issues
387 rows where comments = 2 and state = "closed" sorted by user
This data as json, CSV (advanced)
Suggested facets: milestone, author_association, draft, state_reason, created_at (date), updated_at (date), closed_at (date)
repo 10
state 1
- closed · 387 ✖
| id | node_id | number | title | user ▼ | state | locked | assignee | milestone | comments | created_at | updated_at | closed_at | author_association | pull_request | body | repo | type | active_lock_reason | performed_via_github_app | reactions | draft | state_reason |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1473664029 | PR_kwDOBm6k_c5ELz0u | 1930 | Typo in JSON API `Updating a row` documentation | davidbgk 3556 | closed | 0 | 2 | 2022-12-03T02:22:31Z | 2022-12-08T21:12:35Z | 2022-12-08T21:12:35Z | CONTRIBUTOR | simonw/datasette/pulls/1930 | :books: Documentation preview :books:: https://datasette--1930.org.readthedocs.build/en/1930/ |
datasette 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1930/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 919508498 | MDU6SXNzdWU5MTk1MDg0OTg= | 1375 | JSON export dumps JSON fields as TEXT | frafra 4068 | closed | 0 | 2 | 2021-06-12T09:45:08Z | 2021-06-14T09:41:59Z | 2021-06-13T15:37:58Z | NONE | Hi! When a user tries to export data as JSON, I would expect to see the value of JSON columns represented as JSON instead of being rendered as a string. What do you think? |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1375/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1250161887 | I_kwDOCGYnMM5Kg_Tf | 438 | illegal UTF-16 surrogate | frafra 4068 | closed | 0 | 2 | 2022-05-26T22:49:52Z | 2022-05-27T08:21:53Z | 2022-05-27T08:21:53Z | NONE | I am trying to insert ``` sqlite-utils insert --csv --delimiter ";" --encoding="utf-16-le" --pk "Id" csv fremmedart test.db [------------------------------------] 0% Error: 'utf-16-le' codec can't decode bytes in position 98-99: illegal UTF-16 surrogate The input you provided uses a character encoding other than utf-8. You can fix this by passing the --encoding= option with the encoding of the file. If you do not know the encoding, running 'file filename.csv' may tell you. It's often worth trying: --encoding=latin-1 ``` I tried to convert the file using ``` sqlite-utils insert --csv --delimiter ";" --encoding=utf-8 --pk "Id" csv_utf8 fremmedart test.db [------------------------------------] 0% Error: 'utf-8' codec can't decode byte 0xd9 in position 99: invalid continuation byte The input you provided uses a character encoding other than utf-8. You can fix this by passing the --encoding= option with the encoding of the file. If you do not know the encoding, running 'file filename.csv' may tell you. It's often worth trying: --encoding=latin-1 ``` I have no issues reading such file using this Python code:
|
sqlite-utils 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/438/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 1378495690 | I_kwDOBm6k_c5SKizK | 1814 | Static files not served | frafra 4068 | closed | 0 | 2 | 2022-09-19T20:38:17Z | 2022-09-19T23:35:06Z | 2022-09-19T23:34:30Z | NONE | Folder structure:
File Using datasette revision d0737e4de51ce178e556fc011ccb8cc46bbb6359. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1814/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 267517348 | MDU6SXNzdWUyNjc1MTczNDg= | 9 | Initial test suite | simonw 9599 | closed | 0 | Ship first public release 2857392 | 2 | 2017-10-23T01:28:46Z | 2017-10-24T05:55:33Z | 2017-10-24T05:55:33Z | OWNER | datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/9/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 267828746 | MDU6SXNzdWUyNjc4Mjg3NDY= | 24 | Implement full URL design | simonw 9599 | closed | 0 | Ship first public release 2857392 | 2 | 2017-10-23T21:49:05Z | 2017-10-24T14:12:00Z | 2017-10-24T14:12:00Z | OWNER | Full URL design: |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/24/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 267857622 | MDU6SXNzdWUyNjc4NTc2MjI= | 25 | Endpoint that returns SQL ready to be piped into DB | simonw 9599 | closed | 0 | 2 | 2017-10-24T00:19:26Z | 2017-11-15T05:11:12Z | 2017-11-15T05:11:11Z | OWNER | It would be cool if I could figure out a way to generate both the create table statements and the inserts for an individual table or the entire database and then stream them down to the client. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/25/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 268453968 | MDU6SXNzdWUyNjg0NTM5Njg= | 37 | Ability to serialize massive JSON without blocking event loop | simonw 9599 | closed | 0 | 2 | 2017-10-25T15:58:03Z | 2020-05-30T17:29:20Z | 2020-05-30T17:29:20Z | OWNER | We run the risk of someone attempting a select statement that returns thousands of rows and hence takes several seconds just to JSON encode the response, effectively blocking the event loop and pausing all other traffic. The Twisted community have a solution for this, can we adapt that in some way? http://as.ynchrono.us/2010/06/asynchronous-json_18.html?m=1 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/37/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 272694136 | MDU6SXNzdWUyNzI2OTQxMzY= | 50 | Unit tests against application itself | simonw 9599 | closed | 0 | Ship first public release 2857392 | 2 | 2017-11-09T19:31:49Z | 2017-11-11T22:23:22Z | 2017-11-11T22:23:22Z | OWNER | Use Sanic’s testing mechanism. Test should create a temporary SQLite database file on disk by executing sql that is stored in the test themselves. For the moment we can just test the JSON API more thoroughly and just sanity check that the HTML output doesn’t throw any errors. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/50/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 273026602 | MDU6SXNzdWUyNzMwMjY2MDI= | 52 | Solution for temporarily uploading DB so it can be built by docker | simonw 9599 | closed | 0 | 2 | 2017-11-10T18:55:25Z | 2017-12-10T03:02:57Z | 2017-12-10T03:02:57Z | OWNER | For the |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/52/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 273127117 | MDU6SXNzdWUyNzMxMjcxMTc= | 55 | Ship first version to PyPI | simonw 9599 | closed | 0 | Ship first public release 2857392 | 2 | 2017-11-11T07:38:48Z | 2017-11-13T21:19:43Z | 2017-11-13T21:19:43Z | OWNER | Just before doing this, update the Dockerfile template to |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/55/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 273192789 | MDU6SXNzdWUyNzMxOTI3ODk= | 67 | Command that builds a local docker container | simonw 9599 | closed | 0 | Ship first public release 2857392 | 2 | 2017-11-12T02:13:29Z | 2017-11-13T16:17:52Z | 2017-11-13T16:17:52Z | OWNER | Be nice to indicate that this isn't just for Now. Shouldn't be too hard either. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/67/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 273296178 | MDU6SXNzdWUyNzMyOTYxNzg= | 73 | _nocache=1 query string option for use with sort-by-random | simonw 9599 | closed | 0 | 2 | 2017-11-13T02:57:10Z | 2018-05-28T17:25:15Z | 2018-05-28T17:25:15Z | OWNER | The one place where we wouldn’t want cdching is if we have something which uses sort by random to return random items. We can offer a _nocache=1 querystring argument to support this. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/73/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 273569477 | MDU6SXNzdWUyNzM1Njk0Nzc= | 80 | Deploy final versions of fivethirtyeight and parlgov datasets (with view pagination) | simonw 9599 | closed | 0 | Ship first public release 2857392 | 2 | 2017-11-13T20:37:46Z | 2017-11-13T22:09:46Z | 2017-11-13T22:09:46Z | OWNER | Final versions should be deployed using the first released version of datasette. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/80/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 274578142 | MDU6SXNzdWUyNzQ1NzgxNDI= | 110 | Add --load-extension option to datasette for loading extra SQLite extensions | simonw 9599 | closed | 0 | 2 | 2017-11-16T16:26:19Z | 2017-11-16T18:38:30Z | 2017-11-16T16:58:50Z | OWNER | This would allow users with extra SQLite extensions installed (like spatialite) to load them at runtime. Inspired by this comment: https://github.com/simonw/datasette/issues/46#issuecomment-344810525 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/110/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275135393 | MDU6SXNzdWUyNzUxMzUzOTM= | 125 | Plot rows on a map with Leaflet and Leaflet.markercluster | simonw 9599 | closed | 0 | 2 | 2017-11-19T06:05:05Z | 2018-04-26T15:14:31Z | 2018-04-26T15:14:31Z | OWNER | https://github.com/Leaflet/Leaflet.markercluster would allow us to paginate-load in an enormous set of rows with latitude/longitude points, e.g. https://australian-dunnies.now.sh/ Here's a demo of it loading 50,000 markers: https://leaflet.github.io/Leaflet.markercluster/example/marker-clustering-realworld.50000.html - and it looks like it's easy to support progress bars for if we were iteratively loading 1,000 markers at a time using datasette pagination. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/125/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275135719 | MDU6SXNzdWUyNzUxMzU3MTk= | 127 | Filtered tables should show count of all matching rows, if fast enough | simonw 9599 | closed | 0 | Foreign key edition 2919870 | 2 | 2017-11-19T06:13:29Z | 2017-11-24T22:02:01Z | 2017-11-24T22:02:01Z | OWNER | Relates to #86. If you are viewing a filtered page e.g. https://fivethirtyeight.datasettes.com/fivethirtyeight-2628db9/bob-ross%2Felements-by-episode?CLOUDS=1 we should show the count of matching rows. Since this could be an expensive operation, we will run it with a strict time limit (maybe 50ms). If the time limit is exceeded we will display "many" instead, perhaps? Maybe even link to a count(*) query that would get the full 1000ms time limit which the user can click on if they like (that could even Ajax-in the result). |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/127/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 275164558 | MDU6SXNzdWUyNzUxNjQ1NTg= | 129 | Hide FTS-created tables by default on the database index page | simonw 9599 | closed | 0 | 2 | 2017-11-19T14:50:42Z | 2017-11-22T20:22:02Z | 2017-11-22T20:19:04Z | OWNER | SQLite databases that use FTS include a number of automatically generated tables, e.g.: https://sf-trees-search.now.sh/sf-trees-search-a899b92
Of these, only the We can detect which tables are FTS tables by first finding the virtual tables: Then parsing the above to figure out which ones are USING FTS? - then assume that any table which starts with that We won't hide these completely - instead, we'll default the database index view to not showing them with a message that says "5 hidden tables" and support ?_hidden=1 to display them. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/129/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 275493851 | MDU6SXNzdWUyNzU0OTM4NTE= | 139 | Build a visualization plugin for Vega | simonw 9599 | closed | 0 | 2 | 2017-11-20T20:47:41Z | 2018-07-10T17:48:18Z | 2018-07-10T17:48:18Z | OWNER | https://vega.github.io/vega/examples/population-pyramid/ for example looks pretty easy to hook up to Datasette. Depends on #14 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/139/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 276455748 | MDU6SXNzdWUyNzY0NTU3NDg= | 146 | datasette publish gcloud | simonw 9599 | closed | 0 | 2 | 2017-11-23T18:55:03Z | 2019-06-24T06:48:20Z | 2019-06-24T06:48:20Z | OWNER | See also #103 It looks like you can start a Google Cloud VM with a "docker container" option - and the Google Cloud Registry is easy to push containers to. So it would be feasible to have https://cloud.google.com/container-registry/docs/pushing-and-pulling |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/146/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 276718605 | MDU6SXNzdWUyNzY3MTg2MDU= | 151 | Set up a pattern portfolio | simonw 9599 | closed | 0 | 2 | 2017-11-25T02:09:49Z | 2020-07-02T00:13:24Z | 2020-05-03T03:13:16Z | OWNER | https://www.slideshare.net/nataliedowne/practical-maintainable-css/75 This will be a single page that demonstrates all of the different CSS styles and classes available to Datasette. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/151/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 279547886 | MDU6SXNzdWUyNzk1NDc4ODY= | 163 | Document the querystring argument for setting a different time limit | simonw 9599 | closed | 0 | 2 | 2017-12-05T22:05:08Z | 2021-03-23T02:44:33Z | 2017-12-06T15:06:57Z | OWNER | http://datasette.readthedocs.io/en/latest/sql_queries.html#query-limits Need to explain why this is useful too. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/163/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 280014287 | MDU6SXNzdWUyODAwMTQyODc= | 165 | metadata.json support for per-database and per-table information | simonw 9599 | closed | 0 | Custom templates edition 2949431 | 2 | 2017-12-07T06:15:34Z | 2017-12-07T16:48:34Z | 2017-12-07T16:47:29Z | OWNER | Every database and every table should be able to support the following optional metadata: If |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/165/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 312312125 | MDU6SXNzdWUzMTIzMTIxMjU= | 194 | Rename table_rows and filtered_table_rows to have _count suffix | simonw 9599 | closed | 0 | 2 | 2018-04-08T14:53:37Z | 2018-04-09T05:25:22Z | 2018-04-09T05:25:22Z | OWNER | These fields represent counts of items: But the names make it sound like they might be arrays full of rows. Adding a |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/194/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 314847571 | MDU6SXNzdWUzMTQ4NDc1NzE= | 220 | Investigate syntactic sugar for plugins | simonw 9599 | closed | 0 | 2 | 2018-04-16T23:01:39Z | 2020-06-11T21:50:06Z | 2020-06-11T21:49:55Z | OWNER | Suggested by @andrewhayward on Twitter: https://twitter.com/arhayward/status/986015118965268480?s=21
``` @sql_function random_integer(a,b): return random.randint(a,b) @template_filter uppercase(str): return str.upper() ``` Maybe Would have to work out how to get this to play well with pluggy |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/220/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 315738696 | MDU6SXNzdWUzMTU3Mzg2OTY= | 226 | Unit tests for installable plugins | simonw 9599 | closed | 0 | 2 | 2018-04-19T06:05:32Z | 2020-11-24T19:52:51Z | 2020-11-24T19:52:46Z | OWNER | I'd like more thorough unit test coverage of the plugins mechanism - in particular for installable plugins. I think I can do this while still having the code live in the same repo, by creating a subdirectory in tests/example_plugin with its own setup.py and then running I imagine I will need to bump the version number every time I change the plugin in case someone runs the test again in the same virtual environment. If that doesn't work I can instead ship a datasette-plugins-tests two to PyPI and add that as a tests_require dependency. Refs #14 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/226/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 317475156 | MDU6SXNzdWUzMTc0NzUxNTY= | 237 | Support for ?_search_colname=blah searches | simonw 9599 | closed | 0 | 2 | 2018-04-25T04:29:53Z | 2018-05-05T22:56:42Z | 2018-05-05T22:33:23Z | OWNER | Right now the SQLite FTS also supports searches within a specified field, for example:
The This should also be able to support columns with spaces and special characters in their names, something like this:
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/237/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 317760361 | MDU6SXNzdWUzMTc3NjAzNjE= | 239 | Support for hidden tables in metadata.json | simonw 9599 | closed | 0 | 2 | 2018-04-25T19:21:17Z | 2018-04-26T03:45:12Z | 2018-04-26T03:43:10Z | OWNER | Since we already have a hidden feature, let's expose it more to our users |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/239/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 318737808 | MDU6SXNzdWUzMTg3Mzc4MDg= | 243 | --spatialite option for datasette publish commands | simonw 9599 | closed | 0 | 2 | 2018-04-29T18:19:32Z | 2018-05-31T14:17:53Z | 2018-05-31T14:17:53Z | OWNER | Performs the necessary incantations to install Spatialite on Zeit Now or Heroku and sets the corresponding environment variable to ensure the module is correctly loaded by datasette serve. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/243/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 319954545 | MDU6SXNzdWUzMTk5NTQ1NDU= | 248 | /-/plugins should show version of each installed plugin | simonw 9599 | closed | 0 | 2 | 2018-05-03T14:50:45Z | 2018-05-04T18:25:40Z | 2018-05-04T18:05:04Z | OWNER | Refs #244 https://stackoverflow.com/questions/20180543/how-to-check-version-of-python-modules ```
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/248/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 324451322 | MDU6SXNzdWUzMjQ0NTEzMjI= | 273 | Figure out a way to have /-/version return current git commit hash | simonw 9599 | closed | 0 | 2 | 2018-05-18T15:16:56Z | 2018-05-22T19:35:22Z | 2018-05-22T19:35:22Z | OWNER | https://fivethirtyeight.datasettes.com/-/versions reports Datasette version This isn't actually correct. The deploy script for that site actually deploys current master using Ideally this would show the current commit hash, but I'm not at all sure if it's possible to derive that from |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/273/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 324652142 | MDU6SXNzdWUzMjQ2NTIxNDI= | 274 | Rename --limit to --config, add --help-config | simonw 9599 | closed | 0 | 2 | 2018-05-19T18:57:42Z | 2018-05-20T17:04:55Z | 2018-05-20T17:04:11Z | OWNER | 270 introduced
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/274/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 326189744 | MDU6SXNzdWUzMjYxODk3NDQ= | 285 | num_threads and cache_max_age should be --config options | simonw 9599 | closed | 0 | 2 | 2018-05-24T16:04:51Z | 2018-05-27T00:53:35Z | 2018-05-27T00:43:33Z | OWNER | datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/285/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||||
| 327383759 | MDU6SXNzdWUzMjczODM3NTk= | 295 | Extract unit tests for inspect out to test_inspect.py | simonw 9599 | closed | 0 | 2 | 2018-05-29T15:55:04Z | 2019-05-11T21:40:32Z | 2019-05-11T21:40:32Z | OWNER | Right now they are bundled up as API unit tests for a relatively unimportant endpoint. They should be their own thing. Blocks #294 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/295/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 327459829 | MDU6SXNzdWUzMjc0NTk4Mjk= | 298 | URLify URLs in results from custom SQL statements / views | simonw 9599 | closed | 0 | 2 | 2018-05-29T19:41:07Z | 2018-07-24T04:53:20Z | 2018-07-24T03:56:50Z | OWNER | Consider this custom query:
It would be nice if these URLs were turned into links, as happens on the table view page: https://fivethirtyeight.datasettes.com/fivethirtyeight-5de27e3/twitter-ratio%2Fsenators
This currently does not happen because the table view render logic takes a different path through |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/298/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
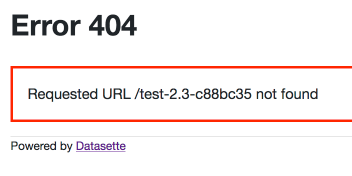
| 328171513 | MDU6SXNzdWUzMjgxNzE1MTM= | 302 | test-2.3.sqlite database filename throws a 404 | simonw 9599 | closed | 0 | 0.23.1 3439337 | 2 | 2018-05-31T14:50:58Z | 2018-06-21T15:21:17Z | 2018-06-21T15:21:16Z | OWNER | The following almost works: http://127.0.0.1:8001test-2.3-c88bc35/HighWays loads OK, but http://127.0.0.1:8001test-2.3-c88bc35 throws a 404:
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/302/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 329147284 | MDU6SXNzdWUzMjkxNDcyODQ= | 305 | Add contributor guidelines to docs | simonw 9599 | closed | 0 | 2 | 2018-06-04T17:25:30Z | 2019-06-24T06:40:19Z | 2019-06-24T06:40:19Z | OWNER | https://channels.readthedocs.io/en/latest/contributing.html is a nice example of this done well. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/305/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 331343824 | MDU6SXNzdWUzMzEzNDM4MjQ= | 309 | On 404s with a trailing slash redirect to that page without a trailing slash | simonw 9599 | closed | 0 | 0.23.1 3439337 | 2 | 2018-06-11T20:46:49Z | 2018-06-21T15:22:02Z | 2018-06-21T15:13:15Z | OWNER | datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/309/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 332998752 | MDExOlB1bGxSZXF1ZXN0MTk1MzM5MTEx | 311 | ?_labels=1 to expand foreign keys (in csv and json), refs #233 | simonw 9599 | closed | 0 | 2 | 2018-06-16T16:31:12Z | 2018-06-16T22:20:31Z | 2018-06-16T22:20:31Z | OWNER | simonw/datasette/pulls/311 | Output looks something like this: |
datasette 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/311/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 333326107 | MDU6SXNzdWUzMzMzMjYxMDc= | 317 | Travis CI fails to upload new releases to PyPI | simonw 9599 | closed | 0 | 0.23.1 3439337 | 2 | 2018-06-18T15:44:26Z | 2018-06-21T15:45:47Z | 2018-06-21T15:45:47Z | OWNER | https://travis-ci.org/simonw/datasette/jobs/393684139
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/317/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
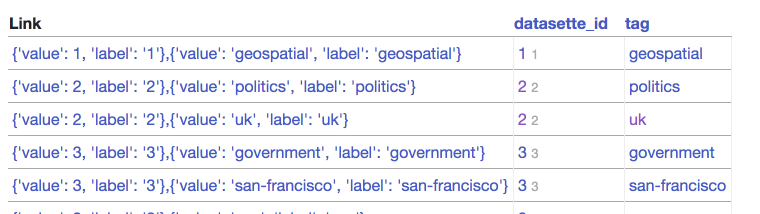
| 334149717 | MDU6SXNzdWUzMzQxNDk3MTc= | 319 | Incorrect display of compound primary keys with foreign key relationships | simonw 9599 | closed | 0 | 0.23.1 3439337 | 2 | 2018-06-20T16:09:36Z | 2018-06-21T15:58:15Z | 2018-06-21T14:56:41Z | OWNER | https://registry.datasette.io/registry-7d4f81f/datasette_tags
Underlying JSON looks like this: ``` { "database": "registry", "table": "datasette_tags", "is_view": false, "human_description_en": "", "rows": [ { "datasette_id": { "value": 1, "label": "Global Power Plant Database" }, "tag": { "value": "geospatial", "label": "geospatial" } }, ```` Bug is likely somewhere in here: https://github.com/simonw/datasette/blob/e04f5b0d348ef7275a0a5ab9eb53527105132885/datasette/views/table.py#L143-L207 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/319/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 344701755 | MDU6SXNzdWUzNDQ3MDE3NTU= | 350 | Don't list default plugins on /-/plugins | simonw 9599 | closed | 0 | 2 | 2018-07-26T05:38:00Z | 2018-08-28T17:13:50Z | 2018-08-28T16:48:19Z | OWNER | https://dbbe707.datasette.io/-/plugins is showing "datasette.publish.now" and "datasette.publish.heroku" |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/350/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 382471625 | MDExOlB1bGxSZXF1ZXN0MjMyMTcyMTA2 | 389 | Bump dependency versions | simonw 9599 | closed | 0 | 2 | 2018-11-20T02:23:12Z | 2019-11-13T19:13:41Z | 2019-11-13T19:13:41Z | OWNER | simonw/datasette/pulls/389 | datasette 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/389/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 398089089 | MDU6SXNzdWUzOTgwODkwODk= | 399 | /-/versions for official Docker image returns wrong Datasette version | simonw 9599 | closed | 0 | 2 | 2019-01-11T01:19:58Z | 2019-01-13T23:31:59Z | 2019-01-13T23:10:45Z | OWNER |
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/399/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 403617881 | MDU6SXNzdWU0MDM2MTc4ODE= | 405 | .json?_nl=on option for exporting newline-delimited JSON | simonw 9599 | closed | 0 | 2 | 2019-01-28T01:10:45Z | 2019-01-28T01:49:00Z | 2019-01-28T01:48:37Z | OWNER | The neat thing about newline-delimited JSON is that you don't have to read an entire array (of potentially thousands of objects) into memory in order to parse it - you can parse things a line at a time instead. It will look like this:
I added this as part of the It can be offered alongside |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/405/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 406055201 | MDU6SXNzdWU0MDYwNTUyMDE= | 406 | Support nullable foreign keys in _labels mode | simonw 9599 | closed | 0 | simonw 9599 | 2 | 2019-02-03T05:34:20Z | 2019-11-02T22:39:28Z | 2019-11-02T22:30:27Z | OWNER | Currently if there's a null in a foreign key we get "None" displayed in the inflated view:
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/406/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 413740684 | MDU6SXNzdWU0MTM3NDA2ODQ= | 11 | Detect numpy types when creating tables | simonw 9599 | closed | 0 | 2 | 2019-02-23T21:09:35Z | 2019-02-24T04:02:20Z | 2019-02-24T04:02:20Z | OWNER | Inspired by #8 |
sqlite-utils 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/11/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 413871266 | MDU6SXNzdWU0MTM4NzEyNjY= | 18 | .insert/.upsert/.insert_all/.upsert_all should add missing columns | simonw 9599 | closed | 0 | 1.0 4348046 | 2 | 2019-02-24T21:36:11Z | 2019-05-25T00:42:11Z | 2019-05-25T00:42:11Z | OWNER | This is a larger change, but it would be incredibly useful: if you attempt to insert or update a document with a field that does not currently exist in the underlying table, sqlite-utils should add the appropriate column for you. |
sqlite-utils 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/18/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 421985685 | MDU6SXNzdWU0MjE5ODU2ODU= | 421 | Documentation for ?_hash=1 and Datasette's hashed URL caching | simonw 9599 | closed | 0 | 0.28 4305096 | 2 | 2019-03-17T23:08:36Z | 2019-05-19T05:32:37Z | 2019-05-19T05:31:27Z | OWNER | Follow on from #418 - the Datasette documentation needs an entire section (probably a new page) describing exactly how the hash-in-URL caching mechanism works. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/421/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 430103450 | MDU6SXNzdWU0MzAxMDM0NTA= | 425 | Submitting SQL on hide page is broken | simonw 9599 | closed | 0 | 2 | 2019-04-07T04:21:31Z | 2019-04-12T05:12:13Z | 2019-04-12T05:00:53Z | OWNER | Clicking the submit button here doesn't work correctly: https://3a208a4.datasette.io/fixtures?sql=select+%2A+from+compound_three_primary_keys+order+by+pk1%2C+pk2%2C+pk3+limit+101&_hide_sql=1 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/425/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 432371762 | MDU6SXNzdWU0MzIzNzE3NjI= | 428 | Make ?_fts_table=x and ?_fts_pk=y available as URL parameters on table view | simonw 9599 | closed | 0 | 2 | 2019-04-12T03:30:55Z | 2019-04-12T04:30:29Z | 2019-04-12T04:21:25Z | OWNER | These can currently only be set using There's no reason not to support these as URL parameters as well. That way it would be easy to use FTS search against a view without having to use |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/428/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 442330564 | MDU6SXNzdWU0NDIzMzA1NjQ= | 457 | Ability to "publish cloudrun" with no user input | simonw 9599 | closed | 0 | 2 | 2019-05-09T16:42:51Z | 2019-05-09T19:41:31Z | 2019-05-09T16:45:08Z | OWNER | If you attempt to deploy a new version of a cloudrun deployment, the script currently pauses and asks for user input for the service name like this:
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/457/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 443040665 | MDU6SXNzdWU0NDMwNDA2NjU= | 466 | Move "no such module: VirtualSpatialIndex" code elsewhere | simonw 9599 | closed | 0 | 0.28 4305096 | 2 | 2019-05-11T22:09:00Z | 2022-01-20T21:29:41Z | 2019-05-11T22:57:22Z | OWNER | We currently show a useful warning (from #331) when the user tries to open a spatialite database without first loading the module: This code is part of |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/466/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 444711254 | MDU6SXNzdWU0NDQ3MTEyNTQ= | 467 | Index page row counts only for DBs with < 30 tables (10ms count limit per table) | simonw 9599 | closed | 0 | 0.28 4305096 | 2 | 2019-05-16T01:21:36Z | 2019-05-16T03:03:45Z | 2019-05-16T03:03:45Z | OWNER | Split out from #460. If a database is mutable, calculating row counts gets expensive. I'm only going to calculate row counts for the index page if it has less than X tables (both hidden and non-hidden) AND each table can be counted in less than 10ms. If any count takes longer than 10ms I'll cancel the counting entirely. We currently show an inaccurate count if this happens, which is just confusing. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/467/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 448395665 | MDU6SXNzdWU0NDgzOTU2NjU= | 22 | Release notes for 1.0 | simonw 9599 | closed | 0 | 1.0 4348046 | 2 | 2019-05-25T00:58:03Z | 2019-05-25T01:18:27Z | 2019-05-25T01:06:52Z | OWNER | sqlite-utils 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/22/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 459714943 | MDU6SXNzdWU0NTk3MTQ5NDM= | 525 | Add section on sqite-utils enable-fts to the search documentation | simonw 9599 | closed | 0 | simonw 9599 | 2 | 2019-06-24T06:39:16Z | 2019-06-24T16:36:35Z | 2019-06-24T16:29:43Z | OWNER | https://datasette.readthedocs.io/en/stable/full_text_search.html already has a section about csvs-to-sqlite, sqlite-utils is even more relevant. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/525/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 462423839 | MDU6SXNzdWU0NjI0MjM4Mzk= | 33 | index_foreign_keys / index-foreign-keys utilities | simonw 9599 | closed | 0 | 2 | 2019-06-30T16:42:03Z | 2019-06-30T23:54:11Z | 2019-06-30T23:50:55Z | OWNER | Sometimes it's good to have indices on all columns that are foreign keys, to allow for efficient reverse lookups. This would be a useful utility: |
sqlite-utils 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/33/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 462430920 | MDU6SXNzdWU0NjI0MzA5MjA= | 35 | table.update(...) method | simonw 9599 | closed | 0 | 2 | 2019-06-30T18:06:15Z | 2019-07-28T15:43:52Z | 2019-07-28T15:43:52Z | OWNER | Spun off from #23 - this method will allow a user to update a specific row. Currently the only way to do that it is to call If the primary key is compound the first argument can be a tuple:
|
sqlite-utils 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/35/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 464040911 | MDExOlB1bGxSZXF1ZXN0Mjk0NDAwNDQ2 | 539 | Secret plugin configuration options | simonw 9599 | closed | 0 | 2 | 2019-07-04T03:21:20Z | 2019-07-04T05:36:45Z | 2019-07-04T05:36:45Z | OWNER | simonw/datasette/pulls/539 | Refs #538 |
datasette 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/539/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 464779810 | MDU6SXNzdWU0NjQ3Nzk4MTA= | 541 | Plugin hook for adding extra template context variables | simonw 9599 | closed | 0 | 2 | 2019-07-05T21:37:05Z | 2019-07-06T00:05:59Z | 2019-07-06T00:05:59Z | OWNER | It turns out I need this for https://github.com/simonw/datasette-auth-github/issues/5 It can be modelled on the |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/541/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 464990184 | MDU6SXNzdWU0NjQ5OTAxODQ= | 547 | Release notes for 0.29 | simonw 9599 | closed | 0 | Datasette 0.29 4471010 | 2 | 2019-07-07T20:30:28Z | 2019-07-08T03:31:59Z | 2019-07-08T03:31:59Z | OWNER | There's a lot of stuff... https://github.com/simonw/datasette/compare/0.28...master |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/547/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 467862459 | MDExOlB1bGxSZXF1ZXN0Mjk3NDEyNDY0 | 38 | table.update() method | simonw 9599 | closed | 0 | 2 | 2019-07-14T17:03:49Z | 2019-07-28T15:43:51Z | 2019-07-28T15:43:51Z | OWNER | simonw/sqlite-utils/pulls/38 | Refs #35 Still to do:
|
sqlite-utils 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/38/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 470542938 | MDU6SXNzdWU0NzA1NDI5Mzg= | 562 | Facet by array shouldn't suggest for arrays that are not arrays-of-strings | simonw 9599 | closed | 0 | 2 | 2019-07-19T20:51:29Z | 2019-11-01T19:42:10Z | 2019-11-01T19:37:55Z | OWNER | It's triggering for arrays that look like this at the moment:
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/562/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 470691622 | MDU6SXNzdWU0NzA2OTE2MjI= | 5 | Add progress bar | simonw 9599 | closed | 0 | 2 | 2019-07-20T16:29:07Z | 2019-07-22T03:30:13Z | 2019-07-22T02:49:22Z | MEMBER | Showing a progress bar would be nice, using Click. The easiest way to do this would probably be be to hook it up to the length of the compressed content, and update it as this code pushes more XML bytes through the parser: |
healthkit-to-sqlite 197882382 | issue | {
"url": "https://api.github.com/repos/dogsheep/healthkit-to-sqlite/issues/5/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 471628483 | MDU6SXNzdWU0NzE2Mjg0ODM= | 44 | Utilities for building lookup tables | simonw 9599 | closed | 0 | 2 | 2019-07-23T10:59:58Z | 2019-07-23T13:07:01Z | 2019-07-23T13:07:01Z | OWNER | While building https://github.com/dogsheep/healthkit-to-sqlite I found a need for a neat mechanism for easily building lookup tables - tables where each unique value in a column is replaced by a foreign key to a separate table. csvs-to-sqlite currently creates those with its "extract" mechanism - but that's written as custom code against Pandas. I'd like to eventually replace Pandas with sqlite-utils there. See also #42 |
sqlite-utils 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/44/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 471818939 | MDU6SXNzdWU0NzE4MTg5Mzk= | 48 | Jupyter notebook demo of the library, launchable on Binder | simonw 9599 | closed | 0 | 2 | 2019-07-23T17:05:05Z | 2022-01-26T02:08:46Z | 2022-01-26T02:08:39Z | OWNER | sqlite-utils 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/48/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||||
| 488835586 | MDU6SXNzdWU0ODg4MzU1ODY= | 4 | Command for importing data from a Twitter Export file | simonw 9599 | closed | 0 | 2 | 2019-09-03T21:34:13Z | 2019-10-11T06:45:02Z | 2019-10-11T06:45:02Z | MEMBER | Twitter lets you export all of your data as an archive file: https://twitter.com/settings/your_twitter_data A command for importing this data into SQLite would be extremely useful. |
twitter-to-sqlite 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/4/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 493670426 | MDU6SXNzdWU0OTM2NzA0MjY= | 3 | Command to fetch all repos belonging to a user or organization | simonw 9599 | closed | 0 | 2 | 2019-09-14T21:54:21Z | 2019-09-17T00:17:53Z | 2019-09-17T00:17:53Z | MEMBER | How about this: |
github-to-sqlite 207052882 | issue | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/3/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 493671014 | MDU6SXNzdWU0OTM2NzEwMTQ= | 5 | Add "incomplete" boolean to users table for incomplete profiles | simonw 9599 | closed | 0 | 2 | 2019-09-14T22:01:50Z | 2020-03-23T19:23:31Z | 2020-03-23T19:23:30Z | MEMBER | User profiles that are fetched from e.g. stargazers (#4) are incomplete - they have a login but they don't have name, company etc. Add a |
github-to-sqlite 207052882 | issue | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/5/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 503190241 | MDU6SXNzdWU1MDMxOTAyNDE= | 584 | Codec error in some CSV exports | simonw 9599 | closed | 0 | 2 | 2019-10-07T01:15:34Z | 2021-06-17T18:13:20Z | 2019-10-18T05:23:16Z | OWNER | Got this exploring my Swarm checkins:
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/584/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 503218205 | MDU6SXNzdWU1MDMyMTgyMDU= | 586 | Enable browser caching for plugin statics with datasette-auth | simonw 9599 | closed | 0 | 2 | 2019-10-07T03:47:14Z | 2019-10-07T15:46:04Z | 2019-10-07T15:46:03Z | OWNER | An authenticated Datasette I run is seeing delays on every page load. On looking at the network inspector it turns out it's because datasette-vega is nearly 1MB and a
This may well turn out to be a bug in |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/586/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 505674949 | MDU6SXNzdWU1MDU2NzQ5NDk= | 17 | import command should empty all archive-* tables first | simonw 9599 | closed | 0 | 2 | 2019-10-11T06:58:43Z | 2019-10-11T15:40:08Z | 2019-10-11T15:40:08Z | MEMBER | Can have a CLI option for NOT doing that. |
twitter-to-sqlite 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/17/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 508190730 | MDU6SXNzdWU1MDgxOTA3MzA= | 23 | Extremely simple migration system | simonw 9599 | closed | 0 | 2 | 2019-10-17T02:13:57Z | 2019-10-17T16:57:17Z | 2019-10-17T16:57:17Z | MEMBER | Needed for #12. This is going to be an incredibly simple version of the Django migration system.
The function names will be detected and used as the names of the migrations. Every time you run the CLI tool it will call the Needs to take into account that there might be no tables at all. As such, migration functions should sanity check that the tables they are going to work on actually exist. |
twitter-to-sqlite 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/23/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 508578780 | MDU6SXNzdWU1MDg1Nzg3ODA= | 25 | Ensure migrations don't accidentally create foreign key twice | simonw 9599 | closed | 0 | 2 | 2019-10-17T16:08:50Z | 2019-10-17T16:56:47Z | 2019-10-17T16:56:47Z | MEMBER | Is it possible for these lines to run against a database table that already has these foreign keys? |
twitter-to-sqlite 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/25/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 516748849 | MDU6SXNzdWU1MTY3NDg4NDk= | 612 | CSV export is broken for tables with null foreign keys | simonw 9599 | closed | 0 | 2 | 2019-11-02T22:52:47Z | 2021-06-17T18:13:20Z | 2019-11-02T23:12:53Z | OWNER | Following on from #406 - this CSV export appears to be broken: https://14da705.datasette.io/fixtures/foreign_key_references.csv?_labels=on&_size=max
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/612/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 520507306 | MDU6SXNzdWU1MjA1MDczMDY= | 618 | Mechanism for seeing indexes on a specific table | simonw 9599 | closed | 0 | 2 | 2019-11-09T20:10:41Z | 2019-11-10T01:40:05Z | 2019-11-10T01:30:25Z | OWNER | The only way to see the indexes that apply to a specific table at the moment is to run the following SQL manually:
It would be good if this list of indexes was displayed in a neater way on the table page. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/618/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 520508502 | MDU6SXNzdWU1MjA1MDg1MDI= | 31 | "friends" command (similar to "followers") | simonw 9599 | closed | 0 | 2 | 2019-11-09T20:20:20Z | 2022-09-20T05:05:03Z | 2020-02-07T07:03:28Z | MEMBER | Current list of commands:
|
twitter-to-sqlite 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/31/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 520718056 | MDExOlB1bGxSZXF1ZXN0MzM5MjM2NjQ3 | 623 | Test against Python 3.8 in Travis | simonw 9599 | closed | 0 | 2 | 2019-11-11T03:24:54Z | 2019-11-11T03:45:35Z | 2019-11-11T03:45:35Z | OWNER | simonw/datasette/pulls/623 | Needed for #622 |
datasette 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/623/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 521323012 | MDExOlB1bGxSZXF1ZXN0MzM5NzIyNzkw | 627 | Support Python 3.8, stop supporting Python 3.5 | simonw 9599 | closed | 0 | 2 | 2019-11-12T04:36:33Z | 2020-04-05T10:23:58Z | 2019-11-12T05:09:12Z | OWNER | simonw/datasette/pulls/627 | Refs #622 |
datasette 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/627/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | |||||
| 521329771 | MDU6SXNzdWU1MjEzMjk3NzE= | 628 | Render jinja2 templates in async mode | simonw 9599 | closed | 0 | 2 | 2019-11-12T05:01:55Z | 2019-11-14T23:28:09Z | 2019-11-14T23:14:24Z | OWNER | I started playing with this in #404 and got good results but it didn't work in Python 3.5. As of #627 I don't support 3.5 any more so this can go ahead. Rendering templates in async mode will mean that template plugins can include async code... which opens the door to custom template functions that execute SQL queries! |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/628/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 521995039 | MDU6SXNzdWU1MjE5OTUwMzk= | 632 | Upgrade datasette publish Heroku runtime | simonw 9599 | closed | 0 | 2 | 2019-11-13T06:46:19Z | 2019-11-13T16:44:07Z | 2019-11-13T16:43:23Z | OWNER |
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/632/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 522352520 | MDU6SXNzdWU1MjIzNTI1MjA= | 634 | Don't run tests twice when releasing a tag | simonw 9599 | closed | 0 | 2 | 2019-11-13T17:02:42Z | 2020-09-15T20:37:58Z | 2020-09-15T20:37:58Z | OWNER | Shipping a release currently runs the tests twice: https://travis-ci.org/simonw/datasette/builds/611463728 It does a regular test run on Python 3.6/7/8 - then the "Release tagged version" step runs the tests again before publishing to PyPI! This second run is not necessary. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/634/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 529376481 | MDExOlB1bGxSZXF1ZXN0MzQ2MjY0OTI2 | 67 | Run tests against 3.5 too | simonw 9599 | closed | 0 | 2 | 2019-11-27T14:20:35Z | 2019-12-31T01:29:44Z | 2019-12-31T01:29:43Z | OWNER | simonw/sqlite-utils/pulls/67 | sqlite-utils 140912432 | pull | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/67/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||||
| 534530973 | MDU6SXNzdWU1MzQ1MzA5NzM= | 649 | Reduce table counts on index page with many databases | simonw 9599 | closed | 0 | 2 | 2019-12-08T11:56:37Z | 2020-02-29T01:08:29Z | 2020-02-29T01:08:29Z | OWNER | Since #467 the index page has attempted to optimistically count times. My personal Dogsheep has enough connected databases and tables that the page can still take way too long to load - sometimes more than twenty seconds. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/649/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 557825032 | MDU6SXNzdWU1NTc4MjUwMzI= | 77 | Ability to insert data that is transformed by a SQL function | simonw 9599 | closed | 0 | 2 | 2020-01-30T23:45:55Z | 2022-02-05T00:04:25Z | 2020-01-31T00:24:32Z | OWNER | I want to be able to run the equivalent of this SQL insert: ```python Convert to "Well Known Text" formatwkt = shape(geojson['geometry']).wkt Insert and commit the recordconn.execute("INSERT INTO places (id, name, geom) VALUES(null, ?, GeomFromText(?, 4326))", ( "Wales", wkt )) conn.commit() ``` From the Datasette SpatiaLite docs: https://datasette.readthedocs.io/en/stable/spatialite.html To do this, I need a way of telling |
sqlite-utils 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/77/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 563347679 | MDU6SXNzdWU1NjMzNDc2Nzk= | 668 | Make it easier to load SpatiaLite | simonw 9599 | closed | 0 | 2 | 2020-02-11T17:03:43Z | 2022-01-20T21:29:41Z | 2021-01-04T20:18:39Z | OWNER | ``` $ datasette spatial.db Serve! files=('spatial.db',) (immutables=()) on port 8001 ERROR: conn=<sqlite3.Connection object at 0x11e388f10>, sql = 'PRAGMA table_info(SpatialIndex);', params = None: no such module: VirtualSpatialIndex Usage: datasette serve [OPTIONS] [FILES]... Error: It looks like you're trying to load a SpatiaLite database without first loading the SpatiaLite module. Read more: https://datasette.readthedocs.io/en/latest/spatialite.html
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/668/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 565837965 | MDU6SXNzdWU1NjU4Mzc5NjU= | 87 | Should detect collections.OrderedDict as a regular dictionary | simonw 9599 | closed | 0 | 2 | 2020-02-16T02:06:34Z | 2020-02-16T02:20:59Z | 2020-02-16T02:20:59Z | OWNER |
|
sqlite-utils 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/87/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 569268612 | MDU6SXNzdWU1NjkyNjg2MTI= | 679 | Release 0.36 | simonw 9599 | closed | 0 | 2 | 2020-02-22T02:41:01Z | 2020-02-22T03:52:13Z | 2020-02-22T03:52:13Z | OWNER | I think we have enough changes to warrant a release - and I want to take advantage of the changes to the Changes since 0.35 so far: https://github.com/simonw/datasette/compare/0.35...be2265b0e811d0ac2875c2f748125c17b0f9289e
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/679/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 576722115 | MDU6SXNzdWU1NzY3MjIxMTU= | 696 | Single failing unit test when run inside the Docker image | simonw 9599 | closed | 0 | Datasette 1.0 3268330 | 2 | 2020-03-06T06:16:36Z | 2021-03-29T17:04:19Z | 2021-03-07T07:41:18Z | OWNER |
It was for
Originally posted by @simonw in https://github.com/simonw/datasette/issues/695#issuecomment-595614469 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/696/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 578883725 | MDU6SXNzdWU1Nzg4ODM3MjU= | 17 | Command for importing commits | simonw 9599 | closed | 0 | 2 | 2020-03-10T21:55:12Z | 2020-03-11T02:47:37Z | 2020-03-11T02:47:37Z | MEMBER | Using this API: https://api.github.com/repos/dogsheep/github-to-sqlite/commits |
github-to-sqlite 207052882 | issue | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/17/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 585266763 | MDU6SXNzdWU1ODUyNjY3NjM= | 34 | IndexError running user-timeline command | simonw 9599 | closed | 0 | 2 | 2020-03-20T18:54:08Z | 2020-03-20T19:20:52Z | 2020-03-20T19:20:37Z | MEMBER |
|
twitter-to-sqlite 206156866 | issue | {
"url": "https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/34/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 585850715 | MDU6SXNzdWU1ODU4NTA3MTU= | 19 | Enable full-text search for more stuff (like commits, issues and issue_comments) | simonw 9599 | closed | 0 | 1.0 5225818 | 2 | 2020-03-23T00:19:56Z | 2020-03-23T19:06:39Z | 2020-03-23T19:06:39Z | MEMBER | Currently FTS is only enabled for repos and releases. |
github-to-sqlite 207052882 | issue | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/19/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 586561727 | MDU6SXNzdWU1ODY1NjE3Mjc= | 21 | Turn GitHub API errors into exceptions | simonw 9599 | closed | 0 | 1.0 5225818 | 2 | 2020-03-23T22:37:24Z | 2020-03-23T23:48:23Z | 2020-03-23T23:48:22Z | MEMBER | This would have really helped in debugging the mess in #13. Running with this |
github-to-sqlite 207052882 | issue | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/21/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 587302139 | MDExOlB1bGxSZXF1ZXN0MzkzMjc0NDMz | 708 | base_url configuration setting, refs #394 | simonw 9599 | closed | 0 | Datasette 0.39 5234079 | 2 | 2020-03-24T21:52:00Z | 2020-03-25T00:18:44Z | 2020-03-25T00:18:44Z | OWNER | simonw/datasette/pulls/708 | Pull request implementing #394 |
datasette 107914493 | pull | {
"url": "https://api.github.com/repos/simonw/datasette/issues/708/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
0 | ||||
| 587322443 | MDU6SXNzdWU1ODczMjI0NDM= | 710 | Remove Zeit Now v1 support | simonw 9599 | closed | 0 | 2 | 2020-03-24T22:39:49Z | 2020-04-04T23:05:12Z | 2020-04-04T23:05:12Z | OWNER | It will remain supported as a plugin but since no-one can sign up for Docker hosting any more (for over a year now) there's no point including it in Datasette core. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/710/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 587398703 | MDU6SXNzdWU1ODczOTg3MDM= | 711 | Release notes for Datasette 0.39 | simonw 9599 | closed | 0 | Datasette 0.39 5234079 | 2 | 2020-03-25T02:31:13Z | 2020-03-25T04:06:55Z | 2020-03-25T04:06:55Z | OWNER | Then I can ship it. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/711/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | |||||
| 598640234 | MDU6SXNzdWU1OTg2NDAyMzQ= | 99 | .upsert_all() should maybe error if dictionaries passed to it do not have the same keys | simonw 9599 | closed | 0 | 2 | 2020-04-13T03:02:25Z | 2020-04-13T03:05:20Z | 2020-04-13T03:05:04Z | OWNER | While investigating #98 I stumbled across this: ``` def test_upsert_compound_primary_key(fresh_db): table = fresh_db["table"] table.upsert_all( [ {"species": "dog", "id": 1, "name": "Cleo", "age": 4}, {"species": "cat", "id": 1, "name": "Catbag"}, ], pk=("species", "id"), ) table.upsert_all( [ {"species": "dog", "id": 1, "age": 5}, {"species": "dog", "id": 2, "name": "New Dog", "age": 1}, ], pk=("species", "id"), )
|
sqlite-utils 140912432 | issue | {
"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/99/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 601271612 | MDU6SXNzdWU2MDEyNzE2MTI= | 26 | Topics are missing from repositories | simonw 9599 | closed | 0 | 2 | 2020-04-16T17:36:32Z | 2020-04-16T17:41:11Z | 2020-04-16T17:41:11Z | MEMBER | I'm sure this used to work, but right now repositories are fetched without their topics. https://developer.github.com/v3/repos/ says you need to send a custom |
github-to-sqlite 207052882 | issue | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/26/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 602575575 | MDU6SXNzdWU2MDI1NzU1NzU= | 6 | Add progress bar to upload command | simonw 9599 | closed | 0 | 2 | 2020-04-18T23:32:41Z | 2020-04-19T00:15:24Z | 2020-04-19T00:15:24Z | MEMBER | Upload was added in #4 |
dogsheep-photos 256834907 | issue | {
"url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/6/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | ||||||
| 603618244 | MDU6SXNzdWU2MDM2MTgyNDQ= | 30 | Issues milestone column is the wrong type | simonw 9599 | closed | 0 | 2 | 2020-04-21T00:24:34Z | 2020-04-21T00:45:23Z | 2020-04-21T00:36:22Z | MEMBER | https://github-to-sqlite.dogsheep.net/github/issues?milestone=2857392
It is TEXT when it should be an INTEGER - which is why the foreign key label is not correctly displayed. |
github-to-sqlite 207052882 | issue | {
"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/30/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed |







Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issues] (
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[number] INTEGER,
[title] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[state] TEXT,
[locked] INTEGER,
[assignee] INTEGER REFERENCES [users]([id]),
[milestone] INTEGER REFERENCES [milestones]([id]),
[comments] INTEGER,
[created_at] TEXT,
[updated_at] TEXT,
[closed_at] TEXT,
[author_association] TEXT,
[pull_request] TEXT,
[body] TEXT,
[repo] INTEGER REFERENCES [repos]([id]),
[type] TEXT
, [active_lock_reason] TEXT, [performed_via_github_app] TEXT, [reactions] TEXT, [draft] INTEGER, [state_reason] TEXT);
CREATE INDEX [idx_issues_repo]
ON [issues] ([repo]);
CREATE INDEX [idx_issues_milestone]
ON [issues] ([milestone]);
CREATE INDEX [idx_issues_assignee]
ON [issues] ([assignee]);
CREATE INDEX [idx_issues_user]
ON [issues] ([user]);
comments 1 ✖