issue_comments
996 rows where author_association = "NONE" sorted by html_url
This data as json, CSV (advanced)
issue >30
- Transformation type `--type DATETIME` 14
- link_or_copy_directory() error - Invalid cross-device link 13
- .json and .csv exports fail to apply base_url 11
- base_url configuration setting 10
- Extract columns cannot create foreign key relation: sqlite3.OperationalError: table sqlite_master may not be modified 10
- Documentation with recommendations on running Datasette in production without using Docker 9
- JavaScript plugin hooks mechanism similar to pluggy 9
- Add GraphQL endpoint 8
- Call for birthday presents: if you're using Datasette, let us know how you're using it here 8
- Full text search of all tables at once? 7
- Populate "endpoint" key in ASGI scope 7
- Incorrect URLs when served behind a proxy with base_url set 6
- publish heroku does not work on Windows 10 6
- Improve the display of facets information 6
- De-tangling Metadata before Datasette 1.0 6
- Metadata should be a nested arbitrary KV store 5
- Windows installation error 5
- Ways to improve fuzzy search speed on larger data sets? 5
- Redesign default .json format 5
- Plugin hook for dynamic metadata 5
- i18n support 5
- datasette --root running in Docker doesn't reliably show the magic URL 5
- Datasette serve should accept paths/URLs to CSVs and other file formats 4
- Mechanism for ranking results from SQLite full-text search 4
- Port Datasette to ASGI 4
- Wildcard support in query parameters 4
- Handle really wide tables better 4
- Prototoype for Datasette on PostgreSQL 4
- Support column descriptions in metadata.json 4
- .delete_where() does not auto-commit (unlike .insert() or .upsert()) 4
- …
| id | html_url ▼ | issue_url | node_id | user | created_at | updated_at | author_association | body | reactions | issue | performed_via_github_app |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 941274088 | https://github.com/dogsheep/swarm-to-sqlite/issues/12#issuecomment-941274088 | https://api.github.com/repos/dogsheep/swarm-to-sqlite/issues/12 | IC_kwDODD6af844GrPo | fs111 33631 | 2021-10-12T18:31:57Z | 2021-10-12T18:31:57Z | NONE | I am running into the same problem. Is there any workaround? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
403 when getting token 951817328 | |
| 1251845216 | https://github.com/dogsheep/twitter-to-sqlite/issues/31#issuecomment-1251845216 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/31 | IC_kwDODEm0Qs5KnaRg | dckc 150986 | 2022-09-20T05:05:03Z | 2022-09-20T05:05:03Z | NONE | yay! Thanks a bunch for the The twitter "Download an archive of your data" feature doesn't include who I follow, so this is particularly handy. The whole Dogsheep thing is great :) I've written about similar things under cloud-services: - 2021: Closet Librarian Approach to Cloud Services - 2015: jukekb - Browse iTunes libraries and upload playlists to Google Music |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"friends" command (similar to "followers") 520508502 | |
| 645515103 | https://github.com/dogsheep/twitter-to-sqlite/issues/47#issuecomment-645515103 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/47 | MDEyOklzc3VlQ29tbWVudDY0NTUxNTEwMw== | hpk42 73579 | 2020-06-17T17:30:01Z | 2020-06-17T17:30:01Z | NONE | It's the one with python3.7:: On Wed, Jun 17, 2020 at 10:24 -0700, Simon Willison wrote:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Fall back to FTS4 if FTS5 is not available 639542974 | |
| 691501132 | https://github.com/dogsheep/twitter-to-sqlite/issues/50#issuecomment-691501132 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/50 | MDEyOklzc3VlQ29tbWVudDY5MTUwMTEzMg== | bcongdon 706257 | 2020-09-12T14:48:10Z | 2020-09-12T14:48:10Z | NONE | This seems to be an issue even with larger values of
|
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
favorites --stop_after=N stops after min(N, 200) 698791218 | |
| 729484478 | https://github.com/dogsheep/twitter-to-sqlite/issues/52#issuecomment-729484478 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/52 | MDEyOklzc3VlQ29tbWVudDcyOTQ4NDQ3OA== | fatihky 4169772 | 2020-11-18T07:12:45Z | 2020-11-18T07:12:45Z | NONE | I'm so sorry that you already have |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Discussion: Adding support for fetching only fresh tweets 745393298 | |
| 748436453 | https://github.com/dogsheep/twitter-to-sqlite/issues/53#issuecomment-748436453 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/53 | MDEyOklzc3VlQ29tbWVudDc0ODQzNjQ1Mw== | anotherjesse 27 | 2020-12-19T07:47:01Z | 2020-12-19T07:47:01Z | NONE | I think this should probably be closed as won't fix. Attempting to make a patch for this I realized that the since_id would limit to tweets posted since that since_id, not when it was favorited. So favoriting something in the older would be missed if you used Better to just use |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
--since support for favorites 771324837 | |
| 1370786026 | https://github.com/dogsheep/twitter-to-sqlite/issues/54#issuecomment-1370786026 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/54 | IC_kwDODEm0Qs5RtIjq | swyxio 6764957 | 2023-01-04T11:06:44Z | 2023-01-04T11:06:44Z | NONE | as of 2023 it appears that this seems an impossible task with twitter liable to switch this around every other day |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Archive import appears to be broken on recent exports 779088071 | |
| 767888743 | https://github.com/dogsheep/twitter-to-sqlite/issues/54#issuecomment-767888743 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/54 | MDEyOklzc3VlQ29tbWVudDc2Nzg4ODc0Mw== | henry501 19328961 | 2021-01-26T23:07:41Z | 2021-01-26T23:07:41Z | NONE | My import got much further with the applied fixes than 0.21.3, but not 100%. I do appear to have all of the tweets imported at least. Not sure when I'll have a chance to look further to try to fix or see what didn't make it into the import. Here's my output: ``` direct-messages-group: not yet implemented branch-links: not yet implemented periscope-expired-broadcasts: not yet implemented direct-messages: not yet implemented mute: not yet implemented periscope-comments-made-by-user: not yet implemented periscope-ban-information: not yet implemented periscope-profile-description: not yet implemented screen-name-change: not yet implemented manifest: not yet implemented fleet: not yet implemented user-link-clicks: not yet implemented periscope-broadcast-metadata: not yet implemented contact: not yet implemented fleet-mute: not yet implemented device-token: not yet implemented protected-history: not yet implemented direct-message-mute: not yet implemented Traceback (most recent call last): File "/Users/henry/.local/share/virtualenvs/python-sqlite-testing-mF3G2xKl/bin/twitter-to-sqlite", line 33, in <module> sys.exit(load_entry_point('twitter-to-sqlite==0.21.3', 'console_scripts', 'twitter-to-sqlite')()) File "/Users/henry/.local/share/virtualenvs/python-sqlite-testing-mF3G2xKl/lib/python3.9/site-packages/click/core.py", line 829, in call return self.main(args, kwargs) File "/Users/henry/.local/share/virtualenvs/python-sqlite-testing-mF3G2xKl/lib/python3.9/site-packages/click/core.py", line 782, in main rv = self.invoke(ctx) File "/Users/henry/.local/share/virtualenvs/python-sqlite-testing-mF3G2xKl/lib/python3.9/site-packages/click/core.py", line 1259, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/Users/henry/.local/share/virtualenvs/python-sqlite-testing-mF3G2xKl/lib/python3.9/site-packages/click/core.py", line 1066, in invoke return ctx.invoke(self.callback, ctx.params) File "/Users/henry/.local/share/virtualenvs/python-sqlite-testing-mF3G2xKl/lib/python3.9/site-packages/click/core.py", line 610, in invoke return callback(args, **kwargs) File "/Users/henry/.local/share/virtualenvs/python-sqlite-testing-mF3G2xKl/lib/python3.9/site-packages/twitter_to_sqlite/cli.py", line 772, in import_ archive.import_from_file(db, filepath.name, open(filepath, "rb").read()) File "/Users/henry/.local/share/virtualenvs/python-sqlite-testing-mF3G2xKl/lib/python3.9/site-packages/twitter_to_sqlite/archive.py", line 233, in import_from_file to_insert = transformer(data) File "/Users/henry/.local/share/virtualenvs/python-sqlite-testing-mF3G2xKl/lib/python3.9/site-packages/twitter_to_sqlite/archive.py", line 21, in callback return {filename: [fn(item) for item in data]} File "/Users/henry/.local/share/virtualenvs/python-sqlite-testing-mF3G2xKl/lib/python3.9/site-packages/twitter_to_sqlite/archive.py", line 21, in <listcomp> return {filename: [fn(item) for item in data]} File "/Users/henry/.local/share/virtualenvs/python-sqlite-testing-mF3G2xKl/lib/python3.9/site-packages/twitter_to_sqlite/archive.py", line 88, in ageinfo return item["ageMeta"]["ageInfo"] KeyError: 'ageInfo' ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Archive import appears to be broken on recent exports 779088071 | |
| 927312650 | https://github.com/dogsheep/twitter-to-sqlite/issues/54#issuecomment-927312650 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/54 | IC_kwDODEm0Qs43RasK | danp 2182 | 2021-09-26T14:09:51Z | 2021-09-26T14:09:51Z | NONE | Similar trouble with ageinfo using 0.22. Here's what my ageinfo.js file looks like:
Commenting out the registration for ageinfo in archive.py gets my archive to import. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Archive import appears to be broken on recent exports 779088071 | |
| 769973212 | https://github.com/dogsheep/twitter-to-sqlite/issues/56#issuecomment-769973212 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/56 | MDEyOklzc3VlQ29tbWVudDc2OTk3MzIxMg== | gsajko 42315895 | 2021-01-29T18:29:02Z | 2021-01-29T18:31:55Z | NONE | I think it was with from cron tab
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Not all quoted statuses get fetched? 796736607 | |
| 772408273 | https://github.com/dogsheep/twitter-to-sqlite/issues/56#issuecomment-772408273 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/56 | MDEyOklzc3VlQ29tbWVudDc3MjQwODI3Mw== | gsajko 42315895 | 2021-02-03T10:36:36Z | 2021-02-03T10:36:36Z | NONE | I figured it out. Those tweets are in database, because somebody quote tweeted them, or retweeted them. And if you grab quoted tweet or reweeted tweet from other tweet json, It doesn't grab all of the details. So if someone quote tweeted a quote tweet, the second quote tweet won't have |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Not all quoted statuses get fetched? 796736607 | |
| 860063190 | https://github.com/dogsheep/twitter-to-sqlite/issues/57#issuecomment-860063190 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/57 | MDEyOklzc3VlQ29tbWVudDg2MDA2MzE5MA== | stiles 232237 | 2021-06-12T14:46:44Z | 2021-06-12T14:46:44Z | NONE | I'm having the same issue (same versions of python and twitter-to-sqlite). It's the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Error: Use either --since or --since_id, not both 907645813 | |
| 1279249898 | https://github.com/dogsheep/twitter-to-sqlite/issues/60#issuecomment-1279249898 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/60 | IC_kwDODEm0Qs5MP83q | chapmanjacobd 7908073 | 2022-10-14T16:58:26Z | 2022-10-14T16:58:26Z | NONE | You could try using Here is a guide: https://github.com/chapmanjacobd/lb/blob/main/Windows.md#prep |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Execution on Windows 1063982712 | |
| 1297201971 | https://github.com/dogsheep/twitter-to-sqlite/issues/61#issuecomment-1297201971 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/61 | IC_kwDODEm0Qs5NUbsz | Profpatsch 3153638 | 2022-10-31T14:47:58Z | 2022-10-31T14:47:58Z | NONE | There’s also a limit of 3200 tweets. I wonder if that can be circumvented somehow. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Data Pull fails for "Essential" level access to the Twitter API (for Documentation) 1077560091 | |
| 1001222213 | https://github.com/dogsheep/twitter-to-sqlite/issues/62#issuecomment-1001222213 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/62 | IC_kwDODEm0Qs47rXBF | swyxio 6764957 | 2021-12-26T17:59:25Z | 2021-12-26T17:59:25Z | NONE | just confirmed that this error does not occur when i use my public main account. gets more interesting! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
KeyError: 'created_at' for private accounts? 1088816961 | |
| 1049775451 | https://github.com/dogsheep/twitter-to-sqlite/issues/62#issuecomment-1049775451 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/62 | IC_kwDODEm0Qs4-kk1b | miuku 43036882 | 2022-02-24T11:43:31Z | 2022-02-24T11:43:31Z | NONE | i seem to have fixed this issue by applying for elevated API access |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
KeyError: 'created_at' for private accounts? 1088816961 | |
| 1050123919 | https://github.com/dogsheep/twitter-to-sqlite/issues/62#issuecomment-1050123919 | https://api.github.com/repos/dogsheep/twitter-to-sqlite/issues/62 | IC_kwDODEm0Qs4-l56P | swyxio 6764957 | 2022-02-24T18:10:18Z | 2022-02-24T18:10:18Z | NONE | gonna close this for now since i'm not actively working on it. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
KeyError: 'created_at' for private accounts? 1088816961 | |
| 344864254 | https://github.com/simonw/datasette/issues/100#issuecomment-344864254 | https://api.github.com/repos/simonw/datasette/issues/100 | MDEyOklzc3VlQ29tbWVudDM0NDg2NDI1NA== | coisnepe 13304454 | 2017-11-16T09:25:10Z | 2017-11-16T09:25:10Z | NONE | @simonw I see. I upgraded sanic-jinja2 and jinja2: it now works flawlessly. Thank you! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
TemplateAssertionError: no filter named 'tojson' 274160723 | |
| 706302863 | https://github.com/simonw/datasette/issues/1003#issuecomment-706302863 | https://api.github.com/repos/simonw/datasette/issues/1003 | MDEyOklzc3VlQ29tbWVudDcwNjMwMjg2Mw== | mhalle 649467 | 2020-10-09T17:17:06Z | 2020-10-09T17:17:06Z | NONE | I agree on the descriptive and python-consistent naming. There is already a tojson, but frankly i find the "to" and "from" confusing in a text templating language where what's a string and what's data isn't 100% transparent. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
from_json jinja2 filter 718238967 | |
| 344597274 | https://github.com/simonw/datasette/issues/101#issuecomment-344597274 | https://api.github.com/repos/simonw/datasette/issues/101 | MDEyOklzc3VlQ29tbWVudDM0NDU5NzI3NA== | eaubin 450244 | 2017-11-15T13:48:55Z | 2017-11-15T13:48:55Z | NONE | This is a duplicate of https://github.com/simonw/datasette/issues/100 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
TemplateAssertionError: no filter named 'tojson' 274161964 | |
| 712397537 | https://github.com/simonw/datasette/issues/1032#issuecomment-712397537 | https://api.github.com/repos/simonw/datasette/issues/1032 | MDEyOklzc3VlQ29tbWVudDcxMjM5NzUzNw== | saulpw 236498 | 2020-10-19T19:37:55Z | 2020-10-19T19:37:55Z | NONE | python-dateutil is awesome, but it can only guess at one date at a time. So if you have a column of dates that are (presumably) in the same format, it can't use the full set of dates to deduce the format. Also, once it has parsed a date, you can't get the format it used, whether to parse or render other dates. These limitations prevent it from being a silver bullet for date parsing, though they're not enough for me to stop using it! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Bring date parsing into Datasette core 724878151 | |
| 762385981 | https://github.com/simonw/datasette/issues/1036#issuecomment-762385981 | https://api.github.com/repos/simonw/datasette/issues/1036 | MDEyOklzc3VlQ29tbWVudDc2MjM4NTk4MQ== | philshem 4997607 | 2021-01-18T17:32:13Z | 2021-01-18T17:34:50Z | NONE | Hi Simon Just finding this old issue regarding downloading blobs. Nice work!
As a feature request, maybe it would be possible to assign a blob column as a certain data type (e.g. I guess the column blob-type definition could fit into this dropdown selection:
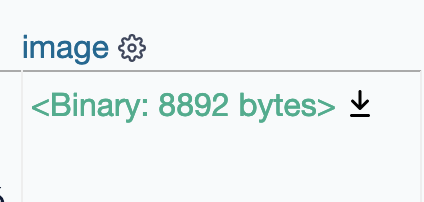
Let me know if I should open a new issue with a feature request. (This could slowly go in the direction of displaying image blob-types in the browser.) Thanks for the great tool! edit: just reading the rest of the twitter thread: https://twitter.com/simonw/status/1318685933256855552 perhaps this is already possible in some form with the plugin datasette-media: https://github.com/simonw/datasette-media |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Make it possible to download BLOB data from the Datasette UI 725996507 | |
| 762391426 | https://github.com/simonw/datasette/issues/1036#issuecomment-762391426 | https://api.github.com/repos/simonw/datasette/issues/1036 | MDEyOklzc3VlQ29tbWVudDc2MjM5MTQyNg== | philshem 4997607 | 2021-01-18T17:45:00Z | 2021-01-18T17:45:00Z | NONE | It might be possible with this library: https://docs.python.org/3/library/imghdr.html quick test of the downloaded blob: ```
The output plugin would be cool. I'll look into making my first datasette plugin. I'm also imagining displaying the image in the browser -- but that would be a step 2. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Make it possible to download BLOB data from the Datasette UI 725996507 | |
| 718317997 | https://github.com/simonw/datasette/issues/1050#issuecomment-718317997 | https://api.github.com/repos/simonw/datasette/issues/1050 | MDEyOklzc3VlQ29tbWVudDcxODMxNzk5Nw== | thadk 283343 | 2020-10-29T02:24:50Z | 2020-10-29T02:29:24Z | NONE | Unsolicited feedback for an unreleased feature of the current unreleased GitHub version (I casually wanted to access a blob row) – the existing #1036 route doesn't support special characters in database or table names (e.g. Also I got this error/crash with my blob and wasn't able to get the file: https://gist.github.com/thadk/28ac32af0e88747ce9056c90b0b19d34 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Switch to .blob render extension for BLOB downloads 729057388 | |
| 721547177 | https://github.com/simonw/datasette/issues/1082#issuecomment-721547177 | https://api.github.com/repos/simonw/datasette/issues/1082 | MDEyOklzc3VlQ29tbWVudDcyMTU0NzE3Nw== | justmars 39538958 | 2020-11-04T06:52:30Z | 2020-11-04T06:53:16Z | NONE | I think I tried the same db size on the following scenarios in Digital Ocean: 1. Basic ($5/month) with 512MB RAM 2. Basic ($10/month) with 1GB RAM 3. Pro ($12/month) with 1GB RAM All such attempts conked out with "out of memory" errors |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
DigitalOcean buildpack memory errors for large sqlite db? 735852274 | |
| 726798745 | https://github.com/simonw/datasette/issues/1091#issuecomment-726798745 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDcyNjc5ODc0NQ== | tballison 6739646 | 2020-11-13T14:35:22Z | 2020-11-13T14:35:22Z | NONE | I'm starting this with docker like so:
I'm not doing any templating or anything else custom. Apropos of nothing, I swapped out a simpler db, so this query should now work: |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 726801731 | https://github.com/simonw/datasette/issues/1091#issuecomment-726801731 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDcyNjgwMTczMQ== | tballison 6739646 | 2020-11-13T14:40:56Z | 2020-11-13T14:40:56Z | NONE | My headers aren't clickable/sortable with custom sql, but I think that's by design. In the default view, https://corpora.tika.apache.org/datasette/file_profiles/file_profiles, ah, y, now I see that the headers should be sortable, but you're right the base_url is not applied. base_url works with "View and Edit SQL" and with "(advanced)" As you point out, does not work with the export csv, json, other or with the "Next page" navigational button at the bottom. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 729018386 | https://github.com/simonw/datasette/issues/1091#issuecomment-729018386 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDcyOTAxODM4Ng== | tballison 6739646 | 2020-11-17T15:48:58Z | 2020-11-17T15:48:58Z | NONE | I don't think we are, but I'll check with Maruan. I think this is the relevant part of our config? ``` Alias "/base/" "/usr/share/corpora/" <Directory "/usr/share/corpora/"> Options +Indexes -Multiviews AllowOverride None </Directory> ProxyPreserveHost On ProxyPass /datasette http://0.0.0.0:8001 ProxyPassReverse /datasette http://0.0.0.0:8001 </VirtualHost> ``` |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 729045320 | https://github.com/simonw/datasette/issues/1091#issuecomment-729045320 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDcyOTA0NTMyMA== | tballison 6739646 | 2020-11-17T16:31:00Z | 2020-11-17T16:31:00Z | NONE | We're using mod_proxy. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 741804334 | https://github.com/simonw/datasette/issues/1091#issuecomment-741804334 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc0MTgwNDMzNA== | tballison 6739646 | 2020-12-09T14:26:05Z | 2020-12-09T14:26:05Z | NONE | Anything we can do to help debug this? Thank you, again! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 742001510 | https://github.com/simonw/datasette/issues/1091#issuecomment-742001510 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc0MjAwMTUxMA== | tballison 6739646 | 2020-12-09T19:36:42Z | 2020-12-09T19:38:04Z | NONE | I don't think this fixes it:
And I confirmed that I actually restarted the server. :rofl: |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
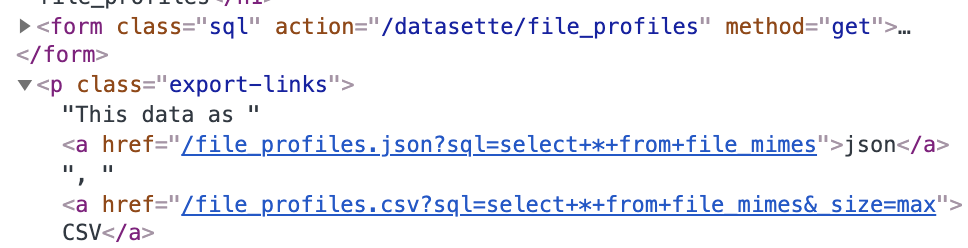
| 742010306 | https://github.com/simonw/datasette/issues/1091#issuecomment-742010306 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc0MjAxMDMwNg== | tballison 6739646 | 2020-12-09T19:53:18Z | 2020-12-09T19:59:52Z | NONE | I can't imagine this helps (esp. given your point about potential rewrites), but you can see that /datasette/ was correctly added to the sql form, but not to the "export-links"
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 756425587 | https://github.com/simonw/datasette/issues/1091#issuecomment-756425587 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc1NjQyNTU4Nw== | henry501 19328961 | 2021-01-07T22:27:19Z | 2021-01-07T22:27:19Z | NONE | I found this issue while troubleshooting the same behavior with an nginx reverse proxy. The solution was to make sure I set:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 758280611 | https://github.com/simonw/datasette/issues/1091#issuecomment-758280611 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc1ODI4MDYxMQ== | tballison 6739646 | 2021-01-11T23:06:10Z | 2021-01-11T23:06:10Z | NONE | +1 Yep! Fixes it. If I navigate to https://corpora.tika.apache.org/datasette, I get a 404 (database not found: datasette), but if I navigate to https://corpora.tika.apache.org/datasette/file_profiles/, everything WORKS! Thank you! |
{
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 758448525 | https://github.com/simonw/datasette/issues/1091#issuecomment-758448525 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc1ODQ0ODUyNQ== | henry501 19328961 | 2021-01-12T06:55:08Z | 2021-01-12T06:55:08Z | NONE | Great, really happy I could help! Reverse proxies get tricky. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 758668359 | https://github.com/simonw/datasette/issues/1091#issuecomment-758668359 | https://api.github.com/repos/simonw/datasette/issues/1091 | MDEyOklzc3VlQ29tbWVudDc1ODY2ODM1OQ== | tballison 6739646 | 2021-01-12T13:52:29Z | 2021-01-12T13:52:29Z | NONE | Y, thank you to both of you! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
.json and .csv exports fail to apply base_url 742011049 | |
| 731260091 | https://github.com/simonw/datasette/issues/1094#issuecomment-731260091 | https://api.github.com/repos/simonw/datasette/issues/1094 | MDEyOklzc3VlQ29tbWVudDczMTI2MDA5MQ== | bapowell 4808085 | 2020-11-20T16:11:29Z | 2020-11-20T16:11:29Z | NONE | I can confirm this issue, running version 0.51.1 under Windows. Fixed by commenting out the following line near the top of datasette\utils\asgi.py :
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
import EX_CANTCREAT means datasette fails to work on Windows 743011397 | |
| 736005833 | https://github.com/simonw/datasette/issues/1116#issuecomment-736005833 | https://api.github.com/repos/simonw/datasette/issues/1116 | MDEyOklzc3VlQ29tbWVudDczNjAwNTgzMw== | nattaylor 2789593 | 2020-11-30T19:54:39Z | 2020-11-30T19:54:39Z | NONE | @simonw thanks for investigating so quickly. If it is undesirable to change that hidden behavior, maybe something like this is a suitable workaround:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
GENERATED column support 753668177 | |
| 742260116 | https://github.com/simonw/datasette/issues/1134#issuecomment-742260116 | https://api.github.com/repos/simonw/datasette/issues/1134 | MDEyOklzc3VlQ29tbWVudDc0MjI2MDExNg== | clausjuhl 2181410 | 2020-12-10T05:57:17Z | 2020-12-10T05:57:17Z | NONE | Hi Simon Thank you for the quick fix! And glad you like our use of Datasette (launches 1. january 2021). It's a site that currently (more to come) makes all minutes and their annexes from Aarhus City Council and the major committees (1997-2019) available to the public. So we're putting Datasette to good use :) |
{
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} |
"_searchmode=raw" throws an index out of range error when combined with "_search_COLUMN" 760312579 | |
| 743732440 | https://github.com/simonw/datasette/issues/1142#issuecomment-743732440 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0MzczMjQ0MA== | nitinpaultifr 6622733 | 2020-12-12T09:56:40Z | 2020-12-12T09:56:40Z | NONE | 'Include all rows' seem like a fairly obvious alternative |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 743998792 | https://github.com/simonw/datasette/issues/1142#issuecomment-743998792 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0Mzk5ODc5Mg== | nitinpaultifr 6622733 | 2020-12-13T12:14:06Z | 2020-12-13T12:14:06Z | NONE | Agreed, it would definitely provide better controls. However, I do feel it makes for a bit of inconsistent UX for the 'Advanced export' section, with links to download for JSON, checkboxes and radio buttons + button to download for CSV. Do you think this example makes the UX a bit nicer/consistent?
I could give it a try if you'd like but I've never contributed to an actual project! |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 744522099 | https://github.com/simonw/datasette/issues/1142#issuecomment-744522099 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0NDUyMjA5OQ== | nitinpaultifr 6622733 | 2020-12-14T15:37:47Z | 2020-12-14T15:37:47Z | NONE | Alright I could give it a try! This might be a stupid question, can you tell me how to run the server from my fork? So that I can test the changes? |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 745162571 | https://github.com/simonw/datasette/issues/1142#issuecomment-745162571 | https://api.github.com/repos/simonw/datasette/issues/1142 | MDEyOklzc3VlQ29tbWVudDc0NTE2MjU3MQ== | nitinpaultifr 6622733 | 2020-12-15T09:22:58Z | 2020-12-15T09:22:58Z | NONE | You're right, probably more straightforward to have the links for JSON. I was imagining to toggle the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
"Stream all rows" is not at all obvious 763361458 | |
| 744618787 | https://github.com/simonw/datasette/issues/1143#issuecomment-744618787 | https://api.github.com/repos/simonw/datasette/issues/1143 | MDEyOklzc3VlQ29tbWVudDc0NDYxODc4Nw== | yurivish 114388 | 2020-12-14T18:15:00Z | 2020-12-15T02:21:53Z | NONE | From a quick look at the README, it does seem to do everything I need, thanks! I think the argument for inclusion in core is to lower the chances of unwanted data access. A local server can be accessed by anybody who can make an HTTP request to your computer regardless of CORS rules, but the default That's probably not what people typically intend, particularly when the data is of a sensitive nature. A default of requiring the user to specify the origin (allowing |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
More flexible CORS support in core, to encourage good security practices 764059235 | |
| 744489028 | https://github.com/simonw/datasette/issues/1144#issuecomment-744489028 | https://api.github.com/repos/simonw/datasette/issues/1144 | MDEyOklzc3VlQ29tbWVudDc0NDQ4OTAyOA== | MarkusH 475613 | 2020-12-14T14:47:11Z | 2020-12-14T14:47:11Z | NONE | Thanks for opening the issue, @simonw. Let me elaborate on my Tweets. datasette-chartjs provides drop down lists to pick the chart visualization (e.g. bar, line, doughnut, pie, ...) as well as the column used for the "x axis" (e.g. time). A user can change the values on-demand. The chart will be redrawn w/o querying the database again. However, if a user wants to change the underlying query, they will use the SQL field provided by datasette or any of the other datasette built-in features to amend a query. In order to maintain a user's selections for the plugin, datasette-chartjs copies some parts of datasette-vega which persist the chosen visualization and column in the hash part of a URL (the stuff behind the Additionally, datasette-vega and datasette-chartjs need to make sure to include the hash in all links and forms that cause a reload of the page. This is, such that the config persists between clicks. This ticket is about moving thes parts into datasette that provide the functionality to do so. This includes:
There's another, optional, feature that we might want to think about during the design phase: the scope of the config. Links within a datasette instance have 1 of 3 scopes:
When updating the links and forms as pointed out in 3. above, it might be worth considering which links need to be updated. I could imagine a plugin that wants to persist some setting across all tables within a database but another setting only within a table. |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
JavaScript to help plugins interact with the fragment part of the URL 765637324 | |
| 751476406 | https://github.com/simonw/datasette/issues/1150#issuecomment-751476406 | https://api.github.com/repos/simonw/datasette/issues/1150 | MDEyOklzc3VlQ29tbWVudDc1MTQ3NjQwNg== | noklam 18221871 | 2020-12-27T14:51:39Z | 2020-12-27T14:51:39Z | NONE | I like the idea of _internal, it's a nice way to get a data catalog quickly. I wonder if this trick applies to db other than SQLite. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Maintain an in-memory SQLite table of connected databases and their tables 770436876 | |
| 753033121 | https://github.com/simonw/datasette/issues/1165#issuecomment-753033121 | https://api.github.com/repos/simonw/datasette/issues/1165 | MDEyOklzc3VlQ29tbWVudDc1MzAzMzEyMQ== | dracos 154364 | 2020-12-31T19:33:47Z | 2020-12-31T19:33:47Z | NONE | Sorry to go on about it, but it's my only example ;) And thought it might be of interest/use. Here is FixMyStreet's Cypress workflow https://github.com/mysociety/fixmystreet/blob/master/.github/workflows/cypress.yml with the master script that sets up server etc at https://github.com/mysociety/fixmystreet/blob/master/bin/browser-tests (that has features such as working inside/outside Vagrant, and can do JS code coverage) and then the tests are at https://github.com/mysociety/fixmystreet/tree/master/.cypress/cypress/integration |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Mechanism for executing JavaScript unit tests 776635426 | |
| 783560017 | https://github.com/simonw/datasette/issues/1166#issuecomment-783560017 | https://api.github.com/repos/simonw/datasette/issues/1166 | MDEyOklzc3VlQ29tbWVudDc4MzU2MDAxNw== | thorn0 94334 | 2021-02-22T18:00:57Z | 2021-02-22T18:13:11Z | NONE | Hi! I don't think Prettier supports this syntax for globs: Tested it. Apparently, it works as a negated character class in regexes (like
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Adopt Prettier for JavaScript code formatting 777140799 | |
| 754911290 | https://github.com/simonw/datasette/issues/1171#issuecomment-754911290 | https://api.github.com/repos/simonw/datasette/issues/1171 | MDEyOklzc3VlQ29tbWVudDc1NDkxMTI5MA== | rcoup 59874 | 2021-01-05T21:31:15Z | 2021-01-05T21:31:15Z | NONE | We did this for Sno under macOS — it's a PyInstaller binary/setup which uses Packages for packaging.
FYI (if you ever get to it) for Windows you need to get a code signing certificate. And if you want automated CI, you'll want to get an "EV CodeSigning for HSM" certificate from GlobalSign, which then lets you put the certificate into Azure Key Vault. Which you can use with azuresigntool to sign your code & installer. (Non-EV certificates are a waste of time, the user still gets big warnings at install time). |
{
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} |
GitHub Actions workflow to build and sign macOS binary executables 778450486 | |
| 1195442266 | https://github.com/simonw/datasette/issues/1175#issuecomment-1195442266 | https://api.github.com/repos/simonw/datasette/issues/1175 | IC_kwDOBm6k_c5HQQBa | RamiAwar 8523191 | 2022-07-26T12:52:10Z | 2022-07-26T12:52:10Z | NONE | I'm using this in a separate FastAPI app, worked perfectly when I changed the AsyncBoundLogger to BoundLogger only. Also for some reason, I'm now getting some logs surfacing from internal packages, like Elasticsearch. But don't have time to deal with that now. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Use structlog for logging 779156520 | |
| 762488336 | https://github.com/simonw/datasette/issues/1175#issuecomment-762488336 | https://api.github.com/repos/simonw/datasette/issues/1175 | MDEyOklzc3VlQ29tbWVudDc2MjQ4ODMzNg== | hannseman 758858 | 2021-01-18T21:59:28Z | 2021-01-18T22:00:31Z | NONE | I encountered your issue when trying to find a solution and came up with the following, maybe it can help. ```python import logging.config from typing import Tuple import structlog import uvicorn from example.config import settings shared_processors: Tuple[structlog.types.Processor, ...] = ( structlog.contextvars.merge_contextvars, structlog.stdlib.add_logger_name, structlog.stdlib.add_log_level, structlog.processors.TimeStamper(fmt="iso"), ) logging_config = { "version": 1, "disable_existing_loggers": False, "formatters": { "json": { "()": structlog.stdlib.ProcessorFormatter, "processor": structlog.processors.JSONRenderer(), "foreign_pre_chain": shared_processors, }, "console": { "()": structlog.stdlib.ProcessorFormatter, "processor": structlog.dev.ConsoleRenderer(), "foreign_pre_chain": shared_processors, }, **uvicorn.config.LOGGING_CONFIG["formatters"], }, "handlers": { "default": { "level": "DEBUG", "class": "logging.StreamHandler", "formatter": "json" if not settings.debug else "console", }, "uvicorn.access": { "level": "INFO", "class": "logging.StreamHandler", "formatter": "access", }, "uvicorn.default": { "level": "INFO", "class": "logging.StreamHandler", "formatter": "default", }, }, "loggers": { "": {"handlers": ["default"], "level": "INFO"}, "uvicorn.error": { "handlers": ["default" if not settings.debug else "uvicorn.default"], "level": "INFO", "propagate": False, }, "uvicorn.access": { "handlers": ["default" if not settings.debug else "uvicorn.access"], "level": "INFO", "propagate": False, }, }, } def setup_logging() -> None: structlog.configure( processors=[ structlog.stdlib.filter_by_level, *shared_processors, structlog.stdlib.PositionalArgumentsFormatter(), structlog.processors.StackInfoRenderer(), structlog.processors.format_exc_info, structlog.stdlib.ProcessorFormatter.wrap_for_formatter, ], context_class=dict, logger_factory=structlog.stdlib.LoggerFactory(), wrapper_class=structlog.stdlib.AsyncBoundLogger, cache_logger_on_first_use=True, ) logging.config.dictConfig(logging_config) ``` And then it'll be run on the startup event:
It depends on a setting called |
{
"total_count": 15,
"+1": 7,
"-1": 0,
"laugh": 1,
"hooray": 1,
"confused": 0,
"heart": 5,
"rocket": 1,
"eyes": 0
} |
Use structlog for logging 779156520 | |
| 984569477 | https://github.com/simonw/datasette/issues/1175#issuecomment-984569477 | https://api.github.com/repos/simonw/datasette/issues/1175 | IC_kwDOBm6k_c46r1aF | AnkitKundariya 24821294 | 2021-12-02T12:09:30Z | 2021-12-02T12:09:30Z | NONE | @hannseman I have tried the above suggestion given by you but somehow I'm getting the below error. note : I'm running my application with Docker.
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Use structlog for logging 779156520 | |
| 998999230 | https://github.com/simonw/datasette/issues/1181#issuecomment-998999230 | https://api.github.com/repos/simonw/datasette/issues/1181 | IC_kwDOBm6k_c47i4S- | rayvoelker 9308268 | 2021-12-21T18:25:15Z | 2021-12-21T18:25:15Z | NONE | I wonder if I'm encountering the same bug (or something related). I had previously been using the .csv feature to run queries and then fetch results for the pandas Datasette v0.59.4
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Certain database names results in 404: "Database not found: None" 781262510 | |
| 765639968 | https://github.com/simonw/datasette/issues/1196#issuecomment-765639968 | https://api.github.com/repos/simonw/datasette/issues/1196 | MDEyOklzc3VlQ29tbWVudDc2NTYzOTk2OA== | QAInsights 2826376 | 2021-01-22T19:37:15Z | 2021-01-22T19:37:15Z | NONE | I tried deployment in WSL. It is working fine https://jmeter.vercel.app/ |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Access Denied Error in Windows 791237799 | |
| 819775388 | https://github.com/simonw/datasette/issues/1196#issuecomment-819775388 | https://api.github.com/repos/simonw/datasette/issues/1196 | MDEyOklzc3VlQ29tbWVudDgxOTc3NTM4OA== | robroc 1219001 | 2021-04-14T19:28:38Z | 2021-04-14T19:28:38Z | NONE | @QAInsights I'm having a similar problem when publishing to Cloud Run on Windows. It's not able to access certain packages in my conda environment where Datasette is installed. Can you explain how you got it to work in WSL? Were you able to access the .db file in the Windows file system? Thank you. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Access Denied Error in Windows 791237799 | |
| 355487646 | https://github.com/simonw/datasette/issues/120#issuecomment-355487646 | https://api.github.com/repos/simonw/datasette/issues/120 | MDEyOklzc3VlQ29tbWVudDM1NTQ4NzY0Ng== | nickdirienzo 723567 | 2018-01-05T07:10:12Z | 2018-01-05T07:10:12Z | NONE | Ah, glad I found this issue. I have private data that I'd like to share to a few different people. Personally, a shared username and password would be sufficient for me, more-or-less Basic Auth. Do you have more complex requirements in mind? I'm not sure if "plugin" means "build a plugin" or "find a plugin" or something else entirely. FWIW, I stumbled upon sanic-auth which looks like a new project to bring some interfaces around auth to sanic, similar to Flask. Alternatively, it shouldn't be too bad to add in Basic Auth. If we went down that route, that would probably be best built as a separate package for sanic that What are your thoughts around this? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Plugin that adds an authentication layer of some sort 275087397 | |
| 439421164 | https://github.com/simonw/datasette/issues/120#issuecomment-439421164 | https://api.github.com/repos/simonw/datasette/issues/120 | MDEyOklzc3VlQ29tbWVudDQzOTQyMTE2NA== | ad-si 36796532 | 2018-11-16T15:05:18Z | 2018-11-16T15:05:18Z | NONE | This would be an awesome feature ❤️ |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Plugin that adds an authentication layer of some sort 275087397 | |
| 496966227 | https://github.com/simonw/datasette/issues/120#issuecomment-496966227 | https://api.github.com/repos/simonw/datasette/issues/120 | MDEyOklzc3VlQ29tbWVudDQ5Njk2NjIyNw== | duarteocarmo 26342344 | 2019-05-29T14:40:52Z | 2019-05-29T14:40:52Z | NONE | I would really like this. If you give me some pointers @simonw I'm willing to PR! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Plugin that adds an authentication layer of some sort 275087397 | |
| 773977128 | https://github.com/simonw/datasette/issues/1210#issuecomment-773977128 | https://api.github.com/repos/simonw/datasette/issues/1210 | MDEyOklzc3VlQ29tbWVudDc3Mzk3NzEyOA== | heyarne 525780 | 2021-02-05T11:30:34Z | 2021-02-05T11:30:34Z | NONE | Thanks for your quick reply! Having changed my |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Immutable Database w/ Canned Queries 796234313 | |
| 1303299509 | https://github.com/simonw/datasette/issues/1217#issuecomment-1303299509 | https://api.github.com/repos/simonw/datasette/issues/1217 | IC_kwDOBm6k_c5NrsW1 | mattmalcher 31312775 | 2022-11-04T11:35:13Z | 2022-11-04T11:35:13Z | NONE | The following worked for deployment to RStudio / Posit Connect An app.py along the lines of: ```python from pathlib import Path from datasette.app import Datasette example_db = Path(file).parent / "data" / "example.db" use connect 'Content URL' setting here to set app to /datasette/ds = Datasette(files=[example_db], settings={"base_url": "/datasette/"}) ds._startup_invoked = True
ds_app = ds.app()
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Possible to deploy as a python app (for Rstudio connect server)? 802513359 | |
| 1303301786 | https://github.com/simonw/datasette/issues/1217#issuecomment-1303301786 | https://api.github.com/repos/simonw/datasette/issues/1217 | IC_kwDOBm6k_c5Nrs6a | mattmalcher 31312775 | 2022-11-04T11:37:52Z | 2022-11-04T11:37:52Z | NONE | All seems to work well, but there are some glitches to do with proxies, see #1883 . Excited to use this :) |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Possible to deploy as a python app (for Rstudio connect server)? 802513359 | |
| 774385092 | https://github.com/simonw/datasette/issues/1217#issuecomment-774385092 | https://api.github.com/repos/simonw/datasette/issues/1217 | MDEyOklzc3VlQ29tbWVudDc3NDM4NTA5Mg== | plpxsk 6165713 | 2021-02-06T02:49:11Z | 2021-02-06T02:49:11Z | NONE | A good reference seems to be the note to run |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Possible to deploy as a python app (for Rstudio connect server)? 802513359 | |
| 774528913 | https://github.com/simonw/datasette/issues/1217#issuecomment-774528913 | https://api.github.com/repos/simonw/datasette/issues/1217 | MDEyOklzc3VlQ29tbWVudDc3NDUyODkxMw== | virtadpt 639730 | 2021-02-06T19:23:41Z | 2021-02-06T19:23:41Z | NONE | I've had a lot of success running it as an OpenFaaS lambda. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Possible to deploy as a python app (for Rstudio connect server)? 802513359 | |
| 784157345 | https://github.com/simonw/datasette/issues/1218#issuecomment-784157345 | https://api.github.com/repos/simonw/datasette/issues/1218 | MDEyOklzc3VlQ29tbWVudDc4NDE1NzM0NQ== | soobrosa 1244799 | 2021-02-23T12:12:17Z | 2021-02-23T12:12:17Z | NONE | Topline this fixed the same problem for me.
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
/usr/local/opt/python3/bin/python3.6: bad interpreter: No such file or directory 803356942 | |
| 778008752 | https://github.com/simonw/datasette/issues/1220#issuecomment-778008752 | https://api.github.com/repos/simonw/datasette/issues/1220 | MDEyOklzc3VlQ29tbWVudDc3ODAwODc1Mg== | aborruso 30607 | 2021-02-12T06:37:34Z | 2021-02-12T06:37:34Z | NONE | I have used my path, I'm running it from the folder in wich I have the db. Do I must an absolute path? Do I must create exactly that folder? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Installing datasette via docker: Path 'fixtures.db' does not exist 806743116 | |
| 778467759 | https://github.com/simonw/datasette/issues/1220#issuecomment-778467759 | https://api.github.com/repos/simonw/datasette/issues/1220 | MDEyOklzc3VlQ29tbWVudDc3ODQ2Nzc1OQ== | aborruso 30607 | 2021-02-12T21:35:17Z | 2021-02-12T21:35:17Z | NONE | Thank you |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Installing datasette via docker: Path 'fixtures.db' does not exist 806743116 | |
| 1072954795 | https://github.com/simonw/datasette/issues/1228#issuecomment-1072954795 | https://api.github.com/repos/simonw/datasette/issues/1228 | IC_kwDOBm6k_c4_8_2r | Kabouik 7107523 | 2022-03-19T06:44:40Z | 2022-03-19T06:44:40Z | NONE |
Exactly, that's highly likely even though I can't double check from this computer just now. Thanks! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
500 error caused by faceting if a column called `n` exists 810397025 | |
| 698110186 | https://github.com/simonw/datasette/issues/123#issuecomment-698110186 | https://api.github.com/repos/simonw/datasette/issues/123 | MDEyOklzc3VlQ29tbWVudDY5ODExMDE4Ng== | obra 45416 | 2020-09-24T04:49:51Z | 2020-09-24T04:49:51Z | NONE | As a half-measure, I'd get value out of being able to upload a CSV and have datasette run csv-to-sqlite on it. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Datasette serve should accept paths/URLs to CSVs and other file formats 275125561 | |
| 698174957 | https://github.com/simonw/datasette/issues/123#issuecomment-698174957 | https://api.github.com/repos/simonw/datasette/issues/123 | MDEyOklzc3VlQ29tbWVudDY5ODE3NDk1Nw== | obra 45416 | 2020-09-24T07:42:05Z | 2020-09-24T07:42:05Z | NONE | Oh. Awesome. On Thu, Sep 24, 2020 at 12:28:53AM -0700, Simon Willison wrote:
-- |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Datasette serve should accept paths/URLs to CSVs and other file formats 275125561 | |
| 735440555 | https://github.com/simonw/datasette/issues/123#issuecomment-735440555 | https://api.github.com/repos/simonw/datasette/issues/123 | MDEyOklzc3VlQ29tbWVudDczNTQ0MDU1NQ== | jsancho-gpl 11912854 | 2020-11-29T19:12:30Z | 2020-11-29T19:12:30Z | NONE | datasette-connectors provides an API for making connectors for any file based database. For example, datasette-pytables is a connector for HDF5 files, so now is possible to use this type of files with Datasette. It'd be nice if Datasette coud provide that API directly, for other file formats and for urls too. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Datasette serve should accept paths/URLs to CSVs and other file formats 275125561 | |
| 882096402 | https://github.com/simonw/datasette/issues/123#issuecomment-882096402 | https://api.github.com/repos/simonw/datasette/issues/123 | IC_kwDOBm6k_c40k7kS | RayBB 921217 | 2021-07-18T18:07:29Z | 2021-07-18T18:07:29Z | NONE | I also love the idea for this feature and wonder if it could work without having to download the whole database into memory at once if it's a rather large db. Obviously this could be slower but could have many use cases. My comment is partially inspired by this post about streaming sqlite dbs from github pages or such https://news.ycombinator.com/item?id=27016630 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Datasette serve should accept paths/URLs to CSVs and other file formats 275125561 | |
| 781330466 | https://github.com/simonw/datasette/issues/1230#issuecomment-781330466 | https://api.github.com/repos/simonw/datasette/issues/1230 | MDEyOklzc3VlQ29tbWVudDc4MTMzMDQ2Ng== | Kabouik 7107523 | 2021-02-18T13:06:22Z | 2021-02-18T15:22:15Z | NONE | [Edit] Oh, I just saw the "Load all" button under the cluster map as well as the setting to alter the max number or results. So I guess this issue only is about the Vega charts.
Note that datasette-cluster-map also seems to be limited to 998 displayed points:

|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Vega charts are plotted only for rows on the visible page, cluster maps only for rows in the remaining pages 811054000 | |
| 790857004 | https://github.com/simonw/datasette/issues/1238#issuecomment-790857004 | https://api.github.com/repos/simonw/datasette/issues/1238 | MDEyOklzc3VlQ29tbWVudDc5MDg1NzAwNA== | tsibley 79913 | 2021-03-04T19:06:55Z | 2021-03-04T19:06:55Z | NONE | @rgieseke Ah, that's super helpful. Thank you for the workaround for now! |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Custom pages don't work with base_url setting 813899472 | |
| 346987395 | https://github.com/simonw/datasette/issues/124#issuecomment-346987395 | https://api.github.com/repos/simonw/datasette/issues/124 | MDEyOklzc3VlQ29tbWVudDM0Njk4NzM5NQ== | janimo 50138 | 2017-11-26T06:24:08Z | 2017-11-26T06:24:08Z | NONE | Are there performance gains when using immutable as opposed to read-only? From what I see other processes can still modify the DB when immutable, but there are no change notifications. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Option to open readonly but not immutable 275125805 | |
| 347123991 | https://github.com/simonw/datasette/issues/124#issuecomment-347123991 | https://api.github.com/repos/simonw/datasette/issues/124 | MDEyOklzc3VlQ29tbWVudDM0NzEyMzk5MQ== | janimo 50138 | 2017-11-27T09:25:15Z | 2017-11-27T09:25:15Z | NONE | That's the only reference to immutable I saw as well, making me think that there may be no perceivable advantages over simply using mode=ro. Since the database is never or seldom updated the change notifications should not impact performance. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Option to open readonly but not immutable 275125805 | |
| 784312460 | https://github.com/simonw/datasette/issues/1240#issuecomment-784312460 | https://api.github.com/repos/simonw/datasette/issues/1240 | MDEyOklzc3VlQ29tbWVudDc4NDMxMjQ2MA== | Kabouik 7107523 | 2021-02-23T16:07:10Z | 2021-02-23T16:08:28Z | NONE | Likewise, while answering to another issue regarding the Vega plugin, I realized that there is no such way of linking rows after a custom query, I only get this "Link" column with individual URLs for the default SQL view:
Or is it there and I am just missing the option in my custom queries? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Allow facetting on custom queries 814591962 | |
| 1692322342 | https://github.com/simonw/datasette/issues/1241#issuecomment-1692322342 | https://api.github.com/repos/simonw/datasette/issues/1241 | IC_kwDOBm6k_c5k3som | publicmatt 52261150 | 2023-08-24T19:56:15Z | 2023-08-24T20:09:52Z | NONE | Something to think about, but I hate how long the url is when sharing a custom SQL query. Would it be possible to hash the query and state of a page instead so the url is more manageable? The mapping from hash to query would have to be stored in order to recover/lookup the page after sharing. It's not uncommon to have things like this currently: I'm thinking a plugin like https://datasette.io/plugins/datasette-query-files, but could be created and managed from the UI (with the right permissions). |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Share button for copying current URL 814595021 | |
| 784347646 | https://github.com/simonw/datasette/issues/1241#issuecomment-784347646 | https://api.github.com/repos/simonw/datasette/issues/1241 | MDEyOklzc3VlQ29tbWVudDc4NDM0NzY0Ng== | Kabouik 7107523 | 2021-02-23T16:55:26Z | 2021-02-23T16:57:39Z | NONE |
Absolutely, that's why I thought my corner case with |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Share button for copying current URL 814595021 | |
| 812711365 | https://github.com/simonw/datasette/issues/1245#issuecomment-812711365 | https://api.github.com/repos/simonw/datasette/issues/1245 | MDEyOklzc3VlQ29tbWVudDgxMjcxMTM2NQ== | jungle-boogie 1111743 | 2021-04-02T20:53:35Z | 2021-04-02T20:53:35Z | NONE | Yes, I agree. Alternatively, maybe the header could be at the top and bottom, above the next page button. Maybe even have the header 50 records down? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Sticky table column headers would be useful, especially on the query page 817544251 | |
| 955384545 | https://github.com/simonw/datasette/issues/1253#issuecomment-955384545 | https://api.github.com/repos/simonw/datasette/issues/1253 | IC_kwDOBm6k_c448gLh | dufferzafar 1449512 | 2021-10-30T16:00:42Z | 2021-10-30T16:00:42Z | NONE | Yeah, I was pressing Ctrl + Enter as well. Came here to open this issue and found out Shift + Enter works. @simonw Any way to configure this? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Capture "Ctrl + Enter" or "⌘ + Enter" to send SQL query? 826064552 | |
| 812680519 | https://github.com/simonw/datasette/issues/1255#issuecomment-812680519 | https://api.github.com/repos/simonw/datasette/issues/1255 | MDEyOklzc3VlQ29tbWVudDgxMjY4MDUxOQ== | jungle-boogie 1111743 | 2021-04-02T19:37:57Z | 2021-04-02T19:37:57Z | NONE | Hello, I'm also experiencing a timeout in my environment. I don't know if it's because I need more indexes or a more powerful system. My data has 1,271,111 and when I try to create a facet, there's a time out. I've tried this on two different rows that should significantly filter down data: Simon's johns_hopkins_csse_daily_reports has more rows and it setup with two facets on load. He does have four indexes created, though. Do I need more indexes? I have one simple one so far:
I'm running Datasette 0.56 installed via pip with Python 3.7.3.
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Facets timing out but work when filtering 826700095 | |
| 812710120 | https://github.com/simonw/datasette/issues/1255#issuecomment-812710120 | https://api.github.com/repos/simonw/datasette/issues/1255 | MDEyOklzc3VlQ29tbWVudDgxMjcxMDEyMA== | jungle-boogie 1111743 | 2021-04-02T20:50:08Z | 2021-04-02T20:50:08Z | NONE | Hello again, I was able to get my facets running with this
|
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Facets timing out but work when filtering 826700095 | |
| 807459633 | https://github.com/simonw/datasette/issues/1258#issuecomment-807459633 | https://api.github.com/repos/simonw/datasette/issues/1258 | MDEyOklzc3VlQ29tbWVudDgwNzQ1OTYzMw== | wdccdw 1385831 | 2021-03-25T20:48:33Z | 2021-03-25T20:49:34Z | NONE | What about allowing default parameters when defining the query in metadata.yml? Something like:
For now, I'm using a custom database-<file>.html file that hardcodes a default param in the link, but I'd rather not customize the template just for that. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Allow canned query params to specify default values 828858421 | |
| 803499509 | https://github.com/simonw/datasette/issues/1261#issuecomment-803499509 | https://api.github.com/repos/simonw/datasette/issues/1261 | MDEyOklzc3VlQ29tbWVudDgwMzQ5OTUwOQ== | brimstone 812795 | 2021-03-21T02:06:43Z | 2021-03-21T02:06:43Z | NONE | I can confirm 0.9.2 fixes the problem. Thanks for the fast response! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Some links aren't properly URL encoded. 832092321 | |
| 802164134 | https://github.com/simonw/datasette/issues/1262#issuecomment-802164134 | https://api.github.com/repos/simonw/datasette/issues/1262 | MDEyOklzc3VlQ29tbWVudDgwMjE2NDEzNA== | henry501 19328961 | 2021-03-18T17:55:00Z | 2021-03-18T17:55:00Z | NONE | Thanks for the comments. I'll take a look at the documentation to familiarize myself, as I haven't tried to write any plugins yet. With some luck I might be ready to write it when the hook is implemented. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Plugin hook that could support 'order by random()' for table view 834602299 | |
| 803160804 | https://github.com/simonw/datasette/issues/1265#issuecomment-803160804 | https://api.github.com/repos/simonw/datasette/issues/1265 | MDEyOklzc3VlQ29tbWVudDgwMzE2MDgwNA== | yunzheng 468612 | 2021-03-19T22:05:12Z | 2021-03-19T22:05:12Z | NONE | Wow that was fast! Thanks for this very cool project and quick update! 👍 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Support for HTTP Basic Authentication 836123030 | |
| 1199115002 | https://github.com/simonw/datasette/issues/1272#issuecomment-1199115002 | https://api.github.com/repos/simonw/datasette/issues/1272 | IC_kwDOBm6k_c5HeQr6 | xmichele 37748899 | 2022-07-29T10:22:58Z | 2022-07-29T10:22:58Z | NONE |
Hello, can't you copy in a later step directly in the output directory, e.g. COPY test_dockerfile.py /usr/lib/python*/.. or something like that ? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Unit tests for the Dockerfile 838245338 | |
| 811209922 | https://github.com/simonw/datasette/issues/1276#issuecomment-811209922 | https://api.github.com/repos/simonw/datasette/issues/1276 | MDEyOklzc3VlQ29tbWVudDgxMTIwOTkyMg== | justinallen 1314318 | 2021-03-31T16:27:26Z | 2021-03-31T16:27:26Z | NONE | Fantastic. Thank you! |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Invalid SQL: "no such table: pragma_database_list" on database page 841456306 | |
| 860047794 | https://github.com/simonw/datasette/issues/1286#issuecomment-860047794 | https://api.github.com/repos/simonw/datasette/issues/1286 | MDEyOklzc3VlQ29tbWVudDg2MDA0Nzc5NA== | frafra 4068 | 2021-06-12T12:36:15Z | 2021-06-12T12:36:15Z | NONE | @mroswell That is a very nice solution. I wonder if custom classes, like |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Better default display of arrays of items 849220154 | |
| 1125083348 | https://github.com/simonw/datasette/issues/1298#issuecomment-1125083348 | https://api.github.com/repos/simonw/datasette/issues/1298 | IC_kwDOBm6k_c5DD2jU | llimllib 7150 | 2022-05-12T14:43:51Z | 2022-05-12T14:43:51Z | NONE | user report: I found this issue because the first time I tried to use datasette for real, I displayed a large table, and thought there was no horizontal scroll bar at all. I didn't even consider that I had to scroll all the way to the end of the page to find it. Just chipping in to say that this confused me, and I didn't even find the scroll bar until after I saw this issue. I don't know what the right answer is, but IMO the UI should suggest to the user that there is a way to view the data that's hidden to the right. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
improve table horizontal scroll experience 855476501 | |
| 823064725 | https://github.com/simonw/datasette/issues/1298#issuecomment-823064725 | https://api.github.com/repos/simonw/datasette/issues/1298 | MDEyOklzc3VlQ29tbWVudDgyMzA2NDcyNQ== | dracos 154364 | 2021-04-20T07:57:14Z | 2021-04-20T07:57:14Z | NONE | My suggestions, originally made on twitter, but might be better here now:
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
improve table horizontal scroll experience 855476501 | |
| 823102978 | https://github.com/simonw/datasette/issues/1298#issuecomment-823102978 | https://api.github.com/repos/simonw/datasette/issues/1298 | MDEyOklzc3VlQ29tbWVudDgyMzEwMjk3OA== | dracos 154364 | 2021-04-20T08:51:23Z | 2021-04-20T08:51:23Z | NONE |
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
improve table horizontal scroll experience 855476501 | |
| 981980048 | https://github.com/simonw/datasette/issues/1304#issuecomment-981980048 | https://api.github.com/repos/simonw/datasette/issues/1304 | IC_kwDOBm6k_c46h9OQ | 20after4 30934 | 2021-11-29T20:13:53Z | 2021-11-29T20:14:11Z | NONE | There isn't any way to do this with sqlite as far as I know. The only option is to insert the right number of ? placeholders into the sql template and then provide an array of values. |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Document how to send multiple values for "Named parameters" 863884805 | |
| 988459453 | https://github.com/simonw/datasette/issues/1304#issuecomment-988459453 | https://api.github.com/repos/simonw/datasette/issues/1304 | IC_kwDOBm6k_c466rG9 | rayvoelker 9308268 | 2021-12-08T03:15:27Z | 2021-12-08T03:15:27Z | NONE | I was thinking if there were a way to use some sort of sting function to "unpack" the values and convert them into ints... hm |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Document how to send multiple values for "Named parameters" 863884805 | |
| 988461884 | https://github.com/simonw/datasette/issues/1304#issuecomment-988461884 | https://api.github.com/repos/simonw/datasette/issues/1304 | IC_kwDOBm6k_c466rs8 | 20after4 30934 | 2021-12-08T03:20:26Z | 2021-12-08T03:20:26Z | NONE | The easiest or most straightforward thing to do is to use named parameters like:
And simply construct the list of placeholders dynamically based on the number of values. Doing this is possible with datasette if you forgo "canned queries" and just use the raw query endpoint and pass the query sql, along with p1, p2 ... in the request. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Document how to send multiple values for "Named parameters" 863884805 | |
| 988463455 | https://github.com/simonw/datasette/issues/1304#issuecomment-988463455 | https://api.github.com/repos/simonw/datasette/issues/1304 | IC_kwDOBm6k_c466sFf | 20after4 30934 | 2021-12-08T03:23:14Z | 2021-12-08T03:23:14Z | NONE | I actually think it would be a useful thing to add support for in datasette. It wouldn't be difficult to unwind an array of params and add the placeholders automatically. |
{
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Document how to send multiple values for "Named parameters" 863884805 | |
| 828670621 | https://github.com/simonw/datasette/issues/1310#issuecomment-828670621 | https://api.github.com/repos/simonw/datasette/issues/1310 | MDEyOklzc3VlQ29tbWVudDgyODY3MDYyMQ== | ColinMaudry 3747136 | 2021-04-28T18:12:08Z | 2021-04-28T18:12:08Z | NONE | Apparently, beside a string, Reponse could also work with bytes. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
I'm creating a plugin to export a spreadsheet file (.ods or .xlsx) 870125126 | |
| 829885904 | https://github.com/simonw/datasette/issues/1310#issuecomment-829885904 | https://api.github.com/repos/simonw/datasette/issues/1310 | MDEyOklzc3VlQ29tbWVudDgyOTg4NTkwNA== | ColinMaudry 3747136 | 2021-04-30T06:58:46Z | 2021-04-30T07:26:11Z | NONE | I made it work with openpyxl. I'm not sure all the code under ```python from datasette import hookimpl from datasette.utils.asgi import Response from openpyxl import Workbook from openpyxl.writer.excel import save_virtual_workbook from openpyxl.cell import WriteOnlyCell from openpyxl.styles import Alignment, Font, PatternFill from tempfile import NamedTemporaryFile def render_spreadsheet(rows): wb = Workbook(write_only=True) ws = wb.create_sheet() ws = wb.active ws.title = "decp" @hookimpl def register_output_renderer(): return {"extension": "xlsx", "render": render_spreadsheet, "can_render": lambda: False} ``` The key part was to find the right function to wrap the spreadsheet object I'll update this issue when the plugin is packaged and ready for broader use. |
{
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
I'm creating a plugin to export a spreadsheet file (.ods or .xlsx) 870125126 | |
| 847271122 | https://github.com/simonw/datasette/issues/1327#issuecomment-847271122 | https://api.github.com/repos/simonw/datasette/issues/1327 | MDEyOklzc3VlQ29tbWVudDg0NzI3MTEyMg== | GmGniap 20846286 | 2021-05-24T19:10:21Z | 2021-05-24T19:10:21Z | NONE | wow, thanks a lot @simonw , problem is solved. I converted my current json file into utf-8 format with Python script. It's working now. I'm using with Window 10. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Support Unicode characters in metadata.json 892457208 | |
| 842495820 | https://github.com/simonw/datasette/issues/1331#issuecomment-842495820 | https://api.github.com/repos/simonw/datasette/issues/1331 | MDEyOklzc3VlQ29tbWVudDg0MjQ5NTgyMA== | MarkusH 475613 | 2021-05-17T17:18:05Z | 2021-05-17T17:18:05Z | NONE | Wow, you are fast! I didn't notice dependabot had opened a PR already. I was about to. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Add support for Jinja2 version 3.0 893537744 |






{kind=link}
Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issue_comments] (
[html_url] TEXT,
[issue_url] TEXT,
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[created_at] TEXT,
[updated_at] TEXT,
[author_association] TEXT,
[body] TEXT,
[reactions] TEXT,
[issue] INTEGER REFERENCES [issues]([id])
, [performed_via_github_app] TEXT);
CREATE INDEX [idx_issue_comments_issue]
ON [issue_comments] ([issue]);
CREATE INDEX [idx_issue_comments_user]
ON [issue_comments] ([user]);
user >30