issue_comments
8,358 rows where author_association = "OWNER" sorted by updated_at descending
This data as json, CSV (advanced)
user 1
- simonw 5,638
| id | html_url | issue_url | node_id | user | created_at | updated_at ▲ | author_association | body | reactions | issue | performed_via_github_app |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1008234293 | https://github.com/simonw/sqlite-utils/issues/364#issuecomment-1008234293 | https://api.github.com/repos/simonw/sqlite-utils/issues/364 | IC_kwDOCGYnMM48GG81 | simonw 9599 | 2022-01-09T05:37:02Z | 2022-01-09T05:37:02Z | OWNER | Calling |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`--batch-size 1` doesn't seem to commit for every item 1095570074 | |
| 1008233910 | https://github.com/simonw/sqlite-utils/issues/364#issuecomment-1008233910 | https://api.github.com/repos/simonw/sqlite-utils/issues/364 | IC_kwDOCGYnMM48GG22 | simonw 9599 | 2022-01-09T05:32:53Z | 2022-01-09T05:35:45Z | OWNER | This is strange. The following: ```pycon
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`--batch-size 1` doesn't seem to commit for every item 1095570074 | |
| 1008232075 | https://github.com/simonw/sqlite-utils/issues/369#issuecomment-1008232075 | https://api.github.com/repos/simonw/sqlite-utils/issues/369 | IC_kwDOCGYnMM48GGaL | simonw 9599 | 2022-01-09T05:13:15Z | 2022-01-09T05:13:56Z | OWNER | I think the query that will help solve this is:
In this case, the query planner needs to decide if it should use the index for the | tbl | idx | stat | |----------------------|---------------------------------|---------------| | ny_times_us_counties | idx_ny_times_us_counties_date | 2092871 2915 | | ny_times_us_counties | idx_ny_times_us_counties_fips | 2092871 651 | | ny_times_us_counties | idx_ny_times_us_counties_county | 2092871 1085 | | ny_times_us_counties | idx_ny_times_us_counties_state | 2092871 37373 | Those numbers are explained by this comment in the SQLite C code: https://github.com/sqlite/sqlite/blob/5622c7f97106314719740098cf0854e7eaa81802/src/analyze.c#L41-L55
Just one catch: against both my |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research how much of a difference analyze / sqlite_stat1 makes 1097091527 | |
| 1008229839 | https://github.com/simonw/sqlite-utils/issues/365#issuecomment-1008229839 | https://api.github.com/repos/simonw/sqlite-utils/issues/365 | IC_kwDOCGYnMM48GF3P | simonw 9599 | 2022-01-09T04:51:44Z | 2022-01-09T04:51:44Z | OWNER | Found one report on Stack Overflow from 9 years ago of someone seeing broken performance after running |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
create-index should run analyze after creating index 1096558279 | |
| 1008229341 | https://github.com/simonw/sqlite-utils/issues/369#issuecomment-1008229341 | https://api.github.com/repos/simonw/sqlite-utils/issues/369 | IC_kwDOCGYnMM48GFvd | simonw 9599 | 2022-01-09T04:45:38Z | 2022-01-09T04:47:11Z | OWNER | This is probably too fancy. I think maybe the way to do this is with Here's the explain for that: https://global-power-plants.datasettes.com/global-power-plants?sql=EXPLAIN+QUERY+PLAN+select+*+from+[global-power-plants]+where+%22country_long%22+%3D+%27United+Kingdom%27 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research how much of a difference analyze / sqlite_stat1 makes 1097091527 | |
| 1008227625 | https://github.com/simonw/sqlite-utils/issues/369#issuecomment-1008227625 | https://api.github.com/repos/simonw/sqlite-utils/issues/369 | IC_kwDOCGYnMM48GFUp | simonw 9599 | 2022-01-09T04:25:38Z | 2022-01-09T04:25:38Z | OWNER |
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research how much of a difference analyze / sqlite_stat1 makes 1097091527 | |
| 1008227436 | https://github.com/simonw/datasette/issues/1588#issuecomment-1008227436 | https://api.github.com/repos/simonw/datasette/issues/1588 | IC_kwDOBm6k_c48GFRs | simonw 9599 | 2022-01-09T04:23:37Z | 2022-01-09T04:25:04Z | OWNER | Relevant code: https://github.com/simonw/datasette/blob/85849935292e500ab7a99f8fe0f9546e903baad3/datasette/utils/init.py#L163-L170 https://github.com/simonw/datasette/blob/85849935292e500ab7a99f8fe0f9546e903baad3/datasette/utils/init.py#L195-L204 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`explain query plan select` is too strict about whitespace 1097101917 | |
| 1008227491 | https://github.com/simonw/datasette/issues/1588#issuecomment-1008227491 | https://api.github.com/repos/simonw/datasette/issues/1588 | IC_kwDOBm6k_c48GFSj | simonw 9599 | 2022-01-09T04:24:09Z | 2022-01-09T04:24:09Z | OWNER | I think this is the fix:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`explain query plan select` is too strict about whitespace 1097101917 | |
| 1008226862 | https://github.com/simonw/sqlite-utils/issues/369#issuecomment-1008226862 | https://api.github.com/repos/simonw/sqlite-utils/issues/369 | IC_kwDOCGYnMM48GFIu | simonw 9599 | 2022-01-09T04:17:55Z | 2022-01-09T04:17:55Z | OWNER | There are some clues as to what effect ANALYZE has in https://www.sqlite.org/optoverview.html Some quotes:
And
And
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research how much of a difference analyze / sqlite_stat1 makes 1097091527 | |
| 1008226487 | https://github.com/simonw/sqlite-utils/issues/369#issuecomment-1008226487 | https://api.github.com/repos/simonw/sqlite-utils/issues/369 | IC_kwDOCGYnMM48GFC3 | simonw 9599 | 2022-01-09T04:14:05Z | 2022-01-09T04:14:05Z | OWNER | Didn't manage to spot a meaningful difference with that database either:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research how much of a difference analyze / sqlite_stat1 makes 1097091527 | |
| 1008220270 | https://github.com/simonw/sqlite-utils/issues/369#issuecomment-1008220270 | https://api.github.com/repos/simonw/sqlite-utils/issues/369 | IC_kwDOCGYnMM48GDhu | simonw 9599 | 2022-01-09T03:12:38Z | 2022-01-09T03:13:15Z | OWNER | Basically no difference using this very basic benchmark:
https://covid-19.datasettes.com/covid.db is 879MB. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research how much of a difference analyze / sqlite_stat1 makes 1097091527 | |
| 1008219844 | https://github.com/simonw/sqlite-utils/issues/369#issuecomment-1008219844 | https://api.github.com/repos/simonw/sqlite-utils/issues/369 | IC_kwDOCGYnMM48GDbE | simonw 9599 | 2022-01-09T03:08:09Z | 2022-01-09T03:08:09Z | OWNER | ``` analyze % sqlite-utils global-power-plants-analyzed.db 'analyze' [{"rows_affected": -1}] analyze % sqlite-utils tables global-power-plants-analyzed.db [{"table": "global-power-plants"}, {"table": "global-power-plants_fts"}, {"table": "global-power-plants_fts_data"}, {"table": "global-power-plants_fts_idx"}, {"table": "global-power-plants_fts_docsize"}, {"table": "global-power-plants_fts_config"}, {"table": "sqlite_stat1"}] analyze % sqlite-utils rows global-power-plants-analyzed.db sqlite_stat1 -t tbl idx stat global-power-plants_fts_config global-power-plants_fts_config 1 1 global-power-plants_fts_docsize 33643 global-power-plants_fts_idx global-power-plants_fts_idx 199 40 1 global-power-plants_fts_data 136 global-power-plants "global-power-plants_owner" 33643 4 global-power-plants "global-power-plants_country_long" 33643 202 ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research how much of a difference analyze / sqlite_stat1 makes 1097091527 | |
| 1008219588 | https://github.com/simonw/sqlite-utils/issues/369#issuecomment-1008219588 | https://api.github.com/repos/simonw/sqlite-utils/issues/369 | IC_kwDOCGYnMM48GDXE | simonw 9599 | 2022-01-09T03:06:42Z | 2022-01-09T03:06:42Z | OWNER | ```
analyze % sqlite-utils indexes global-power-plants.db -t global-power-plants "global-power-plants_owner" 0 12 owner 0 BINARY 1 global-power-plants "global-power-plants_country_long" 0 1 country_long 0 BINARY 1 global-power-plants_fts_idx sqlite_autoindex_global-power-plants_fts_idx_1 0 0 segid 0 BINARY 1 global-power-plants_fts_idx sqlite_autoindex_global-power-plants_fts_idx_1 1 1 term 0 BINARY 1 global-power-plants_fts_config sqlite_autoindex_global-power-plants_fts_config_1 0 0 k 0 BINARY 1 ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research how much of a difference analyze / sqlite_stat1 makes 1097091527 | |
| 1008219484 | https://github.com/simonw/sqlite-utils/issues/369#issuecomment-1008219484 | https://api.github.com/repos/simonw/sqlite-utils/issues/369 | IC_kwDOCGYnMM48GDVc | simonw 9599 | 2022-01-09T03:05:44Z | 2022-01-09T03:05:44Z | OWNER | I'll start by running some experiments against the 11MB database file from https://global-power-plants.datasettes.com/global-power-plants.db |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research how much of a difference analyze / sqlite_stat1 makes 1097091527 | |
| 1008219191 | https://github.com/simonw/sqlite-utils/issues/369#issuecomment-1008219191 | https://api.github.com/repos/simonw/sqlite-utils/issues/369 | IC_kwDOCGYnMM48GDQ3 | simonw 9599 | 2022-01-09T03:03:53Z | 2022-01-09T03:03:53Z | OWNER | Refs: - #366 - #365 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research how much of a difference analyze / sqlite_stat1 makes 1097091527 | |
| 1008163585 | https://github.com/simonw/sqlite-utils/issues/365#issuecomment-1008163585 | https://api.github.com/repos/simonw/sqlite-utils/issues/365 | IC_kwDOCGYnMM48F1sB | simonw 9599 | 2022-01-08T22:14:39Z | 2022-01-09T03:03:07Z | OWNER | The reason I'm hesitating on this is that I've not actually used ANALYZE at all in nearly five years of messing around with SQLite! So I'm nervous that there are surprise downsides I haven't thought of. My hunch is that ANALYZE is only worth worrying about on much larger databases, in which case I'm OK supporting it as a thoroughly documented power-user feature rather than a default. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
create-index should run analyze after creating index 1096558279 | |
| 1008216371 | https://github.com/simonw/sqlite-utils/issues/368#issuecomment-1008216371 | https://api.github.com/repos/simonw/sqlite-utils/issues/368 | IC_kwDOCGYnMM48GCkz | simonw 9599 | 2022-01-09T02:36:22Z | 2022-01-09T02:36:22Z | OWNER | In Python 3.6: https://docs.python.org/3.6/library/subprocess.html
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Offer `python -m sqlite_utils` as an alternative to `sqlite-utils` 1097087280 | |
| 1008216271 | https://github.com/simonw/sqlite-utils/issues/368#issuecomment-1008216271 | https://api.github.com/repos/simonw/sqlite-utils/issues/368 | IC_kwDOCGYnMM48GCjP | simonw 9599 | 2022-01-09T02:35:09Z | 2022-01-09T02:35:09Z | OWNER | Test failure on Python 3.6:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Offer `python -m sqlite_utils` as an alternative to `sqlite-utils` 1097087280 | |
| 1008216201 | https://github.com/simonw/sqlite-utils/issues/364#issuecomment-1008216201 | https://api.github.com/repos/simonw/sqlite-utils/issues/364 | IC_kwDOCGYnMM48GCiJ | simonw 9599 | 2022-01-09T02:34:12Z | 2022-01-09T02:34:12Z | OWNER | I can now write tests that look like this: https://github.com/simonw/sqlite-utils/blob/539f5ccd90371fa87f946018f8b77d55929e06db/tests/test_cli.py#L2024-L2030 Which means I can write a test that exercises this bug. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`--batch-size 1` doesn't seem to commit for every item 1095570074 | |
| 1008215912 | https://github.com/simonw/sqlite-utils/issues/368#issuecomment-1008215912 | https://api.github.com/repos/simonw/sqlite-utils/issues/368 | IC_kwDOCGYnMM48GCdo | simonw 9599 | 2022-01-09T02:30:59Z | 2022-01-09T02:30:59Z | OWNER | Even better, inspired by |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Offer `python -m sqlite_utils` as an alternative to `sqlite-utils` 1097087280 | |
| 1008214998 | https://github.com/simonw/sqlite-utils/issues/364#issuecomment-1008214998 | https://api.github.com/repos/simonw/sqlite-utils/issues/364 | IC_kwDOCGYnMM48GCPW | simonw 9599 | 2022-01-09T02:23:20Z | 2022-01-09T02:23:20Z | OWNER | Possible way of running the test: add this to
Then in the test use |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`--batch-size 1` doesn't seem to commit for every item 1095570074 | |
| 1008214406 | https://github.com/simonw/sqlite-utils/issues/364#issuecomment-1008214406 | https://api.github.com/repos/simonw/sqlite-utils/issues/364 | IC_kwDOCGYnMM48GCGG | simonw 9599 | 2022-01-09T02:18:21Z | 2022-01-09T02:18:21Z | OWNER | I'm having trouble figuring out the best way to write a unit test for this. Filed a relevant feature request for Click here: - https://github.com/pallets/click/issues/2171 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`--batch-size 1` doesn't seem to commit for every item 1095570074 | |
| 1008163050 | https://github.com/simonw/sqlite-utils/issues/365#issuecomment-1008163050 | https://api.github.com/repos/simonw/sqlite-utils/issues/365 | IC_kwDOCGYnMM48F1jq | simonw 9599 | 2022-01-08T22:10:51Z | 2022-01-08T22:10:51Z | OWNER | Is there a downside to having a Imagine the following sequence of events:
The user now has a database file with several million records and a statistics table that is wildly out of date, having been populated when they only had a few. Will this result in surprisingly bad query performance compared to it that statistics table did not exist at all? If so, I lean much harder towards |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
create-index should run analyze after creating index 1096558279 | |
| 1008158616 | https://github.com/simonw/sqlite-utils/issues/366#issuecomment-1008158616 | https://api.github.com/repos/simonw/sqlite-utils/issues/366 | IC_kwDOCGYnMM48F0eY | simonw 9599 | 2022-01-08T21:35:32Z | 2022-01-08T21:35:32Z | OWNER | Built a prototype in a branch, see #367. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Python library methods for calling ANALYZE 1096563265 | |
| 1008158357 | https://github.com/simonw/sqlite-utils/issues/365#issuecomment-1008158357 | https://api.github.com/repos/simonw/sqlite-utils/issues/365 | IC_kwDOCGYnMM48F0aV | simonw 9599 | 2022-01-08T21:33:07Z | 2022-01-08T21:33:07Z | OWNER | The one thing that worries me a little bit about doing this by default is that it adds a surprising new table to the database - it may be confusing to users if they run Options here are:
I'm currently leading towards that third option - @fgregg any thoughts? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
create-index should run analyze after creating index 1096558279 | |
| 1008157998 | https://github.com/simonw/datasette/issues/1587#issuecomment-1008157998 | https://api.github.com/repos/simonw/datasette/issues/1587 | IC_kwDOBm6k_c48F0Uu | simonw 9599 | 2022-01-08T21:29:54Z | 2022-01-08T21:29:54Z | OWNER | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Add `sqlite_stat1`(-4) tables to hidden table list 1097040427 | ||
| 1008157908 | https://github.com/simonw/datasette/issues/1587#issuecomment-1008157908 | https://api.github.com/repos/simonw/datasette/issues/1587 | IC_kwDOBm6k_c48F0TU | simonw 9599 | 2022-01-08T21:29:06Z | 2022-01-08T21:29:06Z | OWNER | Depending on the SQLite version (and compile options) that ran
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Add `sqlite_stat1`(-4) tables to hidden table list 1097040427 | |
| 1008157132 | https://github.com/simonw/sqlite-utils/issues/366#issuecomment-1008157132 | https://api.github.com/repos/simonw/sqlite-utils/issues/366 | IC_kwDOCGYnMM48F0HM | simonw 9599 | 2022-01-08T21:23:08Z | 2022-01-08T21:25:05Z | OWNER | Running This should be added to the default list of hidden tables in Datasette. It looks something like this: | tbl | idx | stat | |---------------------------------|------------------------------------|-----------| | _counts | sqlite_autoindex__counts_1 | 5 1 | | global-power-plants_fts_config | global-power-plants_fts_config | 1 1 | | global-power-plants_fts_docsize | | 33643 | | global-power-plants_fts_idx | global-power-plants_fts_idx | 199 40 1 | | global-power-plants_fts_data | | 136 | | global-power-plants | "global-power-plants_owner" | 33643 4 | | global-power-plants | "global-power-plants_country_long" | 33643 202 |
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Python library methods for calling ANALYZE 1096563265 | |
| 1008155916 | https://github.com/simonw/sqlite-utils/issues/364#issuecomment-1008155916 | https://api.github.com/repos/simonw/sqlite-utils/issues/364 | IC_kwDOCGYnMM48Fz0M | simonw 9599 | 2022-01-08T21:16:46Z | 2022-01-08T21:16:46Z | OWNER | No, |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`--batch-size 1` doesn't seem to commit for every item 1095570074 | |
| 1008154873 | https://github.com/simonw/sqlite-utils/issues/364#issuecomment-1008154873 | https://api.github.com/repos/simonw/sqlite-utils/issues/364 | IC_kwDOCGYnMM48Fzj5 | simonw 9599 | 2022-01-08T21:11:55Z | 2022-01-08T21:11:55Z | OWNER | I'm suspicious that the In [11]: [list(d) for d in list(chunks('abcdefghi', 5))] Out[11]: [['a'], ['b'], ['c'], ['d'], ['e'], ['f'], ['g'], ['h'], ['i']] In [12]: [list(d) for d in list(chunks('abcdefghi', 3))] Out[12]: [['a'], ['b'], ['c'], ['d'], ['e'], ['f'], ['g'], ['h'], ['i']] ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`--batch-size 1` doesn't seem to commit for every item 1095570074 | |
| 1008153586 | https://github.com/simonw/sqlite-utils/issues/364#issuecomment-1008153586 | https://api.github.com/repos/simonw/sqlite-utils/issues/364 | IC_kwDOCGYnMM48FzPy | simonw 9599 | 2022-01-08T21:06:15Z | 2022-01-08T21:06:15Z | OWNER | I added a print statement after |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`--batch-size 1` doesn't seem to commit for every item 1095570074 | |
| 1008151884 | https://github.com/simonw/sqlite-utils/issues/364#issuecomment-1008151884 | https://api.github.com/repos/simonw/sqlite-utils/issues/364 | IC_kwDOCGYnMM48Fy1M | simonw 9599 | 2022-01-08T20:59:21Z | 2022-01-08T20:59:21Z | OWNER | (That Heroku example doesn't record the timestamp, which limits its usefulness) |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`--batch-size 1` doesn't seem to commit for every item 1095570074 | |
| 1008143248 | https://github.com/simonw/sqlite-utils/issues/364#issuecomment-1008143248 | https://api.github.com/repos/simonw/sqlite-utils/issues/364 | IC_kwDOCGYnMM48FwuQ | simonw 9599 | 2022-01-08T20:34:12Z | 2022-01-08T20:34:12Z | OWNER | Built that tool: https://github.com/simonw/stream-delay and https://pypi.org/project/stream-delay/ |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`--batch-size 1` doesn't seem to commit for every item 1095570074 | |
| 1008129841 | https://github.com/simonw/sqlite-utils/issues/364#issuecomment-1008129841 | https://api.github.com/repos/simonw/sqlite-utils/issues/364 | IC_kwDOCGYnMM48Ftcx | simonw 9599 | 2022-01-08T20:04:42Z | 2022-01-08T20:04:42Z | OWNER | It would be easier to test this if I had a utility for streaming out a file one line at a time. A few recipes for this in https://superuser.com/questions/526242/cat-file-to-terminal-at-particular-speed-of-lines-per-second - I'm going to build a quick |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`--batch-size 1` doesn't seem to commit for every item 1095570074 | |
| 1007643254 | https://github.com/simonw/sqlite-utils/issues/365#issuecomment-1007643254 | https://api.github.com/repos/simonw/sqlite-utils/issues/365 | IC_kwDOCGYnMM48D2p2 | simonw 9599 | 2022-01-07T18:37:56Z | 2022-01-07T18:37:56Z | OWNER | Or I could leave off |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
create-index should run analyze after creating index 1096558279 | |
| 1007642831 | https://github.com/simonw/sqlite-utils/issues/365#issuecomment-1007642831 | https://api.github.com/repos/simonw/sqlite-utils/issues/365 | IC_kwDOCGYnMM48D2jP | simonw 9599 | 2022-01-07T18:37:18Z | 2022-01-07T18:37:18Z | OWNER | After implementing #366 I can make it so |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
create-index should run analyze after creating index 1096558279 | |
| 1007641634 | https://github.com/simonw/sqlite-utils/issues/366#issuecomment-1007641634 | https://api.github.com/repos/simonw/sqlite-utils/issues/366 | IC_kwDOCGYnMM48D2Qi | simonw 9599 | 2022-01-07T18:35:35Z | 2022-01-07T18:35:35Z | OWNER | Since the existing CLI feature is this: I can add |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Python library methods for calling ANALYZE 1096563265 | |
| 1007639860 | https://github.com/simonw/sqlite-utils/issues/366#issuecomment-1007639860 | https://api.github.com/repos/simonw/sqlite-utils/issues/366 | IC_kwDOCGYnMM48D100 | simonw 9599 | 2022-01-07T18:32:59Z | 2022-01-07T18:33:07Z | OWNER | From the SQLite docs:
So I think this becomes two methods:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Python library methods for calling ANALYZE 1096563265 | |
| 1007637963 | https://github.com/simonw/sqlite-utils/issues/366#issuecomment-1007637963 | https://api.github.com/repos/simonw/sqlite-utils/issues/366 | IC_kwDOCGYnMM48D1XL | simonw 9599 | 2022-01-07T18:30:13Z | 2022-01-07T18:30:13Z | OWNER | Annoyingly I use the word "analyze" to mean something else in the CLI - for these features:
there's only one method with a similar name in the Python library though and that's this one: |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Python library methods for calling ANALYZE 1096563265 | |
| 1007634999 | https://github.com/simonw/sqlite-utils/issues/365#issuecomment-1007634999 | https://api.github.com/repos/simonw/sqlite-utils/issues/365 | IC_kwDOCGYnMM48D0o3 | simonw 9599 | 2022-01-07T18:26:22Z | 2022-01-07T18:26:22Z | OWNER | I've not used the Annoyingly I use the word "analyze" to mean something else in the CLI - for these features: - #207 - #320 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
create-index should run analyze after creating index 1096558279 | |
| 1007633376 | https://github.com/simonw/sqlite-utils/issues/365#issuecomment-1007633376 | https://api.github.com/repos/simonw/sqlite-utils/issues/365 | IC_kwDOCGYnMM48D0Pg | simonw 9599 | 2022-01-07T18:24:07Z | 2022-01-07T18:24:07Z | OWNER | Relevant documentation: https://www.sqlite.org/lang_analyze.html |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
create-index should run analyze after creating index 1096558279 | |
| 1006344080 | https://github.com/simonw/sqlite-utils/issues/363#issuecomment-1006344080 | https://api.github.com/repos/simonw/sqlite-utils/issues/363 | IC_kwDOCGYnMM47-5eQ | simonw 9599 | 2022-01-06T07:32:05Z | 2022-01-06T07:32:05Z | OWNER | As part of this work I should add test coverage of this error message too: https://github.com/simonw/sqlite-utils/blob/413f8ed754e38d7b190de888c85fe8438336cb11/sqlite_utils/cli.py#L826 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Better error message if `--convert` code fails to return a dict 1094981339 | |
| 1006343303 | https://github.com/simonw/sqlite-utils/issues/363#issuecomment-1006343303 | https://api.github.com/repos/simonw/sqlite-utils/issues/363 | IC_kwDOCGYnMM47-5SH | simonw 9599 | 2022-01-06T07:30:20Z | 2022-01-06T07:30:20Z | OWNER | This check should run inside the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Better error message if `--convert` code fails to return a dict 1094981339 | |
| 1006318443 | https://github.com/simonw/sqlite-utils/issues/356#issuecomment-1006318443 | https://api.github.com/repos/simonw/sqlite-utils/issues/356 | IC_kwDOCGYnMM47-zNr | simonw 9599 | 2022-01-06T06:30:13Z | 2022-01-06T06:30:13Z | OWNER | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`sqlite-utils insert --convert` option 1077431957 | ||
| 1006318007 | https://github.com/simonw/sqlite-utils/issues/356#issuecomment-1006318007 | https://api.github.com/repos/simonw/sqlite-utils/issues/356 | IC_kwDOCGYnMM47-zG3 | simonw 9599 | 2022-01-06T06:28:53Z | 2022-01-06T06:28:53Z | OWNER | Implemented in #361. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`sqlite-utils insert --convert` option 1077431957 | |
| 1006315145 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006315145 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-yaJ | simonw 9599 | 2022-01-06T06:20:51Z | 2022-01-06T06:20:51Z | OWNER | This is all documented. I'm going to rebase-merge it to keep the individual commits. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006311742 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006311742 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-xk- | simonw 9599 | 2022-01-06T06:12:19Z | 2022-01-06T06:12:19Z | OWNER | Got that working:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006309834 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006309834 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-xHK | simonw 9599 | 2022-01-06T06:08:01Z | 2022-01-06T06:08:01Z | OWNER | For |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006301546 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006301546 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-vFq | simonw 9599 | 2022-01-06T05:44:47Z | 2022-01-06T05:44:47Z | OWNER | Just need documentation for |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006300280 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006300280 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-ux4 | simonw 9599 | 2022-01-06T05:40:45Z | 2022-01-06T05:40:45Z | OWNER | I'm going to rename
To avoid that clash with Python's |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006299778 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006299778 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-uqC | simonw 9599 | 2022-01-06T05:39:10Z | 2022-01-06T05:39:10Z | OWNER |
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006295276 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006295276 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-tjs | simonw 9599 | 2022-01-06T05:26:11Z | 2022-01-06T05:26:11Z | OWNER | Here's the traceback if your Traceback (most recent call last): File "/Users/simon/.local/share/virtualenvs/sqlite-utils-C4Ilevlm/bin/sqlite-utils", line 33, in <module> sys.exit(load_entry_point('sqlite-utils', 'console_scripts', 'sqlite-utils')()) File "/Users/simon/.local/share/virtualenvs/sqlite-utils-C4Ilevlm/lib/python3.8/site-packages/click/core.py", line 1137, in call return self.main(args, kwargs) File "/Users/simon/.local/share/virtualenvs/sqlite-utils-C4Ilevlm/lib/python3.8/site-packages/click/core.py", line 1062, in main rv = self.invoke(ctx) File "/Users/simon/.local/share/virtualenvs/sqlite-utils-C4Ilevlm/lib/python3.8/site-packages/click/core.py", line 1668, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/Users/simon/.local/share/virtualenvs/sqlite-utils-C4Ilevlm/lib/python3.8/site-packages/click/core.py", line 1404, in invoke return ctx.invoke(self.callback, ctx.params) File "/Users/simon/.local/share/virtualenvs/sqlite-utils-C4Ilevlm/lib/python3.8/site-packages/click/core.py", line 763, in invoke return __callback(args, **kwargs) File "/Users/simon/Dropbox/Development/sqlite-utils/sqlite_utils/cli.py", line 949, in insert insert_upsert_implementation( File "/Users/simon/Dropbox/Development/sqlite-utils/sqlite_utils/cli.py", line 834, in insert_upsert_implementation db[table].insert_all( File "/Users/simon/Dropbox/Development/sqlite-utils/sqlite_utils/db.py", line 2602, in insert_all first_record = next(records) File "/Users/simon/Dropbox/Development/sqlite-utils/sqlite_utils/db.py", line 3044, in fix_square_braces for record in records: File "/Users/simon/Dropbox/Development/sqlite-utils/sqlite_utils/cli.py", line 831, in <genexpr> docs = (decode_base64_values(doc) for doc in docs) File "/Users/simon/Dropbox/Development/sqlite-utils/sqlite_utils/utils.py", line 86, in decode_base64_values to_fix = [ File "/Users/simon/Dropbox/Development/sqlite-utils/sqlite_utils/utils.py", line 89, in <listcomp> if isinstance(doc[k], dict) TypeError: string indices must be integers ``` I can live with that for the moment. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006294777 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006294777 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-tb5 | simonw 9599 | 2022-01-06T05:24:54Z | 2022-01-06T05:24:54Z | OWNER |
That turned out to be a bad idea because it meant exhausting the iterator early for the check - before we got to the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006288444 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006288444 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-r48 | simonw 9599 | 2022-01-06T05:07:10Z | 2022-01-06T05:07:10Z | OWNER | And here's a demo of
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006284673 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006284673 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-q-B | simonw 9599 | 2022-01-06T04:55:52Z | 2022-01-06T04:55:52Z | OWNER | Test code that just worked for me:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006232013 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006232013 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-eHN | simonw 9599 | 2022-01-06T02:21:35Z | 2022-01-06T02:21:35Z | OWNER | I'm having second thoughts about this bit:
The code in question is this: Do I really want to add the complexity of supporting different variable names there? I think always using Except... |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006230411 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006230411 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-duL | simonw 9599 | 2022-01-06T02:17:35Z | 2022-01-06T02:17:35Z | OWNER | Documentation: https://github.com/simonw/sqlite-utils/blob/33223856ff7fe746b7b77750fbe5b218531d0545/docs/cli.rst#inserting-unstructured-data-with---lines-and---all - I went with a single section titled "Inserting unstructured data with --lines and --all" |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006220129 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006220129 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-bNh | simonw 9599 | 2022-01-06T01:52:26Z | 2022-01-06T01:52:26Z | OWNER | I'm going to refactor all of the tests for |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 1006219848 | https://github.com/simonw/sqlite-utils/pull/361#issuecomment-1006219848 | https://api.github.com/repos/simonw/sqlite-utils/issues/361 | IC_kwDOCGYnMM47-bJI | simonw 9599 | 2022-01-06T01:51:36Z | 2022-01-06T01:51:36Z | OWNER | So far I've just implemented the new help: ``` % sqlite-utils insert --help Usage: sqlite-utils insert [OPTIONS] PATH TABLE FILE Insert records from FILE into a table, creating the table if it does not already exist. By default the input is expected to be a JSON array of objects. Or:
You can also use --convert to pass a fragment of Python code that will be used to convert each input. Your Python code will be passed a "row" variable representing the imported row, and can return a modified row. If you are using --lines your code will be passed a "line" variable, and for --all an "all" variable. Options: --pk TEXT Columns to use as the primary key, e.g. id --flatten Flatten nested JSON objects, so {"a": {"b": 1}} becomes {"a_b": 1} --nl Expect newline-delimited JSON -c, --csv Expect CSV input --tsv Expect TSV input --lines Treat each line as a single value called 'line' --all Treat input as a single value called 'all' --convert TEXT Python code to convert each item --import TEXT Python modules to import --delimiter TEXT Delimiter to use for CSV files --quotechar TEXT Quote character to use for CSV/TSV --sniff Detect delimiter and quote character --no-headers CSV file has no header row --batch-size INTEGER Commit every X records --alter Alter existing table to add any missing columns --not-null TEXT Columns that should be created as NOT NULL --default <TEXT TEXT>... Default value that should be set for a column --encoding TEXT Character encoding for input, defaults to utf-8 -d, --detect-types Detect types for columns in CSV/TSV data --load-extension TEXT SQLite extensions to load --silent Do not show progress bar --ignore Ignore records if pk already exists --replace Replace records if pk already exists --truncate Truncate table before inserting records, if table already exists -h, --help Show this message and exit. ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--lines and --text and --convert and --import 1094890366 | |
| 997496626 | https://github.com/simonw/sqlite-utils/issues/356#issuecomment-997496626 | https://api.github.com/repos/simonw/sqlite-utils/issues/356 | IC_kwDOCGYnMM47dJcy | simonw 9599 | 2021-12-20T00:38:15Z | 2022-01-06T01:29:03Z | OWNER | The implementation of this gets a tiny bit complicated. Ignoring But... when It could run against those already-converted records but that's a little bit strange, since you'd have to do this: Having to use But then for |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`sqlite-utils insert --convert` option 1077431957 | |
| 1006211113 | https://github.com/simonw/sqlite-utils/issues/360#issuecomment-1006211113 | https://api.github.com/repos/simonw/sqlite-utils/issues/360 | IC_kwDOCGYnMM47-ZAp | simonw 9599 | 2022-01-06T01:27:53Z | 2022-01-06T01:27:53Z | OWNER | It looks like you were using The line of code there exhibits another problem: it's reading the entire JSON file into a Python string, so it looks like it's going to run out of RAM even before it gets to the SQLite in-memory database section. To handle a file of this size you'd need to write it to a SQLite database on-disk first. The The code in question is here: That's using Python generators for the CSV/TSV/JSON-NL variants... but it's doing this for regular JSON which requires reading the entire thing into memory: If you have the ability to control how your 170GB file is generated you may have more luck converting it to CSV or TSV or newline-delimited JSON, then using To be honest though I've never tested this tooling with anything nearly that big, so it's possible you'll still run into problems. If you do I'd love to hear about them! I would be tempted to tackle this size of job by writing a custom Python script, either using the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
MemoryError 1091819089 | |
| 1005975080 | https://github.com/simonw/datasette/issues/1534#issuecomment-1005975080 | https://api.github.com/repos/simonw/datasette/issues/1534 | IC_kwDOBm6k_c479fYo | simonw 9599 | 2022-01-05T18:29:06Z | 2022-01-05T18:29:06Z | OWNER | A really big downside to this is that it turns out many CDNs - apparently including Cloudflare - don't support the Vary header at all! More in this thread: https://twitter.com/simonw/status/1478470282931163137 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maybe return JSON from HTML pages if `Accept: application/json` is sent 1065432388 | |
| 1003575286 | https://github.com/simonw/datasette/issues/1585#issuecomment-1003575286 | https://api.github.com/repos/simonw/datasette/issues/1585 | IC_kwDOBm6k_c470Vf2 | simonw 9599 | 2022-01-01T15:40:38Z | 2022-01-01T15:40:38Z | OWNER | API tutorial: https://firebase.google.com/docs/hosting/api-deploy |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Fire base caching for `publish cloudrun` 1091838742 | |
| 1001791592 | https://github.com/simonw/datasette/issues/1152#issuecomment-1001791592 | https://api.github.com/repos/simonw/datasette/issues/1152 | IC_kwDOBm6k_c47tiBo | simonw 9599 | 2021-12-27T23:04:31Z | 2021-12-27T23:04:31Z | OWNER | Another option: rethink permissions to always work in terms of where clauses users as part of a SQL query that returns the overall allowed set of databases or tables. This would require rethinking existing permissions but it might be worthwhile prior to 1.0. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Efficiently calculate list of databases/tables a user can view 770598024 | |
| 1001699559 | https://github.com/simonw/datasette/issues/878#issuecomment-1001699559 | https://api.github.com/repos/simonw/datasette/issues/878 | IC_kwDOBm6k_c47tLjn | simonw 9599 | 2021-12-27T18:53:04Z | 2021-12-27T18:53:04Z | OWNER | I'm going to see if I can come up with the simplest possible version of this pattern for the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
New pattern for views that return either JSON or HTML, available for plugins 648435885 | |
| 1000935523 | https://github.com/simonw/datasette/issues/1576#issuecomment-1000935523 | https://api.github.com/repos/simonw/datasette/issues/1576 | IC_kwDOBm6k_c47qRBj | simonw 9599 | 2021-12-24T21:33:05Z | 2021-12-24T21:33:05Z | OWNER | Another option would be to attempt to import |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Traces should include SQL executed by subtasks created with `asyncio.gather` 1087181951 | |
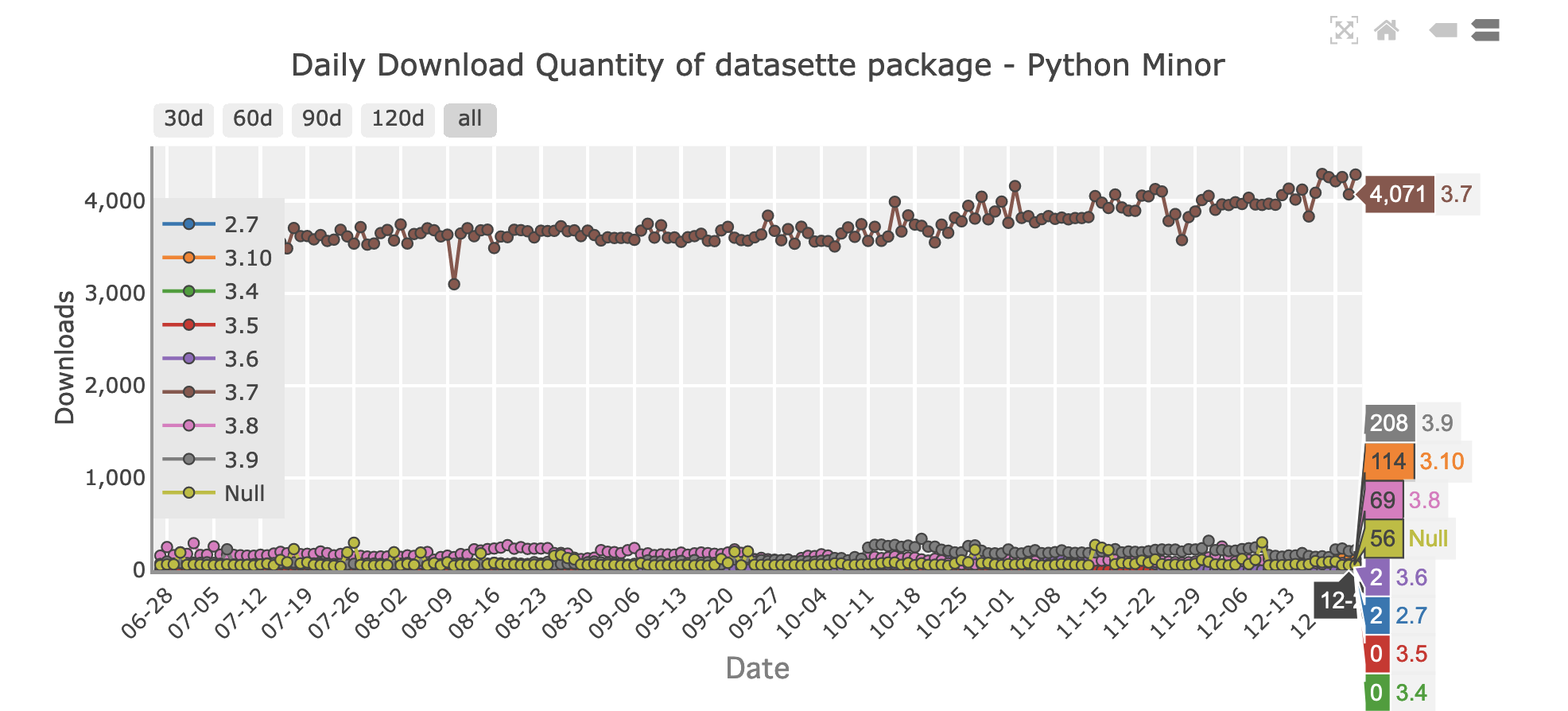
| 1000673444 | https://github.com/simonw/datasette/issues/1577#issuecomment-1000673444 | https://api.github.com/repos/simonw/datasette/issues/1577 | IC_kwDOBm6k_c47pRCk | simonw 9599 | 2021-12-24T06:08:58Z | 2021-12-24T06:08:58Z | OWNER | https://pypistats.org/packages/datasette shows a breakdown of downloads by Python version:
It looks like on a recent day I had 4,071 downloads from Python 3.7... and just 2 downloads from Python 3.6! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Drop support for Python 3.6 1087913724 | |
| 1000535904 | https://github.com/simonw/datasette/issues/1534#issuecomment-1000535904 | https://api.github.com/repos/simonw/datasette/issues/1534 | IC_kwDOBm6k_c47ovdg | simonw 9599 | 2021-12-23T21:44:31Z | 2021-12-23T21:44:31Z | OWNER | A big downside to this is that I would need to use |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maybe return JSON from HTML pages if `Accept: application/json` is sent 1065432388 | |
| 1000485719 | https://github.com/simonw/datasette/issues/1579#issuecomment-1000485719 | https://api.github.com/repos/simonw/datasette/issues/1579 | IC_kwDOBm6k_c47ojNX | simonw 9599 | 2021-12-23T19:19:45Z | 2021-12-23T19:19:45Z | OWNER | All of those removed |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`.execute_write(... block=True)` should be the default behaviour 1087931918 | |
| 1000485505 | https://github.com/simonw/datasette/issues/1579#issuecomment-1000485505 | https://api.github.com/repos/simonw/datasette/issues/1579 | IC_kwDOBm6k_c47ojKB | simonw 9599 | 2021-12-23T19:19:13Z | 2021-12-23T19:19:13Z | OWNER | Updated docs for |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`.execute_write(... block=True)` should be the default behaviour 1087931918 | |
| 1000481686 | https://github.com/simonw/datasette/issues/1579#issuecomment-1000481686 | https://api.github.com/repos/simonw/datasette/issues/1579 | IC_kwDOBm6k_c47oiOW | simonw 9599 | 2021-12-23T19:09:23Z | 2021-12-23T19:09:23Z | OWNER | Re-opening this because I missed updating some of the docs, and I also need to update Datasette's own code to not use |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`.execute_write(... block=True)` should be the default behaviour 1087931918 | |
| 1000479737 | https://github.com/simonw/datasette/issues/1579#issuecomment-1000479737 | https://api.github.com/repos/simonw/datasette/issues/1579 | IC_kwDOBm6k_c47ohv5 | simonw 9599 | 2021-12-23T19:04:23Z | 2021-12-23T19:04:23Z | OWNER | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`.execute_write(... block=True)` should be the default behaviour 1087931918 | ||
| 1000477813 | https://github.com/simonw/datasette/issues/1579#issuecomment-1000477813 | https://api.github.com/repos/simonw/datasette/issues/1579 | IC_kwDOBm6k_c47ohR1 | simonw 9599 | 2021-12-23T18:59:41Z | 2021-12-23T18:59:41Z | OWNER | I'm going to go with |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`.execute_write(... block=True)` should be the default behaviour 1087931918 | |
| 1000477621 | https://github.com/simonw/datasette/issues/1579#issuecomment-1000477621 | https://api.github.com/repos/simonw/datasette/issues/1579 | IC_kwDOBm6k_c47ohO1 | simonw 9599 | 2021-12-23T18:59:12Z | 2021-12-23T18:59:12Z | OWNER | The easiest way to change this would be to default to An alternative would be to add new, separately named methods which do the fire-and-forget thing. If I hadn't recently added |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`.execute_write(... block=True)` should be the default behaviour 1087931918 | |
| 1000476413 | https://github.com/simonw/datasette/issues/1579#issuecomment-1000476413 | https://api.github.com/repos/simonw/datasette/issues/1579 | IC_kwDOBm6k_c47og79 | simonw 9599 | 2021-12-23T18:56:06Z | 2021-12-23T18:56:06Z | OWNER | This is technically a breaking change, but a GitHub code search at https://cs.github.com/?scopeName=All+repos&scope=&q=execute_write%20datasette%20-owner%3Asimonw shows only one repo not-owned-by-me using this, and they're using |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`.execute_write(... block=True)` should be the default behaviour 1087931918 | |
| 1000471782 | https://github.com/simonw/datasette/issues/1578#issuecomment-1000471782 | https://api.github.com/repos/simonw/datasette/issues/1578 | IC_kwDOBm6k_c47ofzm | simonw 9599 | 2021-12-23T18:44:01Z | 2021-12-23T18:44:01Z | OWNER | The example nginx config on https://docs.datasette.io/en/stable/deploying.html#nginx-proxy-configuration is currently: ``` daemon off; events { worker_connections 1024; } http { server { listen 80; location /my-datasette { proxy_pass http://127.0.0.1:8009/my-datasette; proxy_set_header Host $host; } } } ``` This looks to me like it might exhibit the bug. Need to confirm that and figure out an alternative. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Confirm if documented nginx proxy config works for row pages with escaped characters in their primary key 1087919372 | |
| 1000471371 | https://github.com/simonw/datasette/issues/1578#issuecomment-1000471371 | https://api.github.com/repos/simonw/datasette/issues/1578 | IC_kwDOBm6k_c47oftL | simonw 9599 | 2021-12-23T18:42:50Z | 2021-12-23T18:42:50Z | OWNER | Confirmed, that fixed the bug for me on my server. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Confirm if documented nginx proxy config works for row pages with escaped characters in their primary key 1087919372 | |
| 1000470652 | https://github.com/simonw/datasette/issues/1578#issuecomment-1000470652 | https://api.github.com/repos/simonw/datasette/issues/1578 | IC_kwDOBm6k_c47ofh8 | simonw 9599 | 2021-12-23T18:40:46Z | 2021-12-23T18:40:46Z | OWNER | This StackOverflow answer suggests that the fix is to change this: To this: Quoting the nginx documentation: http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_pass
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Confirm if documented nginx proxy config works for row pages with escaped characters in their primary key 1087919372 | |
| 1000469107 | https://github.com/simonw/datasette/issues/1578#issuecomment-1000469107 | https://api.github.com/repos/simonw/datasette/issues/1578 | IC_kwDOBm6k_c47ofJz | simonw 9599 | 2021-12-23T18:36:38Z | 2021-12-23T18:36:38Z | OWNER | This problem doesn't occur on my
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Confirm if documented nginx proxy config works for row pages with escaped characters in their primary key 1087919372 | |
| 1000462309 | https://github.com/simonw/datasette/issues/1577#issuecomment-1000462309 | https://api.github.com/repos/simonw/datasette/issues/1577 | IC_kwDOBm6k_c47odfl | simonw 9599 | 2021-12-23T18:20:46Z | 2021-12-23T18:20:46Z | OWNER | There are a lot of improvements to |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Drop support for Python 3.6 1087913724 | |
| 1000461900 | https://github.com/simonw/datasette/issues/1577#issuecomment-1000461900 | https://api.github.com/repos/simonw/datasette/issues/1577 | IC_kwDOBm6k_c47odZM | simonw 9599 | 2021-12-23T18:19:44Z | 2021-12-23T18:19:44Z | OWNER | The 3.7 feature I want to use today is contextvars - but I have a workaround for the moment, see https://github.com/simonw/datasette/issues/1576#issuecomment-999987418 So I'm going to hold off on dropping 3.6 for a little bit longer. I imagine I'll drop it before Datasette 1.0 though. Leaving this issue open to gather thoughts and feedback on this issue from Datasette users and potential users. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Drop support for Python 3.6 1087913724 | |
| 1000461275 | https://github.com/simonw/datasette/issues/1577#issuecomment-1000461275 | https://api.github.com/repos/simonw/datasette/issues/1577 | IC_kwDOBm6k_c47odPb | simonw 9599 | 2021-12-23T18:18:11Z | 2021-12-23T18:18:11Z | OWNER | From the Twitter thread, there are still a decent amount of LTS Linux releases out there that are stuck on pre-3.7 Python. Though many of those are 3.5 and Datasette dropped support for 3.5 in November 2019: cf7776d36fbacefa874cbd6e5fcdc9fff7661203 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Drop support for Python 3.6 1087913724 | |
| 999990414 | https://github.com/simonw/datasette/issues/1576#issuecomment-999990414 | https://api.github.com/repos/simonw/datasette/issues/1576 | IC_kwDOBm6k_c47mqSO | simonw 9599 | 2021-12-23T02:08:39Z | 2021-12-23T18:16:35Z | OWNER | It's tiny: I'm tempted to vendor it. https://github.com/Skyscanner/aiotask-context/blob/master/aiotask_context/init.py No, I'll add it as a pinned dependency, which I can then drop when I drop 3.6 support. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Traces should include SQL executed by subtasks created with `asyncio.gather` 1087181951 | |
| 999987418 | https://github.com/simonw/datasette/issues/1576#issuecomment-999987418 | https://api.github.com/repos/simonw/datasette/issues/1576 | IC_kwDOBm6k_c47mpja | simonw 9599 | 2021-12-23T01:59:58Z | 2021-12-23T02:02:12Z | OWNER | Another option: https://github.com/Skyscanner/aiotask-context - looks like it might be better as it's been updated for Python 3.7 in this commit https://github.com/Skyscanner/aiotask-context/commit/67108c91d2abb445655cc2af446fdb52ca7890c4 The Skyscanner one doesn't attempt to wrap any existing factories, but that's OK for my purposes since I don't need to handle arbitrary |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Traces should include SQL executed by subtasks created with `asyncio.gather` 1087181951 | |
| 999876666 | https://github.com/simonw/datasette/issues/1576#issuecomment-999876666 | https://api.github.com/repos/simonw/datasette/issues/1576 | IC_kwDOBm6k_c47mOg6 | simonw 9599 | 2021-12-22T20:59:22Z | 2021-12-22T21:18:09Z | OWNER | This article is relevant: Context information storage for asyncio - in particular the section https://blog.sqreen.com/asyncio/#context-inheritance-between-tasks which describes exactly the problem I have and their solution, which involves this trickery: ```python def request_task_factory(loop, coro): child_task = asyncio.tasks.Task(coro, loop=loop) parent_task = asyncio.Task.current_task(loop=loop) current_request = getattr(parent_task, 'current_request', None) setattr(child_task, 'current_request', current_request) return child_task loop = asyncio.get_event_loop() loop.set_task_factory(request_task_factory) ``` They released their solution as a library: https://pypi.org/project/aiocontext/ and https://github.com/sqreen/AioContext - but that company was acquired by Datadog back in April and doesn't seem to be actively maintaining their open source stuff any more: https://twitter.com/SqreenIO/status/1384906075506364417 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Traces should include SQL executed by subtasks created with `asyncio.gather` 1087181951 | |
| 999878907 | https://github.com/simonw/datasette/issues/1576#issuecomment-999878907 | https://api.github.com/repos/simonw/datasette/issues/1576 | IC_kwDOBm6k_c47mPD7 | simonw 9599 | 2021-12-22T21:03:49Z | 2021-12-22T21:10:46Z | OWNER |
Python 3.6 support ends in a few days time, and it looks like Glitch has updated to 3.7 now - so maybe I can get away with Datasette needing 3.7 these days? Tweeted about that here: https://twitter.com/simonw/status/1473761478155010048 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Traces should include SQL executed by subtasks created with `asyncio.gather` 1087181951 | |
| 999874886 | https://github.com/simonw/datasette/issues/1576#issuecomment-999874886 | https://api.github.com/repos/simonw/datasette/issues/1576 | IC_kwDOBm6k_c47mOFG | simonw 9599 | 2021-12-22T20:55:42Z | 2021-12-22T20:57:28Z | OWNER | One way to solve this would be to introduce a It would be really nice if I could solve this using |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Traces should include SQL executed by subtasks created with `asyncio.gather` 1087181951 | |
| 999874484 | https://github.com/simonw/datasette/issues/1576#issuecomment-999874484 | https://api.github.com/repos/simonw/datasette/issues/1576 | IC_kwDOBm6k_c47mN-0 | simonw 9599 | 2021-12-22T20:54:52Z | 2021-12-22T20:54:52Z | OWNER | Here's the full current relevant code from |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Traces should include SQL executed by subtasks created with `asyncio.gather` 1087181951 | |
| 999870993 | https://github.com/simonw/datasette/issues/1518#issuecomment-999870993 | https://api.github.com/repos/simonw/datasette/issues/1518 | IC_kwDOBm6k_c47mNIR | simonw 9599 | 2021-12-22T20:47:18Z | 2021-12-22T20:50:24Z | OWNER | The reason they aren't showing up in the traces is that traces are stored just for the currently executing This is so traces for other incoming requests don't end up mixed together. But there's no current mechanism to track async tasks that are effectively "child tasks" of the current request, and hence should be tracked the same. https://stackoverflow.com/a/69349501/6083 suggests that you pass the task ID as an argument to the child tasks that are executed using |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Complete refactor of TableView and table.html template 1058072543 | |
| 999870282 | https://github.com/simonw/datasette/issues/1518#issuecomment-999870282 | https://api.github.com/repos/simonw/datasette/issues/1518 | IC_kwDOBm6k_c47mM9K | simonw 9599 | 2021-12-22T20:45:56Z | 2021-12-22T20:46:08Z | OWNER |
I wrote code to execute those in parallel using ```diff diff --git a/datasette/views/table.py b/datasette/views/table.py index 9808fd2..ec9db64 100644 --- a/datasette/views/table.py +++ b/datasette/views/table.py @@ -1,3 +1,4 @@ +import asyncio import urllib import itertools import json @@ -615,44 +616,37 @@ class TableView(RowTableShared): if request.args.get("_timelimit"): extra_args["custom_time_limit"] = int(request.args.get("_timelimit"))
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Complete refactor of TableView and table.html template 1058072543 | |
| 999863269 | https://github.com/simonw/datasette/issues/1518#issuecomment-999863269 | https://api.github.com/repos/simonw/datasette/issues/1518 | IC_kwDOBm6k_c47mLPl | simonw 9599 | 2021-12-22T20:35:41Z | 2021-12-22T20:37:13Z | OWNER | It looks like the count has to be executed before facets can be, because the facet_class constructor needs that total count figure: https://github.com/simonw/datasette/blob/6b1384b2f529134998fb507e63307609a5b7f5c0/datasette/views/table.py#L660-L671 It's used in facet suggestion logic here: https://github.com/simonw/datasette/blob/ace86566b28280091b3844cf5fbecd20158e9004/datasette/facets.py#L172-L178 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Complete refactor of TableView and table.html template 1058072543 | |
| 999850191 | https://github.com/simonw/datasette/issues/1518#issuecomment-999850191 | https://api.github.com/repos/simonw/datasette/issues/1518 | IC_kwDOBm6k_c47mIDP | simonw 9599 | 2021-12-22T20:29:38Z | 2021-12-22T20:29:38Z | OWNER | New short-term goal: get facets and suggested facets to execute in parallel with the main query. Generate a trace graph that proves that is happening using |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Complete refactor of TableView and table.html template 1058072543 | |
| 999837569 | https://github.com/simonw/datasette/issues/1518#issuecomment-999837569 | https://api.github.com/repos/simonw/datasette/issues/1518 | IC_kwDOBm6k_c47mE-B | simonw 9599 | 2021-12-22T20:15:45Z | 2021-12-22T20:15:45Z | OWNER | Also the whole |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Complete refactor of TableView and table.html template 1058072543 | |
| 999837220 | https://github.com/simonw/datasette/issues/1518#issuecomment-999837220 | https://api.github.com/repos/simonw/datasette/issues/1518 | IC_kwDOBm6k_c47mE4k | simonw 9599 | 2021-12-22T20:15:04Z | 2021-12-22T20:15:04Z | OWNER | I think I can move this much higher up in the method, it's a bit confusing having it half way through: https://github.com/simonw/datasette/blob/6b1384b2f529134998fb507e63307609a5b7f5c0/datasette/views/table.py#L414-L436 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Complete refactor of TableView and table.html template 1058072543 | |
| 999831967 | https://github.com/simonw/datasette/issues/1518#issuecomment-999831967 | https://api.github.com/repos/simonw/datasette/issues/1518 | IC_kwDOBm6k_c47mDmf | simonw 9599 | 2021-12-22T20:04:47Z | 2021-12-22T20:10:11Z | OWNER | I think I might be able to clean up a lot of the stuff in here using the The catch with that hook - https://docs.datasette.io/en/stable/plugin_hooks.html#render-cell-value-column-table-database-datasette - is that it gets called for every single cell. I don't want the overhead of looking up the foreign key relationships etc once for every value in a specific column. But maybe I could extend the hook to include a shared cache that gets used for all of the cells in a specific table? Something like this:
It's a bit of a gross hack though, and would it ever be useful for plugins outside of the default plugin in Datasette which does the foreign key stuff? If I can think of one other potential application for this No, this optimization doesn't make sense: the most complex cell enrichment logic is the stuff that does a |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Complete refactor of TableView and table.html template 1058072543 | |
| 998354538 | https://github.com/simonw/datasette/pull/1554#issuecomment-998354538 | https://api.github.com/repos/simonw/datasette/issues/1554 | IC_kwDOBm6k_c47ga5q | simonw 9599 | 2021-12-20T23:52:04Z | 2021-12-20T23:52:04Z | OWNER | Abandoning this since it didn't work how I wanted. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
TableView refactor 1079129258 | |
| 997514220 | https://github.com/simonw/datasette/issues/1547#issuecomment-997514220 | https://api.github.com/repos/simonw/datasette/issues/1547 | IC_kwDOBm6k_c47dNvs | simonw 9599 | 2021-12-20T01:26:25Z | 2021-12-20T01:26:25Z | OWNER | OK, this should hopefully fix that for you: |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Writable canned queries fail to load custom templates 1076388044 | |
| 997513369 | https://github.com/simonw/datasette/issues/1547#issuecomment-997513369 | https://api.github.com/repos/simonw/datasette/issues/1547 | IC_kwDOBm6k_c47dNiZ | simonw 9599 | 2021-12-20T01:24:43Z | 2021-12-20T01:24:43Z | OWNER | @wragge thanks, that's a bug! Working on that in #1575. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Writable canned queries fail to load custom templates 1076388044 | |
| 997513177 | https://github.com/simonw/datasette/issues/1575#issuecomment-997513177 | https://api.github.com/repos/simonw/datasette/issues/1575 | IC_kwDOBm6k_c47dNfZ | simonw 9599 | 2021-12-20T01:24:25Z | 2021-12-20T01:24:25Z | OWNER | Looks like |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
__call__() got an unexpected keyword argument 'specname' 1084257842 | |
| 997507074 | https://github.com/simonw/sqlite-utils/issues/356#issuecomment-997507074 | https://api.github.com/repos/simonw/sqlite-utils/issues/356 | IC_kwDOCGYnMM47dMAC | simonw 9599 | 2021-12-20T01:10:06Z | 2021-12-20T01:16:11Z | OWNER | Work-in-progress improved help: ``` Usage: sqlite-utils insert [OPTIONS] PATH TABLE FILE Insert records from FILE into a table, creating the table if it does not already exist. By default the input is expected to be a JSON array of objects. Or:
You can also use --convert to pass a fragment of Python code that will be used to convert each input. Your Python code will be passed a "row" variable representing the imported row, and can return a modified row. If you are using --lines your code will be passed a "line" variable, and for --all an "all" variable. Options: --pk TEXT Columns to use as the primary key, e.g. id --flatten Flatten nested JSON objects, so {"a": {"b": 1}} becomes {"a_b": 1} --nl Expect newline-delimited JSON -c, --csv Expect CSV input --tsv Expect TSV input --lines Treat each line as a single value called 'line' --all Treat input as a single value called 'all' --convert TEXT Python code to convert each item --import TEXT Python modules to import --delimiter TEXT Delimiter to use for CSV files --quotechar TEXT Quote character to use for CSV/TSV --sniff Detect delimiter and quote character --no-headers CSV file has no header row --batch-size INTEGER Commit every X records --alter Alter existing table to add any missing columns --not-null TEXT Columns that should be created as NOT NULL --default <TEXT TEXT>... Default value that should be set for a column --encoding TEXT Character encoding for input, defaults to utf-8 -d, --detect-types Detect types for columns in CSV/TSV data --load-extension TEXT SQLite extensions to load --silent Do not show progress bar --ignore Ignore records if pk already exists --replace Replace records if pk already exists --truncate Truncate table before inserting records, if table already exists -h, --help Show this message and exit. ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
`sqlite-utils insert --convert` option 1077431957 |

Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issue_comments] (
[html_url] TEXT,
[issue_url] TEXT,
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[created_at] TEXT,
[updated_at] TEXT,
[author_association] TEXT,
[body] TEXT,
[reactions] TEXT,
[issue] INTEGER REFERENCES [issues]([id])
, [performed_via_github_app] TEXT);
CREATE INDEX [idx_issue_comments_issue]
ON [issue_comments] ([issue]);
CREATE INDEX [idx_issue_comments_user]
ON [issue_comments] ([user]);
issue >1000