issue_comments
10,495 rows sorted by updated_at descending
This data as json, CSV (advanced)
issue >30
- Port Datasette to ASGI 42
- Authentication (and permissions) as a core concept 40
- await datasette.client.get(path) mechanism for executing internal requests 33
- Ability to sort (and paginate) by column 31
- link_or_copy_directory() error - Invalid cross-device link 28
- Export to CSV 27
- base_url configuration setting 27
- Documentation with recommendations on running Datasette in production without using Docker 27
- Ability for a canned query to write to the database 26
- table.transform() method for advanced alter table 26
- Proof of concept for Datasette on AWS Lambda with EFS 25
- Redesign register_output_renderer callback 24
- Datasette Plugins 22
- table.extract(...) method and "sqlite-utils extract" command 21
- Redesign default .json format 21
- Handle spatialite geometry columns better 20
- "flash messages" mechanism 20
- Move CI to GitHub Issues 20
- load_template hook doesn't work for include/extends 20
- ?sort=colname~numeric to sort by by column cast to real 19
- Better way of representing binary data in .csv output 19
- Introspect if table is FTS4 or FTS5 19
- Ability to ship alpha and beta releases 18
- Magic parameters for canned queries 18
- datasette.client internal requests mechanism 18
- Facets 16
- Support "allow" block on root, databases and tables, not just queries 16
- Database page loads too slowly with many large tables (due to table counts) 16
- Action menu for table columns 16
- Maintain an in-memory SQLite table of connected databases and their tables 16
- …
| id | html_url | issue_url | node_id | user | created_at | updated_at ▲ | author_association | body | reactions | issue | performed_via_github_app |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 747834462 | https://github.com/simonw/datasette/issues/1150#issuecomment-747834462 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0NzgzNDQ2Mg== | simonw 9599 | 2020-12-18T02:52:19Z | 2020-12-18T02:52:26Z | OWNER | Maintaining this database will be the responsibility of a subclass of |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747834113 | https://github.com/simonw/datasette/issues/1150#issuecomment-747834113 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0NzgzNDExMw== | simonw 9599 | 2020-12-18T02:51:13Z | 2020-12-18T02:51:20Z | OWNER | SQLite uses |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747809670 | https://github.com/simonw/datasette/issues/1150#issuecomment-747809670 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0NzgwOTY3MA== | simonw 9599 | 2020-12-18T01:29:30Z | 2020-12-18T01:29:30Z | OWNER | I've been rediscovering the pattern I already documented in this TIL: https://github.com/simonw/til/blob/main/sqlite/list-all-columns-in-a-database.md#better-alternative-using-a-join |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747807891 | https://github.com/simonw/datasette/issues/1150#issuecomment-747807891 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0NzgwNzg5MQ== | simonw 9599 | 2020-12-18T01:23:59Z | 2020-12-18T01:23:59Z | OWNER | https://www.sqlite.org/pragma.html#pragfunc says:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747807289 | https://github.com/simonw/datasette/issues/1150#issuecomment-747807289 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0NzgwNzI4OQ== | simonw 9599 | 2020-12-18T01:22:05Z | 2020-12-18T01:22:05Z | OWNER | Here's a simpler query pattern (not using CTEs so should work on older versions of SQLite) - this one lists all indexes for all tables:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747805275 | https://github.com/simonw/datasette/issues/1150#issuecomment-747805275 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0NzgwNTI3NQ== | simonw 9599 | 2020-12-18T01:15:27Z | 2020-12-18T01:16:17Z | OWNER | This query uses a join to pull foreign key information for every table: https://latest.datasette.io/fixtures?sql=with+tables+as+%28%0D%0A++select%0D%0A++++name%0D%0A++from%0D%0A++++sqlite_master%0D%0A++where%0D%0A++++type+%3D+%27table%27%0D%0A%29%0D%0Aselect%0D%0A++tables.name+as+%27table%27%2C%0D%0A++foo.*%0D%0Afrom%0D%0A++tables%0D%0A++join+pragma_foreign_key_list%28tables.name%29+foo
Same query for |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747804254 | https://github.com/simonw/datasette/issues/1150#issuecomment-747804254 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0NzgwNDI1NA== | simonw 9599 | 2020-12-18T01:12:13Z | 2020-12-18T01:12:13Z | OWNER | Prototype: https://latest.datasette.io/fixtures?sql=select+%27facetable%27+as+%27table%27%2C++from+pragma_table_xinfo%28%27facetable%27%29%0D%0Aunion%0D%0Aselect+%27searchable%27+as+%27table%27%2C++from+pragma_table_xinfo%28%27searchable%27%29%0D%0Aunion%0D%0Aselect+%27compound_three_primary_keys%27+as+%27table%27%2C+*+from+pragma_table_xinfo%28%27compound_three_primary_keys%27%29
table | cid | name | type | notnull | dflt_value | pk | hidden -- | -- | -- | -- | -- | -- | -- | -- compound_three_primary_keys | 0 | pk1 | varchar(30) | 0 | | 1 | 0 compound_three_primary_keys | 1 | pk2 | varchar(30) | 0 | | 2 | 0 compound_three_primary_keys | 2 | pk3 | varchar(30) | 0 | | 3 | 0 compound_three_primary_keys | 3 | content | text | 0 | | 0 | 0 facetable | 0 | pk | integer | 0 | | 1 | 0 facetable | 1 | created | text | 0 | | 0 | 0 facetable | 2 | planet_int | integer | 0 | | 0 | 0 facetable | 3 | on_earth | integer | 0 | | 0 | 0 facetable | 4 | state | text | 0 | | 0 | 0 facetable | 5 | city_id | integer | 0 | | 0 | 0 facetable | 6 | neighborhood | text | 0 | | 0 | 0 facetable | 7 | tags | text | 0 | | 0 | 0 facetable | 8 | complex_array | text | 0 | | 0 | 0 facetable | 9 | distinct_some_null | | 0 | | 0 | 0 searchable | 0 | pk | integer | 0 | | 1 | 0 searchable | 1 | text1 | text | 0 | | 0 | 0 searchable | 2 | text2 | text | 0 | | 0 | 0 searchable | 3 | name with . and spaces | text | 0 | | 0 | 0 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747803268 | https://github.com/simonw/datasette/issues/1150#issuecomment-747803268 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0NzgwMzI2OA== | simonw 9599 | 2020-12-18T01:08:40Z | 2020-12-18T01:08:40Z | OWNER | Next step: design a schema for the in-memory database table that exposes all of the tables. I want to support things like:
Maybe a starting point would be to build concrete tables using the results of things like |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747801751 | https://github.com/simonw/datasette/issues/1151#issuecomment-747801751 | https://api.github.com/repos/simonw/datasette/issues/1151 | MDEyOklzc3VlQ29tbWVudDc0NzgwMTc1MQ== | simonw 9599 | 2020-12-18T01:03:39Z | 2020-12-18T01:03:39Z | OWNER | This feature is illustrated by the tests: https://github.com/simonw/datasette/blob/5e9895c67f08e9f42acedd3d6d29512ac446e15f/tests/test_internals_database.py#L469-L496 I added new documentation for the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Database class mechanism for cross-connection in-memory databases 770448622 | |
| 747801084 | https://github.com/simonw/datasette/issues/1151#issuecomment-747801084 | https://api.github.com/repos/simonw/datasette/issues/1151 | MDEyOklzc3VlQ29tbWVudDc0NzgwMTA4NA== | simonw 9599 | 2020-12-18T01:01:26Z | 2020-12-18T01:01:26Z | OWNER | I tested this with a one-off plugin and it worked! ```python from datasette import hookimpl from datasette.database import Database @hookimpl
def startup(datasette):
datasette.add_database("statistics", Database(
datasette,
memory_name="statistics"
))
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Database class mechanism for cross-connection in-memory databases 770448622 | |
| 747784199 | https://github.com/simonw/datasette/issues/1151#issuecomment-747784199 | https://api.github.com/repos/simonw/datasette/issues/1151 | MDEyOklzc3VlQ29tbWVudDc0Nzc4NDE5OQ== | simonw 9599 | 2020-12-18T00:09:36Z | 2020-12-18T00:09:36Z | OWNER | Is it possible to connect to a memory database in read-only mode?
https://stackoverflow.com/a/40548682 suggests using |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Database class mechanism for cross-connection in-memory databases 770448622 | |
| 747775245 | https://github.com/simonw/datasette/issues/1151#issuecomment-747775245 | https://api.github.com/repos/simonw/datasette/issues/1151 | MDEyOklzc3VlQ29tbWVudDc0Nzc3NTI0NQ== | simonw 9599 | 2020-12-17T23:43:41Z | 2020-12-17T23:56:27Z | OWNER | I'm going to add an argument to the
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Database class mechanism for cross-connection in-memory databases 770448622 | |
| 747779056 | https://github.com/simonw/datasette/issues/1151#issuecomment-747779056 | https://api.github.com/repos/simonw/datasette/issues/1151 | MDEyOklzc3VlQ29tbWVudDc0Nzc3OTA1Ng== | simonw 9599 | 2020-12-17T23:55:57Z | 2020-12-17T23:55:57Z | OWNER | Wait I do use it - if you run |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Database class mechanism for cross-connection in-memory databases 770448622 | |
| 747775792 | https://github.com/simonw/datasette/issues/1151#issuecomment-747775792 | https://api.github.com/repos/simonw/datasette/issues/1151 | MDEyOklzc3VlQ29tbWVudDc0Nzc3NTc5Mg== | simonw 9599 | 2020-12-17T23:45:20Z | 2020-12-17T23:45:20Z | OWNER | Do I use the current https://ripgrep.datasette.io/-/ripgrep?pattern=is_memory - doesn't look like it. I may remove that feature, since it's not actually useful, and replace it with a mechanism for creating shared named memory databases instead. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Database class mechanism for cross-connection in-memory databases 770448622 | |
| 747774855 | https://github.com/simonw/datasette/issues/1151#issuecomment-747774855 | https://api.github.com/repos/simonw/datasette/issues/1151 | MDEyOklzc3VlQ29tbWVudDc0Nzc3NDg1NQ== | simonw 9599 | 2020-12-17T23:42:34Z | 2020-12-17T23:42:34Z | OWNER | This worked as a prototype: ```diff diff --git a/datasette/database.py b/datasette/database.py index 412e0c5..a90e617 100644 --- a/datasette/database.py +++ b/datasette/database.py @@ -24,11 +24,12 @@ connections = threading.local() class Database: - def init(self, ds, path=None, is_mutable=False, is_memory=False): + def init(self, ds, path=None, is_mutable=False, is_memory=False, uri=None): self.ds = ds self.path = path self.is_mutable = is_mutable self.is_memory = is_memory + self.uri = uri self.hash = None self.cached_size = None self.cached_table_counts = None @@ -46,6 +47,8 @@ class Database: }
Outputs ["foo"]db2 = Database(ds, uri="file:datasette?mode=memory&cache=shared", is_memory=True) await db2.table_names() Also outputs ["foo"]``` ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Database class mechanism for cross-connection in-memory databases 770448622 | |
| 747770581 | https://github.com/simonw/datasette/issues/1151#issuecomment-747770581 | https://api.github.com/repos/simonw/datasette/issues/1151 | MDEyOklzc3VlQ29tbWVudDc0Nzc3MDU4MQ== | simonw 9599 | 2020-12-17T23:31:18Z | 2020-12-17T23:32:07Z | OWNER | This works in In [2]: c1 = sqlite3.connect("file:datasette?mode=memory&cache=shared", uri=True) In [3]: c2 = sqlite3.connect("file:datasette?mode=memory&cache=shared", uri=True) In [4]: c1.executescript("CREATE TABLE hello (world TEXT)") Out[4]: <sqlite3.Cursor at 0x1104addc0> In [5]: c1.execute("select * from sqlite_master").fetchall() Out[5]: [('table', 'hello', 'hello', 2, 'CREATE TABLE hello (world TEXT)')] In [6]: c2.execute("select * from sqlite_master").fetchall() Out[6]: [('table', 'hello', 'hello', 2, 'CREATE TABLE hello (world TEXT)')] In [7]: c3 = sqlite3.connect("file:datasette?mode=memory&cache=shared", uri=True) In [9]: c3.execute("select * from sqlite_master").fetchall() Out[9]: [('table', 'hello', 'hello', 2, 'CREATE TABLE hello (world TEXT)')] In [10]: c4 = sqlite3.connect("file:datasette?mode=memory", uri=True) In [11]: c4.execute("select * from sqlite_master").fetchall() Out[11]: [] ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Database class mechanism for cross-connection in-memory databases 770448622 | |
| 747770082 | https://github.com/simonw/datasette/issues/1151#issuecomment-747770082 | https://api.github.com/repos/simonw/datasette/issues/1151 | MDEyOklzc3VlQ29tbWVudDc0Nzc3MDA4Mg== | simonw 9599 | 2020-12-17T23:29:53Z | 2020-12-17T23:29:53Z | OWNER | I'm going to try with |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Database class mechanism for cross-connection in-memory databases 770448622 | |
| 747769830 | https://github.com/simonw/datasette/issues/1151#issuecomment-747769830 | https://api.github.com/repos/simonw/datasette/issues/1151 | MDEyOklzc3VlQ29tbWVudDc0Nzc2OTgzMA== | simonw 9599 | 2020-12-17T23:29:08Z | 2020-12-17T23:29:08Z | OWNER | https://sqlite.org/inmemorydb.html
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Database class mechanism for cross-connection in-memory databases 770448622 | |
| 747768112 | https://github.com/simonw/datasette/issues/1150#issuecomment-747768112 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0Nzc2ODExMg== | simonw 9599 | 2020-12-17T23:25:21Z | 2020-12-17T23:25:21Z | OWNER | Next challenge: figure out how to use the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747767598 | https://github.com/simonw/datasette/issues/1150#issuecomment-747767598 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0Nzc2NzU5OA== | simonw 9599 | 2020-12-17T23:24:03Z | 2020-12-17T23:24:03Z | OWNER | I'm going to assume that even the heaviest user will have trouble going beyond a few hundred database files, so this is fine. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747767499 | https://github.com/simonw/datasette/issues/1150#issuecomment-747767499 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0Nzc2NzQ5OQ== | simonw 9599 | 2020-12-17T23:23:44Z | 2020-12-17T23:23:44Z | OWNER | Grabbing the schema version of 380 files in the root directory takes 70ms. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747767055 | https://github.com/simonw/datasette/issues/1150#issuecomment-747767055 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0Nzc2NzA1NQ== | simonw 9599 | 2020-12-17T23:22:41Z | 2020-12-17T23:22:41Z | OWNER | It's just recursion that's expensive. I created 380 empty SQLite databases in a folder and timed So maybe I tell users that all SQLite databases have to be in the root folder. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747766310 | https://github.com/simonw/datasette/issues/1150#issuecomment-747766310 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0Nzc2NjMxMA== | simonw 9599 | 2020-12-17T23:20:49Z | 2020-12-17T23:20:49Z | OWNER | I tried against my entire So it looks like connecting to a SQLite database file and getting the schema version is extremely fast. Scanning directories is slower. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747764712 | https://github.com/simonw/datasette/issues/1150#issuecomment-747764712 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0Nzc2NDcxMg== | simonw 9599 | 2020-12-17T23:16:31Z | 2020-12-17T23:16:31Z | OWNER | Quick micro-benchmark, run against a folder with 46 database files adding up to 1.4GB total: ```python import pathlib, sqlite3, time paths = list(pathlib.Path(".").glob('*.db')) def schema_version(path): db = sqlite3.connect(path) version = db.execute("PRAGMA schema_version").fetchall()[0] db.close() return version def all(): versions = {} for path in paths: versions[path.name] = schema_version(path) return versions start = time.time(); all(); print(time.time() - start) 0.012346982955932617``` So that's 12ms. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747754229 | https://github.com/simonw/datasette/issues/1150#issuecomment-747754229 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0Nzc1NDIyOQ== | simonw 9599 | 2020-12-17T23:04:38Z | 2020-12-17T23:04:38Z | OWNER | Open question: will this work for hundreds of database files, or is the overhead of connecting to each of 100 databases in turn to run |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747754082 | https://github.com/simonw/datasette/issues/1150#issuecomment-747754082 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc0Nzc1NDA4Mg== | simonw 9599 | 2020-12-17T23:04:13Z | 2020-12-17T23:04:13Z | OWNER | Pages that need a list of all databases - the index page and /-/databases for example - could trigger a "check for new directories in the configured directories" scan. That scan would run at most once every 5 (n) seconds - the check is triggered if it’s run more recently than that it doesn’t run. Hopefully this means it could be done as a blocking operation, rather than trying to run it in a thread. When it runs it scans for .db or .sqlite files (maybe one or two other extensions) that it hasn’t seen before. It also checks that the existing list of known database files still exists. If it finds any new ones it connects to them once to run |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 747734273 | https://github.com/simonw/datasette/issues/461#issuecomment-747734273 | https://api.github.com/repos/simonw/datasette/issues/461 | MDEyOklzc3VlQ29tbWVudDc0NzczNDI3Mw== | simonw 9599 | 2020-12-17T22:14:46Z | 2020-12-17T22:14:46Z | OWNER | I've been thinking about this a bunch. For Datasette to be useful as a private repository of data (Datasette Library, #417) it's crucial that it can handle a much, much larger number of databases. This makes me worry about how many connections (and open file handles) it makes sense to have open at one time. I realize now that this is much less of a problem for private instances. Public instances on the internet could get traffic to any database at any time, so connections could easily get out of control. A private instance with only a few users could instead get away with only opening connections to databases in "active use". This does however make it even more important for Datasette to maintain a cached set of metadata about the tables - which is also needed to power this feature. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Paginate + search for databases/tables on the homepage 443021509 | |
| 747209115 | https://github.com/simonw/datasette/issues/1005#issuecomment-747209115 | https://api.github.com/repos/simonw/datasette/issues/1005 | MDEyOklzc3VlQ29tbWVudDc0NzIwOTExNQ== | simonw 9599 | 2020-12-17T05:11:04Z | 2020-12-17T05:11:04Z | OWNER | Tracking ticket for the next HTTPX release is https://github.com/encode/httpx/pull/1403 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Remove xfail tests when new httpx is released 718259202 | |
| 747208543 | https://github.com/simonw/datasette/issues/741#issuecomment-747208543 | https://api.github.com/repos/simonw/datasette/issues/741 | MDEyOklzc3VlQ29tbWVudDc0NzIwODU0Mw== | simonw 9599 | 2020-12-17T05:09:03Z | 2020-12-17T05:09:03Z | OWNER | I really like this in |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Replace "datasette publish --extra-options" with "--setting" 607223136 | |
| 747207787 | https://github.com/simonw/datasette/issues/1149#issuecomment-747207787 | https://api.github.com/repos/simonw/datasette/issues/1149 | MDEyOklzc3VlQ29tbWVudDc0NzIwNzc4Nw== | simonw 9599 | 2020-12-17T05:06:16Z | 2020-12-17T05:06:16Z | OWNER | So, an idea: what if Datasette's default CSS applied only to elements with classes - or maybe to childen of a |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Make it easier to theme Datasette with CSS 769520939 | |
| 747207487 | https://github.com/simonw/datasette/issues/1149#issuecomment-747207487 | https://api.github.com/repos/simonw/datasette/issues/1149 | MDEyOklzc3VlQ29tbWVudDc0NzIwNzQ4Nw== | simonw 9599 | 2020-12-17T05:05:08Z | 2020-12-17T05:05:08Z | OWNER | I think what I want is for it to be easy to reuse portions of Datasette's CSS - the bit that styles the cog menu for example - without pulling in the whole thing. I tried linking in the
That's because Datasette's built-in CSS applies styles directly to a whole bunch of different tags - |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Make it easier to theme Datasette with CSS 769520939 | |
| 747130908 | https://github.com/dogsheep/google-takeout-to-sqlite/issues/2#issuecomment-747130908 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/2 | MDEyOklzc3VlQ29tbWVudDc0NzEzMDkwOA== | khimaros 231498 | 2020-12-17T00:47:04Z | 2020-12-17T00:47:43Z | NONE | it looks like almost all of the memory consumption is coming from another direction here may be to use the new "Semantic Location History" data which is already broken down by year and month. it also provides much more interesting data, such as estimated address, form of travel, etc. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
killed by oomkiller on large location-history 769376447 | |
| 747126777 | https://github.com/dogsheep/google-takeout-to-sqlite/issues/2#issuecomment-747126777 | https://api.github.com/repos/dogsheep/google-takeout-to-sqlite/issues/2 | MDEyOklzc3VlQ29tbWVudDc0NzEyNjc3Nw== | simonw 9599 | 2020-12-17T00:36:52Z | 2020-12-17T00:36:52Z | MEMBER | The memory profiler tricks I used in https://github.com/dogsheep/healthkit-to-sqlite/issues/7 could help figure out what's going on here. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
killed by oomkiller on large location-history 769376447 | |
| 747070709 | https://github.com/simonw/datasette/issues/675#issuecomment-747070709 | https://api.github.com/repos/simonw/datasette/issues/675 | MDEyOklzc3VlQ29tbWVudDc0NzA3MDcwOQ== | simonw 9599 | 2020-12-16T22:09:15Z | 2020-12-16T22:09:15Z | OWNER | The other way this could work is passing a single argument - the file (or directory) to be copied in - and assuming it should always go in the Which would add |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--cp option for datasette publish and datasette package for shipping additional files and directories 567902704 | |
| 747068624 | https://github.com/simonw/datasette/issues/675#issuecomment-747068624 | https://api.github.com/repos/simonw/datasette/issues/675 | MDEyOklzc3VlQ29tbWVudDc0NzA2ODYyNA== | simonw 9599 | 2020-12-16T22:04:42Z | 2020-12-16T22:04:42Z | OWNER | I can't just use |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--cp option for datasette publish and datasette package for shipping additional files and directories 567902704 | |
| 747067864 | https://github.com/simonw/datasette/issues/675#issuecomment-747067864 | https://api.github.com/repos/simonw/datasette/issues/675 | MDEyOklzc3VlQ29tbWVudDc0NzA2Nzg2NA== | simonw 9599 | 2020-12-16T22:02:55Z | 2020-12-16T22:02:55Z | OWNER | But since we're already running But... I feel the usability of the command will be better if users can use absolute paths on the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--cp option for datasette publish and datasette package for shipping additional files and directories 567902704 | |
| 747066629 | https://github.com/simonw/datasette/issues/675#issuecomment-747066629 | https://api.github.com/repos/simonw/datasette/issues/675 | MDEyOklzc3VlQ29tbWVudDc0NzA2NjYyOQ== | simonw 9599 | 2020-12-16T21:59:58Z | 2020-12-16T22:00:48Z | OWNER | Note that https://github.com/simonw/datasette/blob/17cbbb1f7f230b39650afac62dd16476626001b5/datasette/utils/init.py#L348-L357 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--cp option for datasette publish and datasette package for shipping additional files and directories 567902704 | |
| 747065487 | https://github.com/simonw/datasette/issues/1148#issuecomment-747065487 | https://api.github.com/repos/simonw/datasette/issues/1148 | MDEyOklzc3VlQ29tbWVudDc0NzA2NTQ4Nw== | simonw 9599 | 2020-12-16T21:57:29Z | 2020-12-16T21:57:29Z | OWNER | I filed a new public bug in their issue tracker here: https://github.com/vercel/vercel/issues/5575 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Syntax error with + symbol when deployed to Vercel 767561886 | |
| 747062909 | https://github.com/simonw/datasette/issues/1148#issuecomment-747062909 | https://api.github.com/repos/simonw/datasette/issues/1148 | MDEyOklzc3VlQ29tbWVudDc0NzA2MjkwOQ== | simonw 9599 | 2020-12-16T21:51:54Z | 2020-12-16T21:51:54Z | OWNER | This is a really frustrating bug with Vercel: https://github.com/simonw/datasette-publish-vercel/issues/28
A workaround is to avoid https://aws-partners-singapore.vercel.app/partners?sql=select%0D%0A++A.launch_rank%2C%0D%0A++A.partner_info%0D%0Afrom%0D%0A++summary+A%0D%0A++INNER+JOIN+summary+B+ON+A.launch_rank+%3E%3D+B.launch_rank+-+3%0D%0A++AND+A.launch_rank+-4+%3C%3D+B.launch_rank%0D%0AWHERE%0D%0A++B.%22partner_info%22+LIKE+%27%25Palo+Alto%25%27
|
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Syntax error with + symbol when deployed to Vercel 767561886 | |
| 747059277 | https://github.com/simonw/datasette/issues/675#issuecomment-747059277 | https://api.github.com/repos/simonw/datasette/issues/675 | MDEyOklzc3VlQ29tbWVudDc0NzA1OTI3Nw== | simonw 9599 | 2020-12-16T21:43:52Z | 2020-12-16T21:43:52Z | OWNER | It turns out I need this for a couple of projects:
I want this for |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--cp option for datasette publish and datasette package for shipping additional files and directories 567902704 | |
| 747034481 | https://github.com/dogsheep/dogsheep-beta/issues/29#issuecomment-747034481 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/29 | MDEyOklzc3VlQ29tbWVudDc0NzAzNDQ4MQ== | simonw 9599 | 2020-12-16T21:17:05Z | 2020-12-16T21:17:05Z | MEMBER | I'm just going to add |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Add search highlighting snippets 724759588 | |
| 747031608 | https://github.com/dogsheep/dogsheep-beta/issues/29#issuecomment-747031608 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/29 | MDEyOklzc3VlQ29tbWVudDc0NzAzMTYwOA== | simonw 9599 | 2020-12-16T21:15:18Z | 2020-12-16T21:15:18Z | MEMBER | Should I pass any other details to the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Add search highlighting snippets 724759588 | |
| 747030964 | https://github.com/dogsheep/dogsheep-beta/issues/29#issuecomment-747030964 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/29 | MDEyOklzc3VlQ29tbWVudDc0NzAzMDk2NA== | simonw 9599 | 2020-12-16T21:14:54Z | 2020-12-16T21:14:54Z | MEMBER | To do this I'll need the search term to be passed to the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Add search highlighting snippets 724759588 | |
| 747029636 | https://github.com/dogsheep/dogsheep-beta/issues/29#issuecomment-747029636 | https://api.github.com/repos/dogsheep/dogsheep-beta/issues/29 | MDEyOklzc3VlQ29tbWVudDc0NzAyOTYzNg== | simonw 9599 | 2020-12-16T21:14:03Z | 2020-12-16T21:14:03Z | MEMBER | I think I can do this as a cunning trick in
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Add search highlighting snippets 724759588 | |
| 746827083 | https://github.com/simonw/datasette/issues/1143#issuecomment-746827083 | https://api.github.com/repos/simonw/datasette/issues/1143 | MDEyOklzc3VlQ29tbWVudDc0NjgyNzA4Mw== | simonw 9599 | 2020-12-16T18:56:07Z | 2020-12-16T18:56:07Z | OWNER | I think the right way to do this is to support multiple optional |
{
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
More flexible CORS support in core, to encourage good security practices 764059235 | |
| 746735889 | https://github.com/dogsheep/github-to-sqlite/issues/58#issuecomment-746735889 | https://api.github.com/repos/dogsheep/github-to-sqlite/issues/58 | MDEyOklzc3VlQ29tbWVudDc0NjczNTg4OQ== | simonw 9599 | 2020-12-16T17:59:50Z | 2020-12-16T17:59:50Z | MEMBER | I don't want to add a full HTML parser (like BeautifulSoup) as a dependency for this feature. Since the HTML comes from a single, trusted source (GitHub) I could probably handle this using regular expressions. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Readme HTML has broken internal links 769150394 | |
| 746734412 | https://github.com/dogsheep/github-to-sqlite/issues/58#issuecomment-746734412 | https://api.github.com/repos/dogsheep/github-to-sqlite/issues/58 | MDEyOklzc3VlQ29tbWVudDc0NjczNDQxMg== | simonw 9599 | 2020-12-16T17:58:56Z | 2020-12-16T17:58:56Z | MEMBER | I'm going to rewrite those |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Readme HTML has broken internal links 769150394 | |
| 745162571 | https://github.com/simonw/datasette/issues/1142#issuecomment-745162571 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0NTE2MjU3MQ== | nitinpaultifr 6622733 | 2020-12-15T09:22:58Z | 2020-12-15T09:22:58Z | NONE | You're right, probably more straightforward to have the links for JSON. I was imagining to toggle the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 744618787 | https://github.com/simonw/datasette/issues/1143#issuecomment-744618787 | https://api.github.com/repos/simonw/datasette/issues/1143 | MDEyOklzc3VlQ29tbWVudDc0NDYxODc4Nw== | yurivish 114388 | 2020-12-14T18:15:00Z | 2020-12-15T02:21:53Z | NONE | From a quick look at the README, it does seem to do everything I need, thanks! I think the argument for inclusion in core is to lower the chances of unwanted data access. A local server can be accessed by anybody who can make an HTTP request to your computer regardless of CORS rules, but the default That's probably not what people typically intend, particularly when the data is of a sensitive nature. A default of requiring the user to specify the origin (allowing |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
More flexible CORS support in core, to encourage good security practices 764059235 | |
| 744757558 | https://github.com/simonw/datasette/issues/1143#issuecomment-744757558 | https://api.github.com/repos/simonw/datasette/issues/1143 | MDEyOklzc3VlQ29tbWVudDc0NDc1NzU1OA== | simonw 9599 | 2020-12-14T22:42:10Z | 2020-12-14T22:42:10Z | OWNER | This may involve a breaking change to the CLI settings interface, so I'm adding this to the 1.0 milestone. |
{
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} |
More flexible CORS support in core, to encourage good security practices 764059235 | |
| 744756861 | https://github.com/simonw/datasette/issues/1143#issuecomment-744756861 | https://api.github.com/repos/simonw/datasette/issues/1143 | MDEyOklzc3VlQ29tbWVudDc0NDc1Njg2MQ== | simonw 9599 | 2020-12-14T22:40:28Z | 2020-12-14T22:40:28Z | OWNER | That's a very convincing argument. I'm keen on making sure Datasette is "secure by default" so you're right, encouraging finely grains CORS rules in core rather than leaving that to a plugin sounds like the right call. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
More flexible CORS support in core, to encourage good security practices 764059235 | |
| 744576894 | https://github.com/simonw/datasette/issues/1142#issuecomment-744576894 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0NDU3Njg5NA== | simonw 9599 | 2020-12-14T17:03:13Z | 2020-12-14T17:03:13Z | OWNER | I'm not sure about the radio boxes for JSON, just because you can't right-click on a radio box and copy it to your clipboard like you can with links. Worth trying it out though. The radio boxes for that CSV option are definitely the right way to go. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 744563209 | https://github.com/simonw/datasette/issues/1142#issuecomment-744563209 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0NDU2MzIwOQ== | simonw 9599 | 2020-12-14T16:41:11Z | 2020-12-14T16:41:11Z | OWNER | To check out and start the server: And to run the tests: |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 744522099 | https://github.com/simonw/datasette/issues/1142#issuecomment-744522099 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0NDUyMjA5OQ== | nitinpaultifr 6622733 | 2020-12-14T15:37:47Z | 2020-12-14T15:37:47Z | NONE | Alright I could give it a try! This might be a stupid question, can you tell me how to run the server from my fork? So that I can test the changes? |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 744489028 | https://github.com/simonw/datasette/issues/1144#issuecomment-744489028 | https://api.github.com/repos/simonw/datasette/issues/1144 | MDEyOklzc3VlQ29tbWVudDc0NDQ4OTAyOA== | MarkusH 475613 | 2020-12-14T14:47:11Z | 2020-12-14T14:47:11Z | NONE | Thanks for opening the issue, @simonw. Let me elaborate on my Tweets. datasette-chartjs provides drop down lists to pick the chart visualization (e.g. bar, line, doughnut, pie, ...) as well as the column used for the "x axis" (e.g. time). A user can change the values on-demand. The chart will be redrawn w/o querying the database again. However, if a user wants to change the underlying query, they will use the SQL field provided by datasette or any of the other datasette built-in features to amend a query. In order to maintain a user's selections for the plugin, datasette-chartjs copies some parts of datasette-vega which persist the chosen visualization and column in the hash part of a URL (the stuff behind the Additionally, datasette-vega and datasette-chartjs need to make sure to include the hash in all links and forms that cause a reload of the page. This is, such that the config persists between clicks. This ticket is about moving thes parts into datasette that provide the functionality to do so. This includes:
There's another, optional, feature that we might want to think about during the design phase: the scope of the config. Links within a datasette instance have 1 of 3 scopes:
When updating the links and forms as pointed out in 3. above, it might be worth considering which links need to be updated. I could imagine a plugin that wants to persist some setting across all tables within a database but another setting only within a table. |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
JavaScript to help plugins interact with the fragment part of the URL 765637324 | |
| 744475543 | https://github.com/simonw/datasette/pull/1145#issuecomment-744475543 | https://api.github.com/repos/simonw/datasette/issues/1145 | MDEyOklzc3VlQ29tbWVudDc0NDQ3NTU0Mw== | codecov[bot] 22429695 | 2020-12-14T14:26:25Z | 2020-12-14T14:26:25Z | NONE | Codecov Report
```diff @@ Coverage Diff @@ main #1145 +/-=======================================
Coverage 91.41% 91.41% Continue to review full report at Codecov.
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Update pytest requirement from <6.2.0,>=5.2.2 to >=5.2.2,<6.3.0 766494367 | |
| 744461856 | https://github.com/simonw/datasette/issues/276#issuecomment-744461856 | https://api.github.com/repos/simonw/datasette/issues/276 | MDEyOklzc3VlQ29tbWVudDc0NDQ2MTg1Ng== | robintw 296686 | 2020-12-14T14:04:57Z | 2020-12-14T14:04:57Z | NONE | I'm looking into using datasette with a database with spatialite geometry columns, and came across this issue. Has there been any progress on this since 2018? In one of my tables I'm just storing lat/lon points in a spatialite point geometry, and I've managed to make datasette-cluster-map display the points by extracting the lat and lon in SQL - using something like |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Handle spatialite geometry columns better 324835838 | |
| 744251252 | https://github.com/simonw/datasette/issues/1142#issuecomment-744251252 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0NDI1MTI1Mg== | simonw 9599 | 2020-12-14T07:56:38Z | 2020-12-14T07:56:38Z | OWNER | That's a really solid design for this! I'd be very happy to review a pull request - you should be able to implement this with just template edits and some CSS changes I think. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 744249157 | https://github.com/simonw/datasette/issues/1143#issuecomment-744249157 | https://api.github.com/repos/simonw/datasette/issues/1143 | MDEyOklzc3VlQ29tbWVudDc0NDI0OTE1Nw== | simonw 9599 | 2020-12-14T07:53:15Z | 2020-12-14T07:53:15Z | OWNER | Does this plugin do everything you need? https://github.com/simonw/datasette-cors I'm open to arguments as to why this should be in core rather than in a plugin - I'm on the fence about that at the moment. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
More flexible CORS support in core, to encourage good security practices 764059235 | |
| 744142692 | https://github.com/simonw/datasette/issues/741#issuecomment-744142692 | https://api.github.com/repos/simonw/datasette/issues/741 | MDEyOklzc3VlQ29tbWVudDc0NDE0MjY5Mg== | simonw 9599 | 2020-12-14T03:28:56Z | 2020-12-14T03:28:56Z | OWNER | I'm going to try this out on |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Replace "datasette publish --extra-options" with "--setting" 607223136 | |
| 744066249 | https://github.com/simonw/datasette/issues/983#issuecomment-744066249 | https://api.github.com/repos/simonw/datasette/issues/983 | MDEyOklzc3VlQ29tbWVudDc0NDA2NjI0OQ== | simonw 9599 | 2020-12-13T20:47:52Z | 2020-12-13T20:47:52Z | OWNER | @yozlet just spotted this comment. Wow that is interesting! With the right plugin hooks on the page (see also #987) one relatively simple way to do that could be with bookmarklets - users could install bookmarklets which, when executed against a Datasette page in their browser, use the existing JavaScript plugin integration points to add all kinds of functionality. Doing full sandboxing is certainly daunting, but it looks like Figma figured it out so TIL it's technically feasible. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
JavaScript plugin hooks mechanism similar to pluggy 712260429 | |
| 744003454 | https://github.com/simonw/datasette/pull/1031#issuecomment-744003454 | https://api.github.com/repos/simonw/datasette/issues/1031 | MDEyOklzc3VlQ29tbWVudDc0NDAwMzQ1NA== | frankier 299380 | 2020-12-13T12:52:56Z | 2020-12-13T12:52:56Z | NONE | Please let me know if there's anything I can do to help get this merged. This is causing problems for me because it means when I build my Docker image my databases aren't considered immutable, which I would like them to be so that a download link is produced. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Fallback to databases in inspect-data.json when no -i options are passed 724369025 | |
| 743998792 | https://github.com/simonw/datasette/issues/1142#issuecomment-743998792 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0Mzk5ODc5Mg== | nitinpaultifr 6622733 | 2020-12-13T12:14:06Z | 2020-12-13T12:14:06Z | NONE | Agreed, it would definitely provide better controls. However, I do feel it makes for a bit of inconsistent UX for the 'Advanced export' section, with links to download for JSON, checkboxes and radio buttons + button to download for CSV. Do you think this example makes the UX a bit nicer/consistent?
I could give it a try if you'd like but I've never contributed to an actual project! |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 743966801 | https://github.com/simonw/sqlite-utils/issues/207#issuecomment-743966801 | https://api.github.com/repos/simonw/sqlite-utils/issues/207 | MDEyOklzc3VlQ29tbWVudDc0Mzk2NjgwMQ== | simonw 9599 | 2020-12-13T07:25:23Z | 2020-12-13T07:25:23Z | OWNER | CLI documentation: https://sqlite-utils.readthedocs.io/en/latest/cli.html#analyzing-tables Python library documentation: https://sqlite-utils.readthedocs.io/en/latest/python-api.html#analyzing-a-column |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite-utils analyze-tables command 763283616 | |
| 743966289 | https://github.com/simonw/sqlite-utils/pull/203#issuecomment-743966289 | https://api.github.com/repos/simonw/sqlite-utils/issues/203 | MDEyOklzc3VlQ29tbWVudDc0Mzk2NjI4OQ== | simonw 9599 | 2020-12-13T07:20:51Z | 2020-12-13T07:20:51Z | OWNER | Sorry for not reviewing this yet! I'll try to carve out time to look at it in the next few days. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
changes to allow for compound foreign keys 743384829 | |
| 743956666 | https://github.com/simonw/sqlite-utils/pull/208#issuecomment-743956666 | https://api.github.com/repos/simonw/sqlite-utils/issues/208 | MDEyOklzc3VlQ29tbWVudDc0Mzk1NjY2Ng== | simonw 9599 | 2020-12-13T05:44:49Z | 2020-12-13T05:44:49Z | OWNER | Example output:
```
% sqlite-utils analyze-tables github.db tags Total rows: 261 Null rows: 0 Blank rows: 0 Distinct values: 14 Most common: 88: 107914493 75: 140912432 27: 206156866 21: 207052882 17: 197431109 8: 197882382 5: 256834907 5: 205429375 4: 248903544 3: 206202864 Least common: 1: 209590345 2: 206649770 2: 303218369 3: 206202864 3: 213286752 4: 248903544 5: 205429375 5: 256834907 8: 197882382 17: 197431109 tags.name: (2/3) Total rows: 261 Null rows: 0 Blank rows: 0 Distinct values: 175 Most common: 10: 0.2 9: 0.1 7: 0.3 6: 0.4 5: 0.7 5: 0.5 5: 0.1a 4: 0.9 4: 0.8 4: 0.6 Least common: 1: 0.1.1 1: 0.11.1 1: 0.1a2 1: 0.20.1 1: 0.21.1 1: 0.21.2 1: 0.21.3 1: 0.22 1: 0.22.1 1: 0.23 tags.sha: (3/3) Total rows: 261 Null rows: 0 Blank rows: 0 Distinct values: 261 ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite-utils analyze-tables command and table.analyze_column() method 763320133 | |
| 743913004 | https://github.com/simonw/datasette/issues/1142#issuecomment-743913004 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0MzkxMzAwNA== | simonw 9599 | 2020-12-12T22:17:46Z | 2020-12-12T22:17:46Z | OWNER | You're actually choosing between two options here: the 100 rows you can see on the screen, or the x,000 rows that match the current query. Maybe a radio box would be more obvious? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 743912875 | https://github.com/simonw/datasette/issues/1142#issuecomment-743912875 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0MzkxMjg3NQ== | simonw 9599 | 2020-12-12T22:16:38Z | 2020-12-12T22:16:38Z | OWNER | Yeah, maybe with the number of rows to make it completely clear. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 743732440 | https://github.com/simonw/datasette/issues/1142#issuecomment-743732440 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0MzczMjQ0MA== | nitinpaultifr 6622733 | 2020-12-12T09:56:40Z | 2020-12-12T09:56:40Z | NONE | 'Include all rows' seem like a fairly obvious alternative |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 743708524 | https://github.com/simonw/sqlite-utils/pull/208#issuecomment-743708524 | https://api.github.com/repos/simonw/sqlite-utils/issues/208 | MDEyOklzc3VlQ29tbWVudDc0MzcwODUyNA== | simonw 9599 | 2020-12-12T05:48:20Z | 2020-12-12T05:48:32Z | OWNER |
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite-utils analyze-tables command and table.analyze_column() method 763320133 | |
| 743708325 | https://github.com/simonw/sqlite-utils/pull/208#issuecomment-743708325 | https://api.github.com/repos/simonw/sqlite-utils/issues/208 | MDEyOklzc3VlQ29tbWVudDc0MzcwODMyNQ== | simonw 9599 | 2020-12-12T05:46:27Z | 2020-12-12T05:46:27Z | OWNER | It would be neat if you could optionally specify a subset of columns to analyze, using |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite-utils analyze-tables command and table.analyze_column() method 763320133 | |
| 743708169 | https://github.com/simonw/sqlite-utils/pull/208#issuecomment-743708169 | https://api.github.com/repos/simonw/sqlite-utils/issues/208 | MDEyOklzc3VlQ29tbWVudDc0MzcwODE2OQ== | simonw 9599 | 2020-12-12T05:44:46Z | 2020-12-12T05:44:46Z | OWNER | If there are less than ten values is it worth outputting them twice, once in |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite-utils analyze-tables command and table.analyze_column() method 763320133 | |
| 743708080 | https://github.com/simonw/sqlite-utils/pull/208#issuecomment-743708080 | https://api.github.com/repos/simonw/sqlite-utils/issues/208 | MDEyOklzc3VlQ29tbWVudDc0MzcwODA4MA== | simonw 9599 | 2020-12-12T05:43:45Z | 2020-12-12T05:43:45Z | OWNER | CLI output looks like this at the moment, which is bad:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite-utils analyze-tables command and table.analyze_column() method 763320133 | |
| 743707969 | https://github.com/simonw/sqlite-utils/pull/208#issuecomment-743707969 | https://api.github.com/repos/simonw/sqlite-utils/issues/208 | MDEyOklzc3VlQ29tbWVudDc0MzcwNzk2OQ== | simonw 9599 | 2020-12-12T05:42:26Z | 2020-12-12T05:43:06Z | OWNER | Should truncate values in the least/most common JSON array to a sensible length, otherwise you end up with stuff like this:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite-utils analyze-tables command and table.analyze_column() method 763320133 | |
| 743701697 | https://github.com/simonw/sqlite-utils/issues/207#issuecomment-743701697 | https://api.github.com/repos/simonw/sqlite-utils/issues/207 | MDEyOklzc3VlQ29tbWVudDc0MzcwMTY5Nw== | simonw 9599 | 2020-12-12T04:39:51Z | 2020-12-12T04:39:51Z | OWNER | CLI could be: To analyze all tables or: To analyze specific tables. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite-utils analyze-tables command 763283616 | |
| 743701599 | https://github.com/simonw/sqlite-utils/issues/207#issuecomment-743701599 | https://api.github.com/repos/simonw/sqlite-utils/issues/207 | MDEyOklzc3VlQ29tbWVudDc0MzcwMTU5OQ== | simonw 9599 | 2020-12-12T04:38:52Z | 2020-12-12T04:39:07Z | OWNER | I'll add a |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite-utils analyze-tables command 763283616 | |
| 743701422 | https://github.com/simonw/sqlite-utils/issues/207#issuecomment-743701422 | https://api.github.com/repos/simonw/sqlite-utils/issues/207 | MDEyOklzc3VlQ29tbWVudDc0MzcwMTQyMg== | simonw 9599 | 2020-12-12T04:37:14Z | 2020-12-12T04:38:25Z | OWNER | Prototype: ```python from collections import namedtuple ColumnDetails = namedtuple("ColumnDetails", ("column", "num_null", "num_blank", "num_distinct", "most_common", "least_common")) def analyze_column(db, table, column, values=10): num_null = db.execute("select count() from [{}] where [{}] is null".format(table, column)).fetchone()[0] num_blank = db.execute("select count() from [{}] where [{}] = ''".format(table, column)).fetchone()[0] num_distinct = db.execute("select count(distinct [{}]) from [{}]".format(column, table)).fetchone()[0] most_common = None least_common = None if num_distinct != 1: most_common = [(r[0], r[1]) for r in db.execute( "select [{}], count() from [{}] group by [{}] order by count() desc limit ".format(column, table, column, values) ).fetchall()] if num_distinct <= values: # No need to run the query if it will just return the results in revers order least_common = most_common[::-1] else: least_common = [(r[0], r[1]) for r in db.execute( "select [{}], count() from [{}] group by [{}] order by count() limit {}".format(column, table, column, values) ).fetchall()] return ColumnDetails(column, num_null, num_blank, num_distinct, most_common, least_common) def analyze_table(db, table): for column in db[table].columns: details = analyze_column(db, table, column.name) print(details) ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite-utils analyze-tables command 763283616 | |
| 743080047 | https://github.com/simonw/datasette/issues/998#issuecomment-743080047 | https://api.github.com/repos/simonw/datasette/issues/998 | MDEyOklzc3VlQ29tbWVudDc0MzA4MDA0Nw== | JBPressac 6371750 | 2020-12-11T09:25:09Z | 2020-12-11T09:25:09Z | CONTRIBUTOR | Hello Simon, I have a similar problem with horizontal scrollbar display with Datasette version 0.51 and superior for a table with more than 30 rows. With Datasette 0.50, the horizontal scrollbar is displayed, if I upgrade Datasette to 0.51 and superior, the horizontal scrollbar disappears. Datasette 0.50: horizontal scrollbar
Datasette 0.51 and superior: no horizontal scrollbar
Thanks, |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Wide tables should scroll horizontally within the page 717699884 | |
| 742737794 | https://github.com/simonw/sqlite-utils/issues/205#issuecomment-742737794 | https://api.github.com/repos/simonw/sqlite-utils/issues/205 | MDEyOklzc3VlQ29tbWVudDc0MjczNzc5NA== | simonw 9599 | 2020-12-10T19:18:22Z | 2020-12-10T19:18:22Z | OWNER | Yup, it looks like you're using a window function that was added in SQLite 3.25.0: https://www.sqlite.org/changes.html#version_3_25_0 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite3.OperationalError: near "(": syntax error 760960559 | |
| 742299584 | https://github.com/simonw/sqlite-utils/issues/205#issuecomment-742299584 | https://api.github.com/repos/simonw/sqlite-utils/issues/205 | MDEyOklzc3VlQ29tbWVudDc0MjI5OTU4NA== | kaihendry 765871 | 2020-12-10T07:24:22Z | 2020-12-10T07:24:22Z | NONE | Bumping to ubuntu-20.04 appears to have solved my syntax error. 🤷 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
sqlite3.OperationalError: near "(": syntax error 760960559 | |
| 742260116 | https://github.com/simonw/datasette/issues/1134#issuecomment-742260116 | https://api.github.com/repos/simonw/datasette/issues/1134 | MDEyOklzc3VlQ29tbWVudDc0MjI2MDExNg== | clausjuhl 2181410 | 2020-12-10T05:57:17Z | 2020-12-10T05:57:17Z | NONE | Hi Simon Thank you for the quick fix! And glad you like our use of Datasette (launches 1. january 2021). It's a site that currently (more to come) makes all minutes and their annexes from Aarhus City Council and the major committees (1997-2019) available to the public. So we're putting Datasette to good use :) |
{
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} |
"_searchmode=raw" throws an index out of range error when combined with "_search_COLUMN" 760312579 | |
| 741992106 | https://github.com/simonw/datasette/issues/1091#issuecomment-741992106 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc0MTk5MjEwNg== | simonw 9599 | 2020-12-09T19:19:54Z | 2020-12-09T20:27:45Z | OWNER | Could you try removing the My hunch is that Normally you would need |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 742024588 | https://github.com/simonw/datasette/issues/1134#issuecomment-742024588 | https://api.github.com/repos/simonw/datasette/issues/1134 | MDEyOklzc3VlQ29tbWVudDc0MjAyNDU4OA== | simonw 9599 | 2020-12-09T20:19:59Z | 2020-12-09T20:20:33Z | OWNER | https://byraadsarkivet.aarhus.dk/db/cases?_searchmode=raw&_search=sundhedsfrem%2A is an absolutely beautiful example of a themed Datasette! Very excited to show this to people. |
{
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"_searchmode=raw" throws an index out of range error when combined with "_search_COLUMN" 760312579 | |
| 742023775 | https://github.com/simonw/datasette/issues/1134#issuecomment-742023775 | https://api.github.com/repos/simonw/datasette/issues/1134 | MDEyOklzc3VlQ29tbWVudDc0MjAyMzc3NQ== | simonw 9599 | 2020-12-09T20:18:23Z | 2020-12-09T20:18:23Z | OWNER | A fix for this should be available if you upgrade to 0.52.5 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"_searchmode=raw" throws an index out of range error when combined with "_search_COLUMN" 760312579 | |
| 742023541 | https://github.com/simonw/datasette/issues/1091#issuecomment-742023541 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc0MjAyMzU0MQ== | simonw 9599 | 2020-12-09T20:17:54Z | 2020-12-09T20:17:54Z | OWNER | OK that is really weird. I'll have another go at replicating this locally. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 742023111 | https://github.com/simonw/datasette/issues/1136#issuecomment-742023111 | https://api.github.com/repos/simonw/datasette/issues/1136 | MDEyOklzc3VlQ29tbWVudDc0MjAyMzExMQ== | simonw 9599 | 2020-12-09T20:17:02Z | 2020-12-09T20:17:02Z | OWNER | Documentation for this procedure is now here: https://docs.datasette.io/en/latest/contributing.html#releasing-bug-fixes-from-a-branch |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Establish pattern for release branches to support bug fixes 760621356 | |
| 742022222 | https://github.com/simonw/datasette/issues/1136#issuecomment-742022222 | https://api.github.com/repos/simonw/datasette/issues/1136 | MDEyOklzc3VlQ29tbWVudDc0MjAyMjIyMg== | simonw 9599 | 2020-12-09T20:15:24Z | 2020-12-09T20:15:51Z | OWNER | Used this procedure for the first time for 0.52.5 - deploy run here: https://github.com/simonw/datasette/actions/runs/411465648 - PyPI release here: https://pypi.org/project/datasette/0.52.5/ |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Establish pattern for release branches to support bug fixes 760621356 | |
| 742017622 | https://github.com/simonw/datasette/issues/1136#issuecomment-742017622 | https://api.github.com/repos/simonw/datasette/issues/1136 | MDEyOklzc3VlQ29tbWVudDc0MjAxNzYyMg== | simonw 9599 | 2020-12-09T20:06:47Z | 2020-12-09T20:06:47Z | OWNER | Then I can ship the release directly from that branch, creating the tag as part of the release process:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Establish pattern for release branches to support bug fixes 760621356 | |
| 742014881 | https://github.com/simonw/datasette/issues/1136#issuecomment-742014881 | https://api.github.com/repos/simonw/datasette/issues/1136 | MDEyOklzc3VlQ29tbWVudDc0MjAxNDg4MQ== | simonw 9599 | 2020-12-09T20:01:27Z | 2020-12-09T20:01:27Z | OWNER | I'll write the release notes in the branch, then cherry-pick them over to |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Establish pattern for release branches to support bug fixes 760621356 | |
| 742014366 | https://github.com/simonw/datasette/issues/1136#issuecomment-742014366 | https://api.github.com/repos/simonw/datasette/issues/1136 | MDEyOklzc3VlQ29tbWVudDc0MjAxNDM2Ng== | simonw 9599 | 2020-12-09T20:00:35Z | 2020-12-09T20:00:35Z | OWNER | Actually I'll start from 0.52.4 and then cherry-pick the fixes. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Establish pattern for release branches to support bug fixes 760621356 | |
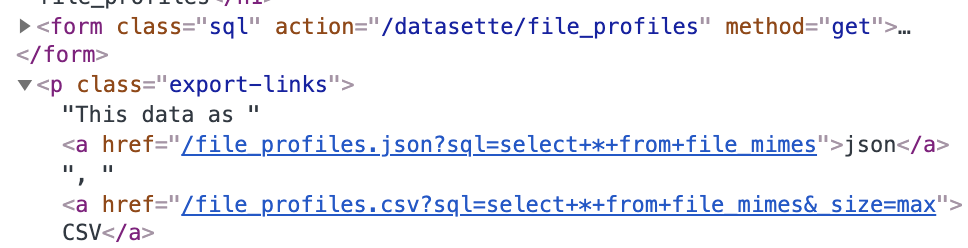
| 742010306 | https://github.com/simonw/datasette/issues/1091#issuecomment-742010306 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc0MjAxMDMwNg== | tballison 6739646 | 2020-12-09T19:53:18Z | 2020-12-09T19:59:52Z | NONE | I can't imagine this helps (esp. given your point about potential rewrites), but you can see that /datasette/ was correctly added to the sql form, but not to the "export-links"
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 742012324 | https://github.com/simonw/datasette/issues/1134#issuecomment-742012324 | https://api.github.com/repos/simonw/datasette/issues/1134 | MDEyOklzc3VlQ29tbWVudDc0MjAxMjMyNA== | simonw 9599 | 2020-12-09T19:57:05Z | 2020-12-09T19:57:05Z | OWNER | Thanks for the bug report! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"_searchmode=raw" throws an index out of range error when combined with "_search_COLUMN" 760312579 | |
| 742009294 | https://github.com/simonw/datasette/issues/1136#issuecomment-742009294 | https://api.github.com/repos/simonw/datasette/issues/1136 | MDEyOklzc3VlQ29tbWVudDc0MjAwOTI5NA== | simonw 9599 | 2020-12-09T19:51:18Z | 2020-12-09T19:51:18Z | OWNER | Likewise, Read The Docs publishes as stable the docs from the latest tagged release, so I would expect that to work fine as well. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Establish pattern for release branches to support bug fixes 760621356 | |
| 742009101 | https://github.com/simonw/datasette/issues/1136#issuecomment-742009101 | https://api.github.com/repos/simonw/datasette/issues/1136 | MDEyOklzc3VlQ29tbWVudDc0MjAwOTEwMQ== | simonw 9599 | 2020-12-09T19:50:53Z | 2020-12-09T19:50:53Z | OWNER | My concern is if this will break anything about CI. I don't think it will - the code that deploys the latest |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Establish pattern for release branches to support bug fixes 760621356 | |
| 742008087 | https://github.com/simonw/datasette/issues/1136#issuecomment-742008087 | https://api.github.com/repos/simonw/datasette/issues/1136 | MDEyOklzc3VlQ29tbWVudDc0MjAwODA4Nw== | simonw 9599 | 2020-12-09T19:48:56Z | 2020-12-09T19:48:56Z | OWNER | I think I'm going to create a branch called |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Establish pattern for release branches to support bug fixes 760621356 | |
| 742001510 | https://github.com/simonw/datasette/issues/1091#issuecomment-742001510 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc0MjAwMTUxMA== | tballison 6739646 | 2020-12-09T19:36:42Z | 2020-12-09T19:38:04Z | NONE | I don't think this fixes it:
And I confirmed that I actually restarted the server. :rofl: |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 741804334 | https://github.com/simonw/datasette/issues/1091#issuecomment-741804334 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc0MTgwNDMzNA== | tballison 6739646 | 2020-12-09T14:26:05Z | 2020-12-09T14:26:05Z | NONE | Anything we can do to help debug this? Thank you, again! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 741665253 | https://github.com/simonw/datasette/issues/766#issuecomment-741665253 | https://api.github.com/repos/simonw/datasette/issues/766 | MDEyOklzc3VlQ29tbWVudDc0MTY2NTI1Mw== | clausjuhl 2181410 | 2020-12-09T09:59:05Z | 2020-12-09T09:59:05Z | NONE | Hi Simon. Any news on using wildcard-searches with datasette? Thanks! |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Enable wildcard-searches by default 617323873 | |
| 740850920 | https://github.com/simonw/datasette/issues/1133#issuecomment-740850920 | https://api.github.com/repos/simonw/datasette/issues/1133 | MDEyOklzc3VlQ29tbWVudDc0MDg1MDkyMA== | simonw 9599 | 2020-12-08T18:55:59Z | 2020-12-08T18:55:59Z | OWNER | Inspiration was this script: https://gist.github.com/simonw/f6e3cd29fde5d15ea9cd746c942046ba - which pipes output through |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Option to omit header row in CSV export 759695780 | |
| 740850057 | https://github.com/simonw/datasette/issues/1133#issuecomment-740850057 | https://api.github.com/repos/simonw/datasette/issues/1133 | MDEyOklzc3VlQ29tbWVudDc0MDg1MDA1Nw== | simonw 9599 | 2020-12-08T18:55:29Z | 2020-12-08T18:55:29Z | OWNER | Can work on this as part of #1062. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Option to omit header row in CSV export 759695780 |





Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issue_comments] (
[html_url] TEXT,
[issue_url] TEXT,
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[created_at] TEXT,
[updated_at] TEXT,
[author_association] TEXT,
[body] TEXT,
[reactions] TEXT,
[issue] INTEGER REFERENCES [issues]([id])
, [performed_via_github_app] TEXT);
CREATE INDEX [idx_issue_comments_issue]
ON [issue_comments] ([issue]);
CREATE INDEX [idx_issue_comments_user]
ON [issue_comments] ([user]);
user >30