issue_comments
10,495 rows sorted by updated_at descending
This data as json, CSV (advanced)
issue >30
- Port Datasette to ASGI 42
- Authentication (and permissions) as a core concept 40
- Ability to sort (and paginate) by column 31
- link_or_copy_directory() error - Invalid cross-device link 28
- Export to CSV 27
- base_url configuration setting 27
- Documentation with recommendations on running Datasette in production without using Docker 26
- Ability for a canned query to write to the database 26
- Proof of concept for Datasette on AWS Lambda with EFS 25
- Redesign register_output_renderer callback 24
- Datasette Plugins 22
- "flash messages" mechanism 20
- Handle spatialite geometry columns better 19
- Ability to ship alpha and beta releases 18
- Magic parameters for canned queries 18
- Facets 16
- Support "allow" block on root, databases and tables, not just queries 16
- Database page loads too slowly with many large tables (due to table counts) 16
- Bug: Sort by column with NULL in next_page URL 15
- Support cross-database joins 15
- The ".upsert()" method is misnamed 15
- --dirs option for scanning directories for SQLite databases 15
- Document (and reconsider design of) Database.execute() and Database.execute_against_connection_in_thread() 15
- latest.datasette.io is no longer updating 15
- Ability to customize presentation of specific columns in HTML view 14
- Allow plugins to define additional URL routes and views 14
- Mechanism for customizing the SQL used to select specific columns in the table view 14
- .execute_write() and .execute_write_fn() methods on Database 14
- Upload all my photos to a secure S3 bucket 14
- Canned query permissions mechanism 14
- …
| id | html_url | issue_url | node_id | user | created_at | updated_at ▲ | author_association | body | reactions | issue | performed_via_github_app |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 688482355 | https://github.com/simonw/sqlite-utils/issues/149#issuecomment-688482355 | https://api.github.com/repos/simonw/sqlite-utils/issues/149 | MDEyOklzc3VlQ29tbWVudDY4ODQ4MjM1NQ== | simonw 9599 | 2020-09-07T19:22:51Z | 2020-09-07T19:22:51Z | OWNER | And the SQLite documentation says:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
FTS table with 7 rows has _fts_docsize table with 9,141 rows 695319258 | |
| 688482055 | https://github.com/simonw/sqlite-utils/issues/149#issuecomment-688482055 | https://api.github.com/repos/simonw/sqlite-utils/issues/149 | MDEyOklzc3VlQ29tbWVudDY4ODQ4MjA1NQ== | simonw 9599 | 2020-09-07T19:21:42Z | 2020-09-07T19:21:42Z | OWNER | Using
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
FTS table with 7 rows has _fts_docsize table with 9,141 rows 695319258 | |
| 688481374 | https://github.com/simonw/sqlite-utils/issues/149#issuecomment-688481374 | https://api.github.com/repos/simonw/sqlite-utils/issues/149 | MDEyOklzc3VlQ29tbWVudDY4ODQ4MTM3NA== | simonw 9599 | 2020-09-07T19:19:08Z | 2020-09-07T19:19:08Z | OWNER | reading through the code for
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
FTS table with 7 rows has _fts_docsize table with 9,141 rows 695319258 | |
| 688481317 | https://github.com/simonw/sqlite-utils/pull/146#issuecomment-688481317 | https://api.github.com/repos/simonw/sqlite-utils/issues/146 | MDEyOklzc3VlQ29tbWVudDY4ODQ4MTMxNw== | simonwiles 96218 | 2020-09-07T19:18:55Z | 2020-09-07T19:18:55Z | CONTRIBUTOR | Just force-pushed to update d042f9c with more formatting changes to satisfy |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Handle case where subsequent records (after first batch) include extra columns 688668680 | |
| 688480665 | https://github.com/simonw/sqlite-utils/issues/149#issuecomment-688480665 | https://api.github.com/repos/simonw/sqlite-utils/issues/149 | MDEyOklzc3VlQ29tbWVudDY4ODQ4MDY2NQ== | simonw 9599 | 2020-09-07T19:16:20Z | 2020-09-07T19:16:20Z | OWNER | Aha! I have managed to replicate the bug:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
FTS table with 7 rows has _fts_docsize table with 9,141 rows 695319258 | |
| 688479163 | https://github.com/simonw/sqlite-utils/pull/146#issuecomment-688479163 | https://api.github.com/repos/simonw/sqlite-utils/issues/146 | MDEyOklzc3VlQ29tbWVudDY4ODQ3OTE2Mw== | simonwiles 96218 | 2020-09-07T19:10:33Z | 2020-09-07T19:11:57Z | CONTRIBUTOR | @simonw -- I've gone ahead updated the documentation to reflect the changes introduced in this PR. IMO it's ready to merge now. In writing the documentation changes, I begin to wonder about the value and role of Of course the documentation will need to change again too if/when something is done about #147. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Handle case where subsequent records (after first batch) include extra columns 688668680 | |
| 688464181 | https://github.com/simonw/sqlite-utils/issues/149#issuecomment-688464181 | https://api.github.com/repos/simonw/sqlite-utils/issues/149 | MDEyOklzc3VlQ29tbWVudDY4ODQ2NDE4MQ== | simonw 9599 | 2020-09-07T18:19:54Z | 2020-09-07T18:19:54Z | OWNER | Even though that table doesn't declare an integer primary key it does have a | rowid | key | name | spdx_id | url | node_id | | --- | --- | --- | --- | --- | --- | | 9150 | apache-2.0 | Apache License 2.0 | Apache-2.0 | https://api.github.com/licenses/apache-2.0 | MDc6TGljZW5zZTI= | | 112 | bsd-3-clause | BSD 3-Clause "New" or "Revised" License | BSD-3-Clause | https://api.github.com/licenses/bsd-3-clause | MDc6TGljZW5zZTU= | https://www.sqlite.org/rowidtable.html explains has this clue:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
FTS table with 7 rows has _fts_docsize table with 9,141 rows 695319258 | |
| 688460865 | https://github.com/simonw/sqlite-utils/issues/149#issuecomment-688460865 | https://api.github.com/repos/simonw/sqlite-utils/issues/149 | MDEyOklzc3VlQ29tbWVudDY4ODQ2MDg2NQ== | simonw 9599 | 2020-09-07T18:07:14Z | 2020-09-07T18:07:14Z | OWNER | Another likely culprit: |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
FTS table with 7 rows has _fts_docsize table with 9,141 rows 695319258 | |
| 688460729 | https://github.com/simonw/sqlite-utils/issues/149#issuecomment-688460729 | https://api.github.com/repos/simonw/sqlite-utils/issues/149 | MDEyOklzc3VlQ29tbWVudDY4ODQ2MDcyOQ== | simonw 9599 | 2020-09-07T18:06:44Z | 2020-09-07T18:06:44Z | OWNER | First posted on SQLite forum here but I'm pretty sure this is a bug in how |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
FTS table with 7 rows has _fts_docsize table with 9,141 rows 695319258 | |
| 688434226 | https://github.com/simonw/sqlite-utils/issues/148#issuecomment-688434226 | https://api.github.com/repos/simonw/sqlite-utils/issues/148 | MDEyOklzc3VlQ29tbWVudDY4ODQzNDIyNg== | simonw 9599 | 2020-09-07T16:50:33Z | 2020-09-07T16:50:33Z | OWNER | This may be as easy as applying I could apply that to a few other queries in that code as well. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
More attractive indentation of created FTS table schema 695276328 | |
| 687880459 | https://github.com/dogsheep/dogsheep-beta/issues/17#issuecomment-687880459 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/17 | MDEyOklzc3VlQ29tbWVudDY4Nzg4MDQ1OQ== | simonw 9599 | 2020-09-06T19:36:32Z | 2020-09-06T19:36:32Z | MEMBER | At some point I may even want to support search types which are indexed from (and inflated from) more than one database file. I'm going to ignore that for the moment though. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Rename "table" to "type" 694500679 | |
| 686774592 | https://github.com/dogsheep/dogsheep-beta/issues/13#issuecomment-686774592 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/13 | MDEyOklzc3VlQ29tbWVudDY4Njc3NDU5Mg== | simonw 9599 | 2020-09-03T21:30:21Z | 2020-09-03T21:30:21Z | MEMBER | This is partially supported: the custom search SQL we run doesn't escape them, but the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Support advanced FTS queries 692386625 | |
| 686767208 | https://github.com/dogsheep/dogsheep-beta/issues/9#issuecomment-686767208 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/9 | MDEyOklzc3VlQ29tbWVudDY4Njc2NzIwOA== | simonw 9599 | 2020-09-03T21:12:14Z | 2020-09-03T21:12:14Z | MEMBER | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for defining custom display of results 691521965 | ||
| 686689612 | https://github.com/dogsheep/dogsheep-beta/issues/3#issuecomment-686689612 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/3 | MDEyOklzc3VlQ29tbWVudDY4NjY4OTYxMg== | simonw 9599 | 2020-09-03T18:44:20Z | 2020-09-03T18:44:20Z | MEMBER | Facets are now displayed but selecting them doesn't work yet. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Datasette plugin to provide custom page for running faceted, ranked searches 689810340 | |
| 686689366 | https://github.com/dogsheep/dogsheep-beta/issues/5#issuecomment-686689366 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/5 | MDEyOklzc3VlQ29tbWVudDY4NjY4OTM2Ng== | simonw 9599 | 2020-09-03T18:43:50Z | 2020-09-03T18:43:50Z | MEMBER | No longer needed thanks to #9 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Add a context column that's not searchable 689847361 | |
| 686689122 | https://github.com/dogsheep/dogsheep-beta/issues/9#issuecomment-686689122 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/9 | MDEyOklzc3VlQ29tbWVudDY4NjY4OTEyMg== | simonw 9599 | 2020-09-03T18:43:20Z | 2020-09-03T18:43:20Z | MEMBER | Needs documentation. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for defining custom display of results 691521965 | |
| 686688963 | https://github.com/dogsheep/dogsheep-beta/issues/9#issuecomment-686688963 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/9 | MDEyOklzc3VlQ29tbWVudDY4NjY4ODk2Mw== | simonw 9599 | 2020-09-03T18:42:59Z | 2020-09-03T18:42:59Z | MEMBER | I'm pleased with how this works now. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for defining custom display of results 691521965 | |
| 686618669 | https://github.com/dogsheep/dogsheep-beta/issues/11#issuecomment-686618669 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/11 | MDEyOklzc3VlQ29tbWVudDY4NjYxODY2OQ== | simonw 9599 | 2020-09-03T16:47:34Z | 2020-09-03T16:53:25Z | MEMBER | I think a |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Public / Private mechanism 692125110 | |
| 686238498 | https://github.com/dogsheep/dogsheep-beta/issues/10#issuecomment-686238498 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/10 | MDEyOklzc3VlQ29tbWVudDY4NjIzODQ5OA== | simonw 9599 | 2020-09-03T04:05:05Z | 2020-09-03T04:05:05Z | MEMBER | Since the first two categories are |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Category 3: received 691557547 | |
| 686163754 | https://github.com/dogsheep/dogsheep-beta/issues/9#issuecomment-686163754 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/9 | MDEyOklzc3VlQ29tbWVudDY4NjE2Mzc1NA== | simonw 9599 | 2020-09-03T00:46:21Z | 2020-09-03T00:46:21Z | MEMBER | Challenge: the Let's say it can either be duplicated in the
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for defining custom display of results 691521965 | |
| 686158454 | https://github.com/dogsheep/dogsheep-beta/issues/9#issuecomment-686158454 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/9 | MDEyOklzc3VlQ29tbWVudDY4NjE1ODQ1NA== | simonw 9599 | 2020-09-03T00:32:42Z | 2020-09-03T00:32:42Z | MEMBER | If this turns out to be too inefficient I could add a |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for defining custom display of results 691521965 | |
| 686154627 | https://github.com/dogsheep/dogsheep-beta/issues/9#issuecomment-686154627 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/9 | MDEyOklzc3VlQ29tbWVudDY4NjE1NDYyNw== | simonw 9599 | 2020-09-03T00:19:22Z | 2020-09-03T00:19:22Z | MEMBER | If this performs well enough (100 displayed items will be 100 extra |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for defining custom display of results 691521965 | |
| 686154486 | https://github.com/dogsheep/dogsheep-beta/issues/9#issuecomment-686154486 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/9 | MDEyOklzc3VlQ29tbWVudDY4NjE1NDQ4Ng== | simonw 9599 | 2020-09-03T00:18:54Z | 2020-09-03T00:18:54Z | MEMBER |
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for defining custom display of results 691521965 | |
| 686153967 | https://github.com/dogsheep/dogsheep-beta/issues/9#issuecomment-686153967 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/9 | MDEyOklzc3VlQ29tbWVudDY4NjE1Mzk2Nw== | simonw 9599 | 2020-09-03T00:17:16Z | 2020-09-03T00:17:55Z | MEMBER | Maybe I can take advantage of https://sqlite.org/np1queryprob.html here - I could define a SQL query for fetching the "display" version of each item, and include a Jinja template fragment in the configuration as well. Maybe something like this:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for defining custom display of results 691521965 | |
| 686061028 | https://github.com/simonw/datasette/pull/952#issuecomment-686061028 | https://api.github.com/repos/simonw/datasette/issues/952 | MDEyOklzc3VlQ29tbWVudDY4NjA2MTAyOA== | dependabot-preview[bot] 27856297 | 2020-09-02T22:26:14Z | 2020-09-02T22:26:14Z | CONTRIBUTOR | Looks like black is up-to-date now, so this is no longer needed. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Update black requirement from ~=19.10b0 to >=19.10,<21.0 687245650 | |
| 685970384 | https://github.com/dogsheep/dogsheep-beta/issues/7#issuecomment-685970384 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/7 | MDEyOklzc3VlQ29tbWVudDY4NTk3MDM4NA== | simonw 9599 | 2020-09-02T20:11:41Z | 2020-09-02T20:11:59Z | MEMBER | Default categories:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for differentiating between "by me" and "liked by me" 691265198 | |
| 685966707 | https://github.com/dogsheep/dogsheep-beta/issues/7#issuecomment-685966707 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/7 | MDEyOklzc3VlQ29tbWVudDY4NTk2NjcwNw== | simonw 9599 | 2020-09-02T20:04:08Z | 2020-09-02T20:04:08Z | MEMBER | I'll make |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for differentiating between "by me" and "liked by me" 691265198 | |
| 685966361 | https://github.com/dogsheep/dogsheep-beta/issues/7#issuecomment-685966361 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/7 | MDEyOklzc3VlQ29tbWVudDY4NTk2NjM2MQ== | simonw 9599 | 2020-09-02T20:03:29Z | 2020-09-02T20:03:41Z | MEMBER | I'm going to implement the first version of this as an indexed integer I'll think about a full tagging system separately. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for differentiating between "by me" and "liked by me" 691265198 | |
| 685965516 | https://github.com/dogsheep/dogsheep-beta/issues/7#issuecomment-685965516 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/7 | MDEyOklzc3VlQ29tbWVudDY4NTk2NTUxNg== | simonw 9599 | 2020-09-02T20:01:54Z | 2020-09-02T20:01:54Z | MEMBER | Relevant post: https://sqlite.org/forum/forumpost/9f06fedaa5 - drh says:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for differentiating between "by me" and "liked by me" 691265198 | |
| 685962280 | https://github.com/dogsheep/dogsheep-beta/issues/7#issuecomment-685962280 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/7 | MDEyOklzc3VlQ29tbWVudDY4NTk2MjI4MA== | simonw 9599 | 2020-09-02T19:55:26Z | 2020-09-02T19:59:58Z | MEMBER | Relevant: https://charlesleifer.com/blog/a-tour-of-tagging-schemas-many-to-many-bitmaps-and-more/ SQLite supports bitwise operators Binary AND (&) and Binary OR (|) - I could try those. Not sure how they interact with indexes though. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for differentiating between "by me" and "liked by me" 691265198 | |
| 685961809 | https://github.com/dogsheep/dogsheep-beta/issues/3#issuecomment-685961809 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/3 | MDEyOklzc3VlQ29tbWVudDY4NTk2MTgwOQ== | simonw 9599 | 2020-09-02T19:54:24Z | 2020-09-02T19:54:24Z | MEMBER | This should implement search highlighting too, as seen on https://til.simonwillison.net/til/search?q=cloud
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Datasette plugin to provide custom page for running faceted, ranked searches 689810340 | |
| 685960072 | https://github.com/dogsheep/dogsheep-beta/issues/8#issuecomment-685960072 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/8 | MDEyOklzc3VlQ29tbWVudDY4NTk2MDA3Mg== | simonw 9599 | 2020-09-02T19:50:47Z | 2020-09-02T19:50:47Z | MEMBER | This doesn't actually help, because the Datasette table view page doesn't then support adding the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Create a view for running faceted searches 691369691 | |
| 685895540 | https://github.com/dogsheep/dogsheep-beta/issues/7#issuecomment-685895540 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/7 | MDEyOklzc3VlQ29tbWVudDY4NTg5NTU0MA== | simonw 9599 | 2020-09-02T17:46:44Z | 2020-09-02T17:46:44Z | MEMBER | Some opet questions about this:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for differentiating between "by me" and "liked by me" 691265198 | |
| 685121074 | https://github.com/dogsheep/dogsheep-beta/issues/2#issuecomment-685121074 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/2 | MDEyOklzc3VlQ29tbWVudDY4NTEyMTA3NA== | simonw 9599 | 2020-09-01T20:42:00Z | 2020-09-01T20:42:00Z | MEMBER | Documentation at the bottom of the Usage section here: https://github.com/dogsheep/dogsheep-beta/blob/0.2/README.md#usage |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Apply porter stemming 689809225 | |
| 685115519 | https://github.com/dogsheep/dogsheep-beta/issues/2#issuecomment-685115519 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/2 | MDEyOklzc3VlQ29tbWVudDY4NTExNTUxOQ== | simonw 9599 | 2020-09-01T20:31:57Z | 2020-09-01T20:31:57Z | MEMBER | Actually this doesn't work: you can't turn on stemming for specific tables, because all of the content goes into a single So stemming needs to be a global option. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Apply porter stemming 689809225 | |
| 684425714 | https://github.com/dogsheep/pocket-to-sqlite/issues/5#issuecomment-684425714 | https://api.github.com/repos/dogsheep/pocket-to-sqlite/issues/5 | MDEyOklzc3VlQ29tbWVudDY4NDQyNTcxNA== | simonw 9599 | 2020-09-01T06:18:32Z | 2020-09-01T06:18:32Z | MEMBER | Good suggestion, I'll setup a demo somewhere. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Set up a demo 629473827 | |
| 684424396 | https://github.com/dogsheep/pocket-to-sqlite/issues/3#issuecomment-684424396 | https://api.github.com/repos/dogsheep/pocket-to-sqlite/issues/3 | MDEyOklzc3VlQ29tbWVudDY4NDQyNDM5Ng== | simonw 9599 | 2020-09-01T06:17:45Z | 2020-09-01T06:17:45Z | MEMBER | It looks like I could ignore the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Extract images into separate tables 503243784 | |
| 684395444 | https://github.com/dogsheep/dogsheep-beta/issues/4#issuecomment-684395444 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/4 | MDEyOklzc3VlQ29tbWVudDY4NDM5NTQ0NA== | simonw 9599 | 2020-09-01T06:00:03Z | 2020-09-01T06:00:03Z | MEMBER | I ran |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Optimize the FTS table 689839399 | |
| 684250044 | https://github.com/dogsheep/dogsheep-beta/issues/3#issuecomment-684250044 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/3 | MDEyOklzc3VlQ29tbWVudDY4NDI1MDA0NA== | simonw 9599 | 2020-09-01T05:01:09Z | 2020-09-01T05:01:23Z | MEMBER | Maybe this starts out as a custom templated canned query. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Datasette plugin to provide custom page for running faceted, ranked searches 689810340 | |
| 683528149 | https://github.com/simonw/sqlite-utils/issues/147#issuecomment-683528149 | https://api.github.com/repos/simonw/sqlite-utils/issues/147 | MDEyOklzc3VlQ29tbWVudDY4MzUyODE0OQ== | simonw 9599 | 2020-08-31T03:17:26Z | 2020-08-31T03:17:26Z | OWNER | +1 to making this something that users can customize. An optional argument to the I think there's a terrifying way that we could find this value... we could perform a binary search for it! Open up a memory connection and try running different bulk inserts against it and catch the exceptions - then adjust and try again. My hunch is that we could perform just 2 or 3 probes (maybe against carefully selected values) to find the highest value that works. If this process took less than a few ms to run I'd be happy to do it automatically when the class is instantiated (and let users disable that automatic proving by setting a value using the constructor argument). |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
SQLITE_MAX_VARS maybe hard-coded too low 688670158 | |
| 683448569 | https://github.com/simonw/datasette/issues/948#issuecomment-683448569 | https://api.github.com/repos/simonw/datasette/issues/948 | MDEyOklzc3VlQ29tbWVudDY4MzQ0ODU2OQ== | simonw 9599 | 2020-08-30T17:39:09Z | 2020-08-30T18:34:34Z | OWNER | So the steps needed are:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Upgrade CodeMirror 684925907 | |
| 683452613 | https://github.com/simonw/datasette/issues/948#issuecomment-683452613 | https://api.github.com/repos/simonw/datasette/issues/948 | MDEyOklzc3VlQ29tbWVudDY4MzQ1MjYxMw== | simonw 9599 | 2020-08-30T18:16:28Z | 2020-08-30T18:16:28Z | OWNER | I added documentation on how to upgrade CodeMirror for the future here: https://docs.datasette.io/en/latest/contributing.html#upgrading-codemirror |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Upgrade CodeMirror 684925907 | |
| 683449837 | https://github.com/simonw/datasette/issues/655#issuecomment-683449837 | https://api.github.com/repos/simonw/datasette/issues/655 | MDEyOklzc3VlQ29tbWVudDY4MzQ0OTgzNw== | simonw 9599 | 2020-08-30T17:51:38Z | 2020-08-30T17:51:38Z | OWNER | I think was fixed by #948 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Copy and paste doesn't work reliably on iPhone for SQL editor 542553350 | |
| 683449804 | https://github.com/simonw/datasette/issues/948#issuecomment-683449804 | https://api.github.com/repos/simonw/datasette/issues/948 | MDEyOklzc3VlQ29tbWVudDY4MzQ0OTgwNA== | simonw 9599 | 2020-08-30T17:51:18Z | 2020-08-30T17:51:18Z | OWNER | Copy and paste on mobile safari seems to work now. #655 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Upgrade CodeMirror 684925907 | |
| 683448635 | https://github.com/simonw/datasette/issues/948#issuecomment-683448635 | https://api.github.com/repos/simonw/datasette/issues/948 | MDEyOklzc3VlQ29tbWVudDY4MzQ0ODYzNQ== | simonw 9599 | 2020-08-30T17:39:54Z | 2020-08-30T17:39:54Z | OWNER | I'll wait for this to deploy to https://latest.datasette.io/ and then test it in various desktop and mobile browsers. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Upgrade CodeMirror 684925907 | |
| 683445704 | https://github.com/simonw/datasette/issues/948#issuecomment-683445704 | https://api.github.com/repos/simonw/datasette/issues/948 | MDEyOklzc3VlQ29tbWVudDY4MzQ0NTcwNA== | simonw 9599 | 2020-08-30T17:11:58Z | 2020-08-30T17:33:30Z | OWNER | One catch: this stripped the license information from the top of the JS. I fixed this by editing the license to be a single |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Upgrade CodeMirror 684925907 | |
| 683445114 | https://github.com/simonw/datasette/issues/948#issuecomment-683445114 | https://api.github.com/repos/simonw/datasette/issues/948 | MDEyOklzc3VlQ29tbWVudDY4MzQ0NTExNA== | simonw 9599 | 2020-08-30T17:06:39Z | 2020-08-30T17:06:39Z | OWNER | Minifying using |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Upgrade CodeMirror 684925907 | |
| 683382252 | https://github.com/simonw/sqlite-utils/issues/145#issuecomment-683382252 | https://api.github.com/repos/simonw/sqlite-utils/issues/145 | MDEyOklzc3VlQ29tbWVudDY4MzM4MjI1Mg== | simonwiles 96218 | 2020-08-30T06:27:25Z | 2020-08-30T06:27:52Z | CONTRIBUTOR | Note: had to adjust the test above because trying to exhaust a |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Bug when first record contains fewer columns than subsequent records 688659182 | |
| 683357092 | https://github.com/simonw/datasette/issues/957#issuecomment-683357092 | https://api.github.com/repos/simonw/datasette/issues/957 | MDEyOklzc3VlQ29tbWVudDY4MzM1NzA5Mg== | simonw 9599 | 2020-08-30T00:15:51Z | 2020-08-30T00:16:02Z | OWNER | Weirdly even removing this single |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Simplify imports of common classes 688622148 | |
| 683356440 | https://github.com/simonw/datasette/issues/957#issuecomment-683356440 | https://api.github.com/repos/simonw/datasette/issues/957 | MDEyOklzc3VlQ29tbWVudDY4MzM1NjQ0MA== | simonw 9599 | 2020-08-30T00:08:18Z | 2020-08-30T00:10:26Z | OWNER | Annoyingly this seems to be the line that causes the circular import:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Simplify imports of common classes 688622148 | |
| 683355993 | https://github.com/simonw/datasette/issues/957#issuecomment-683355993 | https://api.github.com/repos/simonw/datasette/issues/957 | MDEyOklzc3VlQ29tbWVudDY4MzM1NTk5Mw== | simonw 9599 | 2020-08-30T00:02:11Z | 2020-08-30T00:04:18Z | OWNER | I tried doing this and got this error: ``` (datasette) datasette % pytest ==================================================================== test session starts ===================================================================== platform darwin -- Python 3.8.5, pytest-6.0.1, py-1.9.0, pluggy-0.13.1 rootdir: /Users/simon/Dropbox/Development/datasette, configfile: pytest.ini plugins: asyncio-0.14.0, timeout-1.4.2 collected 1 item / 23 errors =========================================================================== ERRORS ===========================================================================
_________ ERROR collecting tests/test_api.py ________
ImportError while importing test module '/Users/simon/Dropbox/Development/datasette/tests/testapi.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
/usr/local/opt/python@3.8/Frameworks/Python.framework/Versions/3.8/lib/python3.8/importlib/init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
tests/test_api.py:1: in <module>
from datasette.plugins import DEFAULT_PLUGINS
datasette/init.py:2: in <module>
from .app import Datasette
datasette/app.py:30: in <module>
from .views.base import DatasetteError, ureg
datasette/views/base.py:12: in <module>
from datasette.plugins import pm
datasette/plugins.py:26: in <module>
mod = importlib.import_module(plugin)
/usr/local/opt/python@3.8/Frameworks/Python.framework/Versions/3.8/lib/python3.8/importlib/init.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
datasette/publish/heroku.py:2: in <module>
from datasette import hookimpl
E ImportError: cannot import name 'hookimpl' from partially initialized module 'datasette' (most likely due to a circular import) (/Users/simon/Dropbox/Development/datasette/datasette/init.py)
all = [ "actor_matches_allow", "hookimpl", "hookspec", "QueryInterrupted", "Forbidden", "NotFound", "Response", "Datasette", ] ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Simplify imports of common classes 688622148 | |
| 683355598 | https://github.com/simonw/datasette/issues/957#issuecomment-683355598 | https://api.github.com/repos/simonw/datasette/issues/957 | MDEyOklzc3VlQ29tbWVudDY4MzM1NTU5OA== | simonw 9599 | 2020-08-29T23:55:10Z | 2020-08-29T23:55:34Z | OWNER | Of these I think I'm going to promote the following to being importable directly
All of the rest are infrequently used enough (or clearly named enough) that I'm happy to leave them as-is. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Simplify imports of common classes 688622148 | |
| 683355508 | https://github.com/simonw/datasette/issues/957#issuecomment-683355508 | https://api.github.com/repos/simonw/datasette/issues/957 | MDEyOklzc3VlQ29tbWVudDY4MzM1NTUwOA== | simonw 9599 | 2020-08-29T23:54:01Z | 2020-08-29T23:54:01Z | OWNER | Reviewing https://github.com/search?q=user%3Asimonw+%22from+datasette%22&type=Code I spotted these others: ```python Various:from datasette.utils import path_with_replaced_args from datasette.plugins import pm from datasette.utils import QueryInterrupted from datasette.utils.asgi import Response, Forbidden, NotFound datasette-publish-vercel:from datasette.publish.common import ( add_common_publish_arguments_and_options, fail_if_publish_binary_not_installed ) from datasette.utils import temporary_docker_directory datasette-insertfrom datasette.utils import actor_matches_allow, sqlite3 obsolete: russian-ira-facebook-ads-datasettefrom datasette.utils import TableFilter simonw/museumsfrom datasette.utils.asgi import asgi_send datasette-mediafrom datasette.utils.asgi import Response, asgi_send_file datasette/tests/plugins/my_plugin.pyfrom datasette.facets import Facet datasette-graphqlfrom datasette.views.table import TableView ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Simplify imports of common classes 688622148 | |
| 683214102 | https://github.com/simonw/datasette/issues/956#issuecomment-683214102 | https://api.github.com/repos/simonw/datasette/issues/956 | MDEyOklzc3VlQ29tbWVudDY4MzIxNDEwMg== | simonw 9599 | 2020-08-29T01:32:21Z | 2020-08-29T01:32:21Z | OWNER | Maybe the bug here is the double colon? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Push to Docker Hub failed - but it shouldn't run for alpha releases anyway 688427751 | |
| 683213973 | https://github.com/simonw/datasette/issues/956#issuecomment-683213973 | https://api.github.com/repos/simonw/datasette/issues/956 | MDEyOklzc3VlQ29tbWVudDY4MzIxMzk3Mw== | simonw 9599 | 2020-08-29T01:31:39Z | 2020-08-29T01:31:39Z | OWNER | Here's how the old Travis mechanism worked: https://github.com/simonw/datasette/blob/52eabb019d4051084b21524bd0fd9c2731126985/.travis.yml#L41-L47 So I was assuming that the eqivalent of |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Push to Docker Hub failed - but it shouldn't run for alpha releases anyway 688427751 | |
| 683212960 | https://github.com/simonw/datasette/issues/956#issuecomment-683212960 | https://api.github.com/repos/simonw/datasette/issues/956 | MDEyOklzc3VlQ29tbWVudDY4MzIxMjk2MA== | simonw 9599 | 2020-08-29T01:25:34Z | 2020-08-29T01:25:34Z | OWNER | So I guess this bit is wrong: https://github.com/simonw/datasette/blob/c36e287d71d68ecb2a45e9808eede15f19f931fb/.github/workflows/publish.yml#L71-L73 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Push to Docker Hub failed - but it shouldn't run for alpha releases anyway 688427751 | |
| 683212421 | https://github.com/simonw/datasette/issues/956#issuecomment-683212421 | https://api.github.com/repos/simonw/datasette/issues/956 | MDEyOklzc3VlQ29tbWVudDY4MzIxMjQyMQ== | simonw 9599 | 2020-08-29T01:22:23Z | 2020-08-29T01:22:23Z | OWNER | Here's the error message again:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Push to Docker Hub failed - but it shouldn't run for alpha releases anyway 688427751 | |
| 683212246 | https://github.com/simonw/datasette/issues/956#issuecomment-683212246 | https://api.github.com/repos/simonw/datasette/issues/956 | MDEyOklzc3VlQ29tbWVudDY4MzIxMjI0Ng== | simonw 9599 | 2020-08-29T01:21:26Z | 2020-08-29T01:21:26Z | OWNER | I added this but I have no idea if I got it right or not: https://github.com/simonw/datasette/blob/c36e287d71d68ecb2a45e9808eede15f19f931fb/.github/workflows/publish.yml#L58-L63 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Push to Docker Hub failed - but it shouldn't run for alpha releases anyway 688427751 | |
| 683189334 | https://github.com/simonw/datasette/issues/955#issuecomment-683189334 | https://api.github.com/repos/simonw/datasette/issues/955 | MDEyOklzc3VlQ29tbWVudDY4MzE4OTMzNA== | simonw 9599 | 2020-08-28T23:30:48Z | 2020-08-28T23:30:48Z | OWNER | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Release updated datasette-atom and datasette-ics 687711713 | ||
| 683185861 | https://github.com/simonw/datasette/issues/955#issuecomment-683185861 | https://api.github.com/repos/simonw/datasette/issues/955 | MDEyOklzc3VlQ29tbWVudDY4MzE4NTg2MQ== | simonw 9599 | 2020-08-28T23:17:09Z | 2020-08-28T23:17:09Z | OWNER | I released 0.49a0 which means I can update the main branches of those two plugins - I'll push a release of them once 0.49 is fully shipped. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Release updated datasette-atom and datasette-ics 687711713 | |
| 683180581 | https://github.com/simonw/sqlite-utils/issues/144#issuecomment-683180581 | https://api.github.com/repos/simonw/sqlite-utils/issues/144 | MDEyOklzc3VlQ29tbWVudDY4MzE4MDU4MQ== | simonw 9599 | 2020-08-28T22:57:04Z | 2020-08-28T22:57:04Z | OWNER | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Run some tests against numpy 688395275 | ||
| 683179678 | https://github.com/simonw/sqlite-utils/issues/144#issuecomment-683179678 | https://api.github.com/repos/simonw/sqlite-utils/issues/144 | MDEyOklzc3VlQ29tbWVudDY4MzE3OTY3OA== | simonw 9599 | 2020-08-28T22:53:17Z | 2020-08-28T22:53:17Z | OWNER | I'm going to try doing this as a GitHub Actions test matrix. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Run some tests against numpy 688395275 | |
| 683178570 | https://github.com/simonw/sqlite-utils/issues/139#issuecomment-683178570 | https://api.github.com/repos/simonw/sqlite-utils/issues/139 | MDEyOklzc3VlQ29tbWVudDY4MzE3ODU3MA== | simonw 9599 | 2020-08-28T22:48:51Z | 2020-08-28T22:48:51Z | OWNER | Thanks @simonwiles, this is now released in 2.16.1: https://sqlite-utils.readthedocs.io/en/stable/changelog.html |
{
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
insert_all(..., alter=True) should work for new columns introduced after the first 100 records 686978131 | |
| 683175491 | https://github.com/simonw/sqlite-utils/issues/143#issuecomment-683175491 | https://api.github.com/repos/simonw/sqlite-utils/issues/143 | MDEyOklzc3VlQ29tbWVudDY4MzE3NTQ5MQ== | simonw 9599 | 2020-08-28T22:37:15Z | 2020-08-28T22:37:15Z | OWNER | I'm going to start running black exclusively in the GitHub Actions workflow, rather than having it run by the unit tests themselves. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Move to GitHub Actions CI 688389933 | |
| 683173375 | https://github.com/simonw/sqlite-utils/pull/142#issuecomment-683173375 | https://api.github.com/repos/simonw/sqlite-utils/issues/142 | MDEyOklzc3VlQ29tbWVudDY4MzE3MzM3NQ== | simonw 9599 | 2020-08-28T22:29:02Z | 2020-08-28T22:29:02Z | OWNER | Yeah I think that failure is actually because there's a brand new release of Black out and it subtly changes some of the formatting rules. I'll merge this and then run Black against the entire codebase. |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
insert_all(..., alter=True) should work for new columns introduced after the first 100 records 688386219 | |
| 683172829 | https://github.com/simonw/sqlite-utils/pull/142#issuecomment-683172829 | https://api.github.com/repos/simonw/sqlite-utils/issues/142 | MDEyOklzc3VlQ29tbWVudDY4MzE3MjgyOQ== | simonw 9599 | 2020-08-28T22:27:05Z | 2020-08-28T22:27:05Z | OWNER | Looks like it failed the "black" formatting test - possibly because there's a new release if black out. I'm going to merge despite that failure. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
insert_all(..., alter=True) should work for new columns introduced after the first 100 records 688386219 | |
| 683172082 | https://github.com/simonw/sqlite-utils/pull/142#issuecomment-683172082 | https://api.github.com/repos/simonw/sqlite-utils/issues/142 | MDEyOklzc3VlQ29tbWVudDY4MzE3MjA4Mg== | simonw 9599 | 2020-08-28T22:24:25Z | 2020-08-28T22:24:25Z | OWNER | Thanks very much! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
insert_all(..., alter=True) should work for new columns introduced after the first 100 records 688386219 | |
| 683146200 | https://github.com/simonw/sqlite-utils/issues/119#issuecomment-683146200 | https://api.github.com/repos/simonw/sqlite-utils/issues/119 | MDEyOklzc3VlQ29tbWVudDY4MzE0NjIwMA== | simonw 9599 | 2020-08-28T21:05:37Z | 2020-08-28T21:05:37Z | OWNER | Maybe use |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Ability to remove a foreign key 652700770 | |
| 682815377 | https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682815377 | https://api.github.com/repos/simonw/sqlite-utils/issues/139 | MDEyOklzc3VlQ29tbWVudDY4MjgxNTM3Nw== | simonwiles 96218 | 2020-08-28T16:14:58Z | 2020-08-28T16:14:58Z | CONTRIBUTOR | Thanks! And yeah, I had updating the docs on my list too :) Will try to get to it this afternoon (budgeting time is fraught with uncertainty at the moment!). |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
insert_all(..., alter=True) should work for new columns introduced after the first 100 records 686978131 | |
| 682771226 | https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682771226 | https://api.github.com/repos/simonw/sqlite-utils/issues/139 | MDEyOklzc3VlQ29tbWVudDY4Mjc3MTIyNg== | simonw 9599 | 2020-08-28T15:57:42Z | 2020-08-28T15:57:42Z | OWNER | That pull request should update this section of the documentation too:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
insert_all(..., alter=True) should work for new columns introduced after the first 100 records 686978131 | |
| 682762911 | https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682762911 | https://api.github.com/repos/simonw/sqlite-utils/issues/139 | MDEyOklzc3VlQ29tbWVudDY4Mjc2MjkxMQ== | simonw 9599 | 2020-08-28T15:54:57Z | 2020-08-28T15:55:20Z | OWNER | Here's a suggested test update: ```diff diff --git a/sqlite_utils/db.py b/sqlite_utils/db.py index a8791c3..12fa2f2 100644 --- a/sqlite_utils/db.py +++ b/sqlite_utils/db.py @@ -1074,6 +1074,13 @@ class Table(Queryable): all_columns = list(sorted(all_columns)) if hash_id: all_columns.insert(0, hash_id) + else: + all_columns += [ + column + for record in chunk + for column in record + if column not in all_columns + ] validate_column_names(all_columns) first = False # values is the list of insert data that is passed to the diff --git a/tests/test_create.py b/tests/test_create.py index a84eb8d..3a7fafc 100644 --- a/tests/test_create.py +++ b/tests/test_create.py @@ -707,13 +707,15 @@ def test_insert_thousands_using_generator(fresh_db): assert 10000 == fresh_db["test"].count -def test_insert_thousands_ignores_extra_columns_after_first_100(fresh_db): +def test_insert_thousands_adds_extra_columns_after_first_100(fresh_db): + # https://github.com/simonw/sqlite-utils/issues/139 fresh_db["test"].insert_all( [{"i": i, "word": "word_{}".format(i)} for i in range(100)] - + [{"i": 101, "extra": "This extra column should cause an exception"}] + + [{"i": 101, "extra": "Should trigger ALTER"}], + alter=True, ) rows = fresh_db.execute_returning_dicts("select * from test where i = 101") - assert [{"i": 101, "word": None}] == rows + assert [{"i": 101, "word": None, "extra": "Should trigger ALTER"}] == rows def test_insert_ignore(fresh_db): ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
insert_all(..., alter=True) should work for new columns introduced after the first 100 records 686978131 | |
| 682312736 | https://github.com/simonw/datasette/issues/954#issuecomment-682312736 | https://api.github.com/repos/simonw/datasette/issues/954 | MDEyOklzc3VlQ29tbWVudDY4MjMxMjczNg== | simonw 9599 | 2020-08-28T04:05:01Z | 2020-08-28T04:05:10Z | OWNER |
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Remove old register_output_renderer dict mechanism in Datasette 1.0 687694947 | |
| 682312494 | https://github.com/simonw/datasette/issues/953#issuecomment-682312494 | https://api.github.com/repos/simonw/datasette/issues/953 | MDEyOklzc3VlQ29tbWVudDY4MjMxMjQ5NA== | simonw 9599 | 2020-08-28T04:03:56Z | 2020-08-28T04:03:56Z | OWNER | Documentation says that the old dictionary mechanism will be deprecated by 1.0: |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
register_output_renderer render function should be able to return a Response 687681018 | |
| 682285212 | https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682285212 | https://api.github.com/repos/simonw/sqlite-utils/issues/139 | MDEyOklzc3VlQ29tbWVudDY4MjI4NTIxMg== | simonw 9599 | 2020-08-28T02:12:51Z | 2020-08-28T02:12:51Z | OWNER | I'd be happy to accept a PR for this, provided it included updated unit tests that illustrate it working. I think this is a really good improvement. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
insert_all(..., alter=True) should work for new columns introduced after the first 100 records 686978131 | |
| 682284908 | https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682284908 | https://api.github.com/repos/simonw/sqlite-utils/issues/139 | MDEyOklzc3VlQ29tbWVudDY4MjI4NDkwOA== | simonw 9599 | 2020-08-28T02:11:40Z | 2020-08-28T02:11:40Z | OWNER | This is deliberate behaviour, but I'm not at all attached to it - you're right in pointing out that it's actually pretty unexpected. I'd be happy to change this behaviour so if you pass |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
insert_all(..., alter=True) should work for new columns introduced after the first 100 records 686978131 | |
| 682182178 | https://github.com/simonw/sqlite-utils/issues/139#issuecomment-682182178 | https://api.github.com/repos/simonw/sqlite-utils/issues/139 | MDEyOklzc3VlQ29tbWVudDY4MjE4MjE3OA== | simonwiles 96218 | 2020-08-27T20:46:18Z | 2020-08-27T20:46:18Z | CONTRIBUTOR |
So the reason for this is that the With regard to the issue of ignoring columns, however, I made a fork and hacked a temporary fix that looks like this: https://github.com/simonwiles/sqlite-utils/commit/3901f43c6a712a1a3efc340b5b8d8fd0cbe8ee63 It doesn't seem to affect performance enormously (but I've not tested it thoroughly), and it now does what I need (and would expect, tbh), but it now fails the test here: https://github.com/simonw/sqlite-utils/blob/main/tests/test_create.py#L710-L716 The existence of this test suggests that @simonw is this something you'd be willing to look at a PR for? I assume you wouldn't want to change the default behaviour at this point, but perhaps an option could be provided, or at least a bit more of a warning in the docs. Are there oversights in the implementation that I've made? Would be grateful for your thoughts! Thanks! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
insert_all(..., alter=True) should work for new columns introduced after the first 100 records 686978131 | |
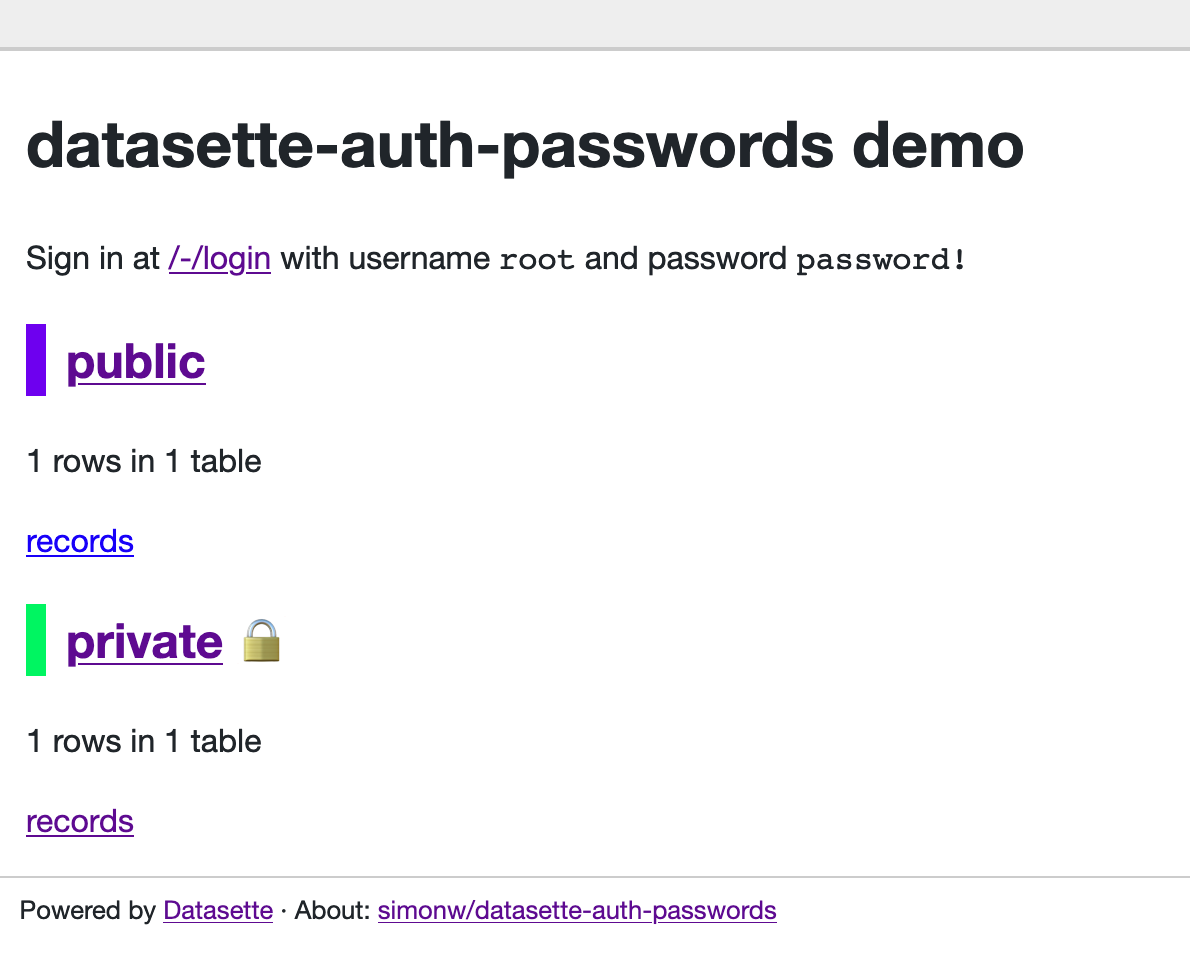
| 680374196 | https://github.com/simonw/datasette/issues/950#issuecomment-680374196 | https://api.github.com/repos/simonw/datasette/issues/950 | MDEyOklzc3VlQ29tbWVudDY4MDM3NDE5Ng== | simonw 9599 | 2020-08-26T00:43:50Z | 2020-08-26T00:43:50Z | OWNER | The problem with the term "private" is that it could be confused with the concept of databases that aren't visible to the public due to the permissions system - the ones that are displayed with the padlock icon e.g. on https://datasette-auth-passwords-demo.datasette.io/
So I think "secret" is a better term for these. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Private/secret databases: database files that are only visible to plugins 685806511 | |
| 680264202 | https://github.com/simonw/datasette/issues/950#issuecomment-680264202 | https://api.github.com/repos/simonw/datasette/issues/950 | MDEyOklzc3VlQ29tbWVudDY4MDI2NDIwMg== | simonw 9599 | 2020-08-25T20:53:13Z | 2020-08-25T20:53:13Z | OWNER | Forcing people to spell out |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Private/secret databases: database files that are only visible to plugins 685806511 | |
| 680263999 | https://github.com/simonw/datasette/issues/950#issuecomment-680263999 | https://api.github.com/repos/simonw/datasette/issues/950 | MDEyOklzc3VlQ29tbWVudDY4MDI2Mzk5OQ== | simonw 9599 | 2020-08-25T20:52:47Z | 2020-08-25T20:52:47Z | OWNER | Naming challenge: secret databases or private databases? I prefer private. But |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Private/secret databases: database files that are only visible to plugins 685806511 | |
| 680263427 | https://github.com/simonw/datasette/issues/950#issuecomment-680263427 | https://api.github.com/repos/simonw/datasette/issues/950 | MDEyOklzc3VlQ29tbWVudDY4MDI2MzQyNw== | simonw 9599 | 2020-08-25T20:51:30Z | 2020-08-25T20:52:13Z | OWNER |
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Private/secret databases: database files that are only visible to plugins 685806511 | |
| 679367931 | https://github.com/simonw/datasette/issues/949#issuecomment-679367931 | https://api.github.com/repos/simonw/datasette/issues/949 | MDEyOklzc3VlQ29tbWVudDY3OTM2NzkzMQ== | simonw 9599 | 2020-08-24T21:09:50Z | 2020-08-24T21:09:50Z | OWNER | I'm attracted to this because of how good GraphiQL is for auto-completing queries. But I realize there's a problem here: GraphQL is designed to be autocomplete-friendly, but SQL is not. If you type |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Try out CodeMirror SQL hints 684961449 | |
| 679363710 | https://github.com/simonw/datasette/issues/949#issuecomment-679363710 | https://api.github.com/repos/simonw/datasette/issues/949 | MDEyOklzc3VlQ29tbWVudDY3OTM2MzcxMA== | simonw 9599 | 2020-08-24T21:00:43Z | 2020-08-24T21:00:43Z | OWNER | I think this requires three extra files from https://github.com/codemirror/CodeMirror/tree/5.57.0/addon/hint
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Try out CodeMirror SQL hints 684961449 | |
| 679355426 | https://github.com/simonw/datasette/issues/948#issuecomment-679355426 | https://api.github.com/repos/simonw/datasette/issues/948 | MDEyOklzc3VlQ29tbWVudDY3OTM1NTQyNg== | simonw 9599 | 2020-08-24T20:43:07Z | 2020-08-24T20:43:07Z | OWNER | It would also be interesting to try out the SQL hint mode, which can autocomplete against tables and columns. This demo shows how to configure that: https://codemirror.net/mode/sql/ |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Upgrade CodeMirror 684925907 | |
| 679333717 | https://github.com/simonw/datasette/issues/948#issuecomment-679333717 | https://api.github.com/repos/simonw/datasette/issues/948 | MDEyOklzc3VlQ29tbWVudDY3OTMzMzcxNw== | simonw 9599 | 2020-08-24T19:55:59Z | 2020-08-24T19:55:59Z | OWNER | CodeMirror 6 is in pre-release at the moment and is a complete rewrite. I'll stick with the 5.x series for now. https://github.com/codemirror/codemirror.next/ |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Upgrade CodeMirror 684925907 | |
| 678732667 | https://github.com/simonw/sqlite-utils/issues/138#issuecomment-678732667 | https://api.github.com/repos/simonw/sqlite-utils/issues/138 | MDEyOklzc3VlQ29tbWVudDY3ODczMjY2Nw== | simonw 9599 | 2020-08-23T05:46:10Z | 2020-08-23T05:46:10Z | OWNER | Actually the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
extracts= doesn't configure foreign keys 684118950 | |
| 678508056 | https://github.com/simonw/sqlite-utils/issues/136#issuecomment-678508056 | https://api.github.com/repos/simonw/sqlite-utils/issues/136 | MDEyOklzc3VlQ29tbWVudDY3ODUwODA1Ng== | simonw 9599 | 2020-08-21T21:13:41Z | 2020-08-21T21:13:41Z | OWNER | The |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--load-extension=spatialite shortcut option 683812642 | |
| 678507502 | https://github.com/simonw/sqlite-utils/issues/137#issuecomment-678507502 | https://api.github.com/repos/simonw/sqlite-utils/issues/137 | MDEyOklzc3VlQ29tbWVudDY3ODUwNzUwMg== | simonw 9599 | 2020-08-21T21:13:19Z | 2020-08-21T21:13:19Z | OWNER | Adding |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--load-extension for other sqlite-utils commands 683830416 | |
| 678497497 | https://github.com/simonw/sqlite-utils/issues/134#issuecomment-678497497 | https://api.github.com/repos/simonw/sqlite-utils/issues/134 | MDEyOklzc3VlQ29tbWVudDY3ODQ5NzQ5Nw== | simonw 9599 | 2020-08-21T21:06:26Z | 2020-08-21T21:06:26Z | OWNER | Ended up needing two skipIfs: |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--load-extension option for sqlite-utils query 683804172 | |
| 678480969 | https://github.com/simonw/sqlite-utils/issues/136#issuecomment-678480969 | https://api.github.com/repos/simonw/sqlite-utils/issues/136 | MDEyOklzc3VlQ29tbWVudDY3ODQ4MDk2OQ== | simonw 9599 | 2020-08-21T20:33:45Z | 2020-08-21T20:33:45Z | OWNER | I think this should initialize SpatiaLite against the current database if it has not been initialized already. Relevant code: https://github.com/simonw/shapefile-to-sqlite/blob/e754d0747ca2facf9a7433e2d5d15a6a37a9cf6e/shapefile_to_sqlite/utils.py#L112-L126 ```python def init_spatialite(db, lib): db.conn.enable_load_extension(True) db.conn.load_extension(lib) # Initialize SpatiaLite if not yet initialized if "spatial_ref_sys" in db.table_names(): return db.conn.execute("select InitSpatialMetadata(1)") def ensure_table_has_geometry(db, table, table_srid):
if "geometry" not in db[table].columns_dict:
db.conn.execute(
"SELECT AddGeometryColumn(?, 'geometry', ?, 'GEOMETRY', 2);",
[table, table_srid],
)
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--load-extension=spatialite shortcut option 683812642 | |
| 678479741 | https://github.com/simonw/sqlite-utils/issues/135#issuecomment-678479741 | https://api.github.com/repos/simonw/sqlite-utils/issues/135 | MDEyOklzc3VlQ29tbWVudDY3ODQ3OTc0MQ== | simonw 9599 | 2020-08-21T20:30:37Z | 2020-08-21T20:30:37Z | OWNER | {
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Code for finding SpatiaLite in the usual locations 683805434 | ||
| 678476842 | https://github.com/simonw/sqlite-utils/issues/135#issuecomment-678476842 | https://api.github.com/repos/simonw/sqlite-utils/issues/135 | MDEyOklzc3VlQ29tbWVudDY3ODQ3Njg0Mg== | simonw 9599 | 2020-08-21T20:23:13Z | 2020-08-21T20:23:13Z | OWNER | I'm going to start with just the first two - I'm not convinced I understand the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Code for finding SpatiaLite in the usual locations 683805434 | |
| 678476338 | https://github.com/simonw/sqlite-utils/issues/134#issuecomment-678476338 | https://api.github.com/repos/simonw/sqlite-utils/issues/134 | MDEyOklzc3VlQ29tbWVudDY3ODQ3NjMzOA== | simonw 9599 | 2020-08-21T20:22:02Z | 2020-08-21T20:22:02Z | OWNER | I think that adds it as |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--load-extension option for sqlite-utils query 683804172 | |
| 678475578 | https://github.com/simonw/sqlite-utils/issues/135#issuecomment-678475578 | https://api.github.com/repos/simonw/sqlite-utils/issues/135 | MDEyOklzc3VlQ29tbWVudDY3ODQ3NTU3OA== | simonw 9599 | 2020-08-21T20:20:05Z | 2020-08-21T20:20:05Z | OWNER | https://github.com/simonw/cryptozoology/blob/2ad69168f3b78ebd90a2cbeea8136c9115e2a9b7/build_cryptids_database.py#L16-L22
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Code for finding SpatiaLite in the usual locations 683805434 | |
| 678474928 | https://github.com/simonw/sqlite-utils/issues/134#issuecomment-678474928 | https://api.github.com/repos/simonw/sqlite-utils/issues/134 | MDEyOklzc3VlQ29tbWVudDY3ODQ3NDkyOA== | simonw 9599 | 2020-08-21T20:18:33Z | 2020-08-21T20:18:33Z | OWNER | This should get me SpatiaLite in the GitHub Actions Ubuntu:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--load-extension option for sqlite-utils query 683804172 | |
| 678474018 | https://github.com/simonw/sqlite-utils/issues/134#issuecomment-678474018 | https://api.github.com/repos/simonw/sqlite-utils/issues/134 | MDEyOklzc3VlQ29tbWVudDY3ODQ3NDAxOA== | simonw 9599 | 2020-08-21T20:16:20Z | 2020-08-21T20:16:20Z | OWNER | Trickiest part of this is how to write a test for it. I'll do a |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--load-extension option for sqlite-utils query 683804172 | |
| 676556377 | https://github.com/simonw/datasette/issues/945#issuecomment-676556377 | https://api.github.com/repos/simonw/datasette/issues/945 | MDEyOklzc3VlQ29tbWVudDY3NjU1NjM3Nw== | simonw 9599 | 2020-08-19T17:21:16Z | 2020-08-19T17:21:16Z | OWNER | Documented here: https://docs.datasette.io/en/latest/plugins.html#installing-plugins |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
datasette install -U for upgrading packages 682005535 | |
| 675889865 | https://github.com/simonw/datasette/issues/943#issuecomment-675889865 | https://api.github.com/repos/simonw/datasette/issues/943 | MDEyOklzc3VlQ29tbWVudDY3NTg4OTg2NQ== | simonw 9599 | 2020-08-19T06:57:00Z | 2020-08-19T06:57:00Z | OWNER | Maybe |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
await datasette.client.get(path) mechanism for executing internal requests 681375466 | |
| 675889551 | https://github.com/simonw/datasette/issues/943#issuecomment-675889551 | https://api.github.com/repos/simonw/datasette/issues/943 | MDEyOklzc3VlQ29tbWVudDY3NTg4OTU1MQ== | simonw 9599 | 2020-08-19T06:56:06Z | 2020-08-19T06:56:17Z | OWNER | I'm leaning towards defaulting to JSON as the requested format - you can pass But weird that it's different from the web UI. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
await datasette.client.get(path) mechanism for executing internal requests 681375466 | |
| 675884980 | https://github.com/simonw/datasette/issues/943#issuecomment-675884980 | https://api.github.com/repos/simonw/datasette/issues/943 | MDEyOklzc3VlQ29tbWVudDY3NTg4NDk4MA== | simonw 9599 | 2020-08-19T06:44:26Z | 2020-08-19T06:44:26Z | OWNER | Need to decide what to do about JSON responses. When called from a template it's likely the intent will be to further loop through the JSON data returned. It would be annoying to have to run Maybe a |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
await datasette.client.get(path) mechanism for executing internal requests 681375466 | |
| 675830678 | https://github.com/simonw/datasette/issues/944#issuecomment-675830678 | https://api.github.com/repos/simonw/datasette/issues/944 | MDEyOklzc3VlQ29tbWVudDY3NTgzMDY3OA== | simonw 9599 | 2020-08-19T03:30:10Z | 2020-08-19T03:30:10Z | OWNER | These templates will need a way to raise a 404 - so that if the template itself is deciding if the page exists (for example using This can imitate the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Path parameters for custom pages 681516976 |

Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issue_comments] (
[html_url] TEXT,
[issue_url] TEXT,
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[created_at] TEXT,
[updated_at] TEXT,
[author_association] TEXT,
[body] TEXT,
[reactions] TEXT,
[issue] INTEGER REFERENCES [issues]([id])
, [performed_via_github_app] TEXT);
CREATE INDEX [idx_issue_comments_issue]
ON [issue_comments] ([issue]);
CREATE INDEX [idx_issue_comments_user]
ON [issue_comments] ([user]);
user >30