment-626340387 | https://api.github.com/repos/simonw/datasette/issues/254 | 626340387 | MDEyOklzc3VlQ29tbWVudDYyNjM0MDM4Nw== | 247131 | 2020-05-10T14:54:13Z | 2020-05-10T14:54:13Z | NONE | This has now been resolved and is not present in current version of datasette. Sample query @simonw mentioned now returns as expected. https://aggreg8streams.tinyviking.ie/simplestreams?sql=select+*+from+cloudimage+where+%22content_id%22+%3D+%22com.ubuntu.cloud%3Areleased%3Adownload%22+order+by+id+limit+10 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
322283067 | |
| https://github.com/simonw/datasette/issues/1497#issuecomment-1387433455 | https://api.github.com/repos/simonw/datasette/issues/1497 | 1387433455 | IC_kwDOBm6k_c5Sso3v | 270255 | 2023-01-18T17:13:45Z | 2023-01-18T17:13:45Z | NONE | You may have just been talking to yourself here, but I found your documentation of the process incredibly useful when I hit the same error myself. Thanks! 🌈 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1034535001 | |
| https://github.com/simonw/datasette/issues/2093#issuecomment-1616195496 | https://api.github.com/repos/simonw/datasette/issues/2093 | 1616195496 | IC_kwDOBm6k_c5gVS-o | 273509 | 2023-07-02T00:06:54Z | 2023-07-02T00:07:17Z | NONE | I'm not keen on requiring metadata to be within the database. I commonly have multiple DBs, from various sources, and having one config file to provide the metadata works out very well. I use Datasette with databases where I'm not the original source, needing to mutate them to add a metadata table or sqlite-docs makes me uncomfortable. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1781530343 | |
| https://github.com/simonw/datasette/issues/1050#issuecomment-718317997 | https://api.github.com/repos/simonw/datasette/issues/1050 | 718317997 | MDEyOklzc3VlQ29tbWVudDcxODMxNzk5Nw== | 283343 | 2020-10-29T02:24:50Z | 2020-10-29T02:29:24Z | NONE | Unsolicited feedback for an unreleased feature of the [current](https://github.com/simonw/datasette/commit/5e0b72247ecab4ce0fcec599b77a83d73a480872) unreleased GitHub version (I casually wanted to access a blob row) – the existing #1036 route doesn't support special characters in database or table names (e.g. `@()` ). Maybe this is motivation for your new idea here. Also I got this error/crash with my blob and wasn't able to get the file: https://gist.github.com/thadk/28ac32af0e88747ce9056c90b0b19d34 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
729057388 | |
| https://github.com/simonw/sqlite-utils/issues/227#issuecomment-779785638 | https://api.github.com/repos/simonw/sqlite-utils/issues/227 | 779785638 | MDEyOklzc3VlQ29tbWVudDc3OTc4NTYzOA== | 295329 | 2021-02-16T11:48:03Z | 2021-02-16T11:48:03Z | NONE | Thank you @simonw | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
807174161 | |
| https://github.com/simonw/datasette/issues/276#issuecomment-744461856 | https://api.github.com/repos/simonw/datasette/issues/276 | 744461856 | MDEyOklzc3VlQ29tbWVudDc0NDQ2MTg1Ng== | 296686 | 2020-12-14T14:04:57Z | 2020-12-14T14:04:57Z | NONE | I'm looking into using datasette with a database with spatialite geometry columns, and came across this issue. Has there been any progress on this since 2018? In one of my tables I'm just storing lat/lon points in a spatialite point geometry, and I've managed to make datasette-cluster-map display the points by extracting the lat and lon in SQL - using something like `select ... ST_X(location) as longitude, ST_Y(location) as latitude from Blah`. Something more 'built-in' would be great though - particularly for the tables I have that store more complex geometries. | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
324835838 | |
| https://github.com/simonw/datasette/pull/1031#issuecomment-714289680 | https://api.github.com/repos/simonw/datasette/issues/1031 | 714289680 | MDEyOklzc3VlQ29tbWVudDcxNDI4OTY4MA== | 299380 | 2020-10-22T07:23:52Z | 2020-10-22T07:23:52Z | NONE | The bug is that currently when there are databases passed in, but no -i flag, e.g. in configuration directory mode, inclusion in inspect-data.json does not automatically cause databases to be considered immutable, as described in the documentation. The reason is that the -i flag is specified multiple=True, which means when it is not passed in we will get an empty list [], rather than None. So the current code decides that no databases are immutable rather than falling back to inspect-data.json -- as is presumably intended. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
724369025 | |
| https://github.com/simonw/datasette/pull/1031#issuecomment-744003454 | https://api.github.com/repos/simonw/datasette/issues/1031 | 744003454 | MDEyOklzc3VlQ29tbWVudDc0NDAwMzQ1NA== | 299380 | 2020-12-13T12:52:56Z | 2020-12-13T12:52:56Z | NONE | Please let me know if there's anything I can do to help get this merged. This is causing problems for me because it means when I build my Docker image my databases aren't considered immutable, which I would like them to be so that a download link is produced. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
724369025 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/issues/4#issuecomment-780817596 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/4 | 780817596 | MDEyOklzc3VlQ29tbWVudDc4MDgxNzU5Ng== | 306240 | 2021-02-17T20:01:35Z | 2021-02-17T20:01:35Z | NONE | I've got this almost working. Just needs some polish | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
778380836 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/issues/4#issuecomment-783688547 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/4 | 783688547 | MDEyOklzc3VlQ29tbWVudDc4MzY4ODU0Nw== | 306240 | 2021-02-22T21:31:28Z | 2021-02-22T21:31:28Z | NONE | @Btibert3 I've opened a PR with my initial attempt at this. Would you be willing to give this a try? https://github.com/dogsheep/google-takeout-to-sqlite/pull/5 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
778380836 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/pull/5#issuecomment-783794520 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/5 | 783794520 | MDEyOklzc3VlQ29tbWVudDc4Mzc5NDUyMA== | 306240 | 2021-02-23T01:13:54Z | 2021-02-23T01:13:54Z | NONE | Also, @simonw I created a test based off the existing tests. I think it's working correctly | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
813880401 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/pull/5#issuecomment-784638394 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/5 | 784638394 | MDEyOklzc3VlQ29tbWVudDc4NDYzODM5NA== | 306240 | 2021-02-24T00:36:18Z | 2021-02-24T00:36:18Z | NONE | I noticed that @simonw is using black for formatting. I ran black on my additions in this PR. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
813880401 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/pull/5#issuecomment-790389335 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/5 | 790389335 | MDEyOklzc3VlQ29tbWVudDc5MDM4OTMzNQ== | 306240 | 2021-03-04T07:32:04Z | 2021-03-04T07:32:04Z | NONE | > The command takes quite a while to start running, presumably because this line causes it to have to scan the WHOLE file in order to generate a count: > > https://github.com/dogsheep/google-takeout-to-sqlite/blob/a3de045eba0fae4b309da21aa3119102b0efc576/google_takeout_to_sqlite/utils.py#L66-L67 > > I'm fine with waiting though. It's not like this is a command people run every day - and without that count we can't show a progress bar, which seems pretty important for a process that takes this long. The wait is from python loading the mbox file. This happens regardless if you're getting the length of the mbox. The mbox module is on the slow side. It is possible to do one's own parsing of the mbox, but I kind of wanted to avoid doing that. | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
813880401 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/pull/5#issuecomment-790391711 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/5 | 790391711 | MDEyOklzc3VlQ29tbWVudDc5MDM5MTcxMQ== | 306240 | 2021-03-04T07:36:24Z | 2021-03-04T07:36:24Z | NONE | > Looks like you're doing this: > > ```python > elif message.get_content_type() == "text/plain": > body = message.get_payload(decode=True) > ``` > > So presumably that decodes to a unicode string? > > I imagine the reason the column is a `BLOB` for me is that `sqlite-utils` determines the column type based on the first batch of items - https://github.com/simonw/sqlite-utils/blob/09c3386f55f766b135b6a1c00295646c4ae29bec/sqlite_utils/db.py#L1927-L1928 - and I got unlucky and had something in my first batch that wasn't a unicode string. Ah, that's good to know. I think explicitly creating the tables will be a great improvement. I'll add that. Also, I noticed after I opened this PR that the `message.get_payload()` is being deprecated in favor of `message.get_content()` or something like that. I'll see if that handles the decoding better, too. Thanks for the feedback. I should have time tomorrow to put together some improvements. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
813880401 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/pull/5#issuecomment-791530093 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/5 | 791530093 | MDEyOklzc3VlQ29tbWVudDc5MTUzMDA5Mw== | 306240 | 2021-03-05T16:28:07Z | 2021-03-05T16:28:07Z | NONE | > I just tried to run this on a small VPS instance with 2GB of memory and it crashed out of memory while processing a 12GB mbox from Takeout. > > Is it possible to stream the emails to sqlite instead of loading it all into memory and upserting at once? @maxhawkins a limitation of the python mbox module is it loads the entire mbox into memory. I did find another approach to this problem that didn't use the builtin python mbox module and created a generator so that it didn't have to load the whole mbox into memory. I was hoping to use standard library modules, but this might be a good reason to investigate that approach a bit more. My worry is making sure a custom processor handles all the ins and outs of the mbox format correctly. Hm. As I'm writing this, I thought of something. I think I can parse each message one at a time, and then use an mbox function to load each message using the python mbox module. That way the mbox module can still deal with the specifics of the mbox format, but I can use a generator. I'll give that a try. Thanks for the feedback @maxhawkins and @simonw. I'll give that a try. @simonw can we hold off on merging this until I can test this new approach? | {
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
813880401 | |
| https://github.com/dogsheep/google-takeout-to-sqlite/pull/5#issuecomment-885098025 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/5 | 885098025 | IC_kwDODFE5qs40wYYp | 306240 | 2021-07-22T17:47:50Z | 2021-07-22T17:47:50Z | NONE | Hi @maxhawkins , I'm sorry, I haven't had any time to work on this. I'll have some time tomorrow to test your commits. I think they look great. I'm great with your commits superseding my initial attempt here. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
813880401 | |
| https://github.com/simonw/datasette/issues/1608#issuecomment-1017993482 | https://api.github.com/repos/simonw/datasette/issues/1608 | 1017993482 | IC_kwDOBm6k_c48rVkK | 316517 | 2022-01-20T22:46:16Z | 2022-01-20T22:46:16Z | NONE | Or you can use https://sphinx-version-warning.readthedocs.io/! 😄 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1109808154 | |
| https://github.com/simonw/datasette/issues/514#issuecomment-539721880 | https://api.github.com/repos/simonw/datasette/issues/514 | 539721880 | MDEyOklzc3VlQ29tbWVudDUzOTcyMTg4MA== | 319156 | 2019-10-08T22:00:03Z | 2019-10-08T22:00:03Z | NONE | If you are just using Nginx to open a reserved port, systemd can do that on its own. https://www.freedesktop.org/software/systemd/man/systemd.socket.html. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
459397625 | |
| https://github.com/dogsheep/dogsheep-photos/pull/38#issuecomment-1656694854 | https://api.github.com/repos/dogsheep/dogsheep-photos/issues/38 | 1656694854 | IC_kwDOD079W85ivyhG | 319473 | 2023-07-29T10:00:45Z | 2023-07-29T10:00:45Z | NONE | Ran across https://github.com/dogsheep/dogsheep-photos/issues/33 which is the same subject. My PR just fixes docs | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1827427757 | |
| https://github.com/dogsheep/dogsheep-photos/pull/38#issuecomment-1656694944 | https://api.github.com/repos/dogsheep/dogsheep-photos/issues/38 | 1656694944 | IC_kwDOD079W85ivyig | 319473 | 2023-07-29T10:01:19Z | 2023-07-29T10:01:19Z | NONE | Duplicate of https://github.com/dogsheep/dogsheep-photos/pull/36 - closing. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1827427757 | |
| https://github.com/dogsheep/dogsheep-photos/pull/31#issuecomment-1656696679 | https://api.github.com/repos/dogsheep/dogsheep-photos/issues/31 | 1656696679 | IC_kwDOD079W85ivy9n | 319473 | 2023-07-29T10:10:29Z | 2023-07-29T10:10:29Z | NONE | +1 to getting this merged down. For future googlers, I installed by... ``` git clone git@github.com:RhetTbull/dogsheep-photos.git cd dogsheep-photos git checkout update_for_bigsur python setup.py install ``` | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
771511344 | |
| https://github.com/dogsheep/healthkit-to-sqlite/issues/14#issuecomment-1073123231 | https://api.github.com/repos/dogsheep/healthkit-to-sqlite/issues/14 | 1073123231 | IC_kwDOC8tyDs4_9o-f | 343884 | 2022-03-19T22:39:29Z | 2022-03-19T22:39:29Z | NONE | I have this issue, too, with a fresh export. None of my `Workout` entries in `export.xml` have an `id` key, though [the sample `export.xml` in the tests folder doesn’t either](https://github.com/dogsheep/healthkit-to-sqlite/blob/main/tests/zip_contents/apple_health_export/export.xml#L14-L21), so I don’t think this is the culprit. Indeed, it seems @simonw is using the [`hash_id` function from `sqlite_utils`](https://sqlite-utils.datasette.io/en/stable/python-api.html#setting-an-id-based-on-the-hash-of-the-row-contents), which creates a column (`id`, in this case) based on a hash of the row’s contents. When I run the script, a `workouts` table is created, with one entry: my first workout. No `workout_points` table is created, as [I’d expect from `utils.py`](https://github.com/dogsheep/healthkit-to-sqlite/blob/main/healthkit_to_sqlite/utils.py#L89-L90). I then get essentially the same error as noted in this thread: ```Importing from HealthKit [###################################-] 98% 00:00:01 Traceback (most recent call last): File "/Users/lchski/.pyenv/versions/3.10.3/bin/healthkit-to-sqlite", line 8, in <module> sys.exit(cli()) File "/Users/lchski/.pyenv/versions/3.10.3/lib/python3.10/site-packages/click/core.py", line 1128, in __call__ return self.main(*args, **kwargs) File "/Users/lchski/.pyenv/versions/3.10.3/lib/python3.10/site-packages/click/core.py", line 1053, in main rv = self.invoke(ctx) File "/Users/lchski/.pyenv/versions/3.10.3/lib/python3.10/site-packages/click/core.py", line 1395, in invoke return ctx.invoke(self.callback, **ctx.params) File "/Users/lchski/.pyenv/versions/3.10.3/lib/python3.10/site-packages/click/core.py", line 754, in invoke return __callback(*args, **kwargs) File "/Users/lchski/.pyenv/versions/3.10.3/lib/python3.10/site-packages/healthkit_to_sqlite/cli.py", line 57, in cli convert_xml_to_sqlite(fp, db, progress_callback=bar.update, zipfile=zf) File "/Users/lchski/.pyenv/versions/3.10.3/lib/python3.10/site-packages/health… | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
771608692 | |
| https://github.com/dogsheep/healthkit-to-sqlite/issues/14#issuecomment-1073139067 | https://api.github.com/repos/dogsheep/healthkit-to-sqlite/issues/14 | 1073139067 | IC_kwDOC8tyDs4_9s17 | 343884 | 2022-03-20T00:54:18Z | 2022-03-20T00:54:18Z | NONE | Update: this appears to be because of running the command twice without clearing the DB in between. Tries to insert a Workout that already exists, causing a collision on the (auto-generated) `id` column. Had a different error with a clean DB, likely due to the workout points format; will make a new issue for that. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
771608692 | |
| https://github.com/simonw/sqlite-utils/issues/239#issuecomment-960292442 | https://api.github.com/repos/simonw/sqlite-utils/issues/239 | 960292442 | IC_kwDOCGYnMM45POZa | 350038 | 2021-11-03T23:28:55Z | 2021-11-03T23:28:55Z | NONE | I am super interested in this feature. After reading the other issues you referenced, I think the right way would be to use the current extract feature and then to use `sqlite-utils convert` to extract the json object into individual columns | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
816526538 | |
| https://github.com/simonw/sqlite-utils/issues/239#issuecomment-960295228 | https://api.github.com/repos/simonw/sqlite-utils/issues/239 | 960295228 | IC_kwDOCGYnMM45PPE8 | 350038 | 2021-11-03T23:35:37Z | 2021-11-03T23:36:50Z | NONE | I think I only wonder how I would parse the JSON `value` within such a lambda... My naive approach would have been `$ sqlite-utils convert demo.db statuses statuses 'return value' --multi` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
816526538 | |
| https://github.com/simonw/datasette/issues/1522#issuecomment-976023405 | https://api.github.com/repos/simonw/datasette/issues/1522 | 976023405 | IC_kwDOBm6k_c46LO9t | 360895 | 2021-11-23T00:08:07Z | 2021-11-23T00:08:07Z | NONE | If you suspect that Cloud Run throttled CPU could be the cause, you can request to have CPU always allocated with `gcloud beta run deploy --no-cpu-throttling` ([read more](https://cloud.google.com/blog/products/serverless/cloud-run-gets-always-on-cpu-allocation)) It could also be the Cloud Run sandbox that somehow gets in the way here, in which case I recommend testing with the second generation execution environment: `gcloud beta run deploy --execution-environment gen2` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1058896236 | |
| https://github.com/simonw/datasette/issues/1479#issuecomment-1709373304 | https://api.github.com/repos/simonw/datasette/issues/1479 | 1709373304 | IC_kwDOBm6k_c5l4vd4 | 363004 | 2023-09-07T02:14:15Z | 2023-09-07T02:14:15Z | NONE | I ran into the same issue on Windows using `datasette publish cloudrun mydatabase.db --service=my-database` do do a [google cloud publish](https://docs.datasette.io/en/stable/publish.html). @Rik-de-Kort your fix worked perfectly! Thanks! I can always go back and delete the temp directories myself :) | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1010112818 | |
| https://github.com/simonw/datasette/issues/411#issuecomment-1779267468 | https://api.github.com/repos/simonw/datasette/issues/411 | 1779267468 | IC_kwDOBm6k_c5qDXeM | 363004 | 2023-10-25T13:23:04Z | 2023-10-25T13:23:04Z | NONE | Using the [Counties example](https://us-counties.datasette.io/counties/county_for_latitude_longitude?longitude=-122&latitude=37), I was able to pull out the MakePoint method as MakePoint(cast(rm_rnb_history_pres.rx_lng as float), cast(rm_rnb_history_pres.rx_lat as float)) as geometry which worked, giving me a geometry column. 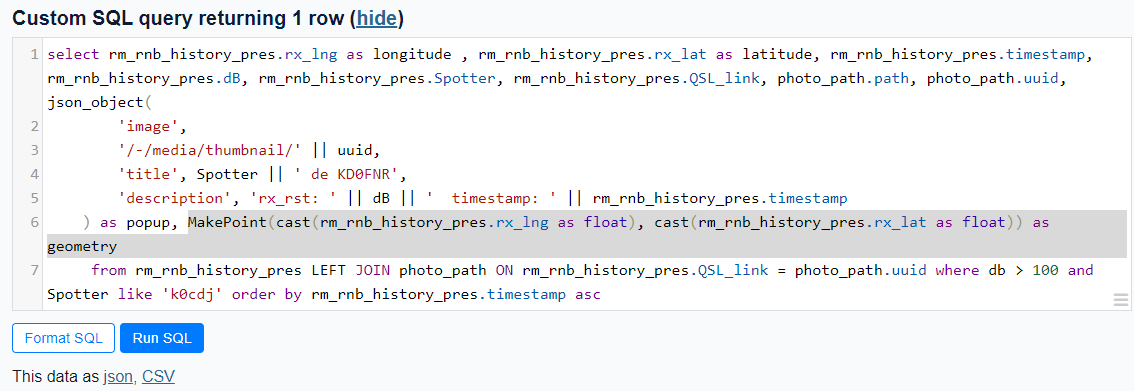 gave 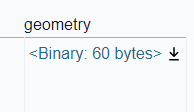 I believe it's the cast to float that does the trick. Prior to using the cast, I also received a 'wrong number of arguments' eror. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
410384988 | |
| https://github.com/simonw/datasette/issues/1615#issuecomment-1023997327 | https://api.github.com/repos/simonw/datasette/issues/1615 | 1023997327 | IC_kwDOBm6k_c49CPWP | 369053 | 2022-01-28T08:37:36Z | 2022-01-28T08:37:36Z | NONE | Oops, it feels like this should perhaps be migrated to GitHub Discussions - sorry! I don't think I have the ability to do that 😅 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1117132741 | |
| https://github.com/simonw/datasette/issues/558#issuecomment-511252718 | https://api.github.com/repos/simonw/datasette/issues/558 | 511252718 | MDEyOklzc3VlQ29tbWVudDUxMTI1MjcxOA== | 380586 | 2019-07-15T01:29:29Z | 2019-07-15T01:29:29Z | NONE | Thanks, the latest version works. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
467218270 | |
| https://github.com/simonw/datasette/issues/155#issuecomment-347714314 | https://api.github.com/repos/simonw/datasette/issues/155 | 347714314 | MDEyOklzc3VlQ29tbWVudDM0NzcxNDMxNA== | 388154 | 2017-11-29T00:46:25Z | 2017-11-29T00:46:25Z | NONE | ``` CREATE TABLE rhs ( id INTEGER PRIMARY KEY, name TEXT ); CREATE TABLE lhs ( symbol INTEGER PRIMARY KEY, FOREIGN KEY (symbol) REFERENCES rhs(id) ); INSERT INTO rhs VALUES (1, "foo"); INSERT INTO rhs VALUES (2, "bar"); INSERT INTO lhs VALUES (1); INSERT INTO lhs VALUES (2); ``` It's expected that in lhs's view, foo / bar should be displayed. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
277589569 | |
| https://github.com/simonw/datasette/issues/161#issuecomment-350108113 | https://api.github.com/repos/simonw/datasette/issues/161 | 350108113 | MDEyOklzc3VlQ29tbWVudDM1MDEwODExMw== | 388154 | 2017-12-07T22:02:24Z | 2017-12-07T22:02:24Z | NONE | It's not throwing the validation error anymore, but i still cannot run following with query: ``` WITH RECURSIVE cnt(x) AS (SELECT 1 UNION ALL SELECT x+1 FROM cnt LIMIT 10) SELECT x FROM cnt; ``` I got `near "WITH": syntax error`. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
278814220 | |
| https://github.com/simonw/datasette/issues/161#issuecomment-350182904 | https://api.github.com/repos/simonw/datasette/issues/161 | 350182904 | MDEyOklzc3VlQ29tbWVudDM1MDE4MjkwNA== | 388154 | 2017-12-08T06:18:12Z | 2017-12-08T06:18:12Z | NONE | You're right..got this resolved after upgrading the sqlite version. Thanks you! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
278814220 | |
| https://github.com/simonw/sqlite-utils/issues/433#issuecomment-1578840450 | https://api.github.com/repos/simonw/sqlite-utils/issues/433 | 1578840450 | IC_kwDOCGYnMM5eGzGC | 392720 | 2023-06-06T14:09:04Z | 2023-06-06T14:09:04Z | NONE | I also ran into this recently. See below for a patch for one possible solution (tested via "it works on my machine", but I don't expect that this behavior would vary a whole lot across terminal emulators and shells). Another possible solution might be to subclass click's `ProgressBar` to keep the logic within the original context manager. Happy to send a PR or for this patch to serve as the basis for a fix that someone else authors. ```patch diff --git a/sqlite_utils/utils.py b/sqlite_utils/utils.py index 06c1a4c..530a3a3 100644 --- a/sqlite_utils/utils.py +++ b/sqlite_utils/utils.py @@ -147,14 +147,23 @@ def decode_base64_values(doc): class UpdateWrapper: - def __init__(self, wrapped, update): + def __init__(self, wrapped, update, render_finish): self._wrapped = wrapped self._update = update + self._render_finish = render_finish def __iter__(self): - for line in self._wrapped: - self._update(len(line)) - yield line + return self + + def __next__(self): + try: + line = next(self._wrapped) + except StopIteration as e: + self._render_finish() + raise + + self._update(len(line)) + return line def read(self, size=-1): data = self._wrapped.read(size) @@ -178,7 +187,7 @@ def file_progress(file, silent=False, **kwargs): else: file_length = os.path.getsize(file.name) with click.progressbar(length=file_length, **kwargs) as bar: - yield UpdateWrapper(file, bar.update) + yield UpdateWrapper(file, bar.update, bar.render_finish) class Format(enum.Enum): ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1239034903 | |
| https://github.com/simonw/datasette/issues/2001#issuecomment-1403071122 | https://api.github.com/repos/simonw/datasette/issues/2001 | 1403071122 | IC_kwDOBm6k_c5ToSqS | 406380 | 2023-01-25T04:12:41Z | 2023-01-25T04:12:41Z | NONE | @cldellow glad to hear you tried it, as I got grossed out by my own suggestion ;) If you are on macOS I do have one trick for debugging segfaults using lldb. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1553615704 | |
| https://github.com/simonw/datasette/issues/1751#issuecomment-1140321380 | https://api.github.com/repos/simonw/datasette/issues/1751 | 1140321380 | IC_kwDOBm6k_c5D9-xk | 408765 | 2022-05-28T19:52:17Z | 2022-05-28T19:52:17Z | NONE | Closing in favor of existing issue #1298. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1251710928 | |
| https://github.com/simonw/datasette/issues/619#issuecomment-626006493 | https://api.github.com/repos/simonw/datasette/issues/619 | 626006493 | MDEyOklzc3VlQ29tbWVudDYyNjAwNjQ5Mw== | 412005 | 2020-05-08T20:29:12Z | 2020-05-08T20:29:12Z | NONE | just trying out datasette and quite like it, thanks! i found this issue annoying enough to have a go at a fix. have you any thoughts on a good approach? (i'm happy to dig in myself if you haven't thought about it yet, but wanted to check if you had an idea for how to fix when you raised the issue) | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
520655983 | |
| https://github.com/simonw/datasette/issues/1900#issuecomment-1319596087 | https://api.github.com/repos/simonw/datasette/issues/1900 | 1319596087 | IC_kwDOBm6k_c5Op3A3 | 419145 | 2022-11-18T06:16:33Z | 2022-11-18T06:16:33Z | NONE | Interesting! So I tried this locally using your copy of `nps-spatialite.db` and I got the same error. 🤔 ``` ❯ datasette package nps-spatialite.db --spatialite [+] Building 27.5s (10/10) FINISHED => [internal] load build definition from Dockerfile 0.0s => => transferring dockerfile: 622B 0.0s => [internal] load .dockerignore 0.0s => => transferring context: 2B 0.0s => [internal] load metadata for docker.io/library/python:3.11.0-slim-bullseye 0.9s => [internal] load build context 2.3s => => transferring context: 72.38MB 2.3s => CACHED [1/6] FROM docker.io/library/python:3.11.0-slim-bullseye@sha256:1cd45c5dad845af18d71745c017325725dc979571c1bbe625b67e6051533716c 0.0s => [2/6] COPY . /app 0.1s =>… | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1452572348 | |
| https://github.com/simonw/datasette/issues/1900#issuecomment-1319639462 | https://api.github.com/repos/simonw/datasette/issues/1900 | 1319639462 | IC_kwDOBm6k_c5OqBmm | 419145 | 2022-11-18T07:24:19Z | 2022-11-18T07:24:19Z | NONE | Is it, uh, possible we are on different architectures? 😅 I'm using an Apple M1 Pro. I jumped into a bash shell of an unmodified `python:3.11.0-slim-bullseye` container and manually ran `apt-get update` and installed `libsqlite3-mod-spatialite`. I don't end up with with `mod_spatialite.so` in `/usr/lib/x86_64-linux-gnu/` — _mine_ is in `/usr/lib/aarch64-linux-gnu/`. [I swapped that directory in here](https://github.com/simonw/datasette/blob/3db37e9a21f774d6c387fd04bf1e4c870554209e/datasette/utils/__init__.py#L407) in a local copy of `datasette` and poof — it worked! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1452572348 | |
| https://github.com/simonw/datasette/issues/1900#issuecomment-1319641636 | https://api.github.com/repos/simonw/datasette/issues/1900 | 1319641636 | IC_kwDOBm6k_c5OqCIk | 419145 | 2022-11-18T07:27:26Z | 2022-11-18T07:27:26Z | NONE | Can confirm that my `uname -a` returns something different at the end: ``` root:xnu-8792.41.9~2/RELEASE_ARM64_T6000 arm64 ``` I'm in `arm64` land, you're in `x86_64`. I am admittedly very fuzzy on how this factors into Docker these days. Honestly thought this was one of the things Docker was suppose to help address. 🤔 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1452572348 | |
| https://github.com/simonw/datasette/issues/1900#issuecomment-1319664697 | https://api.github.com/repos/simonw/datasette/issues/1900 | 1319664697 | IC_kwDOBm6k_c5OqHw5 | 419145 | 2022-11-18T07:59:36Z | 2022-11-18T08:00:38Z | NONE | Okay, my final observations for the night! I've been pushing and pulling the various levers in `utils/__init__.py` to see what makes this work without hard-coding in something for `arm64` and it seems that if I change `/usr/lib/x86_64-linux-gnu/mod_spatialite.so` [here](https://github.com/simonw/datasette/blob/3ecd131e57add427d847b614c920c9624bb2e66b/datasette/utils/__init__.py#L407) to just `mod_spatialite` it's happy. Unfortunately cannot audit that for `x86_64`, but maybe that's a solution that'd be cross-arch compatible? It seems like it's the hard-coding of that path that's tripping it up. (It was actually [this comment from back in 2018 in an entirely unrelated repo](https://github.com/pelias/docker/pull/28#issuecomment-433168462) that nudged me to try this, ha.) | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1452572348 | |
| https://github.com/simonw/datasette/issues/1706#issuecomment-1344669160 | https://api.github.com/repos/simonw/datasette/issues/1706 | 1344669160 | IC_kwDOBm6k_c5QJgXo | 419145 | 2022-12-09T19:11:40Z | 2022-12-09T19:11:40Z | NONE | Ah, yes! Was just trying to do this and had the same issue. +1 to this! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1198822563 | |
| https://github.com/simonw/datasette/issues/1775#issuecomment-1233328232 | https://api.github.com/repos/simonw/datasette/issues/1775 | 1233328232 | IC_kwDOBm6k_c5Jgxho | 428820 | 2022-08-31T19:18:47Z | 2022-08-31T19:18:47Z | NONE | I want contribute if strings is in pot file, or Json, yml, yaml, Js or other type .. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1323346408 | |
| https://github.com/simonw/datasette/issues/1775#issuecomment-1233684765 | https://api.github.com/repos/simonw/datasette/issues/1775 | 1233684765 | IC_kwDOBm6k_c5JiIkd | 428820 | 2022-09-01T03:12:50Z | 2022-09-01T03:12:50Z | NONE | I want to begin translation to es and it documentation, if u like i would do PR asap. But user interface, frontend and backend is a good feature be i18n support. When you have may be .pot file I can translate to, or Json file with all strings for internationalized | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1323346408 | |
| https://github.com/simonw/datasette/issues/1775#issuecomment-1233702481 | https://api.github.com/repos/simonw/datasette/issues/1775 | 1233702481 | IC_kwDOBm6k_c5JiM5R | 428820 | 2022-09-01T03:48:27Z | 2022-09-01T03:48:27Z | NONE | I want to do may be 3 or 4 PR for your evaluation, and when you allowed then I want supporting that effort El mié, 31 de ago. de 2022, 10:36 p. m., Simon Willison < ***@***.***> escribió: > I don't want to start any efforts around documentation translation until > after the Datasette 1.0 release, because I'd like to be confident that > we're not translating documentation that may have some big changes before > Datasette is fully stable! > > — > Reply to this email directly, view it on GitHub > <https://github.com/simonw/datasette/issues/1775#issuecomment-1233697166>, > or unsubscribe > <https://github.com/notifications/unsubscribe-auth/AADIWFDUWQ22P3KVJVMRC7TV4AQFNANCNFSM55EFFS5Q> > . > You are receiving this because you authored the thread.Message ID: > ***@***.***> > | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1323346408 | |
| https://github.com/simonw/sqlite-utils/issues/399#issuecomment-1548913065 | https://api.github.com/repos/simonw/sqlite-utils/issues/399 | 1548913065 | IC_kwDOCGYnMM5cUomp | 433780 | 2023-05-16T03:11:03Z | 2023-05-16T03:11:52Z | NONE | Using this thread and some [other resources](https://sqlite-utils.datasette.io/en/stable/cli.html#spatialite-helpers) I managed to cobble together a couple of sqlite-utils lines to add a geometry column for a table that already has a lat/lng column. ``` # add a geometry column sqlite-utils add-geometry-column [db name] [table name] geometry --type POINT --srid 4326 # add a point for each row to geometry column sqlite-utils --load-extension=spatialite [db name] 'update [table name] SET Geometry=MakePoint(longitude, latitude, 4326);' ``` | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1124731464 | |
| https://github.com/simonw/datasette/pull/363#issuecomment-417684877 | https://api.github.com/repos/simonw/datasette/issues/363 | 417684877 | MDEyOklzc3VlQ29tbWVudDQxNzY4NDg3Nw== | 436032 | 2018-08-31T14:39:45Z | 2018-08-31T14:39:45Z | NONE | It looks like the check passed, not sure why it's showing as running in GH. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
355299310 | |
| https://github.com/simonw/datasette/issues/101#issuecomment-344597274 | https://api.github.com/repos/simonw/datasette/issues/101 | 344597274 | MDEyOklzc3VlQ29tbWVudDM0NDU5NzI3NA== | 450244 | 2017-11-15T13:48:55Z | 2017-11-15T13:48:55Z | NONE | This is a duplicate of https://github.com/simonw/datasette/issues/100 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
274161964 | |
| https://github.com/simonw/datasette/issues/1265#issuecomment-803160804 | https://api.github.com/repos/simonw/datasette/issues/1265 | 803160804 | MDEyOklzc3VlQ29tbWVudDgwMzE2MDgwNA== | 468612 | 2021-03-19T22:05:12Z | 2021-03-19T22:05:12Z | NONE | Wow that was fast! Thanks for this very cool project and quick update! 👍 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
836123030 | |
| https://github.com/simonw/sqlite-utils/issues/235#issuecomment-1172697090 | https://api.github.com/repos/simonw/sqlite-utils/issues/235 | 1172697090 | IC_kwDOCGYnMM5F5fAC | 474467 | 2022-07-01T20:37:40Z | 2022-07-01T20:37:55Z | NONE | I just ran into what appears to be the same issue on a MacBook Pro, M1 Pro. Environment: ``` markd@Marks-MacBook-Pro metabase % python --version Python 3.8.9 markd@Marks-MacBook-Pro metabase % sqlite3 --version 3.37.0 2021-12-09 01:34:53 9ff244ce0739f8ee52a3e9671adb4ee54c83c640b02e3f9d185fd2f9a179aapl markd@Marks-MacBook-Pro metabase % sqlite-utils --version sqlite-utils, version 3.27 markd@Marks-MacBook-Pro metabase % sqlite3 gh.db SQLite version 3.37.0 2021-12-09 01:34:53 Enter ".help" for usage hints. sqlite> .dbconfig defensive off dqs_ddl on dqs_dml on enable_fkey off enable_qpsg off enable_trigger on enable_view on fts3_tokenizer off legacy_alter_table on legacy_file_format off load_extension off no_ckpt_on_close off reset_database off trigger_eqp off trusted_schema on writable_schema off ``` Error ``` markd@Marks-MacBook-Pro metabase % github-to-sqlite repos gh.db a8cteam51 Traceback (most recent call last): File "/Users/markd/Library/Python/3.8/bin/github-to-sqlite", line 8, in <module> sys.exit(cli()) File "/Users/markd/Library/Python/3.8/lib/python/site-packages/click/core.py", line 1130, in __call__ return self.main(*args, **kwargs) File "/Users/markd/Library/Python/3.8/lib/python/site-packages/click/core.py", line 1055, in main rv = self.invoke(ctx) File "/Users/markd/Library/Python/3.8/lib/python/site-packages/click/core.py", line 1657, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/Users/markd/Library/Python/3.8/lib/python/site-packages/click/core.py", line 1404, in invoke return ctx.invoke(self.callback, **ctx.params) File "/Users/markd/Library/Python/3.8/lib/python/site-packages/… | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
810618495 | |
| https://github.com/simonw/sqlite-utils/issues/235#issuecomment-1172766270 | https://api.github.com/repos/simonw/sqlite-utils/issues/235 | 1172766270 | IC_kwDOCGYnMM5F5v4- | 474467 | 2022-07-01T22:40:26Z | 2022-07-01T22:40:26Z | NONE | Note, I do not get this issue using my Intel MacBook Pro =/ Environment ``` markd@Marks-MBP metabase % python3 --version Python 3.9.13 markd@Marks-MBP metabase % sqlite3 --version 3.37.0 2021-12-09 01:34:53 9ff244ce0739f8ee52a3e9671adb4ee54c83c640b02e3f9d185fd2f9a179aapl markd@Marks-MBP metabase % sqlite-utils --version sqlite-utils, version 3.27 markd@Marks-MBP metabase % sqlite3 github.db SQLite version 3.37.0 2021-12-09 01:34:53 Enter ".help" for usage hints. sqlite> .dbconfig defensive off dqs_ddl on dqs_dml on enable_fkey off enable_qpsg off enable_trigger on enable_view on fts3_tokenizer off legacy_alter_table on legacy_file_format off load_extension off no_ckpt_on_close off reset_database off trigger_eqp off trusted_schema on writable_schema off ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
810618495 | |
| https://github.com/simonw/sqlite-utils/issues/235#issuecomment-1198414383 | https://api.github.com/repos/simonw/sqlite-utils/issues/235 | 1198414383 | IC_kwDOCGYnMM5Hblov | 474467 | 2022-07-28T17:10:06Z | 2022-07-28T17:10:06Z | NONE | I was able to fight through this by capturing the SQL commands from the `add_foreign_keys()` function in sqlite-utils and then executing them manually via the sqlite3 client, first setting PRAGMA writable_schema on and then updating the sqlite_master table. Still no clue why they were failing when run in context... | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
810618495 | |
| https://github.com/simonw/datasette/issues/1144#issuecomment-744489028 | https://api.github.com/repos/simonw/datasette/issues/1144 | 744489028 | MDEyOklzc3VlQ29tbWVudDc0NDQ4OTAyOA== | 475613 | 2020-12-14T14:47:11Z | 2020-12-14T14:47:11Z | NONE | Thanks for opening the issue, @simonw. Let me elaborate on my Tweets. [datasette-chartjs](https://github.com/MarkusH/datasette-chartjs) provides drop down lists to pick the chart visualization (e.g. bar, line, doughnut, pie, ...) as well as the column used for the "x axis" (e.g. time). A user can change the values on-demand. The chart will be redrawn w/o querying the database again. However, if a user wants to change the underlying query, they will use the SQL field provided by datasette or any of the other datasette built-in features to amend a query. In order to maintain a user's selections for the plugin, datasette-chartjs copies some parts of [datasette-vega](https://github.com/simonw/datasette-vega) which persist the chosen visualization and column in the hash part of a URL (the stuff behind the `#`). The plugin load the config from the hash upon initialization on the next page and use it accordingly. Additionally, datasette-vega and datasette-chartjs need to make sure to include the hash in all links and forms that cause a reload of the page. This is, such that the config persists between clicks. This ticket is about moving thes parts into datasette that provide the functionality to do so. This includes: 1. a way to load config options with a given prefix from the current URL hash 1. a way to update the current URL hash with a new config value or a bunch of config options 1. updating all necessary links and forms on the current page to include the URL hash whenever its updated 1. to prevent leaking config options to external pages, only "internal" links should be updated There's another, optional, feature that we might want to think about during the design phase: the scope of the config. Links within a datasette instance have 1 of 3 scopes: 1. global, for the whole datasette project 1. database, for all tables in a database 1. table, only for a table within a database When updating the links and forms as pointed out in 3. above, it might be worth considering which links need … | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
765637324 | |
| https://github.com/simonw/datasette/issues/983#issuecomment-753600999 | https://api.github.com/repos/simonw/datasette/issues/983 | 753600999 | MDEyOklzc3VlQ29tbWVudDc1MzYwMDk5OQ== | 475613 | 2021-01-03T11:11:21Z | 2021-01-03T11:11:21Z | NONE | With regards to JS/Browser events, given your example of menu items that plugins could add, I could imagine this code to work: ```js // as part of datasette datasette.events.AddMenuItem = 'DatasetteAddMenuItemEvent'; document.addEventListener(datasette.events.AddMenuItem, (e) => { // do whatever is needed to add the menu item. Data comes from `e` alert(e.title + ' ' + e.link); }); // as part of a plugin const event = new Event(datasette.events.AddMenuItem, {link: '/foo/bar', title: 'Go somewhere'}); Document.dispatchEvent(event) ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
712260429 | |
| https://github.com/simonw/datasette/issues/1331#issuecomment-842495820 | https://api.github.com/repos/simonw/datasette/issues/1331 | 842495820 | MDEyOklzc3VlQ29tbWVudDg0MjQ5NTgyMA== | 475613 | 2021-05-17T17:18:05Z | 2021-05-17T17:18:05Z | NONE | Wow, you are _fast_! I didn't notice dependabot had opened a PR already. I was about to. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
893537744 | |
| https://github.com/simonw/datasette/issues/1331#issuecomment-842499728 | https://api.github.com/repos/simonw/datasette/issues/1331 | 842499728 | MDEyOklzc3VlQ29tbWVudDg0MjQ5OTcyOA== | 475613 | 2021-05-17T17:24:30Z | 2021-05-17T17:24:30Z | NONE | > I wonder if there are any new 3.0 features we should be taking advantage of here that would justify pinning to 3.0 minimum? The changelog reads like bug fixes and removal of deprecated parts to me | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
893537744 | |
| https://github.com/simonw/datasette/issues/1331#issuecomment-844970776 | https://api.github.com/repos/simonw/datasette/issues/1331 | 844970776 | MDEyOklzc3VlQ29tbWVudDg0NDk3MDc3Ng== | 475613 | 2021-05-20T10:40:25Z | 2021-05-20T10:40:25Z | NONE | Any chance you could push a new datasette release with the updated dependencies in the setup.py, @simonw? | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
893537744 | |
| https://github.com/simonw/datasette/issues/949#issuecomment-1791571572 | https://api.github.com/repos/simonw/datasette/issues/949 | 1791571572 | IC_kwDOBm6k_c5qyTZ0 | 498744 | 2023-11-02T21:36:24Z | 2023-11-02T21:36:24Z | NONE | FWIW, code mirror 6 now has this standard although if you want table-specific suggestions, you'd have to handle parsing out which table the user is querying yourself. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
684961449 | |
| https://github.com/simonw/sqlite-utils/issues/235#issuecomment-1206241356 | https://api.github.com/repos/simonw/sqlite-utils/issues/235 | 1206241356 | IC_kwDOCGYnMM5H5chM | 503614 | 2022-08-05T09:26:15Z | 2022-08-05T09:29:42Z | NONE | I am getting the same error when using github-to-sqlite (which uses sqlite-utils internally). I am also using an M1 MacBook Pro, with macOS Monterey 12.5, with Python 3.10.6 for arm64 installed using pyenv. I have sqlite-utils 3.28 installed. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
810618495 | |
| https://github.com/simonw/datasette/issues/1439#issuecomment-1059863997 | https://api.github.com/repos/simonw/datasette/issues/1439 | 1059863997 | IC_kwDOBm6k_c4_LD29 | 505230 | 2022-03-06T00:57:57Z | 2022-03-06T00:57:57Z | NONE | Probably too late… but I have just seen this because http://simonwillison.net/2022/Mar/5/dash-encoding/#atom-everything And it reminded me of comma tools at W3C. http://www.w3.org/,tools Example, the text version of W3C homepage https://www.w3.org/,text > The challenge comes down to telling the difference between the following: > > * `/db/table` - an HTML table page `/db/table` > * `/db/table.csv` - the CSV version of `/db/table` `/db/table,csv` > * `/db/table.csv` - no this one is actually a database table called `table.csv` `/db/table.csv` > * `/db/table.csv.csv` - the CSV version of `/db/table.csv` `/db/table.csv,csv` > * `/db/table.csv.csv.csv` and so on... `/db/table.csv.csv,csv` I haven't checked all the cases in the thread. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
973139047 | |
| https://github.com/simonw/datasette/issues/1210#issuecomment-773977128 | https://api.github.com/repos/simonw/datasette/issues/1210 | 773977128 | MDEyOklzc3VlQ29tbWVudDc3Mzk3NzEyOA== | 525780 | 2021-02-05T11:30:34Z | 2021-02-05T11:30:34Z | NONE | Thanks for your quick reply! Having changed my `metadata.yml`, queries AND database I can't really reproduce it anymore, sorry. But at least I'm happy to say that it works now! :) Thanks again for the super nifty tool, very appreciated. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
796234313 |