issues
784 rows where state = "open" sorted by node_id
This data as json, CSV (advanced)
Suggested facets: milestone, comments, author_association, draft, updated_at (date)
created_at (date) >30 ✖
- 2022-02-02 5
- 2022-12-28 5
- 2023-03-09 5
- 2020-09-17 4
- 2020-12-29 4
- 2021-01-05 4
- 2021-02-08 4
- 2022-02-24 4
- 2022-03-20 4
- 2022-04-11 4
- 2022-09-06 4
- 2023-08-24 4
- 2019-05-23 3
- 2020-05-05 3
- 2020-05-28 3
- 2020-08-28 3
- 2020-09-30 3
- 2020-10-09 3
- 2020-10-11 3
- 2020-12-17 3
- 2021-01-06 3
- 2021-01-15 3
- 2021-02-18 3
- 2021-04-02 3
- 2021-04-12 3
- 2021-08-13 3
- 2021-09-05 3
- 2021-11-15 3
- 2021-12-11 3
- 2022-03-25 3
- …
repo 16
- datasette 555
- sqlite-utils 89
- github-to-sqlite 23
- dogsheep-photos 21
- twitter-to-sqlite 20
- dogsheep-beta 15
- google-takeout-to-sqlite 13
- healthkit-to-sqlite 12
- apple-notes-to-sqlite 8
- evernote-to-sqlite 6
- pocket-to-sqlite 5
- hacker-news-to-sqlite 5
- swarm-to-sqlite 4
- dogsheep.github.io 4
- inaturalist-to-sqlite 2
- genome-to-sqlite 2
state 1
- open · 784 ✖
| id | node_id ▼ | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at | closed_at | author_association | pull_request | body | repo | type | active_lock_reason | performed_via_github_app | reactions | draft | state_reason |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1054244712 | I_kwDOBm6k_c4-1n9o | 1510 | Datasette 1.0 documented template context (maybe via API docs) | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 3 | 2021-11-15T23:23:58Z | 2023-06-28T02:05:21Z | OWNER | Documented context plus protective unit tests. Goal is that custom templates built for 1.x will not break without a 2.x release. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1510/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1054243511 | I_kwDOBm6k_c4-1nq3 | 1509 | Datasette 1.0 JSON API (and documentation) | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 3 | 2021-11-15T23:22:45Z | 2022-03-15T20:38:56Z | OWNER | The new JSON API in a stable, documented form. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1509/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1054246919 | I_kwDOBm6k_c4-1ogH | 1511 | Review plugin hooks for Datasette 1.0 | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 1 | 2021-11-15T23:26:05Z | 2021-11-16T01:20:14Z | OWNER | I need to perform a detailed review of the plugin interface - especially the plugin hooks like register_facet_classes() which I don't yet have complete confidence in. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1511/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1056746091 | I_kwDOBm6k_c4-_Kpr | 1515 | Handle foreign keys that point to a non-existent table | simonw 9599 | open | 0 | 0 | 2021-11-17T23:40:13Z | 2021-11-18T01:31:56Z | OWNER | Spotted in https://github.com/simonw/datasette-graphql/issues/79 Demo: https://datasette-graphql-demo.datasette.io/fixtures/bad_foreign_key The foreign key links to a 404 page.
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1515/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1049946823 | I_kwDOBm6k_c4-lOrH | 1502 | Full-text search: No support to unary "-" operator | gustavorps 516827 | open | 0 | 0 | 2021-11-10T15:11:19Z | 2021-11-10T15:11:19Z | NONE | datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1502/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||||
| 1051277222 | I_kwDOBm6k_c4-qTem | 1504 | Link to ?_size=max at bottom of table page | simonw 9599 | open | 0 | 0 | 2021-11-11T19:06:33Z | 2021-11-11T19:06:33Z | OWNER | This can have text such as "Show 1,000 rows per page", based on the max size limit setting. Would make it easier for people to see more data at once without having to know how to hack the URL, similar to the |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1504/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1052247023 | I_kwDOBm6k_c4-uAPv | 1505 | Datasette should have an option to output CSV with semicolons | simonw 9599 | open | 0 | 1 | 2021-11-12T18:02:21Z | 2021-11-16T11:40:52Z | OWNER | datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1505/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||||
| 1006016302 | I_kwDOBm6k_c479pcu | 1477 | Consider adding request to the documented default template context | simonw 9599 | open | 0 | 0 | 2021-09-24T02:34:09Z | 2021-09-24T02:34:09Z | OWNER | I made a plugin for this today but I think perhaps it should be a default thing instead: https://datasette.io/plugins/datasette-template-request |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1477/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 999902754 | I_kwDOBm6k_c47mU4i | 1473 | base logo link visits `undefined` rather than href url | mroswell 192568 | open | 0 | 2 | 2021-09-18T04:17:04Z | 2021-09-19T00:45:32Z | CONTRIBUTOR | I have two connected sites: http://www.SaferOrToxic.org (a Hugo website) and: http://disinfectants.SaferOrToxic.org/disinfectants/listN (a datasette table page) The latter is linked as "The List" in the former's menu. (I'd love a prettier URL, but that's what I've got.) On: http://disinfectants.SaferOrToxic.org/disinfectants/listN ... all the other menu links should point back to: https://www.SaferOrToxic.org And they do! But the logo, for some reason--though it has an href pointing to: https://www.SaferOrToxic.org Keeps going to this instead: https://disinfectants.saferortoxic.org/disinfectants/undefined What is causing that? How can I fix it? In #1284 back in March, I was doing battle with the index.html template, in a still unresolved issue. (I wanted only a single table page at the root.) But I thought, well, if I can't resolve that, at least I could just point the main website to the datasette page ("The List,") and then have the List point back to the home website. The menu hrefs to https://www.SaferOrToxic.org work just fine, exactly as they should, from the datasette page. Even the Home link works properly. But the logo link keeps rewriting to: https://disinfectants.saferortoxic.org/disinfectants/undefined This is the HTML:
Is this somehow related to cloudflare? Or something in the datasette code? I'm starting to think it's a cloudflare issue.
Can I at least rule out it being a datasette issue? My repository is here: https://github.com/mroswell/list-N (BTW, I couldn't figure out how to reference a local image, either, on the datasette side, which is why I'm using the image from the www home page.) |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1473/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1006781949 | I_kwDOBm6k_c48AkX9 | 1478 | Documentation Request: Feature alternative ID instead of default ID | mroswell 192568 | open | 0 | 0 | 2021-09-24T19:56:13Z | 2021-09-25T16:18:54Z | CONTRIBUTOR | My data already has an ID that comes from a federal agency. Would love to have documentation on how to modify the template to: - Remove the generated ID from the table - Link the federal ID to the detail page - and to ensure that the JSON file uses that as the ID. I'd be happy to include the database ID in the export, but not as a key. I don't want to remove the ID from the database, though, because my experience with the federal agency is that data often has anomalies. I don't want all hell to break loose if they end up applying the same ID to multiple rows (which they haven't done yet). I just don't want it to display in the table or the data exports. Perhaps this isn't a template issue, maybe more of a db manipulation... Margie |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1478/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1010112818 | I_kwDOBm6k_c48NRky | 1479 | Win32 "used by another process" error with datasette publish | kirajano 76450761 | open | 0 | 7 | 2021-09-28T19:12:00Z | 2023-09-07T02:14:16Z | NONE | I unfortunately was not successful to deploy to fly.io. Please see the details above of the three scenarios that I took. I am also new to datasette. Failed to deploy. Attaching logs:
1. Tried with an app created via Error error connecting to docker: An unknown error occured. Traceback (most recent call last): File "c:\users\grott\anaconda3\lib\runpy.py", line 193, in _run_module_as_main "main", mod_spec) File "c:\users\grott\anaconda3\lib\runpy.py", line 85, in _run_code exec(code, run_globals) File "C:\Users\grott\Anaconda3\Scripts\datasette.exe__main__.py", line 7, in <module> File "c:\users\grott\anaconda3\lib\site-packages\click\core.py", line 829, in call return self.main(args, kwargs) File "c:\users\grott\anaconda3\lib\site-packages\click\core.py", line 782, in main rv = self.invoke(ctx) File "c:\users\grott\anaconda3\lib\site-packages\click\core.py", line 1259, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "c:\users\grott\anaconda3\lib\site-packages\click\core.py", line 1259, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "c:\users\grott\anaconda3\lib\site-packages\click\core.py", line 1066, in invoke return ctx.invoke(self.callback, ctx.params) File "c:\users\grott\anaconda3\lib\site-packages\click\core.py", line 610, in invoke return callback(args, **kwargs) File "c:\users\grott\anaconda3\lib\site-packages\datasette_publish_fly__init__.py", line 156, in fly "--remote-only", File "c:\users\grott\anaconda3\lib\contextlib.py", line 119, in exit next(self.gen) File "c:\users\grott\anaconda3\lib\site-packages\datasette\utils__init__.py", line 451, in temporary_docker_directory tmp.cleanup() File "c:\users\grott\anaconda3\lib\tempfile.py", line 811, in cleanup _shutil.rmtree(self.name) File "c:\users\grott\anaconda3\lib\shutil.py", line 516, in rmtree return _rmtree_unsafe(path, onerror) File "c:\users\grott\anaconda3\lib\shutil.py", line 395, in _rmtree_unsafe _rmtree_unsafe(fullname, onerror) File "c:\users\grott\anaconda3\lib\shutil.py", line 404, in _rmtree_unsafe onerror(os.rmdir, path, sys.exc_info()) File "c:\users\grott\anaconda3\lib\shutil.py", line 402, in _rmtree_unsafe os.rmdir(path) PermissionError: [WinError 32] The process cannot access the file because it is being used by another process: 'C:\Users\grott\AppData\Local\Temp\tmpgcm8cz66\frosty-fog-8565' ```
Error not possible to validate configuration: server returned Post "https://api.fly.io/graphql": unexpected EOF Traceback (most recent call last):
File "c:\users\grott\anaconda3\lib\runpy.py", line 193, in _run_module_as_main These are also the contents of the generated .toml file in 2 scenario: ``` fly.toml file generated for dark-feather-168 on 2021-09-28T20:35:44+02:00app = "dark-feather-168" kill_signal = "SIGINT" kill_timeout = 5 processes = [] [env] [experimental] allowed_public_ports = [] auto_rollback = true [[services]] http_checks = [] internal_port = 8080 processes = ["app"] protocol = "tcp" script_checks = [] [services.concurrency] hard_limit = 25 soft_limit = 20 type = "connections" [[services.ports]] handlers = ["http"] port = 80 [[services.ports]] handlers = ["tls", "http"] port = 443 [[services.tcp_checks]] grace_period = "1s" interval = "15s" restart_limit = 6 timeout = "2s" ```
```[+] Building 147.3s (11/11) FINISHED => [internal] load build definition from Dockerfile 0.2s => => transferring dockerfile: 396B 0.0s => [internal] load .dockerignore 0.1s => => transferring context: 2B 0.0s => [internal] load metadata for docker.io/library/python:3.8 4.7s => [auth] library/python:pull token for registry-1.docker.io 0.0s => [internal] load build context 0.1s => => transferring context: 82.37kB 0.0s => [1/5] FROM docker.io/library/python:3.8@sha256:530de807b46a11734e2587a784573c12c5034f2f14025f838589e6c0e3 108.3s => => resolve docker.io/library/python:3.8@sha256:530de807b46a11734e2587a784573c12c5034f2f14025f838589e6c0e3b5 0.0s => => sha256:56182bcdf4d4283aa1f46944b4ef7ac881e28b4d5526720a4e9ba03a4730846a 2.22kB / 2.22kB 0.0s => => sha256:955615a668ce169f8a1443fc6b6e6215f43fe0babfb4790712a2d3171f34d366 54.93MB / 54.93MB 21.6s => => sha256:911ea9f2bd51e53a455297e0631e18a72a86d7e2c8e1807176e80f991bde5d64 10.87MB / 10.87MB 15.5s => => sha256:530de807b46a11734e2587a784573c12c5034f2f14025f838589e6c0e3b5c5b6 1.86kB / 1.86kB 0.0s => => sha256:ff08f08727e50193dcf499afc30594c47e70cc96f6fcfd1a01240524624264d0 8.65kB / 8.65kB 0.0s => => sha256:2756ef5f69a5190f4308619e0f446d95f5515eef4a814dbad0bcebbbbc7b25a8 5.15MB / 5.15MB 6.4s => => sha256:27b0a22ee906271a6ce9ddd1754fdd7d3b59078e0b57b6cc054c7ed7ac301587 54.57MB / 54.57MB 37.7s => => sha256:8584d51a9262f9a3a436dea09ba40fa50f85802018f9bd299eee1bf538481077 196.45MB / 196.45MB 82.3s => => sha256:524774b7d3638702fe9ae0ea3fcfb81b027dfd75cc2fc14f0119e764b9543d58 6.29MB / 6.29MB 26.6s => => extracting sha256:955615a668ce169f8a1443fc6b6e6215f43fe0babfb4790712a2d3171f34d366 5.4s => => sha256:9460f6b75036e38367e2f27bb15e85777c5d6cd52ad168741c9566186415aa26 16.81MB / 16.81MB 40.5s => => extracting sha256:2756ef5f69a5190f4308619e0f446d95f5515eef4a814dbad0bcebbbbc7b25a8 0.6s => => extracting sha256:911ea9f2bd51e53a455297e0631e18a72a86d7e2c8e1807176e80f991bde5d64 0.6s => => sha256:9bc548096c181514aa1253966a330134d939496027f92f57ab376cd236eb280b 232B / 232B 40.1s => => extracting sha256:27b0a22ee906271a6ce9ddd1754fdd7d3b59078e0b57b6cc054c7ed7ac301587 5.8s => => sha256:1d87379b86b89fd3b8bb1621128f00c8f962756e6aaaed264ec38db733273543 2.35MB / 2.35MB 41.8s => => extracting sha256:8584d51a9262f9a3a436dea09ba40fa50f85802018f9bd299eee1bf538481077 18.8s => => extracting sha256:524774b7d3638702fe9ae0ea3fcfb81b027dfd75cc2fc14f0119e764b9543d58 1.2s => => extracting sha256:9460f6b75036e38367e2f27bb15e85777c5d6cd52ad168741c9566186415aa26 2.9s => => extracting sha256:9bc548096c181514aa1253966a330134d939496027f92f57ab376cd236eb280b 0.0s => => extracting sha256:1d87379b86b89fd3b8bb1621128f00c8f962756e6aaaed264ec38db733273543 0.8s => [2/5] COPY . /app 2.3s => [3/5] WORKDIR /app 0.2s => [4/5] RUN pip install -U datasette 26.9s => [5/5] RUN datasette inspect covid.db --inspect-file inspect-data.json 3.1s => exporting to image 1.2s => => exporting layers 1.2s => => writing image sha256:b5db0c205cd3454c21fbb00ecf6043f261540bcf91c2dfc36d418f1a23a75d7a 0.0s Use 'docker scan' to run Snyk tests against images to find vulnerabilities and learn how to fix them Traceback (most recent call last): "main", mod_spec) File "c:\users\grott\anaconda3\lib\runpy.py", line 85, in _run_code exec(code, run_globals) File "C:\Users\grott\Anaconda3\Scripts\datasette.exe__main__.py", line 7, in <module> File "c:\users\grott\anaconda3\lib\site-packages\click\core.py", line 829, in call return self.main(args, kwargs) File "c:\users\grott\anaconda3\lib\site-packages\click\core.py", line 782, in main rv = self.invoke(ctx) File "c:\users\grott\anaconda3\lib\site-packages\click\core.py", line 1259, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "c:\users\grott\anaconda3\lib\site-packages\click\core.py", line 1066, in invoke return ctx.invoke(self.callback, ctx.params) File "c:\users\grott\anaconda3\lib\site-packages\click\core.py", line 610, in invoke return callback(args, **kwargs) File "c:\users\grott\anaconda3\lib\site-packages\datasette\cli.py", line 283, in package call(args) File "c:\users\grott\anaconda3\lib\contextlib.py", line 119, in exit next(self.gen) File "c:\users\grott\anaconda3\lib\site-packages\datasette\utils__init__.py", line 451, in temporary_docker_directory tmp.cleanup() File "c:\users\grott\anaconda3\lib\tempfile.py", line 811, in cleanup _shutil.rmtree(self.name) File "c:\users\grott\anaconda3\lib\shutil.py", line 516, in rmtree return _rmtree_unsafe(path, onerror) File "c:\users\grott\anaconda3\lib\shutil.py", line 395, in _rmtree_unsafe _rmtree_unsafe(fullname, onerror) File "c:\users\grott\anaconda3\lib\shutil.py", line 404, in _rmtree_unsafe onerror(os.rmdir, path, sys.exc_info()) File "c:\users\grott\anaconda3\lib\shutil.py", line 402, in _rmtree_unsafe os.rmdir(path) PermissionError: [WinError 32] The process cannot access the file because it is being used by another process: 'C:\Users\grott\AppData\Local\Temp\tmpkb27qid3\datasette'``` |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1479/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1015646369 | I_kwDOBm6k_c48iYih | 1480 | Exceeding Cloud Run memory limits when deploying a 4.8G database | ghing 110420 | open | 0 | 9 | 2021-10-04T21:20:24Z | 2022-10-07T04:39:10Z | CONTRIBUTOR | When I try to deploy a 4.8G SQLite database to Google Cloud Run, I get this error message:
Unfortunately, the maximum amount of memory that can be allocated to an instance is 8192M. Naively profiling the memory usage of running Datasette with this database locally on my MacBook shows the following memory usage (using Activity Monitor) when I just start up Datasette locally:
I'm trying to understand if there's a query or other operation that gets run during container deployment that causes memory use to be so large and if this can be avoided somehow. This is somewhat related to #1082, but on a different platform, so I decided to open a new issue. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1480/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1072106103 | I_kwDOBm6k_c4_5wp3 | 1542 | feature request: order and dependency of plugins (that use js) | fs111 33631 | open | 0 | 1 | 2021-12-06T12:40:45Z | 2021-12-15T17:47:08Z | NONE | I have been playing with datasette for the last couple of weeks and it is great! I am a big fan of Basically what would like to have is a way to say load my plugin after the plugins I depend on have been loaded and rendered. There seems to be no prior art where plugins have these dependencies on the js level so I was wondering if that could be added or if it exists how to do it. Basically what I want to do is: my-awesome-plugin has a dependency on datastte-cluster-map. Whenever datasette cluster map has finished rendering on page load, call my plugin, but no earlier. To make that work datasette probably needs some total order in which way plugins are loaded intialized. Since I am new to datastte, I may be missing something obvious, so please let me know if the above makes no sense. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1542/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1058072543 | I_kwDOBm6k_c4_EOff | 1518 | Complete refactor of TableView and table.html template | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 45 | 2021-11-19T02:55:16Z | 2022-03-15T18:35:49Z | OWNER | Split from #878. The current In #878 I started exploring a new pattern for building views. In doing so it became clear that I've been trying to build this as a I also know that I want to have a fully documented template context for All of this adds up to the |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1518/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1058803238 | I_kwDOBm6k_c4_HA4m | 1520 | Pattern for avoiding accidental URL over-rides | simonw 9599 | open | 0 | 1 | 2021-11-19T18:28:05Z | 2021-11-19T18:29:26Z | OWNER | Following #1517 I'm experimenting with a plugin that does this:
Need to figure out a pattern to avoid that happening. Plugins get to add their routes before Datasette's default routes, which is why this is happening here. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1520/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1059209412 | I_kwDOBm6k_c4_IkDE | 1523 | Come up with a more elegant solution for base_url than ds.urls.path() | simonw 9599 | open | 0 | 0 | 2021-11-20T19:05:22Z | 2021-11-20T19:05:22Z | OWNER | While fixing #1519 I added a lot of ugly code that looks like this: https://github.com/simonw/datasette/blob/08947fa76433d18988aa1ee1d929bd8320c75fe2/datasette/facets.py#L228-L230 See these two commits in particular: fe687fd0207c4c56c4778d3e92e3505fc4b18172 and 08947fa76433d18988aa1ee1d929bd8320c75fe2 It would be great to come up with a less verbose and error-prone way of handling this problem. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1523/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1060631257 | I_kwDOBm6k_c4_N_LZ | 1528 | Add new `"sql_file"` key to Canned Queries in metadata? | asg017 15178711 | open | 0 | 3 | 2021-11-22T21:58:01Z | 2022-06-10T03:23:08Z | CONTRIBUTOR | Currently for canned queries, you have to inline SQL in your
This works fine, but for a few reasons, I usually have my canned queries already written in separate So, I'd like to see a new
Both of these would work in the exact same way, where Datasette would instead open + include A few reasons why I'd like to keep my canned queries SQL separate from metadata.yaml:
Let me know if this is a feature you'd like to see, I can try to send up a PR if this sounds right! |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1528/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1065429936 | I_kwDOBm6k_c4_gSuw | 1532 | Use datasette-table Web Component to guide the design of the JSON API for 1.0 | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 4 | 2021-11-28T20:37:18Z | 2022-03-16T20:13:34Z | OWNER | I realized that one of the reasons I'm having trouble committing to nailing down the JSON API for 1.0 is that I don't use it much myself - I use the As an experiment I built a Web Component for embedding Datasette tables on pages - https://github.com/simonw/datasette-table - and I think it's actually going to be a really useful tool for helping me dog food the v1.0 API design. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1532/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1067775061 | I_kwDOBm6k_c4_pPRV | 1539 | Research PRAGMA query_only | simonw 9599 | open | 0 | 0 | 2021-11-30T23:30:24Z | 2021-11-30T23:30:24Z | OWNER | https://www.sqlite.org/pragma.html#pragma_query_only
Would it be worth adding this as an extra protection against accidental writes to a DB file over a read-only connection? |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1539/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1068791148 | I_kwDOBm6k_c4_tHVs | 1540 | Idea: hover to reveal details of linked row | simonw 9599 | open | 0 | 6 | 2021-12-01T19:28:07Z | 2021-12-09T23:38:39Z | OWNER |
Hovering over that could work a little bit like GitHub issue links:
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1540/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1069881276 | I_kwDOBm6k_c4_xRe8 | 1541 | Different default layout for row page | simonw 9599 | open | 0 | 1 | 2021-12-02T18:56:36Z | 2021-12-02T18:56:54Z | OWNER | The row page displays as a table even though it only has one table row. maybe default to the same display as the narrow page version, even for wide pages? |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1541/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1955676270 | I_kwDOBm6k_c50kUBu | 2201 | Discord invite link is invalid | andrewsanchez 11708906 | open | 0 | 0 | 2023-10-21T21:50:05Z | 2023-10-21T21:50:05Z | NONE | https://datasette.io/discord leads to https://discord.com/invite/ktd74dm5mw and returns the following: |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2201/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1977726056 | I_kwDOBm6k_c514bRo | 2203 | custom plugin not seen as sql function | LyzardKing 7113541 | open | 0 | 0 | 2023-11-05T10:30:19Z | 2023-11-05T10:30:19Z | NONE | Hi, I'm not sure if this is the right repo for this issue. I'm using datasette with the parquet (to read a duckdb), and jellyfish plugins. Both work perfectly. Now I need to create a simple plugin that uses the python rouge package and returns a similarity score (similarly to how the jellyfish plugin works).
If I create a custom plugin, even the example hello_world one, copied directly from the tutorial, I get the following error:
Since the jellyfish plugin doesn't do anything more complex, I'm wondering if there is some other kind of issue with my setup. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2203/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1978023780 | I_kwDOBm6k_c515j9k | 2205 | request.post_vars() method obliterates form keys with multiple values | simonw 9599 | open | 0 | Datasette 1.0a-next 8755003 | 3 | 2023-11-05T23:25:08Z | 2023-11-06T04:10:34Z | OWNER | In GET requests you can do You can't even try calling |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2205/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1978022687 | I_kwDOBm6k_c515jsf | 2204 | request.post_body() can only be called once | simonw 9599 | open | 0 | 0 | 2023-11-05T23:22:03Z | 2023-11-05T23:23:23Z | OWNER | This code here: It consumes the messages, which means if you try to call it a second time you won't be able to get at the body. This is efficient - we don't end up with a Potential solution: set Potential optimization: only do this for bodies that are shorter than a certain threshold - maybe 1MB - and raise an exception if you attempt to call I'm a bit nervous about that option though, since it could result in errors that don't show up in testing but do show up in production. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2204/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1994845152 | I_kwDOBm6k_c525uvg | 2207 | ModuleNotFoundError: No module named 'click_default_group | honzajavorek 283441 | open | 0 | 0 | 2023-11-15T14:04:32Z | 2023-11-15T14:04:32Z | NONE | No matter what I do, I'm getting this error:
I have datasette in my dependencies like this:
I had the latest regular version (not pre-release) there originally, but the result was the same:
Full pyproject.toml is at https://github.com/honzajavorek/junior.guru/ Previously datasette worked for me, but I guess something had to upgrade and now I can't even launch it. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2207/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1994857251 | I_kwDOBm6k_c525xsj | 2208 | No suggested facets when a column named 'value' is included | rgieseke 198537 | open | 0 | 1 | 2023-11-15T14:11:17Z | 2023-11-15T14:18:59Z | CONTRIBUTOR | When a column named 'value' is included there are no suggested facets is shown as the query uses an alias of 'value'. Currently the following is shown (from https://latest.datasette.io/fixtures/facetable) When I add a column named 'value' only the JSON facets are processed. I think that not using aliases could be a solution (except if someone wants to use a column named There is also a TODO with a similar question in the same file. I have not looked into that yet. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2208/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 2028698018 | I_kwDOBm6k_c5463mi | 2213 | feature request: gzip compression of database downloads | fgregg 536941 | open | 0 | 1 | 2023-12-06T14:35:03Z | 2023-12-06T15:05:46Z | CONTRIBUTOR | At the bottom of database pages, datasette gives users the opportunity to download the underlying sqlite database. It would be great if that could be served gzip compressed. this is similar to #1213, but for me, i don't need datasette to compress html and json because my CDN layer does it for me, however, cloudflare at least, will not compress a mimetype of "application" (see list of mimetype: https://developers.cloudflare.com/speed/optimization/content/brotli/content-compression/) |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2213/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 2019811176 | I_kwDOBm6k_c54Y99o | 2211 | Unreachable exception handlers for `sqlite3.OperationalError` | mattparmett 1214074 | open | 0 | 0 | 2023-12-01T00:50:22Z | 2023-12-01T00:50:22Z | NONE | There are several places where Because the exception will be caught by the first handler, the logic in the second handler is unreachable and will never be executed. If this is intended behavior, the second handler can be removed. If this is not intended, and the second handler should be the one that catches this exception, then This issue was found via a CodeQL query on the repository, and I've listed the occurrences found by the query below. There may be other instances of this issue in the code that were not surfaced by the query. I'd be happy to share the query if others would like to view or run it. One example: Other instances: https://github.com/simonw/datasette/blob/main/datasette/views/base.py#L266-L270 https://github.com/simonw/datasette/blob/main/datasette/views/base.py#L452-L456 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2211/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 2029908157 | I_kwDOBm6k_c54_fC9 | 2214 | CSV export fails for some `text` foreign key references | precipice 2874 | open | 0 | 1 | 2023-12-07T05:04:34Z | 2023-12-07T07:36:34Z | NONE | I'm starting this issue without a clear reproduction in case someone else has seen this behavior, and to use the issue as a notebook for research. I'm using Datasette with the SWITRS data set, which is a California Highway Patrol collection of traffic incident data from the past decade or so. I receive data from them in CSV and want to work with it in Datasette, then export it to CSV for mapping in Felt.com. Their data makes extensive use of codes for incident column data ( If I import the data and set up the integer foreign keys, everything works fine, but if I set up the text foreign keys, CSV export starts to fail. The foreign key configuration is as follows: ``` Some tables use integer ids, like sensible tables do. Let's import them firstsince we favor them.for TABLE in DAY_OF_WEEK CHP_SHIFT POPULATION SPECIAL_COND BEAT_TYPE COLLISION_SEVERITY do sqlite-utils create-table records.db $TABLE id integer name text --pk=id sqlite-utils insert records.db $TABLE lookup-tables/$TABLE.csv --csv sqlite-utils add-foreign-key records.db collisions $TABLE $TABLE id sqlite-utils create-index records.db collisions $TABLE done Other tables use letter keys, like they were raised by WOLVES. Let's put themat the end of the import queue.for TABLE in WEATHER_1 WEATHER_2 LOCATION_TYPE RAMP_INTERSECTION SIDE_OF_HWY \ PRIMARY_COLL_FACTOR PCF_CODE_OF_VIOL PCF_VIOL_CATEGORY TYPE_OF_COLLISION MVIW \ PED_ACTION ROAD_SURFACE ROAD_COND_1 ROAD_COND_2 LIGHTING CONTROL_DEVICE \ STWD_VEHTYPE_AT_FAULT CHP_VEHTYPE_AT_FAULT PRIMARY_RAMP SECONDARY_RAMP do sqlite-utils create-table records.db $TABLE key text name text --pk=key sqlite-utils insert records.db $TABLE lookup-tables/$TABLE.csv --csv sqlite-utils add-foreign-key records.db collisions $TABLE $TABLE key sqlite-utils create-index records.db collisions $TABLE done ``` You can see the full code and import script here: https://github.com/radical-bike-lobby/switrs-db If I run this code and then hit the CSV export link in the Datasette interface (the simple link or the "advanced" dialog), export fails after a small number of CSV rows are written. I am not seeing any detailed error messages but this appears in the logging output: ``` INFO: 127.0.0.1:57885 - "GET /records/collisions.csv?_facet=PRIMARY_RD&PRIMARY_RD=ASHBY+AV&_labels=on&_size=max HTTP/1.1" 200 OK Caught this error: ``` (No other output follows I've stared at the rows directly after the error occurs and can't yet see what is causing the problem. I'm going to set up a development environment and see if I get any more detailed error output, and then stare more at some problematic lines to see if I can get a simple reproduction. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2214/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 2023057255 | I_kwDOBm6k_c54lWdn | 2212 | Can't filter with numbers | fzakaria 605070 | open | 0 | 0 | 2023-12-04T05:26:29Z | 2023-12-04T05:26:29Z | NONE | I have a schema that uses numbers for a column (actually it's a boolean 1 or 0 but SQLite doesn't have Boolean). I can't seem to get the facet to work or even filtering on this column. My guess is that Datasette is "stringifying" the number and it's not matching? Example: https://debian-sqlelf.fly.dev/debian/elf_symbols?_sort_desc=name&_facet=exported&exported=0 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/2212/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1087919372 | I_kwDOBm6k_c5A2FUM | 1578 | Confirm if documented nginx proxy config works for row pages with escaped characters in their primary key | simonw 9599 | open | 0 | 4 | 2021-12-23T18:27:59Z | 2021-12-24T21:33:19Z | OWNER | Found this while working on https://github.com/simonw/datasette-tiddlywiki
Then clicking on |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1578/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1077628073 | I_kwDOBm6k_c5AO0yp | 1550 | Research option for returning all rows from arbitrary query | simonw 9599 | open | 0 | 2 | 2021-12-11T19:31:11Z | 2021-12-11T23:43:24Z | OWNER | Inspired by thinking about #1549 - returning ALL rows from an arbitrary query is a lot easier if you just run that query and keep iterating over the cursor. I've avoided doing that in the past because it could tie up a connection for a long time - but in private instances this wouldn't be such a problem. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1550/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1077620955 | I_kwDOBm6k_c5AOzDb | 1549 | Redesign CSV export to improve usability | fgregg 536941 | open | 0 | Datasette 1.0 3268330 | 5 | 2021-12-11T19:02:12Z | 2022-04-04T11:17:13Z | CONTRIBUTOR | Original title: Set content type for CSV so that browsers will attempt to download instead opening in the browser Right now, if the user clicks on the CSV related to a <s>table or a</s> query, the response header for the content type is "content-type: text/plain; charset=utf-8" Most browsers will try to open a file with this content-type in the browser. This is not what most people want to do, and lots of folks don't know that if they want to download the CSV and open it in the a spreadsheet program they next need to save the page through their browser. It would be great if the response header could be something like
which would lead browsers to open a download dialog. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1549/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1079111498 | I_kwDOBm6k_c5AUe9K | 1553 | if csv export is truncated in non streaming mode set informative response header | fgregg 536941 | open | 0 | 3 | 2021-12-13T22:50:44Z | 2021-12-16T19:17:28Z | CONTRIBUTOR | streaming mode is currently not enabled for custom queries, so the queries will be truncated to max row limit. it would be great if a response is truncated that an header signalling that was set in the header. i need to write some pagination code for getting full results back for a custom query and it would make the code much better if i could reliably known when there is nothing more to limit/offset |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1553/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1082584499 | I_kwDOBm6k_c5Ahu2z | 1558 | Redesign `facet_results` JSON structure prior to Datasette 1.0 | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 3 | 2021-12-16T19:45:10Z | 2023-01-09T15:31:17Z | OWNER |
Originally posted by @simonw in https://github.com/simonw/datasette/issues/625#issuecomment-996130862 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1558/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1083657868 | I_kwDOBm6k_c5Al06M | 1565 | Documented JavaScript variables on different templates made available for plugins | simonw 9599 | open | 0 | 8 | 2021-12-17T22:30:51Z | 2021-12-19T22:37:29Z | OWNER | While working on https://github.com/simonw/datasette-leaflet-freedraw/issues/10 I found myself writing this atrocity to figure out the SQL query used for a specific table page:
Instead, I think pages like that one should have a block of script at the bottom something like this:
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1565/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1084185188 | I_kwDOBm6k_c5An1pk | 1573 | Make trace() a documented internal API | simonw 9599 | open | 0 | 1 | 2021-12-19T20:32:56Z | 2021-12-19T21:13:13Z | OWNER | This should be documented so plugin authors can use it to add their own custom traces: https://github.com/simonw/datasette/blob/8f311d6c1d9f73f4ec643009767749c17b5ca5dd/datasette/tracer.py#L28-L52 Including the new |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1573/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1090810196 | I_kwDOBm6k_c5BBHFU | 1583 | consider adding deletion step of cloudbuild artifacts to gcloud publish | fgregg 536941 | open | 0 | 1 | 2021-12-30T00:33:23Z | 2021-12-30T00:34:16Z | CONTRIBUTOR | right now, as part of the the publish process images and other artifacts are stored to gcloud's cloud storage before being deployed to cloudrun. after successfully deploying, it would be nice if the the script deleted these artifacts. otherwise, if you have regularly scheduled build process, you can end up paying to store lots of out of date artifacts. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1583/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1091257796 | I_kwDOBm6k_c5BC0XE | 1584 | give error with recursive sql | tunguyenatwork 58088336 | open | 0 | 0 | 2021-12-30T18:53:16Z | 2021-12-30T18:53:16Z | NONE | I got an error "near "WITH": syntax error" after I upgraded to version 0.59 from 0.52.4. This error is related to recursive sql. It works great on the previous version but it failed after upgraded. Below is an example of sql: WITH RECURSIVE manager_of(position, super_position) AS (SELECT position, case ifnull(INDIRECT_SUPER_POSITION,'') when '' then super_position else INDIRECT_SUPER_POSITION end as SUPER_POSITION FROM position where super_position<>'SGV000000001' and super_position!='' and position <> super_position),chain_manager_of_position(position, level) AS (SELECT super_position, 1 as level FROM manager_of WHERE super_position!='' and (position=:pos or position in (Select position from employee where employee=:ein)) UNION ALL SELECT super_position, level+1 as level FROM manager_of JOIN chain_manager_of_position USING(position)) SELECT * FROM chain_manager_of_position left join employee using(position) where employee is not NULL order by level limit 1 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1584/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1091838742 | I_kwDOBm6k_c5BFCMW | 1585 | Fire base caching for `publish cloudrun` | simonw 9599 | open | 0 | 1 | 2022-01-01T15:38:15Z | 2022-01-01T15:40:38Z | OWNER | https://gist.github.com/steren/03d3e58c58c9a53fd49bb78f58541872 has a recipe for this, via https://twitter.com/steren/status/1477038411114446848 Could this enable easier vanity URLs of the format |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1585/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1096536240 | I_kwDOBm6k_c5BW9Cw | 1586 | run analyze on all databases as part of start up or publishing | fgregg 536941 | open | 0 | 1 | 2022-01-07T17:52:34Z | 2022-02-02T07:13:37Z | CONTRIBUTOR | Running It might be nice if the analyze was run as part of the start up of "serve" or "publish". |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1586/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1100015398 | I_kwDOBm6k_c5BkOcm | 1591 | Maybe let plugins define custom serve options? | simonw 9599 | open | 0 | 7 | 2022-01-12T08:18:47Z | 2022-01-15T11:56:59Z | OWNER | https://twitter.com/psychemedia/status/1481171650934714370
I've thought something like this might be useful for other plugins in the past, too. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1591/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1100499619 | I_kwDOBm6k_c5BmEqj | 1592 | Row pages should show links to foreign keys | simonw 9599 | open | 0 | 1 | 2022-01-12T15:50:20Z | 2022-01-12T15:52:17Z | OWNER | Refs #1518 refactor. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1592/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1102568047 | I_kwDOBm6k_c5Bt9pv | 1596 | Documentation page warning of changes coming in 1.0 | simonw 9599 | open | 0 | 0 | 2022-01-13T23:26:04Z | 2022-01-13T23:26:04Z | OWNER | I should start this relatively soon. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1596/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1102966378 | I_kwDOBm6k_c5Bve5q | 1599 | Add architecture documentation | simonw 9599 | open | 0 | 0 | 2022-01-14T04:55:38Z | 2022-01-14T04:56:03Z | OWNER | datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1599/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||||
| 1121121305 | I_kwDOBm6k_c5C0vQZ | 1618 | Reconsider policy on blocking queries containing the string "pragma" | strada 770231 | open | 0 | 6 | 2022-02-01T19:39:46Z | 2022-02-02T19:42:03Z | NONE | First of all, thanks for creating this cool project, and also supporting publishing to various hosting services out of the box. While testing out, I noticed legitimate queries such as
Example as seen from a Datasette instance: https://fivethirtyeight.datasettes.com/polls?sql=select+*+from+books+where+title+like+%27Pragmatic%25%27%0D%0A I'd propose a regular expression like
I can create a pull request with this change, unless the maintainers think it would allow unwanted queries to be executed. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1618/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1121583414 | I_kwDOBm6k_c5C2gE2 | 1619 | JSON link on row page is 404 if base_url setting is used | simonw 9599 | open | 0 | 5 | 2022-02-02T07:09:53Z | 2023-03-24T15:38:04Z | OWNER | On my local environment: Then hit http://127.0.0.1:3344/foo/bar/fixtures/table%2Fwith%2Fslashes.csv/3
But... that http://127.0.0.1:3344/foo/bar/foo/bar/fixtures/table%2Fwith%2Fslashes.csv/3?_format=json |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1619/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1122427321 | I_kwDOBm6k_c5C5uG5 | 1624 | Index page `/` has no CORS headers | simonw 9599 | open | 0 | 2 | 2022-02-02T21:56:10Z | 2022-09-28T16:54:22Z | OWNER | Compare the following: ``` % curl -I 'https://latest.datasette.io/fixtures' HTTP/1.1 200 OK link: https://latest.datasette.io/fixtures.json; rel="alternate"; type="application/json+datasette" cache-control: max-age=5 referrer-policy: no-referrer access-control-allow-origin: * access-control-allow-headers: Authorization access-control-expose-headers: Link content-type: text/html; charset=utf-8 x-databases: _memory, _internal, fixtures, extra_database Date: Wed, 02 Feb 2022 21:55:49 GMT Server: Google Frontend Transfer-Encoding: chunked % curl -I 'https://latest.datasette.io/' |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1624/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1122450452 | I_kwDOBm6k_c5C5zwU | 1625 | Try running tests against macOS and Windows in addition to Ubuntu | simonw 9599 | open | 0 | 0 | 2022-02-02T22:25:57Z | 2022-02-02T22:25:57Z | OWNER | I already do this for Related: - #1617 - #1545 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1625/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1122557010 | I_kwDOBm6k_c5C6NxS | 1627 | Get the tests passing against Windows | simonw 9599 | open | 0 | 0 | 2022-02-03T01:23:06Z | 2022-02-03T01:23:32Z | OWNER |
Originally posted by @simonw in https://github.com/simonw/datasette/issues/1626#issuecomment-1028515161 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1627/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1108300685 | I_kwDOBm6k_c5CD1ON | 1604 | Option to assign a domain/subdomain using `datasette publish cloudrun` | simonw 9599 | open | 0 | 1 | 2022-01-19T16:21:17Z | 2022-01-19T16:23:54Z | OWNER | Looks like this API should be able to do that: https://twitter.com/steren/status/1483835859191304192 - https://cloud.google.com/run/docs/reference/rest/v1/namespaces.domainmappings/create |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1604/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1108671952 | I_kwDOBm6k_c5CFP3Q | 1605 | Scripted exports | eyeseast 25778 | open | 0 | 10 | 2022-01-19T23:45:55Z | 2022-11-30T15:06:38Z | CONTRIBUTOR | Posting this while I'm thinking about it: I mentioned at the end of this thread that I'm usually doing I used to use a tool called datafreeze to do scripted exports, but that project looks dead now. The ergonomics of it are pretty nice, though, and the This is related to the idea for |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1605/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1113384383 | I_kwDOBm6k_c5CXOW_ | 1611 | Avoid ever running count(*) against SpatiaLite KNN table | simonw 9599 | open | 0 | 1 | 2022-01-25T03:32:54Z | 2022-02-02T06:45:47Z | OWNER | Got this in a trace:
Looks like running |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1611/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1114628238 | I_kwDOBm6k_c5Cb-CO | 1613 | Improvements to help make Datasette a better tool for learning SQL | simonw 9599 | open | 0 | 5 | 2022-01-26T04:56:07Z | 2022-01-26T16:41:46Z | OWNER | Tracking issue for the general goal of making Datasette a better tool for learning SQL. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1613/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1115435536 | I_kwDOBm6k_c5CfDIQ | 1614 | Try again with SQLite codemirror support | simonw 9599 | open | 0 | 1 | 2022-01-26T20:05:20Z | 2022-12-23T21:27:10Z | OWNER | I tried and failed to implement autocomplete a while ago. Relevant code: Sounds like upgrading to CodeMirror 6 ASAP would be worthwhile since it has better accessibility and touch screen support: https://codemirror.net/6/ |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1614/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1125576543 | I_kwDOBm6k_c5DFu9f | 1630 | Review datasette.utils and decide which functions should be documented for 1.0 | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 0 | 2022-02-07T06:39:52Z | 2022-02-07T06:39:52Z | OWNER | Follows: - #1176 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1630/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1129052172 | I_kwDOBm6k_c5DS_gM | 1633 | base_url or prefix does not work with _exact match | henrikek 6613091 | open | 0 | 2 | 2022-02-09T21:45:07Z | 2022-04-28T09:12:56Z | NONE | When i hit "Apply" button to search with "_exact" for a column syntax the URL prefix is removed from the url.
And the result is:
If I add the marked row to url_builder.py it seams to work:
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1633/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1131295060 | I_kwDOBm6k_c5DbjFU | 1634 | Update Dockerfile generated by `datasette publish` | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 4 | 2022-02-11T00:07:26Z | 2022-03-11T17:38:08Z | OWNER | The generated ENV DATASETTE_SECRET 'edab49cbc5d5f6f33238f54852037e3fee710821960b73edd2ce743454182ae2'
RUN pip install -U datasette datasette-auth-passwords datasette-tiddlywiki datasette-graphql
RUN datasette inspect fixtures.db other.db --inspect-file inspect-data.json
ENV PORT 8080
EXPOSE 8080
CMD datasette serve --host 0.0.0.0 -i fixtures.db -i other.db --cors --inspect-file inspect-data.json --metadata metadata.json --create --port $PORT /data/*.db
Here's the code that generates it: https://github.com/simonw/datasette/blob/7d24fd405f3c60e4c852c5d746c91aa2ba23cf5b/datasette/utils/init.py#L389-L400 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1634/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 2,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1142107925 | I_kwDOBm6k_c5EEy8V | 1638 | `filters_from_request` plugin hook docs should mention that returning an async function is allowed | simonw 9599 | open | 0 | 0 | 2022-02-18T00:08:26Z | 2022-02-18T00:08:26Z | OWNER | https://docs.datasette.io/en/stable/plugin_hooks.html#filters-from-request-request-database-table-datasette doesn't mention that you can return an |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1638/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1148638868 | I_kwDOBm6k_c5EdtaU | 1639 | Make datasette-redirect-forbidden unneccessary | simonw 9599 | open | 0 | 0 | 2022-02-23T22:18:46Z | 2022-02-23T22:18:46Z | OWNER | I wrote This should be a feature of Datasette core. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1639/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1148725876 | I_kwDOBm6k_c5EeCp0 | 1640 | Support static assets where file length may change, e.g. logs | broccolihighkicks 57859326 | open | 0 | 2 | 2022-02-24T00:34:42Z | 2022-03-05T01:19:25Z | NONE | This is a bit of an oxymoron. I am serving a log.txt file for a background process using the Datasette --static CLI. This is useful as I can observe a background process from the web UI to see any errors that occur (instead of spelunking the logs via docker exec/ssh etc). I get this error, which I think is because Datasette assumes that the size of the content does not change (but appending new log lines means the content length changes).
Thanks, I am finding Datasette very useful. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1640/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1149310456 | I_kwDOBm6k_c5EgRX4 | 1641 | Tweak mobile keyboard settings | simonw 9599 | open | 0 | 1 | 2022-02-24T13:47:10Z | 2022-02-24T13:49:26Z | OWNER |
Twitter: https://twitter.com/forestgregg/status/1496842959563726852 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1641/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1154399841 | I_kwDOBm6k_c5Ezr5h | 1645 | Sensible `cache-control` headers for static assets, including those served by plugins | curiousleo 697092 | open | 0 | Datasette 1.0 3268330 | 4 | 2022-02-28T18:12:03Z | 2022-03-08T02:59:29Z | NONE | What I'm seeingWith A table view returns
A static asset returns no
What I expected to seeI expected the static asset to return a Why this mattersI'm productionising a Datasette deployment right now and was looking into putting it behind a Varnish instance. I was surprised to see requests for static assets being served from Datasette rather than Varnish, this is what led me to look more closely at the response headers. While Datasette serves those static assets pretty quickly, I don't see why Datasette should serve them. By their nature, static assets like images and JS files are very cacheable, so it should be easy to serve them from a cache like Varnish. (Note that Varnish can easily be configured to override this header, enabling caching for static assets. But it would be better if this override was not necessary.) DiscussionIt seems clear to me that serving static assets without a I see two options here: A. Static assets use the same logic as table / SQL views to set the |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1645/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1161937073 | I_kwDOBm6k_c5FQcCx | 1653 | Mechanism to default a table to sorting by multiple columns | simonw 9599 | open | 0 | 2 | 2022-03-07T21:20:11Z | 2022-03-07T21:23:39Z | OWNER | Discussed in https://github.com/simonw/datasette/discussions/1652
<sup>Originally posted by **zaneselvans** March 7, 2022</sup>
It's easy to tell datasette to sort tables using a single column, as [described in the docs](https://docs.datasette.io/en/stable/metadata.html#setting-a-default-sort-order):
```yaml
databases:
ferc1:
tables:
f1_edcfu_epda:
sort: created_time
```
But is there some way to tell it to sort using a composite key, like you would in an `ORDER BY` clause instead? For example, the way it's being done **[in this query](https://data.catalyst.coop/ferc1?sql=select%0D%0A++rowid%2C%0D%0A++respondent_id%2C%0D%0A++report_year%2C%0D%0A++spplmnt_num%2C%0D%0A++row_number%2C%0D%0A++row_seq%2C%0D%0A++row_prvlg%2C%0D%0A++acct_num%2C%0D%0A++depr_plnt_base%2C%0D%0A++est_avg_srvce_lf%2C%0D%0A++net_salvage%2C%0D%0A++apply_depr_rate%2C%0D%0A++mrtlty_crv_typ%2C%0D%0A++avg_remaining_lf%2C%0D%0A++report_prd%0D%0Afrom%0D%0A++f1_edcfu_epda%0D%0Awhere%0D%0A++respondent_id+%3D+210%0D%0A++AND+report_year+%3D+2020%0D%0Aorder+by%0D%0A++report_year%2C+report_prd%2C+respondent_id%2C+spplmnt_num%2C+row_number%0D%0Alimit%0D%0A++1000)** on our Datasette?
```sql
SELECT
respondent_id,
report_year,
spplmnt_num,
row_number,
row_seq,
row_prvlg,
acct_num,
depr_plnt_base,
est_avg_srvce_lf,
net_salvage,
apply_depr_rate,
mrtlty_crv_typ,
avg_remaining_lf,
report_prd
FROM
f1_edcfu_epda
WHERE
respondent_id = 210
AND report_year = 2020
ORDER BY
report_year, report_prd, respondent_id, spplmnt_num, row_number
LIMIT
1000
```
The problem here is that by default it's using `rowid` (the SQLite assigned autoincrementing integer key) to order the records, but the table **should** have a natural composite primary key, but the original database that this data is being migrated from doesn't enforce unique primary keys, so there are dupes, and we don't want to drop those rows, and the records are somehow getting jumbled in the database (the `rowid` ordering isn't lined up with the expected ordering based on the composite primary key, though it's close) and this jumbling is confusing to users that expect to see the data ordered based on the natural primary key.
I've tried setting the `sort` metadata parameter to a list of column names, a tuple of column names, a quoted string of comma-separated column names, a quoted string of a tuple of column names...
```yaml
databases:
ferc1:
tables:
f1_edcfu_epda:
sort: "(report_year, report_prd, respondent_id, spplmnt_num, row_number)"
```
and they all give me server errors like:
```
Cannot sort table by (report_year, report_prd, respondent_id, spplmnt_num, row_number)
``` |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1653/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1163369515 | I_kwDOBm6k_c5FV5wr | 1655 | query result page is using 400mb of browser memory 40x size of html page and 400x size of csv data | fgregg 536941 | open | 0 | 8 | 2022-03-09T00:56:40Z | 2023-10-17T21:53:17Z | CONTRIBUTOR | is using about 400 mb in firefox 97 on mac os x. if you download the html for the page, it's about 11mb and if you get the csv for the data its about 1mb. it's using over a 1G on chrome 99. i found this because, i was trying to figure out why editing the SQL was getting very slow. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1655/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1174655187 | I_kwDOBm6k_c5GA9DT | 1671 | Filters fail to work correctly against calculated numeric columns returned by SQL views because type affinity rules do not apply | rayvoelker 9308268 | open | 0 | 8 | 2022-03-20T19:17:24Z | 2022-03-22T17:43:12Z | NONE | I found a strange behavior, and I'm not sure if it's related to views and boolean values perhaps, or if there's something else weird going on here, but I'll provide an example that may help show what I'm seeing happen. ```bash !/bin/bashecho "\"id\",\"expiration_date\" 0,2018-01-04 1,2019-01-05 2,2020-01-06 3,2021-01-07 4,2022-01-08 5,2023-01-09 6,2024-01-10 7,2025-01-11 8,2026-01-12 9,2027-01-13 " > test.csv csvs-to-sqlite test.csv test.db sqlite-utils create-view --replace test.db test_view "select id, expiration_date, case when julianday('NOW') >= julianday(expiration_date) then 1 else 0 end as has_expired FROM test" ```
Thanks again and let me know if you want me to provide anything else! |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1671/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1174697144 | I_kwDOBm6k_c5GBHS4 | 1672 | Refactor CSV handling code out of DataView | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 1 | 2022-03-20T21:47:00Z | 2022-03-20T21:52:39Z | OWNER |
Originally posted by @simonw in https://github.com/simonw/datasette/issues/1660#issuecomment-1073355032 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1672/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1174708375 | I_kwDOBm6k_c5GBKCX | 1673 | Streaming CSV spends a lot of time in `table_column_details` | simonw 9599 | open | 0 | 1 | 2022-03-20T22:25:28Z | 2022-03-20T22:34:06Z | OWNER | At least I think it does. I tried running While investigating: - #1355 And spotted this: ``` datasette covid.db --get /covid/ny_times_us_counties.csv?_size=10&_stream=on' (python v3.10.2) Total Samples 5800 GIL: 71.00%, Active: 98.00%, Threads: 4 %Own %Total OwnTime TotalTime Function (filename:line) |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1673/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1174717287 | I_kwDOBm6k_c5GBMNn | 1674 | Tweak design of /.json | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 1 | 2022-03-20T22:58:01Z | 2022-03-20T22:58:40Z | OWNER | https://latest.datasette.io/.json Currently:
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1674/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1175690070 | I_kwDOBm6k_c5GE5tW | 1676 | Reconsider ensure_permissions() logic, can it be less confusing? | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 3 | 2022-03-21T17:14:57Z | 2022-12-02T01:23:40Z | OWNER |
Originally posted by @simonw in https://github.com/simonw/datasette/issues/1675#issuecomment-1074177827 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1676/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1175894898 | I_kwDOBm6k_c5GFrty | 1680 | Consider simplifying permissions for 1.0 | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 0 | 2022-03-21T20:17:29Z | 2022-03-21T20:17:29Z | OWNER | Permission checks right now can express one of three opinions:
But... there's also a concept of a "default" for a given permission check, which might be I worry this is too complicated. Could this be simplified before 1.0? In particular the default concept. See also: - #1676 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1680/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1177101697 | I_kwDOBm6k_c5GKSWB | 1681 | Potential bug in numeric handling where_clause for filters | simonw 9599 | open | 0 | 2 | 2022-03-22T17:43:50Z | 2022-03-22T17:49:09Z | OWNER |
Originally posted by @simonw in https://github.com/simonw/datasette/issues/1671#issuecomment-1075432283 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1681/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1179998071 | I_kwDOBm6k_c5GVVd3 | 1684 | Mechanism for disabling faceting on large tables only | simonw 9599 | open | 0 | 1 | 2022-03-24T20:06:11Z | 2022-03-24T20:13:19Z | OWNER | Forest turned off faceting on https://labordata.bunkum.us/ because it was causing performance problems on some of the huge tables - but it would be nice if it could still be an option on smaller tables such as https://labordata.bunkum.us/voluntary_recognitions-4421085/voluntary_recognitions One option: a new setting that automatically disables faceting (and facet suggestion) for tables that have either more than X rows or that are so big that the count could not be completed within the time limit. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1684/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1181037277 | I_kwDOBm6k_c5GZTLd | 1686 | heroku bails if app name specifed in datasette publish is the same as existing app | tlongers 2115933 | open | 0 | 0 | 2022-03-25T17:10:34Z | 2022-03-25T17:10:34Z | NONE | Seem that
The resulting error has the below traceback:
It's a solid failsafe, but does |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1686/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1181364043 | I_kwDOBm6k_c5Gai9L | 1687 | Make show_json.html or a similar mechanism stable for plugins | simonw 9599 | open | 0 | 0 | 2022-03-25T23:42:45Z | 2022-03-25T23:42:45Z | OWNER | I used It would be useful if it (or something like it) was documented and stable for plugins to use. Also relevant: - #878 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1687/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1182227211 | I_kwDOBm6k_c5Gd1sL | 1692 | [plugins][feature request]: Support additional script tag attributes when loading custom JS | hydrosquall 9020979 | open | 0 | 2 | 2022-03-27T01:16:03Z | 2022-03-30T06:14:51Z | CONTRIBUTOR | Motivation
To be able to support legacy browsers without slowing down users with modern browsers, I would like to be able to set additional HTML attributes on the tag fallback script, ```html <script type="module" src="/index.my-es-module-bundle.js"></script> <script src="/index.my-legacy-fallback-bundle.js" nomodule="" defer></script>``` ProposalTo achieve this, I propose additional optional properties to the API accepted by the Under this API, I'd write something like this to get the above HTML rendered in Datasette.
Resources
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1692/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1182141761 | I_kwDOBm6k_c5Gdg1B | 1690 | Idea: `datasette.set_actor_cookie(response, actor)` | simonw 9599 | open | 0 | 2 | 2022-03-26T22:41:52Z | 2022-03-26T22:43:00Z | OWNER | I just wrote this code in a plugin and it felt like it could benefit from an abstraction: https://github.com/simonw/datasette-auth0/blob/152e6eb21e96e9b73bd9c205f9749a1297d0ef0b/datasette_auth0/init.py#L79-L92
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1690/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1185868354 | I_kwDOBm6k_c5GrupC | 1695 | Option to un-filter facet not shown for `?col__exact=value` | simonw 9599 | open | 0 | 2 | 2022-03-30T04:44:02Z | 2022-03-30T04:46:18Z | OWNER | Spotted this on a page with
With
|
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1695/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1186696202 | I_kwDOBm6k_c5Gu4wK | 1696 | Show foreign key label when filtering | simonw 9599 | open | 0 | 2 | 2022-03-30T16:18:54Z | 2023-01-29T20:56:20Z | OWNER | For example here:
3 corresponds to "Human Related: Other" - it would be neat to display this in this area of the page somehow. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1696/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1193090967 | I_kwDOBm6k_c5HHR-X | 1699 | Proposal: datasette query | eyeseast 25778 | open | 0 | 6 | 2022-04-05T12:36:43Z | 2022-04-11T01:32:12Z | CONTRIBUTOR | I started sketching out a plugin to add a At its most basic, it will write the results of a query to STDOUT.
This isn't much improvement over using sqlite-utils. To make better use of datasette and its ecosystem, run For example, using the metadata file from alltheplaces-datasette:
That query would be good to get as CSV, and we can auto-discover metadata and databases in the current directory:
In this case, If a query takes parameters, I can pass them in at runtime, using the
I'm very interested in feedback on this, including whether it should be a plugin or in Datasette core. (I don't have a strong opinion about this, but I'm prototyping it as a plugin to start.) |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1699/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1196327155 | I_kwDOBm6k_c5HToDz | 1702 | Be more consistent with column quoting | simonw 9599 | open | 0 | 0 | 2022-04-07T16:59:20Z | 2022-04-07T16:59:20Z | OWNER | This tutorial made me notice that Datasette is pretty inconsistent with how column quoting works: https://datasette.io/tutorials/learn-sql It has examples of each of Datasette should generate SQL as consistently as possible to support learners. That tutorial should also provide a tiny bit of extra information about what's going on here. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1702/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1197925865 | I_kwDOBm6k_c5HZuXp | 1704 | File PRs against incompatible plugins pinning to datasette<1.0 | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 0 | 2022-04-08T23:15:30Z | 2022-04-08T23:15:30Z | OWNER | As part of the preparation for the 1.0 release, test all existing known plugins against the alpha. For any that break, submit a PR suggesting they pin to a version <1.0 - and include a link to the documentation on how to upgrade the plugin for 1.0. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1704/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1197926598 | I_kwDOBm6k_c5HZujG | 1705 | How to upgrade your plugin for 1.0 documentation | simonw 9599 | open | 0 | Datasette 1.0a-next 8755003 | 1 | 2022-04-08T23:16:47Z | 2022-12-13T05:29:05Z | OWNER | Among other things, needed by: - #1704 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1705/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1198822563 | I_kwDOBm6k_c5HdJSj | 1706 | [feature] immutable mode for a directory, not just individual sqlite file | hydrosquall 9020979 | open | 0 | 4 | 2022-04-10T00:50:57Z | 2022-12-09T19:11:40Z | CONTRIBUTOR | Motivation
ProposalImmutable flag works for both single files and directories |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1706/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1200224939 | I_kwDOBm6k_c5Hifqr | 1707 | [feature] expanded detail page | fgregg 536941 | open | 0 | 1 | 2022-04-11T16:29:17Z | 2022-04-11T16:33:00Z | CONTRIBUTOR | Right now, if click on the detail page for a row you get the info for the row and links to related tables:
It would be very cool if there was an option to expand the rows of the related tables from within this detail view. If you had that then datasette could fulfill a pretty common use case where you want to search for an entity and get a consolidate detail view about what you know about that entity. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1707/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1200649124 | I_kwDOBm6k_c5HkHOk | 1708 | Datasette 1.0 alpha upcoming release notes | simonw 9599 | open | 0 | Datasette 1.0a-next 8755003 | 2 | 2022-04-11T22:57:12Z | 2022-12-13T05:29:06Z | OWNER | I'm going to try writing the release notes first, to see if that helps unblock me. ⚠️ Any release notes in this issue are a draft, and should not be treated as the real thing ⚠️ |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1708/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1200649502 | I_kwDOBm6k_c5HkHUe | 1709 | Redesigned JSON API with ?_extra= parameters | simonw 9599 | open | 0 | Datasette 1.0a-next 8755003 | 1 | 2022-04-11T22:57:49Z | 2022-12-13T05:29:06Z | OWNER | This will be the single biggest breaking change for the 1.0 release. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1709/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1200650491 | I_kwDOBm6k_c5HkHj7 | 1711 | Template context powered entirely by the JSON API format | simonw 9599 | open | 0 | Datasette 1.0a-next 8755003 | 1 | 2022-04-11T22:59:27Z | 2022-12-13T05:29:06Z | OWNER | Datasette 1.0 will have a stable template context. I'm going to achieve this by refactoring the templates to work only with keys returned by the API (or some of its extras) - then the API documentation will double up as template documentation. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1711/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1203943272 | I_kwDOBm6k_c5Hwrdo | 1713 | Datasette feature for publishing snapshots of query results | simonw 9599 | open | 0 | 5 | 2022-04-14T01:42:00Z | 2022-07-04T05:16:35Z | OWNER | https://twitter.com/simonw/status/1514392335718645760
A lot of people said they would find this useful. Probably going to build this as a plugin. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1713/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1221849746 | I_kwDOBm6k_c5I0_KS | 1732 | Custom page variables aren't decoded | tannewt 52649 | open | 0 | 2 | 2022-04-30T14:55:46Z | 2022-05-03T01:50:45Z | NONE | I have a page Datasette should unescape the url component before passing them into the template. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1732/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1216436131 | I_kwDOBm6k_c5IgVej | 1721 | Implement plugin hooks: `register_table_extras`, `register_row_extras`, `register_query_extras` | simonw 9599 | open | 0 | Datasette 1.0a-next 8755003 | 0 | 2022-04-26T20:21:49Z | 2022-12-13T05:29:07Z | OWNER | Designed in: - #1720 Part of: - #262 - #1709 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1721/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1216479167 | I_kwDOBm6k_c5Igf-_ | 1722 | `db.primary_keys()` and `db.table_columns()` don't show up in traces | simonw 9599 | open | 0 | 0 | 2022-04-26T21:08:36Z | 2022-04-26T21:08:36Z | OWNER | Noticed this while working on: - #1715 This code here isn't showing up in traces: https://github.com/simonw/datasette/blob/579f59dcec43a91dd7d404e00b87a00afd8515f2/datasette/views/table.py#L218-L220 Because those functions don't use the regular trace-instrumented |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1722/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1216622905 | I_kwDOBm6k_c5IhDE5 | 1725 | Performance question - what is happening in this gap? | simonw 9599 | open | 0 | 0 | 2022-04-27T00:21:11Z | 2022-04-27T00:21:11Z | OWNER | Trace from https://latest-with-plugins.datasette.io/github/commits?_facet=repo&_trace=1&_facet=committer
What's going on in that gap? Can I improve the tracing output to show some non-SQL queries to figure that out? |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1725/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1217014076 | I_kwDOBm6k_c5Iiik8 | 1726 | Security page in the documentation | simonw 9599 | open | 0 | 0 | 2022-04-27T08:43:30Z | 2022-04-27T08:43:30Z | OWNER | A page talking about how to run Datasette securely, and security concerns to take into account. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1726/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1217759117 | I_kwDOBm6k_c5IlYeN | 1727 | Research: demonstrate if parallel SQL queries are worthwhile | simonw 9599 | open | 0 | 32 | 2022-04-27T18:54:21Z | 2022-09-26T14:48:31Z | OWNER | I added parallel SQL query execution here: - https://github.com/simonw/datasette/issues/1723 My hunch is that this will take advantage of multiple cores, since Python's I'd really like to prove this is the case though. Just not sure how to do it! Larger question: is this performance optimization actually improving performance at all? Under what circumstances is it worthwhile? |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1727/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1219385669 | I_kwDOBm6k_c5IrllF | 1729 | Implement ?_extra and new API design for TableView | simonw 9599 | open | 0 | Datasette 1.0a-next 8755003 | 12 | 2022-04-28T22:28:14Z | 2022-12-13T05:29:07Z | OWNER | Part of: - #262 - #1518 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1729/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
|||||||
| 1219398983 | I_kwDOBm6k_c5Iro1H | 1730 | SQL tracing should much more closely track the SQL query execution | simonw 9599 | open | 0 | 0 | 2022-04-28T22:41:04Z | 2022-04-28T22:41:10Z | OWNER | In #1727 I realized that the SQL tracing was measuring a whole bunch of stuff outside of the SQL query itself. I started experimenting with this fix for that but it didn't work - I got back an empty JSON array of traces for some reason: ```diff diff --git a/datasette/database.py b/datasette/database.py index ba594a8..d7f9172 100644 --- a/datasette/database.py +++ b/datasette/database.py @@ -7,7 +7,7 @@ import sys import threading import uuid -from .tracer import trace +from .tracer import trace, trace_child_tasks from .utils import ( detect_fts, detect_primary_keys, @@ -207,30 +207,31 @@ class Database: time_limit_ms = custom_time_limit
Originally posted by @simonw in https://github.com/simonw/datasette/issues/1727#issuecomment-1111602802 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1730/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1237586379 | I_kwDOBm6k_c5JxBHL | 1742 | ?_trace=1 fails with datasette-geojson for some reason | simonw 9599 | open | 0 | 4 | 2022-05-16T19:06:05Z | 2022-05-16T19:42:13Z | OWNER | view-source:https://calands.datasettes.com/calands/CPAD_2020a_SuperUnits.geojson?_sort=id&id__exact=4&_labels=on&_trace=1 is showing me a blank page. |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1742/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
||||||||
| 1237871948 | I_kwDOBm6k_c5JyG1M | 1743 | `datasette.utils.to_css_class()` should be a documented internal | simonw 9599 | open | 0 | 0 | 2022-05-16T23:57:26Z | 2022-05-16T23:57:26Z | OWNER | Because I'm using it in this plugin: - https://github.com/simonw/datasette-upload-dbs/issues/1 |
datasette 107914493 | issue | {
"url": "https://api.github.com/repos/simonw/datasette/issues/1743/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |


















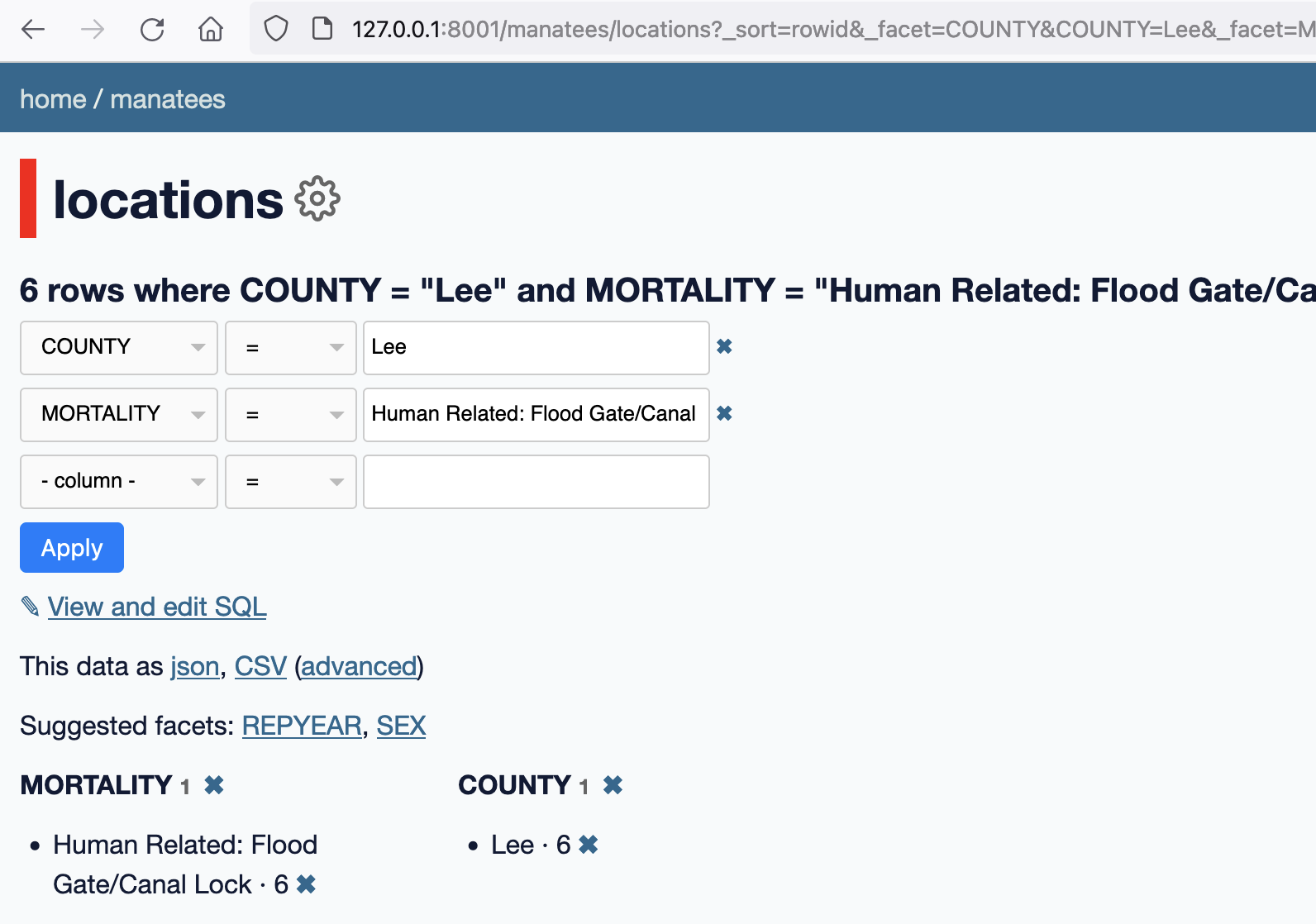



{kind=link}
Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issues] (
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[number] INTEGER,
[title] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[state] TEXT,
[locked] INTEGER,
[assignee] INTEGER REFERENCES [users]([id]),
[milestone] INTEGER REFERENCES [milestones]([id]),
[comments] INTEGER,
[created_at] TEXT,
[updated_at] TEXT,
[closed_at] TEXT,
[author_association] TEXT,
[pull_request] TEXT,
[body] TEXT,
[repo] INTEGER REFERENCES [repos]([id]),
[type] TEXT
, [active_lock_reason] TEXT, [performed_via_github_app] TEXT, [reactions] TEXT, [draft] INTEGER, [state_reason] TEXT);
CREATE INDEX [idx_issues_repo]
ON [issues] ([repo]);
CREATE INDEX [idx_issues_milestone]
ON [issues] ([milestone]);
CREATE INDEX [idx_issues_assignee]
ON [issues] ([assignee]);
CREATE INDEX [idx_issues_user]
ON [issues] ([user]);