github
| html_url | issue_url | id | node_id | user | created_at | updated_at | author_association | body | reactions | issue | performed_via_github_app |
|---|---|---|---|---|---|---|---|---|---|---|---|
| https://github.com/dogsheep/github-to-sqlite/issues/79#issuecomment-1847317568 | https://api.github.com/repos/dogsheep/github-to-sqlite/issues/79 | 1847317568 | IC_kwDODFdgUs5uG9RA | 23789 | 2023-12-08T14:50:13Z | 2023-12-08T14:50:13Z | NONE | Adding `&per_page=100` would reduce the number of API requests by 3x. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1570375808 | |
| https://github.com/simonw/sqlite-utils/pull/604#issuecomment-1846560096 | https://api.github.com/repos/simonw/sqlite-utils/issues/604 | 1846560096 | IC_kwDOCGYnMM5uEEVg | 9599 | 2023-12-08T05:16:44Z | 2023-12-08T05:17:20Z | OWNER | Also tested this manually like so: ```bash sqlite-utils create-table strict.db strictint id integer size integer --strict sqlite-utils create-table strict.db notstrictint id integer size integer sqlite-utils install sqlite-utils-shell sqlite-utils shell strict.db ``` ``` Attached to strict.db Type 'exit' to exit. sqlite-utils> insert into strictint (size) values (4); 1 row affected sqlite-utils> insert into strictint (size) values ('four'); An error occurred: cannot store TEXT value in INTEGER column strictint.size sqlite-utils> insert into notstrictint (size) values ('four'); 1 row affected sqlite-utils> commit; Done ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
2001006157 | |
| https://github.com/simonw/sqlite-utils/issues/603#issuecomment-1846555822 | https://api.github.com/repos/simonw/sqlite-utils/issues/603 | 1846555822 | IC_kwDOCGYnMM5uEDSu | 9599 | 2023-12-08T05:09:55Z | 2023-12-08T05:10:31Z | OWNER | I'm unable to replicate this issue. This is with a fresh install of `sqlite-utils==3.35.2`: ``` (base) ~ python3.12 Python 3.12.0 (v3.12.0:0fb18b02c8, Oct 2 2023, 09:45:56) [Clang 13.0.0 (clang-1300.0.29.30)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import sqlite_utils >>> db = sqlite_utils.Database(memory=True) >>> db["foo"].insert({"bar": 1}) <Table foo (bar)> >>> import sys >>> sys.version '3.12.0 (v3.12.0:0fb18b02c8, Oct 2 2023, 09:45:56) [Clang 13.0.0 (clang-1300.0.29.30)]' ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1988525411 | |
| https://github.com/simonw/sqlite-utils/issues/605#issuecomment-1846554637 | https://api.github.com/repos/simonw/sqlite-utils/issues/605 | 1846554637 | IC_kwDOCGYnMM5uEDAN | 9599 | 2023-12-08T05:07:54Z | 2023-12-08T05:07:54Z | OWNER | Thanks for opening an issue - this should help future Google searchers figure out what's going on here. Another approach here could be to store large integers as `TEXT` in SQLite (or even as `BLOB`). Both storing as `REAL` and storing as `TEXT/BLOB` feel nasty to me, but it looks like SQLite has a hard upper limit of 9223372036854775807 for integers. | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
2007893839 | |
| https://github.com/simonw/sqlite-utils/pull/604#issuecomment-1843585454 | https://api.github.com/repos/simonw/sqlite-utils/issues/604 | 1843585454 | IC_kwDOCGYnMM5t4uGu | 22429695 | 2023-12-06T19:48:26Z | 2023-12-08T05:05:03Z | NONE | ## [Codecov](https://app.codecov.io/gh/simonw/sqlite-utils/pull/604?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report All modified and coverable lines are covered by tests :white_check_mark: > Comparison is base [(`9286c1b`)](https://app.codecov.io/gh/simonw/sqlite-utils/commit/9286c1ba432e890b1bb4b2a1f847b15364c1fa18?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 95.77% compared to head [(`1698a9d`)](https://app.codecov.io/gh/simonw/sqlite-utils/pull/604?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 95.72%. > Report is 1 commits behind head on main. > :exclamation: Current head 1698a9d differs from pull request most recent head 61c6e26. Consider uploading reports for the commit 61c6e26 to get more accurate results <details><summary>Additional details and impacted files</summary> ```diff @@ Coverage Diff @@ ## main #604 +/- ## ========================================== - Coverage 95.77% 95.72% -0.06% ========================================== Files 8 8 Lines 2842 2852 +10 ========================================== + Hits 2722 2730 +8 - Misses 120 122 +2 ``` </details> [:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/simonw/sqlite-utils/pull/604?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). :loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
2001006157 | {
"id": 254,
"slug": "codecov",
"node_id": "MDM6QXBwMjU0",
"owner": {
"login": "codecov",
"id": 8226205,
"node_id": "MDEyOk9yZ2FuaXphdGlvbjgyMjYyMDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8226205?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/codecov",
"html_url": "https://github.com/codecov",
"followers_url": "https://api.github.com/users/codecov/followers",
"following_url": "https://api.github.com/users/codecov/following{/other_user}",
"gists_url": "https://api.github.com/users/codecov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/codecov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/codecov/subscriptions",
"organizations_url": "https://api.github.com/users/codecov/orgs",
"repos_url": "https://api.github.com/users/codecov/repos",
"events_url": "https://api.github.com/users/codecov/events{/privacy}",
"received_events_url": "https://api.github.com/users/codecov/received_events",
"type": "Organization",
"site_admin": false
},
"name": "Codecov",
"description": "Codecov provides highly integrated tools to group, merge, archive and compare coverage reports. Whether your team is comparing changes in a pull request or reviewing a single commit, Codecov will improve the code review workflow and quality.\r\n\r\n## Code coverage done right.\u00ae\r\n\r\n1. Upload coverage reports from your CI builds.\r\n2. Codecov merges all builds and languages into one beautiful coherent report.\r\n3. Get commit statuses, pull request comments and coverage overlay via our browser extension.\r\n\r\nWhen Codecov merges your uploads it keeps track of the CI provider (inc. build details) and user specified context, e.g. `#unittest` ~ `#smoketest` or `#oldcode` ~ `#newcode`. You can track the `#unittest` coverage independently of other groups. [Learn more here](\r\nhttp://docs.codecov.io/docs/flags)\r\n\r\nThrough **Codecov's Browser Extension** reports overlay directly in GitHub UI to assist in code review in [Chrome](https://chrome.google.com/webstore/detail/codecov/gedikamndpbemklijjkncpnolildpbgo) or Firefox (https://addons.mozilla.org/en-US/firefox/addon/codecov/)\r\n\r\n*Highly detailed* **pull request comments** and *customizable* **commit statuses** will improve your team's workflow and code coverage incrementally.\r\n\r\n**File backed configuration** all through the `codecov.yml`. \r\n\r\n## FAQ\r\n- Do you **merge multiple uploads** to the same commit? **Yes**\r\n- Do you **support multiple languages** in the same project? **Yes**\r\n- Can you **group coverage reports** by project and/or test type? **Yes**\r\n- How does **pricing** work? Only paid users can view reports and post statuses/comments. ",
"external_url": "https://codecov.io",
"html_url": "https://github.com/apps/codecov",
"created_at": "2016-09-25T14:18:27Z",
"updated_at": "2023-09-08T15:29:16Z",
"permissions": {
"administration": "read",
"checks": "write",
"contents": "read",
"emails": "read",
"issues": "read",
"members": "read",
"metadata": "read",
"pull_requests": "write",
"statuses": "write"
},
"events": [
"check_run",
"check_suite",
"create",
"delete",
"fork",
"member",
"membership",
"organization",
"public",
"pull_request",
"push",
"release",
"repository",
"status",
"team_add"
]
} |
| https://github.com/simonw/datasette/issues/2214#issuecomment-1844819002 | https://api.github.com/repos/simonw/datasette/issues/2214 | 1844819002 | IC_kwDOBm6k_c5t9bQ6 | 2874 | 2023-12-07T07:36:33Z | 2023-12-07T07:36:33Z | NONE | If I uncheck `expand labels` in the Advanced CSV export dialog, the error does not occur. Re-checking that box and re-running the export does cause the error to occur.  | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
2029908157 | |
| https://github.com/simonw/sqlite-utils/pull/604#issuecomment-1843975536 | https://api.github.com/repos/simonw/sqlite-utils/issues/604 | 1843975536 | IC_kwDOCGYnMM5t6NVw | 16437338 | 2023-12-07T01:17:05Z | 2023-12-07T01:17:05Z | CONTRIBUTOR | Apologies - I pushed a fix that addresses the mypy failures. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
2001006157 | |
| https://github.com/simonw/sqlite-utils/pull/604#issuecomment-1843586503 | https://api.github.com/repos/simonw/sqlite-utils/issues/604 | 1843586503 | IC_kwDOCGYnMM5t4uXH | 9599 | 2023-12-06T19:49:10Z | 2023-12-06T19:49:29Z | OWNER | This looks really great on first glance - design is good, implementation is solid, tests and documentation look great. Looks like a couple of `mypy` failures in the tests at the moment: ``` mypy sqlite_utils tests sqlite_utils/db.py:543: error: Incompatible types in assignment (expression has type "type[Table]", variable has type "type[View]") [assignment] tests/test_lookup.py:156: error: Name "test_lookup_new_table" already defined on line 5 [no-redef] Found 2 errors in 2 files (checked 54 source files) Error: Process completed with exit code 1. ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
2001006157 | |
| https://github.com/simonw/sqlite-utils/issues/606#issuecomment-1843579184 | https://api.github.com/repos/simonw/sqlite-utils/issues/606 | 1843579184 | IC_kwDOCGYnMM5t4skw | 9599 | 2023-12-06T19:43:55Z | 2023-12-06T19:43:55Z | OWNER | Updated documentation: - https://sqlite-utils.datasette.io/en/latest/cli.html#cli-add-column - https://sqlite-utils.datasette.io/en/latest/cli-reference.html#add-column | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
2029161033 | |
| https://github.com/simonw/sqlite-utils/issues/606#issuecomment-1843465748 | https://api.github.com/repos/simonw/sqlite-utils/issues/606 | 1843465748 | IC_kwDOCGYnMM5t4Q4U | 9599 | 2023-12-06T18:36:51Z | 2023-12-06T18:36:51Z | OWNER | I'll add `bytes` too - `float` already works. This makes sense because when you are working with the Python API you use `str` and `float` and `bytes` and `int` to specify column types. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
2029161033 | |
| https://github.com/simonw/datasette/issues/2213#issuecomment-1843072926 | https://api.github.com/repos/simonw/datasette/issues/2213 | 1843072926 | IC_kwDOBm6k_c5t2w-e | 536941 | 2023-12-06T15:05:44Z | 2023-12-06T15:05:44Z | CONTRIBUTOR | it probably does not make sense to gzip large sqlite database files on the fly. it can take many seconds to gzip a large file and you either have to have this big thing in memory, or write it to disk, which some deployment environments will not like. i wonder if it would make sense to gzip the databases as part of the datasette publish process. it would be very cool to statically serve those as if they dynamically zipped (i.e. serve the filename example.db, not example.db.zip, and rely on the browser to expand). | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
2028698018 | |
| https://github.com/simonw/datasette/issues/670#issuecomment-1816642044 | https://api.github.com/repos/simonw/datasette/issues/670 | 1816642044 | IC_kwDOBm6k_c5sR8H8 | 16142258 | 2023-11-17T15:32:20Z | 2023-11-17T15:32:20Z | NONE | Any progress on this? It would be very helpful on my end as well. Thanks! | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
564833696 | |
| https://github.com/simonw/sqlite-utils/issues/344#issuecomment-1815825863 | https://api.github.com/repos/simonw/sqlite-utils/issues/344 | 1815825863 | IC_kwDOCGYnMM5sO03H | 16437338 | 2023-11-17T06:44:49Z | 2023-11-17T06:44:49Z | CONTRIBUTOR | hello Simon, I've added more STRICT table support per https://github.com/simonw/sqlite-utils/issues/344#issuecomment-982014776 in changeset https://github.com/simonw/sqlite-utils/commit/e4b9b582cdb4e48430865f8739f341bc8017c1e4. It also fixes table.transform() to preserve STRICT mode. Please pull if you deem appropriate. Thanks! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1066474200 | |
| https://github.com/simonw/datasette/pull/2209#issuecomment-1812753347 | https://api.github.com/repos/simonw/datasette/issues/2209 | 1812753347 | IC_kwDOBm6k_c5sDGvD | 22429695 | 2023-11-15T15:31:12Z | 2023-11-15T15:31:12Z | NONE | ## [Codecov](https://app.codecov.io/gh/simonw/datasette/pull/2209?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report All modified and coverable lines are covered by tests :white_check_mark: > Comparison is base [(`452a587`)](https://app.codecov.io/gh/simonw/datasette/commit/452a587e236ef642cbc6ae345b58767ea8420cb5?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69% compared to head [(`c88414b`)](https://app.codecov.io/gh/simonw/datasette/pull/2209?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69%. <details><summary>Additional details and impacted files</summary> ```diff @@ Coverage Diff @@ ## main #2209 +/- ## ======================================= Coverage 92.69% 92.69% ======================================= Files 40 40 Lines 6047 6047 ======================================= Hits 5605 5605 Misses 442 442 ``` </details> [:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/simonw/datasette/pull/2209?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). :loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1994861266 | {
"id": 254,
"slug": "codecov",
"node_id": "MDM6QXBwMjU0",
"owner": {
"login": "codecov",
"id": 8226205,
"node_id": "MDEyOk9yZ2FuaXphdGlvbjgyMjYyMDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8226205?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/codecov",
"html_url": "https://github.com/codecov",
"followers_url": "https://api.github.com/users/codecov/followers",
"following_url": "https://api.github.com/users/codecov/following{/other_user}",
"gists_url": "https://api.github.com/users/codecov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/codecov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/codecov/subscriptions",
"organizations_url": "https://api.github.com/users/codecov/orgs",
"repos_url": "https://api.github.com/users/codecov/repos",
"events_url": "https://api.github.com/users/codecov/events{/privacy}",
"received_events_url": "https://api.github.com/users/codecov/received_events",
"type": "Organization",
"site_admin": false
},
"name": "Codecov",
"description": "Codecov provides highly integrated tools to group, merge, archive and compare coverage reports. Whether your team is comparing changes in a pull request or reviewing a single commit, Codecov will improve the code review workflow and quality.\r\n\r\n## Code coverage done right.\u00ae\r\n\r\n1. Upload coverage reports from your CI builds.\r\n2. Codecov merges all builds and languages into one beautiful coherent report.\r\n3. Get commit statuses, pull request comments and coverage overlay via our browser extension.\r\n\r\nWhen Codecov merges your uploads it keeps track of the CI provider (inc. build details) and user specified context, e.g. `#unittest` ~ `#smoketest` or `#oldcode` ~ `#newcode`. You can track the `#unittest` coverage independently of other groups. [Learn more here](\r\nhttp://docs.codecov.io/docs/flags)\r\n\r\nThrough **Codecov's Browser Extension** reports overlay directly in GitHub UI to assist in code review in [Chrome](https://chrome.google.com/webstore/detail/codecov/gedikamndpbemklijjkncpnolildpbgo) or Firefox (https://addons.mozilla.org/en-US/firefox/addon/codecov/)\r\n\r\n*Highly detailed* **pull request comments** and *customizable* **commit statuses** will improve your team's workflow and code coverage incrementally.\r\n\r\n**File backed configuration** all through the `codecov.yml`. \r\n\r\n## FAQ\r\n- Do you **merge multiple uploads** to the same commit? **Yes**\r\n- Do you **support multiple languages** in the same project? **Yes**\r\n- Can you **group coverage reports** by project and/or test type? **Yes**\r\n- How does **pricing** work? Only paid users can view reports and post statuses/comments. ",
"external_url": "https://codecov.io",
"html_url": "https://github.com/apps/codecov",
"created_at": "2016-09-25T14:18:27Z",
"updated_at": "2023-09-08T15:29:16Z",
"permissions": {
"administration": "read",
"checks": "write",
"contents": "read",
"emails": "read",
"issues": "read",
"members": "read",
"metadata": "read",
"pull_requests": "write",
"statuses": "write"
},
"events": [
"check_run",
"check_suite",
"create",
"delete",
"fork",
"member",
"membership",
"organization",
"public",
"pull_request",
"push",
"release",
"repository",
"status",
"team_add"
]
} |
| https://github.com/simonw/datasette/pull/2209#issuecomment-1812750369 | https://api.github.com/repos/simonw/datasette/issues/2209 | 1812750369 | IC_kwDOBm6k_c5sDGAh | 198537 | 2023-11-15T15:29:37Z | 2023-11-15T15:29:37Z | CONTRIBUTOR | Looks like tests are passing now but there is an issue with yaml loading and/or cog. https://github.com/simonw/datasette/actions/runs/6879299298/job/18710911166?pr=2209 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1994861266 | |
| https://github.com/simonw/datasette/pull/2209#issuecomment-1812623778 | https://api.github.com/repos/simonw/datasette/issues/2209 | 1812623778 | IC_kwDOBm6k_c5sCnGi | 198537 | 2023-11-15T14:22:42Z | 2023-11-15T15:24:09Z | CONTRIBUTOR | Whoops, looks like I forgot to check for other places where the 'facetable' table is used in the tests. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1994861266 | |
| https://github.com/simonw/datasette/issues/2208#issuecomment-1812617851 | https://api.github.com/repos/simonw/datasette/issues/2208 | 1812617851 | IC_kwDOBm6k_c5sClp7 | 198537 | 2023-11-15T14:18:58Z | 2023-11-15T14:18:58Z | CONTRIBUTOR | Without aliases:  The proposed fix in #2209 also works when the 'value' column is actually facetable (just added another value in the 'value' column). 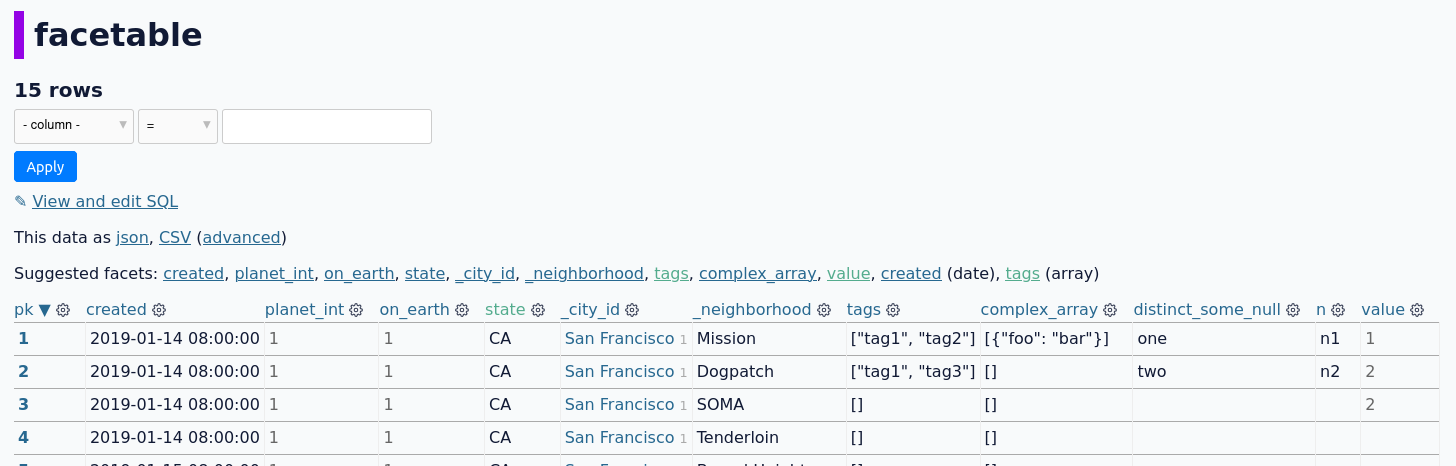 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1994857251 | |
| https://github.com/simonw/datasette/pull/2206#issuecomment-1801888957 | https://api.github.com/repos/simonw/datasette/issues/2206 | 1801888957 | IC_kwDOBm6k_c5rZqS9 | 22429695 | 2023-11-08T13:26:13Z | 2023-11-08T13:26:13Z | NONE | ## [Codecov](https://app.codecov.io/gh/simonw/datasette/pull/2206?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report All modified and coverable lines are covered by tests :white_check_mark: > Comparison is base [(`452a587`)](https://app.codecov.io/gh/simonw/datasette/commit/452a587e236ef642cbc6ae345b58767ea8420cb5?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69% compared to head [(`eec10df`)](https://app.codecov.io/gh/simonw/datasette/pull/2206?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69%. <details><summary>Additional details and impacted files</summary> ```diff @@ Coverage Diff @@ ## main #2206 +/- ## ======================================= Coverage 92.69% 92.69% ======================================= Files 40 40 Lines 6047 6047 ======================================= Hits 5605 5605 Misses 442 442 ``` </details> [:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/simonw/datasette/pull/2206?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). :loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1983600865 | {
"id": 254,
"slug": "codecov",
"node_id": "MDM6QXBwMjU0",
"owner": {
"login": "codecov",
"id": 8226205,
"node_id": "MDEyOk9yZ2FuaXphdGlvbjgyMjYyMDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8226205?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/codecov",
"html_url": "https://github.com/codecov",
"followers_url": "https://api.github.com/users/codecov/followers",
"following_url": "https://api.github.com/users/codecov/following{/other_user}",
"gists_url": "https://api.github.com/users/codecov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/codecov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/codecov/subscriptions",
"organizations_url": "https://api.github.com/users/codecov/orgs",
"repos_url": "https://api.github.com/users/codecov/repos",
"events_url": "https://api.github.com/users/codecov/events{/privacy}",
"received_events_url": "https://api.github.com/users/codecov/received_events",
"type": "Organization",
"site_admin": false
},
"name": "Codecov",
"description": "Codecov provides highly integrated tools to group, merge, archive and compare coverage reports. Whether your team is comparing changes in a pull request or reviewing a single commit, Codecov will improve the code review workflow and quality.\r\n\r\n## Code coverage done right.\u00ae\r\n\r\n1. Upload coverage reports from your CI builds.\r\n2. Codecov merges all builds and languages into one beautiful coherent report.\r\n3. Get commit statuses, pull request comments and coverage overlay via our browser extension.\r\n\r\nWhen Codecov merges your uploads it keeps track of the CI provider (inc. build details) and user specified context, e.g. `#unittest` ~ `#smoketest` or `#oldcode` ~ `#newcode`. You can track the `#unittest` coverage independently of other groups. [Learn more here](\r\nhttp://docs.codecov.io/docs/flags)\r\n\r\nThrough **Codecov's Browser Extension** reports overlay directly in GitHub UI to assist in code review in [Chrome](https://chrome.google.com/webstore/detail/codecov/gedikamndpbemklijjkncpnolildpbgo) or Firefox (https://addons.mozilla.org/en-US/firefox/addon/codecov/)\r\n\r\n*Highly detailed* **pull request comments** and *customizable* **commit statuses** will improve your team's workflow and code coverage incrementally.\r\n\r\n**File backed configuration** all through the `codecov.yml`. \r\n\r\n## FAQ\r\n- Do you **merge multiple uploads** to the same commit? **Yes**\r\n- Do you **support multiple languages** in the same project? **Yes**\r\n- Can you **group coverage reports** by project and/or test type? **Yes**\r\n- How does **pricing** work? Only paid users can view reports and post statuses/comments. ",
"external_url": "https://codecov.io",
"html_url": "https://github.com/apps/codecov",
"created_at": "2016-09-25T14:18:27Z",
"updated_at": "2023-09-08T15:29:16Z",
"permissions": {
"administration": "read",
"checks": "write",
"contents": "read",
"emails": "read",
"issues": "read",
"members": "read",
"metadata": "read",
"pull_requests": "write",
"statuses": "write"
},
"events": [
"check_run",
"check_suite",
"create",
"delete",
"fork",
"member",
"membership",
"organization",
"public",
"pull_request",
"push",
"release",
"repository",
"status",
"team_add"
]
} |
| https://github.com/simonw/datasette/pull/2202#issuecomment-1801876943 | https://api.github.com/repos/simonw/datasette/issues/2202 | 1801876943 | IC_kwDOBm6k_c5rZnXP | 49699333 | 2023-11-08T13:19:00Z | 2023-11-08T13:19:00Z | CONTRIBUTOR | Superseded by #2206. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1959278971 | {
"id": 29110,
"slug": "dependabot",
"node_id": "MDM6QXBwMjkxMTA=",
"owner": {
"login": "github",
"id": 9919,
"node_id": "MDEyOk9yZ2FuaXphdGlvbjk5MTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/9919?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/github",
"html_url": "https://github.com/github",
"followers_url": "https://api.github.com/users/github/followers",
"following_url": "https://api.github.com/users/github/following{/other_user}",
"gists_url": "https://api.github.com/users/github/gists{/gist_id}",
"starred_url": "https://api.github.com/users/github/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/github/subscriptions",
"organizations_url": "https://api.github.com/users/github/orgs",
"repos_url": "https://api.github.com/users/github/repos",
"events_url": "https://api.github.com/users/github/events{/privacy}",
"received_events_url": "https://api.github.com/users/github/received_events",
"type": "Organization",
"site_admin": false
},
"name": "Dependabot",
"description": "",
"external_url": "https://dependabot-api.githubapp.com",
"html_url": "https://github.com/apps/dependabot",
"created_at": "2019-04-16T22:34:25Z",
"updated_at": "2023-10-12T13:35:09Z",
"permissions": {
"checks": "write",
"contents": "write",
"issues": "write",
"members": "read",
"metadata": "read",
"pull_requests": "write",
"statuses": "read",
"vulnerability_alerts": "read",
"workflows": "write"
},
"events": [
"check_suite",
"issues",
"issue_comment",
"label",
"pull_request",
"pull_request_review",
"pull_request_review_comment",
"repository"
]
} |
| https://github.com/simonw/datasette/issues/2205#issuecomment-1794054390 | https://api.github.com/repos/simonw/datasette/issues/2205 | 1794054390 | IC_kwDOBm6k_c5q7xj2 | 9599 | 2023-11-06T04:09:43Z | 2023-11-06T04:10:34Z | OWNER | That `keep_blank_values=True` is from https://github.com/simonw/datasette/commit/0934844c0b6d124163d0185fb6a41ba5a71433da Commit message: > request.post_vars() no longer discards empty values Relevant test: https://github.com/simonw/datasette/blob/452a587e236ef642cbc6ae345b58767ea8420cb5/tests/test_internals_request.py#L19-L27 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1978023780 | |
| https://github.com/simonw/datasette/issues/2205#issuecomment-1794052079 | https://api.github.com/repos/simonw/datasette/issues/2205 | 1794052079 | IC_kwDOBm6k_c5q7w_v | 9599 | 2023-11-06T04:06:05Z | 2023-11-06T04:08:50Z | OWNER | It should return a `MultiParams`: https://github.com/simonw/datasette/blob/452a587e236ef642cbc6ae345b58767ea8420cb5/datasette/utils/__init__.py#L900-L917 Change needs to be made before 1.0. ```python return MultiParams(urllib.parse.parse_qs(body.decode("utf-8"))) ``` Need to remember why I was using `keep_blank_values=True` there and check that using `MultiParams` doesn't conflict with that reason. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1978023780 | |
| https://github.com/simonw/datasette/issues/2205#issuecomment-1793880738 | https://api.github.com/repos/simonw/datasette/issues/2205 | 1793880738 | IC_kwDOBm6k_c5q7HKi | 9599 | 2023-11-05T23:26:14Z | 2023-11-05T23:26:14Z | OWNER | I found this problem while trying to use WTForms with this pattern: ```python choices = [(col, col) for col in await db.table_columns(table)] class ConfigForm(Form): template = TextAreaField("Template") api_token = PasswordField("OpenAI API token") columns = MultiCheckboxField('Columns', choices=choices) ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1978023780 | |
| https://github.com/simonw/datasette/issues/1415#issuecomment-1793787454 | https://api.github.com/repos/simonw/datasette/issues/1415 | 1793787454 | IC_kwDOBm6k_c5q6wY- | 45269373 | 2023-11-05T16:44:49Z | 2023-11-05T16:46:59Z | NONE | thanks for documenting this @bendnorman! got stuck at exactly the same point `gcloud builds submit ... returned non-zero exit status 1`, without a clue why this was happening. i now managed to get the github action to deploy datasette by assigning the following roles to the service account: `roles/run.admin`, `roles/storage.admin`, `roles/cloudbuild.builds.builder`, `roles/viewer`, `roles/iam.serviceAccountUser`. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
959137143 | |
| https://github.com/simonw/sqlite-utils/pull/591#issuecomment-1793278279 | https://api.github.com/repos/simonw/sqlite-utils/issues/591 | 1793278279 | IC_kwDOCGYnMM5q40FH | 9599 | 2023-11-04T00:58:03Z | 2023-11-04T00:58:03Z | OWNER | I'm going to abandon this PR and ship the 3.12 testing change directly to `main`. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1884335789 | |
| https://github.com/simonw/sqlite-utils/pull/591#issuecomment-1708693020 | https://api.github.com/repos/simonw/sqlite-utils/issues/591 | 1708693020 | IC_kwDOCGYnMM5l2JYc | 22429695 | 2023-09-06T16:14:03Z | 2023-11-04T00:54:25Z | NONE | ## [Codecov](https://app.codecov.io/gh/simonw/sqlite-utils/pull/591?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report All modified and coverable lines are covered by tests :white_check_mark: > Comparison is base [(`347fdc8`)](https://app.codecov.io/gh/simonw/sqlite-utils/commit/347fdc865e91b8d3410f49a5c9d5b499fbb594c1?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 95.74% compared to head [(`1f14df1`)](https://app.codecov.io/gh/simonw/sqlite-utils/pull/591?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 95.74%. <details><summary>Additional details and impacted files</summary> ```diff @@ Coverage Diff @@ ## main #591 +/- ## ======================================= Coverage 95.74% 95.74% ======================================= Files 8 8 Lines 2842 2842 ======================================= Hits 2721 2721 Misses 121 121 ``` </details> [:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/simonw/sqlite-utils/pull/591?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). :loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1884335789 | |
| https://github.com/simonw/sqlite-utils/pull/596#issuecomment-1793274869 | https://api.github.com/repos/simonw/sqlite-utils/issues/596 | 1793274869 | IC_kwDOCGYnMM5q4zP1 | 9599 | 2023-11-04T00:47:55Z | 2023-11-04T00:47:55Z | OWNER | Thanks! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1919296686 | |
| https://github.com/simonw/sqlite-utils/pull/598#issuecomment-1793274485 | https://api.github.com/repos/simonw/sqlite-utils/issues/598 | 1793274485 | IC_kwDOCGYnMM5q4zJ1 | 9599 | 2023-11-04T00:46:55Z | 2023-11-04T00:46:55Z | OWNER | Manually tested. Before:  After:  | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1926729132 | |
| https://github.com/simonw/sqlite-utils/issues/433#issuecomment-1793274350 | https://api.github.com/repos/simonw/sqlite-utils/issues/433 | 1793274350 | IC_kwDOCGYnMM5q4zHu | 9599 | 2023-11-04T00:46:30Z | 2023-11-04T00:46:30Z | OWNER | And a GIF of the fix after applying: - #598  | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1239034903 | |
| https://github.com/simonw/sqlite-utils/issues/433#issuecomment-1793273968 | https://api.github.com/repos/simonw/sqlite-utils/issues/433 | 1793273968 | IC_kwDOCGYnMM5q4zBw | 9599 | 2023-11-04T00:45:19Z | 2023-11-04T00:45:19Z | OWNER | Here's an animated GIF that demonstrates the bug:  | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1239034903 | |
| https://github.com/simonw/sqlite-utils/pull/598#issuecomment-1793272429 | https://api.github.com/repos/simonw/sqlite-utils/issues/598 | 1793272429 | IC_kwDOCGYnMM5q4ypt | 9599 | 2023-11-04T00:40:34Z | 2023-11-04T00:40:34Z | OWNER | Thanks! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1926729132 | |
| https://github.com/simonw/sqlite-utils/pull/600#issuecomment-1793269219 | https://api.github.com/repos/simonw/sqlite-utils/issues/600 | 1793269219 | IC_kwDOCGYnMM5q4x3j | 9599 | 2023-11-04T00:34:33Z | 2023-11-04T00:34:33Z | OWNER | The GIS tests now pass in that container too: ```bash pytest tests/test_gis.py ``` ``` ======================== test session starts ========================= platform linux -- Python 3.10.12, pytest-7.4.3, pluggy-1.3.0 rootdir: /tmp/sqlite-utils plugins: hypothesis-6.88.1 collected 12 items tests/test_gis.py ............ [100%] ========================= 12 passed in 0.48s ========================= ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1977004379 | |
| https://github.com/simonw/sqlite-utils/issues/599#issuecomment-1793268750 | https://api.github.com/repos/simonw/sqlite-utils/issues/599 | 1793268750 | IC_kwDOCGYnMM5q4xwO | 9599 | 2023-11-04T00:33:25Z | 2023-11-04T00:33:25Z | OWNER | See details of how I tested this here: - https://github.com/simonw/sqlite-utils/pull/600#issuecomment-1793268126 Short version: having applied this fix, the following command (on simulated `aarch64`): ```bash sqlite-utils memory "select spatialite_version()" --load-extension=spatialite ``` Outputs: ```json [{"spatialite_version()": "5.0.1"}] ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1976986318 | |
| https://github.com/simonw/sqlite-utils/pull/600#issuecomment-1793268126 | https://api.github.com/repos/simonw/sqlite-utils/issues/600 | 1793268126 | IC_kwDOCGYnMM5q4xme | 9599 | 2023-11-04T00:31:34Z | 2023-11-04T00:31:34Z | OWNER | Testing this manually on macOS using Docker Desk top like this: ```bash docker run -it --rm arm64v8/ubuntu /bin/bash ``` Then inside the container: ```bash uname -m ``` Outputs: `aarch64` Then: ```bash apt install spatialite-bin libsqlite3-mod-spatialite git python3 python3-venv -y cd /tmp git clone https://github.com/simonw/sqlite-utils cd sqlite-utils python3 -m venv venv source venv/bin/activate pip install -e '.[test]' sqlite-utils memory "select spatialite_version()" --load-extension=spatialite ``` Which output: ``` Traceback (most recent call last): File "/tmp/sqlite-utils/venv/bin/sqlite-utils", line 33, in <module> sys.exit(load_entry_point('sqlite-utils', 'console_scripts', 'sqlite-utils')()) File "/tmp/sqlite-utils/venv/lib/python3.10/site-packages/click/core.py", line 1157, in __call__ return self.main(*args, **kwargs) File "/tmp/sqlite-utils/venv/lib/python3.10/site-packages/click/core.py", line 1078, in main rv = self.invoke(ctx) File "/tmp/sqlite-utils/venv/lib/python3.10/site-packages/click/core.py", line 1688, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/tmp/sqlite-utils/venv/lib/python3.10/site-packages/click/core.py", line 1434, in invoke return ctx.invoke(self.callback, **ctx.params) File "/tmp/sqlite-utils/venv/lib/python3.10/site-packages/click/core.py", line 783, in invoke return __callback(*args, **kwargs) File "/tmp/sqlite-utils/sqlite_utils/cli.py", line 1959, in memory _load_extensions(db, load_extension) File "/tmp/sqlite-utils/sqlite_utils/cli.py", line 3232, in _load_extensions if ":" in ext: TypeError: argument of type 'NoneType' is not iterable ``` Then I ran this: ```bash git checkout -b MikeCoats-spatialite-paths-linux-arm main git pull https://github.com/MikeCoats/sqlite-utils.git spatialite-paths-linux-arm ``` And now: ```bash sqlite-utils memory "select spatialite_version()" --load-extension=spatialite ``` Outputs: ```json [{"spatialite_version()": "… | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1977004379 | |
| https://github.com/simonw/sqlite-utils/pull/600#issuecomment-1793264654 | https://api.github.com/repos/simonw/sqlite-utils/issues/600 | 1793264654 | IC_kwDOCGYnMM5q4wwO | 22429695 | 2023-11-04T00:22:07Z | 2023-11-04T00:27:29Z | NONE | ## [Codecov](https://app.codecov.io/gh/simonw/sqlite-utils/pull/600?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report All modified and coverable lines are covered by tests :white_check_mark: > Comparison is base [(`622c3a5`)](https://app.codecov.io/gh/simonw/sqlite-utils/commit/622c3a5a7dd53a09c029e2af40c2643fe7579340?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 95.77% compared to head [(`b1a6076`)](https://app.codecov.io/gh/simonw/sqlite-utils/pull/600?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 95.77%. <details><summary>Additional details and impacted files</summary> ```diff @@ Coverage Diff @@ ## main #600 +/- ## ======================================= Coverage 95.77% 95.77% ======================================= Files 8 8 Lines 2840 2840 ======================================= Hits 2720 2720 Misses 120 120 ``` | [Files](https://app.codecov.io/gh/simonw/sqlite-utils/pull/600?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) | Coverage Δ | | |---|---|---| | [sqlite\_utils/db.py](https://app.codecov.io/gh/simonw/sqlite-utils/pull/600?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison#diff-c3FsaXRlX3V0aWxzL2RiLnB5) | `97.22% <ø> (ø)` | | | [sqlite\_utils/utils.py](https://app.codecov.io/gh/simonw/sqlite-utils/pull/600?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison#diff-c3FsaXRlX3V0aWxzL3V0aWxzLnB5) | `94.56% <ø> (ø)` | | </details> [:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/… | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1977004379 | {
"id": 254,
"slug": "codecov",
"node_id": "MDM6QXBwMjU0",
"owner": {
"login": "codecov",
"id": 8226205,
"node_id": "MDEyOk9yZ2FuaXphdGlvbjgyMjYyMDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8226205?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/codecov",
"html_url": "https://github.com/codecov",
"followers_url": "https://api.github.com/users/codecov/followers",
"following_url": "https://api.github.com/users/codecov/following{/other_user}",
"gists_url": "https://api.github.com/users/codecov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/codecov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/codecov/subscriptions",
"organizations_url": "https://api.github.com/users/codecov/orgs",
"repos_url": "https://api.github.com/users/codecov/repos",
"events_url": "https://api.github.com/users/codecov/events{/privacy}",
"received_events_url": "https://api.github.com/users/codecov/received_events",
"type": "Organization",
"site_admin": false
},
"name": "Codecov",
"description": "Codecov provides highly integrated tools to group, merge, archive and compare coverage reports. Whether your team is comparing changes in a pull request or reviewing a single commit, Codecov will improve the code review workflow and quality.\r\n\r\n## Code coverage done right.\u00ae\r\n\r\n1. Upload coverage reports from your CI builds.\r\n2. Codecov merges all builds and languages into one beautiful coherent report.\r\n3. Get commit statuses, pull request comments and coverage overlay via our browser extension.\r\n\r\nWhen Codecov merges your uploads it keeps track of the CI provider (inc. build details) and user specified context, e.g. `#unittest` ~ `#smoketest` or `#oldcode` ~ `#newcode`. You can track the `#unittest` coverage independently of other groups. [Learn more here](\r\nhttp://docs.codecov.io/docs/flags)\r\n\r\nThrough **Codecov's Browser Extension** reports overlay directly in GitHub UI to assist in code review in [Chrome](https://chrome.google.com/webstore/detail/codecov/gedikamndpbemklijjkncpnolildpbgo) or Firefox (https://addons.mozilla.org/en-US/firefox/addon/codecov/)\r\n\r\n*Highly detailed* **pull request comments** and *customizable* **commit statuses** will improve your team's workflow and code coverage incrementally.\r\n\r\n**File backed configuration** all through the `codecov.yml`. \r\n\r\n## FAQ\r\n- Do you **merge multiple uploads** to the same commit? **Yes**\r\n- Do you **support multiple languages** in the same project? **Yes**\r\n- Can you **group coverage reports** by project and/or test type? **Yes**\r\n- How does **pricing** work? Only paid users can view reports and post statuses/comments. ",
"external_url": "https://codecov.io",
"html_url": "https://github.com/apps/codecov",
"created_at": "2016-09-25T14:18:27Z",
"updated_at": "2023-09-08T15:29:16Z",
"permissions": {
"administration": "read",
"checks": "write",
"contents": "read",
"emails": "read",
"issues": "read",
"members": "read",
"metadata": "read",
"pull_requests": "write",
"statuses": "write"
},
"events": [
"check_run",
"check_suite",
"create",
"delete",
"fork",
"member",
"membership",
"organization",
"public",
"pull_request",
"push",
"release",
"repository",
"status",
"team_add"
]
} |
| https://github.com/simonw/sqlite-utils/pull/600#issuecomment-1793265952 | https://api.github.com/repos/simonw/sqlite-utils/issues/600 | 1793265952 | IC_kwDOCGYnMM5q4xEg | 9599 | 2023-11-04T00:25:34Z | 2023-11-04T00:25:34Z | OWNER | The tests failed because they found a spelling mistake in a completely unrelated area of the code - not sure why that had not been caught before. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1977004379 | |
| https://github.com/simonw/sqlite-utils/pull/600#issuecomment-1793263638 | https://api.github.com/repos/simonw/sqlite-utils/issues/600 | 1793263638 | IC_kwDOCGYnMM5q4wgW | 9599 | 2023-11-04T00:19:58Z | 2023-11-04T00:19:58Z | OWNER | Thanks for this! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1977004379 | |
| https://github.com/simonw/datasette/issues/949#issuecomment-1791911093 | https://api.github.com/repos/simonw/datasette/issues/949 | 1791911093 | IC_kwDOBm6k_c5qzmS1 | 9599 | 2023-11-03T05:28:09Z | 2023-11-03T05:28:58Z | OWNER | Datasette is using that now, see: - #1893 | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
684961449 | |
| https://github.com/simonw/datasette/issues/949#issuecomment-1791571572 | https://api.github.com/repos/simonw/datasette/issues/949 | 1791571572 | IC_kwDOBm6k_c5qyTZ0 | 498744 | 2023-11-02T21:36:24Z | 2023-11-02T21:36:24Z | NONE | FWIW, code mirror 6 now has this standard although if you want table-specific suggestions, you'd have to handle parsing out which table the user is querying yourself. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
684961449 | |
| https://github.com/simonw/datasette/issues/411#issuecomment-1779267468 | https://api.github.com/repos/simonw/datasette/issues/411 | 1779267468 | IC_kwDOBm6k_c5qDXeM | 363004 | 2023-10-25T13:23:04Z | 2023-10-25T13:23:04Z | NONE | Using the [Counties example](https://us-counties.datasette.io/counties/county_for_latitude_longitude?longitude=-122&latitude=37), I was able to pull out the MakePoint method as MakePoint(cast(rm_rnb_history_pres.rx_lng as float), cast(rm_rnb_history_pres.rx_lat as float)) as geometry which worked, giving me a geometry column. 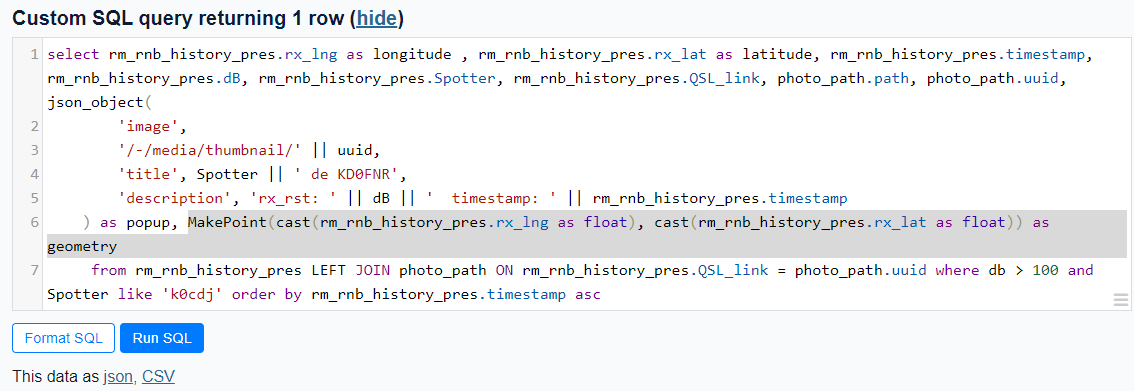 gave 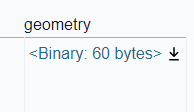 I believe it's the cast to float that does the trick. Prior to using the cast, I also received a 'wrong number of arguments' eror. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
410384988 | |
| https://github.com/simonw/datasette/pull/2202#issuecomment-1777247375 | https://api.github.com/repos/simonw/datasette/issues/2202 | 1777247375 | IC_kwDOBm6k_c5p7qSP | 22429695 | 2023-10-24T13:49:27Z | 2023-10-24T13:49:27Z | NONE | ## [Codecov](https://app.codecov.io/gh/simonw/datasette/pull/2202?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report All modified and coverable lines are covered by tests :white_check_mark: > Comparison is base [(`452a587`)](https://app.codecov.io/gh/simonw/datasette/commit/452a587e236ef642cbc6ae345b58767ea8420cb5?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69% compared to head [(`be4d0f0`)](https://app.codecov.io/gh/simonw/datasette/pull/2202?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69%. <details><summary>Additional details and impacted files</summary> ```diff @@ Coverage Diff @@ ## main #2202 +/- ## ======================================= Coverage 92.69% 92.69% ======================================= Files 40 40 Lines 6047 6047 ======================================= Hits 5605 5605 Misses 442 442 ``` </details> [:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/simonw/datasette/pull/2202?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). :loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1959278971 | |
| https://github.com/simonw/datasette/pull/2200#issuecomment-1777228352 | https://api.github.com/repos/simonw/datasette/issues/2200 | 1777228352 | IC_kwDOBm6k_c5p7lpA | 49699333 | 2023-10-24T13:40:25Z | 2023-10-24T13:40:25Z | CONTRIBUTOR | Superseded by #2202. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1949756141 | |
| https://github.com/simonw/datasette/issues/1655#issuecomment-1767248394 | https://api.github.com/repos/simonw/datasette/issues/1655 | 1767248394 | IC_kwDOBm6k_c5pVhIK | 6262071 | 2023-10-17T21:53:17Z | 2023-10-17T21:53:17Z | NONE | @fgregg, I am happy to do that and just could not find a way to create issues at your fork repo. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1163369515 | |
| https://github.com/simonw/datasette/issues/1655#issuecomment-1767219901 | https://api.github.com/repos/simonw/datasette/issues/1655 | 1767219901 | IC_kwDOBm6k_c5pVaK9 | 536941 | 2023-10-17T21:29:03Z | 2023-10-17T21:29:03Z | CONTRIBUTOR | @yejiyang why don’t you move this discussion to my fork to spare simon’s notifications | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1163369515 | |
| https://github.com/simonw/datasette/issues/1655#issuecomment-1767133832 | https://api.github.com/repos/simonw/datasette/issues/1655 | 1767133832 | IC_kwDOBm6k_c5pVFKI | 6262071 | 2023-10-17T20:37:18Z | 2023-10-17T21:12:48Z | NONE | @fgregg Thanks for your reply. I tried to use your fork branch `datasette = {url = "https://github.com/fgregg/datasette/archive/refs/heads/no_limit_csv_publish.zip"}` and got error - TypeError: 'str' object is not callable. I used the same templates as in your branch [here ](https://github.com/labordata/warehouse/tree/main/templates). ``` INFO: 127.0.0.1:47232 - "GET /-/static/sql-formatter-2.3.3.min.js HTTP/1.1" 200 OK Traceback (most recent call last): File "/home/jiyang/github/global-chemical-inventory-database/.venv/lib/python3.10/site-packages/datasette/app.py", line 1632, in route_path response = await view(request, send) File "/home/jiyang/github/global-chemical-inventory-database/.venv/lib/python3.10/site-packages/datasette/app.py", line 1814, in async_view_fn response = await async_call_with_supported_arguments( File "/home/jiyang/github/global-chemical-inventory-database/.venv/lib/python3.10/site-packages/datasette/utils/__init__.py", line 1016, in async_call_with_supported_arguments return await fn(*call_with) File "/home/jiyang/github/global-chemical-inventory-database/.venv/lib/python3.10/site-packages/datasette/views/table.py", line 673, in table_view response = await table_view_traced(datasette, request) File "/home/jiyang/github/global-chemical-inventory-database/.venv/lib/python3.10/site-packages/datasette/views/table.py", line 822, in table_view_traced await datasette.render_template( File "/home/jiyang/github/global-chemical-inventory-database/.venv/lib/python3.10/site-packages/datasette/app.py", line 1307, in render_template return await template.render_async(template_context) File "/home/jiyang/github/global-chemical-inventory-database/.venv/lib/python3.10/site-packages/jinja2/environment.py", line 1324, in render_async return self.environment.handle_exception() File "/home/jiyang/github/global-chemical-inventory-database/.venv/lib/python3.10/site-packages/jinja2/environment.py", line 936, in handle_exception raise rewri… | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1163369515 | |
| https://github.com/simonw/datasette/issues/1655#issuecomment-1766994810 | https://api.github.com/repos/simonw/datasette/issues/1655 | 1766994810 | IC_kwDOBm6k_c5pUjN6 | 536941 | 2023-10-17T19:01:59Z | 2023-10-17T19:01:59Z | CONTRIBUTOR | hi @yejiyang, have your tried using my fork of datasette: https://github.com/fgregg/datasette/tree/no_limit_csv_publish | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1163369515 | |
| https://github.com/simonw/datasette/issues/1655#issuecomment-1761630595 | https://api.github.com/repos/simonw/datasette/issues/1655 | 1761630595 | IC_kwDOBm6k_c5pAFmD | 6262071 | 2023-10-13T14:37:48Z | 2023-10-13T14:37:48Z | NONE | Hi @fgregg, I came across this issue and found your setup at labordata.bunkum.us can help me with a research project at https://database.zeropm.eu/. I really like the approach [here](https://labordata.bunkum.us/f7-06c761c?sql=select+*+from+f7) when dealing with a custom SQL query returning more than 1000 rows: 1) At the table in HTML page, only first 1000 rows displayed; 2) When click the "Download this data as a CSV Spreadsheet(All Rows)" button, a csv with ALL ROWS (could be > 100 Mb) get downloaded. I am trying to repeat the setup but have yet to be successful so far. What I tried: 1) copy the query.html & table.html templates from this [github repo](https://github.com/labordata/warehouse/tree/main/templates) and use it my project 2) use the same datasette version 1.0a2. Do you know what else I should try to set it correctly? I appreciate your help. @simonw I would like to use this opportunity to thank you for developing & maintaining such an amazing project. I introduce your datasette to several projects in my institute. I am also interested in your cloud version. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1163369515 | |
| https://github.com/simonw/datasette/issues/2196#issuecomment-1760560526 | https://api.github.com/repos/simonw/datasette/issues/2196 | 1760560526 | IC_kwDOBm6k_c5o8AWO | 1892194 | 2023-10-13T00:07:07Z | 2023-10-13T00:07:07Z | NONE | That worked! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1910269679 | |
| https://github.com/simonw/datasette/pull/2052#issuecomment-1760552652 | https://api.github.com/repos/simonw/datasette/issues/2052 | 1760552652 | IC_kwDOBm6k_c5o7-bM | 9599 | 2023-10-12T23:59:21Z | 2023-10-12T23:59:21Z | OWNER | I'm landing this despite the cog failures. I'll fix them on main if I have to. | {
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} |
1651082214 | |
| https://github.com/simonw/datasette/pull/2052#issuecomment-1632867333 | https://api.github.com/repos/simonw/datasette/issues/2052 | 1632867333 | IC_kwDOBm6k_c5hU5QF | 22429695 | 2023-07-12T16:38:27Z | 2023-10-12T23:52:24Z | NONE | ## [Codecov](https://app.codecov.io/gh/simonw/datasette/pull/2052?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report All modified lines are covered by tests :white_check_mark: > Comparison is base [(`3feed1f`)](https://app.codecov.io/gh/simonw/datasette/commit/3feed1f66e2b746f349ee56970a62246a18bb164?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.46% compared to head [(`8ae479c`)](https://app.codecov.io/gh/simonw/datasette/pull/2052?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69%. > Report is 112 commits behind head on main. <details><summary>Additional details and impacted files</summary> ```diff @@ Coverage Diff @@ ## main #2052 +/- ## ========================================== + Coverage 92.46% 92.69% +0.22% ========================================== Files 38 40 +2 Lines 5750 6047 +297 ========================================== + Hits 5317 5605 +288 - Misses 433 442 +9 ``` [see 19 files with indirect coverage changes](https://app.codecov.io/gh/simonw/datasette/pull/2052/indirect-changes?src=pr&el=tree-more&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) </details> [:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/simonw/datasette/pull/2052?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). :loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison). | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1651082214 | |
| https://github.com/simonw/datasette/pull/2052#issuecomment-1760545012 | https://api.github.com/repos/simonw/datasette/issues/2052 | 1760545012 | IC_kwDOBm6k_c5o78j0 | 9599 | 2023-10-12T23:48:16Z | 2023-10-12T23:48:16Z | OWNER | Oh! I think I broke Cog on `main` and these tests are running against this branch rebased against main. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1651082214 | |
| https://github.com/simonw/datasette/pull/2052#issuecomment-1760542865 | https://api.github.com/repos/simonw/datasette/issues/2052 | 1760542865 | IC_kwDOBm6k_c5o78CR | 9599 | 2023-10-12T23:44:53Z | 2023-10-12T23:45:15Z | OWNER | Weird, the `cog` check is failing in CI. ``` Run cog --check docs/*.rst cog --check docs/*.rst shell: /usr/bin/bash -e {0} env: pythonLocation: /opt/hostedtoolcache/Python/3.9.18/x64 PKG_CONFIG_PATH: /opt/hostedtoolcache/Python/3.9.18/x64/lib/pkgconfig Python_ROOT_DIR: /opt/hostedtoolcache/Python/3.9.18/x64 Python2_ROOT_DIR: /opt/hostedtoolcache/Python/3.9.18/x64 Python3_ROOT_DIR: /opt/hostedtoolcache/Python/3.9.18/x64 LD_LIBRARY_PATH: /opt/hostedtoolcache/Python/3.9.18/x64/lib Check failed Checking docs/authentication.rst Checking docs/binary_data.rst Checking docs/changelog.rst Checking docs/cli-reference.rst Checking docs/configuration.rst (changed) ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1651082214 | |
| https://github.com/simonw/datasette/issues/2199#issuecomment-1760441535 | https://api.github.com/repos/simonw/datasette/issues/2199 | 1760441535 | IC_kwDOBm6k_c5o7jS_ | 9599 | 2023-10-12T22:08:42Z | 2023-10-12T22:08:42Z | OWNER | Pushed that incomplete code here: https://github.com/datasette/datasette-upgrade | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1940346034 | |
| https://github.com/simonw/datasette/issues/2196#issuecomment-1760417555 | https://api.github.com/repos/simonw/datasette/issues/2196 | 1760417555 | IC_kwDOBm6k_c5o7dcT | 9599 | 2023-10-12T21:54:52Z | 2023-10-12T21:54:52Z | OWNER | I can't replicate this bug. Closing, but please re-open if it's still happening. As an aside, the link I promote is https://datasette.io/discord which redirects: ``` curl -i 'https://datasette.io/discord' HTTP/2 301 location: https://discord.gg/ktd74dm5mw content-type: text/plain x-cloud-trace-context: 8dcfd08d3d1fa44f7ee78568e0f5305e;o=1 date: Thu, 12 Oct 2023 21:54:17 GMT server: Google Frontend content-length: 0 ``` ``` curl -i 'https://discord.gg/ktd74dm5mw' HTTP/2 301 date: Thu, 12 Oct 2023 21:54:28 GMT content-type: text/plain;charset=UTF-8 content-length: 0 location: https://discord.com/invite/ktd74dm5mw strict-transport-security: max-age=31536000; includeSubDomains; preload permissions-policy: interest-cohort=() x-content-type-options: nosniff x-frame-options: DENY x-robots-tag: noindex, nofollow, noarchive, nocache, noimageindex, noodp x-xss-protection: 1; mode=block report-to: {"endpoints":[{"url":"https:\/\/a.nel.cloudflare.com\/report\/v3?s=Dzzrf%2FgGkfFxtzSAQ46slMVDLcFjsH9fsvVkzHtgUUiZ891rXAa6LvTRpHK%2BdSMSQ54F57hS9z1mZXXklIbONZW1bfBuFjSK9J4XmjjLjsFUulMXvpjfCLkB6PI%3D"}],"group":"cf-nel","max_age":604800} nel: {"success_fraction":0,"report_to":"cf-nel","max_age":604800} server: cloudflare cf-ray: 815294ddff282511-SJC ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1910269679 | |
| https://github.com/simonw/datasette/issues/2199#issuecomment-1760413191 | https://api.github.com/repos/simonw/datasette/issues/2199 | 1760413191 | IC_kwDOBm6k_c5o7cYH | 9599 | 2023-10-12T21:52:25Z | 2023-10-12T21:52:25Z | OWNER | Demo of that logic: ``` $ datasette upgrade metadata-to-config ../datasette/metadata.json Upgrading ../datasette/metadata.json to new metadata.yaml format New metadata.yaml file will be written to metadata-new-1.yaml New datasette.yaml file will be written to datasette.yaml $ touch metadata-new-1.yaml $ datasette upgrade metadata-to-config ../datasette/metadata.json Upgrading ../datasette/metadata.json to new metadata.yaml format New metadata.yaml file will be written to metadata-new-2.yaml New datasette.yaml file will be written to datasette.yaml $ touch datasette.yaml $ datasette upgrade metadata-to-config ../datasette/metadata.json Upgrading ../datasette/metadata.json to new metadata.yaml format New metadata.yaml file will be written to metadata-new-2.yaml New datasette.yaml file will be written to datasette-new.yaml ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1940346034 | |
| https://github.com/simonw/datasette/issues/2199#issuecomment-1760412424 | https://api.github.com/repos/simonw/datasette/issues/2199 | 1760412424 | IC_kwDOBm6k_c5o7cMI | 9599 | 2023-10-12T21:51:44Z | 2023-10-12T21:51:44Z | OWNER | Started playing with this plugin idea, now tearing myself away to work on something more important: ```python from datasette import hookimpl import click import pathlib @hookimpl def register_commands(cli): @cli.group() def upgrade(): """ Apply configuration upgrades to an existing Datasette instance """ pass @upgrade.command() @click.argument( "metadata", type=click.Path(exists=True) ) @click.option( "new_metadata", "-m", "--new-metadata", help="Path to new metadata.yaml file", type=click.Path(exists=False) ) @click.option( "new_datasette", "-c", "--new-datasette", help="Path to new datasette.yaml file", type=click.Path(exists=False) ) @click.option( "output_dir", "-e", "--output-dir", help="Directory to write new files to", type=click.Path(), default="." ) def metadata_to_config(metadata, new_metadata, new_datasette, output_dir): """ Upgrade an existing metadata.json/yaml file to the new metadata.yaml and datasette.yaml split introduced prior to Datasette 1.0. """ print("Upgrading {} to new metadata.yaml format".format(metadata)) output_dir = pathlib.Path(output_dir) if not new_metadata: # Pick a filename for the new metadata.yaml file that does not yet exist new_metadata = pick_filename("metadata", output_dir) if not new_datasette: new_datasette = pick_filename("datasette", output_dir) print("New metadata.yaml file will be written to {}".format(new_metadata)) print("New datasette.yaml file will be written to {}".format(new_datasette)) def pick_filename(base, output_dir): options = ["{}.yaml".format(base), "{}-new.yaml".format(base)] i = 0 while True: option = options.pop(0) option_path = output_dir / option if not option_path.exists(): return option_path # If we ran out … | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1940346034 | |
| https://github.com/simonw/datasette/issues/2199#issuecomment-1760411937 | https://api.github.com/repos/simonw/datasette/issues/2199 | 1760411937 | IC_kwDOBm6k_c5o7cEh | 9599 | 2023-10-12T21:51:16Z | 2023-10-12T21:51:16Z | OWNER | I think I'm OK with not preserving comments, just because it adds a level of complexity to the tool which I don't think is worth the value it provides. If people want to keep their comments I'm happy to leave them to copy those over by hand. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1940346034 | |
| https://github.com/simonw/datasette/issues/2199#issuecomment-1760401731 | https://api.github.com/repos/simonw/datasette/issues/2199 | 1760401731 | IC_kwDOBm6k_c5o7ZlD | 15178711 | 2023-10-12T21:41:42Z | 2023-10-12T21:41:42Z | CONTRIBUTOR | I dig it - I was thinking an Observable notebook where you paste your `metadata.json`/`metadata.yaml` and it would generate the new metadata + datasette.yaml files, but an extensible `datasette upgrade` plugin would be nice for future plugins. One thing to think about: If someone has comments in their original `metadata.yaml`, could we preserve them in the new files? tbh maybe not too important bc if people cared that much they could just copy + paste, and it might be too distracting | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1940346034 | |
| https://github.com/simonw/datasette/issues/2199#issuecomment-1760396195 | https://api.github.com/repos/simonw/datasette/issues/2199 | 1760396195 | IC_kwDOBm6k_c5o7YOj | 9599 | 2023-10-12T21:36:25Z | 2023-10-12T21:36:25Z | OWNER | Related idea: how about a `datasette-upgrade` plugin which adds a `datasette upgrade` command that can be used to automate this process? Maybe something like this: ```bash datasette install datasette-upgrade datasette upgrade metadata-to-config metadata.json ``` This would output two new files: `metadata.yaml` and `datasette.yaml`. If files with those names existed already in the current directory they would be called `metadata-new.yaml` and `datasette-new.yaml`. The command would tell you what it did: ``` Your metadata.json file has been rewritten as two files: metadata-new.yaml datasette.yaml Start Datasette like this to try them out: datasette -m metadata-new.yaml -c datasette.yaml ``` The command is `datasette upgrade metadata-to-config` because `metadata-to-config` is the name of the upgrade recipe. The first version of the plugin would only have that single recipe, but we could add more recipes in the future for other upgrades. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1940346034 | |
| https://github.com/simonw/datasette/issues/2199#issuecomment-1759952247 | https://api.github.com/repos/simonw/datasette/issues/2199 | 1759952247 | IC_kwDOBm6k_c5o5r13 | 9599 | 2023-10-12T16:23:10Z | 2023-10-12T16:23:10Z | OWNER | Some options for where this could go: - Directly in the release notes? I'm not sure about that, those are getting pretty long already. I think the release notes should link to relevant upgrade guides. - On a new page? We could have a "upgrade instructions" page in the documentation. - At the bottom of the new https://docs.datasette.io/en/latest/configuration.html page I'm leaning towards the third option at the moment. But... we may also need to provide upgrade instructions for plugin authors. Those could live in a separate area of the documentation though, since issues affecting end-users who configure Datasette and issues affecting plugin authors are unlikely to overlap much. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1940346034 | |
| https://github.com/simonw/datasette/pull/2190#issuecomment-1759948683 | https://api.github.com/repos/simonw/datasette/issues/2190 | 1759948683 | IC_kwDOBm6k_c5o5q-L | 9599 | 2023-10-12T16:20:41Z | 2023-10-12T16:20:41Z | OWNER | I'm going to land this and open a new issue for the upgrade instructions. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1901483874 | |
| https://github.com/simonw/datasette/pull/2190#issuecomment-1759947534 | https://api.github.com/repos/simonw/datasette/issues/2190 | 1759947534 | IC_kwDOBm6k_c5o5qsO | 9599 | 2023-10-12T16:19:59Z | 2023-10-12T16:19:59Z | OWNER | It would be nice if we could catch that and turn that into a less intimidating Click exception too. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1901483874 | |
| https://github.com/simonw/datasette/pull/2190#issuecomment-1759947021 | https://api.github.com/repos/simonw/datasette/issues/2190 | 1759947021 | IC_kwDOBm6k_c5o5qkN | 9599 | 2023-10-12T16:19:38Z | 2023-10-12T16:19:38Z | OWNER | This looks good and works well. The error from this currently looks like: ``` datasette -m metadata.json -p 8844 Traceback (most recent call last): File "/Users/simon/.local/share/virtualenvs/datasette-AWNrQs95/bin/datasette", line 33, in <module> sys.exit(load_entry_point('datasette', 'console_scripts', 'datasette')()) File "/Users/simon/.local/share/virtualenvs/datasette-AWNrQs95/lib/python3.10/site-packages/click/core.py", line 1130, in __call__ return self.main(*args, **kwargs) File "/Users/simon/.local/share/virtualenvs/datasette-AWNrQs95/lib/python3.10/site-packages/click/core.py", line 1055, in main rv = self.invoke(ctx) File "/Users/simon/.local/share/virtualenvs/datasette-AWNrQs95/lib/python3.10/site-packages/click/core.py", line 1657, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/Users/simon/.local/share/virtualenvs/datasette-AWNrQs95/lib/python3.10/site-packages/click/core.py", line 1404, in invoke return ctx.invoke(self.callback, **ctx.params) File "/Users/simon/.local/share/virtualenvs/datasette-AWNrQs95/lib/python3.10/site-packages/click/core.py", line 760, in invoke return __callback(*args, **kwargs) File "/Users/simon/Dropbox/Development/datasette/datasette/cli.py", line 98, in wrapped return fn(*args, **kwargs) File "/Users/simon/Dropbox/Development/datasette/datasette/cli.py", line 546, in serve metadata_data = fail_if_plugins_in_metadata(parse_metadata(metadata.read())) File "/Users/simon/Dropbox/Development/datasette/datasette/utils/__init__.py", line 1282, in fail_if_plugins_in_metadata raise Exception( Exception: Datasette no longer accepts plugin configuration in --metadata. Move your "plugins" configuration blocks to a separate file - we suggest calling that datasette..json - and start Datasette with datasette -c datasette..json. See https://docs.datasette.io/en/latest/configuration.html for more details. ``` With wrapping: `Exception: Datasette no longer accepts plugin configu… | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1901483874 | |
| https://github.com/simonw/datasette/pull/2191#issuecomment-1724480716 | https://api.github.com/repos/simonw/datasette/issues/2191 | 1724480716 | IC_kwDOBm6k_c5myXzM | 22429695 | 2023-09-18T21:28:36Z | 2023-10-12T16:15:40Z | NONE | ## [Codecov](https://app.codecov.io/gh/simonw/datasette/pull/2191?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) Report All modified lines are covered by tests :white_check_mark: > Comparison is base [(`6ed7908`)](https://app.codecov.io/gh/simonw/datasette/commit/6ed7908580fa2ba9297c3225d85c56f8b08b9937?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.69% compared to head [(`0135e7c`)](https://app.codecov.io/gh/simonw/datasette/pull/2191?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) 92.68%. > Report is 14 commits behind head on main. > :exclamation: Current head 0135e7c differs from pull request most recent head 18b48f8. Consider uploading reports for the commit 18b48f8 to get more accurate results <details><summary>Additional details and impacted files</summary> ```diff @@ Coverage Diff @@ ## main #2191 +/- ## ========================================== - Coverage 92.69% 92.68% -0.02% ========================================== Files 40 40 Lines 6039 6042 +3 ========================================== + Hits 5598 5600 +2 - Misses 441 442 +1 ``` | [Files](https://app.codecov.io/gh/simonw/datasette/pull/2191?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison) | Coverage Δ | | |---|---|---| | [datasette/app.py](https://app.codecov.io/gh/simonw/datasette/pull/2191?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Simon+Willison#diff-ZGF0YXNldHRlL2FwcC5weQ==) | `94.09% <100.00%> (-0.11%)` | :arrow_down: | | [datasette/default\_permissions.py](https://app.codecov.io/gh/simonw/datasette/pull/2191?src=pr&el=tree&utm_medi… | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1901768721 | |
| https://github.com/simonw/datasette/issues/2197#issuecomment-1752096661 | https://api.github.com/repos/simonw/datasette/issues/2197 | 1752096661 | IC_kwDOBm6k_c5obt-V | 9599 | 2023-10-08T16:17:04Z | 2023-10-08T16:17:29Z | OWNER | https://lite.datasette.io/?install=datasette-packages#/-/packages confirms that Datasette Lite still works (`click-default-group-wheel` was originally built to allow it to run) and that it's now using these packages: ``` "click-default-group": "1.2.4", "datasette": "0.64.5", ``` Full list: ```json { "aiofiles": "23.2.1", "anyio": "3.7.1", "asgi-csrf": "0.9", "asgiref": "3.7.2", "certifi": "2022.12.7", "click": "8.1.3", "click-default-group": "1.2.4", "datasette": "0.64.5", "datasette-packages": "0.2", "h11": "0.12.0", "httpcore": "0.15.0", "httpx": "0.23.0", "hupper": "1.12", "idna": "3.4", "itsdangerous": "2.1.2", "janus": "1.0.0", "Jinja2": "3.1.2", "MarkupSafe": "2.1.2", "mergedeep": "1.3.4", "micropip": "0.3.0", "packaging": "23.0", "Pint": "0.22", "pip": "23.2.1", "pluggy": "1.0.0", "pyparsing": "3.0.9", "python-multipart": "0.0.6", "PyYAML": "6.0", "rfc3986": "1.5.0", "setuptools": "67.6.1", "sniffio": "1.3.0", "typing-extensions": "4.5.0", "uvicorn": "0.23.2" } ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1930008379 | |
| https://github.com/simonw/datasette/issues/2197#issuecomment-1752095961 | https://api.github.com/repos/simonw/datasette/issues/2197 | 1752095961 | IC_kwDOBm6k_c5obtzZ | 9599 | 2023-10-08T16:13:42Z | 2023-10-08T16:14:39Z | OWNER | Confirmed - I ran this in a fresh virtual environment: ```bash pip install --no-cache datasette ``` And now: ```bash pip freeze | grep click ``` ``` click==8.1.7 click-default-group==1.2.4 ``` ```bash datasette --version ``` ``` datasette, version 0.64.5 ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1930008379 | |
| https://github.com/simonw/datasette/issues/2197#issuecomment-1752093039 | https://api.github.com/repos/simonw/datasette/issues/2197 | 1752093039 | IC_kwDOBm6k_c5obtFv | 9599 | 2023-10-08T15:59:53Z | 2023-10-08T15:59:53Z | OWNER | Replicated this myself: ```bash cd /tmp mkdir dddd cd dddd pipenv shell pip install datasette pip freeze | grep click ``` ``` click==8.1.7 click-default-group==1.2.4 click-default-group-wheel==1.2.3 ``` Yeah this is bad, I'll ship a `0.64.5` release. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1930008379 | |
| https://github.com/simonw/sqlite-utils/issues/433#issuecomment-1747231893 | https://api.github.com/repos/simonw/sqlite-utils/issues/433 | 1747231893 | IC_kwDOCGYnMM5oJKSV | 62745 | 2023-10-04T16:15:09Z | 2023-10-04T16:28:21Z | CONTRIBUTOR | I confirm the bug, as above, and that @jonafato 's patch fixes it for me. However, it's not the right fix. The problem is that ProgressBar is being used in the wrong way. This also results in two lines being printed instead of one, like this: ``` [#######-----------------------------] 20% [####################################] 100%% ``` The bug is reproducible for me in any terminal, including Gnome Terminal and Guake, and VSCode. With VSCode I can use this launch.json to reproduce it: ```json { "version": "0.2.0", "configurations": [ { "name": "Python: Module", "type": "python", "request": "launch", "module": "sqlite_utils", "justMyCode": false, "args": ["insert", "test.db", "test", "--csv", "tests/sniff/example1.csv"] } ] } ``` [edit - deleted my analysis of why the current code is wrong, which was confused and confusing] | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1239034903 | |
| https://github.com/simonw/datasette/pull/1870#issuecomment-1745568725 | https://api.github.com/repos/simonw/datasette/issues/1870 | 1745568725 | IC_kwDOBm6k_c5oC0PV | 2495794 | 2023-10-03T19:12:37Z | 2023-10-03T19:12:37Z | NONE | Hello! Resurrecting this issue since we're running into something similar with data.catalyst.coop as our database files have ballooned up to several GB. Our Cloud Run revisions now require huge amounts of RAM to start up without receiving a SIGBUS. I'd love to see this fix merged in. It sounds like we want to make the immutable/read-only mode decision more flexible before doing so, so that we can use `ro` in Docker and `immutable` outside. If that sounds right, I'm happy to take a crack at adding that as a command-line flag or something that gets set automatically based on the expected execution environment. | {
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} |
1426379903 | |
| https://github.com/simonw/datasette/issues/1168#issuecomment-1739816358 | https://api.github.com/repos/simonw/datasette/issues/1168 | 1739816358 | IC_kwDOBm6k_c5ns32m | 9599 | 2023-09-28T18:29:05Z | 2023-09-28T18:29:05Z | OWNER | Datasette Cloud really wants this. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
777333388 | |
| https://github.com/simonw/datasette/pull/2155#issuecomment-1737906995 | https://api.github.com/repos/simonw/datasette/issues/2155 | 1737906995 | IC_kwDOBm6k_c5nllsz | 79087 | 2023-09-27T18:44:02Z | 2023-09-27T18:44:02Z | NONE | @simonw Any chance we can get this tiny patch merged for an upcoming release? | {
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1865572575 | |
| https://github.com/simonw/datasette/pull/2155#issuecomment-1737363182 | https://api.github.com/repos/simonw/datasette/issues/2155 | 1737363182 | IC_kwDOBm6k_c5njg7u | 418191 | 2023-09-27T13:05:41Z | 2023-09-27T13:05:41Z | CONTRIBUTOR | I'm hitting the #2123 issue and I just patched my local version with this and it seems to work fine. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1865572575 | |
| https://github.com/simonw/sqlite-utils/issues/595#issuecomment-1733312349 | https://api.github.com/repos/simonw/sqlite-utils/issues/595 | 1733312349 | IC_kwDOCGYnMM5nUD9d | 123451970 | 2023-09-25T09:38:13Z | 2023-09-25T09:38:57Z | NONE | Never mind When I created the connection using `sqlite_utils.Database(path)` I just needed to add the following statement right after and it did the trick `self.db.conn.execute("PRAGMA foreign_keys = ON")` Hope this helps people in the future 👍 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907281675 | |
| https://github.com/simonw/sqlite-utils/issues/297#issuecomment-1732018273 | https://api.github.com/repos/simonw/sqlite-utils/issues/297 | 1732018273 | IC_kwDOCGYnMM5nPIBh | 1108600 | 2023-09-22T20:49:51Z | 2023-09-22T20:49:51Z | NONE | This would be awesome to have for multi-gig tsv and csv files! I'm currently looking at a 10 hour countdown for one such important. Not a problem because I'm lazy and happy to let it run and check on it tomorrow.. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
944846776 | |
| https://github.com/simonw/datasette/issues/2195#issuecomment-1730458954 | https://api.github.com/repos/simonw/datasette/issues/2195 | 1730458954 | IC_kwDOBm6k_c5nJLVK | 9599 | 2023-09-21T22:57:39Z | 2023-09-21T22:57:48Z | OWNER | Worth noting that it already sets `--cors` automatically without you needing to specify it: https://github.com/simonw/datasette/blob/d97e82df3c8a3f2e97038d7080167be9bb74a68d/datasette/utils/__init__.py#L374-L374 I wonder if that's actually surprising behaviour that we should change before 1.0. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907765514 | |
| https://github.com/simonw/datasette/issues/2195#issuecomment-1730457374 | https://api.github.com/repos/simonw/datasette/issues/2195 | 1730457374 | IC_kwDOBm6k_c5nJK8e | 9599 | 2023-09-21T22:56:18Z | 2023-09-21T22:56:18Z | OWNER | Maybe I should add `--cors` and `--crossdb` to `datasette publish cloudrun` as well? | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907765514 | |
| https://github.com/simonw/datasette/issues/2195#issuecomment-1730446937 | https://api.github.com/repos/simonw/datasette/issues/2195 | 1730446937 | IC_kwDOBm6k_c5nJIZZ | 9599 | 2023-09-21T22:46:42Z | 2023-09-21T22:46:52Z | OWNER | Found more when I [searched for YAML](https://github.com/search?q=datasette+publish+extra-options++language%3AYAML&type=code). Here's the most interesting: https://github.com/labordata/warehouse/blob/0029a72fc1ceae9091932da6566f891167179012/.github/workflows/build.yml#L59 `--extra-options="--crossdb --setting sql_time_limit_ms 100000 --cors --setting facet_time_limit_ms 500 --setting allow_facet off --setting trace_debug 1"` Uses both `--cors` and `--crossdb`. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907765514 | |
| https://github.com/simonw/datasette/issues/2195#issuecomment-1730441613 | https://api.github.com/repos/simonw/datasette/issues/2195 | 1730441613 | IC_kwDOBm6k_c5nJHGN | 9599 | 2023-09-21T22:42:12Z | 2023-09-21T22:42:12Z | OWNER | https://github.com/search?q=datasette+publish+extra-options+language%3AShell&type=code&l=Shell shows 17 matches, I'll copy in illustrative examples here: ``` --extra-options="--setting sql_time_limit_ms 5000" --extra-options="--config default_cache_ttl:3600 --config hash_urls:1" --extra-options "--setting sql_time_limit_ms 3500 --setting default_page_size 20 --setting trace_debug 1" --extra-options="--config default_page_size:50 --config sql_time_limit_ms:30000 --config facet_time_limit_ms:10000" --extra-options="--setting sql_time_limit_ms 5000" --extra-options "--setting suggest_facets off --setting allow_download on --setting truncate_cells_html 0 --setting max_csv_mb 0 --setting sql_time_limit_ms 2000" ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907765514 | |
| https://github.com/simonw/datasette/issues/2195#issuecomment-1730438503 | https://api.github.com/repos/simonw/datasette/issues/2195 | 1730438503 | IC_kwDOBm6k_c5nJGVn | 9599 | 2023-09-21T22:38:10Z | 2023-09-21T22:38:10Z | OWNER | I'd really like to remove `--extra-options`. I think the new design makes that completely obsolete? Maybe it doesn't. You still need `--extra-options` for the `--crossdb` option for example. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907765514 | |
| https://github.com/simonw/datasette/issues/2195#issuecomment-1730437934 | https://api.github.com/repos/simonw/datasette/issues/2195 | 1730437934 | IC_kwDOBm6k_c5nJGMu | 9599 | 2023-09-21T22:37:22Z | 2023-09-21T22:37:22Z | OWNER | Here's the full help for Cloud Run at the moment: ```bash datasette publish cloudrun --help ``` ``` Usage: datasette publish cloudrun [OPTIONS] [FILES]... Publish databases to Datasette running on Cloud Run Options: -m, --metadata FILENAME Path to JSON/YAML file containing metadata to publish --extra-options TEXT Extra options to pass to datasette serve --branch TEXT Install datasette from a GitHub branch e.g. main --template-dir DIRECTORY Path to directory containing custom templates --plugins-dir DIRECTORY Path to directory containing custom plugins --static MOUNT:DIRECTORY Serve static files from this directory at /MOUNT/... --install TEXT Additional packages (e.g. plugins) to install --plugin-secret <TEXT TEXT TEXT>... Secrets to pass to plugins, e.g. --plugin- secret datasette-auth-github client_id xxx --version-note TEXT Additional note to show on /-/versions --secret TEXT Secret used for signing secure values, such as signed cookies --title TEXT Title for metadata --license TEXT License label for metadata --license_url TEXT License URL for metadata --source TEXT Source label for metadata --source_url TEXT Source URL for metadata --about TEXT About label for metadata --about_url TEXT About URL for metadata -n, --name TEXT Application name to use when building --service TEXT Cloud Run service to deploy (or over-write) --spatialite Enable SpatialLite extension --show-files … | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907765514 | |
| https://github.com/simonw/datasette/issues/2195#issuecomment-1730437237 | https://api.github.com/repos/simonw/datasette/issues/2195 | 1730437237 | IC_kwDOBm6k_c5nJGB1 | 9599 | 2023-09-21T22:36:22Z | 2023-09-21T22:36:22Z | OWNER | I think the actual design of this is pretty simple. Current help starts like this: ``` Usage: datasette publish cloudrun [OPTIONS] [FILES]... Publish databases to Datasette running on Cloud Run Options: -m, --metadata FILENAME Path to JSON/YAML file containing metadata to publish --extra-options TEXT Extra options to pass to datasette serve ``` The `-s` and `-c` short options are not being used. So I think `-c/--config` can point to a JSON or YAML `datasette.yaml` file, and `-s/--setting key value` can mirror the new `-s/--setting` option in `datasette serve` itself (a shortcut for populating the config file directly from the CLI). Here's the relevant help section from `datasette serve`: ``` -m, --metadata FILENAME Path to JSON/YAML file containing license/source metadata -c, --config FILENAME Path to JSON/YAML Datasette configuration file -s, --setting SETTING... nested.key, value setting to use in Datasette configuration ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907765514 | |
| https://github.com/simonw/datasette/issues/2189#issuecomment-1730388418 | https://api.github.com/repos/simonw/datasette/issues/2189 | 1730388418 | IC_kwDOBm6k_c5nI6HC | 9599 | 2023-09-21T22:26:19Z | 2023-09-21T22:26:19Z | OWNER | 1.0a7 is out with this fix as well now: https://docs.datasette.io/en/1.0a7/changelog.html#a7-2023-09-21 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1901416155 | |
| https://github.com/simonw/datasette/issues/2057#issuecomment-1730363182 | https://api.github.com/repos/simonw/datasette/issues/2057 | 1730363182 | IC_kwDOBm6k_c5nIz8u | 9599 | 2023-09-21T22:09:10Z | 2023-09-21T22:09:10Z | OWNER | Tests all pass now. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1662951875 | |
| https://github.com/simonw/datasette/issues/2194#issuecomment-1730362441 | https://api.github.com/repos/simonw/datasette/issues/2194 | 1730362441 | IC_kwDOBm6k_c5nIzxJ | 9599 | 2023-09-21T22:08:19Z | 2023-09-21T22:08:19Z | OWNER | That worked https://github.com/simonw/datasette/commit/e4f868801a6633400045f59584cfe650961c3fa6 is the latest commit right now and https://latest.datasette.io/-/versions shows that as the deployed version. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907695234 | |
| https://github.com/simonw/datasette/issues/2057#issuecomment-1730356422 | https://api.github.com/repos/simonw/datasette/issues/2057 | 1730356422 | IC_kwDOBm6k_c5nIyTG | 9599 | 2023-09-21T22:01:00Z | 2023-09-21T22:01:00Z | OWNER | Tested that locally with Python 3.9 from `pyenv` and it worked. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1662951875 | |
| https://github.com/simonw/datasette/issues/2057#issuecomment-1730353462 | https://api.github.com/repos/simonw/datasette/issues/2057 | 1730353462 | IC_kwDOBm6k_c5nIxk2 | 9599 | 2023-09-21T21:57:17Z | 2023-09-21T21:57:17Z | OWNER | Still fails in Python 3.9: https://github.com/simonw/datasette/actions/runs/6266752548/job/17018363302 ``` plugin_info["name"] = distinfo.name or distinfo.project_name AttributeError: 'PathDistribution' object has no attribute 'name' Test failed: datasette-json-html should not have been loaded ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1662951875 | |
| https://github.com/simonw/datasette/issues/2193#issuecomment-1730353006 | https://api.github.com/repos/simonw/datasette/issues/2193 | 1730353006 | IC_kwDOBm6k_c5nIxdu | 9599 | 2023-09-21T21:56:43Z | 2023-09-21T21:56:43Z | OWNER | The test fails as expected now. Closing this issue, will solve the remaining problems in: - #2057 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907655261 | |
| https://github.com/simonw/datasette/issues/2193#issuecomment-1730352111 | https://api.github.com/repos/simonw/datasette/issues/2193 | 1730352111 | IC_kwDOBm6k_c5nIxPv | 9599 | 2023-09-21T21:55:41Z | 2023-09-21T21:55:41Z | OWNER | https://github.com/simonw/datasette/actions/runs/6267146158/job/17019594849 failed on 3.9 this time. ``` plugin_info["name"] = distinfo.name or distinfo.project_name AttributeError: 'PathDistribution' object has no attribute 'name' Test failed: datasette-json-html should not have been loaded ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907655261 | |
| https://github.com/simonw/datasette/issues/2195#issuecomment-1730313565 | https://api.github.com/repos/simonw/datasette/issues/2195 | 1730313565 | IC_kwDOBm6k_c5nIn1d | 9599 | 2023-09-21T21:16:31Z | 2023-09-21T21:16:31Z | OWNER | The `@add_common_publish_arguments_and_options` decorator described here is bad. If I update it to support a new `config` option all plugins that use it will break. https://github.com/simonw/datasette/blob/f130c7c0a88e50cea4121ea18d1f6db2431b6fab/docs/plugin_hooks.rst#L347-L355 I want to deprecate it and switch to a different, better design to address the same problem. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907765514 | |
| https://github.com/simonw/datasette/issues/2195#issuecomment-1730312128 | https://api.github.com/repos/simonw/datasette/issues/2195 | 1730312128 | IC_kwDOBm6k_c5nInfA | 9599 | 2023-09-21T21:15:11Z | 2023-09-21T21:15:11Z | OWNER | As soon as `datasette publish cloudrun` has this I can re-enable this bit of the demo deploy: https://github.com/simonw/datasette/blob/2da1a6acec915b81a16127008fd739c7d6075681/.github/workflows/deploy-latest.yml#L91-L97 Which should fix this broken demo from https://simonwillison.net/2022/Dec/2/datasette-write-api/ https://todomvc.datasette.io/ | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907765514 | |
| https://github.com/simonw/datasette/issues/2194#issuecomment-1730305920 | https://api.github.com/repos/simonw/datasette/issues/2194 | 1730305920 | IC_kwDOBm6k_c5nIl-A | 9599 | 2023-09-21T21:09:21Z | 2023-09-21T21:09:21Z | OWNER | I'm going to disable this bit of the deploy for the moment, which will break the demo linked to from https://simonwillison.net/2022/Dec/2/datasette-write-api/ https://github.com/simonw/datasette/blob/2da1a6acec915b81a16127008fd739c7d6075681/.github/workflows/deploy-latest.yml#L91-L97 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907695234 | |
| https://github.com/simonw/datasette/issues/2194#issuecomment-1730259871 | https://api.github.com/repos/simonw/datasette/issues/2194 | 1730259871 | IC_kwDOBm6k_c5nIauf | 9599 | 2023-09-21T20:34:09Z | 2023-09-21T20:34:09Z | OWNER | ... which raises the challenge that `datasette publish` doesn't yet know what to do with a config file! https://github.com/simonw/datasette/blob/2da1a6acec915b81a16127008fd739c7d6075681/.github/workflows/deploy-latest.yml#L114-L122 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907695234 | |
| https://github.com/simonw/datasette/issues/2194#issuecomment-1730258302 | https://api.github.com/repos/simonw/datasette/issues/2194 | 1730258302 | IC_kwDOBm6k_c5nIaV- | 9599 | 2023-09-21T20:32:53Z | 2023-09-21T20:33:02Z | OWNER | Correct usage is now: ```bash python tests/fixtures.py fixtures.db fixtures-config.json fixtures-metadata.json \ plugins --extra-db-filename extra_database.db ``` ``` Test tables written to fixtures.db - metadata written to fixtures-metadata.json - config written to fixtures-config.json Wrote plugin: plugins/register_output_renderer.py Wrote plugin: plugins/view_name.py Wrote plugin: plugins/my_plugin.py Wrote plugin: plugins/messages_output_renderer.py Wrote plugin: plugins/sleep_sql_function.py Wrote plugin: plugins/my_plugin_2.py Test tables written to extra_database.db ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907695234 | |
| https://github.com/simonw/datasette/issues/2194#issuecomment-1730256435 | https://api.github.com/repos/simonw/datasette/issues/2194 | 1730256435 | IC_kwDOBm6k_c5nIZ4z | 9599 | 2023-09-21T20:31:22Z | 2023-09-21T20:31:31Z | OWNER | New error: "Error: Metadata should end with .json" https://github.com/simonw/datasette/actions/runs/6266720924/job/17018265851 <img width="678" alt="CleanShot 2023-09-21 at 13 31 08@2x" src="https://github.com/simonw/datasette/assets/9599/720726be-fcfc-49a4-8316-ee49d96ac86b"> | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907695234 | |
| https://github.com/simonw/datasette/issues/2057#issuecomment-1730250337 | https://api.github.com/repos/simonw/datasette/issues/2057 | 1730250337 | IC_kwDOBm6k_c5nIYZh | 9599 | 2023-09-21T20:26:12Z | 2023-09-21T20:26:12Z | OWNER | That does seem to fix the problem! | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1662951875 | |
| https://github.com/simonw/datasette/issues/2057#issuecomment-1730247545 | https://api.github.com/repos/simonw/datasette/issues/2057 | 1730247545 | IC_kwDOBm6k_c5nIXt5 | 9599 | 2023-09-21T20:23:47Z | 2023-09-21T20:23:47Z | OWNER | Hunch: https://pypi.org/project/importlib-metadata/ may help here. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1662951875 | |
| https://github.com/simonw/datasette/issues/2194#issuecomment-1730245204 | https://api.github.com/repos/simonw/datasette/issues/2194 | 1730245204 | IC_kwDOBm6k_c5nIXJU | 9599 | 2023-09-21T20:21:42Z | 2023-09-21T20:21:42Z | OWNER | I think I see the problem - it's from here: https://github.com/simonw/datasette/commit/b2ec8717c3619260a1b535eea20e618bf95aa30b#diff-5dbc88d6e5c3615caf10e32a9d6fc6ff683f5b5814948928cb84c3ab91c038b6L770 The `config` and `metadata` Click options are the wrong way round: https://github.com/simonw/datasette/blob/80a9cd9620fddf2695d12d8386a91e7c6b145ef2/tests/fixtures.py#L785-L786 https://github.com/simonw/datasette/blob/80a9cd9620fddf2695d12d8386a91e7c6b145ef2/tests/fixtures.py#L801 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907695234 | |
| https://github.com/simonw/datasette/issues/2194#issuecomment-1730242734 | https://api.github.com/repos/simonw/datasette/issues/2194 | 1730242734 | IC_kwDOBm6k_c5nIWiu | 9599 | 2023-09-21T20:19:29Z | 2023-09-21T20:19:29Z | OWNER | Maybe `plugins/` does not exist? It should have been created by this line: https://github.com/simonw/datasette/blob/80a9cd9620fddf2695d12d8386a91e7c6b145ef2/.github/workflows/deploy-latest.yml#L41-L42 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907695234 | |
| https://github.com/simonw/datasette/issues/2194#issuecomment-1730241813 | https://api.github.com/repos/simonw/datasette/issues/2194 | 1730241813 | IC_kwDOBm6k_c5nIWUV | 9599 | 2023-09-21T20:18:40Z | 2023-09-21T20:18:40Z | OWNER | This looks to be the step that is failing: https://github.com/simonw/datasette/blob/80a9cd9620fddf2695d12d8386a91e7c6b145ef2/.github/workflows/deploy-latest.yml#L50-L60 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1907695234 | |
| https://github.com/simonw/datasette/issues/2189#issuecomment-1730232308 | https://api.github.com/repos/simonw/datasette/issues/2189 | 1730232308 | IC_kwDOBm6k_c5nIT_0 | 9599 | 2023-09-21T20:11:16Z | 2023-09-21T20:11:16Z | OWNER | We're planning a breaking change in `1.0a7`: - #2191 Since that's a breaking change I'm going to ship 1.0a7 right now with this fix, then ship that breaking change as `1.0a8` instead. | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1901416155 | |
| https://github.com/simonw/datasette/issues/2189#issuecomment-1730231404 | https://api.github.com/repos/simonw/datasette/issues/2189 | 1730231404 | IC_kwDOBm6k_c5nITxs | 9599 | 2023-09-21T20:10:28Z | 2023-09-21T20:10:28Z | OWNER | Release 0.64.4: https://docs.datasette.io/en/stable/changelog.html#v0-64-4 | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1901416155 | |
| https://github.com/simonw/datasette/issues/2057#issuecomment-1730226107 | https://api.github.com/repos/simonw/datasette/issues/2057 | 1730226107 | IC_kwDOBm6k_c5nISe7 | 9599 | 2023-09-21T20:06:19Z | 2023-09-21T20:06:19Z | OWNER | No that's not it actually, it's something else. Got to this point: ```bash DATASETTE_LOAD_PLUGINS=datasette-init python -i $(which datasette) plugins ``` That fails and drops me into a debugger: ``` File "/Users/simon/Dropbox/Development/datasette/datasette/cli.py", line 186, in plugins app = Datasette([], plugins_dir=plugins_dir) File "/Users/simon/Dropbox/Development/datasette/datasette/app.py", line 405, in __init__ for plugin in get_plugins() File "/Users/simon/Dropbox/Development/datasette/datasette/plugins.py", line 89, in get_plugins plugin_info["name"] = distinfo.name or distinfo.project_name AttributeError: 'PathDistribution' object has no attribute 'name' ``` | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
1662951875 |